第六章非线性回归分析预测法
回归分析预测方法

上一页 下一页 返回
8.1回归分析预测法概述
[阅读材料]
实际工作中,如何判定市场现象之间是否具有相关关系是预 测者必须首先解决的问题。市场现象之间是否存在相关关系 ,主要可以通过两种方法来判定。一种方法是根据经济理论 知识和实践经验,结合我国市场的具体表现,从定性的角度 判断市场现象之间是否存在相关关系。如根据马克思主义的 政治经济学理论,根据市场学理论,根据我国市场长期以来 的发展变化规律等,都可以判定两种或多种市场现象之间是 否存在相关关系。这种方法是判断市场现象相关关系的根本 方法。另一种方法是对市场现象之间的关系进行相关分析, 从定量的角度来判断市场现象之间是否存在相关关系。
上一页 下一页 返回
8.1回归分析预测法概述
函数关系与相关关系的区别,突出表现在变量之间的具体关 系值是否确定和随机。函数关系是相对于确定的、非随机变 量而言的;而相关关系则是相对于非确定的、随机变量而言的。 值得指出的是函数关系与相关关系虽然是两种不同类型的相 互关系,但彼此之间也具有一定的联系,一方面,由于在观 察和测量中存在误差等原因,实际工作中的函数关系有时通 过相关关系表现出来;另一方面,在研究相关关系时又常常借 用函数关系的形式近似地将它表达出来,以便找到相关关系 的一般数量特征,当随机因素不存在时,相关关系就转化为 函数关系。因此,函数关系是相关关系的特例。
上一页 下Байду номын сангаас页 返回
8.1回归分析预测法概述
2.按照相关的变动方向不同,可分为正相关回归分析预测和 负相关回归分析预测
《非线性回归分析》课件
封装式
• 基于模型的错误率和复 杂性进行特征选择。
• 常用的封装方法包括递 归特征消除法和遗传算 法等。
嵌入式
• 特征选择和模型训练同 时进行。
• 与算法结合在一起的特 征选择方法,例如正则 化(Lasso、Ridge)。
数据处理方法:缺失值填充、异常值 处理等
1
网格搜索
通过预定义的参数空间中的方格进行搜
随机搜索
2
索。
在预定义的参数空间中进行随机搜索。
3
贝叶斯调参
使用贝叶斯优化方法对超参数进行优化。
集成学习在非线性回归中的应用
集成学习是一种将若干个基学习器集成在一起以获得更好分类效果的方法,也可以用于非线性回归建模中。
1 堆叠
使用多层模型来组成一个 超级学习器,每个模型继 承前一模型的输出做为自 己的输入。
不可避免地存在数据缺失、异常值等问题,需要使用相应的方法对其进行处理。这是非线性回归 分析中至关重要的一环。
1 缺失值填充
常见的方法包括插值法、代入法和主成分分析等。
2 异常值处理
常见的方法包括删除、截尾、平滑等。
3 特征缩放和标准化
为了提高模型的计算速度和准确性,需要对特征进行缩放和标准化。
偏差-方差平衡与模型复杂度
一种广泛用于图像识别和计算机 视觉领域的神经网络。
循环神经网络
一种用于处理序列数据的神经网 络,如自然语言处理。
sklearn库在非线性回归中的应用
scikit-learn是Python中最受欢迎的机器学习库之一,可以用于非线性回归的建模、评估和调参。
1 模型建立
scikit-learn提供各种非线 性回归算法的实现,如 KNN回归、决策树回归和 支持向量机回归等。
非线性回归分析的入门知识

非线性回归分析的入门知识在统计学和机器学习领域,回归分析是一种重要的数据分析方法,用于研究自变量和因变量之间的关系。
在实际问题中,很多情况下自变量和因变量之间的关系并不是简单的线性关系,而是呈现出一种复杂的非线性关系。
因此,非线性回归分析就应运而生,用于描述和预测这种非线性关系。
本文将介绍非线性回归分析的入门知识,包括非线性回归模型的基本概念、常见的非线性回归模型以及参数估计方法等内容。
一、非线性回归模型的基本概念在回归分析中,线性回归模型是最简单和最常用的模型之一,其数学表达式为:$$Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_pX_p +\varepsilon$$其中,$Y$表示因变量,$X_1, X_2, ..., X_p$表示自变量,$\beta_0, \beta_1, \beta_2, ..., \beta_p$表示模型的参数,$\varepsilon$表示误差项。
线性回归模型的关键特点是因变量$Y$与自变量$X$之间呈线性关系。
而非线性回归模型则允许因变量$Y$与自变量$X$之间呈现非线性关系,其数学表达式可以是各种形式的非线性函数,例如指数函数、对数函数、多项式函数等。
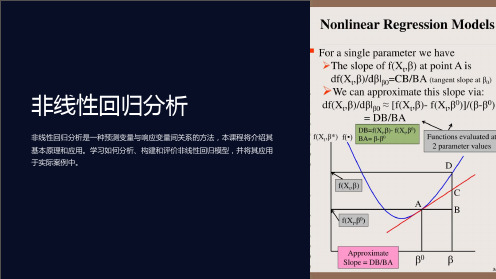
一般来说,非线性回归模型可以表示为:$$Y = f(X, \beta) + \varepsilon$$其中,$f(X, \beta)$表示非线性函数,$\beta$表示模型的参数。
非线性回归模型的关键在于确定合适的非线性函数形式$f(X,\beta)$以及估计参数$\beta$。
二、常见的非线性回归模型1. 多项式回归模型多项式回归模型是一种简单且常见的非线性回归模型,其形式为: $$Y = \beta_0 + \beta_1X + \beta_2X^2 + ... + \beta_nX^n +\varepsilon$$其中,$X^2, X^3, ..., X^n$表示自变量$X$的高次项,$\beta_0, \beta_1, \beta_2, ..., \beta_n$表示模型的参数。
回归分析预测法

回归分析预测法(总25页) -本页仅作为预览文档封面,使用时请删除本页-什么是回归分析预测法回归分析预测法,是在分析市场现象自变量和因变量之间相关关系的基础上,建立变量之间的回归方程,并将回归方程作为预测模型,根据自变量在预测期的数量变化来预测因变量关系大多表现为相关关系,因此,回归分析预测法是一种重要的市场预测方法,当我们在对市场现象未来发展状况和水平进行预测时,如果能将影响市场预测对象的主要因素找到,并且能够取得其数量资料,就可以采用回归分析预测法进行预测。
它是一种具体的、行之有效的、实用价值很高的常用市场预测方法。
[编辑]回归分析预测法的分类回归分析预测法有多种类型。
依据相关关系中自变量的个数不同分类,可分为一元回归分析预测法和多元回归分析预测法。
在一元回归分析预测法中,自变量只有一个,而在多元回归分析预测法中,自变量有两个以上。
依据自变量和因变量之间的相关关系不同,可分为线性回归预测和非线性回归预测。
[编辑]回归分析预测法的步骤1.根据预测目标,确定自变量和因变量明确预测的具体目标,也就确定了因变量。
如预测具体目标是下一年度的销售量,那么销售量Y就是因变量。
通过市场调查和查阅资料,寻找与预测目标的相关影响因素,即自变量,并从中选出主要的影响因素。
2.建立回归预测模型依据自变量和因变量的历史统计资料进行计算,在此基础上建立回归分析方程,即回归分析预测模型。
3.进行相关分析回归分析是对具有因果关系的影响因素(自变量)和预测对象(因变量)所进行的数理统计分析处理。
只有当变量与因变量确实存在某种关系时,建立的回归方程才有意义。
因此,作为自变量的因素与作为因变量的预测对象是否有关,相关程度如何,以及判断这种相关程度的把握性多大,就成为进行回归分析必须要解决的问题。
进行相关分析,一般要求出相关关系,以相关系数的大小来判断自变量和因变量的相关的程度。
4.检验回归预测模型,计算预测误差回归预测模型是否可用于实际预测,取决于对回归预测模型的检验和对预测误差的计算。
非线性回归预测法——高斯牛顿法(詹学朋)

非线性回归预测法前面所研究的回归模型,我们假定自变量与因变量之间的关系是线性的,但社会经济现象是极其复杂的,有时各因素之间的关系不一定是线性的,而可能存在某种非线性关系,这时,就必须建立非线性回归模型。
一、非线性回归模型的概念及其分类非线性回归模型,是指用于经济预测的模型是曲线型的。
常见的非线性回归模型有下列几种: (1)双曲线模型:i ii x y εββ++=121 (3-59) (2)二次曲线模型:i i i i x x y εβββ+++=2321 (3-60)(3)对数模型:i i i x y εββ++=ln 21 (3-61)(4)三角函数模型:i i i x y εββ++=sin 21 (3-62)(5)指数模型:i x i i ab y ε+= (3-63)i i i x x i e y εβββ+++=221110 (3-64)(6)幂函数模型:i b i i ax y ε+= (3-65)(7)罗吉斯曲线:i x x i iie e y εββββ++=++1101101 (3-66)(8)修正指数增长曲线:i x i i br a y ε++= (3-67)根据非线性回归模型线性化的不同性质,上述模型一般可细分成三种类型。
第一类:直接换元型。
这类非线性回归模型通过简单的变量换元可直接化为线性回归模型,如:(3-59)、(3-60)、(3-61)、(3-62)式。
由于这类模型的因变量没有变形,所以可以直接采用最小平方法估计回归系数并进行检验和预测。
第二类:间接代换型。
这类非线性回归模型经常通过对数变形的代换间接地化为线性回归模型,如:(3-63)、(3-64)、(3-65)式。
由于这类模型在对数变形代换过程中改变了因变量的形态,使得变形后模型的最小平方估计失去了原模型的残差平方和为最小的意义,从而估计不到原模型的最佳回归系数,造成回归模型与原数列之间的较大偏差。
第三类:非线性型。
6.1第六章回归分析

变量之间的联系
确定型的关系:指某一个或某几个现象的变动必然会 引起另一个现象确定的变动,他们之间的关系可以使 用数学函数式确切地表达出来,即y=f(x)。当知道x的 数值时,就可以计算出确切的y值来。如圆的周长与 半径的关系:周长=2πr。 非确定关系:例如,在发育阶段,随年龄的增长,人 的身高会增加。但不能根据年龄找到确定的身高,即 不能得出11岁儿童身高一定就是1米40公分。年龄与 身高的关系不能用一般的函数关系来表达。研究变量 之间既存在又不确定的相互关系及其密切程度的分析 称为相关分析。
(3)方差齐性检验
方差齐性是指残差的分布是常数,与预测变量或 因变量无关。即残差应随机的分布在一条穿过0点 的水平直线的两侧。在实际应用中,一般是绘制 因变量预测值与学生残差(或标准化残差)的散 点图。在线性回归Plots对话框中的源变量表中,选 择SRESID或ZRESID(学生氏残差或标准化残差) 做Y轴;选择ZPRED(标准化预测值)做X轴就 可以在执行后的输出信息中显示检验方差齐性的 散点图。
要认真检查数据的合理性。
2、选择自变量和因变量
3、选择回归分析方法
Enter选项,强行进入 法,即所选择的自变量 全部进人回归模型,该
选项是默认方式。
Remove选项,消去法, 建立的回归方程时,根
据设定的条件剔除部分
自变量。
选择回归分析方法
Forward选项,向前选择 法,根据在option对话框中 所设定的判据,从无自变 量开始。在拟合过程中, 对被选择的自变量进行方 差分析,每次加入一个F值 最大的变量,直至所有符 合判据的变量都进入模型 为止。第一个引入归模型 的变量应该与因变量间相 关系数绝对值最大。
得到它们的均方。
第六章非线性回归分析预测法

年份 零售额 x 流通费率 y 1991 10.2 7 1992 11.7 6.2 1993 13 5.8 1994 15 5.3 1995 16.5 5 1996 19 4.8 1997 22 4.6 1998 25 4.3 1999 28.5 4.2 2000 32 4.1
变量变换后的回归模型为
' ˆ y 2.64459 41.9742x
而
故
1 x x 1 ˆ 2.64459 41.9742 y x
'
§6.2 非线性回归模型应用
用原变量表示的回归模型为
1 ˆ 2.64459 41.9742 y x 预测:2001年该商品零售额为36.33进
2001年流通费用率预测为
1 ˆ 2.64459 41.9742 y 3.79946 36 .33
§6.2 非线性回归模型应用
三、不能化为线性回归的非线性回归的处理 一般用分段求和法
§5.2
多元线性回归预测法
二、检验模型 本例: m =3, n =10,取检验水平为0.05
F0.05 (m 1, n m) F0.05 (2,7) 4.74
Coefficients 标准误差 t Stat P-valueLower 95% Intercept 2.64459 0.12936 20.4443 3.4E-08 2.34629 X Variable 41.9742 1 2.05571 20.4183 3.5E-08 37.2337
§6.2 非线性回归模型应用
而 P 0.000276 满足 F F (m 1, n m) 或 P 故线性关系显著
F 32.874
数据预测—非线性回归

数据预测—非线性回归非线性回归是一种在数据预测中常用的方法,它适用于无法通过线性关系来准确预测的场景。
通过寻找非线性模型中的最佳拟合曲线,非线性回归可以帮助我们预测未来的数据趋势。
什么是非线性回归回归分析是一种统计方法,用于确定自变量与因变量之间的关系。
线性回归假设自变量与因变量之间存在线性关系,但在某些情况下,真实的关系可能是非线性的。
这时,我们就需要使用非线性回归来更准确地建立模型。
非线性回归用曲线来描述自变量与因变量的关系,常见的非线性模型包括指数模型、多项式模型、对数模型等。
通过调整非线性模型的参数,我们可以找到最佳的拟合曲线,从而预测未来的数据。
如何进行非线性回归进行非线性回归的一般步骤如下:1. 收集数据:首先,我们需要收集自变量与因变量之间的样本数据。
2. 选择合适的模型:根据数据的特点,选择适合的非线性模型来描述自变量与因变量之间的关系。
3. 参数估计:使用统计方法,估计非线性模型中的参数值,找到最佳的拟合曲线。
4. 模型评估:通过评估模型的拟合程度,确定模型的可靠性和预测能力。
5. 预测未来数据:使用已建立的非线性模型,预测未来的数据趋势。
非线性回归的优势和应用非线性回归相比线性回归具有以下优势:- 更准确的预测能力:非线性回归可以更好地拟合真实的数据模式,提供更准确的预测结果。
- 更强的灵活性:非线性回归可以适应各种复杂的数据模式和关系,允许我们探索更多的可能性。
非线性回归在各个领域都有广泛的应用,例如金融、医学、经济学等。
在金融领域,非线性回归可以用于股票价格预测和风险评估;在医学领域,非线性回归可以用于疾病发展趋势预测和药物效果评估。
总结非线性回归是一种在数据预测中常用的方法,适用于无法通过线性关系进行准确预测的场景。
通过寻找非线性模型中的最佳拟合曲线,非线性回归可以帮助我们更准确地预测未来的数据趋势。
非线性回归具有更准确的预测能力和更强的灵活性,在各个领域都有广泛的应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
而 P 0.000276 满足 F F (m 1, n m) 或 P 故线性关系显著
F 32.874
方差分析 df 回归分析 残差 总计 SS MS F Significance F 2 21.6006 10.8003 32.8784 0.000276 7 2.29944 0.32849 9 23.9
某商店商品流通率与商品零售额资料
年份 零售额 x 流通费率 y 1991 10.2 7 1992 11.7 6.2 1993 13 5.8 1994 15 5.3 1995 16.5 5 1996 19 4.8 1997 22 4.6 1998 25 4.3 1999 28.5 4.2 2000 32 4.1
§6.2 非线性回归模型应用
用变换后的数据进行回归计算
SUMMARY OUTPUT 回归统计 Multiple 0.99054 R R Square 0.98117 Adjusted 0.97882 R Square 标准误差 0.13842 观测值 10 方差分析 df 回归分析 残差 总计 SS MS F Significance F 1 7.98772 7.98772 416.907 3.5E-08 8 0.15328 0.01916 9 8.141
8 7 6 5 4 3 2 1 0 0 10 20 30 40 系列1
1 y 1 2 u x
§6.2 非线性回归模型应用
变量变换 数据变换
1 x x
'
y 1 2 x u
'
年份 零售额 x 流通费率 y 1/x 1991 10.2 7 0.09804 1992 11.7 6.2 0.08547 1993 13 5.8 0.07692 1994 15 5.3 0.06667 1995 16.5 5 0.06061 1996 19 4.8 0.05263 1997 22 4.6 0.04545 1998 25 4.3 0.04 1999 28.5 4.2 0.03509 2000 32 4.1 0.03125
§6.1 非线性回m-1个自变量x2,x3 …,xm,
假设因变量与自变量的关系非是线性的,这是
建立的回归模型为非线性回归模型
§6.1 非线性回归模型的形式及其分类
二、非线性回归模型类型P177
(一)可化为线性回归的非线性回归模型
(二)不可线性化的非线性回归模型
Coefficients 标准误差 t Stat P-valueLower 95% Intercept 2.64459 0.12936 20.4443 3.4E-08 2.34629 X Variable 41.9742 1 2.05571 20.4183 3.5E-08 37.2337
§6.2 非线性回归模型应用
2001年流通费用率预测为
1 ˆ 2.64459 41.9742 y 3.79946 36 .33
§6.2 非线性回归模型应用
三、不能化为线性回归的非线性回归的处理 一般用分段求和法
§5.2
多元线性回归预测法
二、检验模型 本例: m =3, n =10,取检验水平为0.05
F0.05 (m 1, n m) F0.05 (2,7) 4.74
§5.2
多元线性回归预测法
二、检验模型 根据有关计算结果进行显著性检验 (2)t检验(检验因变量与某个自变量的线性 关系是否显著): t值越大,或P值越小,回 归效果越好。满足下列条件,则可认为线性 关系显著的,否则为线性关系不显著的
| t | t / 2 (n m)
或
P
m为回归系数个数, n为样本容量
§6.2 非线性回归模型应用
一、确定模型的形式 常用方法有 (1)经验法 (2)散点图法 二、可化为线性回归的非线性回归模型的处理 1、做变量代换:把非线性转化为线性 2、数据转换:按变量代换的结果转化数据 3、最小二乘估计:用转换后的数据计算,分 析,检验 4、用原变量表示预测模型
§6.2 非线性回归模型应用
变量变换后的回归模型为
' ˆ y 2.64459 41.9742x
而
故
1 x x 1 ˆ 2.64459 41.9742 y x
'
§6.2 非线性回归模型应用
用原变量表示的回归模型为
1 ˆ 2.64459 41.9742 y x 预测:2001年该商品零售额为36.33进