引用 基于SPSS的聚类分析的实用方法(层次聚类法和迭代聚类法)
【SPSS数据分析】SPSS聚类分析的软件操作与结果解读
【SPSS数据分析】SPSS聚类分析的软件操作与结果解读
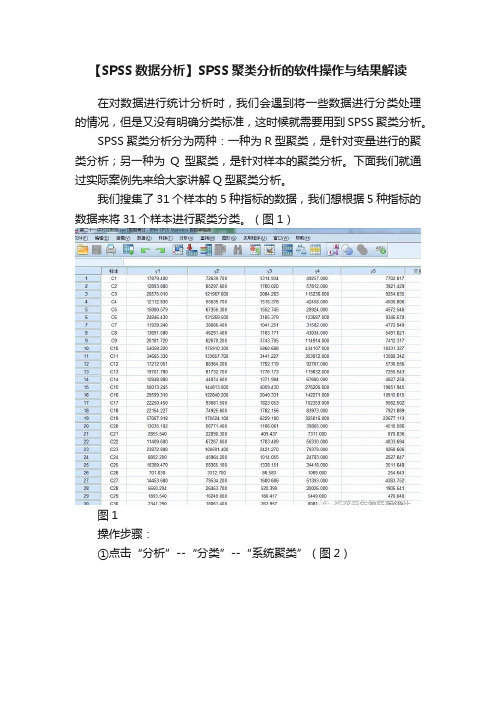
在对数据进行统计分析时,我们会遇到将一些数据进行分类处理的情况,但是又没有明确分类标准,这时候就需要用到SPSS聚类分析。
SPSS聚类分析分为两种:一种为R型聚类,是针对变量进行的聚类分析;另一种为Q型聚类,是针对样本的聚类分析。
下面我们就通过实际案例先来给大家讲解Q型聚类分析。
我们搜集了31个样本的5种指标的数据,我们想根据5种指标的数据来将31个样本进行聚类分类。
(图1)
图1
操作步骤:
①点击“分析”--“分类”--“系统聚类”(图2)
图2
③将“样本”选入个案标注依据,将γ1-5选入变量,并勾选下方“个案”标签(图3)
图3
④点击右侧“统计”按钮,将解的范围设置为2-4,意思为分聚为2,3,4类,这里可根据自己分类需求设置(图4)
图4
⑤点击右侧“图”,勾选“谱系图”(图5),点击右侧“方法”,将聚类方法设置为“组间联接”,将区间设置为“平方欧氏距离”(图6)
图5
图6
⑥点击“保存”,将解的范围设置为2-4(图7)
图7
⑦分析结果
图8
由上图(图8)可以看出,第一列为31个样本聚为4类的结果,第二列为31个样本聚为3类的结果,第三列为31个样本聚为2类的结果。
至于冰柱图和谱系图都是用图形化来进一步表达这个些结果,这里就不再赘述,想学习的朋友可以关注我们公众号进行深入学习。
以上就是今天所讲解的SPSS聚类分析的软件操作与分析结果详解,回顾一下重点,Q型聚类是根据变量数据针对样本进行的聚类。
然而还有R型聚类我们将在下一期中进行详细的讲解和分析。
敬请大家的关注!。
spss聚类分析2篇

spss聚类分析2篇第一篇:SPSS聚类分析的基本操作步骤与原理SPSS软件作为一款专业化数据统计与分析工具,其功能十分强大,在各种分析领域都有深入的应用。
其中,聚类分析是一种常用的数据分析方法之一,通过对样本数据进行事先未知的分组,可以发现数据之间的内在联系和相似性,并进一步进行分类或归纳分析。
下面,我们将简单介绍SPSS聚类分析的基本操作步骤与原理。
一、数据准备在进行SPSS聚类分析前,需要准备好分析的数据集。
其中,每个样本需要包含多个属性或变量项,比如年龄、性别、地区、收入等。
同时,还需要确定使用哪些变量进行聚类分析,这些变量一般应具有一定的类别性、独立性和完备性等特点。
可以通过SPSS软件中的“数据”菜单栏进行导入和编辑。
二、SPSS聚类分析的基本步骤1、选择聚类变量在进行聚类分析前,需要选择一组合适的聚类变量,这些变量应当与样本的属性或特征相关,以便进行分类或差异分析。
可以通过在“数据”菜单下选择“聚类”进行设置。
2、选择计算距离方法对于聚类分析来说,计算距离是一项重要的操作。
不同的距离计算方法可以对聚类结果造成不同的影响。
SPSS软件中提供了多种距离计算方法,比如欧几里得距离、曼哈顿距离、切比雪夫距离等。
可以在“聚类”设置中进行选择。
3、执行聚类分析在进行聚类分析之前,需要先设置合适的参数,比如聚类数目、初始聚类中心等。
可以在“聚类”分析设置中进行调整。
完成参数设定后,选择“聚类”分析并执行操作即可。
4、聚类结果分析聚类分析完成后,可以对结果进行分析和评估。
一般来说,需要对每个群组进行描述性统计分析,比如均数、标准差等。
同时,还需要通过各种可视化方法呈现聚类结果,比如热图、散点图等。
通过聚类结果的分析,可以对样本数据进行分类和归纳分析,有助于研究者更好地推理出样本数据特征。
三、SPSS聚类分析原理SPSS聚类分析的原理基于数据相似性度量和聚合分组方法。
具体而言,在进行聚类分析时,首先需要确定相似性度量的方法,常用的包括欧几里得距离、曼哈顿距离等。
SPSS聚类分析和判别分析论文

基于聚类分析的我国城镇居民消费结构实证分析摘要:近年来,我国城镇居民的整体消费水平逐渐提高,但各地区间的消费结构仍存在较大差别。
文章选用 8 个城镇居民消费结构统计指标,采用欧式距离平方和离差平方和法,对我国 31 个省、直辖市及自治区的 2013年城镇居民消费结构进行聚类分析和比较研究。
这不仅从总体上掌握了我国消费结构类型的地区分布,而且系统分析了我国各地区消费结构的特点及产生原因,为国家制定消费政策提供了决策依据。
关键词:消费结构;聚类分析;判别分析;政策建议;一、引言近年来,随着我国经济的快速发展 , 城镇居民的收入不断增加,并且在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,我国各地区城镇居民的消费支出也强劲增长,消费结构发生了巨大的变化,结构不合理现象也得到了一定程度的调整。
但是,由于各地区的经济发展不平衡及原有经济基础的差异,使各地区的消费结构仍存在着明显差别。
为了进一步改善消费结构,正确引导消费,提高我国城市居民的消费水平和生活质量,有必要考察我国各地区城镇居民的消费结构之间的异同并进行比较研究,以期发现特点和规律,从宏观上把握各地区城镇居民的消费现状和不同地区消费水平的差异,为提高我国各地区消费水平和谐增长提供决策依据。
二、消费结构的数据分析消费结构指居民在生活消费过程中,不同类型消费的比例及其相互之间的配合、替代、制约的关系。
就其数量关系来看,消费结构是指在消费过程中不同商品或劳务消费支出占居民总消费支出的比重,反映了一定社会经济条件下人们对各类商品及劳务的需求结构,体现一国或各地区的经济发展水平和居民生活状况。
(一)数据来源为了更加深入地了解我国城镇居民消费结构,先利用 2013 年全国数据(如表 1 所示),对全国 31 个省、直辖市、自治区进行聚类分析。
分析采用选用了城镇居民食品、衣着、居住、家庭用品及服务设备、医疗保健、交通和通信、教育文化娱乐服务、其它商品和服务八项指标,分别用来反映较高、中等、较低居民消费结构。
SPSS聚类分析具体操作步骤spss如何聚类

算法步骤:初始 化聚类中心、分 配数据点到最近 的聚类中心、重 新计算聚类中心、 迭代直到聚类中 心不再变化
适用场景:探索 性数据分析、市 场细分、异常值 检测等
注意事项:选择 合适的聚类数目、 处理空值和异常 值、考虑数据的 尺度问题
定义:根据数据点间的距离或相似性,将数据点分为多个类别的过程 常用方法:层次聚类、K-均值聚类、DBSCAN聚类等 适用场景:适用于探索性数据分析,发现数据中的模式和结构 注意事项:选择合适的距离度量方法、确定合适的类别数目等
常见的聚类分析方法包括层次聚类、Kmeans聚类、DBSCAN聚类等。
聚类分析基于数据的相似性或距离度量, 将相似的数据点归为一类,使得同一类 中的数据点尽可能相似,不同类之间的 数据点尽可能不同。
聚类分析广泛应用于数据挖掘、市场细分、 模式识别等领域。
K-means聚类:将数据划分为K个簇,使得每个数据点到所在簇中心的距离之和最小
聚类结果的可视化:通过图表展示聚类结果 聚类质量的评估:使用适当的指标评估聚类效果的好坏 聚类结果的解释:根据实际需求和背景知识,对聚类结果进行合理的解释和解读 聚类结果的应用:探讨聚类结果在各个领域的应用场景和价值
SPSS聚类分析常 用方法
定义:将数据集 划分为K个聚类, 使得每个数据点 属于最近的聚类 中心
聚类结果展示:通过图表或表格展示聚类结果,包括各类别的样本数和占比
聚类质量评估:采用适当的指标评估聚类效果,如轮廓系数、Davies-Bouldin指数等
聚类结果解读:根据业务背景和数据特征,解释各类别的含义和特征 聚类结果应用:说明聚类分析在具体场景中的应用,如市场细分、客户分类等
SPSS聚类分析注 意事项
确定聚类变量:选 择与聚类目标相关 的变量,确保变量 间无高度相关性。
spss软件聚类分析怎么用,从输入数据到结果,树状图结果。整个操作怎么进行。需要基本思路。

banner学习者请关注这里:实例系列教程问题:spss软件聚类分析怎么用,从输入数据到结果,树状图结果。
整个操作怎么进行。
需要基本思路。
_问题描述:具体操作步骤,以前从未接触过,请高手指导,十分感谢答案1:: excel表:整理一份excel数据表,第一列为材料或数据的名称,后几列为各项数值导入数据:打开SPSS,点击File——Open——DATA, 选择已经编辑好的excel表点击analyze——Classify——Hierarchical cluster analysis——数据导入variables,表头项导入label case by;选择Method 项,根据需要选择方法,点击Plots选择dendrogram(打对勾),其余各项根据自己需要选择要计算的统计量,点击ok即可。
答案2:: 基于SPSS的聚类分析的实用方法(层次聚类法和迭代聚类法)层次聚类法和迭代聚类法的主要区别在于:层次聚类法的聚类结果受奇异值的影响非常大,且聚类过程是单方向的,一旦某个样本进入某一类,就不可能从该类出来,再归入其他的类;迭代聚类法的聚类结果受奇异值和不合适的聚类变量的影响较小,对于不合适的初始聚类可以进行反复调整,但其缺点是聚类结果对初始聚类非常敏感,而且它也只能得到局部最优解.(一)层次聚类Analyze--; C1assify--;Hierachical Cluster在“C1uster”组中选择聚类类型:要进行变量聚类选择指定“Vanables”;要进行观测量聚类指定“Cases”。
指定参与分析的变量,将选定的变量通过按钮箭头转移到箭头按钮右侧的“Variable[s]:”矩形框中;将标识变量通过下面一个箭头按钮转移到按钮右侧的“Label Cases by:”下面的矩形框中。
如果不使用系统默认值,或由于参与分析的变量量纲不一致需要指定选择项,则应该根据需要有选择性地执行下述某些步骤。
1.确定聚类方法在主对话框中,点击“Methed”按钮,展开分层聚类分析的方法选择对话框,即“Hierachical Cluster Analysis:Method”。
spss聚类分析方法选择

SPSS聚类分析方法选择一、导言SPSS(Statistical Package for the Social Sciences)是一款被广泛使用的统计分析软件,其功能强大且易于操作。
聚类分析是SPSS中常用的一种数据分析方法,可以将相似的个体归为一类,帮助我们理解数据的结构和特征。
在进行聚类分析时,我们首先需要选择适合的聚类方法。
本文将介绍SPSS中常用的聚类方法,并讨论如何选择最适合的方法。
二、常见的SPSS聚类分析方法1. K均值聚类K均值聚类是SPSS中最常见的聚类方法之一。
该方法将样本分为K个簇,使簇内的样本相似度最大化,簇间的相似度最小化。
K均值聚类需要预先确定簇的个数K,并且聚类结果对初始点的选取敏感。
该方法适用于样本数较大、特征数较少的数据。
2. 密度聚类密度聚类是一种基于密度的聚类方法,常用的有DBSCAN和OPTICS。
这些方法将样本集合中的数据点组成的簇定义为密度相连的点的最大集合。
密度聚类能够有效地处理一些非球形分布的数据,对噪声数据也有较好的鲁棒性。
3. 层次聚类层次聚类使用一种树状结构来组织数据,常用的有凝聚层次聚类和分裂层次聚类。
凝聚层次聚类从单个样本开始,逐步合并最相似的簇,直到形成一个包含所有样本的簇。
分裂层次聚类则从整个样本集开始,逐步将样本分割成小的、不相交的簇。
层次聚类可用于确定最佳的簇的个数,但在处理大型数据集时计算复杂度较高。
4. 二分K均值聚类二分K均值聚类将样本集合分为两个簇,并且分别对每个子簇进行迭代划分,直到满足预定的停止条件。
该方法适用于样本数较大、特征数较多的数据。
三、选择合适的聚类方法在选择SPSS聚类分析方法时,需要根据具体的数据集特点和分析目的进行考虑:1.数据集特点:数据集的样本数、特征数和分布形态对聚类方法的选择有很大影响。
如果样本数较大、特征数较少,并且数据呈现相对均匀的分布,可以选择K均值聚类。
如果数据集存在非球形分布、噪声数据等问题,可以考虑使用密度聚类方法。
SPSS数据的聚类分析
如何实现聚类?
---聚类分析的基本思想和方法
➢ 1、什么是聚类分析?
• 聚类分析: 是根据“物以类聚”的道理,对样品或指 标进行分类,使得同一类中的对象之间的相似性比与其 他类的对象的相似性更强的一种多元统计分析方法。
• 聚类分析的目的:把相似的研究对象归成类;即:使类 内对象的相似性最大化和类间对象的差异性最大化。
2023/5/3
4
zf
以系统聚类法为例
凝聚式
分解式
2023/5/3
5
zf
二、相似性度量
➢ 1、相似性的度量指标:
• 相似系数:性质越接近的变量或样品,它们的相似系数 越接近于1或-1,而彼此无关的变量或样品它们的相似系 数则越接近于0,相似的为一类,不相似的为不同类;
• 距离:变量或样本间的距离越近,说明其相似性越高, 应归为一类;距离越远则说明相似性越弱,应归为不同 的类。
为什么这样 分类?
20有23何/5/好3 处?
因为每一个类别里面的人消费方式都不一样,需要针对不同的 人群,制定不同的关系管理方式,以提高客户对公司商业活动的 参与率。 挖掘有价值的客户,并制定相应的促销策略:对经常购买酸奶 的客户;对累计消费达到12个月的老客户。
针对2潜在客户派发广告,比在大街上乱发传单命中率更高 ,成本z更f 低!
Dpq min d (xi , x j )
2023其/5/中3 ,d(xi,xj)表示点xi∈
Gp和xj
1∈4
zf
Gq之间的距离
以当前某个样本与 已经形成的小类中 的各样本距离中的 最小值作为当前样 本与该小类之间的
距离。
例1:为了研究辽宁省5省区某年城镇居民生活消费的 分布规律,根据调查资料做类型划分
SPSS聚类以及各种聚类分析详解
精选可编辑ppt
3
精选可编辑ppt
4
数据标准化处理:
精选可编辑ppt
5
存储中间过程数据
精选可编辑ppt
6
数据标准 化处理, 并存储。
精选可编辑ppt
7
精选可编辑ppt
8
指定5类
精选可编辑ppt
9
精选可编辑ppt
收敛标准值 10
精选可编辑ppt
11
存储最终结果输出情况,在数据文件中(QCL-1、QCL-2)
(4)若选出的一对样品都出现在同一组中,则这对样 品就不用再分组了。
按上述四条原则反复进行,直到把所有样品都分类完毕, 最后以分类图形式表示
精选可编辑ppt
25
2、分类方法 例:设有7个样品,每个样品测得P个指标,数据如表
样品 指标
X1 X2 XP
X1 X2 X3 X4 X5 X6 X7
精选可编辑ppt
2)形成一个由小到大的分析系统。 3)把整个分类系统画成一张分类图
精选可编辑ppt
21
二、聚类统计量
首先定义一些分类统计指标 —— 刻画样或指标之间 的相似程度(这些统计指标称为聚类统计量)
在市场研究中,样品 —— 用作分类的事物
指标ቤተ መጻሕፍቲ ባይዱ—— 用来作为分类依据的变量。(如: 年龄、收入、销售量)
(一)相似系数(夹角余弦)
39
观测量概述表
精选可编辑ppt
40
聚类步骤,与图结合看!
精选可编辑ppt
41
4、5
精选可编辑ppt
42
精选可编辑ppt
43
聚类方法有系统聚类和逐步聚类,输入数据集可以是普 通数据集、相关矩阵(CORR过程产生)或协方差矩阵 (FACTOR等过程产生)。SAS提供的聚类过程有:
SPSSAU聚类分析步骤说明
聚类分析聚类分析:聚类分析是通过数据建模简化数据的一种方法。
“物以类聚,人以群分”正是对聚类分析最好的诠释。
一、聚类分析可以分为:对样本进行聚类分析(Q型聚类),此类聚类的代表是K-means聚类方法;对变量(标题)进行聚类分析(R型聚类),此类聚类的代表是分层聚类。
常见为样本聚类,比如有500个人,这500个人可以聚成几个类别。
下面具体阐述对样本进行聚类分析的方法说明(分层聚类将在之后的文章中介绍):聚类分析(Q型聚类)用于将样本进行分类处理,通常是以定量数据作为分类标准。
如果是按样本聚类,则使用SPSSAU的进阶方法模块中的“聚类分析”功能,其会自动识别出应该使用K-means聚类算法还是K-prototype聚类算法。
二、Q型聚类分析的优点:1、可以综合利用多个变量的信息对样本进行分类;2、分类结果是直观的,聚类谱系图非常清楚地表现其数值分类结果;3、聚类分析所得到的结果比传统分类方法更细致、全面、合理。
三、分析思路以下分析思路为对样本进行聚类分析(1)指标归类当研究人员并不完全确定题项应该分为多少个变量,或者研究人员对变量与题项的对应关系并没有充分把握时,可以使用探索性因子分析将各量表题项提取为多个因子(变量),利用提取得到的因子进行后续的聚类分析。
特别提示:分析角度上,通过探索性因子分析,将各量表题项提取为多个因子,提取出的因子可以在后续进行聚类分析。
比如:可先讲20个题做因子分析,并且得到因子得分。
将因子得分在进一步进行聚类分析。
最终聚类得到几个类别群体。
再去对比几个类别群体的差异等。
(2)聚类分析第一步:进行聚类分析设置如果使用探索性因子分析出来的因子进行聚类分析,当提取出五个因子时,应该首先计算此五个因子对应题项的平均分,分别使用平均得分代表此五个因子(比如因子1对应三个题项,则计算此三个题项的平均值去代表因子1),利用计算完成平均得分后得到的因子进行聚类分析。
第二步:结合不同聚类类别人群特征进行类别命名聚类分析完成后,每个类别的样本应该如何称呼,或者每个类别样本的名字是什么,软件并不能进行判断。
基于SPSS分析系统的聚类分析
6:单击确定运行。
三:两步聚类:
1:打开数据“鸢尾花分析——两步聚类”,查看文件的变量设置。
2:点击“分析”——“分类”——“两步聚类”,打开两步聚类分析设置界面。
3:同时选中“花萼长”至“花瓣宽”4个变量,将其选入连续变量框中,聚类数量栏选中“选中固定值”,数量改为“3”。
4:单击统计量按钮,单击方案范围,最小聚类数设为2,最大聚类数设为4,单击继续返回。单击绘制按钮,选中“树状图”,单击继续返回。
5:单击保存按钮,单击方案范围,最小聚类数设为2,最大聚类数设为4,单击继续返回。
6:单击确定运行。
二:快速聚类
1:打开数据“鸢尾花分析——快速聚类”,查看文件的变量设置。
4:单击输出按钮,选中“图表和表格”和“创建聚类成员变量”,单击继续返回。选项按钮设置保留默认设置。
6:单击确定运行。
实验结果
1、系统聚类
表中说明了群集之间的聚类方式和聚类系数,及下次聚类的步骤阶。
表中可以看出分成2、3、4个聚类时各个案例所在的群集。
图中形象的各个案例聚集的步骤
表中可以看出分成3类时,各个统计量的参数
.473
4
.000
.497
.328
5
.000
.000
.000
a.由于聚类中心内没有改动或改动较小而达到收敛。任何中心的最大绝对坐标更改为.000。当前迭代为5。初始中心间的最小距离为38.236。
最终聚类中心
聚类
1
2
3
花萼长
50.06
68.50
59.02
花萼宽
34.28
30.74
27.48
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
引用基于SPSS的聚类分析的实用方法(层次聚类法和迭代聚类法)引用 qjzhen001 的基于SPSS的聚类分析的实用方法(层次聚类法和迭代聚类法)
基于SPSS的聚类分析的实用方法(层次聚类法和迭代聚类法)
层次聚类法和迭代聚类法的主要区别在于:层次聚类法的聚类结果受奇异值的影响非
常大,且聚类过程是单方向的,一旦某个样本进入某一类,就不可能从该类出来,再归入其他的类;迭代聚类法的聚类结果受奇异值和不合适的聚类变量的影响较小,对于不合适的初始聚类可以进行反复调整,但其缺点是聚类结果对初始聚类非常敏感,而且它也只能得到局部最优解.
(一)层次聚类
Analyze--> C1assify-->Hierachical Cluster
在“C1uster”组中选择聚类类型:要进行变量聚类选择指定“Vanables”;要进行
观测量聚类指定“Cases”。
指定参与分析的变量,将选定的变量通过按钮箭头转移到箭头按钮右侧的
“Variable[s]:”矩形框中;将标识变量通过下面一个箭头按钮转移到按钮右侧的“Label Cases by:”下面的矩形框中。
如果不使用系统默认值,或由于参与分析的变量量纲不一致需要指定选择项,则应该根据需要有选择性地执行下述某些步骤。
1.确定聚类方法
在主对话框中,点击“Methed”按钮,展开分层聚类分析的方法选择对话框,即
“Hie rachical Cluster Analysis:Method”。
在对话框中根据需要指定聚类方法、距离测度的方法、对数值进行转换方法,即标准化数值的方法和对测度的转换方法。
(1)聚类方法选择
“C1uster Method:”表中列出可以选择的聚类方法:
Between-groups linkage组内连接
Within-groups linkage组内连接
Nearest neighbor最近邻法
Furthest neighbor最远邻法
Centroid clustering重心聚类法
Median clustering中位数法
Ward’s method Ward最小方差法。
(后三种聚类方法应与欧氏距离平方法一起使用)
几种方法的具体情况见下面的英文文档
(2)对距离的测度方法选择
在Method中指定的是用哪两点间的距离的大小决定是否合并两类。
距离的具体计算
方法还根据参与距离的变量类型从以下三种对话框选择其一,展开选择菜单后再进行具体
方法的选择。
这三个对话框分别对应于等间隔测度的变量(一般为连续变量)、计数变量(一般为离散变量)和二值变量。
这里只考虑连续变量的情况
“Interval”(系统默认)
Euclidean distance:Euclidean距离,即两观察单位间的距离为其值差的平方和的
平方根,该技术用于Q型聚类;
Squared Euclidean distance:Euclidean距离平方,即两观察单位间的距离为其值
差的平方和,该技术用于Q型聚类;
Cosine:变量矢量的余弦,这是模型相似性的度量;
Pearson correlation:相关系数距离,适用于R型聚类;
Chebychev:Chebychev距离,即两观察单位间的距离为其任意变量的最大绝对差值,该技术用于Q型聚类;
Block:City-Block或Manhattan距离,即两观察单位间的距离为其值差的绝对值和,适用于Q型聚类;
Minkowski:距离是一个绝对幂的度量,即变量绝对值的第p次幂之和的平方根;p由用户指定
Customized:距离是一个绝对幂的度量,即变量绝对值的第p次幂之和的第r次根,
p与r由用户指定。
(3)确定标准化的方法:“Transform Value”
“Standardize” 下为标准化列表
对数据进行标准化的可选择的方法有:
① None 不进行标准化,是系统默认值。
② Z scores 把数值标准化到Z分数。
③ Range -1to l把数值标准化到-1到+l范围内。
选择该项,对每个值用变量或观测量的值的范围去除。
如果值范围是0,所有值保持不变。
④ Maximum magnituds of 1 把数值标准化到最大值为1。
该方法是把正在标准化的
变量或观测量的值用最大值去除。
如果最大值为0,则改用最小值去除,其商加1。
⑤ Range 0 to 1 把数值标准化到0到1的范围内,对正在被标准化的变量或观测量
的值剪去最小值,然后除以范围。
如果范围是0,对变量或观测量的所有值都设置成0.5。
⑥ Mean of 1 把数值标准化到一个均值的范围内,对正在被标准化的变量或观测量
的值除以这些值的均值。
如果均值是0,对变量或观测量的所有值都加1,使其均值为1。
⑦ Standard devia tion of 1 把数值标准化到单位标准差。
该方法对正在被标准化
的变量或观测量的值除以这些值的标准差,如果标准差为0,则这些值保持不变。
(4)测度的转换方法选择
对距离测度数值进行转换,在距离计算完成后进行。
可选择的转换方法有三种,在“Methd”对话框右下角的标有“Transform Mearure”的框中选择。
① Absolute Values 把距离值标准化。
当数值符号表示相关方向,且只对负相关关
系感兴趣时使用此方法进行变换。
② Change sign 把相似性值变为不相似性值,或相反。
用求反的方法使距离顺序颠倒。
③ Rescale to 0-- 1 range 通过首先去掉最小值然后除以范围的方法使距离标准化。
对于已经按某种换算方法标准化了的测度,一般不再使用此方法进行转换。
2.选择要求输出的统计量:Statistics对话框
Aggomeration schedule 输出聚合过程表
Proximity matrix:输出的是每个案例之间的欧氏距离平方表(Q型聚类)。
Cluster membership决定聚合的群数。
试探性地做时就选none,做完后根据判断的
合适的群数在输入确定的群数,这时会得出一个更多的结果cluster membership,即在此群数下,各案例所属的群。
当然也可选择Range of solutions确定群数的范围。
3.选择统计图表: Plot
Dendrogram 树形图;
Icicle冰柱图:
对于生成什么样的冰柱图还可以进一步用以下选择项确定:
All clusters 聚类的每一步都表现在图中。
可用此种图查看聚类的全过程。
但如果
参与聚类的个体很多会造成图过大,没有必要。
可以使用下面一个选择项限定显示的范围。
Specified range of clusters 指定显示的聚类范围。
当选择此项时,该项下面的选
择框加亮,表示等待输入显示范围。
在Start后的矩形框中输入要求显示聚类过程的起始
步数,在Stop后的矩形框中输入显示中止于哪一步,把显示的两步之间的增量输入到By
后面的矩形框中。
输入到矩形框中的数字必须是正整数。
例如,输入的结果是:Start: 3 Stop: 10 By:2
生成的冰柱图从第三步开始,显示第三、五、七、九步聚类的情况。
None:不生成冰柱图
对于显示方向可以用Orientation下面的选择项确定:
Vertical纵向显示的冰柱图。
(系统默认)
HoriZontal显示水平的冰柱图。
4.生成新变量的选择:save
聚类分析的结果可以用新变量保存在工作数据文件中。
单击主对话框的“save”按钮,展开相应的对话框。
可以看出只能生成一个表明参与聚类的个体最终被分配到哪一类的新
变量。
通过对话框可以选择是否建立新变量和建立的新变量含义。
None 不建立新变量。
Single solution:单一结果。
生成一个新变量表明每个个体聚类最后所属的类。
在
该项后面的矩形框中指定类数。
如果指定5 clusters,则新变量的值为1-- 5。
Range of solutions:指定范围内的结果。
生成若干个新变量,表明聚为若干个类时,每个个体聚类后所属的类。
在该项后商的矩形框中指定显示范围,即把表示从第几类显示
到第几类的数字分别输入到From后面的矩形框和through后面的矩形框中。
例如输入结
果是“From 4 through 6”,在聚类结束后在数据窗中原变量后面增加了3个新变量分别
表明分为4类时、分为5类时和分为6类时的聚类结果。
即聚为4、5、6类时各观测量分
别属于哪一类。
新变量选择完成后按“Continue”按钮,返回到主对话框。
(二)迭代聚类
Analyze--> C1assify--> K-Means Cluster
“Methed”框,给出两个可选择的聚类方法:
1)Iterate and classify 选择初始类中心,在迭代过程中使用k-Means算法不断更换类中心,把观测量分派到与之最近的以类中心为标志的类中去;
2)Classify TYPE="audio/mpeg">。