试验统计方法复习题
试验统计方法_习题集(含答案)

《试验统计方法》课程习题集一、单选题1.∑(X-Y)=0, 则()A Y为任意数B Y为正数C Y=0D Y=⎺X2.用加权法计算平均数⎺X,其中的权是()。
A 组中值B 样本容量C 组次数D 平均数3. X落在正态分布(-∞,μ-2σ)内的概率为 ( )。
A 0.95B 0.9545C 0.02275D 0.0254.小样本要用t测验是因为 ( )。
A t分布不涉及参数B 小样本的标准离差服从t分布C t值使用了样本容量D 小样本趋于t分布5.己知变量X和Y之间存在相关关系,则X和Y的相关系数可能是( )A 0.05B -0.86C 1.04D 1.816.进行统计假设测验时,否定H0的依据是()。
A 经验判断B 抽样分布C 小概率原理D 统计数间的差异7.方差分析是一种( )的方法。
A 分解平方和B F测验C 多样本平均数测验D 假设测验8.实施品比试验时,同一重复()完成。
A 可以分期B 必须同时C 一天内 D不超出两天9.与两尾测验相比,一尾测验()。
A 犯α错误概率增大B 犯β错误概率增大C α、β错误增大D α、β错误不变10.r=0.5,表明x和y的变异可以相互以线性关系说明的部分占了( )。
A 50%B 25%C 75%D 45%11.田间试验设计中采用局部控制可以()。
A 降低误差B 估计误差C 便于试验操作D 消除误差12.组内又分亚组的单向分组资料的方差分析()。
A 处理效应可再分解B 误差效应可再分解C 平均数可再分解D 组内可再分解13. P (∣X-μ∣≥1σ)=( )。
A 0.6826B 0.9545C 0.3174D 0.997314.随机区组试验中,区组项平方和的大小反映了()。
A 土壤差异情况B 处理差异情况C 样本差异情况D 总体差异情况15.样本标准差S是( )。
A 相对变异量B 绝对变异量C 平均变异量D 总变异量16.二项分布的平均数μ=( )。
A pB 1-pC npD pq17.多重比较时犯α错误的概率依次为( )。
试验统计方法复习资料

生统——Spring一、名词解释1.试验方案:根据试验目的和要求所拟进行比较的一组试验处理的总称。
2.试验因素:被变动并设有比较的一组处理的因子。
简称因素或因子。
3.单因素试验:整个试验中只变更、比较一个试验因素的不同水平,其它作为试验条件的因素均严格控制一致的试验。
4.多因素试验:在同一试验方案中包含两个或两个以上的试验因素,各个因素都分为不同水平,其它试验条件均严格控制一致的试验。
5.处理组合:各因素不同水平的组合。
6.试验指标:用于衡量试验效果的指示性状。
7.试验效应:试验因素对试验指标所起的增加或减少的作用。
8.简单效应:在同一因素内两种水平间试验指标的相差。
9.平均效应:一个因素内各简单效应的平均数。
也称主要效应,简称主效。
10.交互作用效应:两个因素简单效应间的平均差异。
简称互作。
11.对照:试验方案中包括有对照水平或处理,简称对照。
(试验当中所设计的比较标准的处理)12.唯一差异原则:指在试验中进行比较的各个处理,其间的差别仅在于不同的试验因素或不同的水平,其余所有的条件都应完全一致。
13.误差:测量值与真实值之间的差异称为误差。
14.随机误差:由随机或偶然因素造成的试验结果与处理真值之间的差异称为偶然性误差或随机误差。
15.系统误差:由固定原因一起的试验结果与处理真值之间的差异称为系统误差。
16.精确度:试验中同一性状的重复观察值彼此接近的程度。
(即试验误差的大小)17.准确度:试验中某一性状的观察值与其理论值真值的接近程度。
18.空白试验:在整个试验地上种植单一品种的作物。
19.匀田种植:在即将进行试验的土地上连续几茬播种密生植物以便均衡土壤肥力差异的方法。
20.重复:试验中同一处理种植小区数即为重复次数。
21.随机排列:指一个区组中每一处理都有同等的机会设置在任何一个试验小区上,避免任何主观成见。
22.局部控制:指将整个试验环境分成若干个相对最为一致的小环境,再在小环境内设置成套处理,使非试验因素(试验环境)最大程度的一致。
试验统计方法复习题

试验统计方法复习题试验统计方法复习题1.何谓实验因素和实验水平?何谓简单效应、主要效应和交互效应?举例说明之。
实验因素: 被变动并设有待比较的一组处理的因子或试验研究的对象。
实验水平: 实验因素的量的不同级别或质的不同状态。
简单效应: 同一因素内俩种水平间实验指标的相差。
主要效应:一个因素内各简单效应的平均数。
交互效应:俩个因素简单效应间的平均差异。
2.什么是实验方案,如何制定一个正确的实验方案?试结合所学专业举例说明之。
试验指标:用于衡量试验效果的指示性状。
制定实验方案的要点○1.目的明确。
○2. 选择适当的因素及其水平。
○3设置对照水平或处理,简称对照(check,符号CK)。
○4应用唯一差异原则。
3.什么是实验误差?实验误差与实验的准确度、精确度以及实验处理间的比较的可靠性有什么关系?○1.试验误差的概念:试验结果与处理真值之间的差异.○2随机误差影响了数据的精确性,精确性是指观测值间的符合程度,随机误差是偶然性的,整个试验过程中涉及的随机波动因素愈多,试验的环节愈多,时间愈长,随机误差发生的可能性及波动程度便愈大。
系统误差是可以通过试验条件及试验过程的仔细操作而控制的。
实际上一些主要的系统性偏差较易控制,而有些细微偏差则较难控制。
4.试分析田间实验误差的主要来源,如何控制田间实验的系统误差?如何降低田间实验的随机误差?误差来源:(1)试验材料固有的差异(2)试验时农事操作和管理技术的不一致所引起的差异(3)进行试验时外界条件的差异控制误差的途径:(1)选择同质一致的试验材料(2) 改进操作和管理技术,使之标准化(3) 控制引起差异的外界主要因素选择条件均匀一致的试验环境;试验中采用适当的试验设计和科学的管理技术;应用相应的科学统计分析方法。
尽量减少实验中的随机波动因素、环节和时间可以有效的降低随机误差。
5.田间实验设计的基本原则是什么?完全随机设计、完全随机区组设计、拉丁设计各有何特点?各在什么情况下使用?(1)基本原则是:○1.重复○2随机排列○3局部控制(2)完全随机设计的特点是设计分析简便,但是应用该设计的条件是要求试验的环境因素相当均匀,所以一般用于实验室培养试验及网、温室的盆钵试验。
《试验统计学》题库

《试验统计学》期末考试题型与范围Ⅰ、试题型与范围一、试范围与分数比例Ⅱ、复习题一、术语解释试验指标 (狭义的)试验方案 (狭义的)试验设计变异系数标准(偏)差标准误(差) 标准正态分布乘积和抽样调查抽样分布处理(组合) 次数分布单向分类资料单因素试验倒数转换第II类错误第I类错误调和平均数独立事件独立性测验对立事件对数转换多因素试验反正弦转换方差方差分析的基本假定复置抽样概率概率(古典定义) 概率(统计定义) 互斥事件回归方程回归估计标准误差回归截距回归平方和回归系数极差几何平均数简单效应交互作用效应精确性局部控制决定系数均方离均差乘积和两向分类资料偶然误差平方根转换平方和平均数平均效应全面调查适合性测验数量性状资料水平随机排列随机事件随机误差统计假设测验唯一差异原则误差平方和系统误差显著水准线性可加模型小概率原理协方差样本样本简单相关系数样本容量样本协方差因变量因素正规方程质量性状资料置信度中数众数主效主要效应准确性自变量自由度总体总体参数的置信区间总体简单相关系数总体协方差概率分布二、选择题⒈_______是指那些用计数方法或者测量方法取得的数据资料。
A、可量资料B、可数资料C、数量性状资料D、质量性状资料⒉_________是指能观察但不能计量的资料。
例如玫瑰花的颜色、学生的性别、人类的血型…等等,都可以归入这类性状。
A、可量资料B、可数资料C、数量性状资料D、质量性状资料⒊按某种质量性状的表现分为若干类,然后将所有观察对象归属到各类之中,统计各类中的个体数。
这类资料叫做_______。
A、可量资料B、可数资料C、属性资料D、不可计量的资料⒋当一种性状只具有两种可能的表现时,可以用一种只可以取0、1两种数值的变量来表示。
这种变量叫______变量。
这种变量也属于离散型随机变量。
A、连续型随机变量B、指示变量C、属性资料D、离散型随机变量⒌按某种质量的表现分为若干类,然后将所有观察对象归属到各类之中,统计各类中的个体数。
田间试验设计与统计分析期末复习试题

一、判断题1. 在采用分层随机抽样时,若各区层所包含的抽样单位数不同,则从各区层抽取单位数应根据其所包含的抽样单位数按比例配置。
(√)2.二项分布属于连续型概率分布(×)3.一般情况下,长方形尤其是狭长形小区的试验误差比正方形小区的大(×)4.准确性是指在试验中某一试验指标或性状的观测值与其真值接近的程度(√)5.调和平均数主要用于反映研究对象不同阶段的平均速率(√)6.在计算植物生长率时,用调和平均数比用算术平均数更能代表其平均水平(×)7.就同一资料而言,调和平均>数几何平均数>算术平均数(×)8.通常将样本容量n30的样本称为大样本,将样本容量n30的样本称为小样本(√)9.正态分布属于离散型概率分布(×)10.统计分析的试验误差主要指随机误差。
这种误差越小,试验的准确性越高(×)二、填空题1. 正交试验设计表的主要性质有正交性、代表性、综合可比性。
2. 两个变量数据依据确定性关系可分为函数关系和相关关系2种类型。
3. 常用统计图的绘制方法主要有直方图、多边形图、条形图、圆图这4种图形。
4.在田间试验中,由观察、测量所得的资料,一般可分为数量性状资料和质量性状资料两大类。
5. 小样本抽样分布主要包括三类分布:t分布、 X²分布和F分布。
6. 随机事件可分为:必然事件、不可能事件和基本事件3种类型7. 常用的田间试验设计方法主要有随机区组试验、随机裂区试验、拉丁方试验。
8. 正交试验设计表的主要类型有两种分别相同水平正交表和混合水平正交表9. 田间试验常用的随机抽样方法有简单随机抽样、分层随机抽样、整群随机抽样和多级随机抽样10. 试验地土壤差异测量的方法有目测法和肥力测定法12. 试验处理重复的作用分别是估计试验误差和降低试验误差。
13. 试验地土壤肥力差异的表现形式大致可分为肥力梯度的变化和斑块状变化。
14. 在研究玉米种植密度和产量的相关关系中,其中种植密度是自变数,产量是依变数15. 小麦品种A每穗小穗数的平均数和标准差值为18和3(厘米),品种B为30和4.5(厘米),根据 CVA 大于_ CVB_,品种_ A _ 的该性状变异大于品种_ B _。
南京农业大学 试验统计方法试卷
6
8.18
11
F 0.23 31.20
P(注:与 0.05 比较) >0.05 <0.05
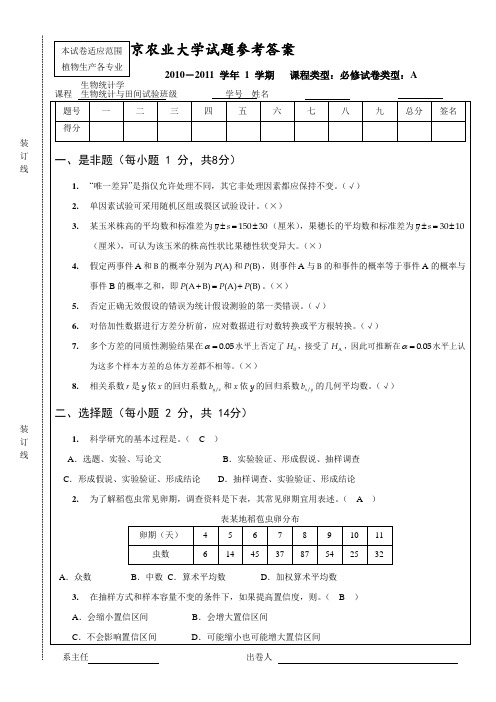
(1)此试验采用的试验设计方法属何种类型?(2 分) 答:随机区组设计。
(2)请将表中缺项补足,并根据表中结果作出结论(注:F0.05(3,6)=4.76,F0.05(6,3)=8.94)。(9 分) (3)能否根据上表中结果推断甲、乙条件下测量结果是否相同?说明如何分析才能得到这个结论。(2 分) 答:不能,应作多重比较。 3.用某农药处理芹麻种根,得如下结果:(本小题 12 分)
活虫
23(12.27)
11(14.68)
5(12.051)
39(39.000)
总数
56(56.00)
67(67.00)
55(55.000) 178(178.000)
2
(Oij
Eij )2
(33 43.73)2
(56 52.32)2
(5 12.051)2
18.4809 (3 分)
Eij
HA :不同浸种时间的杀虫效果有差异[即浸种时间的长短与杀虫效果有关(或相关)](1 分)
②取显著水平 0.05(1 分)
③ 测验计算
理论次数计算(括号中,按 Eij
Oi•O• j O••
计算)
杀虫效果
1 小时
浸种时间 3 小时
(6 分) 5 小时
总数
死虫
33(43.73)
56(52.32)
50(42.949) 139(139.000)
杀虫效果
死虫 活虫 总数
1 小时 33 23 56
浸种时间 3 小时 56 11 67
5 小时 50 5 55
大学试验统计复习题

第一章复习1.解释以下概念:总体、个体、样本、样本容量、变量、参数?1.总体是具有相同性质的个体所组成的集合,是指研究对象的全体。
2.个体是组成总体的基本单元。
3.样本是从总体中抽出的若干个个体所构成的集合。
4.样本容量是指样本个体的数目。
5.变量是相同性质的事物间表现差异性的某种特征。
6.参数是描述总体特征的数量。
7.统计数是描述样本特征的数量。
8.因素是指试验中所研究的影响试验指标的原因或原因组合。
2.统计数、因素、水平、处理、重复、效应、互作、试验误差?1.水平是指每个试验因素的不同状态(处理的某种特定状态或数量上的差别)。
2.处理是指对受试对象给予的某种外部干预(或措施)。
3.重复是指在试验中,将一个处理实施在两个或两个以上的试验单位上。
4.效应是由处理因素作用于受试对象而引起试验差异的作用。
5.互作是指两个或两个以上处理因素间的相互作用产生的效应。
6.试验误差是指试验中不可控因素所引起的观测值偏离真值的差异,可以分为随机误差和系统误差。
3.随机误差与系统误差有何区别?随机误差也称为抽样误差或偶然误差,它是由于试验中许多无法控制的偶然因素所造成的试验结果与真实结果之间的差异,是不可避免的。
随机误差可以通过试验设计和精心管理设法减小,但不能完全消除。
系统误差也称为片面误差,是由于试验处理以外的其他条件明显不一致所产生的带有倾向性的或定向性的偏差。
系统误差主要由一些相对固定的因素引起,在某种程度上是可控制的,在试验过程中是可以避免的。
4.准确性与精确性有何区别?准确性也称为准确度,是指在调查或试验中某一试验指标或性状的观测值与真值接近的程度。
精确性也称为精确度,是指调查或试验中同一试验指标或性状的重复观测值彼此的接近程度的大小。
准确性是说明测定值对真值符合程度的大小,用统计数接近参数真值的程度来衡量。
精确性是反映多次测定值的变异程度,用样本中的各个变量问的变异程度的大小来衡量。
填空1.变量按其性质可以分为(连续)变量和(非连续(离散型))变量。
临床试验统计考题

临床试验统计考题
临床试验统计是医学和医药领域中的重要内容,涉及设计、分析和解释临床试验数据的统计学方法。
以下是一些可能出现在临床试验统计考试中的题目类型:
1.试验设计题:例如,设计一项针对某种疾病治疗效果的临床试验,包括样本量计算、
随机分组设计等。
2.推断统计题:要求根据给定的数据进行推断性统计分析,比如对治疗效果的置信区
间估计、假设检验等。
3.数据分析与解释题:提供试验数据,要求进行描述性统计分析,并解释结果的临床
意义。
4.试验结果解读题:提供试验结果或文献摘要,要求根据数据和统计分析的结果进行
解读,判断治疗效果的可信度或临床实用性。
5.统计学方法应用题:考察某种统计学方法在临床试验中的应用,例如生存分析、重
复测量数据分析等。
这些题目要求考生掌握统计学基础知识,包括假设检验、置信区间、样本量计算、试验设计、数据分析和解释等方面的内容。
备考时,建议多做一些实际案例的练习,熟悉常用的统计软件,并理解统计方法在临床试验中的实际应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
试验统计方法复习题1.何谓实验因素和实验水平?何谓简单效应、主要效应和交互效应?举例说明之。
实验因素: 被变动并设有待比较的一组处理的因子或试验研究的对象。
实验水平: 实验因素的量的不同级别或质的不同状态。
简单效应: 同一因素内俩种水平间实验指标的相差。
主要效应:一个因素内各简单效应的平均数。
交互效应:俩个因素简单效应间的平均差异。
2.什么是实验方案,如何制定一个正确的实验方案?试结合所学专业举例说明之。
试验指标:用于衡量试验效果的指示性状。
制定实验方案的要点○1.目的明确。
○2. 选择适当的因素及其水平。
○3设置对照水平或处理,简称对照(check,符号CK)。
○4应用唯一差异原则。
3.什么是实验误差?实验误差与实验的准确度、精确度以及实验处理间的比较的可靠性有什么关系?○1.试验误差的概念:试验结果与处理真值之间的差异.○2随机误差影响了数据的精确性,精确性是指观测值间的符合程度,随机误差是偶然性的,整个试验过程中涉及的随机波动因素愈多,试验的环节愈多,时间愈长,随机误差发生的可能性及波动程度便愈大。
系统误差是可以通过试验条件及试验过程的仔细操作而控制的。
实际上一些主要的系统性偏差较易控制,而有些细微偏差则较难控制。
4.试分析田间实验误差的主要来源,如何控制田间实验的系统误差?如何降低田间实验的随机误差?误差来源:(1)试验材料固有的差异(2)试验时农事操作和管理技术的不一致所引起的差异(3)进行试验时外界条件的差异控制误差的途径:(1)选择同质一致的试验材料(2) 改进操作和管理技术,使之标准化(3) 控制引起差异的外界主要因素选择条件均匀一致的试验环境;试验中采用适当的试验设计和科学的管理技术;应用相应的科学统计分析方法。
尽量减少实验中的随机波动因素、环节和时间可以有效的降低随机误差。
5.田间实验设计的基本原则是什么?完全随机设计、完全随机区组设计、拉丁设计各有何特点?各在什么情况下使用?(1)基本原则是:○1.重复○2随机排列○3局部控制(2)完全随机设计的特点是设计分析简便,但是应用该设计的条件是要求试验的环境因素相当均匀,所以一般用于实验室培养试验及网、温室的盆钵试验。
完全随机区组设计○1.特点: 根据“局部控制”的原则,将试验地(或试验环境)按肥力变异梯度(或条件变异梯度)划分为等于重复次数的区组,一区组亦即一重复,区组内各处理都独立地随机排列。
○2应用条件:对试验地的地形要求不严,必要时,不同区组亦可分散设置在不同地段上。
拉丁方设计的○1.特点:将处理从纵横二个方向排列为区组(或重复),使每个处理在每一列和每一行中出现的次数相等,精确度高,但缺乏伸缩性。
○2 拉丁方设计的通常应用范围只限于4—8个处理。
当在采用4个处理的拉丁方设计时,为保证鉴别差异的灵敏度,可采用复拉丁方设计,即用2个(4×4)拉丁方。
6.总体、样本、参数、统计数、随机样本的概念和关系?总体:具有共同性质的个体所组成的集团.样本:从总体中抽取若干个个体的集合称为样本。
参数:由总体中全部个体观察值计算得总体特征值.统计数:测定样本中的各个体而得的样本特征数,如平均数等,称为统计数随机样本:从总体中随机抽取的样本称为随机样本关系:试验研究的目的是为了获得总体的信息或特征;试验研究的方法则是抽样研究;利用样本的结果(统计数)推断或估计总体特征 (参数).7.算术平均数的意义和特征?平均数:是数据的代表值,表示资料中观察值的中心位置(集中趋势),并且可作为资料的代 表而与另一组资料相比较,借以明确二者之间相差的情况。
算术平均数的重要特性:(1)离均差之和为零 (2)离均差平方的总和最小8.变异数的意义、种类及计算方法?变异数的意义:一表示资料数据间的变异程度或离散程度或离均程度; 二可以衡量平均值的代表性.变异数的种类: ①极差 R=最大观察值—最小观察值②方差 s 2= 1)(1--∑n y ni y③标准差 s=1)(--∑n y y ④变异系数CV=y s 00100⨯ 9.统计概率、正态离差的含义?统计概率:统计学上通过大量实验而估计的概率。
正态离差:变数y 离其平均数u 以σ为单位转换,u=σμ-y 称为正态离差。
10.正态分布曲线的特性?(只要第5点)正态曲线与横轴之间的总面积等于1,因此在曲线下横轴的任何定值,例如从y=y1到y=y2之间的面积,等于介于这两个定值间面积占总面积的成数,或者说等于y 落于这个区间内的概率。
11.小概率事件不可能性原理的含义及应用。
○1小概率原理----若事件A 发生的概率较小,如小于0.05或0.01,则认为事件A 在一次试 验中不太可能发生,这称为小概率事件实际不可能性原理,○2应用:如果事先假设了一些条件,在这些假设的条件下若计算出某一事件为一小概率事件, 然而它在一次正常的试验中竟然发生了;反过来说明假设的条件不正确,从而否定该假设(接受另一个相反的假设)12.抽样分布的含义,单个样本平均数抽样分布含义及其参数?俩个样本平均数差数的抽样分布的含义和参数? (1)抽样分布:从已知的总体中以一定的样本容量进行随机抽样,由样本的统计数所对应的概率 分布 (2)由平均数构成的新总体的分布,称为平均数的抽样分布 参数: ○1) 该抽样分布的平均数与母总体的平均数相等。
○2 该抽样分布的方差与母总体方差间存在如下关系:(3)含义:如果从一个总体随机地抽取一个样本容量为n1的样本,同时随机独立地从另一 个总体抽取一个样本容量为n2的样本,那么可以得到分别属于两个总体的样本, 这两个独立随机抽取的样本平均数间差数的抽样分布参数:○1该抽样分布的平均数与母总体的平均数之差相等。
○2该抽样分布的方差与母总体方差间的关系为:12.什么是统计假设?统计假设有哪几种?各有什么含义?假设测验时直接测验的统计假设是哪一种?为什么?统计假设:对样本所属的总体(特征值或参数)提出假设(包括无效假设和备择假设两个)。
无效假设:记作H0,假设样本所属总体效应或参数(平均数)与某一指定值相等或假设两个总 体参数相等,即相对而言都不具有自己的独特效应.备择假设:记作HA,假设样本所属总体效应或参数(平均数)与某一指定值不相等或假设两个 总体参数不相等,或相对而言它们都有自己的独特效应.所以也可以称为有效假设. 无效假设,因为无效假设总体已知,可以研究抽样分布,可以进一步算出抽样在无效假设中 出现的概率。
13.什么是统计假设测验,它的原理与方法。
统计假设测验的含义:首先对样本所属的总体提出统计假设(无效假设 ,备择假设 )然后计算 样本在无效假设的总体中出现的概率,若概率大则接受该假设;若概率小 则否定该假设,从而接受另一个相反的备择假设.原理:小概率事件实际上不可能发生原理方法:(一)提出统计假设:对所研究的总体首先提出统计假设(二)计算概率: 在假定无效假设为正确的前提下,研究抽样分布,从而计算出样本在无效假设的总体中出现的概率 μμ=y ⎪⎭⎪⎬⎫==n n y y σσσσ 222121μμμ-=-y y 2221212222121n n y y y y σσσσσ+=+=-(三) 推断: 根据“小概率事件实际上不可能发生”原理接受或否定无效假设14.区间估计、置信区间、置信限、置信度的概念,区间估计与假设测验的关系。
区间估计:在一定的概率保证之下,由样本的统计数估计出总体参数可能位于的区间. 置信区间:在一定的概率保证之下,由样本的统计数估计出的总体参数可能位于的区间. 置信限 :置信区间的上、下限。
置信度:保证总体参数位于置信区间的概率以P=(1-α)表示。
区间估计与统计假设测验的关系为:如果无效假设位于置信区间内,就接受无效假设,称为差异不显著;如果无效假设位于置信区间外,就否定无效假设,接受备择假设,称为差异显著;15.什么是显著水平?为什么要有一个显著水平?根据什么确定显著水平?它和统计推断有何关系?用来测验假设的小概率标准5%或1%等,称为显著水平。
当由随机误差造成的概率小于5%或1%时,就可认为它不可能属于抽样误差,从而否定假设。
若实际计算的 就否定 接受称差异显著.如果在0.05显著水平上否定H0接受HA,称差异显著.如果在0.01显著水平上否定H0接受HA,称差异极显著.若实际计算的 就接受 称差不异显著如果样本平均数位于否定区域则否定无效假设,称差异显著;如果样本平均数位于接受区域则接受无效假设,称差不异显著.16:什么叫统计推断/它包括哪些内容?为什么统计推断的结论有可能发生错误?有哪俩内错误?如何克服?统计推断:利用概率论和抽样分布的原理,由样本结果(统计数)推断或估计其总体特征(参数). 它有两条路:一是统计假设测验,二是参数的区间估计.由于实验材料的差异、随机差异、和外界条件等均可导致统计推断发生错误。
有随机误差和系统误差俩内,随机误差不可能避免,但可以减少,主要是控制实验过程,试验误差的控制途径可以选择同质一致的试验材料,改进操作和管理技术使之标准化,控制引起差异的外界主要因素,选择条件均匀一致的试验环境;试验中采用适当的试验设计和科学的管理技术;应用相应的科学统计分析方法。
17.方差分析的含义及基本步骤,如何进行自由度和平方和的分解?(1)方差分析:是将总变异剖分为各个变异来源的相应部分,从而发现各变异原因在总变异中相对重要程度的一种统计分析方法。
是关于k(k ≥3)个样本平均数的假设测验方法. 方差分析的步骤:○1.平方和及自由度的分解:把试验资料总变异的平方和及自由度分解为各个因素的平方和及自由度,并计算出它们的方差.○2.F 测验:利用f 分布测验各个因素的方差是否显著大于误差方差.以明确哪个因素的效应是显著的.○3.多重比较:对方差显著的因素内水平间的平均数进行比较(差异显著性测验),以明确哪些平均数间差异显著,哪些平均数间差异不显著. αα≤≥p u u ,00:μμ=H 0:μμ≠A H αα-=<1,p u u 00:μμ=H(2)把试验资料总变异的平方和及自由度分解为各个因素的平方和及自由度,并计算出它们的方差.总平方和=组内(误差)平方和+组间(处理间)平方和总自由度DFT =组间自由度DFt +组内自由度DFe18. F 测验的俩个前提条件,如何进行F 测验和多重比较?数据的线性模型与方差分析有何关系? F 测验需具备条件:(1)变数y 遵循正态分布N( μ , σ2), (2) s12 和 s22 彼此独立 。
F 测验的方法:○1.提出统计假设 ○2.规定显著水平 ○3.计算概率○4推断;如果 就否定无效假设,接受 备择假设,如果接受无效假设多重比较的基本思路:利用误差方差计算出最小显著差异标准,若任两个均值之差的绝对值标准, 则它们的总体均值 μi 与μj 就差异显著; 反之就差异不显著.(3)方差分析的理论依据: 线性可加模型, 即总体每一个变量可以按其变异的原因分解成若干个线性组成部分。