死锁问题排查
死锁的排查方法

死锁的排查方法
死锁的排查主要有以下几种方法:
1. 资源分级:对系统中的各种资源(如CPU、内存、磁盘等)进行分级,
优先分配高级别的资源给进程。
2. 请求和保持:当一个进程在等待一个资源时,如果该资源被其他进程占用,则该进程请求其他空闲资源,并保持对已分配资源的占有,防止释放可能引起死锁的资源。
3. 饥饿策略:当一个进程等待时间过长而无法获得需要的资源时,由系统自动收回其已占有的资源,并在一段时间内不再分配给该进程。
4. 死锁检测与恢复:定期检测系统中是否存在死锁,如果存在则采取相应措施(如回滚、重试等)来解除死锁。
5. 避免死锁:通过一些算法(如银行家算法、避免循环等待等)来避免死锁的发生。
以上方法各有优缺点,实际应用中需要综合考虑各种因素选择适合的方法。
数据库死锁的检测与解决技巧

数据库死锁的检测与解决技巧数据库死锁是在多用户并发访问数据库时可能发生的一种情况,它会导致数据库无法继续正常执行操作。
在日常的数据库管理中,必须及时发现和解决死锁问题,以确保数据库的稳定性和可用性。
本文将介绍数据库死锁的检测与解决技巧。
一、死锁的定义与原因1. 死锁的定义:死锁是指两个或多个事务互相等待对方所持有的资源,而导致它们在无外力介入的情况下都无法继续执行的状态。
2. 死锁的原因:死锁通常发生在多个事务同时在数据库中申请资源时。
以下为常见的死锁原因:(1) 彼此互斥的资源:多个事务需要使用彼此互斥的资源。
(2) 事务保持资源并等待:一个事务保持资源并等待其他事务所持有的资源。
(3) 循环等待:多个事务形成一个闭环,每个事务等待下一个事务所持有的资源。
二、死锁的检测技巧1. 手动查询:可以通过查询系统视图或工具来检测是否存在死锁情况。
例如,在MySQL中,可以通过执行"show engine innodb status"命令来获取相关信息。
2. 使用系统工具:大多数数据库管理系统都提供了相关的工具来检测和解决死锁问题。
例如,在Oracle中,可以使用AWR报告来识别死锁情况。
3. 使用第三方工具:如果数据库管理系统的自带工具无法满足需求,可以考虑使用第三方工具来进行死锁检测。
一些常用的第三方工具包括Percona Toolkit和pt-deadlock-logger等。
三、死锁的解决技巧1. 重构数据库设计:死锁问题可能是由于数据库设计不合理导致的。
通过对数据库模式、索引和查询进行优化,可以减少死锁的发生概率,从而提高数据库的性能和可用性。
2. 事务隔离级别的选择:选择合适的事务隔离级别对于降低死锁的风险是至关重要的。
较高的隔离级别会导致更多的锁冲突和死锁发生机会,而较低的隔离级别可能影响数据的一致性和并发性。
需要在性能和数据一致性之间做出权衡选择。
3. 降低事务的持有时间:较长时间的事务可能会增加死锁的风险。
数据库死锁问题的排查与解决方法

数据库死锁问题的排查与解决方法引言:数据库死锁是在多个并发事务同时访问共享资源时经常会遇到的一个问题。
当两个或多个事务相互等待对方释放资源时,系统进入了死锁状态。
这导致事务无法继续执行,对生产系统的性能和可用性造成了严重影响。
因此,排查和解决数据库死锁问题对于确保系统的稳定运行至关重要。
本文将重点介绍数据库死锁问题的排查和解决方法。
一、什么是数据库死锁?数据库死锁是指两个或多个事务相互等待对方释放资源而无法继续执行的状态。
其中,每个事务都持有一部分资源,并且等待其他事务释放它们需要的资源。
当死锁发生时,没有任何一个事务能够继续执行,只能通过干预来解锁资源,打破死锁循环。
二、数据库死锁原因分析导致数据库死锁的原因通常可以归结为以下几个方面:1.事务并发性高:并发事务的同时访问和修改共享资源,容易导致死锁。
2.事务等待资源:当一个事务需要的资源已被其他事务占用时,会进入等待状态,如果等待的资源得不到释放,容易导致死锁。
3.资源争抢:不同事务之间竞争有限的资源,若资源分配不当,容易形成死锁。
三、数据库死锁排查方法1.使用数据库的死锁监控工具:现代数据库管理系统(DBMS)通常提供了监控死锁的工具。
通过使用这些工具,可以查看当前死锁的详细信息,如死锁链条和被锁定的资源等。
根据这些信息,可以定位死锁发生的位置,并进一步分析原因。
2.分析系统日志:通过分析数据库系统的日志,可以追踪事务的执行过程,查找是否有死锁相关的错误信息。
系统日志也会记录死锁发生时的相关信息,帮助我们了解死锁的原因。
3.使用性能监控工具:通过监控数据库系统的性能指标,如锁等待时间、阻塞的事务数量等,可以发现是否存在潜在的死锁问题。
这些工具可以帮助我们分析事务之间的竞争关系,进一步找到导致死锁的根本原因。
四、数据库死锁解决方法1.减少事务并发度:降低并发事务的数量,可以减少死锁的发生。
对于一些读写频繁、修改操作较多的事务,可以考虑对其进行优化,减少对共享资源的争抢。
MySQL死锁问题排查

MySQL死锁问题排查1.监控⽇志通过监控发现如下异常,尾随其后的还有报错相应的堆栈信息,指出了具体是哪个SQL语句发⽣了死锁com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transactionat com.***.***.im.service.platform.dao.impl.ImMessageDaoImpl.insert(ImMessageDaoImpl.java:50)at com.***.***.im.service.platform.service.impl.ImMessageServiceImpl.saveNewSessionMessage(ImMessageServiceImpl.java:543)通过⽇志查看代码,觉得不⼤可能是同⼀个事务并发执⾏导致的死锁2.查看隔离级别select @@tx_isolation; //当前session隔离级别select @@global.tx_isolation; //全局回话隔离级别业务代码有可能使⽤默认的隔离级别,默认的级别就是全局的隔离级别;业务也可能设置了当前事物的隔离级别,我们使⽤的默认级别,是RR(可重复读)3.查看最近⼀次innoDB监测的死锁联系DBA,查看发⽣死锁的业务对应的数据库,和innodb记录的死锁⽇志show engine innodb status;查询得到最近的⼀次死锁⽇志为:------------------------LATEST DETECTED DEADLOCK------------------------2019-04-01 23:32:49 0x7f6306adb700*** (1) TRANSACTION:TRANSACTION 23734694036, ACTIVE 1 sec starting index readmysql tables in use 1, locked 1LOCK WAIT 7 lock struct(s), heap size 1136, 25 row lock(s)MySQL thread id 7109502, OS thread handle 140046693021440, query id 5270358204 172.31.21.66 im_w1 updatingupdate im_servicer_sessionset unread_count=0where session_id=142298 and servicer_id=8708*** (1) WAITING FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 5351 page no 18 n bits 224 index PRIMARY of table `im`.`im_servicer_session` trx id 23734694036lock_mode X locks rec but not gap waitingRecord lock, heap no 148 PHYSICAL RECORD: n_fields 11; compact format; info bits 00: len 8; hex 00000000000006a4; asc ;;1: len 6; hex 000586b2b07f; asc ;;2: len 7; hex 27000002141d37; asc ' 7;;3: len 8; hex 0000000000022bda; asc + ;;4: len 8; hex 0000000000002204; asc " ;;5: len 1; hex 00; asc ;;6: len 5; hex 9943c20000; asc C ;;7: len 1; hex 00; asc ;;8: len 4; hex 00000003; asc ;;9: len 5; hex 99a2c37642; asc vB;;10: len 5; hex 99a2c37830; asc x0;;*** (2) TRANSACTION:TRANSACTION 23734694015, ACTIVE 1 sec insertingmysql tables in use 1, locked 14 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 2MySQL thread id 7108183, OS thread handle 140063290537728, query id 5270358482 172.31.35.143 im_w1 updateinsert into im_message_0_34( chat_id,message_type,message,house_id,send_time,send_status,receive_status,show_type )values ( '4NzP0DZO7wngS5YiGFcJTKu0L2Xrhan7zpbBBO/1KdQ=',0,'嗯嗯',106874,'2019-04-01 23:32:48.113',0,1,0 )*** (2) HOLDS THE LOCK(S):RECORD LOCKS space id 5351 page no 18 n bits 224 index PRIMARY of table `im`.`im_servicer_session` trx id 23734694015lock_mode X locks rec but not gapRecord lock, heap no 148 PHYSICAL RECORD: n_fields 11; compact format; info bits 00: len 8; hex 00000000000006a4; asc ;;1: len 6; hex 000586b2b07f; asc ;;2: len 7; hex 27000002141d37; asc ' 7;;3: len 8; hex 0000000000022bda; asc + ;;4: len 8; hex 0000000000002204; asc " ;;5: len 1; hex 00; asc ;;6: len 5; hex 9943c20000; asc C ;;7: len 1; hex 00; asc ;;8: len 4; hex 00000003; asc ;;9: len 5; hex 99a2c37642; asc vB;;10: len 5; hex 99a2c37830; asc x0;;*** (2) WAITING FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 5388 page no 1531 n bits 264 index idx_chat_id of table `im`.`im_message_0_34` trx id 23734694015lock_mode X locks gap before rec insert intention waitingRecord lock, heap no 110 PHYSICAL RECORD: n_fields 2; compact format; info bits 00: len 30; hex 344f69384254415559786c496a483947657577705071365a3764794f546e; asc 4Oi8BTAUYxlIjH9GeuwpPq6Z7dyOTn; (total 44 bytes);1: len 8; hex 00000000000069a0; asc i ;;*** WE ROLL BACK TRANSACTION (2)从⽇志中可以看到只是简单的记录排它锁(X lock),并⾮间隙锁(gap lock)。
Oracle常见死锁发生的原因以及解决方法

Oracle常见死锁发生的原因以及解决方法死锁是指在并发程序中,两个或多个进程因为争夺系统资源而陷入无限等待的状态,从而无法继续执行下去。
在Oracle数据库中,死锁是一个非常常见的问题,它会导致系统性能下降,甚至造成系统崩溃。
本文将详细介绍Oracle常见死锁发生的原因以及解决方法。
一、死锁发生的原因1.竞争资源:当多个进程同时请求相同的资源时,可能会导致死锁的发生。
例如,如果两个进程同时请求一个表的写锁,那么它们就会陷入死锁状态。
2.锁的顺序:当多个进程按照不同的顺序请求锁时,可能会导致死锁的发生。
例如,如果进程A先请求资源X,再请求资源Y,而进程B先请求资源Y,再请求资源X,那么它们就会陷入死锁状态。
3.锁的持有时间:当一个进程持有一个锁,并且在等待其他资源时继续保持该锁,可能会导致死锁的发生。
例如,如果进程A持有资源X的锁,并且在等待资源Y时继续保持该锁,而进程B持有资源Y的锁,并且在等待资源X时继续保持该锁,那么它们就会陷入死锁状态。
二、死锁的解决方法1. 死锁检测和解除:Oracle数据库提供了死锁检测和解除的机制。
当一个进程请求一个资源时,数据库会检查是否存在死锁。
如果存在死锁,数据库会选择一个进程进行回滚,解除死锁状态,并且通知其他进程重新尝试获取资源。
2.超时设置:为了避免死锁的发生,可以设置超时时间。
当一个进程请求一个资源时,如果在指定的超时时间内无法获取资源,那么就放弃该请求,并且释放已经持有的资源。
这样可以防止死锁的发生,但是会增加系统的开销。
3.锁的顺序:为了避免死锁的发生,可以规定所有进程按照相同的顺序请求锁。
例如,可以规定所有进程按照资源的名称进行排序,然后按照顺序请求锁。
这样可以避免死锁的发生,但是可能会影响系统的性能。
4.锁的粒度:为了避免死锁的发生,可以尽量减小锁的粒度。
例如,可以将一个大的锁分解成多个小的锁,这样可以减少锁的冲突,降低死锁的概率。
但是需要注意的是,锁的粒度过小可能会导致系统的性能下降。
死锁的原因及解决方法

死锁的原因及解决方法死锁是指在多道程序设计中,两个或多个进程因竞争系统资源而造成的一种僵局,导致它们都无法继续执行的状态。
死锁是计算机系统中常见的问题,它会严重影响系统的性能和稳定性。
因此,了解死锁的原因及解决方法对于保障系统的正常运行至关重要。
死锁的原因主要包括资源竞争、进程推进顺序不当、资源分配不当等。
首先,资源竞争是死锁产生的主要原因之一。
当多个进程同时竞争有限的资源时,可能会出现互相等待对方释放资源的情况,从而导致死锁的发生。
其次,进程推进顺序不当也是死锁的原因之一。
如果多个进程之间的资源申请和释放顺序不当,就有可能出现死锁的情况。
此外,资源分配不当也会导致死锁的发生。
当系统对资源的分配不合理时,可能会造成资源的浪费和死锁的产生。
针对死锁问题,我们可以采取一些解决方法来有效地预防和解决死锁。
首先,可以采用资源分配图来分析系统中可能出现的死锁情况,从而及时发现潜在的死锁问题。
其次,可以采用银行家算法来避免死锁的发生。
银行家算法是一种动态资源分配算法,它可以根据系统的资源情况来判断是否能满足进程的资源请求,从而避免死锁的发生。
此外,还可以采用资源剥夺和回滚来解决死锁问题。
资源剥夺是指当系统检测到死锁发生时,可以暂时剥夺某些进程的资源,以解除死锁情况。
而回滚则是指将系统恢复到死锁发生之前的状态,从而避免死锁的发生。
总之,死锁是计算机系统中常见的问题,它会严重影响系统的性能和稳定性。
了解死锁的原因及解决方法对于保障系统的正常运行至关重要。
我们可以通过资源分配图、银行家算法、资源剥夺和回滚等方法来预防和解决死锁问题,从而确保系统的稳定和高效运行。
死锁 和 解决死锁的方法

死锁和解决死锁的方法
死锁是指两个或多个进程因为相互等待对方所持有的资源而陷入无限等待状态,每个进程都在等待其他进程所持有的资源。
如果不采取措施解决死锁,系统将永远停滞下去。
解决死锁的方法有以下四种:
1. 预防死锁:通过合理规划资源的分配顺序,避免进程发生死锁。
例如,使用银行家算法预测系统的安全状态,判断在分配资源时是否会导致死锁的发生。
2. 避免死锁:基于资源需求量、可用资源量、已分配资源量等信息,动态地判断系统是否安全,是否存在死锁,从而避免死锁的发生。
例如,使用银行家算法,只有在系统安全状态才会分配资源,从而避免死锁的发生。
3. 检测死锁:为了避免死锁的发生,可以定期检测系统的资源分配状态,判断是否存在死锁。
一旦检测到死锁,可以通过回滚、剥夺资源等方法解除死锁。
例如,使用死锁检测算法来检测死锁并解除死锁。
4. 解除死锁:当检测到死锁时,可以采取解除死锁的措施,如剥夺某个进程所占用的资源、撤回某个进程的资源申请等,以解除死锁状态。
通常需要考虑到进程的优先级、资源占用量等因素,选择合适的解除死锁策略。
SQLSERVER数据库死锁的分析,排查
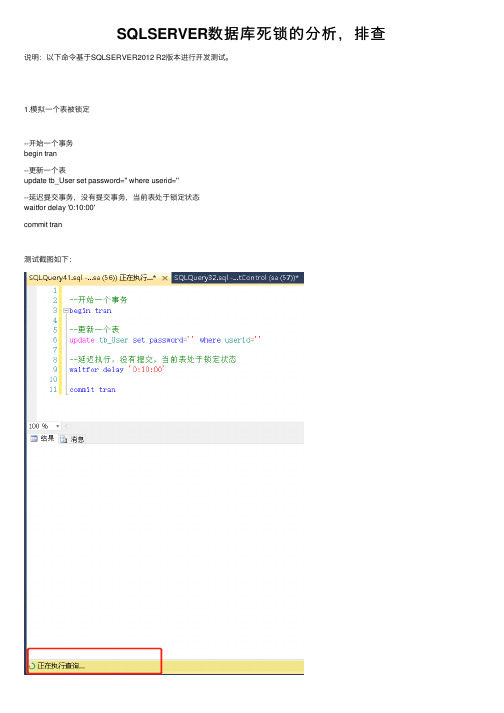
SQLSERVER数据库死锁的分析,排查说明:以下命令基于SQLSERVER2012 R2版本进⾏开发测试。
1.模拟⼀个表被锁定--开始⼀个事务begin tran--更新⼀个表update tb_User set password='' where userid=''--延迟提交事务,没有提交事务,当前表处于锁定状态waitfor delay '0:10:00'commit tran测试截图如下:2.怎么知道数据库哪些对象被锁定了?--查询被锁定的系统资源名称select request_session_id spid,OBJECT_NAME(resource_associated_entity_id) tableNamefrom sys.dm_tran_locks where resource_type='OBJECT'可以看到在会话ID为56的进程中,TB_User表被锁定了,测试截图如下:3.怎么查看该表做了什么操作被锁定,参与执⾏了什么Sql语句呢?根据上⾯的spid 我们根据以下脚本进⾏查询SELECT DEST.TEXTFROM sys.[dm_exec_connections] SDECCROSS APPLY sys.[dm_exec_sql_text](SDEC.[most_recent_sql_handle]) AS DESTWHERE SDEC.[most_recent_session_id] = 56我们可以看到因为执⾏了步骤1被锁定的,这样就找到了死锁的原因,测试截图如下:4.怎么解决死锁的问题?如果出现了死锁,我们也找到了问题所在,肯定是看我们执⾏的脚本是否有问题,并且进⾏改进。
但是如果我们想直接终⽌该进程,可以使⽤以下命令:5.在使⽤步骤2中的命令,查看被锁定的资源,发现刚才锁定的进程已经释放了,测试截图如下:以上就是怎么排查SqlServer中出现死锁,以及简单的解决办法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
死锁问题排查
1. 现象,队列报警开启依赖,充斥⼤量报警,⼤志显示死锁:
2. 抓取最近⼤次死锁记录,核⼤截图:
3. 分析
死锁本来是个⼤常简单的问题,只要保证并发内部顺序性,就能避免⼤部分,但是这个看起来似乎有点不⼤样,单个表同样的操作(全表扫描)死锁(理论上不应该)
tmp⼤表,记录较少,transaction 1 、2暴漏语句均⼤可⼤索引,全表记录锁定( n-key)
⼤志显示transaction 2 等待被锁定锁,transaction 1 等待被transaction 2锁定记录,造成死锁
但是问题是针对同⼤张表的顺序扫描加锁,为什么会死锁,百思不得姐,⼤度怀疑5.7版本加⼤了垃圾特性,根据现象看似乎是进⼤了锁表过程中的已加锁条⼤的跳跃,然后回来继续加锁,加剧了死锁可能,但是经过⼤晚上的求证也没发现该特性的踪迹
开始怀疑是⼤志展现的不全,还有别的因素加⼤,早上过来翻看代码,重新整理
了场景:
transaction 1⼤先执⼤(看id),锁定原有tmp记录
transaction 2 开始执⼤,⼤先进⼤了插⼤操作(⼤增,新插⼤的在后⼤),锁定后半部分
transaction 2 继续执⼤update操作,从头开始全表扫描,尝试锁定前半部分记录
transaction 1 继续执⼤,尝试锁定后半部分记录
此时1持有前部分,尝试获取后半部分锁,2持有后半部分(插⼤获得),尝试获取前半部分锁,互不相让,形成僵持
innodb检查锁定graph 1->2->1->2 形成环,确认死锁,报deadlock,查找回滚成本最低的transaction 1进⼤回滚,保证transaction 2的顺利进⼤
4. 解决问题
核⼤根源是
a. 全表锁定,极容易造成死锁
b. 表内锁定的⼤顺序性
破坏其⼤可以解决,简单办法,在条件上加索引,基本能保证不会锁定同样的记录
5. 总结
a. 根据某个点熟悉问题,排查验证可能性
b. 很多时候不可⼤,需要回过头来,根据上⼤的熟悉,从宏观上再看问题
c. 技术问题,特别是极端技术问题⼤多和具体业务强关联,要弄清楚具体业
务场景。