spss整理
计算机专业应用-第一章 SPSS入门与数据整理

二、数据文件的编辑
在SPSS中,数据文件的编辑、整理等功能被集中 在了Data和Edit两个菜单项中 。
1 数据的增删——类似Excel操作; 2 数据的整理——排序、行列互换 …
3 数据的算术处理——加权、个数清 点、运算和新变量生成、重新赋值、 缺失值替代
三、给变量值排序
三、给变量值排序
四 、给变量值排名次
二、SPSS的 应用
很有用 很有用
4天就可学 会!
这种精英 还不多呢!
三、 SPSS的特点——老版本
1、 操作简便
界面非常友好,除了数据录入及部分命令程序等少数输入工作需要键盘键入 外,大多数操作可通过鼠标拖曳、点击“菜单”、“按钮”和“对话框”来完成。
三、 SPSS的特点——老版本
2、 编程方便
例、某克山病区测得11例克山病患者与13名健康人的血磷 值(mmol/L)如下, 问该地急性克山病患者与健康人的血 磷值是否不同
患者:0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人:0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87
三、 SPSS的特点——新版本
1、 操作简便
界面非常友好,除了数据录入及部分命令程序等少数输入工作需要键盘键入 外,大多数操作可通过鼠标拖曳、点击“菜单”、“按钮”和“对话框”来完成。
(1) 定义变量
(2)输入数据
(3) 保存数据
(4) 数据分析
(4) 数据分析
(5) 图形绘制
(5) 图形绘制
单击保存类型列表框,可 以看到SPSS所支持的各种数 据类型,有DBF、FoxPro、 EXCEL、ACCESS等,这里 我们仍然将其存为SPSS自己 的数据格式(*.sav文件)。
SPSS期末考试整理

●一。
变量的赋值1.乘方(**),例如二的三次方:2**32.不同规则的赋值:转换→计算变量(如果),每一个规则的赋值都要重新进行此步骤(但注意每一遍的变量名都不变,并且他都会问你要不要替换成新的变量,你选是就行了)3.不同规则的赋值:(1)转换→重新编码为不同变量:输入变量,输出变量,要点击“变化量”才可保存输出变量→新值和旧值:值(直接选取取值)、范围(最大到最小的范围,包含端点值),点击“添加”成功保存新值和旧值→所有不同取值规则都完成后点击继续、确定,则在变量视图多出一个新变量(2)若不想包含端点值,可以采取小数的方式变换,eg. 899.9(小数位比该变量属性的小数位多一位就行了)(3)这种要先把BMI按照男女分开,然后再分组的,可以在对话框中点击“如果”选项进行设置,并且要分别对男女进行上述操作(一共做两遍)。
二。
离散化1可视离散化:转换→可视分箱,分割点:所以想生成几组,就定义几个分割点;填写第一个分割点的时候就必须填写最小值;一定要选中上端点排除。
三。
排序1.转换→自动重新编码:不分组,从头到尾排序2.转换→个案排秩(1)多层次数据:基于A变量对B变量进行排序。
(例如,基于职称对收入进行排序,就是不同职称各自组内排工资的高低)(2)设置秩1;绑定值四。
时间序列:转换→变动值五。
查找与计数:转换→对个案内的值计数(查找“基本工资800-900女职工”,生成新变量,满足这个条件的标为1,不符合这个标准的标为0,男职工标为缺失。
范围:包含上限下限)●六。
数据→个案排序:把变量顺序完全按照你想要的标准排序,所有的变量顺序都会改变七。
拆分文件:要分男女进行数据统计:数据→拆分文件→比较组/按组输出,分组依据。
不分男女进行数据统计:数据→拆分文件→分析所有个案八。
选择个案(例如只选择三年级的变量进行分析):数据→选择个案→如果条件满足:如果;随机个案样本;基于时间或个案范围;使用过滤变量(例如要把身高为缺失值和值为0的剔除)→输出:过滤(不符合条件的数据会画上“/”,原始数据并未删除);将选定个案复制到新数据集(形成一个新的SPSS数据文件,原始数据并未删除);删除未选定的个案(删除原始数据,不建议使用)→之后在分析的时候就只会分析三年级的变量。
SPSS数据的整理与分析
数据的整理与分析chy一、数据收集-问卷星1、检查与剔除不合格问卷,比如答题时间太短、年龄不符合、问卷填写不完整等。
2、应答率/回收率:是指定的或者抽中的需要作答的对象中,最终完成作答的百分比。
3、合格率:合格数量/作答数量。
4、一般的,访问问卷的回收率最高,回收率一般要求在90%以上;邮寄问卷的回收率低,回收率在50%左右就可以了;发送式自填问卷的回收率一般,回收率要求在67%以上。
5、如果不高尽量不要写入,反而起反作用。
6、可以运用问卷星中的图与表描述,直观描述。
二、数据整理-Excel1、结果导出方式:文本、数字、分数,保存excel原版。
2、再另存一版你用于SPSS分析的表格。
3、注意反向计分的题目。
4、如果量表分为几个维度,可以单独列出来进行分析。
(如我发到群里的表格,可以用总分与其他条目分析,也可以用这个量表包括的几个维度分别与其他条目分析,观察其关联)。
5、如果分不清楚,可以标注一下变量的类型,如分类变量还是数据变量(如我的Excel的第二行,但是导入到SPSS中时需要删除)。
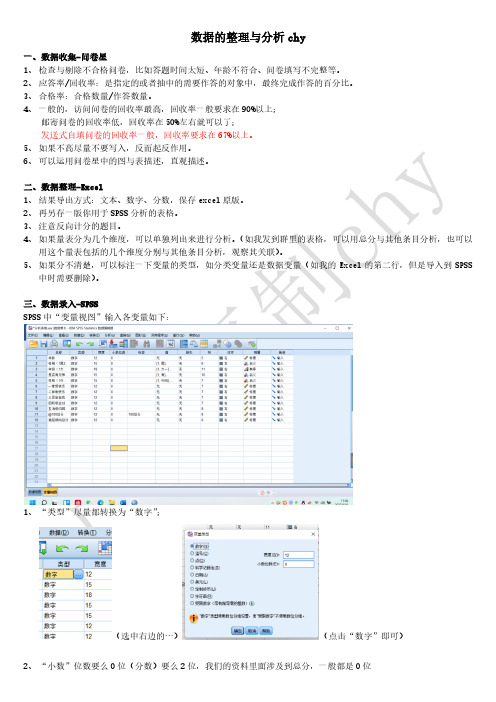
三、数据录入-SPSSSPSS中“变量视图”输入各变量如下:1、“类型”尽量都转换为“数字”;(选中右边的…)(点击“数字”即可)3、“值”的标记:(用于计数资料的标记,在结果中易于观察)点击…,分别输入对应的值和代表的标签,点击“添加”和确定即可4、“测量”分为三类:(1)标度:指计数资料,如年龄、108总分等;(2)有序:指等级资料,如年级等;(3)名义:指计数资料,如性别、性格等。
5、如何把计数资料转换为计量资料,即赋值(以“拖延总分为例”)步骤:(注意填写名称和标签,点击“变化量”) ----点击“旧值和新值”进行赋值:0-20赋值为1:--添加--20.1-40赋值为2:--添加--40.1-60赋值为3:--添加--然后“变量视图”最后一行就会出现新的变量“拖延分数三分类”,可以把“名义”改为“有序”,也可不改。
spss整理笔记

1、 spss的三种输出结: 表格格式格式文本格式标准图与交互图果2、变量名的定义与保留字不同,同时变量名不能一数字开头。
变量名不能与spss保留字相同, spss的保留字有ALL 、 END 、 BY 、EQ 、 GE 、 GT 、LE 、 LT 、 NE 、NOT 、 OR 、TO 、WITH 。
3、字符型:字符型数据的默认显示宽度为8 个字符位,系统不区分变量名中的大小写字母,并且不能进行数学运算。
注意:在输入数据时不应输入引号,否则双引号将会作为字符型数据的一部分。
4、(1)定类尺度(Nominal Measurement):定类尺度是对事物的类别或属性的一种测度,按照事物的某种属性对其进行分类或分组。
离散型特点:其值仅代表了事物的类别和属性,即能测度类别差异,不能比较各类之间的大小,所以各类之间没有顺序和等级。
对定类尺度的变量只能计算频数和频率。
在spss中,能适用定类尺度的数据可以是数值型,也可以是字符型变量。
使用定类变量对事物进行分类时,必须符合穷尽原则和互斥原则。
(2)定序尺度( Ordinal Measurement ):定序尺度是对事物之间的等级或顺序差别的一种测度,可比较优劣或排序。
离散型特点:由于定序变量只能侧度类别之间的顺序,无法测出类别之间的准确差值,即测量数值不代表绝对的数量大小,所以其测量结果只能排序,不能进行运算。
(3)定矩尺度( Interval Measurement ):定矩尺度是对事物类别或次序之间间距的测度。
特点:不仅能将事物区分为不同类型并进行排序,而且可能准确指出类别之间的差距是多少;定矩变量通常以自然或物理单位为计量尺度,因此测量结果往往表现为数值,所以计量结果可以进行加减运算。
(4)定比尺度( Scale Measurement ):定比尺度是能够测算两个测度值之间比值的一种计量尺度,它的测量结果同定距变量一样表现为数值。
特点:定比变量是测量尺度的最高水平,它除了具有其他三种测量尺度的全部特点外,还具有可计算两个测度之间比值的特点,因此它可以进行加、减、乘、除运算,而定矩变量值可进行加减运算。
SPSS数据文件的整理

Step02:选择排序变量
在左侧的候选变量列表框中选择主排序变量DQ,单击右 向箭头按钮,将变量选择进入【Sort by(排序依据)】列表 框中。
Step03:选择排序类型
3. 实例内容:固定资产 ห้องสมุดไป่ตู้资文件的合并
已知2-5-1.sav、2-5-2.sav和2-5-3.sav中的数据是北京、 天津、河北等省市在2005年部分行业的固定投资额 (亿元)数据,请完成以下问题。 问题一:将2-5-1.sav和2-5-2.sav的数据文件纵向合并。 问题二:将2-5-2.sav和2-5-3.sav的数据文件横向合并。
Step03:新变量命名
从左侧的候选变量列表框中可以选择一个变量,应用它的值作为 转 置 后 新 变 量 的 名 称 。 此 时 , 选 择 该 变 量 进 入 【Name Variable(名称变量)】列表框内即可。如果用户不选择变量命名, 则系统将自动给转置后的新变量赋予Var001、Var002…的变量名。
Step04:单击【OK】按钮,操作结束。
注意:数据文件转置后,数据属性的定义都会丢失,因此用户要 慎重选择本功能。
2.实例内容:国家财政分项目收入数据(2-4.sav)
Step01:选定对话框
Step02:选择转置变量
Step03:新变量命名
Step04:完成操作
2.3.3文件合并:固定资产投资
2.实例内容:地区生产总值分析
地区生产总值是指某地区在一定时间内的国内生产总 值,它可以作为衡量该地区经济发展的重要综合指 标。随书光盘中的数据2-3.sav列出了2005年我国部 分省份的地区生产总值及第一产业、第二产业和第 三产业的生产总值,请根据这些数据分析不同省份 经济发展状况的差异性。
章spss的数据整理

Statistics 身 高( 厘 米) N Std. Error of Mean Std. Deviation Variance Range Minimum Maximum Valid Missing
12 0 1.78306 6.17669 38.152 18.00 158.00 176.00
5
注意统计教练 的帮助功能
调用EXCEL,把当前 数据输出到EXCEL中
在统计结果上,右击鼠标, 选择“Results Coach”
输出统计结果格式的修改
对于表格和图标,都可以在其之上双击 鼠标,进行各种修改。
a Coefficients Coefficientsa
Unstandardized UnstandardizedStandardized Standardized Coefficients Coefficients Coefficients Coefficients Model B Model B Std. Error Std. Error Beta Beta t 1 (Constant) -87.368 61.680 -1.416 1 (Constant) -87.368 61.680 粮 食 平均 单 价 213.423 73.278 .243 2.913 粮 食平 均 单 价 213.423 .038 73.278 .243 人 均 收入 .352 .767 9.185
2
数据的分类汇总
分组的标志 汇总的变量 如何分别统 计男生和女 生的平均身 高?
3
数据的拆分
分组统计结果输出 在同一表格中
如何按照性 之后的统计 分组统计结果输出 别对身高进 分析都是分 在不同表格中 行统计分析 别对男生和 ? 女生展开。
spss第二讲数据整理data、transform
38
SPSS统计软件
变量清单
将汇总变量 加入当前数
据 替代当前数
据文件 创建汇 总文件
分组变量
汇总统计 量
汇总统计量清单
39
SPSS统计软件 文件级数据整理 4.文件的拆分
操作提示:Data →Split File…
2)按班号对技能成绩大于60分的成绩进行汇总, 另存为新的数据文件。
3)以姓名定义新变量名,进行行列转置,另存为“转置.sav”。
48
SPSS统计软件
数据管理练习
3、数据:新医学生成绩.sav 要求:1)描述不同班级(号)学生的妇科和儿科平均成绩与标准差,结果保 存为“新成绩.spv”。 2)选出内科成绩大于18的学生,描述其外科成绩平均水平,结果保存为 “外科成绩.spv”。
Recode可以用于字符型变量
23
SPSS统计软件
演示:将数据transform.sav中字符型“city”变量转化为数 值型变量“newcity”。(按照字母排序)
24
SPSS统计软件 变量级数据整理:4.Rank Cases
编秩变量 分组变量
操作提示: Transform →Rank Cases
SPSS统计软件
第二讲 SPSS数据整理
课前复习
1
SPSS统计软件
SPSS的特点
SPSS操作界面----三个窗口 SPSS的保存
(新医学生成绩)
2
SPSS统计软件
SPSS数据格式
1.一条记录占一行(反映某个研究对象具体特征的一组观测值。 ) 2.一个变量占一列(测量指标) 3.SPSS数据分析时特殊数据格式(配对设计、重复测量资料数据) 最终的数据集应当包含原始数据的所有信息
SPSS统计分析数据转换与整理
2020/10/11
36
第五节 分类汇总
1. 分类汇总的目的
分类汇总是按照某分类变量进行分类汇总 计算。
例如:某企业希望了解本企业不同学历职 工的基本工资上是否存在较大差距。最简单 的做法就是分类汇总,即将职工按学历进行 分类,分别计算不同学历职工的平均工资, 然后可对平均工资进行比较。
(2)复合条件表达式
又称逻辑表达式,是由逻辑运算符号、圆括
号和简单条件表达式等组成的式子。其中,逻
辑运算符号包括&或AND(并且)、|或OR (或者)、~或NOT(非)。NOT的运算优先 级最高,其次是AND,最低是OR。可以通过圆 括号改变运算的优先级。(nl<=35)and not (zc<3)
2020/10/11
18
03-2 变量计算的应用举例
利用职工基本情况数据,依据职称级别计 算实发工资,再按职称1至4将实发工资 分别上调50%,30%,20%,10%。
2020/10/11
19
第三节 数据选取
数据选取就是根据分析的需要,从已收 集到的大批量数据(总体)中按照一定 的规则抽取部分数据(样本)参与分析 的过程,通常也称为抽样。
2020/10/11
13
4.SPSS函数
SPSS函数是事先编好并存储在SPSS软件 中,能够实现某些特定计算任务的一段计 算机程序。这些程序都有各自的名字称为 函数名。执行这些程序段得到的计算结果 称为函数值。 函数书写的具体形式为:函数名(参数)
2020/10/11
14
其中,函数名是SPSS已经规定好的,参数 可以是常量(字符型常量应用引号括起来), 也可以是变量或算术表达式。参数可能是一个, 也可能是多个,各参数之间用逗号分隔。
SPSS数据整理
率(0-100%);
• (14)Percentage outside:先确定1个下 限,再确定1个上限,求数值在该区间外的 例数占总例数的比率(0-100%);
• (15)Fraction inside:先确定1个下限, 再确定1个上限,求数值在该区间内的例数 占总例数的比率(0-1);
结果
• 原文件中的行变成新文件中的列,原文件中 的列变成新文件中的行;
• 原文件中的变量变成新文件中的个案,原文 件中的个案变成新文件中的变量
• 原文件中未被选定的变量将在新文件中丢失
3 数据的分组汇总
选Data菜单的Aggregate...命令项
• 类组(Break Group): 分类变量的不同取值 将原始数据分成若干组.如: origin=1、2、3 分别代表美国、欧洲和日本,分成三个类 组
例6 :在cars.sav文件
• 标出美国产的汽车马力在135以下的
• 注意:
– Count 在标示数据的过程中,不能对同时满足 多个取值条件的记录进行标示,只能对满足某 一个条件的变量进行标示。
四、变量的重新赋值
• 选Transform菜单的Recode命令项, • 该过程用于将原变量按照某种一一对应的
(7)Number of cases:合计类组的观察例数; (8)Sum of values :求类组所有观察值的和。 (9)Percentage above:先确定1个数值,求大于该
数值的所有例数占总例数的百分比(0-100%); (10)Percentage below:先确定1个数值,求小于
• 选Data菜单的Select Cases...命令项,
(1)All cases:表示所有的观察例数都被选择,该 选项可用于解除先前的选择;
SPSS统计数据整理与分析
广西工学院实验报告用纸F r e q u e n c y— — 装订线— —F r e q u e n c y图 1-3分析:首先,本次被调查的科目是微积分A1的期末成绩且总学生数是74人,其中信管091班为38位学生,信管092班为36位学生。
图1-1表明信管091班的平均分(64分)高于信管092班的平均分(56.5分),但信管091班的标准差却高于信管092班。
信管091班的最低分为27分,信管092班的为33分,同时,信管091班的最高分为90分,信管092班的为83分。
图 1-2表明信管091班直接重修的人数为4人,需要补考的人数为9人。
图1-3表明信管092班直接重修的人数为7人,需要补考的人数为12人。
同时,信管091班很信管092班的微积分A1期末成绩均呈平峰分布(两个峰度统计量分别为-0.816和-1.238)。
且信管092班更平峰。
综上所述:信管091班的微积分A1的成绩总体要好于信管092班。
意见:两个班需要在学习方面多作交流,建立学习小组,每小组3到4个人,每小组都要有一个学习较优秀的同学,同时要有个学习一般的同学和学习较差的同学,让学习较优秀的同学带领学习一般的同学和学习较差的同学定期的一起进行学习交流。
尽量把学习差的同学提升到一般,把学习一般的同学提升到较好的水平,顺序渐进,逐步提升。
(1)分析:用人单位对该校毕业生工作表现最为满意。
对外语水平方面最不满意。
学校应该重视外语水平的教学改革,以跟上时代的步伐,尽快适应社会的改革发展需要。
(2)分析:用人单位对该校毕业生外语水平方面的满意程度差别最大,产生的原因可能是该校不重视外语水平的教学,或是学生学习外语的积极性偏低,也可能是学校在招生时忽略对外语水平的要求。
(3)分析:社会对三个学院的毕业生工作表现和专业水平方面的满意程度比较一致,对三个学院毕业生的外语水平的满意程度较差。
学校应加大改革外语教学,加大力度提升外语教学水平,重视学生综合素质的发展。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Spss知识点1.SPSS:①Statistical Package for the Social Sciences,即“社会科学统计软件包”②Statistical Product and Service Solutions,意为“统计产品与服务解决方案”2.SPSS两个常用窗口:数据编辑窗口(功能:定义SPSS数据的结构、录入编辑和管理待分析的数据 .sav) 结果输出窗口(功能:显示管理SPSS统计分析结果、报表及图形 .spv)3.利用SPSS做数据分析的一般步骤:12①建立SPSS 数据文件(定义数据文件结构、录入修改和编辑待分析的数据)②分析数据(统计分析之前的数据预处理、统计分析和建模)③结果的说明和解释④数据和分析结果的保存4.SPSS数据文件的特点:①SPSS数据文件的扩展名是:.sav ②SPSS数据文件属于结构性数据文件(数据结构:变量名、数据类型、变量名标签、变量值标签、缺失值的定义、度量尺度以及数据的显示属性;在数据编辑窗口的变量视图Variable View中完成。
数据内容:待分析的具体数据;在数据编辑窗口的数据视图Date View中完成。
)5.SPSS数据的基本组织方式:①原始数据的组织方式(数据编辑窗口中一行称为一个个案,所有个案组成完整的SPSS数据。
一列称为一个变量,每个变量都有一个名字,称为变量名,它是访问和分析SPSS每个变量的唯一标识。
)②计数数据的组织方式(数据编辑窗口中一行为变量的一个分组。
所有行囊括了该变量的所有分组情况。
一列仍为一个变量,代表某个问题或某个特征方面以及相应的计数结果。
)6.变量名:是变量访问和分析的唯一标志。
7.变量命名原则:①首字符必须是字母或汉字,后面可以是任意字母、数字或除了“!”、“?”、“*”之外的任意字母或数字②长度应少于64个字符(32个汉字)③不能用下划线“_”、句号和圆点作为变量名的最后一个字符④SPSS的变量名不能与SPSS的保留字相同,如ALL、AND、WITH、OR等⑤同一文件中变量名必须惟一,不区分大小写。
8.数据类型是指每个变量取值的类型。
有数值型、字符型和日期型。
9.若字符型数据定义为数值型时,需要定义一个变量值标签。
10.变量值标签是对变量取值含义的解释说明信息,对于定类型和定序性数据尤为重要。
如定类(民族、性别)定序(收入的高中低)11.计量尺度又叫变量层次。
定距>定序>定类12.定类变量(定类尺度 Nominal Variable):①是最低层次的变量,变量取值只有类别属性之分,而无大小、程度之别。
②根据变量值,只能知道研究对象是相同或是不同。
从数学运算特征来看,只具有等于或不等于(=、≠)的性质。
例如:性别。
13.定序变量:①变量层次高于定类变量。
②变量取值除了有类别属性之外,还有等级、次序的差别,其数学特性除了(=、≠)之外,还有大于或小于(><)之分。
例如:文化程度、职称、态度等14.定距变量(定距尺度 Interval Variable):①变量层次高于定序变量。
②变量取值除了有类别、次序属性之外,取值之间的距离还可以用标准化的距离去量度。
其数学特性除了(=、≠;><)之外,还可以进行加或减(+,-)。
例如:智商、成绩、收入等。
15.高层次的变量包含低层次变量的数学特征。
16.一个变量的层次并不是唯一的。
高层次的变量可以作为低层次变量来使用,但是会使资料的信息使用不完全,尽量按其最高层次来统计分析。
如:收入17.Spss支持的数据格式有SPSS文件格式、Excel文件格式、dbf文件格式、文本文件格式。
18.读取Excel文件:SPSS默认将Excel工作表中的全部数据读到SPSS数据编辑窗口中。
但也可在【range】后指定读取工作表中某个区域的数据。
如果Excel工作表文件第一行或指定区域的第一行上存储了变量名信息,则应选择【read variable name】,即以第一行文字信息作为变量名;否则不选,SPSS的变量名将自动取名为工作表中的单元格。
形成spss文件的方法:数据文件结构自定义输入、读取已经形成的execl文件。
19.纵向合并:(增加个案)应用情况:①两个带合并文件的内容合并起来有实际意义。
②在不同数据文件中,数据含义相同的数据项最好取相同的变量名,且数据类型也最好相同,可简化操作过程,有利于自动匹配。
含义不同的数据项最好取不同的名字。
20.横向合并:增加变量应用情况:①两个数据文件必须至少有一个名称相同的变量,该变量是两个数据文件横向拼接的依据,称为关键变量。
如职工号、商品序号。
②两个数据文件都必须事先按关键变量值的升序排序。
③不同数据文件中数据含义不同的数据项,变量名不应相同。
21.数据排序:①数据排序是整行数据排序,而不是只对某列变量排序。
②多重排序中指定排序变量的次序很关键。
排序时先指定的变量优于后制定的变量。
③数据排序以后原有数据的排列次序必然被打乱。
因此在时间序列的数据中,如果数据中没有标示时间的变量(如年份、月份、季度等),则应注意保留数据的原始排序。
22.变量计算:①变量计算是针对所有个案(或指定的部分个案)的,每条个案都有自己的计算结果。
②变量计算的结果应保存到一个指定变量中,该变量的数据类型应与计算结果的数据类型相一致。
23.分类汇总按照某分类变量进行分类计算。
24.数据分组:就是根据统计分析的需要,将数据按照某种标准重新划分为不同的组别。
25.统计分组的原则:(1)完备性原则(穷尽性原则)所有单位在分组后都要各有其所,不能被遗漏。
(2)互斥性原则组与组之间有明确的界限,每个单位只能归为一组,不能同时归为两组或两组以上。
26.定类变量(品质分组)定序变量(变量分组)定距变量:离散变量单项式分组连续变量(按理论取值)组距式分组27.单项式分组:以一个具体的变量值作为一组。
适用范围:离散变量;变量值变动范围小。
如:居民家庭按家庭成员数量分组。
28.组距式分组:以一个区间的变量值为一组。
适用条件:变量值变动范围较大,连续变量、离散变量均可(变量值较多的情况下)29.数据计数:①变量值相同,可以一块写。
②变量值不同,加一个if条件,一个一个的定义变量。
30.加权处理:加权变量的过程本质是数据复制。
74 单价为加权变量,销售量为权数。
通过加权处理,可以达到将数据编辑窗口中的计数数据还原为原始数据的目的。
一旦指定了加权变量,在以后的分析中加权就是一直有效的,知道取消为止。
31.数据拆分与排序的区别:数据拆分不仅是按指定变量对数据进行简单排序,更重要的是根据指定变量对数据进行分组,它将为以后所进行的分组统计分析提供便利。
32.定类变量只能用于条形图或饼图,一般用饼图。
33.定类变量不能计算平均值。
34.若变量以分组做频数分析时应先加权。
35.基本描述统计量:集中趋势、离散程度、分布形态。
36.低层次数据的测度值适用于高层次的测量数据,但高层次数据的测度值并不适用于低层次的测量数据。
37.数据选取:38.组距分组的编制:(1)组数和组距 组数:,n 为数据个数(多少行),对结果四舍五入取整后的理论值。
组距:每个组的上限和下限的距离。
d=U-L {最大值-最小值)除以组数40(2)组限:各组两端的数值称为组限;每组的起点值为下限(组中的最小值)(L ),每组的终点值为上限(组中的最大值)(U )。
连续变量:重叠组限,“下限不在本组内”。
离散变量:间断组限 (3)闭口组的组中值求法:开口组的组中值求法:39.频数(frequency,次数) :变量值落在某个区间(或某个类别)中的个数(或单位数)。
40.频率(relative frequency)(百分比) :某一区间或类别数据个数占全部数据个数的百分比。
41.有效百分比:各组频数占总有效样本单位数(总样本-缺失样本量)的百分比。
42.累计频数(cumulative frequencies):各组频数的逐级累加43.向上累计频数:由最低变量值的频数向高变量值频数的累计相加,累计频数表明某变量值以下(或该组上限以下)的总频数。
邻组组距下限值缺上限的开口组的组中邻组组距上限值缺下限的开口组的组中2121+=-=2 2下限上限下限或组的下限组的上限组中值-+=+=44.向下累计频数:由最高变量值的频数向低变量值频数的累计相加,累计频数表明某变量值以上(或该组下限以上)的总频数。
45.注意的问题:①累加方向取决于变量值本身的大小,与变量值的排列顺序无关。
②要反映某变量值以下的总频数,用向上累计频数;要反映某变量值以上的总频数,用向下累计频数。
③只有定序、定距变量才能计算累计频数。
46.频数分析的应用举例:频数分析的功能是描述变量的分布特征①定类、定序及变动范围较小的离散变量的频数分析-----直接进行。
定类变量定序变量单项式分组数据例:常住人口②连续变量的频数分析-----先统计分组,再进行频数分析。
47.饼图 (Pie Chart):也称圆瓣图、扇形图,是用圆形及圆内扇形的面积来表示频数百分比变化的图形;主要用于表示总体或样本中各组成部分所占的比例,对于研究结构性问题十分有用;绘制圆瓣图时,扇形面积可以表示频数,也可以表示百分比,这些扇形的中心角度,是按各部分数据百分比占3600的相应比例确定的(如频率0.3,则中心角度为360*0.3);最适用于定类变量,其他两种也可以。
48.条形图或柱形图(bar Chart):①用宽度(无意义)相同的条形的高度或长短来表示频数分布变化的图形②主要用于反映定类、定序变量的频数分布③绘制时,各类别可以放在纵轴,也可以放在横轴上。
柱形图的纵坐标或条形图的横坐标可以表示频数,也可以表示百分比。
49.直方图 (Histogram):①用矩形的面积来表示频数分布的图形②在直角坐标中,用横轴表示数据分组,纵轴表示频数密度(高),各组与相应的频数就形成了一个矩形,即直方图,宽有意义为组距。
③直方图下的总面积等于总频数(或等于1)适应于(只用于)定距变量的分析。
钟型分布:①特征是“两头少、中间多”,靠近中间的变量值分布的次数多,靠近两边的变量值次数分布的少,其分布曲线宛如一口古钟②图(a)被称为正态分布图;(b)和(c)被称为偏态分布,其中,图(b)为正(右)偏态分布图,(c)为负(左)偏态分布③许多社会经济和自然现象总体的频数分布都趋向于正态分布50.U型分布:U型分布的形状跟钟型分布相反,靠近中间的变量值频数少,靠近两端的变量值频数多,形成“两头多、中间少”的U字型例如,人口死亡率分布就是这种分布;人口总体中,幼儿和老年人死亡率高,而中青年死亡率低51.52.算术平均数 (mean)用于数值型数据【定距变量】,不能用于定类数据和定序数据。