如何在plsql程序中处理批量数据
数据库技术中的数据批量处理方法(七)

数据库技术中的数据批量处理方法随着信息技术的快速发展,海量的数据涌入数据库中,如何高效处理这些数据成为数据库技术领域的重要问题之一。
在数据库技术中,数据批量处理方法被广泛应用于数据导入、数据清洗、数据分析等场景中,以提高数据处理效率和准确性。
本文将从不同角度探讨数据库技术中的数据批量处理方法。
一、并行处理技术并行处理技术是数据库中常用的一种数据批量处理方法。
通过将数据分割成多个小块,并利用多台处理节点同时处理这些小块的数据,可以大大提高数据处理的速度和效率。
在分布式数据库系统中,可以使用分片和分区的方法将数据进行划分,实现数据的并行处理。
另外,通过使用并行查询技术对数据进行并行操作,可以充分利用多核处理器和集群系统的并行计算能力,提高查询和分析任务的处理速度。
二、批量导入技术大量数据的导入是数据库中常见的需求,如何高效地进行数据的批量导入成为了数据库工程师关注的问题。
传统的导入方法是逐条插入数据,但这种方法对于大量数据的导入效率较低。
因此,数据库技术中的数据批量导入方法应运而生。
数据批量导入方法可以通过预先构建好数据文件,再通过文件导入的方式将数据批量插入到数据库中,以提高导入的效率。
此外,还可以使用数据库的导入工具,如MySQL的LOAD DATA INFILE命令或Oracle的External Tables,实现数据的快速导入。
三、ETL技术ETL(Extract, Transform, Load)技术是数据库中常用的数据批量处理方法。
ETL技术通过抽取数据、转换数据、加载数据的过程,实现对数据的清洗、转换和整合。
在数据仓库和大数据平台中,ETL技术被广泛应用于数据的清洗和预处理。
通过使用ETL工具,可以实现对数据的抽取、清洗、规范化、数据质量控制等一系列操作,从而为后续的数据分析和挖掘提供高质量的数据基础。
四、并发控制技术在数据库的并发操作中,数据的批量处理方法也起到重要的作用。
通过合理的并发控制技术,可以避免数据的冲突和死锁等问题,提高数据库的并发处理能力。
plsql使用技巧

1、PL/SQL Developer记住登陆密码在使用PL/SQL Developer时,为了工作方便希望PL/SQL Developer记住登录Oracle的用户名和密码;2、执行单条SQL语句在使用PL/SQL Developer的SQL Window时,按F8键,PL/SQL Developer默认是执行该窗口的所有SQL语句,需要设置为鼠标所在的那条SQL语句,即执行当前SQL语句;3、格式化SQL语句在使用PL/SQL Developer的SQL Window时,有时候输入的SQL语句太长或太乱,希望能用比较通用的写法格式话一下,这样看起来会好看些,也好分析;使用方法:选中需要格式化的SQL语句,然后点击工具栏的PL/SQL beautifier按钮即可. 4、查看执行计划在使用PL/SQL Developer的SQL Window时,有时候输入的SQL语句执行的效率,分析下表结构,如何可以提高查询的效率,可以通过查看Oracle提供的执行计划;使用方法:选中需要分析的SQL语句,然后点击工具栏的Ex pl ain pl an按钮(即执行计划,或者直接按F5即可.5、调试存储过程在使用PL/SQL Developer操作Oracle时,有时候调用某些存储过程,或者调试存储过程; 调用存储过程的方法:首先,在PL/SQL Developer左边的Browser中选择Procedures,查找需要调用的存储过程;然后,选中调试的存储过程,点击右键,选择Test,在弹出来的Test scrīpt 窗口中,对于定义为in类型的参数,需要给该参数的Value输入值;最后点击上面的条数按钮: Start debugger 或者按F9;最后点击:RUN 或者Ctrl+R以下的技巧只针对PL/ SQL Developer6以上版本,版本5只有其中的部分特性.1,右键菜单在PL/SQL Developer(下面简称PL D中的每一个文本编辑窗口,如SQL Window,Comman d Window和Porgram Window,右键点击某个对象名称,会弹出一个包含操作对象命令的菜单,我们这里称之为右键菜单.如下图:对象类型可以是表,视图,同义词,存储过程和函数等.根据对象类型的不同,弹出的菜单也有区别.表和视图有View, Edit, Rename, Drop, Query data 和Edit data等功能.View和Edit 分别是查看和修改表的结构信息,如字段,主键,索引和约束等.Query data相当于新打开一个窗口,并执行select * from 表.Edit data相当于新打开一个窗口,并执行select * from 表for update.存储过程和函数有Test功能,选中后可以进入调试状态.有时由于PL D识别错误,右键点击对象并不能出来正确的菜单,可以在对象所在的DDL或D ML语句的前面,加上分号,这样PL D就能正确的判断出对象的类型2,Select for Update有时我们需要把一些数据导入数据库中,如果用UE拼Insert语句,会比较麻烦,而且操作性不强.PL D的SQL Window可以查询,新增,修改和删除表的内容.查询自不必说,而新增,删除和修改,只需在select语句后加入for update,对表进行行级锁定,然后点击窗口的锁型图标,即可进入编辑状态.下面介绍一下如何从Excel中提取文本插入到数据库中我们的Excel文件中有三列:在数据库中建立临时表:create table t1 (cino varchar2(100, contno varchar2(100, loanno varchar2(100然后在SQL Window中输入select t1 for update,并点击锁型鼠标,进入编辑状态:用鼠标点击第一行的输入窗口,这时PL D会死锁几秒钟,然后可以见到光标在第一行的输入框中闪动,用鼠标把CINO, CONTNO, LOANNO选中:进入Excel中,把需要插入数据库的内容选中,然后切换到PL D,按Ctrl + V:点击r,然后再点击Commit按钮,则数据提交到表t1中,执行select * from t1可以看到内容: 3,PL/SQL BeautifierPL D 6以上版本有对DML代码格式化的功能.在SQL Window或Program Window中选中部分代码(如果不选则对整个窗口的代码操作,在菜单中选Edit aPL/SQL Beautifier,得到格式化的代码.对于非法的DML语句或DDL语句,PL D将会在下方状态栏提示PL/SQL B eautifier could not parse text.在缺省的状态下,PL D会把DML语句的每一个字段都排在单独的一行,这样不方便查看.在菜单中选Edit a PL/SQL Beautifier Options,进入Preferences窗口,选择Edit,进入配置文件编辑界面:在标签栏选DML,在窗口中部的Select, Insert和Update组框中把Fit选中,然后点击Sav e,把配置文件保存到PL D的安装目录下,点击Close关闭.在Rules file中输入配置文件所在位置,点击OK,完成配置文件切换.这时再对代码进行格式化,就可以使每一个字段尽可能的在一行上了.4,TNS Names菜单Help a Support Info a TNS Names,可以查看Oracle 的tnsnames.ora.5,Copy to Excel在SQL Window中执行Select语句,在结果出来以后,右键点击下面的数据区,选择Copy to Excel,可以把数据区的记录原样拷贝到Excel中.但有两点需要注意:一,field中不能以=开始,否则Excel会误认为是函数;二,数字不要超过17位,否则后面的位数将会置为0,但可以通过在数字前加l来使Excel认为该field是文本,同时对于数据库中Numbe类型的字段,最好用t o_char输出,不然可能会显示不正常下面介绍几个使用PL/SQL Developer过程中发现的小技巧1.执行光标所在行SQL语句一个sql窗口中如果有多条sql语句,点击执行或者按F8,会全部执行,其实我们需要的只是实行其中的某一条.下面介绍一种方法可以执行光标所在行SQL语句,不用选中也不用Shift+H omeTools-->Preferences-->Window Types-->SQL Window-->选中AutoSelect statement复选框,然后Ap pl y,就OK了.2.使用自定义快捷键PL/SQL Developer也可以像其他IDE那样使用自定义快捷键提高编写代码效率,为开发者提供方便.如我们平时在sql窗口中使用最频繁的select * from 我们就可以设置一个快捷键来简化s elect * from的输入.s = SELECT * FROMw = WHERE 1 = 1 ANDsc = SELECT count(* FROM复制代码另存到PL/SQL Developer的安装路径下的~\Pl ugIns目录下2.Tools-->Preferences-->User Interface-->Editor-->AutoRe pl ace,选中Enable复选框,然后浏览文件选中之前创建的shortcuts.txt,点击Ap pl y3.重启PL/SQL Developer,在sql窗口中输入s+空格,w+空格,sc+空格做测试3.自动保存访问数据库的用户名和密码Tools->Preferences->Oracle->Logon History , 勾上"Store history"和"Store with passw ord" ,点击Ap pl y重新登录后就可以记住用户名密码了如果各位有好的使用技巧,希望发上来,共同分享1auto select & auto executePL/SQL DEVELOPER的自动选择,自动执行功能,我觉得用起来也特别的爽.只要启用了这个功能之后,你按F8(对应"执行"的快捷键,你就可以执行光标所在SQL 语句了,而不再需要先用鼠标选取需要执行的语句了.要启用这个功能,需要先设置一下.Tools->Preferences->SQL Window,将AutoExecute que ries和AutoSelect statement这两项选中,即可.2PL/SQL Beautifier(代码格式化当我们在写SP的时候一般都会使用这个咚咚,这样会让代码更易懂易读,附件中我整理了一个模板,大家可以直接导入即可;支持的功能为:关键字大写、变量小写、自动对齐、INSERT/SELECT单字段换行……3代码段高亮在SP Window中,将鼠标放在左边对应的声明上,右边就会出现对应的代码段高亮显PL/SQL Developer记住登陆密码在使用PL/SQL Developer时,为了工作方便希望PL/SQL Developer记住登录Oracle的用户名和密码;2 、执行单条SQL语句在使用PL/SQL Developer的SQL Window 时,按F8 键, PL/SQL Developer默认是执行该窗口的所有SQL语句,需要设置为鼠标所在的那条SQL语句,即执行当前SQL语句;3 、格式化SQL语句在使用PL/SQL Developer的SQL Window 时,有时候输入的SQL语句太长或太乱,希望能用比较通用的写法格式话一下,这样看起来会好看些,也好分析;使用方法:选中需要格式化的SQL语句,然后点击工具栏的PL/SQL beautifier 按钮即可 .4 、查看执行计划在使用PL/SQL Developer的SQL Window 时,有时候输入的SQL语句执行的效率,分析下表结构,如何可以提高查询的效率,可以通过查看Oracle 提供的执行计划;使用方法:选中需要分析的SQL语句,然后点击工具栏的Ex pl ain pl an 按钮(即执行计划,或者直接按F5 即可.5 、调试存储过程在使用PL/SQL Developer操作Oracle 时,有时候调用某些存储过程,或者调试存储过程;调用存储过程的方法:首先,在PL/SQL Developer左边的Browser 中选择Procedures ,查找需要调用的存储过程;然后,选中调试的存储过程,点击右键,选择Test ,在弹出来的Tes t scrīpt 窗口中,对于定义为in 类型的参数,需要给该参数的Value 输入值;最后点击上面的条数按钮: Start debugger 或者按F9 ;最后点击: RUN 或者Ctrl+R .(具体要调式一个存储过程,请参照操作手册,这个大概说明下应用.6、oralce精简客户端的使用要想PL/SQL连接oracle数据库,除了PL/SQL Developer之外还需要Oracle客户端,有一个更方便的方法就是使用Oracle精简客户端,很多地方可以下载,文件很小,耗资源也少.安装完成后修改安装目录下的\Oracle\ora90\network\ADMIN\tnsnames.ora文件:格式如下:DATABASE_NAME =(DESCRIPTION =(ADDRESS_LIST =#(SERVICE_NAME = dealer(SID = SID_NAME#(SERVER = DEDICATED以下的技巧只针对PL/SQL Developer6以上版本,版本5只有其中的部分特性.1,右键菜单在PL/SQL Developer(下面简称PL D中的每一个文本编辑窗口,如SQL Window,Comman d Window和Porgram Window,右键点击某个对象名称,会弹出一个包含操作对象命令的菜单,我们这里称之为右键菜单.如下图:对象类型可以是表,视图,同义词,存储过程和函数等.根据对象类型的不同,弹出的菜单也有区别.表和视图有View, Edit, Rename,Drop, Query data 和Editdata等功能.View和Edit分别是查看和修改表的结构信息,如字段,主键,索引和约束等.Quer ydata相当于新打开一个窗口,并执行select * from 表.Edit data相当于新打开一个窗口,并执行select * from表for update.存储过程和函数有Test功能,选中后可以进入调试状态.有时由于PL D识别错误,右键点击对象并不能出来正确的菜单,可以在对象所在的DDL或D ML语句的前面,加上分号,这样PL D就能正确的判断出对象的类型2,Select for Update有时我们需要把一些数据导入数据库中,如果用UE拼Insert语句,会比较麻烦,而且操作性不强.PL D的SQLWindow可以查询,新增,修改和删除表的内容.查询自不必说,而新增,删除和修改,只需在sele ct语句后加入forupdate,对表进行行级锁定,然后点击窗口的锁型图标,即可进入编辑状态.下面介绍一下如何从Excel中提取文本插入到数据库中我们的Excel文件中有三列:在数据库中建立临时表:create table t1 (cino varchar2(100, contno varchar2(100, loanno varchar2(100然后在SQL Window中输入select t1 for update,并点击锁型鼠标,进入编辑状态:用鼠标点击第一行的输入窗口,这时PL D会死锁几秒钟,然后可以见到光标在第一行的输入框中闪动,用鼠标把CINO, CONTNO, LOANNO选中:进入Excel中,把需要插入数据库的内容选中,然后切换到PL D,按Ctrl + V:点击√,然后再点击Commit按钮,则数据提交到表t1中,执行select * from t1可以看到内容: 3,PL/SQL BeautifierPL D 6以上版本有对DML代码格式化的功能.在SQL Window或ProgramWindow中选中部分代码(如果不选则对整个窗口的代码操作,在菜单中选Edit àPL/SQL Beautifier,得到格式化的代码.对于非法的DML语句或DDL语句,PL D将会在下方状态栏提示PL/SQL Beautifiercould not parse text. 在缺省的状态下,PLD 会把 DML 语句的每一个字段都排在单独的一行,这样不方便查看.在菜单中选 Edit à PL/SQL Beautifier Options,进入Preferences 窗口,选择 Edit,进入配置文件编辑界面: 在标签栏选 DML,在窗口中部的Select, Insert 和 Update 组框中把 Fit 选中,然后点击 Save,把配置文件保存到 PLD 的安装目录下, 点击 Close 关闭.在 Rules file 中输入配置文件所在位置,点击 OK,完成配置文件切换.这时再对代码进行格式化,就可以使每一个字段尽可能的在一行上了. 4,TNS Names 菜单 Help à Support Info à TNS Names,可以查看 Oracle 的 tnsnames.ora. 5,Copy to Excel 在 SQL Window 中执行 Select 语句,在结果出来以后,右键点击下面的数据区,选择 Copy to Excel,可以把数据区的记录原样拷贝到 Excel 中.但有两点需要注意:一,field 中不能以=开始, 否则 Excel 会误认为是函数;二,数字不要超过 17 位,否则后面的位数将会置为 0,但可以通过在数字前加'来使 Excel 认为该 field 是文本,同时对于数据库中 Numbe 类型的字段,最好用 to_char 输出,不然可能会显示不正常。
plsql developer 用法

PL/SQL Developer是一个集成开发环境,专门用于Oracle PL/SQL程序设计。
以下是如何使用PL/SQL Developer的简要说明:
打开PL/SQL Developer并登陆,选择要连接的数据库。
在对象浏览器窗口界面中,找到“my object”,此处为当前登陆的用户的所有object。
在“my object”里,找到“table”文件夹,里边显示了当前账户的所有表格。
选中需要查看的表,右键点击,选中“查询数据”,即可查看数据。
打开sql window,即可在此窗口内输入sql语句,全选后点击执行即可看到结果。
选中表,右键点击,可以编辑对表进行编辑。
以上信息仅供参考,具体用法可能会因版本和具体需求略有不同。
如果在使用过程中遇到问题,建议查阅PL/SQL Developer的官方文档或寻求专业人士的帮助。
plsql的set语句用法_概述说明以及解释

plsql的set语句用法概述说明以及解释1. 引言1.1 概述本文将重点介绍和解释PL/SQL的SET语句的用法。
PL/SQL是Oracle数据库中一种编程语言,用于存储过程、触发器和函数等对象的开发。
SET语句作为PL/SQL中最基本且常用的语句之一,具有灵活性和强大功能,在数据处理和逻辑控制方面起到了重要作用。
1.2 文章结构本文主要分为五个部分。
首先是引言部分,对文章进行概要介绍。
接下来是PL/SQL的SET语句的基本用法及使用场景进行详细讲解。
然后是对SET语句的详细说明和示例,包括赋值操作符、条件判断和逻辑运算符以及查询子句和聚合函数的使用方法。
第四部分将通过应用实例分析SET语句在PL/SQL编程中的具体应用,涵盖更新表中记录、处理游标数据集合以及执行动态SQL操作等方面。
最后是总结与展望部分,对PL/SQL的SET语句进行优势特点总结,并展望未来其在PL/SQL开发中的趋势与发展。
1.3 目的本文旨在全面阐述和解释PL/SQL的SET语句用法,并通过实例演示其在实际应用中的作用。
通过阅读本文,读者将能够掌握SET语句的基本语法和使用场景,了解SET语句中赋值操作符、条件判断和逻辑运算符以及查询子句和聚合函数的使用方法。
此外,读者还将通过应用实例的分析了解如何使用SET语句来更新表中的记录、处理游标数据集合以及执行动态SQL操作。
最后,在总结与展望部分,读者将对PL/SQL的SET语句有更全面和深入的认识,并对未来其在PL/SQL开发中的趋势与发展有一定预期。
2. PL/SQL的SET语句用法2.1 什么是PL/SQL的SET语句PL/SQL的SET语句是一种用于在程序中设置变量值或表字段值的命令。
它提供了一种简单而有效的方法来更新数据或执行计算操作。
2.2 SET语句的基本语法PL/SQL中的SET语句通常由关键字SET、要设置值的目标对象以及赋予该对象新值组成。
SET语句可以用于设置各种类型的变量或数据库表字段。
plsql使用技巧

plsql使用技巧PL/SQL是Oracle数据库的一种编程语言,可以用于编写存储过程、触发器、函数等程序。
本文将从以下几个方面介绍PL/SQL的使用技巧:一、变量和常量的使用1.1 变量的定义在PL/SQL中,可以使用DECLARE语句来定义变量。
例如:DECLAREv_name VARCHAR2(100);BEGINv_name := 'John';END;1.2 常量的定义在PL/SQL中,可以使用CONSTANT关键字来定义常量。
例如:DECLAREc_pi CONSTANT NUMBER := 3.1415926;BEGINNULL;END;1.3 变量和常量的命名规则在PL/SQL中,变量和常量的命名规则与其他编程语言类似。
变量和常量的名称必须以字母开头,并且只能包含字母、数字和下划线。
二、条件语句的使用2.1 IF语句IF语句用于根据条件执行不同的代码块。
例如:DECLAREv_age NUMBER := 18;BEGINIF v_age >= 18 THENDBMS_OUTPUT.PUT_LINE('You are an adult.');ELSEDBMS_OUTPUT.PUT_LINE('You are a minor.');END IF;END;2.2 CASE语句CASE语句用于根据不同情况执行不同代码块。
例如:DECLAREv_day_of_week NUMBER := 5;BEGINCASE v_day_of_weekWHEN 1 THEN DBMS_OUTPUT.PUT_LINE('Monday');WHEN 2 THEN DBMS_OUTPUT.PUT_LINE('Tuesday');WHEN 3 THEN DBMS_OUTPUT.PUT_LINE('Wednesday'); WHEN 4 THEN DBMS_OUTPUT.PUT_LINE('Thursday'); WHEN 5 THEN DBMS_OUTPUT.PUT_LINE('Friday');ELSE DBMS_OUTPUT.PUT_LINE('Weekend');END CASE;END;三、循环语句的使用3.1 FOR循环FOR循环用于执行一组代码块一定次数。
PLSQL批量插入单条、多条数据过程
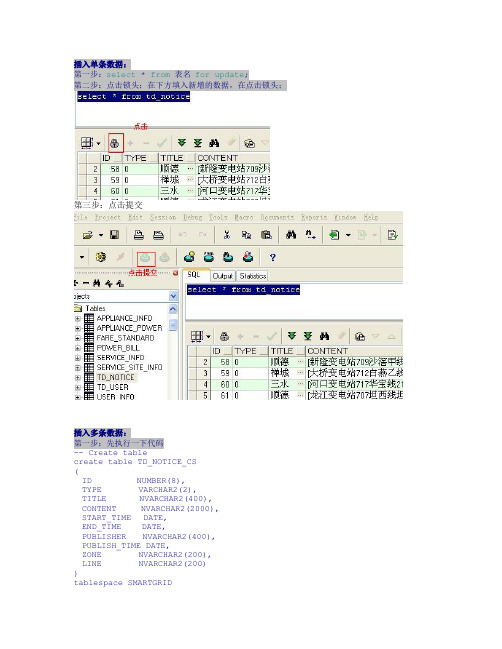
插入单条数据:第一步:select * from表名for update;第二步:点击锁头;在下方填入新增的数据,在点击锁头;第三步:点击提交插入多条数据:第一步:先执行一下代码-- Create tablecreate table TD_NOTICE_CS(ID NUMBER(8),TYPE VARCHAR2(2),TITLE NVARCHAR2(400),CONTENT NVARCHAR2(2000),START_TIME DATE,END_TIME DATE,PUBLISHER NVARCHAR2(400),PUBLISH_TIME DATE,ZONE NVARCHAR2(200),LINE NVARCHAR2(200))tablespace SMARTGRIDpctfree 10initrans 1maxtrans 255storage(initial 64Kminextents 1maxextents unlimited);第二步:执行select*from TD_NOTICE_CS for update;点击锁头,把excel数据复制黏贴进去,确定数据与字段对应没错之后,再按锁头锁住,点击提交第三步:执行以下语句:select * from TD_NOTICE_CS;查询到有你需要插入的数据之后再进行第四步;第四步:执行以下语句:insert into TD_NOTICE(ID,TYPE,TITLE,CONTENT,START_TIME,END_TIME,PUBLISHER,PUBLISH_TIME,ZONE,LINE)select ID,TYPE,TITLE,CONTENT,START_TIME,END_TIME,PUBLISHER,PUBLISH_TIME,ZONE,LINEfrom TD_NOTICE_cs执行成功后,点击“提交按钮”就可以了select max(id) from TD_NOTICEselect min(id) from TD_NOTICE_CSselect max(id) from TD_NOTICE_CSselect * from TD_NOTICE_CS for update。
plsql procedure用法

PL/SQL Procedure用法PL/SQL(Procedural Language/Structured Query Language)是一种编程语言,用于编写存储过程、触发器、函数和包等数据库对象。
PL/SQL Procedure是其中的一种类型,它是一段预定义的可重复使用的代码块,可以接收输入参数并返回结果。
在本文中,我们将深入探讨PL/SQL Procedure的用法,包括创建、调用、参数传递和异常处理等方面。
创建PL/SQL Procedure在Oracle数据库中,可以使用CREATE PROCEDURE语句创建PL/SQL Procedure。
下面是一个创建简单PL/SQL Procedure的示例:CREATE OR REPLACE PROCEDURE calculate_salary (emp_id IN NUMBER)ASsalary NUMBER;BEGIN-- 根据员工ID查询薪水SELECT salary INTO salary FROM employees WHERE employee_id = emp_id;-- 输出薪水信息DBMS_OUTPUT.PUT_LINE('Employee ID: ' || emp_id);DBMS_OUTPUT.PUT_LINE('Salary: ' || salary);END;/上述代码创建了一个名为calculate_salary的PL/SQL Procedure,它接收一个输入参数emp_id,并根据该参数查询员工的薪水信息并输出。
在创建过程时,可以使用CREATE OR REPLACE关键字,以便在已存在同名过程时进行替换。
调用PL/SQL Procedure调用PL/SQL Procedure可以使用EXECUTE或EXEC关键字,后跟过程名和参数。
以下是调用上述示例过程的示例:EXECUTE calculate_salary(1001);在调用过程时,需要传递与过程定义中参数类型和顺序匹配的参数值。
PLSQL安装配置和使用说明

PLSQL安装配置和功能说明1.PLSQL简介PL/SQL Developer是一个集成开发环境,专门面向Oracle数据库存储程序单元的开发。
如今,有越来越多的商业逻辑和应用逻辑转向了Oracle Server,因此,PL/SQL编程也成了整个开发过程的一个重要组成部分。
PL/SQL Developer侧重于易用性、代码品质和生产力,充分发挥Oracle应用程序过程中的主要优势。
2.PLSQL安装以如下图所示的软件版本为例点击安装,安装完成之后通常需要注册注册码;根据所需码进行注册(产品号、序列码、密码……)当然也可以通过上网进行搜索相关注册所需信息。
3.PLSQL使用3.1.PLSQL使用前提条件Pl/sql 在正常使用前必须有oracle数据库环境,(安装oracle服务器端或者客户端数据库软件)。
以安装了oracle11g客户端软件环境为例3.1.1.tnsnames连接找到tnsnames.ora文件,如图所示:在安装的oracle数据库文件夹:F:app\liu\product\11.1.0\db_1\NETWORK\ADMIN\tnsnames.ora不管是oracle的10g还是11g版本,主要是找到标红的文件夹本例子完整的路径如下:F:\app\liu\product\11.1.0\db_1\NETWORK\ADMIN\tnsnames.ora3.1.2.tnsnames 配置打开tnsnames.ora文件进行编辑在文件中增加如下内容:MISSDDB =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = 10.6.0.241)(PORT = 1521))(CONNECT_DATA =(SID = orcl)))或者OPIDSSCK_231 =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = 10.6.0.231)(PORT = 1521))(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = opids) ))添加这两段的目的是增加两个数据库的连接(MISSDDB 、OPIDSSCK_231 )如图:3.2.PLSQL常用功能3.2.1.登陆当打开PL/SQL Developer时,直接在“登录”对话框中输入用户名、密码、数据库(本地网络服务名)和连接为的身份(除了sys用户需要选择连接为sysdba之外,其他用户都选择标准/Normal)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
如何在plsql程序处理批量数据.Author: Wenxing.zhongDate: 2008-05-29在ebao的应用程序中,有很多的业务需要通过pl/sql程序来处理,每天晚上可能要运行多个job来处理当天,当周或者当月的数据;这些后台批处理pl/sql程序在业务数据量比较少的场合基本能够在一个晚上的时间内跑完,但是随着客户业务数据量的不断增长,部分pl/sql程序的执行时间不断的增长,以至于一个晚上跑不完影响业务系统白天的正常运行,引起客户不断的抱怨,给项目组带来比较大的压力;笔者在income和taiping项目的优化中,经历了其中的许多案例,现把优化过程中的一些体会写下来,供各个项目组参考;在和开发人员的交流中,开发人员不断向我抱怨,数据量太多了,我们没有办法提高程序的处理速度,我们必须一条一条数据来进行处理,因为里面有很多的业务逻辑处理,真的没有办法吗,不,有,只是我们没有发现,下面我罗列出一些针对批量处理的方法,希望能够抛砖引玉,给各个开发人员开阔一些思路;批量数据处理的一些方法:1,使用oracle批量处理的特性,如forall,bulk collect ;2,使用临时表来储存常用的一些数据,避免对大表的多次访问;3,使用多个job来并行处理;4,优化sql,提高sql的执行效率;一:使用oracle批量处理特性:(1)bulk collect 的使用:在ebao的程序中经常会有这样的程序:先声明一个游标CURSOR c_policy_fee ISSELECT *FROM t_policy_fee where xxxxx=xxxx;然后For cur_rec in c_policy_fee loop业务处理End loop;在游标获取的数据量较大的场合考虑用如下的方法:TYPE id_type IS TABLE OF t_policy_fee.id%TYPE;TYPE description_type IS TABLE OF t_policy_fee.description%TYPE;t_id id_type;t_description description_type;BEGINSELECT id, descriptionBULK COLLECT INTO t_id, t_description FROM t_policy_fee;For I in id.first st loop业务处理End loop;我们可以做一个测试,来看看两者速度的差异:SQL> create table tst_policy_fee as select * from t_policy_fee where rownum<1000000;SQL>Table createdExecuted in 15.625 secondsSQL>SQL> DECLARE2 TYPE id_type IS TABLE OF tst_policy_fee.fee_id%TYPE;3 TYPE description_type IS TABLE OFtst_policy_fee.FINISH_TIME%TYPE;45 t_id id_type := id_type();6 t_description description_type := description_type();78 CURSOR c_data IS9 SELECT fee_id,FINISH_TIME10 FROM tst_policy_fee;11 BEGIN12 FOR cur_rec IN c_data LOOP13 t_id.extend;14 t_description.extend;1516 t_id(t_st) := cur_rec.fee_id;17 t_description(t_st) := cur_rec.FINISH_TIME;18 END LOOP;19 END;20 /SQL>PL/SQL procedure successfully completedEx ecuted in 7.343 secondsSQL>SQL> DECLARE2 TYPE id_type IS TABLE OF tst_policy_fee.fee_id%TYPE;3 TYPE description_type IS TABLE OFtst_policy_fee.FINISH_TIME%TYPE;45 t_id id_type;6 t_description description_type;7 BEGIN8 SELECT fee_id,FINISH_TIME9 BULK COLLECT INTO t_id, t_description FROM tst_policy_fee;10 END;11 /PL/SQL procedure successfully completeExecuted in 2.282 seconds可以看出速度有提高,也许有人说这样并没有显著的提高,不过,在循环处理中,从cache中取数据和从游标中取数据还是有区分的;Bulk collect主要是为了提高批量查询的速度,当然如果数据量不大,性能就体现不出来了;(2)使用forall特性:Forall主要提高批量insert,update,delete操作;对批量插入的操作:在ebao的程序中,可能有如下的一些需求:For cur_red in cursor1 loop业务处理Insert into tablexx values(xx,xx,xx);End loop;在数据量少的场合,觉得没有问题,但是数据量一旦到5万,10万。
性能就会有影响了,其实我们这里可以用到批量插入的方法:如:先声明一个typetype tab_interim_trans is table of t_tps_gl_interim_trans%rowtype index by binary_integer;tab_interim_trans_rec tab_interim_trans;For cur_red in cursor1 loop业务处理给tab_interim_trans_rec(i) 填充值;End loop;Forall I IN 1.. tab_interim_trans_rec.COUNTINSERT INTO t_tps_gl_interim_trans VALUEStab_interim_trans_rec(i);如以下的测试:常规100万数据的插入速度测试:SQL> DECLARE2 CURSOR c_data IS3 SELECT fee_id,FINISH_TIME4 FROM tst_policy_fee;5 BEGIN6 FOR cur_rec IN c_data LOOP7 insert into tst_forall(fee_id,finish_time)values(cur_rec.fee_id,cur_rec.finish_time);8 END LOOP;9 commit;10 END;11 /SQL>PL/SQL procedure successfully completedExecuted in 53.062 seconds使用oracle 特性100万数据的插入速度测试:SQL> DECLARE2 i pls_integer :=0;3 type tab_tst_forall is table of tst_forall%rowtype index by binary_integer;4 tab_tst_forall_rec tab_tst_forall;5 CURSOR c_data IS6 SELECT fee_id,FINISH_TIME7 FROM tst_policy_fee;8 BEGIN9 FOR cur_rec IN c_data LOOP10 i :=i +1;11 tab_tst_forall_rec(i).fee_id:=cur_rec.fee_id;12 tab_tst_forall_rec(i).FINISH_TIME:=cur_rec.FINISH_TIME;13 END LOOP;14 forall i in 1..tab_tst_forall_rec.count15 insert into tst_forall values tab_tst_forall_rec(i);16 commit;17 END;18 /PL/SQL procedure successfully completedExecuted in 17.344 seconds我们测试用的表的字段较少,在实际生产上,性能能够提高的更多。
对于批量更新的操作:在我们的程序中,存在如下的需求:For cur_red in cursor1 loop业务处理Update table1 set x=x+1 where …….End loop;在和开发人员的交流中,开发人员向我抱怨,我们这个没有办法优化,因为我需要用到循环中的值来做更新;其实不然,我们可以用一些type对象或者临时表来把用来更新的值先存储起来,如下:For cur_red in cursor1 loop业务处理Insert into temp values(1,xx,xx);或者:给temp_tbl充值;End loop;Select * bulk collect into temp_tbl from temp;Forall I in 1..temp_tbl.countUpdate tablexx set col1=temp_tbl(i).col1 wherecol2=temp_tbl(i).col2常规的批量更新100万数据:SQL>SQL> DECLARE2 m_fee_id tst_policy_fee.fee_id%TYPE;3 CURSOR c_data IS4 SELECT fee_id5 FROM tst_policy_fee;6 BEGIN7 FOR cur_rec IN c_data LOOP8 m_fee_id:= cur_rec.fee_id;9 update tst_policy_fee set finish_time=sysdate wherefee_id=m_fee_id;10 END LOOP;11 END;12 /PL/SQL procedure successfully completedExecuted in 379.266 seconds使用oracle特性的批量更新100万数据:SQL> DECLARE2 TYPE fee_id_type IS TABLE OF tst_policy_fee.fee_id%TYPE;3 fee_id_tbl fee_id_type;4 BEGIN5 SELECT fee_id6 BULK COLLECT INTO fee_id_tbl FROM tst_policy_fee;7 forall i in 1..fee_id_tbl.count8 update tst_policy_fee set finish_time=sysdate wherefee_id=fee_id_tbl(i);9 END;10 /SQL>SQL>SQL>PL/SQL procedure successfully completedExecuted in 204.735 seconds二:使用临时表来避免对大表的多次访问在我们的程序中,经常看到这种现象,先从表table1获取到一些数据,然后循环去访问大表,但其实在这个循环中,只用到了大表中的部分数据,如只是查询t_policy_fee表中10月份的数据;在这种情况下,我们可以考虑在循环外先把这部分数据存放到一个临时表中(注意:只需要把用到的字段存放到临时表即可):如:在循环中,有如下的sql:select tpf.fee_id,tpf.policy_type,tpf.fee_type from t_policy_fee tpfwhere tpf.finish_time >= to_date(‘20080701’)and tpf.finish_time < to_date(‘20080701’)+ 1and tpf.posted = 'N'and tpf.cred_id is nulland tpf.fee_status in (6, 1);我们可以修改成:在循环还,用一个临时表把数据先插入到一个临时表中:insert into t_tpf_policy_fee select tpf.fee_id,tpf.policy_type,tpf.fee_type fromt_policy_fee tpfwhere tpf.finish_time >= i_start_dateand tpf.finish_time < i_end_date + 1and tpf.posted = 'N'and tpf.cred_id is nulland tpf.fee_status in (6, 1);然后在循还中访问临时表t_tpf_policy_fee;三:使用多个job并发运行业务处理我们可能会碰到这样的一个场景,从一个大表中抽取出100万数据,然后需要逐条对这100万数据进行处理,而且这个循还操作没有办法避免,那我们其实可以考虑把这100万数据分为4部分,然后用四个job并发运行,这样相当于每个job只需要运行25万数据,可以提高3/4的时间,但是这样操作必须有一个限制,就是db服务器的cpu必须要由多个,能够启动的job数取决于服务器的cpu个数,一般job数可以设置为(num of cpu -1 );四:提高程序中sql的执行效率在我们很多pl/sql程序中,可能处理的数据量不多,但是批处理还是运行比较长的时间,很有可能是我们程序中存在一些性能不佳的sql,我们可以把这些sql单独拿出来运行并请dba进行相关的优化;。