实验四 编译 用Yacc工具构造语法分析器
编译原理YACC

如: 输入 3+4*5 输出 345*+
{ print „+‟ }
{ print „*‟ } { print „i‟ }
E E+T T T*F Fi
{ print „+‟ } { print „*‟ } { print „i‟ }
program program statement \n | ɛ statement expression | VARIABLE = expression expression INTEGER | VARIABLE | expression + expression | expression - expression | expression * expression | expression / expression | ( expression )
NS1.S S S1 B S B B 0 B 1
{ N.v=S1.v+S.v*2-S.L } { S.v=S1.v*2+B.v, S.L=S1.L+1 } { S.v=B.v, S.L=1 } { B.v=0 } { B.v=1 }
N S . S
S B S B B 1 B 1
1
0
用Bison验证实现
YTU COMPILER
1. Declarations 定义段
%{ /* 合法的C声明、包含文件、宏定义等 */ #include <stdio.h> #include <ctype.h> … %} 开始符号定义 语义值类型定义 终结符定义 算符优先级、结合性的说明
YTU COMPILER
实验四 借助FlexBison进行语法分析

实验四借助Flex/Bison进行语法分析一.说明:利用附录提供的C语言文法的相关参考资料,利用Yacc/Bison编写一个C语言分析器。
二.具体内容:利用语法分析器生成工具Bison编写一个语法分析程序,与词法分析器结合,能够根据语言的上下文无关文法,识别输入的单词序列是否文法的句子。
三.实验要求:实验资料如下:3.1 阅读Flex源文件input.lex、Bison源文件cgrammar-new.y。
3.2 实现C 语言的语法分析功能,最后上机调试。
3.3 生成语法分析程序2_2.exe,以给定的测试文件作为输入,输出运行结果到输出文件中。
四.实验过程:(1)执行以下命令,生成lex.yy.c、cgrammar-new.tab.h、cgrammar-new.tab.c。
(2)cgrammar-new.y有移近规约冲突。
执行命令bison -d cgrammar-new.y 后,Bison提示移近规约冲突“cgrammar-new.y: conflicts: 1 shift/reduce”。
以Bison的"-v"选项生成状态机描述文件cgrammar-new.output,即执行bison -d cgrammar-new.y。
cgrammar-new.output文件内容如下:修改以下两处:2.1 在yacc的头部加入%nonassoc LOWER_THAN_ELSE%nonassoc ELSE2.2 在355行加入%prec LOWER_THAN_ELSE(3)编译使用cl.exe或gcc编译器,编译lex.yy.c cgrammar-new.tab.c main.c parser.c。
使用cl.exe编译后,得到以下错误提示:修改lex.yy.c,使其能顺利编译。
3.1 将lex.yy.c中的#ifdef __cplusplusstatic int yyinput()#elsestatic int input()#endif改为static int yyinput()2.2 将lex.yy.c中的#ifdef __cplusplusreturn yyinput();#elsereturn input();#endif改为return yyinput();(3)生成可执行文件2_2.exe,并分析源文件test.c。
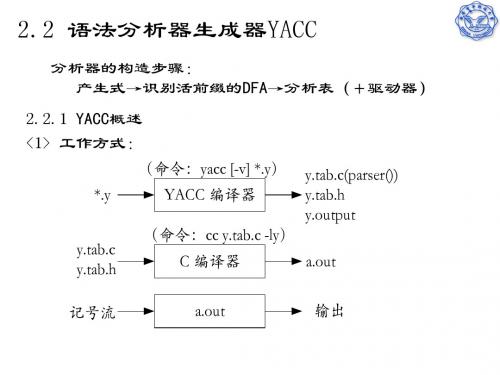
语法分析器生成器YACC
E : num num
再分析3++5
5
分析器动作 移进 num,转向state 3 按(2)“E : num”归约,goto State 1 移进 +,转向State 4 移进error,转向 state 2 按(3)“E : error”归约,goto State 5, 按(1)“E : E‘+’E”归约,goto State 1 移进 +,转向State 4 移进 num,转向 State 3 按(2)“E : num”归约,goto State 5 按(1)“E : E‘+’E”归约,goto State 1 接受
2.2.3.2 YACC对语义的支持
分析器工作原理:
记号流 归约前栈顶 归约后栈顶 $3 E $2 + $1($$) E ... ... 驱动器 分析表 输出
语义栈对语法制导翻译提供直接支持。语义栈的 类型决定了文法符号的属性,语义栈类型表示能力的 强弱决定了YACC的能力。
<1> YACC默认的语义值类型 YACC语义栈与yylval同类型,并以终结符的yylval 值作为栈中的初值。因为yylval的默认类型为整型,所 以,当用户所需文法符号的语义类型是整型时,无需定 义它的类型。如在下述表达式的产生式中: E :E '+' E | E '*' E | num ; { $$=$1+$3;} { $$=$1*$3;}
2.2.1 YACC概述
利用YACC进行语法分析器设计的关键,也是如何编写 YACC源程序。 下边首先介绍YACC源程序的基本结构,然后着重讨论 YACC的产生式、YACC解决产生式冲突的方法、以及YACC对语 义的支持和对错误的处理等。
Yacc语法分析器设计步骤
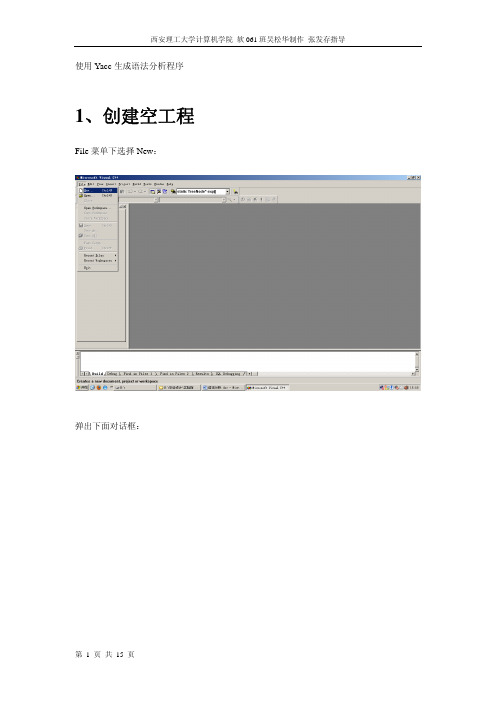
使用Yacc生成语法分析程序1、创建空工程File菜单下选择New:弹出下面对话框:选择Win32 Console Application,同时在Project Name下输入工程名字:ParserByYacc点击Ok按钮,弹出下面对话框:不做任何选择,按照默认“An empty project”,直接点击Finish按钮,弹出下面对话框:直接点击OK按钮,工程创建完毕。
2、使用Yacc生成语法分析程序点击“开始”,在“开始”菜单中选择“运行”,如下图所示在弹出的对话框中敲入cmd,启动DOS窗口使用DOS命令切换到E:\ ParserByYacc将yacc.exe文件拷贝到ParserByYacc工程下:将编写好的TINY.Y文件拷贝到ParserByYacc工程下:运行yacc生成y.tab.c和y.tab.h文件:3、添加文件首先在windows环境下,把设计好的文件GLOBALS.H、MAIN.C、SCAN.C、SCAN.H、PARSE.H、UTIL.C 和UTIL.H拷贝到ParserByYacc工程下:如图所示,选中Project菜单,选择下面Add To Project子菜单下面的Files子菜单:点击后弹出对话框:选中的刚拷贝进来的文件和Yacc生成的文件,点击OK按钮:在左侧的工程文件列表中,可以清楚地看到这些文件:4、生成可执行文件编译生成可执行文件ParserByYacc.exe在本工程的debug目录下:为了验证本语法分析程序的运行结果,把样本程序SAMPLE.TNY拷贝到可执行程序所在的目录下:5、验证运行结果Windows环境下点击“开始”,选中其中的“运行(R)”弹出下面对话框,输入cmd命令:输入上图所示的类似命令,进入可执行程序所在目录。
在当前目录下输入命令:ParserByYacc sample.tny,然后回车,则得到相应的运行结果:。
编译原理 lex和yacc的综合设计 python

编译原理lex和yacc的综合设计python
1、Lex和Yacc是一种强大的词法分析和语法分析技术,它们常用于编译器的开发和编写编译器前端。
它们分别可以分析和解释输入字符流,并产生相应的输出。
Lex是一个词法分析器,它可以将输入字符流分解为令牌(即识别的节点),这些令牌可以用于编写解释器或编译器的前端。
Yacc则是一种用来构建语法分析器的工具,它可以识别输入的令牌序列,并生成相应的程序。
2、编译原理是编译器的最小系统,它涉及源程序的分析和分解,目标程序的生成和优化,以及中间代码的翻译。
Lex和Yacc则是用来处理字符流和语法检查的两个有力工具,在处理中间代码生成和优化方面非常有用,是编译器的核心部分。
3、Lex和Yacc的综合设计一般需要借助某种语言将可执行模块链接起来,最常用的技术是使用C,C是一种高性能语言,可以让开发者实现快速迭代,也可以利用其标准库实现代码复用,因此是完成Lex和Yacc综合设计的最佳语言。
4、Python是一种脚本语言,不适合用于编写Lex和Yacc综合设计,因为Python 并不专业,不能满足低级程序设计的需求,处理过程中往往性能不佳。
yacc语法

yacc语法Yacc是一个Unix系统上的自动语法分析工具,它被广泛用于编译器的实现以及其他与语法分析相关的任务。
使用Yacc可以通过自定义语法规则、自动生成语法分析代码,从而减轻开发者的工作量。
本文将围绕Yacc语法展开讲解。
1. 定义语法规则Yacc语法的最基本的元素就是语法规则。
语法规则可以由终结符(nonterminals)和非终结符(terminals)组成。
具体来说,终结符就是由程序中定义的特定单词组成,而非终结符则是一个标识符,它表示一个语法符号的集合。
在Yacc中,语法规则通常被写成这样:`[nonterminal] : options {actions}`其中,`nonterminal`表示非终结符,`options`表示由终结符和非终结符组成的可选项,`actions`则表示在匹配到语法规则时所要执行的动作。
2. 处理符号在Yacc语法中,为了辨别终结符和非终结符,我们使用符号。
符号可以区分终结符和非终结符,并且它们可以用在语法规则和实际输入中。
在Yacc语法中,我们使用`%token`和`%type`命令来声明符号。
具体来说,`%token`命令用于声明终结符,例如:`%token PLUS`而`%type`命令则用于声明非终结符,例如:`%type <ast_node> expression`在这个例子中,我们使用`<ast_node>`指定非终结符的类型。
3. 定义树状结构在Yacc语法中,我们通常需要定义树状结构来帮助我们分析输入。
在Yacc语法中,树状结构被称为抽象语法树(Abstract Syntax Tree, AST)。
为了定义抽象语法树,我们需要使用`$$`符号,它表示正式生成的语法树的节点。
例如,在下面的语法规则中,我们使用`$$`来表示生成的AST节点:```statement : type identifier EQUALS expression { $$ =parse_statement($1, $2, $4); }```在这个例子中,我们通过调用`parse_statement()`函数来生成AST节点。
用Yacc实现语法分析器-4-编译原理
⽤Yacc实现语法分析器-4-编译原理⽤Yacc实现语法分析器⼀、实验⽬的掌握语法分析器的构造原理,掌握Yacc的编程⽅法。
⼆、实验内容⽤Yacc编写⼀个语法分析程序,使之与词法分析器结合,能够根据语⾔的上下⽂⽆关⽂法,识别输⼊的单词序列是否⽂法的句⼦。
program→blockblock→ { stmts }stmts→ stmt stmts | estmt→ id= expr ;| if ( bool ) stmt| if ( bool) stmt else stmt| while (bool) stmt| do stmt while (bool ) ;| break ;| blockbool →expr < expr| expr <= expr| expr > expr| expr >= expr| exprexpr→expr + term| expr - term| termterm→term * factor| term / factor| factorfactor→ ( expr ) | id| num 三、实验步骤及结果实验环境:unix实验结果:按归约的先后顺序显⽰每次归约时所使⽤的产⽣式。
部分代码:⽤于产⽣flex输⼊的代码View CodeTest.l:[a-zA-Z_][a-zA-Z_0-9]* {return ID;}[0-9]+\.[0-9]+ {return REAL;}[0-9]+ {return NUM;}"||" {return OR;}"&&" {return AND;}"|" {return'|';}"&" {return'&';}"<=" {return LE;}"<" { return'<';}">=" {return GE;}">" {return'>';}"!=" {return NE;}"=" { return'=';}"==" {return EQ;}"\+" {return'+';}"\-" {return'-';}"\*" {return'*';}"\/" {return'/';}"(" {return'(';}")" {return')';}";" {return';';}"{" {return'{';}"}" {return'}';}"[" {return'['; }"]" {return']';}Test.y:rel : expr '<' expr { printf("rel-->expr<expr\n"); }| expr LE expr { printf("rel-->expr<=expr\n"); }| expr GE expr { printf("rel-->expr>=expr\n"); }| expr '>' expr { printf("rel-->expr>expr\n"); }| expr { printf("rel-->expr\n"); };expr : expr '+' term { printf("expr-->expr+term\n"); }| expr '-' term { printf("expr-->expr-term\n"); }| term { printf("expr-->term\n"); };term : term '*' unary { printf("term-->term*unary\n"); }| term '/' unary { printf("term-->term/unary\n"); }| unary { printf("term-->unary\n"); };unary : '!' unary { printf("unary-->!unary\n"); }| '-' unary %prec UMINUS{ printf("unary-->-unary\n"); } | factor { printf("unary-->factor\n"); };factor : '('bool')' { printf("factor-->(bool)\n"); }| loc { printf("factor-->loc\n"); }| NUM { printf("factor-->num\n"); }| REAL { printf("factor-->real\n"); }| TRUE { printf("factor-->true\n"); }| FALSE { printf("factor-->false\n"); }Flex⽣成代码:View CodeTest.l:[a-zA-Z_][a-zA-Z_0-9]* {return ID;}[0-9]+\.[0-9]+ {return REAL;}[0-9]+ {return NUM;}"||" {return OR;}"&&" {return AND;}"|" {return'|';}"&" {return'&';}"<=" {return LE;}"<" { return'<';}">=" {return GE;}">" {return'>';}"!=" {return NE;}"=" { return'=';}"==" {return EQ;}"\+" {return'+';}"\-" {return'-';}"\*" {return'*';}"\/" {return'/';}"(" {return'(';}")" {return')';}";" {return';';}"{" {return'{';}"}" {return'}';}"[" {return'['; }"]" {return']';}Test.y:rel : expr '<' expr { printf("rel-->expr<expr\n"); } | expr LE expr { printf("rel-->expr<=expr\n"); }| expr GE expr { printf("rel-->expr>=expr\n"); } | expr '>' expr { printf("rel-->expr>expr\n"); }| expr { printf("rel-->expr\n"); };expr : expr '+' term { printf("expr-->expr+term\n"); } | expr '-' term { printf("expr-->expr-term\n"); }| term { printf("expr-->term\n"); };term : term '*' unary { printf("term-->term*unary\n"); }| term '/' unary { printf("term-->term/unary\n"); }| unary { printf("term-->unary\n"); };unary : '!' unary { printf("unary-->!unary\n"); }| '-' unary %prec UMINUS{ printf("unary-->-unary\n"); }| factor { printf("unary-->factor\n"); };factor : '('bool')' { printf("factor-->(bool)\n"); }| loc { printf("factor-->loc\n"); }| NUM { printf("factor-->num\n"); }| REAL { printf("factor-->real\n"); }| TRUE { printf("factor-->true\n"); }| FALSE { printf("factor-->false\n"); }Yacc⽣成部分代码:View Code#line 1334 "y.tab.c"yyvsp -= yylen;yyssp -= yylen;YY_STACK_PRINT (yyss, yyssp);*++yyvsp = yyval;/* Now `shift' the result of the reduction. Determine what statethat goes to, based on the state we popped back to and the rulenumber reduced by. */yyn = yyr1[yyn];yystate = yypgoto[yyn - YYNTOKENS] + *yyssp;if (0 <= yystate && yystate <= YYLAST && yycheck[yystate] == *yyssp) yystate = yytable[yystate];elseyystate = yydefgoto[yyn - YYNTOKENS];goto yynewstate;/*------------------------------------.| yyerrlab -- here on detecting error |`------------------------------------*/yyerrlab:/* If not already recovering from an error, report this error. */if (!yyerrstatus){++yynerrs;#if YYERROR_VERBOSEyyn = yypact[yystate];if (YYPACT_NINF < yyn && yyn < YYLAST){YYSIZE_T yysize = 0;int yytype = YYTRANSLATE (yychar);const char* yyprefix;char *yymsg;int yyx;/* Start YYX at -YYN if negative to avoid negative indexes inYYCHECK. */int yyxbegin = yyn < 0 ? -yyn : 0;/* Stay within bounds of both yycheck and yytname. */int yychecklim = YYLAST - yyn;int yyxend = yychecklim < YYNTOKENS ? yychecklim : YYNTOKENS;int yycount = 0;yyprefix = ", expecting ";for (yyx = yyxbegin; yyx < yyxend; ++yyx)if (yycheck[yyx + yyn] == yyx && yyx != YYTERROR){yysize += yystrlen (yyprefix) + yystrlen (yytname [yyx]);yycount += 1;if (yycount == 5){yysize = 0;break;}}yysize += (sizeof ("syntax error, unexpected ")+ yystrlen (yytname[yytype]));yymsg = (char *) YYSTACK_ALLOC (yysize);if (yymsg != 0){char *yyp = yystpcpy (yymsg, "syntax error, unexpected ");yyp = yystpcpy (yyp, yytname[yytype]);if (yycount < 5){yyprefix = ", expecting ";for (yyx = yyxbegin; yyx < yyxend; ++yyx)if (yycheck[yyx + yyn] == yyx && yyx != YYTERROR){yyp = yystpcpy (yyp, yyprefix);yyp = yystpcpy (yyp, yytname[yyx]);yyprefix = " or ";}}yyerror (yymsg);YYSTACK_FREE (yymsg);}elseyyerror ("syntax error; also virtual memory exhausted");}else例如,程序⽚断{i = 2;while (i <=100){sum = sum + i;i = i + 2;}}(注:原本是在windwos环境下编程,最后到unix环境下,发现速度快了,灵活性⾼了,同时⽅便了很多。
编译原理实践yacc(sql查询语句解析)_概述说明
编译原理实践yacc(sql查询语句解析) 概述说明1. 引言1.1 概述本篇文章旨在介绍编译原理实践中使用Yacc工具对SQL查询语句进行解析的过程。
编译原理是计算机科学中的重要研究领域,主要涉及将高级语言转化为低级的机器语言,以便计算机能够理解和执行。
通过使用编译原理中的概念和技术,可以大大简化复杂语法的分析和解析过程,提高程序开发的效率。
1.2 文章结构本文共分为五个部分,每个部分都有其特定的内容和目标:- 引言:介绍本篇文章的背景和目的。
- 编译原理实践yacc:阐述编译原理及介绍Yacc工具在该领域中的应用。
- SQL查询语句解析过程:详细讲解SQL查询语句的基本结构、词法分析过程以及语法分析过程。
- Yacc工具的使用和配置:指导读者如何安装Yacc工具,并演示如何编写Yacc 源文件以及生成解析器代码并进行运行。
- 结论与展望:总结全文内容并提供未来可能的拓展方向。
1.3 目的本文目的在于通过对编译原理和Yacc工具在SQL查询语句解析中的应用进行介绍,帮助读者更好地理解编译原理的相关概念,并掌握使用Yacc工具进行语法分析和解析的方法。
通过实践演示和案例讲解,读者能够学会配置和使用Yacc 工具,并将其应用于自己感兴趣的领域。
以上为“1. 引言”部分内容的详细描述,请结合实际情况进行参考与调整。
2. 编译原理实践yacc2.1 什么是编译原理编译原理是计算机科学领域的一个重要分支,研究如何将高级程序语言转换为机器语言。
它涉及到编程语言的词法分析、语法分析和代码生成等多个方面。
通过编译原理,我们可以了解程序如何被解释和执行,从而能够更好地设计和优化程序。
2.2 Yacc介绍Yacc(Yet Another Compiler Compiler)是一款用于生成语法解析器的工具。
它是由AT&T贝尔实验室的Stephen C. Johnson在20世纪70年代开发的,并成为Unix操作系统环境下广泛使用的编译器工具之一。
编译器构造与语法分析
编译器构造与语法分析在计算机科学中,编译器是一个重要的概念。
它是将高级编程语言翻译成计算机能够理解的低级语言的工具。
编译器的构造和语法分析是编译器设计中的两个关键步骤。
本文将介绍编译器的构造原理和语法分析算法。
一、编译器构造在编译器构造中,主要包括以下几个步骤:词法分析、语法分析、语义分析、中间代码生成和代码优化。
1. 词法分析词法分析是将源代码分割成一个个词法单元的过程。
词法单元包括关键字、标识符、运算符、常量和分隔符等。
词法分析器会从源代码中逐个读取字符,并根据预定的规则将其组合成具有特定含义的词法单元。
2. 语法分析语法分析是将词法分析的结果进行语法分析的过程。
语法分析器根据预定的文法规则,检查源代码是否符合语法规范。
常用的语法分析算法有自顶向下的递归下降分析和自底向上的LR分析等。
3. 语义分析语义分析是对源代码进行语义检查和语义处理的过程。
在语义分析阶段,编译器会根据预定的语义规则检查源代码中是否存在语义错误,并生成相应的语法树或符号表。
4. 中间代码生成中间代码生成是将源代码转换成中间代码的过程。
中间代码是介于源代码和目标代码之间的一种抽象表示形式,通常是一种类似于三地址码或虚拟机指令的形式。
5. 代码优化代码优化是对中间代码进行优化的过程。
通过对中间代码进行逻辑优化和算法优化,可以提高生成目标代码的效率和质量。
二、语法分析语法分析是编译器设计中的一个重要环节,它负责分析源代码的语法结构,并根据语法规则构建语法树。
常用的语法分析算法有自顶向下的递归下降分析和自底向上的LR分析。
1. 自顶向下的递归下降分析自顶向下的递归下降分析是一种简单直观的语法分析方法。
它从文法的起始符号开始,通过递归地调用子程序来逐步分析源代码,直到达到终结符号或非终结符号的底部。
2. 自底向上的LR分析自底向上的LR分析是一种自底向上的语法分析方法。
它从输入的末尾开始,逐步向前移动,以确定语法规则。
通过构建LR分析表和状态机,可以在线性时间内进行语法分析。
Yacc利用指南
YACC(BISON)利用指南YACC(Yet Another Compile-Compiler)是语法分析器生成工具,它生成的是LALR分析器。
Yacc于上世纪70年代产生,是美国贝尔实验室的产品,已经用于帮忙实现了几百个编译器。
Yacc是linux下的工具,本实验利用的编译工具是cygwin(cygwin在windows下模拟一个linux环境)下的bison,它与Yacc的利用方式大体相同,只有很少的不同。
一.YACC的利用方式:1.用户依照Yacc规定的规则写出文法说明文件,该文件一般以.y为扩展名(有的系统以.grm为扩展名。
)2.Yacc编译器将此文法说明文件(假设该文件为)转换成用C编写的语法分析器文件(若是在编译时加上某些参数还能够生成头文件)。
那个文件里至少应该包括语法分析驱动程序yyparse()和LALR分析表。
在那个文件里,语法分析驱动程序挪用yylex()那个函数获取输入记号,每次挪用yylex()都能获取一个输入记号。
yylex()能够由lex生成,也能够自己用c语言写一个yylex()函数,只要每次挪用该函数时返回一个记号即可。
3.用C编译器(本实验所给工具为cygwin下的gcc)将编译为可执行文件(cygwin下默以为)。
4.即为可执行的语法分析器。
二.文法说明文件(即Yacc源程序)的写法:文法说明文件,顾名思义,就是将一个语言的文法说清楚。
在Yacc中,那个说明文件能够分为三部份,以符号%%分开:[第一部份:概念段]%%第二部份:规则段[%%第三部份:辅助函数段]其中,第一部份及第三部份和第三部份之上的%%都能够省略(即上述方括号括起的部份能够省略)。
以%开头的符号和关键字,或是规则段的各个规则一般顶着行首来写,前面没有空格。
1. 第一部份概念段的写法:概念段能够分为两部份:第一部份以符号%{和%}包裹,里面为以C语法写的一些概念和声明:例如,文件包括,宏概念,全局变量概念,函数声明等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验4 用Yacc工具构造语法分析器一、实验目的掌握移进-归约技术语法分析技术,利用语法分析器生成工具Yacc/Bison实现语法分析器的构造。
二、实验内容利用语法分析器生成工具Yacc/Bison编写一个语法分析程序,与词法分析器结合,能够根据语言的上下文无关文法,识别输入的单词序列是否文法的句子。
源语言的文法定义见教材附录 A.1,p394,要求实现完整的语言。
三、实验要求1.个人完成,提交实验报告。
2.实验报告中给出采用测试源代码片断,及其对应的最右推导过程(形式可以自行考虑,如依次给出推导使用的产生式)。
例如,程序片断四、实验思路本次实验是一次实现词法分析和语法分析的过程,词法分析的内容与第二次实验类似,对关键词,数字,标识符以及其他类型的字符进行识别,分别返回对应的数据类型,这个过程相对来说是比较简单的,由于有特定的词法分析过程的格式,很容易将代码编写出来。
语法分析的过程则给出了文法以及相应的语义动作,代码的编写相对比较复杂。
首先,在D:\FlexBison的目录下建立一个文件夹,我命名为expmt3,将bison.exe和flex.exe放到expmt3目录下。
然后编写mylex.l文件和myyacc.y文件,在dos下切换到expmt3目录下,先用命令flex mylex.l生成lex.yy.c文件,再用命令bison –d myyacc.y生成myyacc.tab.c文件和myyacc.tab.h文件,在这个目录中再新建一个example.c文件,用vc++打开这个文件,然后编译这个文件,再将前两步生成的lex.yy.c、myyacc.tab.c和myyacc.tab.h文件加入到工程中,再编译并连接生成可执行文件。
最后测试程序的正确性要在expmt3的debug目录下创建一个测试文件test.txt,将测试片段放入其中,然后在dos界面运行程序,知道产生正确的结果,实验就完成了。
五、具体代码Mylex.l%option noyywrap%{#include<ctype.h>#include<string.h>#include<stdio.h>#include<stdlib.h>#include "myYacc.tab.h"%}delim [ \t\n]ws {delim}+letter [A-Za-z]digit [0-9]%%{ws} { }"if" {printf("IF ");return(IF);}"else" {printf("ELSE ");return(ELSE);}"int" {printf("INT "); return(BASIC);}"float" {printf("FLOAT "); return(BASIC);}"break" {printf("BREAK");return(BREAK);}"do" {printf("DO ");return(DO);}"while" {printf("WHILE ");return(WHILE);}"true" {printf("TRUE ");return(TRUE);}"index" {printf("INDEX "); return(INDEX);}"bool" {printf("BOOL "); return(BASIC);}"char" {printf("CHAR "); return(BASIC);}"real" {printf("real");return(REAL);}"false" {printf("FLASE "); return(FALSE);}[a-zA-Z_][a-zA-Z0-9_]* {printf("ID");return(ID);}[+-]?[0-9]+ {printf("NUM");return(NUM);}[+-]?[0-9]*[.][0-9]+ {printf("NUM");return(NUM);}"<" {printf("LT ");return('<');}"<=" {printf("LE ");return(LE);}"=" {printf("= ");return('=');}"==" {printf("EQ ");return(EQ);}"!=" {printf("NE ");return(NE);}">" {printf("GT ");return('>');}">=" {printf("GE ");return(GE);}"+" {printf("+ ");return('+');}"-" {printf("- ");return('-');}"[" {printf("[ ");return('[');}"]" {printf("] ");return(']');}"{" {printf("{");return('{');}"}" {printf("}");return('}');}"(" {printf("(");return('(');}")" {printf(")");return(')');}";" {printf(";");return(';');}"," {printf(",");return(',');}"&&" {printf("&&");return(AND);}"||" {printf("||");return(OR);}%%Myyacc.y%{#include<ctype.h>#include<stdio.h>extern int yylex();extern int yyerror();%}%token NUM%token ID%token IF WHILE DO BREAK REAL TRUE FALSE BASIC ELSE INDEX GE LE NE EQ AND OR%%program : block { printf("program-->block\n"); };block : '{' decls stmts '}' { printf("block-->{decls stmts}\n"); };decls :| decls decl { printf("decls-->decls decl\n"); };decl : type ID ';' { printf("decl-->type id;\n"); };type : type '[' NUM ']' { printf("type-->type[num]\n"); }| BASIC { printf("type-->basic\n"); };stmts :| stmts stmt { printf("stmts-->stmts stmt\n"); };stmt : matched_stmt { printf("stmt-->matched_stmt\n");}| open_stmt { printf("stmt-->open_stmt\n");};open_stmt: IF '(' booL ')' stmt { printf("open_stmt-->if(bool)stmt\n");} | IF '(' booL ')' matched_stmt ELSE open_stmt { printf("open_stmt-->if(bool) matched_stmt else open_stmt\n");};matched_stmt: IF '(' booL ')' matched_stmt ELSE matched_stmt{ printf("matched_stmt-->if(bool) matched_stmt else matched_stmt\n");} | other { printf("matched_stmt-->other\n");};other: loc '=' booL ';' { printf("stmt-->loc=bool;\n"); }| WHILE '(' booL ')' stmt { printf("stmt-->while(bool)stmt\n"); }| DO stmt WHILE '(' booL ')' ';' { printf("stmt-->do stmt while(bool);\n"); } | BREAK ';' { printf("stmt-->break;\n"); }| block { printf("stmt-->block\n"); };loc : loc '[' booL ']' { printf("loc-->loc[bool]\n"); }| ID { printf("loc-->id\n"); };booL : booL OR join { printf("bool-->bool||join\n"); }| join { printf("bool-->join\n"); };join : join AND equality { printf("join-->join&&equality\n"); }| equality { printf("join-->equality\n"); };equality : equality EQ rel { printf("equality-->equality==rel\n"); }| equality NE rel { printf("equality-->equality!=rel\n"); } | rel { printf("equality-->rel\n"); };rel : expr '<' expr { printf("rel-->expr<expr\n"); }| expr LE expr { printf("rel-->expr<=expr\n"); }| expr GE expr { printf("rel-->expr>=expr\n"); }| expr '>' expr { printf("rel-->expr>expr\n"); }| expr { printf("rel-->expr\n"); };expr : expr '+' term { printf("expr-->expr+term\n"); }| expr '-' term { printf("expr-->expr-term\n"); }| term { printf("expr-->term\n"); };term : term '*' unary { printf("term-->term*unary\n"); }| term '/' unary { printf("term-->term/unary\n"); }| unary { printf("term-->unary\n"); };unary : '!' unary { printf("unary-->!unary\n"); } | '-' unary { printf("unary-->-unary\n"); }| factor { printf("unary-->factor\n"); };factor : '(' booL ')' { printf("factor-->(bool)\n"); } | loc { printf("factor-->loc\n"); }| NUM { printf("factor-->num\n"); }| REAL { printf("factor-->real\n"); }| TRUE { printf("factor-->true\n"); }| FALSE { printf("factor-->false\n"); } ;%%int yyerror(s)char *s;{fprintf(stderr,"syntactic error:%s\n",s);return 0;}六、实验结果七、实验总结实验中的注意事项:(1)一个由Yacc 生成的解析器调用yylex()函数来获得标记。