统计学(第五版)课后答案
统计学第五版贾俊平版课后答案

统计学第五版贾俊平版课后题答案(部分)第7章抽样与参数估计7.1(1)已知: EMBED Equation.3 , EMBED Equation.3 , EMBED Equation.3。
, EMBED Equation.3 , EMBED Equation.3样本均值的抽样标准差 EMBED Equation.3。
(2)估计误差 EMBED Equation.3。
7.2(1)已知: EMBED Equation.3 , EMBED Equation.3 , EMBED Equation.3。
, EMBED Equation.3 , EMBED Equation.3。
样本均值的抽样标准差 EMBED Equation.3。
(2)估计误差 EMBED Equation.3(3)由于总体标准差已知,所以总体均值 EMBED Equation.3 的95%的置信区间为:,即(115.8,124.2)。
EMBED Equation.37.3已知: EMBED Equation.3 , EMBED Equation.3 , EMBED Equation.3。
, EMBED Equation.3 , EMBED Equation.3由于总体标准差已知,所以总体均值 EMBED Equation.3 的95%的置信区间为:,即(87818.856,121301.144)。
EMBED Equation.37.4(1)已知: EMBED Equation.3 , EMBED Equation.3 , EMBED Equation.3。
, EMBED Equation.3 , EMBED Equation.3由于 EMBED Equation.3 为大样本,所以总体均值 EMBED Equation.3 的90%的置信区间为:,即(79.026,82.974)。
EMBED Equation.3。
(2)已知: EMBED Equation.3 , EMBED Equation.3由于 EMBED Equation.3 为大样本,所以总体均值 EMBED Equation.3 的95%的置信区间为:,即(78.648,83.352)。
统计学第五版课后习题答案(完整版)

统计学(第五版)课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学第五版课后答案(贾俊平)之欧阳德创编

第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.00754.2 随机抽取25个网络用户,得到他们的年龄数据如下:单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线: 分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)4.3 某银行为缩短顾客到银行办理业务等待的时间。
统计学第五版课后题答案李金昌

统计学第五版课后题答案李金昌第1章绪论 1 .试述数据、数据库、数据库系统、数据库管理系统的概念。
答:( l )数据( Data ) :叙述事物的符号记录称作数据。
数据的种类存有数字、文字、图形、图像、声音、正文等。
数据与其语义就是不可分的。
解析在现代计算机系统中数据的概念就是广义的。
早期的计算机系统主要用作科学计算,处置的数据就是整数、实数、浮点数等传统数学中的数据。
现代计算机能够存储和处置的对象十分广为,则表示这些对象的数据也越来越繁杂。
数据与其语义就是不可分的。
500 这个数字可以表示一件物品的价格是 500 元,也可以表示一个学术会议参加的人数有 500 人,还可以表示一袋奶粉重 500 克。
( 2 )数据库( DataBase ,缩写 DB ) :数据库就是长期储存在计算机内的、存有非政府的、可以共享资源的数据子集。
数据库中的数据按一定的数据模型非政府、叙述和储存,具备较小的冗余度、较低的数据独立性和易扩展性,并可向各种用户共享资源。
( 3 )数据库系统( DataBas 。
Sytem ,缩写 DBS ) :数据库系统就是所指在计算机系统中导入数据库后的系统形成,通常由数据库、数据库管理系统(及其开发工具)、应用领域系统、数据库管理员形成。
解析数据库系统和数据库就是两个概念。
数据库系统就是一个人一机系统,数据库就是数据库系统的一个组成部分。
但是在日常工作中人们常常把数据库系统缩写为数据库。
期望读者能从人们讲话或文章的上下文中区分“数据库系统”和“数据库”,不要引发混为一谈。
( 4 )数据库管理系统( DataBase Management sytem ,简称 DBMs ) :数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。
DBMS 的主要功能包含数据定义功能、数据压低功能、数据库的运转管理功能、数据库的创建和保护功能。
解析 DBMS 就是一个大型的繁杂的软件系统,就是计算机中的基础软件。
统计学(第五版)课后答案
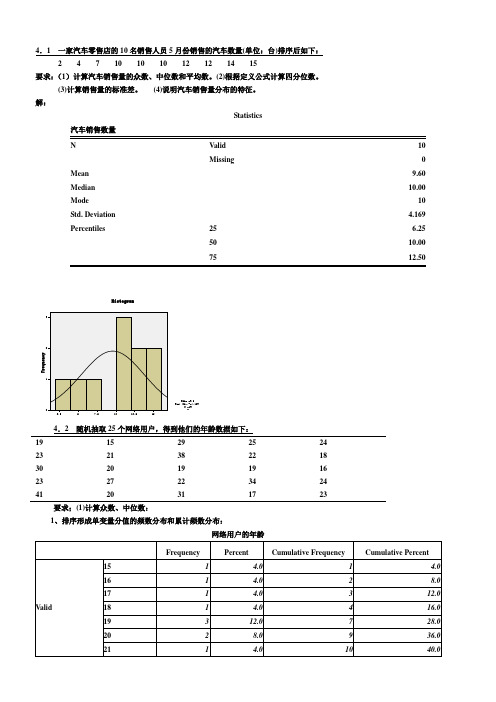
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid 10Missing 0 Mean 9.60 Median 10.00 Mode 10 Std. Deviation 4.169 Percentiles 25 6.2550 10.0075 12.504.2 随机抽取25个网络用户,得到他们的年龄数据如下:19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:1、排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25 和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差; Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线:分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K=+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄(Binned)分组后的均值与方差:分组后的直方图:4.6 在某地区抽取120家企业,按利润额进行分组,结果如下:要求:(1)计算120家企业利润额的平均数和标准差。
统计学贾俊平-课后思考题和练习题答案

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
解释分类数据,顺序数据和数值型数据答案同举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学第五版课后练答案
统计学第五版课后练答案(7-8章)(总11页)-本页仅作为预览文档封面,使用时请删除本页-第七章 参数估计(1)x σ==(2)2x z α∆= 1.96=某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
x σ==(2)在95%的置信水平下,求估计误差。
x x t σ∆=⋅,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=2z α 因此,x x t σ∆=⋅2x z ασ=⋅0.025x z σ=⋅=×=(3)如果样本均值为120元,求总体均值 的95%的置信区间。
置信区间为:22x z x z αα⎛-+ ⎝=()120 4.2,120 4.2-+=(,)22x z x z αα⎛-+ ⎝=104560±=(,) 从总体中抽取一个n=100的简单随机样本,得到x =81,s=12。
要求:大样本,样本均值服从正态分布:2,x N n σμ⎛⎫ ⎪⎝⎭或2,s x N n μ⎛⎫⎪⎝⎭置信区间为:22x z x z αα⎛-+ ⎝= (1)构建μ的90%的置信区间。
2z α=0.05z =,置信区间为:()81 1.645 1.2,81 1.645 1.2-⨯+⨯=(,)(2)构建μ的95%的置信区间。
2z α=0.025z =,置信区间为:()81 1.96 1.2,81 1.96 1.2-⨯+⨯=(,) (3)构建μ的99%的置信区间。
2z α=0.005z =,置信区间为:()81 2.576 1.2,81 2.576 1.2-⨯+⨯=(,)(1)2x z α±=25 1.96±=(,) (2)2x z α±=119.6 2.326±=(,)(3)2x z α±=3.419 1.645±=(,)(1)2x z α±=8900 1.96±=(,)(2)2x z α±=8900 1.96±=(,)(3)2x z α±=8900 1.645±=(,) (4)2x z α±=8900 2.58±=(,)某大学为了解学生每天上网的时间,在全校7 500名学生中采取重复抽样方法随机抽取36解:(1)样本均值x =,样本标准差s=1α-=,t=2z α=0.05z =,2x z α±=3.32 1.645±=(,)1α-=,t=2z α=0.025z =,2x zα±3.32 1.96±=(,)1α-=,t=2z α=0.005z =,2x z α±3.32 2.76±(,)x t α±=10 2.365±某居民小区为研究职工上班从家里到单位的距离,抽取了由16个人组成的一个随机样本,他们到单位的距离(单位:km)分别是: 10 3 14 8 6 9 12 11 7 5 10 15 9 16 13 2假定总体服从正态分布,求职工上班从家里到单位平均距离的95%的置信区间。
统计学第五版课后答案(贾俊平)之欧阳理创编
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:StatisticsMissing0Mean9.60Median10.00Mode10Std. Deviation 4.169Percentiles25 6.255010.007512.504.2下:单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线: 分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 最小值)÷ 组数=(4115)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)4.3 某银行为缩短顾客到银行办理业务等待的时间。
统计学第五版课后答案(贾俊平)之欧阳术创编
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.00754.2 随机抽取25个网络用户,得到他们的年龄数据如下:单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线: 分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:4.3 某银行为缩短顾客到银行办理业务等待的时间。
统计学第五版课后题答案
统计学第五版贾俊平版课后题答案(部分)第三章数据的图表展示3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB AC E E A BD D CA DBC C A ED C BC B C ED B C C B C要求:(1)指出上面的数据属于什么类型。
顺序数据(2)用Excel制作一张频数分布表。
用数据分析——直方图制作:接收频率E16D17C32B21A14(3)绘制一张条形图,反映评价等级的分布。
用数据分析——直方图制作:(4)绘制评价等级的帕累托图。
逆序排序后,制作累计频数分布表:接收 频数 频率(%) 累计频率(%) C 32 32 32 B 21 21 53 D 17 17 70 E 16 16 86 A14141005101520253035CDBAE204060801001203.2 某行业管理局所属40个企业2002年的产品销售收入数据如下: 152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 9788123115119138112146113126要求:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
1、确定组数: ()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(152-87)÷6=10.83,取10 3(2)按规定,销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115 万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
7.02377
Variance
49.333
Skewness
1.163
Kurtosis
1.302
分组后的直方图:
4.6在某地区抽取120家企业,按利润额进行分组,结果如下:
按利润额分组(万元)
企业数(个)
200~300
300~400
400~500
500~600
600以上
19
解:已知μ0=250,σ= 30,N=25, =270这里是小样本分布,σ已知,用Z统计量。右侧检验,α=0.05,则Zα=1.645
提出假设:假定这种化肥没使小麦明显增产。即H0:μ≤250H1:μ>250
计算统计量:Z =( -μ0)/(σ/√N)=(270-250)/(30/√25)= 3.33
(1) =25,σ=3.5,n=60,置信水平为95%(2) =119.6,s=23.89,n=75,置信水平为95%
(3) =3.419,s=0.974,n=32,置信水平为90%
解:∵
∴1)1-=95%, 其置信区间为:25±1.96×3.5÷√60= 25±0.885
2)1-=98%,则=0.02,/2=0.01, 1-/2=0.99,查标准正态分布表,可知: 2.33
解:已知μ0=4.55,σ²=0.108²,N=9, =4.484,
这里采用双侧检验,小样本,σ已知,使用Z统计。假定现在生产的铁水平均含碳量与以前无显著差异。则,
H0:μ=4.55;H1:μ≠4.55α=0.05,α/2 =0.025,查表得临界值为 1.96
计算检验统计量: = (4.484-4.55)/(0.108/√9)= -1.833
解:H0:μ≥700;H1:μ<700已知: =680 =60
由于n=36>30,大样本,因此检验统计量: = =-2
当α=0.05,查表得 =1.645。因为z<- ,故拒绝原假设,接受备择假设,说明这批产品不合格。
8.3某地区小麦的一般生产水平为亩产250公斤,其标准差为30公斤,先用一种花费进行试验,从25个小区抽样,平均产量为270公斤。这种化肥是否使小麦明显增产?
4.0
23
92.0
38
1
4.0
24
96.0
41
1
4.0
25
100.0
Total
25
100.0
从频数看出,众数Mo有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25
4.1一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:
2 4 7 10 10 10 12 12 14 15
要求:(1)计算汽车销售量的众数、中位数和平均数。(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。(4)说明汽车销售量分布的特征。
解:
Statistics
汽车销售数量
决策:∵Z值落入接受域,∴在=0.05的显著性水平上接受H0。
结论:有证据表明现在生产的铁水平均含碳量与以前没有显著差异,可以认为现在生产的铁水平均含碳量为4.55。
8.2一种元件,要求其使用寿命不得低于700小时。现从一批这种元件中随机抽取36件,测得其平均寿命为680小时。已知该元件寿命服从正态分布, =60小时,试在显著性水平0.05下确定这批元件是否合格。
为分组情况下的直方图:
为分组情况下的概率密度曲线:
分组:
1、确定组数: ,取k=6
2、确定组距:组距=(最大值-最小值)÷组数=(41-15)÷6=4.3,取5
3、分组频数表
网络用户的年龄(Binned)
Frequency
Percent
Cumulative Frequency
Cumulative Percent
(5)置信区间: =0.95,
重复抽样: = =(2.79,3.85)
不重复抽样: = =(2.80,3.84)
7.8从一个正态总体中随机抽取样本量为8的样本,各样本值分别为:10、8、12、15、6、13、5、11.,求总体均值μ的95%的置信区间
解:本题为一个小样本正态分布,σ未知。先求样本均值: = 80÷8=10
要求:(1)如果比较成年组和幼儿组的身高差异,你会采用什么样的统计量?为什么?
均值不相等,用离散系数衡量身高差异。
(2)比较分析哪一组的身高差异大?
成年组
幼儿组
平均
172.1
平均
71.3
标准差
4.201851
标准差
2.496664
离散系数
0.024415
离散系数
0.035016
幼儿组的身高差异大。
7.3从一个总体中随机抽取n=100的随机样本,得到x=104560,假定总体标准差σ=86414,构建总体均值μ的95%的置信区间。解:已知n =100, =104560,σ= 85414,1-=95%,
27
22
34
24
41
20
31
17
23
要求;(1)计算众数、中位数:
1、排序形成单变量分值的频数分布和累计频数分布:
网络用户的年龄
Frequency
Percent
Cumulative Frequency
Cumulative Percent
Valid
15
1
4.0
1
4.0
16
1
4.0
2
8.0
17
1
4.0
3
0.221
Kurtosis
-0.625
Std. Error of Kurtosis
0.438
4.9一家公司在招收职员时,首先要通过两项能力测试。在A项测试中,其平均分数是100分,标准差是15分;在B项测试中,其平均分数是400分,标准差是50分。一位应试者在A项测试中得了115分,在B项测试中得了425分。与平均分数相比,该应试者哪一项测试更为理想?
2)已知丌=0.8 , E = 0.1,α=0.05,α/2 =0.025,则 1.96
N= ²丌(1-丌)/E²= 1.96²×0.8×0.2÷0.1²≈62
8.1已知某炼铁厂的含碳量服从正态分布N(4.55,0.108²),现在测定了9炉铁水,其平均含碳量为4.484,如果估计方差没有变化,可否认为现在生产的铁水平均含碳量为4.55?
每包重量(g)
包数
96~98
98~100
100~102
102~104
104~106
2
3
34
7
4
合计
50
已知食品包重量服从正态分布,要求:
(1)确定该种食品平均重量的95%的置信区间。解:大样本,总体方差未知,用z统计量
样本均值=101.4,样本标准差s=1.829
置信区间: =0.95, = =1.96
(2)抽样平均误差:重复抽样: = =1.61/6=0.268
不重复抽样: = =
=0.268× =0.268×0.998=0.267
(3)置信水平下的概率度: =0.95,t= = =1.96
(4)边际误差(极限误差): =0.95, =
重复抽样: = =1.96×0.268=0.525
不重复抽样: = =1.96×0.267=0.523
12.0
18
1
4.0
4
16.0
19
3
12.0
7
28.0
20
2
8.0
9
36.0
21
1
4.0
10
40.0
22
2
8.0
12
48.0
23
3
12.0
15
60.0
24
2
8.0
17
68.0
25
1
4.0
18
72.0
27
1
4.0
19
76.0
29
1
4.0
20
80.0
30
1
4.0
21
84.0
31
1
4.0
22
88.0
34
1
(2)构建 的95%的置信区间。 = =1.96,置信区间为:(81-1.96×1.2,81+1.96×1.2)=(78.65,83.35)
(3)构建 的99%的置信区间。 = =2.576,置信区间为:(81-2.576×1.2,81+2.576×1.2)=(77.91,84.09)
7.5利用下面的信息,构建总体均值的置信区间
(1)求总体中赞成该项改革的户数比例的置信区间
(2)若小区管理者预计赞成的比例能达到80%,估计误差不超过10%,应抽取多少户进行调查?
解:1)已知N=50,P=32/50=0.64,α=0.05,α/2 =0.025,则 1.96
置信区间:P± √{P(1-P)/N}= 0.64±1.96√0.64×0.36/50= 0.64±1.96×0.48/7.07=0.64±0.133
30
42
18
11
合计
120
要求:(1)计算120家企业利润额的平均数和标准差。(2)计算分布的偏态系数和峰态系数。
解:
Statistics
企业利润组中值Mi(万元)
N
Valid
120
Missing
0
Mean
426.6667
Std. Deviation
116.48445