数据仓库与数据集市
数据仓库的逻辑模型

数据仓库的逻辑模型介绍
数据仓库是一种面向主题的、集成的、稳定的、不同时间的数据集合,用于支持管理决策过程。
逻辑模型是数据仓库的核心,它描述了数据仓库中数据的组织和存储方式,以及数据仓库的结构和功能。
本文将介绍数据仓库的逻辑模型,包括数据仓库的数据源、数据存储、数据集市和数据访问。
一、数据源
数据仓库的数据源可以是多种类型的,包括关系数据库、OLAP 数据库、文件系统、外部数据源等。
不同的数据源具有不同的特点和优势,需要根据实际情况选择合适的数据源。
二、数据存储
数据仓库的数据存储是指将数据源中的数据加载到数据仓库中,并对数据进行处理和转换,以满足数据仓库的需求。
数据存储通常采用分布式存储架构,以支持大量数据的存储和查询。
三、数据集市
数据集市是数据仓库中面向特定主题的数据集合,它将数据仓库中的数据按照业务需求进行分类和组织。
数据集市通常包括多个表,每个表代表一个主题,例如销售、客户、产品等。
数据集市中的数据可以根据业务需求进行查询和分析。
四、数据访问
数据访问是指数据仓库中的数据如何被访问和使用。
数据仓库的数据访问通常采用OLAP(联机分析处理)和数据挖掘技术。
OLAP技术支持用户对数据仓库中的数据进行快速查询和分析,数据挖掘技术则可以帮助用户从大量数据中发现有价值的信息和规律。
总之,数据仓库的逻辑模型是数据仓库的核心,它描述了数据仓
库中数据的组织和存储方式,以及数据仓库的结构和功能。
数据仓库的数据源、数据存储、数据集市和数据访问是数据仓库逻辑模型的重要组成部分,它们共同构成了一个完整的数据仓库系统。
数据仓库和数据集市的区别

数据仓库和数据集市的区别数据仓库与数据集市看了很多数据仓库方面的资料,都涉及到了“数据集市”这一说法,刚开始对数据仓库和数据集市的区别也理解得比较肤浅,现在做个深入的归纳和总结,主要从如下几个方面进行阐述:(1) 基本概念(2) 为什么提出数据集市(3) 数据仓库设计方法论(4) 数据集市和数据仓库的区别(5) 仓库建模与集市建模(6) 案例分析:电信CRM数据仓库Bill Inmon说过一句话叫“IT经理们面对最重要的问题就是到底先建立数据仓库还是先建立数据集市”,足以说明搞清楚这两者之间的关系是十分重要而迫切的!通常在考虑建立数据仓库之前,会涉及到如下一些问题:(1) 采取自上而下还是自下而上的设计方法(2) 企业范围还是部门范围(3) 先建立数据仓库还是数据集市(4) 建立领航系统还是直接实施(5) 数据集市是否相互独立一、基本概念数据仓库一词尚没有一个统一的定义,著名的数据仓库专家W. H. Inmon 在其著作《Buildingthe Data Warehouse》一书中给予如下描述:数据仓库(Data Warehouse) 是一个面向主题的(SubjectOri2ented) 、集成的( Integrate ) 、相对稳定的(Non -Volatile ) 、反映历史变化( TimeVariant) 的数据集合用于支持管理决策。
对于数据仓库的概念我们可以从两个层次予以理解,首先,数据仓库用于支持决策,面向分析型数据处理,它不同于企业现有的操作型数据库;其次,数据仓库是对多个异构的数据源有效集成,集成后按照主题进行了重组,并包含历史数据,而且存放在数据仓库中的数据一般不再修改。
为最大限度地实现灵活性,集成的数据仓库的数据应该存储在标准RDBMS 中,并经过规范的数据库设计,以及为了提高性能而增加一些小结性信息和不规范设计。
这种类型的数据仓库设计被称为原子数据仓库。
原子数据仓库的子集,又称为数据集市。
大数据:数据仓库和数据集市的比较

大数据:数据仓库和数据集市的比较随着科技的发展,数据成为了当下最热门的话题之一。
随着互联网的普及和各行各业的信息化建设与发展,数据规模与数据类型也日益增加。
面对如此巨大的数据量,如何正确地处理和分析数据,如何从中发现有价值的信息,也日益成为了各个企业必须面对的挑战。
在处理这些大数据时,数据仓库和数据集市是两种常见的数据存储和分析方式。
本文将详细比较数据仓库和数据集市的优缺点。
一、数据仓库数据仓库是指将企业内部不同系统中的数据进行收集和汇总,形成一个一致且具有高性能的数据存储库,并且保证数据的一致性、可更新性和可查询性。
数据仓库的主要特点:1、定期批量更新数据:数据仓库通常会对企业内部的数据进行定期批量的更新,而且一般是在业务量相对较小时进行。
2、面向历史:数据仓库主要面向数据的历史信息,针对的是过去的数据。
3、专注于查询:在数据仓库中,主要对数据进行查询操作。
4、主题导向:数据仓库是围绕着业务主题进行组织的,它包含了企业整个业务的各个方面。
数据仓库的优点:1、高效性:基于数据仓库的数据分析拥有更高的业务性能,用于大量数据处理时更加简单、高效。
2、数据一致性好:由于数据仓库的数据集中存储,因此能够保证数据的一致性。
3、适用于大型企业:数据仓库的搭建需要较高的成本,会考虑到企业经营的全局信息。
数据仓库的缺点:1、对实时更新的需求差:数据仓库的数据一般是较为静态的,更新时延相对较高。
2、对数据的一致性要求高:数据仓库在数据插入、更新、删除等操作上的成本相对更高,因此数据的一致性也更加重视。
3、可变性不强:数据仓库在建库时便需要考虑到全局信息,所以数据的构建相对比较稳定。
二、数据集市数据集市是指将企业内部不同系统中的数据进行收集,然后根据需要进行分类、整合、清洗、分析等操作,组成具有相同语义的业务数据集合,提供给业务部门,以支持各个业务部门的分析需求和决策需要。
数据集市的主要特点:1、实时更新:数据集市需要及时更新数据,这样业务部门才能随时获取到最新的数据信息。
详解数据仓库和数据集市:ODS、DW、DWD、DWM、DWS、ADS
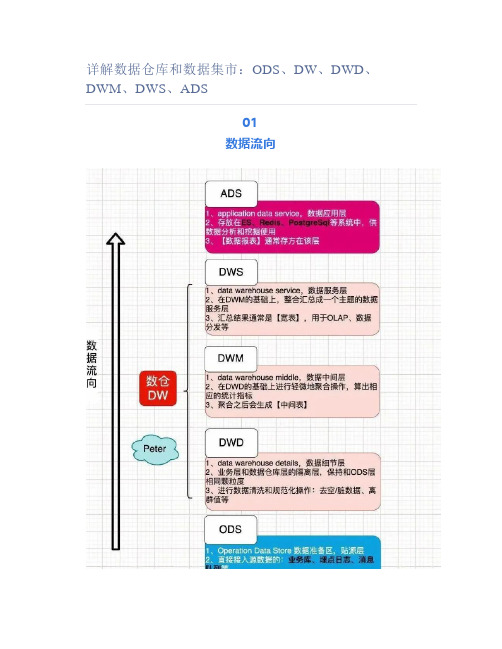
详解数据仓库和数据集市:ODS、DW、DWD、DWM、DWS、ADS01数据流向02应用示例03何为数仓DWData warehouse(可简写为DW或者DWH)数据仓库,是在数据库已经大量存在的情况下,它是一整套包括了etl、调度、建模在内的完整的理论体系。
数据仓库的方案建设的目的,是为前端查询和分析作为基础,主要应用于OLAP(on-line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
目前行业比较流行的有:AWS Redshift,Greenplum,Hive等。
数据仓库并不是数据的最终目的地,而是为数据最终的目的地做好准备,这些准备包含:清洗、转义、分类、重组、合并、拆分、统计等主要特点•面向主题▪操作型数据库组织面向事务处理任务,而数据仓库中的数据是按照一定的主题域进行组织。
▪主题是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通过与多个操作型信息系统相关。
•集成▪需要对源数据进行加工与融合,统一与综合▪在加工的过程中必须消除源数据的不一致性,以保证数据仓库内的信息时关于整个企业的一致的全局信息。
(关联关系)•不可修改▪DW中的数据并不是最新的,而是来源于其他数据源▪数据仓库主要是为决策分析提供数据,涉及的操作主要是数据的查询•与时间相关▪处于决策的需要数据仓库中的数据都需要标明时间属性与数据库的对比•DW:专门为数据分析设计的,涉及读取大量数据以了解数据之间的关系和趋势•数据库:用于捕获和存储数据04为何要分层数据仓库中涉及到的问题:1.为什么要做数据仓库?2.为什么要做数据质量管理?3.为什么要做元数据管理?4.数仓分层中每个层的作用是什么?5.…...在实际的工作中,我们都希望自己的数据能够有顺序地流转,设计者和使用者能够清晰地知道数据的整个声明周期,比如下面左图。
但是,实际情况下,我们所面临的数据状况很有可能是复杂性高、且层级混乱的,我们可能会做出一套表依赖结构混乱,且出现循环依赖的数据体系,比如下面的右图。
数据仓库-数据集市-BI-数据分析-介绍

数据仓库-数据集市-BI-数据分析-介绍数据仓库数据集市BI数据分析介绍在当今数字化的时代,数据已经成为企业和组织最宝贵的资产之一。
如何有效地管理、分析和利用这些数据,以获取有价值的信息和洞察,成为了摆在众多企业面前的重要课题。
在这个过程中,数据仓库、数据集市、商业智能(BI)和数据分析等技术和概念发挥着至关重要的作用。
接下来,让我们一起深入了解一下这些概念。
数据仓库,简单来说,就是一个用于存储和管理企业数据的大型数据库系统。
它的目的是将来自不同数据源(如操作系统、数据库、文件等)的数据整合到一个统一的、一致的环境中,以便进行分析和决策支持。
数据仓库中的数据通常是经过清洗、转换和集成的,以确保数据的质量和一致性。
它采用了特定的架构和技术,如星型模式、雪花模式等,来优化数据的存储和查询性能。
数据仓库就像是一个大型的数据仓库,将各种各样的数据收集起来,经过整理和分类,以便后续的使用。
与数据仓库密切相关的是数据集市。
数据集市可以看作是数据仓库的一个子集,它专注于特定的业务领域或主题,例如销售数据集市、客户数据集市等。
数据集市的数据来源于数据仓库,经过进一步的筛选和加工,以满足特定业务部门或用户的需求。
数据集市的规模通常比数据仓库小,但更具针对性和灵活性,能够更快地提供相关的数据和分析结果。
接下来,我们谈谈商业智能(BI)。
BI 是一套用于将数据转化为有价值的信息和知识的技术和工具。
它包括数据报表、数据可视化、数据挖掘、联机分析处理(OLAP)等功能。
通过 BI 系统,用户可以以直观的方式查看和分析数据,从而发现数据中的趋势、模式和关系。
BI 帮助企业管理层做出更明智的决策,提高企业的竞争力和运营效率。
例如,通过数据报表,管理层可以清晰地了解企业的销售业绩、成本支出等情况;通过数据可视化,复杂的数据可以以图表、地图等形式展现,更容易理解和分析。
数据分析则是一个更广泛的概念,它涵盖了从数据收集、数据处理、数据分析到结果解释和报告的整个过程。
人力资源管理实践中的数字化应用有哪些

人力资源管理实践中的数字化应用有哪些在当今数字化时代,企业的人力资源管理领域正经历着深刻的变革。
数字化技术的广泛应用为人力资源管理带来了新的机遇和挑战,从招聘与选拔到员工培训与发展,从绩效管理到员工关系管理,数字化的身影无处不在。
接下来,让我们深入探讨一下人力资源管理实践中的数字化应用。
一、招聘与选拔中的数字化应用1、智能招聘系统企业可以利用智能招聘系统,如招聘网站、招聘 APP 等,发布职位信息,吸引潜在候选人。
这些平台通常具备强大的搜索和筛选功能,能够根据设定的条件,如学历、工作经验、技能等,快速筛选出符合要求的简历。
2、人才库管理通过数字化手段建立企业的人才库,将过往的求职者、潜在候选人以及内部员工的信息进行整合和管理。
当有新的职位需求时,可以在人才库中快速搜索和匹配合适的人选。
3、视频面试视频面试工具的出现打破了地域限制,让招聘双方能够更加便捷地进行交流。
同时,一些视频面试平台还具备录制、分析等功能,帮助面试官更全面地评估候选人的表现。
4、人工智能评估利用人工智能技术对候选人的简历、面试表现进行评估和预测。
例如,通过自然语言处理技术分析简历中的关键词和语句,判断候选人的专业能力和工作经验;通过面部表情和语音分析,评估候选人的情绪稳定性和沟通能力。
二、培训与发展中的数字化应用1、在线学习平台企业可以搭建在线学习平台,提供丰富的课程资源,员工可以根据自己的需求和兴趣自主选择学习内容。
这种方式打破了时间和空间的限制,让员工能够随时随地进行学习。
2、虚拟现实(VR)和增强现实(AR)培训对于一些需要实际操作和体验的培训,如技能培训、安全培训等,VR 和 AR 技术能够提供沉浸式的学习环境,让员工更加直观地感受和掌握相关知识和技能。
3、学习管理系统(LMS)LMS 可以对员工的学习过程进行跟踪和管理,包括学习进度、考试成绩、培训反馈等。
通过数据分析,企业能够了解员工的学习情况,针对性地提供支持和改进培训方案。
数仓的标准层

数仓的标准层
数仓的标准层通常分为以下四层:
1.ODS层(临时存储层):为接口数据的临时存储区域,为后一步的数据处理做准备。
一般来说,ODS层的数据和源系统的数据是同构的,主要目的是简化后续数据加工处理的工作。
2.PDW层(数据仓库层):数据应该是清洗后、准确且一致的数据。
这层的数据一般遵循数据库第三范式,其数据粒度通常和ODS的粒度相同。
3.MID层(数据集市层):这层数据是面向主题来组织数据的,通常是星形或雪花结构的数据。
从数据粒度来说,这层的数据是轻度汇总级的数据,已经不存在明细数据了。
4.APP层(应用层):这层数据是完全为了满足具体的分析需求而构建的数据,也是星形或雪花结构的数据。
从数据粒度来说是高度汇总的数据。
数仓的标准分层只是一个建议性质的标准,实际实施时需要根据实际情况确定数据仓库的分层,不同类型的数据也可能采取不同的分层方法。
数据仓库数据集市概念区别

数据仓库数据集市概念区别数据集市≠数据仓库NCR公司可扩展数据仓库解决⽅案⼩组王闯⾈编译我们知道,决策⽀持系统(DSS)主要有两种实现⽅式,即建⽴⼀个数据集市或者⼀个数据仓库。
到底哪⼀种更能满⾜决策⽀持的要求并且适合企业今后的发展,是近两年来学术界和有关供应商激烈争论的⼀个话题。
在数据集市领域,主要的供应商和拥护者以美国红砖(Red Brick)公司为代表,其总裁Ralph Kimball在1997年12⽉的⼀篇论⽂中提出,"数据仓库只不过是⼀些数据集市的集合⽽已"。
认为企业多建⽴⼀些数据集市,将来⾃然就形成了数据仓库。
⽽业界公认的数据仓库之⽗ Bill Inmon在今年1⽉⽴即撰⽂反驳,旗帜鲜明地指出,"你可以在⼤海中捕到很多的⼩鱼并堆积起来,但它们仍然不是鲸"。
在5⽉份的《数据管理综述》(DataManage ment Review)中,Bill Inmon⼜发表了"数据集市不等于数据仓库"的论⽂,进⼀步阐述两者在本质上的区别以及各⾃的适⽤场合,本⽂就是根据这篇论⽂的主要内容编译⽽成的。
问题的提出现在,各企业IT部门的经理所⾯临的最主要问题之⼀是先建⽴数据仓库还是先建⽴数据集市。
长期以来,数据集市供应商们不断地给他们灌输这样的观念,即建⽴数据仓库⽐较复杂,投资过⼤,设计与开发周期太长,难以集成和管理企业范围内的各种源数据;并认为,基于数据仓库的DSS投资⽅案难以得到企业管理层的批准。
数据集市供应商们给业界描绘了⼀幅数据仓库前景暗淡的图画,这完全是出于⾃⾝的⽬的,是不正确的。
数据集市供应商们把数据仓库当成其增加营业收⼊的绊脚⽯,⾃然要避开和攻击数据仓库。
事实上,他们在销售时强调数据集市的建设周期短,是以企业信息系统结构的长期规划为代价的。
持数据集市主张的⼈认为,决策⽀持系统的成功实现,除了数据仓库以外,还有更简便、更有效的其它途径。
⽅法之⼀就是建⽴多个数据集市,当它们增加得⾜够⼤时,那就是所谓的数据仓库了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据仓库与数据集市看了很多数据仓库方面的资料,都涉及到了“数据集市”这一说法,刚开始对数据仓库和数据集市的区别也理解得比较肤浅,现在做个深入的归纳和总结,主要从如下几个方面进行阐述:看了很多数据仓库方面的资料,都涉及到了“数据集市”这一说法,刚开始对数据仓库和数据集市的区别也理解得比较肤浅,现在做个深入的归纳和总结,主要从如下几个方面进行阐述:()基本概念()为什么提出数据集市()数据仓库设计方法论()数据集市和数据仓库的区别()仓库建模与集市建模()案例分析:电信数据仓库说过一句话叫“IT经理们面对最重要的问题就是到底先建立数据仓库还是先建立数据集市”,足以说明搞清楚这两者之间的关系是十分重要而迫切的!通常在考虑建立数据仓库之前,会涉及到如下一些问题:()采取自上而下还是自下而上的设计方法()企业范围还是部门范围()先建立数据仓库还是数据集市()建立领航系统还是直接实施()数据集市是否相互独立一、基本概念数据仓库一词尚没有一个统一的定义著名的数据仓库专家在其著作《》一书中给予如下描述数据仓库是一个面向主题的、集成的I、相对稳定的、反映历史变化T的数据集合用于支持管理决策。
对于数据仓库的概念我们可以从两个层次予以理解首先数据仓库用于支持决策面向分析型数据处理它不同于企业现有的操作型数据库其次数据仓库是对多个异构的数据源有效集成集成后按照主题进行了重组并包含历史数据而且存放在数据仓库中的数据一般不再修改。
为最大限度地实现灵活性,集成的数据仓库的数据应该存储在标准中,并经过规范的数据库设计,以及为了提高性能而增加一些小结性信息和不规范设计。
这种类型的数据仓库设计被称为原子数据仓库。
原子数据仓库的子集又莆菁小T硬挚獯嬖诘闹饕康氖亲魑菁械墓8:骰。
币沧魑握招允莶挚狻T硬挚獾拇笮12.写娣藕褪菘馍杓瓶赡芪薹闾厥饫嘈陀没y母髦中枨蟆F渥蛹即各个数据集市被拷贝到其它计算机上可作为它们自己的数据仓库。
数据集市可以和产生它们的原子数据仓库一样大甚至更大。
它们可以位于原子数据仓库的附近,或分布到更靠近用户的位置,放置在何处取决于使用和通讯成本。
数据集市是用来满足特殊用户的应用需求的数据仓库,它们的规模可能达到数百。
使其成为数据集市的关键是它的使用目标、范围,而非规模大小。
数据集市可以理解为是一个小型的部门或者工作组级别的数据仓库。
有两种类型的数据集市(如下图):□□□□□this加esized=true;this加tyie加idth=5oo;}"四加独立型(直接从操作型环境中获取数据):这些数据集市是由特定的工作组、部门或业务线进行控制的,完全是为满足其需求而构建的。
实际上,它们甚至与其他工作组、部门或业务线中的数据集市没有任何连通性口从属型(从企业级数据仓库中获取数据):这样的数据集市往往以分布式的方式实现。
虽然不同的数据集市是在特定的工作组、部门或生产线中实现的,但它们可以是集成、互连的,以提供更加全局的业务范围的数据视图。
实际上,在最高的集成层次上,它们可以成为业务范围的数据仓库。
这意味着一个部门中的终端用户可以访问和使用另一部门中数据集市中的数据口D二、为什么提出数据集市口虽然口OLTP口和遗留系统拥有宝贵的信息,但是可能难以从这些系统中提取有意义的信息并且速度也较慢。
而且这些系统虽然一般可支持预先定义操作的报表,但却经常无法支持一个组织对于历史的、联合的、智能的或易于访问的信息的需求。
因为数据分布在许多跨系统和平台的表中,而且通常是“脏的”,包含了不一致的和无效的值,使得难于分析。
口数据集市将合并不同系统的数据源来满足业务信息需求。
若能有效地得以实现,数据集市将可以快速且方便地访问简单信息以及系统的和历史的视图。
一个设计良好的数据集市有如下特点(有些特点数据仓库也具有,有些特点是相对于数据仓库来讲的):叫(皿特定用户群体所需的信息,通常是一个部门或者一个特定组织的用户,且无需受制于源系统的大量需求和操作性危机(想对于数据仓库)。
叫(皿支持访问非易变(nonvolatile)的业务信息。
(非易变的信息是以预定的时间间隔进行更新的,并且不受口OLTP口系统进行中的更新的影响。
)□口(3)口调和来自于组织里多个运行系统的信息,比如账目、销售、库存和客户管理以及组织外部的行业数据。
叫(皿通过默认有效值、使各系统的值保持一致以及添加描述以使隐含代码有意义,从而提供净化的(cleansed)数据。
口口(皿为即席分析和预定义报表提供合理的查询响应时间(由于数据集市是部门级的,相对于庞大的数据仓库来讲,其查询和分析的响应时间会大大缩短)。
口D三、数据仓库设计方法论口在数据仓库建立之前,会考虑其实现方法,通常有自顶向下、自底向上和两者综合进行的这样三种实现方案,下面分别对其做简要阐述:口(1)自顶向下的实现口自顶向下的方法就是在单个项目阶段中实现数据仓库。
自顶向下的实现需要在项目开始时完成更多计划和设计工作。
这就需要涉及参与数据仓库实现的每个工作组、部门或业务线中的人员。
要使用的数据源、安全性、数据结构、数据质量、数据标准和整个数据模型的有关决策一般需要在真正的实现开始之前就完成。
口(2)自底向上的实现口自底向上的实现包含数据仓库的计划和设计,无需等待安置好更大业务范围的数据仓库设计。
这并不意味着不会开发更大业务范围的数据仓库设计;随着初始数据仓库实现的扩展,将逐渐增加对它的构建。
现在,该方法得到了比自顶向下方法更广泛的接受,因为数据仓库的直接结果可以实现,并可以用作扩展更大业务范围实现的证明。
口(3)一种折中方案口每种实现方法都有利弊。
在许多情况下,最好的方法可能是某两种的组合。
该方法的关键之一就是确定业务范围的架构需要用于支持集成的计划和设计的程度,因为数据仓库是用自底向上的方法进行构建。
在使用自底向上或阶段性数据仓库项目模型来构建业务范围架构中的一系列数据集市时,您可以一个接一个地集成不同业务主题领域中的数据集市,从而形成设计良好的业务数据仓库。
这样的方法可以极好地适用于业务。
在这种方法中,可以把数据集市理解为整个数据仓库系统的逻辑子集,换句话说数据仓库就是一致化了的数据集市的集合。
这种方案的实施步骤通常分如下几步:口(皿从整个企业的角度定义计划和需求口(7)口构建完整的仓库体系结构口(皿使数据内容一致而且标准化口(皿将数据仓库作为一种超级数据集市来实施口关于inmon口和口Kimball的大辩论:口Ralph皿mba皿和口Bi皿inmon口一直是商业智能领域中的革新者,开发并测试了新的技术和体系结构。
口Bii皿nmon口将数据仓库定义为“一个面向主题的、集成的、随时间变化的、非易变的用于支持管理的决策过程的数据集合”;他通过“面向主题”表示应该围绕主题来组织数据仓库中的数据,例如客户、销售、产品等等。
每个主题区域仅仅包含该主题相关的信息。
数据仓库应该一次增加一个主题,并且当需要容易地访问多个主题时,应该创建以数据仓库为来源的数据集市。
换言之,某个特定数据集市中的所有数据都应该来自于面向主题的数据存储。
unmon口的方法包含了更多上述工作而减少了对于信息的初始访问。
但他认为这个集中式的体系结构持续下去将提供更强的一致性和灵活性,并且从长远来看将真正节省资源和工作。
下图是他的设计方法图解:口500){thisoresized=true;thisostyieowidth=50o;}"D/>DRaiPhDKimbaiio说“数据仓库仅仅是构成它的数据集市的联合”,他认为“可以通过一系列维数相同的数据集市递增地构建数据仓库”。
每个数据集市将联合多个数据源来满足特定的业务需求。
通过使用“一致的”维,能够共同看到不同数据集市中的信息,这表示它们拥有公共定口皿口皿的方法将提供集成的数据来回答组织迫切的业务问题并且要快于口inmon口的方法。
inmon口的方法是只有在构建几个单主题区域之后,集中式的数据仓库才创建数据集市。
而口□皿口皿认为该方法缺乏灵活性并且在现在的商业环境中所花时间太长。
叫实际上,方法的选择取决于项目的主要商业驱动。
如果该组织正忍受糟糕的数据管理和不一致的数据,或者希望为今后打下良好的基础,那么口inmon口的方法就更好一些。
口如果该组织迫切需要给用户提供信息,那么口皿口口皿的方法将满足该需求。
而一旦满足了迫切的信息需求后,就应该考虑包含独立数据仓库的数据体系结构的转换计划。
数据仓库将使数据集市与遗留系统和口OLTP口系统隔离,并且支持更快地创建将来的数据集市。
由于数据仓库在整个发展中一直承担了重任,所以它将支持极力关注数据集市。
实际上基于商业驱动的需要,采用上面三种设计方案中的最后一种方法:自顶向下和自底向上综合的方案会很好的适应数据仓库建立过程中的不同需求。
口四、数据仓库与数据集市的区别数据仓库是企业级的,能为整个企业各个部门的运行提供决策支持手段;而数据集市则是一种微型的数据仓库,它通常有更少的数据,更少的主题区域,以及更少的历史数据,因此是部门级的,一般只能为某个局部范围内的管理人员服务,因此也称之为部门级数据仓库。
数据仓库和数据集市之间的区别如下图:数据仓库和数据集市的区别可从如下三个方面进行理解:(1)数据仓库向各个数据集市提供数据(2)几个部门的数据集市组成一个数据仓库500){this.resized=true;this.style.width=500;}"resized="true"/>(3)下面从其数据内容特征进行分析,数据仓库中数据结构采用规范化模式,数据集市中的数据结构采用星型模式,通常仓库中数据粒度比集市的粒度要细,下图反映了数据结构和数据内容特征的区别数据仓库的数据结构数据集市的数据结构■N500){this.resized=true;this.style.width=500;}"resized="true"/>五、数据仓库建模与数据集市建模数据只是所有业务活动、资源以及企业结果的记录。
数据模型是对那些数据的组织良好的抽象,因此数据模型成为理解和管理企业业务的最佳方法是极其自然的。
数据模型起到了指导或计划数据仓库的实现的作用。
在真正的实现开始之前,联合每个业务领域的数据模型可以帮助确保其结果是有效的数据仓库,并且可以帮助减少实现的成本。
⑴数据仓库的建模数据仓库数据的建模是将需求转换成图画以及支持表示那些需求的元数据的过程。
出于易读性目的,本文将关于需求和建模的讨论相分离,但实际上这些步骤通常是重叠的。
一旦在文档中记录一些初始需求,初始模型就开始成型。
随着需求变得更加完整,模型也会如此。
最重要的是向终端用户提供良好集成并易于解释的数据仓库的逻辑模型。