ONEStor分布式存储系统介绍
分布式存储解决方案

分布式存储解决方案目录一、内容概览 (2)1. 背景介绍 (3)2. 目标与意义 (3)二、分布式存储技术概述 (5)1. 分布式存储定义 (6)2. 分布式存储技术分类 (7)3. 分布式存储原理及特点 (8)三、分布式存储解决方案架构 (9)1. 整体架构设计 (10)1.1 硬件层 (12)1.2 软件层 (13)1.3 网络层 (14)2. 关键组件介绍 (15)2.1 数据节点 (16)2.2 控制节点 (18)2.3 存储节点 (19)2.4 其他辅助组件 (20)四、分布式存储解决方案核心技术 (22)1. 数据分片技术 (23)1.1 数据分片原理 (25)1.2 数据分片策略 (26)1.3 数据分片实例分析 (28)2. 数据复制与容错技术 (29)2.1 数据复制原理及策略 (31)2.2 容错机制与实现方法 (32)2.3 错误恢复过程 (34)3. 数据一致性技术 (35)3.1 数据一致性概念及重要性 (36)3.2 数据一致性协议与算法 (37)3.3 数据一致性维护与保障措施 (38)4. 负载均衡与性能优化技术 (39)4.1 负载均衡原理及策略 (41)4.2 性能优化方法与手段 (43)4.3 实例分析与展示 (43)五、分布式存储解决方案应用场景及案例分析 (44)1. 场景应用分类 (46)2. 具体案例分析报告展示 (47)一、内容概览分布式存储解决方案是一种旨在解决大规模数据存储和管理挑战的技术架构,它通过将数据分散存储在多个独立的节点上,提高数据的可用性、扩展性和容错能力。
本文档将全面介绍分布式存储系统的核心原理、架构设计、应用场景以及优势与挑战。
我们将从分布式存储的基本概念出发,阐述其相较于集中式存储的优势,如数据分布的均匀性、高可用性和可扩展性。
深入探讨分布式存储系统的关键组件,包括元数据管理、数据分布策略、负载均衡和容错机制等,并分析这些组件如何协同工作以保障数据的可靠存储和高效访问。
system_storage_DS3000_系列产品的详细介绍

部门级产品
Performance
Price
入门级产品
System Storage DS3300iSCSI 磁盘系统
System Storage DS3400光纤磁盘系统
节约机柜成本节约能耗,优秀的IOPS每瓦特数据同转速下比3.5寸盘更好的IOPS
大容量,最高达单碟2TB廉价,SATA硬盘的替代品
政府级的数据安全性能不影响读写性能
New!
New!
New!
DS3500为客户提供了更丰富的磁盘选择,使客户可以结合各种磁盘优势,选择最符合业务需要的存储解决方案
降低存储系统的总成本无需 SATA 转换器 与SATA 磁盘几乎同等的价格明显强于SATA磁盘的性能表现顺序读提高25% 顺序写提高140% 随机读提高15% 随机写提高20% 根据希捷的数据,近线SAS与SATA性比,每瓦特实现高达38%的IOPS增值
System x DS3000 存储产品介绍
DS3000系列产品定位
DS3950 8Gbps光纤技术,成熟稳定,久经考验,最大可扩展至112块磁盘,中端存储的旗舰产品
DS3200
DS3300
DS3400
DS3500
DS3950
DS3500 采用SAS 2.0技术,支持远端镜像等功能,提供多种主机接口,以入门级的价格提供中端存储的性能
DS3300
DS3400 主机缆接 – 直接连接,通过光纤线
双节点直接连接集群
四节点直接连接
DS3400 主机缆接 – SAN连接,通过SAN交换机
高可用性集群
ONEStor分布式存储系统介绍
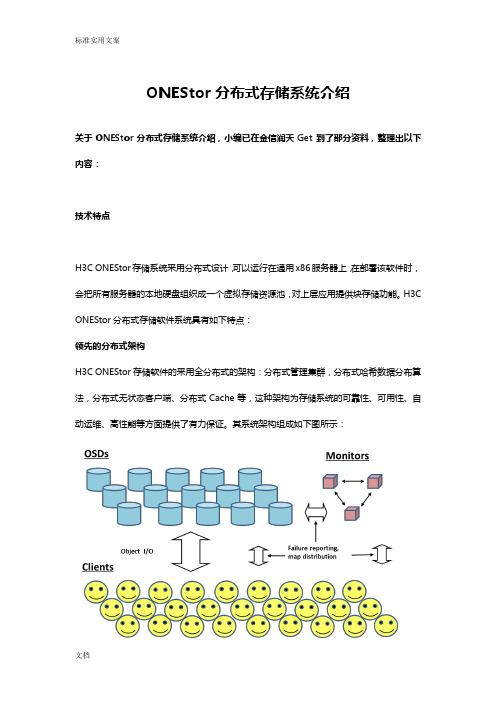
ONEStor分布式存储系统介绍关于ONEStor分布式存储系统介绍,小编已在金信润天Get到了部分资料,整理出以下内容:技术特点H3C ONEStor存储系统采用分布式设计,可以运行在通用x86服务器上,在部署该软件时,会把所有服务器的本地硬盘组织成一个虚拟存储资源池,对上层应用提供块存储功能。
H3C ONEStor分布式存储软件系统具有如下特点:领先的分布式架构H3C ONEStor存储软件的采用全分布式的架构:分布式管理集群,分布式哈希数据分布算法,分布式无状态客户端、分布式Cache等,这种架构为存储系统的可靠性、可用性、自动运维、高性能等方面提供了有力保证。
其系统架构组成如下图所示:上图中,ONEStor逻辑上可分为三部分:OSD、Monitor、Client。
在实际部署中,这些逻辑组件可灵活部署,也就是说既可以部署在相同的物理服务器上,也可以根据性能和可靠性等方面的考虑,部署在不同的硬件设备上。
下面对每一部分作一简要说明。
OSD:Object-based Storage DeviceOSD由系统部分和守护进程(OSD deamon)两部分组成。
OSD系统部分可看作安装了操作系统和文件系统的计算机,其硬件部分包括处理器、内存、硬盘以及网卡等。
守护进程即运行在内存中的程序。
在实际应用中,通常将每块硬盘(SSD或HDD)对应一个OSD,并将其视为OSD的硬盘部分,其余处理器、内存、网卡等在多个OSD之间进行复用。
ONEStor存储集群中的用户都保存在这些OSD中。
OSD deamon负责完成OSD的所有逻辑功能,包括与monitor和其他OSD(事实上是其他OSD的deamon)通信以维护更新系统状态,与其他OSD共同完成数据的存储和维护,与client通信完成各种数据对象操作等等。
Monitor:Monitor是集群监控节点。
Monitor持有cluster map信息。
所谓Cluster Map,粗略的说就是关于集群本身的逻辑状态和存储策略的数据表示。
主流超融合厂商技术优劣对比

主流超融合厂商技术对比超融合基础架构(HCI)是继服务器虚拟化技术之后的一次重大IT技术革新,其特点是通过分布式存储技术将各个计算节点(Hypervisor)的存储资源整合为一个统一的存储资源池,给虚拟化平台提供存储服务,实现计算、存储、网络、虚拟化的统一管理和资源的横向扩展,保障用户业务的高可用。
在超融合基础架构中,虚拟化是基础,而分布式存储则是超融合的技术核心。
从架构而言,HCI的分布式存储通常有两种方式来支持虚拟化,一种是以Nutanix NGFS为代表的采用控制虚拟机方式支持Hypervisor,如图一;另一种是直接在Hypervisor中集成分布式存储功能,如VSAN。
业界除了VSAN外,其它HCI全部采用控制虚拟机方案支持VMware虚拟化,而对于KVM虚拟化,各厂家采用在物理主机中实现分布式存储功能。
图一主流的超融合厂商有Nutanix(NGFS),VMware(VSAN),以及国内新兴代表力量如华为(FusionCube),H3C(OneStor),SMARTX(ZBS),深信服(aSAN),和道熵(Titlis)。
其中Nutanix的NGFS和SMARTX 的ZBS 脱胎于Google的GFS分布式文件系统;华为的FusionCube和H3C的OneStor是基于Ceph的定制化开发;而深信服的aSAN则是基于GlusterFS;VSAN在很大程度上和Ceph架构类似;而道熵的Titlis分布式存储在接口层兼容了标准Ceph接口,底层采用了磁盘阵列中常见的存储虚拟化技术。
根据对超融合产品的重要程度,我们选择了几方面的技术功能进行了相关考察:1、抗xx错误2副本或3副本机制可以保证在硬盘损坏甚至节点宕机的恶劣环境下,仍然保持高可用。
但是面对“静默错误”的情况,分布式块存储的副本机制则无能为力,腾讯云在不久前的“静默错误”风波证明了这一点,后果也是相当严重,用户的所有数据全部丢失,无法修复。
云计算——分布式存储

THANKS
感谢观看
云计算——分布式存储
汇报人: 2023-12-14
目录
• 分布式存储概述 • 分布式存储技术原理 • 分布式存储系统架构 • 分布式存储应用场景 • 分布式存储性能优化策略 • 分布式存储安全问题及解决方案
01
分布式存储概述
定义与特点
定义
分布式存储是一种数据存储技术,它通过将数据分散到多个独立的节点上,以 实现数据的分布式存储和访问。
云计算平台建设
01
02
03
云存储服务
分布式存储作为云计算平 台的核心组件,提供高效 、可扩展的存储服务。
云服务集成
与其他云服务(如计算、 网络、安全等)紧密集成 ,形成完整的云计算解决 方案。
自动化运维与管理
通过自动化工具实现分布 式存储系统的运维和管理 ,提高效率。
物联网数据存储与处理
实时数据采集
现状
目前,分布式存储技术已经成为了云计算领域的重要组成部 分,各大云服务提供商都提供了基于分布式存储的云存储服 务。同时,随着技术的不断发展,分布式存储的性能和稳定 性也在不断提高。
优势与挑战
优势
分布式存储具有高性能、高可用性、安全性、容错性和可维护性等优势,它可以 提供更加高效、灵活和可靠的数据存储服务,同时还可以提供更加灵活的扩展能 力,以满足不断增长的数据存储需求。
支持物联网设备实时采集 数据,并存储在分布式存 储系统中。
数据处理与分析
对物联网数据进行处理和 分析,提取有价值的信息 。
智能决策与控制
基于物联网数据分析结果 ,实现智能决策和控制, 提高生产效率。
05
分布式存储性能优化策略
数据压缩与解压缩技术
Thin LUN磁盘空间回收问题

ONEStor 构成。
O N E S t o r 存储系统基于Ceph,可运行在多台通用的x86服务器。
ONEStor 通过把多台不同服务器的本地硬盘组织成一个统一的存储资源池,对上层应用提供存储服务。
分布式存储磁盘空间报警每台服务器2块600GB 的SAS 盘安装CVK笔者单位在IDC 机房的服务器实施了虚拟化与云计算。
整个云平台由6台惠普ProLiant DL580 Gen9高配服务器,单台配置为512G 内存、4棵12核心CPU、2块600G 的SAS 盘、3块2T 的SATA 盘、2块480G 的固态盘,安装部署了新华三公司的云计算管理平台和分布式存储系统,由CAS(Cloud Automation System)和Thin LUN 磁盘空间回收问题■ 四川 赖文书编者按: 笔者单位在启动业务上云后,对原有提系统及设备进行了更新部署,其中采用的H3C ONEStor 存储系统出现磁盘空间报警问题,笔者联合厂商工程师专家进行了排查。
图1 OSD 磁盘使用率detection”命令,出现“Followingp o r t (s ) h a s (h a v e ) l o o p b a c k l i n k : GigabitEthernet1/0/9”字样,说明GigabitEthernet1/0/9有环回。
通过查看GigabitEthernet1/0/9端口的线标,发现该端口对应着二层的某间办公室。
顺藤摸瓜,解决问题笔者前往网线上标注的房间查明故障原因,发现该房间的墙插上连接了4口普通小交换机,小交换机的四个口都插满网线,办公室只有三台电脑,电脑走明线连接小交换机。
在经过一番排查后,笔者发现一根网线的两端都连在交换机上,形成了线路环回,同在一个VLAN 的队长办公室电脑和其他一些办公室电脑都受到影响,将其移除,经过测试网络立刻畅通,一切如初。
经验总结1.加强管理引起环路是因为管理不善,对各部门的控制力不足,需制定相应的管理制度,完善联网准入制度,不准私自购买小交换机、无线路由器等设备。
分布式存储系统详解

传统SAN架构
FC/IP
孤立的存储资源:存储通过 专用网络连接到有限数量的 服务器。
存储设备通过添加硬盘框 增加容量,控制器性能成 为瓶颈。
第3页
分布式Server SAN架构
虚拟化/操作系统 InfiniBand /10GE Network
InfiniBand /10GE Network
Server 3
Disk3 P9 P10 P11 P12
P2’ P6’ P14’ P18’
Disk4 P13 P14’ P15 P16’ P7’ P11’ P19’ P23’
Disk5 P17 P18’ P19 P20’ P3’ P12’ P15’ P24’
Disk6 P21 P22 P23 P24 P4’ P8’ P16’ P20’
第10页
FusionStorage部署方式
融合部署
指的是将VBS和OSD部署在同一台服务器中。 虚拟化应用推荐采用融合部署的方式部署。
分离部署
指的是将VBS和OSD分别部署在不同的服务器中。 高性能数据库应用则推荐采用分离部署的方式。
第11页
基础概念 (1/2)
资源池:FusionStorage中一组硬盘构成的存储池。
第二层为SSD cache,SSD cache采用热点读机制,系统会统计每个读取的数据,并统计热点访问因 子,当达到阈值时,系统会自动缓存数据到SSD中,同时会将长时间未被访问的数据移出SSD。
FusionStorage预读机制,统计读数据的相关性,读取某块数据时自动将相关性高的块读出并缓存
到SSD中。
数据可靠是第一位的, FusionStorage建议3副本配 置部署。
如果两副本故障,仍可保障 数据不丢失。
大规模分布式存储系统概念及分类

大规模分布式存储系统概念及分类一、大规模分布式存储系统概念大规模分布式存储系统,是指将大量存储设备通过网络连接起来,形成一个统一的存储资源池,实现对海量数据的存储、管理和访问。
这种系统具有高可用性、高扩展性、高性能和低成本等特点,广泛应用于云计算、大数据、互联网等领域。
大规模分布式存储系统的主要特点如下:1. 数据规模大:系统可存储的数据量达到PB级别甚至更高。
2. 高并发访问:系统支持大量用户同时访问,满足高并发需求。
3. 高可用性:通过冗余存储、故障转移等技术,确保数据安全可靠。
4. 易扩展:系统可根据业务需求,动态添加或减少存储设备,实现无缝扩展。
5. 低成本:采用通用硬件,降低存储成本。
二、大规模分布式存储系统分类1. 块存储系统(1)分布式文件系统:如HDFS、Ceph等,适用于大数据存储和处理。
(2)分布式块存储:如Sheepdog、Lustre等,适用于高性能计算场景。
2. 文件存储系统文件存储系统以文件为单位进行存储,支持丰富的文件操作接口。
常见的文件存储系统有:(1)网络附加存储(NAS):如NFS、SMB等,适用于文件共享和备份。
(2)分布式文件存储:如FastDFS、MooseFS等,适用于大规模文件存储。
3. 对象存储系统对象存储系统以对象为单位进行存储,具有高可用性和可扩展性。
常见的对象存储系统有:(1)Amazon S3:适用于云存储场景。
(2)OpenStack Swift:适用于私有云和混合云场景。
4. 键值存储系统键值存储系统以键值对为单位进行存储,具有简单的数据模型和高速访问性能。
常见的键值存储系统有:(1)Redis:适用于高速缓存和消息队列场景。
(2)Memcached:适用于分布式缓存场景。
5. 列存储系统列存储系统以列为单位进行存储,适用于大数据分析和查询。
常见的列存储系统有:(1)HBase:基于Hadoop的分布式列存储数据库。
(2)Cassandra:适用于大规模分布式系统的高可用性存储。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ONEStor分布式存储系统介绍关于ONEStor分布式存储系统介绍,小编已在金信润天Get到了部分资料,整理出以下内容:技术特点H3C ONEStor存储系统采用分布式设计,可以运行在通用x86服务器上,在部署该软件时,会把所有服务器的本地硬盘组织成一个虚拟存储资源池,对上层应用提供块存储功能。
H3C ONEStor分布式存储软件系统具有如下特点:领先的分布式架构H3C ONEStor存储软件的采用全分布式的架构:分布式管理集群,分布式哈希数据分布算法,分布式无状态客户端、分布式Cache等,这种架构为存储系统的可靠性、可用性、自动运维、高性能等方面提供了有力保证。
其系统架构组成如下图所示:上图中,ONEStor逻辑上可分为三部分:OSD、Monitor、Client。
在实际部署中,这些逻辑组件可灵活部署,也就是说既可以部署在相同的物理服务器上,也可以根据性能和可靠性等方面的考虑,部署在不同的硬件设备上。
下面对每一部分作一简要说明。
OSD:Object-based Storage DeviceOSD由系统部分和守护进程(OSD deamon)两部分组成。
OSD系统部分可看作安装了操作系统和文件系统的计算机,其硬件部分包括处理器、内存、硬盘以及网卡等。
守护进程即运行在内存中的程序。
在实际应用中,通常将每块硬盘(SSD或HDD)对应一个OSD,并将其视为OSD的硬盘部分,其余处理器、内存、网卡等在多个OSD之间进行复用。
ONEStor存储集群中的用户都保存在这些OSD中。
OSD deamon负责完成OSD的所有逻辑功能,包括与monitor 和其他OSD(事实上是其他OSD的deamon)通信以维护更新系统状态,与其他OSD共同完成数据的存储和维护,与client通信完成各种数据对象操作等等。
Monitor:Monitor是集群监控节点。
Monitor持有cluster map信息。
所谓Cluster Map,粗略的说就是关于集群本身的逻辑状态和存储策略的数据表示。
ONEStor Cluster Map包括Monitor map、osd map、pg map、crush map等,这些map构成了集群的元数据。
总之,可以认为Monitor 持有存储集群的一些控制信息,并且这些map信息是轻量级的,只有在集群的物理设备(如主机、硬盘)和存储策略发生变化时map信息才发生改变。
Client:这里的Client可以看出外部系统获取存储服务的网关设备。
client通过与OSD或者Monitor 的交互获取cluster map,然后直接在本地进行计算,得出数据的存储位置后,便直接与对应的OSD通信,完成数据的各种操作。
在此过程中,客户端可以不依赖于任何元数据服务器,不进行任何查表操作,便完成数据访问流程。
这一点正是ONEStor分布式存储系统可以实现扩展性的重要保证。
客户的数据到达Client后,如何存储到OSD上,其过程大致如下图所示:首先对上图中的一些名词进行简要描述:File:此处的file是对用户或者应用而言的,指用户或者应用需要存储或者访问的文件。
如果将ONEStor作为对象存储的后端,这个file也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
Object:此处的object是ONEStor内部定义的“对象”。
object的大小用户可以自行配置(在配置文件中设置,通常为2MB或4MB)。
当上层应用向ONEStor集群存入size较大的file时,需要将file切分成统一大小的一系列 object(最后一个的大小可以不同)进行存储。
为避免混淆,在本文中将尽量避免使用中文的“对象”这一名词,而直接使用进行说明。
PG:(Placement Group)PG是一个逻辑概念,其作用是对object的存储进行组织和位置映射。
这样便在object和osd之间提供一个中间映射层,即object->pg->osd。
某个object 通过算法映射到某个确定的pg,这个pg再通过某种算法映射到一组确定的osd(其个数和副本或纠删码配置有关,具体见后面章节描述)。
从数量上看,一般object数量远大与pg 数量,pg数量(一般比osd大两个数量级)远大于osd数量。
PG的概念类似于一致性哈希算法中的虚拟节点,引入PG后,可以在总体上大大减少每个osd相关的元数据的数量。
下面对上图中的寻址流程进行简要说明。
1, File->Object映射:(ino,ono)->oid这个映射比较简单,就是将用户要操作的file,映射为ONEStor能够处理的object。
其本质就是按照配置文件定义的object大小对file进行切分,相当于RAID中的条带化过程。
这种切分的好处有二:一是让大小不限的file变成size一致、可以被存储集群高效管理的object;二是让对单一file实施的串行处理变为对多个object实施的并行化处理,以提高读写性能。
对于要操作的将会从Monitor获得全局唯一的inode number,即ino。
File切分后产生的object将获得唯一(在File的范围内)的object number,即ono。
Ono的编号从0开始,依次累加。
oid就是将ono连缀在ino之后得到的。
容易看出,由于ino的全局唯一性(通过Monitor获得),oid同样具备全局唯一性。
2, Object -> PG映射在file被映射为一个或多个object之后,就需要将每个object独立地映射到一个PG中去。
这个映射过程也很简单,其计算公式是:hash(oid) & mask -> pgid或者更加明显的表示成:hash(oid) mod (pgno) -> pgid上式中,pgno表示配置的pg数量,一般为2的整数次幂。
整个计算由两步组成。
首先是使用ONEStor系统指定的一个特定的哈希函数计算oid的哈希值(这个值将具备近似均匀分布的特性)。
然后,将这个伪随机值对pgno取模,就得到了pgid。
这样,pgid的取值范围是从0到pgno-1。
由哈希函数的伪随机特性,容易想见,大量的oid将近似均匀地映射到不同的pgid上。
3, PG -> OSD映射第三次映射就是将作为object的逻辑组织单元的PG通过CRUSH算法映射到一组OSD集合。
集合中具体的OSD个数一般为数据副本的个数。
比如,用户配置了3副本,那么每个pg将映射到3个osd。
多副本可以大大提高数据的可靠性(具体可见后面相关章节的说明)。
相比于“object -> PG”映射过程,CRUSH算法要复杂的多。
通常情况下,一个好的分布式算法至少满足如下的要求:1,数据的放置位置是Client计算出来的,而不是向Server查出来的2,数据在存储体上满足概率均匀分布3,存储体动态变化时数据重分布时引入的数据迁移量达到最优或者次优除了这3点基本要求外,一个好的算法还应该满足:4,可以基于指定的策略放置副本: 用于故障域隔离或其它要求5,在存储体引入权“weight”的概念,以便对磁盘容量/速度等进行区分CRUSH算法是ONEStor的核心算法,完全满足上面提到的5点要求,限于篇幅,此处不对算法本身进行描述。
当系统中的OSD状态、数量发生变化时,cluster map亦随之变化,而这种变化将会影响到PG与OSD之间的映射,从而使数据重新再OSD之间分布。
由此可见,任何组件,只要拥有cluster map,都可以独立计算出每个object所在的位置(去中心化)。
而对于cluster map,只有当删除添加设备或设备故障时,这些元数据才需要更新,更新的cluster map会及时更新给client和OSD,以便client和OSD重新计算数据的存储位置。
1.自动化运维自动化运维主要体现在如下几个方面:(1)存储集群快速部署,包括批量部署、单节点增减、单磁盘增减等。
(2)设置监控报警系统,发生故障时能快速界定问题、排查故障。
(3)根据硬件能力,灵活地对集群中的节点进行灵活配置。
(4)允许用户定制数据分布策略,方便地进行故障域隔离,以及对数据存储位置进行灵活选择。
(5)在增删存储介质,或存储介质发生故障时,自动进行数据均衡。
保证集群数据的高可用性。
(6)在系统平衡数据(例如系统扩容或者存储节点、磁盘发生故障)的过程中,为保证用户IO,ONEStor存储系统支持IO优先级控制和Qos保证能力。
对于(1)(2)两点,详见“ONEStor管理系统”章节,在此不再赘述。
对于(3),ONEStor系统可以根据用户需求灵活地部署Monitor节点和Client节点。
一方面,这些节点既可以部署在单独的物理服务器上,也可以部署在和OSD相同的物理节点上。
另一方面,Monitor和Client的节点可以根据用户的需求灵活地调整。
比如为了可靠性保证,至少需要部署3个Monitor节点;为了保证对象存储网关的性能,需要部署过个RGW (Client)节点。
对于(4),用户的需求主要体现在存储策略上,比如在选用副本策略时,用户可能希望不同数据副本存储在不同机架上面的主机上;或者主副本存储在某个机架的主机上,其它副本存储在另外机架的主机上;或者主副本存储在SSD上,其它副本存储在HDD上。
诸如此类等等。
这些需要都可以通过配置cluster map中的rule set进行灵活地配置。
对于(5),在增删存储介质,或存储介质发生故障时,系统会及时进行检测。
比如,在磁盘发生故障时,ONEStor会利用损坏数据在其他存储体上的副本进行复制,并将复制的数据保存在健康的存储体上;在增加磁盘时,同样会把其他存储体的数据安排容量比例重新分布到新磁盘,使集群的数据达到均衡。
在上述过程中,完全不需要人工干预。
对于(6),我们知道,在系统扩容或者存储节点、磁盘故障过程中,为保证数据的可靠性,系统会自动进行数据平衡。
为了尽快完成数据平衡,往往会沾满每个存储节点的带宽和IO 能力,这样做的好处是会使平衡时间最短,坏处是此时前端用户的IO请求会得不到满足。
在某些业务场景下,这时用户无法接受的。
为此,ONEStor存储系统实现了IO优先级和Qos 控制机制,可以对前端用户网络流量和后端存储网络流量进行控制,保证一定比例的用户IO得到满足。
2.线性扩展能力所谓线性扩展能力,主要体现在两个方面:一个是集群部署规模可以线性扩展,另一个方面,随集群规模的扩展,其性能要能够线性或近似线性扩展。
在规模上,传统存储之所以在扩展能力上受限,一个很重要的原因就是一般其采用集中式控制,并且在控制节点存储大量的元数据信息,从而使控制节点容易成为系统的瓶颈。