Oracle自定义聚合函数-分析函数
Oracle中分析函数用法小结

Oracle中分析函数用法小结一.分析函数适用场景:○1需要对同样的数据进行不同级别的聚合操作○2需要在表内将多条数据和同一条数据进行多次的比较○3需要在排序完的结果集上进行额外的过滤操作二.分析函数语法:FUNCTION_NAME(<argument>,<argument>...)OVER(<Partition-Clause><Order-by-Clause><Windowing Clause>)例:sum(sal) over (partition by deptno order by ename) new_aliassum就是函数名(sal)是分析函数的参数,每个函数有0~3个参数,参数可以是表达式,例如:sum(sal+comm) over 是一个关键字,用于标识分析函数,否则查询分析器不能区别sum()聚集函数和sum()分析函数partition by deptno 是可选的分区子句,如果不存在任何分区子句,则全部的结果集可看作一个单一的大区order by ename 是可选的order by 子句,有些函数需要它,有些则不需要.依靠已排序数据的那些函数,如:用于访问结果集中前一行和后一行的LAG和LEAD,必须使用,其它函数,如AVG,则不需要.在使用了任何排序的开窗函数时,该子句是强制性的,它指定了在计算分析函数时一组内的数据是如何排序的.1)FUNCTION子句ORACLE提供了26个分析函数,按功能分5类分析函数分类等级(ranking)函数:用于寻找前N种查询开窗(windowing)函数:用于计算不同的累计,如SUM,COUNT,AVG,MIN,MAX等,作用于数据的一个窗口上例:sum(t.sal) over (order by t.deptno,t.ename) running_total,sum(t.sal) over (partition by t.deptno order by t.ename) department_total制表(reporting)函数:与开窗函数同名,作用于一个分区或一组上的所有列例:sum(t.sal) over () running_total2,sum(t.sal) over (partition by t.deptno) department_total2制表函数与开窗函数的关键不同之处在于OVER语句上缺少一个ORDER BY子句!LAG,LEAD函数:这类函数允许在结果集中向前或向后检索值,为了避免数据的自连接,它们是非常有用的.VAR_POP,VAR_SAMP,STDEV_POPE及线性的衰减函数:计算任何未排序分区的统计值2)PARTITION子句按照表达式分区(就是分组),如果省略了分区子句,则全部的结果集被看作是一个单一的组3)ORDER BY子句分析函数中ORDER BY的存在将添加一个默认的开窗子句,这意味着计算中所使用的行的集合是当前分区中当前行和前面所有行,没有ORDER BY时,默认的窗口是全部的分区在Order by 子句后可以添加nulls last,如:order by comm desc nulls last 表示排序时忽略comm列为空的行.4)WINDOWING子句用于定义分析函数将在其上操作的行的集合Windowing子句给出了一个定义变化或固定的数据窗口的方法,分析函数将对这些数据进行操作默认的窗口是一个固定的窗口,仅仅在一组的第一行开始,一直继续到当前行,要使用窗口,必须使用ORDER BY子句根据2个标准可以建立窗口:数据值的范围(RANGES)或与当前行的行偏移量.5)Rang窗口Range 5 preceding:将产生一个滑动窗口,他在组中拥有当前行以前5行的集合ANGE窗口仅对NUMBERS和DATES起作用,因为不可能从VARCHAR2中增加或减去N个单元另外的限制是ORDER BY中只能有一列,因而范围实际上是一维的,不能在N维空间中例:avg(t.sal) over(order by t.hiredate asc range 100 preceding) 统计前100天平均工资6)Row窗口利用ROW分区,就没有RANGE分区那样的限制了,数据可以是任何类型,且ORDER BY 可以包括很多列7)Specifying窗口UNBOUNDED PRECEDING:这个窗口从当前分区的每一行开始,并结束于正在处理的当前行CURRENT ROW:该窗口从当前行开始(并结束)Numeric Expression PRECEDING:对该窗口从当前行之前的数字表达式(Numeric Expression)的行开始,对RANGE来说,从行序值小于数字表达式的当前行的值开始. Numeric Expression FOLLOWING:该窗口在当前行Numeric Expression行之后的行终止(或开始),且从行序值大于当前行Numeric Expression行的范围开始(或终止)range between 100 preceding and 100 following:当前行100前, 当前行100后注意:分析函数允许你对一个数据集进排序和筛选,这是SQL从来不能实现的.除了最后的Order by子句之外,分析函数是在查询中执行的最后的操作集,这样的话,就不能直接在谓词中使用分析函数,即不能在上面使用where或having子句!!!下面我们通过一个实际的例子:按区域查找上一年度订单总额占区域订单总额20%以上的客户,来看看分析函数的应用。
ORACLE 聚合函数(共7个)
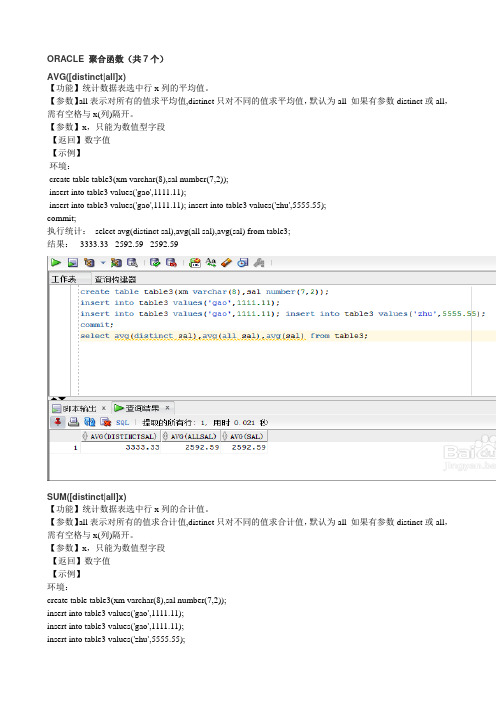
ORACLE 聚合函数(共7个)AVG([distinct|all]x)【功能】统计数据表选中行x列的平均值。
【参数】all表示对所有的值求平均值,distinct只对不同的值求平均值,默认为all 如果有参数distinct或all,需有空格与x(列)隔开。
【参数】x,只能为数值型字段【返回】数字值【示例】环境:create table table3(xm varchar(8),sal number(7,2));insert into table3 values('gao',1111.11);insert into table3 values('gao',1111.11); insert into table3 values('zhu',5555.55);commit;执行统计:select avg(distinct sal),avg(all sal),avg(sal) from table3;结果: 3333.33 2592.59 2592.59SUM([distinct|all]x)【功能】统计数据表选中行x列的合计值。
【参数】all表示对所有的值求合计值,distinct只对不同的值求合计值,默认为all 如果有参数distinct或all,需有空格与x(列)隔开。
【参数】x,只能为数值型字段【返回】数字值【示例】环境:create table table3(xm varchar(8),sal number(7,2));insert into table3 values('gao',1111.11);insert into table3 values('gao',1111.11);insert into table3 values('zhu',5555.55);commit;执行统计:select SUM(distinct sal),SUM(all sal),SUM(sal) from table3;结果: 6666.66 7777.77 7777.77STDDEV([distinct|all]x)【功能】统计数据表选中行x列的标准误差。
Oracle分析函数用法详解

Oracle分析函数Oracle分析函数实际上操作对象是查询出的数据集,也就是说不需二次查询数据库,实际上就是oracle实现了一些我们自身需要编码实现的统计功能,对于简化开发工作量有很大的帮助,特别在开发第三方报表软件时是非常有帮助的。
Oracle从8.1.6开始提供分析函数。
一、基本语法oracle分析函数的语法:function_name(arg1,arg2,...)over(<partition-clause> <order-by-clause ><windowing clause>)说明:1.partition-clause 数据记录集分组2.order-by-clause 数据记录集排序3.windowing clause 功能非常强大、比较复杂,定义分析函数在操作行的集合。
有三种开窗方式: range、row、specifying。
二、常用分析函数1. avg(distinct|all expression) 计算组内平均值,distinct 可去除组内重复数据select deptno,empno,sal,avg(sal) over (partition by deptno) avg_sal from t;DEPTNO EMPNO SAL AVG_SAL---------- ---------- ---------- ----------10 7782 2450 2916.666677839 5000 2916.666677934 1300 2916.6666720 7566 2975 21757902 3000 21757876 1100 21757369 800 21757788 3000 217530 7521 1250 1566.666677844 1500 1566.666677499 1600 1566.666677900 950 1566.666677698 2850 1566.666677654 1250 1566.666672.count(<distinct><*><expression>) 对组内数据进行计数3.rank() 和dense_rank()dense_rank()根据 order by 子句表达式的值,从查询返回的每一行,计算和其他行的相对位置,序号从 1 开始,有重复值时序号不跳号。
oracle最全函数大全(分析函数-聚合函数-转换函数-日期型函数-字符型函数-数值型函数-其他函数)

oracle函数大全(分析函数,聚合函数,转换函数,日期型函数,字符型函数,数值型函数,其他函数)oracle函数大全 (1)oracle分析函数--SQL*PLUS环境 (1)oracle 10g函数大全--聚合函数 (19)oracle 10g函数大全--转换函数 (23)oracle 10g函数大全--日期型函数 (40)oracle 10g函数大全--字符型函数 (45)oracle 10g函数大全--数值型函数 (55)oracle 10g函数大全--其他函数 (58)oracle分析函数--SQL*PLUS环境一、总体介绍1.1.分析函数如何工作语法 FUNCTION_NAME(<参数>,…) OVER (<PARTITION BY 表达式,…> <ORDER BY 表达式 <ASC DESC> <NULLS FIRST NULLS LAST>> <WINDOWING子句>) PARTITION子句ORDER BY子句 WINDOWING子句缺省时相当于RANGE UNBOUNDED PRECEDING1. 值域窗(RANGE WINDOW)RANGE N PRECEDING 仅对数值或日期类型有效,选定窗为排序后当前行之前,某列(即排序列)值大于/小于(当前行该列值–/+ N)的所有行,因此与ORDER BY子句有关系。
2. 行窗(ROW WINDOW)ROWS N PRECEDING 选定窗为当前行及之前N行。
还可以加上BETWEEN AND 形式,例如RANGE BETWEEN m PRECEDING AND n FOLLOWING 函数 AVG(<distinct all> eXPr)一组或选定窗中表达式的平均值 CORR(expr, expr) 即COVAR_POP(exp1,exp2) / (STDDEV_POP(expr1) * STDDEV_POP(expr2)),两个表达式的互相关,-1(反相关) ~1(正相关),0表示不相关COUNT(<distinct> <*> <expr>) 计数COVAR_POP(expr, expr) 总体协方差COVAR_SAMP(expr, expr) 样本协方差CUME_DIST 累积分布,即行在组中的相对位置,返回0 ~ 1DENSE_RANK 行的相对排序(与ORDER BY搭配),相同的值具有一样的序数(NULL计为相同),并不留空序数FIRST_VALUE 一个组的第一个值LAG(expr, <offset>, <default>) 访问之前的行,OFFSET是缺省为1 的正数,表示相对行数,DEFAULT是当超出选定窗范围时的返回值(如第一行不存在之前行)LAST_VALUE 一个组的最后一个值LEAD(expr, <offset>, <default>) 访问之后的行,OFFSET是缺省为1 的正数,表示相对行数,DEFAULT是当超出选定窗范围时的返回值(如最后行不存在之前行)MAX(expr) 最大值MIN(expr) 最小值NTILE(expr) 按表达式的值和行在组中的位置编号,如表达式为4,则组分4份,分别为1 ~ 4的值,而不能等分则多出的部分在值最小的那组PERCENT_RANK 类似CUME_DIST,1/(行的序数 - 1)RANK 相对序数,答应并列,并空出随后序号RATIO_TO_REPORT(expr) 表达式值 / SUM(表达式值)ROW_NUMBER 排序的组中行的偏移STDDEV(expr) 标准差STDDEV_POP(expr) 总体标准差STDDEV_SAMP(expr) 样本标准差SUM(expr) 合计VAR_POP(expr) 总体方差VAR_SAMP(expr) 样本方差VARIANCE(expr) 方差REGR_ xxxx(expr, expr) 线性回归函数REGR_SLOPE:返回斜率,等于COVAR_POP(expr1, expr2) / VAR_POP(expr2) REGR_INTERCEPT:返回回归线的y截距,等于AVG(expr1) - REGR_SLOPE(expr1, expr2) * AVG(expr2)REGR_COUNT:返回用于填充回归线的非空数字对的数目REGR_R2:返回回归线的决定系数,计算式为:If VAR_POP(expr2) = 0 then return NULLIf VAR_POP(expr1) = 0 and VAR_POP(expr2) != 0 then return 1If VAR_POP(expr1) > 0 and VAR_POP(expr2 != 0 thenreturn POWER(CORR(expr1,expr),2)REGR_AVGX:计算回归线的自变量(expr2)的平均值,去掉了空对(expr1, expr2)后,等于AVG(expr2)REGR_AVGY:计算回归线的应变量(expr1)的平均值,去掉了空对(expr1, expr2)后,等于AVG(expr1)REGR_SXX:返回值等于REGR_COUNT(expr1, expr2) * VAR_POP(expr2)REGR_SYY:返回值等于REGR_COUNT(expr1, expr2) * VAR_POP(expr1)REGR_SXY: 返回值等于REGR_COUNT(expr1, expr2) * COVAR_POP(expr1, expr2) 首先:创建表及接入测试数据create table students(id number(15,0),area varchar2(10),stu_type varchar2(2),score number(20,2));insert into students values(1, '111', 'g', 80 );insert into students values(1, '111', 'j', 80 );insert into students values(1, '222', 'g', 89 );insert into students values(1, '222', 'g', 68 );insert into students values(2, '111', 'g', 80 );insert into students values(2, '111', 'j', 70 );insert into students values(2, '222', 'g', 60 );insert into students values(2, '222', 'j', 65 );insert into students values(3, '111', 'g', 75 );insert into students values(3, '111', 'j', 58 );insert into students values(3, '222', 'g', 58 );insert into students values(3, '222', 'j', 90 );insert into students values(4, '111', 'g', 89 );insert into students values(4, '111', 'j', 90 );insert into students values(4, '222', 'g', 90 );insert into students values(4, '222', 'j', 89 ); commit;二、具体应用:1、分组求和:1.2.GROUP BY子句1.2.1.GROUPING SETSselect id,area,stu_type,sum(score) scorefrom studentsgroup by grouping sets((id,area,stu_type),(id,area),id) order by id,area,stu_type;/*--------理解grouping setsselect a, b, c, sum( d ) from tgroup by grouping sets ( a, b, c )等效于select * from (select a, null, null, sum( d ) from t group by a union allselect null, b, null, sum( d ) from t group by b union allselect null, null, c, sum( d ) from t group by c )*/1.2.2.ROLLUPselect id,area,stu_type,sum(score) scorefrom studentsgroup by rollup(id,area,stu_type)order by id,area,stu_type;1.2.3.rollupselect a, b, c, sum( d )from tgroup by rollup(a, b, c);等效于select * from (select a, b, c, sum( d ) from t group by a, b, c union allselect a, b, null, sum( d ) from t group by a, b union allselect a, null, null, sum( d ) from t group by a union allselect null, null, null, sum( d ) from t)*/1.2.4.CUBEselect id,area,stu_type,sum(score) scorefrom studentsgroup by cube(id,area,stu_type)order by id,area,stu_type;/*--------理解cubeselect a, b, c, sum( d ) from tgroup by cube( a, b, c)等效于select a, b, c, sum( d ) from tgroup by grouping sets(( a, b, c ),( a, b ), ( a ), ( b, c ),( b ), ( a, c ), ( c ),() )*/1.2.5.GROUPING/*从上面的结果中我们很容易发现,每个统计数据所对应的行都会出现null,如何来区分到底是根据那个字段做的汇总呢,grouping函数判断是否合计列!*/select decode(grouping(id),1,'all id',id) id,decode(grouping(area),1,'all area',to_char(area)) area,decode(grouping(stu_type),1,'all_stu_type',stu_type) stu_type, sum(score) scorefrom studentsgroup by cube(id,area,stu_type)order by id,area,stu_type;1.3.OVER()函数的使用1.3.1.统计名次1.3.1.1.D ENSE_RANK(),允许并列名次、名次不间断,如122344456将score按ID分组排名:dense_rank() over(partition by id order by score desc)将score不分组排名:dense_rank() over(order by score desc)select id,area,score,dense_rank() over(partition by id order by score desc) 分组id排序, dense_rank() over(order by score desc) 不分组排序from students order by id,area;1.3.1.2.R OW_NUMBER(),不允许并列名次、相同值名次不重复,结果如123456……将score按ID分组排名:row_number() over(partition by id order by score desc)将score不分组排名:row_number() over(order by score desc)select id,area,score,row_number() over(partition by id order by score desc) 分组id排序,row_number() over(order by score desc) 不分组排序from students order by id,area;1.3.1.3.r ank(),允许并列名次、复制名次自动空缺,结果如12245558……将score按ID分组排名:rank() over(partition by id order by score desc) 将score不分组排名:rank() over(order by score desc)select id,area,score,rank() over(partition by id order by score desc) 分组id排序,rank() over(order by score desc) 不分组排序from students order by id,area;1.3.1.4.c ume_dist(),名次分析——-最大排名/总个数函数:cume_dist() over(order by id)select id,area,score,cume_dist() over(order by id) a, --按ID最大排名/总个数cume_dist() over(partition by id order by score desc) b, --ID分组中,scroe最大排名值/本组总个数row_number() over (order by id) 记录号from students order by id,area;1.3.1.5.c ume_dist(),允许并列名次、复制名次自动空缺,取并列后较大名次,结果如22355778……将score按ID分组排名:cume_dist() over(partition by id order by score desc)*sum(1) over(partition by id)将score不分组排名:cume_dist() over(order by score desc)*sum(1) over() select id,area,score,sum(1) over() as 总数,sum(1) over(partition by id) as 分组个数,(cume_dist() over(partition by id order by score desc))*(sum(1)over(partition by id)) 分组id排序,(cume_dist() over(order by score desc))*(sum(1) over()) 不分组排序from students order by id,area1.3.1.6.s um(),max(),avg(),RATIO_TO_REPORT()--分组统计select id,area,sum(1) over() as 总记录数,sum(1) over(partition by id) as 分组记录数,sum(score) over() as 总计 ,sum(score) over(partition by id) as 分组求和,sum(score) over(order by id) as 分组连续求和,sum(score) over(partition by id,area) as 分组ID和area求和,sum(score) over(partition by id order by area) as 分组ID并连续按area求和,max(score) over() as 最大值,max(score) over(partition by id) as 分组最大值,max(score) over(order by id) as 分组连续最大值,max(score) over(partition by id,area) as 分组ID和area求最大值,max(score) over(partition by id order by area) as 分组ID并连续按area求最大值,avg(score) over() as 所有平均,avg(score) over(partition by id) as 分组平均,avg(score) over(order by id) as 分组连续平均,avg(score) over(partition by id,area) as 分组ID和area平均,avg(score) over(partition by id order by area) as 分组ID并连续按area平均,RATIO_TO_REPORT(score) over() as "占所有%",RATIO_TO_REPORT(score) over(partition by id) as "占分组%",score from students;3、LAG(COL,n,default)、LEAD(OL,n,default) --取前后边N条数据取前面记录的值:lag(score,n,x) over(order by id)取后面记录的值:lead(score,n,x) over(order by id)参数:n表示移动N条记录,X表示不存在时填充值,iD表示排序列select id,lag(score,1,0) over(order by id) lg,score from students; select id,lead(score,1,0) over(order by id) lg,score from students;4、FIRST_VALUE()、LAST_VALUE()取第起始1行值:first_value(score,n) over(order by id)取第最后1行值:LAST_value(score,n) over(order by id)select id,first_value(score) over(order by id) fv,score from students; select id,last_value(score) over(order by id) fv,score from students;sum(...) over ...【功能】连续求和分析函数【参数】具体参示例【说明】Oracle分析函数NC示例:select bdcode,sum(1) over(order by bdcode) aa from bd_bdinfo【示例】1.原表信息: SQL> break on deptno skip 1 -- 为效果更明显,把不同部门的数据隔段显示。
oralce函数

oralce函数Oracle是一种关系数据库管理系统,它使用了一种名为Oracle数据库的数据库管理系统。
Oracle是一种强大的工具,提供了许多内置函数,可以用于在数据库中进行各种操作。
以下是一些常用的Oracle函数。
1.聚合函数-AVG:计算指定列的平均值。
-COUNT:计算指定列中非空数据的数量。
-SUM:计算指定列的总和。
-MAX:找到指定列的最大值。
-MIN:找到指定列的最小值。
2.字符串函数-CONCAT:将两个字符串连接成一个字符串。
-LOWER:将字符串转换为小写。
-UPPER:将字符串转换为大写。
-LENGTH:计算字符串的长度。
-SUBSTR:返回一个字符串的子字符串。
3.数值函数-ROUND:将一个数值四舍五入到指定的小数位数。
-CEIL:向上取整,返回不小于指定数值的最小整数。
-FLOOR:向下取整,返回不大于指定数值的最大整数。
-ABS:返回指定数值的绝对值。
-MOD:返回两个数值的余数。
4.日期和时间函数-SYSDATE:返回当前日期和时间。
-ADD_MONTHS:在指定日期上增加指定的月份。
-TRUNC:截断日期或时间到指定的精度。
-MONTHS_BETWEEN:计算两个日期之间的月数差。
-TO_CHAR:将日期转换为指定格式的字符串。
5.条件函数-DECODE:根据条件返回不同的值。
-CASE:根据条件执行不同的操作。
-NVL:如果给定的表达式为NULL,则将其替换为指定的值。
-NULLIF:如果两个表达式的值相等,则返回NULL。
6.分析函数-ROW_NUMBER:为每一行分配一个唯一的数字。
-RANK:为每一行分配一个排名,如果有并列的值,则排名相同。
-DENSE_RANK:为每一行分配一个排名,如果有并列的值,则排名可以重复。
-LEAD:返回指定行后的值。
-LAG:返回指定行前的值。
上述函数只是Oracle提供的一小部分功能,Oracle还提供了许多其他有用的函数。
oracle之分析函数

Oracle 分析函数的使用Oracle 分析函数使用介绍分析函数是oracle816引入的一个全新的概念,为我们分析数据提供了一种简单高效的处理方式.在分析函数出现以前,我们必须使用自联查询,子查询或者内联视图,甚至复杂的存储过程实现的语句,现在只要一条简单的sql语句就可以实现了,而且在执行效率方面也有相当大的提高.下面我将针对分析函数做一些具体的说明.今天我主要给大家介绍一下以下几个函数的使用方法1. 自动汇总函数rollup,cube,2. rank 函数, rank,dense_rank,row_number3. lag,lead函数4. sum,avg,的移动增加,移动平均数5. ratio_to_report报表处理函数6. first,last取基数的分析函数基础数据1. 使用rollup函数的介绍select area_code,sum(local_fare) local_farefrom ttgroup by area_codeunion allselect'合计' area_code,sum(local_fare) local_fare from tt;1 0 UNION-ALL2 1 SORT (GROUP BY) (Cost=5 Card=1309 Bytes=24871)3 2 TABLE ACCESS (FULL) OF 'T' (Cost=2 Card=1309 Bytes=24871)4 1 SORT (AGGREGATE)5 4 TABLE ACCESS (FULL) OF 'T' (Cost=2 Card=1309 Bytes=17017)Statistics----------------------------------------------------------0 recursive calls0 db block gets6 consistent gets0 physical reads0 redo size561 bytes sent via SQL*Net to client503 bytes received via SQL*Net from client2 SQL*Net roundtrips to/from client1 sorts (memory)0 sorts (disk)6 rows processed下面是使用分析函数rollup得出的汇总数据的例子SQL> select nvl(area_code,'合计') area_code,sum(local_fare) local_fare2 from tt3 group by rollup(area_code);4 /AREA_CODE LOCAL_FARE---------- --------------5761 54225413.045762 52039619.605763 69186545.025764 53156768.465765 104548719.19合计333157065.31从上面的结果中我们很容易发现,每个统计数据所对应的行都会出现null,我们如何来区分到底是根据那个字段做的汇总呢,这时候,oracle的grouping函数就粉墨登场了.如果当前的汇总记录是利用该字段得出的,grouping函数就会返回1,否则返回01 select decode(grouping(area_code),1,'all area',to_char(area_code))area_code,2 decode(grouping(bill_month),1,'all month',bill_month) bill_month,3 sum(local_fare) local_fare4 from t5 group by cube(area_code,bill_month)6* order by area_code,bill_month nulls last07:07:29 SQL> /AREA_CODE BILL_MONTH LOCAL_FARE---------- --------------- --------------5761 200405 13060.435761 200406 13318.935761 200407 13710.275761 200408 14135.785761 all month 54225.415762 200405 12643.795762 200406 12795.065762 200407 13224.305762 200408 13376.475762 all month 52039.625763 200405 16649.785763 200406 17120.525763 200407 17487.495763 200408 17928.765763 all month 69186.545764 200405 12487.795764 200406 13295.195764 200407 13444.095764 200408 13929.695764 all month 53156.775765 200405 25057.745765 200406 26058.465765 200407 26301.885765 200408 27130.645765 all month 104548.72all area 200405 79899.532. rank函数的介绍问题2.我想查出这几个月份中各个地区的总话费的排名.为了将rank,dense_rank,row_number函数的差别显示出来,我们对已有的基础数据做一些修改,将5763的数据改成与5761的数据相同.1 update t t1 set local_fare = (2 select local_fare from t t23 where t1.bill_month = t2.bill_month4 and _type = _type5 and t2.area_code = '5761'6) where area_code = '5763'SQL> /update tt t1 set local_fare =(select local_fare from tt t2where t1.bill_month = t2.bill_monthand _type = _typeand t2.area_code ='5761')where area_code ='5763';8 rows updated.Elapsed: 00:00:00.01我们先使用rank函数来计算各个地区的话费排名.SQL> select area_code,sum(local_fare) local_fare,2 rank() over (order by sum(local_fare) desc) fare_rank3 from t4 group by area_codeselect area_code,sum(local_fare) local_fare,rank() over (order by sum(local_fare)desc) fare_rankfrom ttgroup by area_codeAREA_CODE LOCAL_FARE FARE_RANK---------- -------------- ----------5765 104548.72 15761 54225.41 25763 54225.41 25764 53156.77 45762 52039.62 5Elapsed: 00:00:00.01我们可以看到红色标注的地方出现了,跳位,排名3没有出现下面我们再看看dense_rank查询的结果.select area_code,sum(local_fare) local_fare,dense_rank() over (order by sum(local_fare)desc) fare_rankfrom ttgroup by area_code/AREA_CODE LOCAL_FARE FARE_RANK---------- -------------- ----------5765 104548.72 15761 54225.41 25763 54225.41 25764 53156.77 3 这是这里出现了第三名5762 52039.62 4Elapsed: 00:00:00.00在这个例子中,出现了一个第三名,这就是rank和dense_rank的差别,rank如果出现两个相同的数据,那么后面的数据就会直接跳过这个排名,而dense_rank则不会,差别更大的是,row_number哪怕是两个数据完全相同,排名也会不一样,这个特性在我们想找出对应没个条件的唯一记录的时候又很大用处select area_code,sum(local_fare) local_fare,row_number() over (order by sum(local_fare)desc) fare_rankfrom ttgroup by area_code/AREA_CODE LOCAL_FARE FARE_RANK---------- -------------- ----------5765 104548.72 15761 54225.41 25763 54225.41 35764 53156.77 45762 52039.62 5在row_nubmer函数中,我们发现,哪怕sum(local_fare)完全相同,我们还是得到了不一样排名,我们可以利用这个特性剔除数据库中的重复记录.这里的几个例子是为了说明这三个函数的基本用法。
Oracle自定义聚合函数-分析函数

自定义聚合函数,分析函数--from GTA Aaron最近做一数据项目要用到连乘的功能,而Oracle数据库里没有这样的预定义聚合函数,当然利用数据库已有的函数进行数学运算也可以达到这个功能,如:select exp(sum(ln(field_name))) from table_name;不过今天的重点不是讲这个数学公式,而是如何自己创建聚合函数,实现自己想要的功能。
很幸运Oracle 允许用户自定义聚合函数,提供了相关接口,LZ研究了下,留贴共享。
首先介绍聚合函数接口:用户可以通过实现Oracle的Extensibility Framework中的ODCIAggregate interface 来创建自定义聚合函数,而且自定义的聚合函数跟内建的聚合函数用法上没有差别。
通过实现ODCIAggregate rountines来创建自定义的聚合函数。
可以通过定义一个对象类型(Object Type),然后在这个类型内部实现ODCIAggregate 接口函数(routines),可以用任何一种Oracle支持的语言来实现这些接口函数,比如C/C++, JAVA, PL/SQL等。
在这个Object Type定义之后,相应的接口函数也都在该Object Type Body内部实现之后,就可以通过CREATE FUNCTION语句来创建自定义的聚合函数了。
每个自定义的聚合函数需要实现4个ODCIAggregate 接口函数,这些函数定义了任何一个聚合函数内部需要实现的操作:1. 自定义聚合函数初始化操作,从这儿开始一个聚合函数。
初始化的聚合环境(aggregation context)会以对象实例(object type instance)传回给oracle.static function ODCIAggregateInitialize(var IN OUT agg_type ) return number 2. 自定义聚合函数,最主要的步骤,这个函数定义我们的聚合函数具体做什么操作,self 为当前聚合函数的指针,用来与前面的计算结果进行关联。
Oracle之分析函数

Oracle之分析函数⼀、分析函数 1、分析函数 分析函数是Oracle专门⽤于解决复杂报表统计需求的功能强⼤的函数,它可以在数据中进⾏分组然后计算基于组的某种统计值,并且每⼀组的每⼀⾏都可以返回⼀个统计值。
2、分析函数和聚合函数的区别 普通的聚合函数⽤group by分组,每个分组返回⼀个统计值,⽽分析函数采⽤partition by分组,并且每组每⾏都可以返回⼀个统计值。
3、分析函数的形式 分析函数带有⼀个开窗函数over(),包含分析⼦句。
分析⼦句⼜由下⾯三部分组成: partition by :分组⼦句,表⽰分析函数的计算范围,不同的组互不相⼲; ORDER BY:排序⼦句,表⽰分组后,组内的排序⽅式; ROWS/RANGE:窗⼝⼦句,是在分组(PARTITION BY)后,组内的⼦分组(也称窗⼝),此时分析函数的计算范围窗⼝,⽽不是PARTITON。
窗⼝有两种,ROWS和RANGE; 使⽤形式如下:OVER(PARTITION BY xxx PORDER BY yyy ROWS BETWEEN rowStart AND rowEnd) 注:窗⼝⼦句在这⾥我只说rows⽅式的窗⼝,range⽅式和滑动窗⼝也不提。
⼆、OVER() 函数 1、sql 查询语句的 order by 和 OVER() 函数中的 ORDER BY 的执⾏顺序 分析函数是在整个sql查询结束后(sql语句中的order by的执⾏⽐较特殊)再进⾏的操作, 也就是说sql语句中的order by也会影响分析函数的执⾏结果: [1] 两者⼀致:如果sql语句中的order by满⾜分析函数分析时要求的排序,那么sql语句中的排序将先执⾏,分析函数在分析时就不必再排序; [2] 两者不⼀致:如果sql语句中的order by不满⾜分析函数分析时要求的排序,那么sql语句中的排序将最后在分析函数分析结束后执⾏排序。
2、分析函数中的分组/排序/窗⼝分析函数包含三个分析⼦句:分组(partition by),排序(order by),窗⼝(rows/range)窗⼝就是分析函数分析时要处理的数据范围,就拿sum来说,它是sum窗⼝中的记录⽽不是整个分组中的记录,因此我们在想得到某个栏位的累计值时,我们需要把窗⼝指定到该分组中的第⼀⾏数据到当前⾏, 如果你指定该窗⼝从该分组中的第⼀⾏到最后⼀⾏,那么该组中的每⼀个sum值都会⼀样,即整个组的总和。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
自定义聚合函数,分析函数
--from GTA Aaron
最近做一数据项目要用到连乘的功能,而Oracle数据库里没有这样的预定义聚合函数,当然利用数据库已有的函数进行数学运算也可以达到这个功能,如:
select exp(sum(ln(field_name))) from table_name;
不过今天的重点不是讲这个数学公式,而是如何自己创建聚合函数,实现自己想要的功能。
很幸运Oracle 允许用户自定义聚合函数,提供了相关接口,LZ研究了下,留贴共享。
首先介绍聚合函数接口:
用户可以通过实现Oracle的Extensibility Framework中的ODCIAggregate interface 来创建自定义聚合函数,而且自定义的聚合函数跟内建的聚合函数用法上没有差别。
通过实现ODCIAggregate rountines来创建自定义的聚合函数。
可以通过定义一个对象类型(Object Type),然后在这个类型内部实现ODCIAggregate 接口函数(routines),可以用任何一种Oracle支持的语言来实现这些接口函数,比如C/C++, JAVA, PL/SQL等。
在这个Object Type定义之后,相应的接口函数也都在该Object Type Body内部实现之后,就可以通过CREATE FUNCTION语句来创建自定义的聚合函数了。
每个自定义的聚合函数需要实现4个ODCIAggregate 接口函数,这些函数定义了任何一个聚合函数内部需要实现的操作:
1. 自定义聚合函数初始化操作,从这儿开始一个聚合函数。
初始化的聚合环境
(aggregation context)会以对象实例(object type instance)传回给oracle.
static function ODCIAggregateInitialize(var IN OUT agg_type ) return number 2. 自定义聚合函数,最主要的步骤,这个函数定义我们的聚合函数具体做什么操作,self 为
当前聚合函数的指针,用来与前面的计算结果进行关联。
这个函数用来遍历需要处理的
数据,被oracle重复调用。
每次调用的时候,当前的aggreation context 和新的(一组)值会作为传入参数。
这个函数会处理这些传入值,然后返回更新后的aggregation context. 这个函数对每一个NON-NULL的值都会被执行一次。
NULL值不会被传递个聚合函数。
member function ODCIAggregateIterate(self IN OUT agg_type ,value IN varchar2) return number
3. 用来合并两个聚合函数的两个不同的指针对应的结果,用户合并不同结果结的数据,特别
是处理并行(parallel)查询聚合函数的时候.
这个函数用来把两个aggregation context整合在一起,一般用来并行计算中(当一个函数被设置成enable parallel 处理的时候)。
member function ODCIAggregateMerge (self IN OUT agg_type, value IN agg_type) return number
4. 终止聚合函数的处理,返回聚合函数处理的结果.
这个函数是Oracle调用的最后一个函数。
它接收aggregation context作为参数,返回最后的aggregate value.
member function OCDIAggregateTerminate(self IN agg_type,returnValue OUT varchar2,flags IN number)
下一步我们就根据这些接口来创建连乘聚合函数,
首先创建OBJECT TYPE:
CREATE OR REPLACE TYPE sermult_context AS OBJECT(
multvalue NUMBER, -- 保存连乘后的值
--(该步骤是必须的)初始化函数,必须要实现的方法,用于在聚合运算的最开始部分,初始化上下文环境
static FUNCTION ODCIAggregateInitialize(serm IN OUT sermult_context) RETURN NUMBER,
--(该步骤是必须的)迭代运算函数,oracle依据该函数进行迭代运算,第一个参数为聚合运算的上下文,
--第二个参数为当前需要处理的值,可以为number varchar2等类型,
--在迭代过程中,如果当前值为null,则忽略该次迭代
member FUNCTION ODCIAggregateIterate(self IN OUT sermult_context,currvalue IN NUMBER) RETURN NUMBER,
--(该步骤是必须的,但是在执行过程中,oracle会有选择的执行该步骤)该函数用于合并两个上下文到一个上下文中,
--在并行和串行环境下均有可能发挥作用
member FUNCTION ODCIAggregateMerge(self IN OUT sermult_context, value IN sermult_context)RETURN NUMBER,
--(该步骤是必须的)该函数在聚合运算的最后一步运行,用于对结果进行处理并返回处理结果,
--第一个参数为上下文,第二个参数为返回值,可以为number,varchar2等类型
--第三个参数为标识位
MEMBER FUNCTION ODCIAggregateTerminate(self IN sermult_context,returnValue OUT NUMBER,flags IN NUMBER) RETURN NUMBER )
接下来实现接口函数功能,
create or replace type body sermult_context is
static function ODCIAggregateInitialize(serm IN OUT sermult_context) return number is
begin
serm := sermult_context(1);
return ODCIConst.Success;
end;
member function ODCIAggregateIterate(self IN OUT sermult_context,currvalue IN NUMBER) return number is
begin
self.multvalue := self.multvalue*currvalue;
return ODCIConst.Success;
end;
member function ODCIAggregateMerge(self IN OUT sermult_context, value IN sermult_context) return number is
BEGIN
self.multvalue := self.multvalue*value.multvalue;
RETURN ODCIConst.Success;
end;
member function ODCIAggregateTerminate(self IN sermult_context, returnValue OUT number, flags IN number) return number is
begin
returnValue := self.multvalue;
return ODCIConst.Success;
end;
END;
最后一步激动人心的时刻,创建连乘聚合函数,
CREATE FUNCTION SerMult (input NUMBER) RETURN NUMBER PARALLEL_ENABLE AGGREGATE USING sermult_context;
到此连乘聚合函数SerMult创建完成,下一步我们来进行测试,
WITH T1 AS
(
SELECT 5.5 A,'b' as b FROM DUAL
UNION ALL
SELECT 2.2 A,'b' as b FROM DUAL
UNION ALL
SELECT 3.3 A,'c' as b FROM DUAL
UNION ALL
SELECT 4.4 A,'c' as b FROM DUAL
)
SELECT b, SerMult(A) as SerM FROM T1 group by b
没有问题,我们再来用exp(sum(ln(field_name))) 来计算看下结果,
SELECT b, exp(sum(ln(a))) as SerM FROM T1 GROUP BY b
可见这种算法存在一定的精度问题。
前面提过自定义的聚合函数和内建的用法上差不多,那也就是说自定义的聚合函数也可作为分析函数,那么我们测试一下是否可行,
SELECT A,b,SerMult(A) OVER (PARTITION BY b) AS SerM FROM T1
看样子是没有问题的,一举两得哈。