Hadoop-0.20.2详细安装及疑难问题
在 Ubuntu 上安装Hadoop-0.20.2 教程

在Ubuntu 上安装Hadoop 教程实践环境:U buntu8.04+jdk1.6+hadoop-0.20.1 ( 三台实体机)机器名IP 作用Ubuntu01 192.168.0.4 NameNode 、master 、jobTrackerUbuntu02 192.168.0.3 DataNode 、slave 、taskTracker1 、安装ubuntu8.04更新源修改2 、安装jdk1.6sudo apt-get install sun-java6-jdk(物理机可能安装不上,直接下载jdk安装jdk-1_5_0_14-linux-i586.bin文件安装# chmod a+x jdk-1_5_0_14-linux-i586.bin ←使当前用户拥有执行权限# ./jdk-1_5_0_14-linux-i586.bin ←选择yes直到安装完毕)安装后,添加如下语句到/etc/profile 中:export JA VA_HOME=/usr/lib/jvm/java-6-sunexport JRE_HOME=/usr/lib/jvm/java-6-sun/jreexport CLASSPATH=.:$JA V A_HOME/lib:$JRE_HOME/lib:$CLASSPATHexport PA TH=$JA V A_HOME/bin:$JRE_HOME/bin:$PA TH注意:每台机器的java 环境最好一致。
安装过程中如有中断,切换为root 权限来安装。
(7 、安装hadoop下载hadoop-0.20.1.tar.gz :$ wget /apache-mirror/hadoop/core/hadoop-0.20.2/hadoop-0.20.2.tar.gz解压:$ tar -zvxf hadoop-0.20.2.tar.gz把Hadoop 的安装路径添加到/etc/profile 中:export HADOOP_HOME=/home/wl826214/hadoop-0.20.2export PA TH=$HADOOP_HOME/bin:$PA TH8 、配置hadoophadoop 的主要配置都在hadoop-0.20. 2 /conf 下。
解决Hadoop使用中常见的问题

解决Hadoop使用中常见的问题在大数据时代,Hadoop已经成为了处理海量数据的重要工具。
然而,随着Hadoop的普及,一些常见的问题也随之出现。
本文将探讨这些问题并提供解决方案,帮助用户更好地使用Hadoop。
一、数据丢失问题在使用Hadoop时,数据丢失是一个常见的问题。
这可能是由于硬件故障、网络问题或软件错误引起的。
为了解决这个问题,我们可以采取以下措施:1. 数据备份:在Hadoop集群中,数据通常会被复制到多个节点上。
这样,即使一个节点发生故障,数据仍然可以从其他节点中恢复。
因此,我们应该确保数据的备份策略已经正确配置。
2. 定期监控:通过监控Hadoop集群的状态,我们可以及时发现并解决数据丢失的问题。
可以使用一些监控工具,如Ambari、Ganglia等,来实时监控集群的健康状况。
二、任务执行时间过长问题在处理大规模数据时,任务执行时间过长是一个普遍存在的问题。
这可能是由于数据倾斜、节点负载不均衡等原因引起的。
为了解决这个问题,我们可以采取以下措施:1. 数据倾斜处理:当某个任务的输入数据不均匀地分布在各个节点上时,会导致某些节点的负载过重,从而影响整个任务的执行效率。
我们可以通过数据倾斜处理算法,如Dynamic Partitioning、Salting等,将数据均匀地分布到各个节点上,从而提高任务的执行效率。
2. 节点负载均衡:通过调整Hadoop集群的配置,我们可以实现节点负载的均衡。
例如,可以使用Hadoop的资源管理器(ResourceManager)来动态分配任务给各个节点,从而使得节点的负载更加均衡。
三、数据安全问题随着大数据的快速发展,数据安全问题变得尤为重要。
在Hadoop中,数据安全主要包括数据的保密性和完整性。
为了解决这个问题,我们可以采取以下措施:1. 数据加密:我们可以使用Hadoop提供的加密功能来保护数据的机密性。
可以使用Hadoop的加密文件系统(HDFS Encryption)来对数据进行加密,从而防止未经授权的访问。
Hadoop使用常见问题以及解决方法

Hadoop使用常见问题以及解决方法1:Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out Answer:程序里面需要打开多个文件,进行分析,系统一般默认数量是1024,(用ulimit -a可以看到)对于正常使用是够了,但是对于程序来讲,就太少了。
修改办法:修改2个文件。
/etc/security/limits.confvi /etc/security/limits.conf加上:* soft nofile 102400* hard nofile 409600$cd /etc/pam.d/$sudo vi login添加 session required /lib/security/pam_limits.so针对第一个问题我纠正下答案:这是reduce 预处理阶段shuffle时获取已完成的map的输出失败次数超过上限造成的,上限默认为5。
引起此问题的方式可能会有很多种,比如网络连接不正常,连接超时,带宽较差以及端口阻塞等。
通常框架内网络情况较好是不会出现此错误的。
2:Too many fetch-failuresAnswer:出现这个问题主要是结点间的连通不够全面。
1) 检查、/etc/hosts要求本机ip对应服务器名要求要包含所有的服务器ip + 服务器名2) 检查 .ssh/authorized_keys要求包含所有服务器(包括其自身)的public key3:处理速度特别的慢出现map很快但是reduce很慢而且反复出现reduce=0% Answer:结合第二点,然后修改conf/hadoop-env.sh 中的export HADOOP_HEAPSIZE=40004:能够启动 datanode ,但无法访问,也无法结束的错误在重新格式化一个新的分布式文件时,需要将你NameNode上所配置的.dir 这一namenode用来存放NameNode持久存储名字空间及事务日志的本地文件系统路径删除,同时将各DataNode上的dfs.data .dir的路径DataNode存放块数据的本地文件系统路径的目录也删除。
hadoop安装及运行维护汇总小问题共13页word资料

windows安装hadoop博客分类:•hadoopWindowsHadoopJavaJDKMapreducehadoop是什么就不多说了,看这里hadoop推荐部署环境是在linux,但是我们想要在windows体验一下还是可以的,followme我的环境:windowsxp,hadoop安装包(0.20.1),cygwin打开cygwin Java代码1.explorer.把hadoop的包放到这个目录下然后输入命令Java代码1.tarzxfhadoop-0.20.1.tar.gz解压完成后进入hadoop-0.20.1的配置目录,打开core-site.xml,加入以下内容。
这里是定义namenode运行地址和端口Xml代码1.<property>2.<name></name>3.<value>hdfs://localhost:9000</value>4.</property>打开hdfs-site.xml,加入以下内容Java代码1.<property>2.<name>dfs.replication</name>3.<value>1</value>4.</property>这里把复制因子设置为1是因为我们在windows上做伪分布,只能启动一个datanode接下来可以定义namenode数据目录,和datanode数据目录。
当然这个不是必须的,默认是在/tmp目录下面Xml代码1.<property>2.<name>.dir</name>3.<value>c:/filesystem/name</value>4.</property>5.<property>6.<name>dfs.data.dir</name>7.<value>c:/filesystem/data</value>8.</property>最后修改hadoop-env.sh,把下面注释的这行打开,并设置为你的jdk路径。
hadoop安装配置指南

Hadoop安装、配置指南一、环境1、软件版本Hadoop:hadoop-0.20.2.Hive:hive-0.5.0JDK:jdk1.6以上版本2、配置的机器:主机[服务器master]:192.168.10.121 hadoop13从机[服务器slaves]:192.168.10.68 hadoop4在本文中,在命令或二、先决条件1、配置host:打开/etc/host文件,添加如下映射192.168.10.121 hadoop13 hadoop13192.168.10.68 hadoop4 hadoop42、配置SSH自动登陆1)以ROOT用户,登陆到[服务器master]上执行,如下操作:ssh-keygen -t rsa //一路回车cd ~/.sshcat id_rsa.pub >> authorized_keysscp -r ~/.ssh [服务器slaves]:~/2)以ROOT用户,登陆到[服务器slaves]上执行,如下操作:scp -r ~/.ssh [服务器master]:~/3)测试SSH是否配置成功在主服务器中执行如下命令:ssh [服务器master]ssh 192.168.10.68成功显示结果:Last login: Thu Aug 26 14:11:27 2010 from 在从服务器中执行如下命令:ssh [服务器slaves]ssh 192.168.10.121成功显示结果Last login: Thu Aug 26 18:23:58 2010 from 三、安装hadoop1、JDK安装,解压到/usr/local/jdk1.6.0_17,并配置/etc/profile环境export JAVA_HOME=/usr/local/jdk/jdk1.7.0export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre:$PATHexport CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jarJDK路径:/usr/local/jdk/jdk1.7.0export JAVA_HOME=/usr/local/jdk/jdk1.7.0export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre:$PATHexport CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar/usr/local/jdk/jdk1.7.02、下载Hadoop 并解压到[服务器master]的/root/zwmhadoop目录下tar zxvf hadoop-0.20.2.tar.gz四、配置hadoop1.配置主机[服务器master]到zwm hadoop/hadoop-0.20.2/ hadoop 目录下,修改以下文件:1)配置conf/hadoop-env.sh文件,在文件中添加环境变量,增加以下内容:export JAVA_HOME=/usr/local/jdk1.6.0_17export HADOOP_HOME=/root/zwmhadoop/hadoop-0.20.2/2)配置conf/core-site.xml文件,增加以下内容<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name></name><value>hdfs://192.168.10.121:9000</value>//你的namenode的配置,机器名加端口<description>The nam e of the default file system. Either the literal string "local" o r a host:port for DFS.</description></property></configuration>3)配置conf/hdfs-site.xml文件,增加以下内容<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>hadoop.t m p.dir</name><value>/root/zwmhadoop/t m p</value>//Hadoop的默认临时路径,这个最好配置,然后在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的t mp目录即可。
Hadoop伪分布式安装步骤(hadoop0.20.2版本)

Hadoop伪分布式安装步骤(hadoop0.20.2版本)最近在学习hadoop,⾃⼰下了个视频教程,他的教学版本是hadoop0.20.2版本,现在的最新版本都到了3.0了,版本虽然有点⽼,但是还是学了⼀下,觉得有借鉴的价值。
不废话了,开始介绍:先说⼀下环境:ubuntu14.04,其中要装上ssh open-server服务,装上jdk环境。
伪分布式模式安装和配置步骤如下图:详细步骤1 ⾸先把⽂件导⼊linux系统(我⽤的ubuntu虚拟机,hadoop-0.20.2.tar.gz安装包放在了桌桌⾯)。
⾸先把这个安装包放在/opt⽬录下,并解压:2 配置相关⽂件hadoop-env.sh⽂件配置(版本不同,⽂件位置可能不⼀样,hadoop0.20.2在/conf下)core-site.xml (/conf下)修改hdfs-site.xmlhdfs-site.xml配置⽂件中还有其他⼀些配置,此次配置没有⽤到,如下图:mapred-site.xml配置下图是mapred-site.xml其他⼀些配置,此次没⽤到,列到这⾥:注意:由于我布置的是伪分布式,只有⼀个节点(即本机),所以core-site.xml和mapred-site.xml两个配置⽂件中的相关ip地址是localhost,如果完全分布式部署,是要写相应的IP的。
另外,9000和9001是hadoop缺省端⼝,⼀般没必要修改。
ssh设置⾸先进⼊/root然后按照下图输⼊(让每个节点之间互通免密码)这样就⼤功告成啦完全分布式安装⼤致步骤如下:1 配置host⽂件2 简历hadoop运⾏账号3 配置ssh免密码连接4 下载hadoop并解压5 配置namenode,修改site⽂件6 配置hadoop-env.sh7 配置master和slaves⽂件8 向各节点复制hadoop9 格式化namenode10 启动hadoop11 ⽤jps检查阁后台进程是否成功启动后续:以上都是基于hadoop0.20.2版本的,属于⽐较过时的东西,推荐⼀个⼤神总结的hadoop2.6.0的安装和配置,写的很详细,⽽且也是正确的。
Hadoop的安装与环境搭建教程图解
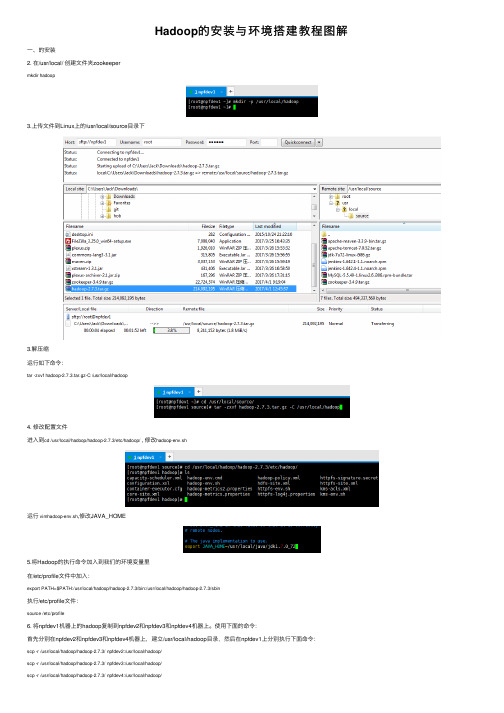
Hadoop的安装与环境搭建教程图解⼀、的安装2. 在/usr/local/ 创建⽂件夹zookeepermkdir hadoop3.上传⽂件到Linux上的/usr/local/source⽬录下3.解压缩运⾏如下命令:tar -zxvf hadoop-2.7.3.tar.gz-C /usr/local/hadoop4. 修改配置⽂件进⼊到cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop/ , 修改hadoop-env.sh运⾏vimhadoop-env.sh,修改JAVA_HOME5.将Hadoop的执⾏命令加⼊到我们的环境变量⾥在/etc/profile⽂件中加⼊:export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin执⾏/etc/profile⽂件:source /etc/profile6. 将npfdev1机器上的hadoop复制到npfdev2和npfdev3和npfdev4机器上。
使⽤下⾯的命令:⾸先分别在npfdev2和npfdev3和npfdev4机器上,建⽴/usr/local/hadoop⽬录,然后在npfdev1上分别执⾏下⾯命令:scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev2:/usr/local/hadoop/scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev3:/usr/local/hadoop/scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev4:/usr/local/hadoop/记住:需要各⾃修改npfdev2和npfdev3和npfdev4的/etc/profile⽂件:在/etc/profile⽂件中加⼊:export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin执⾏/etc/profile⽂件:source /etc/profile然后分别在npfdev1和npfdev2和npfdev3和npfdev4机器上,执⾏hadoop命令,看是否安装成功。
hadoop小型机群配置

HADOOP-0.20.2分布式集群配置本文以安装和使用hadoop-0.20.2为例。
硬件环境1.虚拟机VMWare Workstation 6.5.2build2.三台机器均安装redhat linux9.03.java jdk1.6.0_24node:192.168.1.100 hadoop1datanode:192.168.1.101 hadoop2datanode:192.168.1.102 hadoop3注意:三台机器dns 和默认网关必须一致。
登陆密码一致最好。
而且务必三台机器互相ping通主机,即主机名和ip解析正确。
若ping不通,修改/etc/hosts文件,使用sudo vi /etc/hosts 命令,设置如下(namenode):192.168.1.100hadoop1192.168.1.101hadoop2192.168.1.102hadoop3Hadoop2(datanode)的设置为:192.168.1.100 hadoop1192.168.1.101 hadoop2Hadoop3(datanode)的设置为:192.168.1.100 hadoop1192.168.1.102 hadoop3.本集群将namenode和jobtracker 设置成一台机器即hadoop1。
配置sshRedhat linux9 自带ssh。
开启命令:service sshd restart。
必须配置SSH使用无密码公钥来进行免密码登陆各个节点。
本集群设置如下:在namenode节点即hadoop1上根目录下执行:[root@hadoop1 root]$ssh-keygen –t dsa一路回车,遇到y/n 选择y。
即在默认目录下/root/.ssh/生成id_dsa 和id_dsa.pub 2个文件,第一个为私钥,第二个为公钥。
[root@hadoop1 root]$cd .ssh进入.ssh目录下,将id_dsa.pub 复制给authorized_keys文件,并给予权限。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
安装
2011年4月4日
10:13
Hadoop-0.20.2安装使用
1、Cygwin 安装 ssh
2、按照以下的文档配置ssh
在Windows上安装Ha
doop教程.pdf
3、几个配置文件的配置
3.1、conf/core-site.xml
<property>
<name></name>
<value>hdfs://localhost:9000</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/workspace/temp/hadoop/tmp/hadoop-
${}</value>
<final>true</final>
</property>
3.2、conf/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
<final>true</final>
</property>
<property>
<name>.dir</name>
<value>/workspace/temp/hadoop/data/hadoop/name</value>
<final>true</final>
</property>
<property>
<name>dfs.data.dir</name>
<value>/workspace/temp/hadoop/data/hadoop/data</value>
<final>true</final>
</property>
3.3、conf/mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
<final>true</final>
</property>
3.4、conf/hadoop-env.sh
export JAVA_HOME=D:/workspace/tools/jdk1.6
4、解决启动的时候 ClassNotFound: org.apache.hadoop.util.PlatformName
将 %hadoop_home%\bin\hadoop-config.sh中的第190行
修改为如下:
JAVA_PLATFORM=`CLASSPATH=${CLASSPATH} ${JAVA} -Xmx32m -classpath ${HADOOP_COMMON_HOME}/hadoop-common-0.21.0.jar
org.apache.hadoop.util.PlatformName | sed -e "s/ /_/g"`
5、命令
6、创建HBase文件夹
bin/hadoop dfs -mkdir Hbase
bin/hadoop dfs -mkdir tmp
http://localhost:50070/
http://localhost:50030/
1、修改bin/hbase-env.sh 中的
export JAVA_HOME
export HBASE_MANAGES_ZK=true
2、将conf/hbase-default.xml文件中的内容完全复制到conf/hbase-site.xml中
3、对conf/hbase-site.xml文件做如下修改:
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/workspace/temp/hadoop/tmp/hbase-${}</value>
<description>Temporary directory on the local filesystem.</description> </property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>127.0.0.1</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>
<description>Property from ZooKeeper's config zoo.cfg.
The port at which the clients will connect.
</description>
</property>
Hive-0.5.0安装和使用
一、创建Hive所需目录
bin/hadoop dfs -mkdir /user/hive/warehouse
bin/hadoop dfs -mkdir /tmp
bin/hadoop dfs -chmod g+w /user/hive/warehouse
bin/hadoop dfs -chmod g+w /tmp
二、修改bin/hive-config.sh文件,增加以下内容
export HIVE_HOME=/cygdrive/d/workspace/tools/hadoop/run/hive export HADOOP_HOME=/cygdrive/d/workspace/tools/hadoop/run/hadoop。