河北工业大学-数据结构实验报告-基于哈夫曼编码的通信系统的设计与实现
数据结构实验实验报告Huffman赫夫曼编码及应用

实验报告课程名称:数据结构实验名称:赫夫曼编码及应用院(系):计算机与通信工程学院专业班级:计算机科学与技术姓名:学号:指导教师:2020 年 5 月12 日一、实验目的掌握赫夫曼树和赫夫曼编码的基本思想和算法的程序实现。
二、实验内容及要求1、任务描述a.提取原始文件中的数据(包括中文、英文或其他字符),根据数据出现的频率为权重,b.构建Huffman编码表;c.根据Huffman编码表对原始文件进行加密,得到加密文件并保存到硬盘上;d.将加密文件进行解密,得到解码文件并保存点硬盘上;e.比对原始文件和解码文件的一致性,得出是否一致的结论。
2、主要数据类型与变量a.对Huffman树采用双亲孩子表示法,便于在加密与解密时的操作。
typedef struct Huffman* HuffmanTree;struct Huffman{unsigned int weight; //权值unsigned int p, l, r;//双亲,左右孩子};b.对文本中出现的所有字符用链表进行存储。
typedef struct statistics* List;struct statistics {char str; //存储此字符int Frequency; //出现的频率(次数)string FinalNum; //Huffman编码struct statistics* Next;};3、算法或程序模块对读取到的文本进行逐字符遍历,统计每个字符出现的次数,并记录在创建的链表中。
借助Huffman树结构,生成结构数组,先存储在文本中出现的所有字符以及它们出现的频率(即权值),当作树的叶子节点。
再根据叶子节点生成它们的双亲节点,同样存入Huffman树中。
在完成对Huffman树的创建与存储之后,根据树节点的双亲节点域以及孩子节点域,生成每个字符的Huffman编码,并存入该字符所在链表节点的FinalNum域。
哈夫曼编码译码系统实验报告,数据结构课程设计报告

v .. . ..安徽大学数据结构课程设计报告项目名称:哈弗曼编/译码系统的设计与实现姓名:鉏飞祥学号:E21414018专业:软件工程完成日期2016/7/4计算机科学与技术学院1 .需求分析1.1问题描述•问题描述:利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(解码)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
试为这样的信息收发站设计一个哈夫曼编译码系统。
1.2基本要求(1)输入的形式和输入值的范围;(2)输出的形式;(3)程序所能达到的功能。
1.基本要求(1)初始化(Initialzation)。
从数据文件DataFile.data中读入字符及每个字符的权值,建立哈夫曼树HuffTree;(2)编码(EnCoding)。
用已建好的哈夫曼树,对文件ToBeTran.data中的文本进行编码形成报文,将报文写在文件Code.txt中;(3)译码(Decoding)。
利用已建好的哈夫曼树,对文件CodeFile.data中的代码进行解码形成原文,结果存入文件Textfile.txt中;(4)输出(Output)。
输出DataFile.data中出现的字符以及各字符出现的频度(或概率);输出ToBeTran.data及其报文Code.txt;输出CodeFile.data及其原文Textfile.txt;2. 概要设计说明本程序中用到的所有抽象数据类型的定义。
主程序的流程以及各程序模块之间的层次(调用)关系。
(1)数据结构哈夫曼树的节点struct huff{int weight;int parent;int l;int r;};哈夫曼编码的存储struct huff *hufftree;(2)程序模块选择1到i-1中parent为0且权值最小的两个下标void Select(struct huff *HT, int n, int &s1, int &s2)构建哈夫曼树:void huffmancoding(struct huff *ht,int *w,int n)对原文进行编码:void code(char *c)根据报文找到原文:void decoding(char *zifu)3. 详细设计核心技术分析:1:构建哈夫曼树及生成哈夫曼编码:根据每个字符权值不同,根据最优二叉树的构建方法,递归生成哈夫曼树,并且用数组存放哈夫曼树。
数据结构哈夫曼编码实验报告

数据结构哈夫曼编码实验报告一、实验目的:通过哈夫曼编、译码算法的实现,巩固二叉树及哈夫曼树相关知识的理解掌握,训练学生运用所学知识,解决实际问题的能力。
二、实验内容:已知每一个字符出现的频率,构造哈夫曼树,并设计哈夫曼编码。
1、从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树。
2、打印每一个字符对应的哈夫曼编码。
3、对从终端读入的字符串进行编码,并显示编码结果。
4、对从终端读入的编码串进行译码,并显示译码结果。
三、实验方案设计:(对基本数据类型定义要有注释说明,解决问题的算法思想描述要完整,算法结构和程序功能模块之间的逻辑调用关系要清晰,关键算法要有相应的流程图,对算法的时间复杂度要进行分析)1、算法思想:(1)构造两个结构体分别存储结点的字符及权值、哈夫曼编码值:(2)读取前n个结点的字符及权值,建立哈夫曼树:(3)根据哈夫曼树求出哈夫曼编码:2、算法时间复杂度:(1)建立哈夫曼树时进行n到1次合并,产生n到1个新结点,并选出两个权值最小的根结点:O(n²);(2)根据哈夫曼树求出哈夫曼编码:O(n²)。
(3)读入电文,根据哈夫曼树译码:O(n)。
四、该程序的功能和运行结果:(至少有三种不同的测试数据和相应的运行结果,充分体现该程序的鲁棒性)1、输入字符A,B,C,D,E,F及其相应权值16、12、9、30、6、3。
2、输入字符F,E,N,G,H,U,I及其相应权值30、12、23、22、12、7、9。
3、输入字符A,B,C,D,E,F,G,H,I,G及其相应权值19、23、25、18、12、67、23、9、32、33。
哈夫曼编译码的设计与实现实验报告
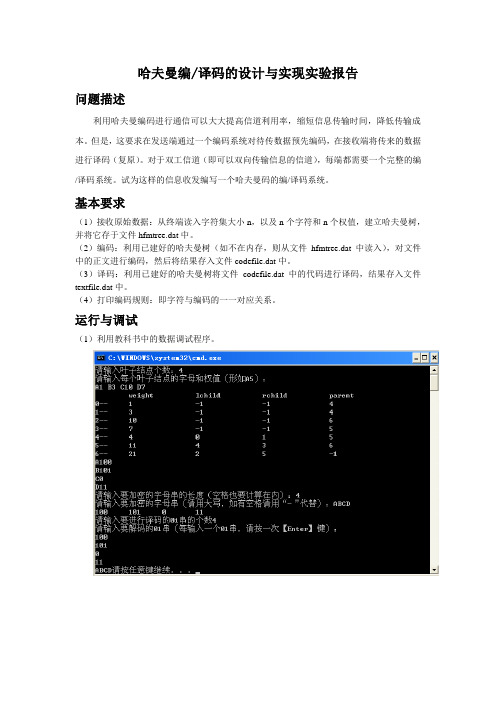
哈夫曼编/译码的设计与实现实验报告问题描述利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
试为这样的信息收发编写一个哈夫曼码的编/译码系统。
基本要求(1)接收原始数据:从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树,并将它存于文件hfmtree.dat中。
(2)编码:利用已建好的哈夫曼树(如不在内存,则从文件hfmtree.dat中读入),对文件中的正文进行编码,然后将结果存入文件codefile.dat中。
(3)译码:利用已建好的哈夫曼树将文件codefile.dat中的代码进行译码,结果存入文件textfile.dat中。
(4)打印编码规则:即字符与编码的一一对应关系。
运行与调试(1)利用教科书中的数据调试程序。
(2)用下表给出的字符集和频度的实际统计数据建立哈夫曼树,并实现以下报文的编码和译码:“THIS-PROGRAM-IS-MY-FA VORITE”。
字符 A B C D E F G H I J K L M 频度186 64 13 22 32 103 21 15 47 57 1 5 32 20 字符N O P Q R S T U V W X Y Z频度57 63 15 1 48 51 80 23 8 18 1 16 1实验小结通过这次实验,让我对于树的应用多了认识,在读取文件时,遇到的一些困难,不过在和同学交流的过程中,解决了这个问题,我觉的自己对于树及文件的应用又有了一些进步。
通过这次实验,感觉收获很大。
源程序// 哈夫曼编译码的设计与实现.cpp : 定义控制台应用程序的入口点。
//#include "stdafx.h"#include<iostream>#include<fstream>#include<string>#define Maxvalue 10000#define MAXBIT 200using namespace std;struct node{char letter;string num;};typedef struct{char letter;int weight; //结点权值int parent;int lchild;int rchild;}HnodeType;typedef struct{int bit[MAXBIT];int start;}HcodeType;HnodeType *HaffmanTree(int n){HnodeType *HuffNode;HuffNode=new HnodeType[2*n-1];int i,j;int m1,m2,x1,x2;for(i=0;i<2*n-1;i++) //数组HuffNode[]初始化{HuffNode[i].weight=0;HuffNode[i].parent=-1;HuffNode[i].lchild=-1;HuffNode[i].rchild=-1;}cout<<"请输入每个叶子结点的字母和权值(形如A5):"<<endl;for(i=0;i<n;i++)cin>>HuffNode[i].letter>>HuffNode[i].weight; //输入n个叶子结点的权值for(i=0;i<n-1;i++) //构造哈夫曼树{m1=m2=Maxvalue;x1=x2=0;for(j=0;j<n+i;j++) //选取最和次小两个权值{if(HuffNode[j].parent==-1&&HuffNode[j].weight<m1){m2=m1;x2=x1;m1=HuffNode[j].weight;x1=j;}else{if(HuffNode[j].parent==-1&&HuffNode[j].weight<m2){m2=HuffNode[j].weight;x2=j;}}}//将找出的两棵子树合并为一棵子树HuffNode[x1].parent=n+i;HuffNode[x2].parent=n+i;HuffNode[n+i].weight=HuffNode[x1].weight+HuffNode[x2].weight;HuffNode[n+i].lchild=x1;HuffNode[n+i].rchild=x2;}cout<<" weight"<<" lchild"<<" rchild"<<" parent"<<endl; for(i=0;i<2*n-1;i++)cout<<i<<"--"<<" "<<HuffNode[i].weight<<" "<<HuffNode[i].lchild<<" "<<HuffNode[i].rchild<<" "<<HuffNode[i].parent<<endl;ofstream outFile("hfmtree.dat",ios::out);if(!outFile)cerr<<"文件打开失败!"<<endl;else{outFile<<" weight"<<" lchild"<<" rchild"<<"parent"<<endl;for(i=0;i<2*n-1;i++)outFile<<i<<"--"<<" "<<HuffNode[i].weight<<""<<HuffNode[i].lchild<<" "<<HuffNode[i].rchild<<""<<HuffNode[i].parent<<endl;outFile.close();}return HuffNode;}void HaffmanCode(HnodeType *HuffNode,int n){HcodeType *HuffCode,cd;HuffCode=new HcodeType[2*n-1];int c,p,i,j;for(i=0;i<n;i++){cd.start=n-1;c=i;p=HuffNode[c].parent;while(p!=-1){if(HuffNode[p].lchild==c)cd.bit[cd.start]=0;elsecd.bit[cd.start]=1;cd.start--;c=p;p=HuffNode[c].parent;}for(j=cd.start+1;j<n;j++)HuffCode[i].bit[j]=cd.bit[j];HuffCode[i].start=cd.start;}for(i=0;i<n;i++){cout<<HuffNode[i].letter;for(j=HuffCode[i].start+1;j<n;j++)cout<<HuffCode[i].bit[j];cout<<endl;}ofstream outFile1("codefile.dat",ios::out|ios::binary);if(!outFile1)cerr<<"文件打开失败!"<<endl;else{for(i=0;i<n;i++){outFile1<<HuffNode[i].letter;for(j=HuffCode[i].start+1;j<n;j++)outFile1<<HuffCode[i].bit[j];outFile1<<endl;}outFile1.close();}}int _tmain(int argc, _TCHAR* argv[]){HnodeType *HuffNode;int n,i;cout<<"请输入叶子结点个数:";cin>>n;if(cin.fail()){cout<<"输入有误!"<<endl;return 0;}HuffNode=HaffmanTree(n);HaffmanCode(HuffNode,n);int num;cout<<"请输入要加密的字母串的长度(空格也要计算在内):";cin>>num;char *l1;char l;node l2[27];l1=new char[num];cout<<"请输入要加密的字母串(请用大写,如有空格请用“-”代替):";for(int n=0;n<num;n++)cin>>l1[n];ofstream outFile2("bianma.dat",ios::out|ios::binary);if(!outFile2)cerr<<"文件打开失败!"<<endl;else{for(i=0;i<num;i++)outFile2<<l1[i];outFile2.close();}ifstream inFile1("codefile.dat",ios::in|ios::binary);ifstream inFile2("bianma.dat",ios::in|ios::binary);cerr<<"读取文件失败!"<<endl;if(!inFile2)cerr<<"读取文件失败!"<<endl;else{while(inFile2.peek ()!=EOF){inFile2>>l;for(i=0;i<2*n-1;i++){inFile1>>l2[i].letter;inFile1>>l2[i].num;}for(i=0;i<n;i++){if(l2[i].letter==l)cout<<l2[i].num<<" ";}}inFile1.close();inFile2.close();}delete []l1;cout<<endl;int a;cout<<"请输入要进行译码的串的个数:";cin>>a;string *s;s=new string[a];cout<<"请输入要解码的串(每输入一个串,请按一次【Enter】键):"<<endl; for(i=0;i<a;i++)cin>>s[i];ofstream outFile4("yima.dat",ios::out);if(!outFile4)cerr<<"文件打开失败!"<<endl;else{for(i=0;i<a;i++)outFile4<<s[i]<<endl;outFile4.close();}ifstream inFile3("codefile.dat",ios::in|ios::binary);cerr<<"读取文件失败!"<<endl;else{for(i=0;i<2*n-1;i++){inFile3>>l2[i].letter;inFile3>>l2[i].num;}ifstream inFile4("yima.dat",ios::in);if(!inFile4)cerr<<"读取文件失败!"<<endl;else{for(int j=0;j<a;j++)inFile4>>s[j];}for(int j=0;j<a;j++){for(i=0;i<n;i++){if(l2[i].num==s[j])cout<<l2[i].letter;}}inFile3.close();}return 0;}。
数据结构哈夫曼编码实验报告

数据结构哈夫曼编码实验报告数据结构哈夫曼编码实验报告1·实验目的1·1 理解哈夫曼编码的基本原理1·2 掌握哈夫曼编码的算法实现方式1·3 熟悉哈夫曼编码在数据压缩中的应用2·实验背景2·1 哈夫曼编码的概念和作用2·2 哈夫曼编码的原理和算法2·3 哈夫曼编码在数据压缩中的应用3·实验环境3·1 硬件环境:计算机、CPU、内存等3·2 软件环境:编程语言、编译器等4·实验过程4·1 构建哈夫曼树4·1·1 哈夫曼树的构建原理4·1·2 哈夫曼树的构建算法4·2 哈夫曼编码4·2·1 哈夫曼编码的原理4·2·2 哈夫曼编码的算法4·3 实现数据压缩4·3·1 数据压缩的概念和作用4·3·2 哈夫曼编码在数据压缩中的应用方法5·实验结果5·1 构建的哈夫曼树示例图5·2 哈夫曼编码表5·3 数据压缩前后的文件大小对比5·4 数据解压缩的正确性验证6·实验分析6·1 哈夫曼编码的优点和应用场景分析6·2 数据压缩效果的评估和对比分析6·3 实验中遇到的问题和解决方法7·实验总结7·1 实验所获得的成果和收获7·2 实验中存在的不足和改进方向7·3 实验对于数据结构学习的启示和意义附件列表:1·实验所用的源代码文件2·实验中用到的测试数据文件注释:1·哈夫曼编码:一种用于数据压缩的编码方法,根据字符出现频率构建树形结构,实现高频字符用较短编码表示,低频字符用较长编码表示。
2·哈夫曼树:由哈夫曼编码算法构建的一种特殊的二叉树,用于表示字符编码的结构。
哈夫曼编码译码系统实验报告,数据结构课程设计报告书

专业资料安徽大学数据结构课程设计报告项目名称:哈弗曼编/译码系统的设计与实现姓名:鉏飞祥学号:E21414018专业:软件工程完成日期2016/7/4计算机科学与技术学院1 .需求分析1.1问题描述•问题描述:利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(解码)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
试为这样的信息收发站设计一个哈夫曼编译码系统。
1.2基本要求(1) 输入的形式和输入值的范围;(2) 输出的形式;(3) 程序所能达到的功能。
1.基本要求(1)初始化(Initialzation)。
从数据文件DataFile.data中读入字符及每个字符的权值,建立哈夫曼树HuffTree;(2)编码(EnCoding)。
用已建好的哈夫曼树,对文件ToBeTran.data中的文本进行编码形成报文,将报文写在文件Code.txt中;(3)译码(Decoding)。
利用已建好的哈夫曼树,对文件CodeFile.data 中的代码进行解码形成原文,结果存入文件Textfile.txt中;(4)输出(Output)。
输出DataFile.data中出现的字符以及各字符出现的频度(或概率);输出ToBeTran.data及其报文Code.txt;输出CodeFile.data 及其原文Textfile.txt;2. 概要设计说明本程序中用到的所有抽象数据类型的定义。
主程序的流程以及各程序模块之间的层次(调用)关系。
(1)数据结构哈夫曼树的节点struct huff{int weight;int parent;int l;int r;};哈夫曼编码的存储struct huff *hufftree;(2)程序模块选择1到i-1中parent为0且权值最小的两个下标void Select(struct huff *HT, int n, int &s1, int &s2)构建哈夫曼树:void huffmancoding(struct huff *ht,int *w,int n)对原文进行编码:void code(char *c)根据报文找到原文:void decoding(char *zifu)3. 详细设计核心技术分析:1:构建哈夫曼树及生成哈夫曼编码:根据每个字符权值不同,根据最优二叉树的构建方法,递归生成哈夫曼树,并且用数组存放哈夫曼树。
数据结构 哈夫曼编码实验报告

数据结构哈夫曼编码实验报告数据结构哈夫曼编码实验报告1. 实验目的本实验旨在通过实践理解哈夫曼编码的原理和实现方法,加深对数据结构中树的理解,并掌握使用Python编写哈夫曼编码的能力。
2. 实验原理哈夫曼编码是一种用于无损数据压缩的算法,通过根据字符出现的频率构建一棵哈夫曼树,并根据哈夫曼树对应的编码。
根据哈夫曼树的特性,频率较低的字符具有较长的编码,而频率较高的字符具有较短的编码,从而实现了对数据的有效压缩。
实现哈夫曼编码的主要步骤如下:1. 统计输入文本中每个字符的频率。
2. 根据字符频率构建哈夫曼树,其中树的叶子节点代表字符,内部节点代表字符频率的累加。
3. 遍历哈夫曼树,根据左右子树的关系对应的哈夫曼编码。
4. 使用的哈夫曼编码对输入文本进行编码。
5. 将编码后的二进制数据保存到文件,同时保存用于解码的哈夫曼树结构。
6. 对编码后的文件进行解码,还原原始文本。
3. 实验过程3.1 统计字符频率首先,我们需要统计输入文本中每个字符出现的频率。
可以使用Python中的字典数据结构来记录字符频率。
遍历输入文本的每个字符,将字符添加到字典中,并递增相应字符频率的计数。
```pythondef count_frequency(text):frequency = {}for char in text:if char in frequency:frequency[char] += 1else:frequency[char] = 1return frequency```3.2 构建哈夫曼树根据字符频率构建哈夫曼树是哈夫曼编码的核心步骤。
我们可以使用最小堆(优先队列)来高效地构建哈夫曼树。
首先,将每个字符频率作为节点存储到最小堆中。
然后,从最小堆中取出频率最小的两个节点,将它们作为子树构建成一个新的节点,新节点的频率等于两个子节点频率的和。
将新节点重新插入最小堆,并重复该过程,直到最小堆中只剩下一个节点,即哈夫曼树的根节点。
《数据结构课程设计》赫夫曼编码实验报告

目录一、概述 (1)二、系统分析 (1)三、概要设计 (2)四、详细设计 (4)4.1 赫夫曼树的建立 (4)4.1.1 选择选择parent 为0 且权值最小的两个根结点的算法 (5)4.1.2 统计字符串中字符的种类以及各类字符的个数 (7)4.1.3构造赫夫曼树 (8)4.2赫夫曼编码 (10)4.2.1赫夫曼编码算法 (10)4.2.2建立正文的编码文件 (11)4.3代码文件的译码 (12)五、运行与测试 (14)六、总结与心得 (14)参考文献 (15)附录 (15)一、概述本设计是对输入的一串电文字符实现赫夫曼编码,再对赫夫曼编码生产的代码串进行译码,输出电文字符串。
在当今信息爆炸时代,如何采用有效的数据压缩技术节省数据文件的存储空间和计算机网络的传送时间越来越引起人们的重视,赫夫曼编码正是一种应用广泛且非常有效的数据压缩技术。
二、系统分析赫夫曼编码的应用很广泛,利用赫夫曼树求得的用于通信的二进制编码成为赫夫曼编码。
树中从根到每个叶子都有一条路径,对路径上的各分支约定:指向左子树的分支表示“0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“1”的序列作为和每个叶子对应的字符的编码,这就是赫夫曼编码。
通常我们把数据压缩的过程称为编码,解压缩的过程称为解码。
电报通信是传递文字的二进制码形式的字符串,但在信息传递时,总希望总长度能尽可能短,即采用最短码。
假设每种字符在电文中出现的次数为W i ,编码长度为L i ,电文中有n 种字符,则电文编码总长为∑W i L i 。
若将此对应到二叉树上,W i 为叶节点的权,L i 为根节点到叶节点的路径长度。
那么,∑W i L i 恰好为二叉树上带权路径长度。
因此,设计电文总长最短的二进制前缀编码,就是以n 种子符出现的频率作权,构造一刻赫夫曼树,此构造过程成为赫夫曼编码。
根据设计要求和分析,要实现设计,必须实现以下方面的功能:(1)赫夫曼树的建立;(2)赫夫曼编码的生成;(3)编码文件的译码;三、概要设计程序由哪些模块组成以及模块之间的层次结构、各模块的调用关系;每个模块的功能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于哈夫曼编码的通信系统的设计与实现一、实验目的(1)掌握二叉树的存储结构及其相关操作。
(2)掌握构造哈夫曼树的基本思想,及其编码/译码过程。
二、实验内容利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传输数据预先编码,在接收端将传来的数据进行译码。
对于双工信道,每端都需要一个完整的编/译码系统。
试为这样的信息收发站设计一个基于哈夫曼编码的通信系统。
一个完整的系统应具有以下功能1)初始化处理:建立通信系统(1)建立有100句中文的信息集合,每个句子称为一条信息。
(2)输入编码参数:①从终端输入编码字符集大小n,字符编码长度m(设n为4,m为8);②从终端输入编码字符(设为A,B,C,D);(3)生成每条信息的字符编码,构造字符编码集合;(4)计算每个字符编码集合中出现的概率;(5)根据字符概率构造哈夫曼树,求出每个字符的二进制编码。
2)发送端信息编码(1)用户从信息集合中选择一条信息,找到该信息对应的字符编码;(2)根据该信息的字符编码,哈夫曼树求出的每个字符的二进制编码,构造出该信息的二进制编码,记录二进制比编码。
3)接受端信息译码(1)根据得到的信息的二进制编码,利用哈夫曼树求出每个字符的二进制编码还原出信息的字符编码;(2)根据信息的字符编码,找到对应的信息。
三、源程序代码#include<stdio.h>#include<malloc.h>#include<stdlib.h>char *codechar;int ncodechar,lcodechar;int *arraychar[100];char *temp;float *proba;char pass[50];int passl;struct node{float pro;int num;struct node* p;struct node* lc;struct node* rc;char *res;int length;}*hc;char message[100][20]={{"人之初"}, {"性本善"}, {"性相近"}, {"习相远"}, {"苟不教"}, {"性乃迁"},{"教之道"}, {"贵以专"}, {"昔孟母"}, {"择邻处"}, {"子不学"}, {"断机杼"},{"窦燕山"}, {"有义方"}, {"教五子"}, {"名俱扬"}, {"养不教"}, {"父之过"},{"教不严"}, {"师之惰"}, {"子不学"}, {"非所宜"}, {"幼不学"}, {"老何为"},{"玉不琢"}, {"不成器"}, {"人不学"}, {"不知义"}, {"为人子"}, {"方少时"},{"亲师友"}, {"习礼仪"}, {"香九龄"}, {"能温席"}, {"孝于亲"}, {"所当执"},{"融四岁"}, {"能让梨"}, {"弟于长"}, {"宜先知"}, {"首孝弟"}, {"次见闻"},{"知某数"}, {"识某文"}, {"一而十"}, {"十而百"}, {"百而千"}, {"千而万"},{"三才者"}, {"天地人"}, {"三光者"}, {"日月星"}, {"三纲者"}, {"君臣义"},{"父子亲"}, {"夫妇顺"}, {"曰春夏"}, {"曰秋冬"}, {"此四时"}, {"运不穷"},{"曰南北"}, {"曰西东"}, {"此四方"}, {"应乎中"}, {"曰水火"}, {"木金土"},{"此五行"}, {"本乎数"}, {"曰仁义"}, {"礼智信"}, {"此五常"}, {"不容紊"},{"稻粱菽"}, {"麦黍稷"}, {"此六谷"}, {"人所食"}, {"马牛羊"}, {"鸡犬豕"},{"此六畜"}, {"人所饲"}, {"曰喜怒"}, {"曰哀惧"}, {"爱恶欲"}, {"七情具"},{"匏土革"}, {"木石金"}, {"丝与竹"}, {"乃八音"}, {"高曾祖"}, {"父而身"},{"身而子"}, {"子而孙"}, {"自子孙"}, {"至玄曾"}, {"乃九族"}, {"人之伦"},{"父子恩"}, {"夫妇从"}, {"兄则友"}, {"弟则恭"}} ;int zifushengcheng();int probability();int huffman();int Exchange(struct node *a,struct node *b);int Exchangenum(int *a,int *b);int Exchangepoint(struct node **a,struct node ** b);int produce(struct node *a,int *b);int sent();int receive();int main(){int i;char t;printf("初始化通讯系统:\n请输入编码字符集大小n,字符编码长度m(以n m格式来输入):\n");scanf("%d %d",&ncodechar,&lcodechar);codechar=(char *)malloc(sizeof(char)*ncodechar);proba=(float *)malloc(sizeof(float)*ncodechar);for(i=0;i<ncodechar;i++){proba[i]=0;}for(i=0;i<100;i++){arraychar[i]=(int *)malloc(sizeof(int )*lcodechar);}hc=(struct node*)malloc(sizeof(struct node)*(ncodechar*2-1));temp=(char *)malloc(sizeof(char)*(ncodechar));printf("请输入编码字符(以A B C D的格式来输入):\n");for(i=0;i<ncodechar;i++){scanf("%c",&t);if(t=='\n'||t==' '){i--;continue;}codechar[i]=t;}zifushengcheng();probability();huffman();sent();receive();return 1;}int sent(){int i,j,k,x;printf("\n--------------------------------发送方------------------------------------\n");for(i=0;i<100;i++){printf("%d:",i+1);for(j=0;j<20;j++){printf("%c",message[i][j]);}printf(" 相应的字符编码:");for(k=0;k<lcodechar;k++){printf("%c",codechar[arraychar[i][k]]);}printf("\n");}printf("请从以上100条信息中选择发送的信息,输入你的信息号:");scanf("%d",&x);printf("你选择发送的信息是:");for(j=0;j<20;j++){printf("%c",message[x-1][j]);}printf("\n相应的字符编码是:");for(i=0;i<lcodechar;i++){printf("%c",codechar[arraychar[x-1][i]]);}printf("\n根据哈夫曼树得到的哈夫曼编码是:");for(i=0;i<lcodechar;i++){for(j=0;j<ncodechar*2-1;j++){if(arraychar[x-1][i]==hc[j].num){for(k=0;k<hc[j].length;k++){printf("%c",hc[j].res[k]);pass[passl]=hc[j].res[k];passl++;}}}}return 1;}int receive(){int i,j,k=0,m;int *get=(int *)malloc(sizeof(int)*lcodechar);printf("\n--------------------------------接收方------------------------------------\n接收到的哈夫曼编码是:");for(i=0;i<passl;i++){printf("%c",pass[i]);}i=0;while(i!=lcodechar){for(j=0;(j<ncodechar*2-1);j++){for(m=0;m<hc[j].length;m++,k++){if(hc[j].res[m]!=pass[k]){break;}}if(m==hc[j].length){get[i]=hc[j].num;i++;break;}k=k-m;}}printf("\n根据哈夫曼树转换出的字符编码为:\n");for(i=0;i<lcodechar;i++){printf("%c",codechar[get[i]]);}for(i=0;i<100;i++){for(j=0;j<lcodechar;j++){if(get[j]!=arraychar[i][j])break;}if(j==lcodechar){printf("\n字符编码转换后得到的信息是:\n");for(k=0;k<20;k++){printf("%c",message[i][k]);}break;}}printf("\n接收结束,谢谢使用!");return 1;}int zifushengcheng(){int i,j=0,k=0,yushu,x;int *b[100];for(i=0;i<100;i++){b[i]=(int *)malloc(sizeof(int)*lcodechar);for(j=0;j<lcodechar;j++){b[i][j]=0;}for(i=0;i<100;i++){x=i;do{yushu=x%ncodechar;x=(int)(x/ncodechar);b[i][j]=yushu;j++;}while(x!=0);for(j=ncodechar-1;j>=0;j--,k++){arraychar[i][k]=b[i][j];}j=0;k=0;}for(i=0;i<100;i++){for(j=ncodechar;j<lcodechar;j++){arraychar[i][j]=rand()%ncodechar;}}/*for(i=0;i<100;i++){for(j=0;j<lcodechar;j++){printf("%d ",arraychar[i][j]);}printf(" ");for(j=0;j<lcodechar;j++){printf("%c",codechar[arraychar[i][j]]);}printf("\n");}*/return 1;}int probability(){for(i=0;i<100;i++){for(j=0;j<lcodechar;j++){for(k=0;k<ncodechar;k++){if(arraychar[i][j]==k){proba[k]++;}}}}printf("随机生成的字符编码概率:\n");for(i=0;i<ncodechar;i++){proba[i]=proba[i]/(100*lcodechar);printf("%c:%f ",codechar[i],proba[i]);}return 1;}int huffman(){int i,j,k,l=0;for(i=0;i<(ncodechar*2-1);i++){hc[i].lc=NULL;hc[i].rc=NULL;hc[i].p=NULL;hc[i].num=i;if(i<ncodechar){hc[i].pro=proba[i];continue;}hc[i].pro=0;}for(i=0;i<ncodechar-1;i++){for(j=i*2;j<(ncodechar+i);j++){for(k=j+1;k<(ncodechar+i);k++){if(hc[k].pro<hc[j].pro&&hc[k].pro!=0){Exchange(&hc[k],&hc[j]);}}}hc[i+ncodechar].pro=hc[i*2].pro+hc[i*2+1].pro;hc[i+ncodechar].lc=&hc[i*2];hc[i+ncodechar].rc=&hc[i*2+1];hc[i*2].p=&hc[i+ncodechar];hc[i*2+1].p=&hc[i+ncodechar];}printf("\n构造的哈夫曼树:");for(i=0;i<ncodechar*2-1;i++){printf("\nchar:%c num:%d pro:%f",codechar[hc[i].num],hc[i].num,hc[i].pro);printf(" lc:");if(hc[i].lc==NULL){printf(" ");}else{printf("%d,",hc[i].lc->num);}printf(" rc:");if(hc[i].rc==NULL){printf(" ");}else{printf("%d,",hc[i].rc->num);}printf(" p:");if(hc[i].p==NULL){printf(" ");}else{printf("%d,",hc[i].p->num);}}produce(&hc[ncodechar*2-2],&l);printf("\n生成的哈夫曼编码是:");for(i=0;i<ncodechar*2-1;i++){printf("\nchar:%c num:%d length:%d code:",codechar[hc[i].num],hc[i].num,hc[i].length);for(j=0;j<hc[i].length;j++){printf("%c",hc[i].res[j]);}}return 1;}int produce(struct node*a,int *b){int i;a->length=(*b);a->res=(char *)malloc(sizeof(char)*(*b));for(i=0;i<(*b);i++){a->res[i]=temp[i];}if(a->lc!=NULL&&a->rc!=NULL){temp[(*b)]='0';(*b)++;produce((a->lc),b);temp[(*b)]='1';(*b)++;produce((a->rc),b);}(*b)--;return 1;}int Exchange(struct node*a,struct node*b){float t;t=a->pro;a->pro=b->pro;b->pro=t;Exchangenum(&a->num,&b->num);Exchangepoint(&a->p,&b->p);Exchangepoint(&a->lc,&b->lc);Exchangepoint(&a->rc,&b->rc);return 1;}int Exchangepoint(struct node **a,struct node ** b) {struct node *t;t=*a;*a=*b;*b=t;return 1;}int Exchangenum(int *a,int *b){int t;t=*a;*a=*b;*b=t;return 1;}参考至《百度文库》四、结果分析本次实验是学习编程以来接触的最大程序,参考了较多相关源文件,对c语的函数引用有了更深刻的了解,初步掌握了二叉树的存储结构及其相关操作。