哈夫曼编码译码系统课程设计实验报告(含源代码C++_C语言)
哈夫曼编码译码实验报告

哈夫曼编码译码实验报告哈夫曼编码译码实验报告一、引言哈夫曼编码是一种用来对数据进行压缩的算法,它能够根据数据的频率分布来分配不同长度的编码,从而实现对数据的高效压缩。
本次实验旨在通过实际操作,深入理解哈夫曼编码的原理和实现方式,并通过编码和解码过程来验证其有效性。
二、实验目的1. 掌握哈夫曼编码的原理和算法;2. 学会使用编程语言实现哈夫曼编码和解码;3. 验证哈夫曼编码在数据压缩中的实际效果。
三、实验过程1. 数据准备在实验开始前,首先需要准备一段文本数据作为实验材料。
为了更好地展示哈夫曼编码的效果,我们选择了一篇新闻报道作为实验文本。
这篇报道涵盖了多个领域的信息,包括科技、经济、体育等,具有一定的复杂性。
2. 哈夫曼编码实现根据哈夫曼编码的原理,我们首先需要统计文本中每个字符的频率。
为了方便处理,我们将每个字符与其频率构建成一个字符-频率的映射表。
然后,我们根据频率构建哈夫曼树,将频率较低的字符作为叶子节点,频率较高的字符作为内部节点。
最后,根据哈夫曼树构建编码表,将每个字符映射到对应的二进制编码。
3. 哈夫曼解码实现在哈夫曼解码过程中,我们需要根据编码表将二进制编码转换回字符。
为了实现高效解码,我们可以将编码表转换为一个二叉树,其中每个叶子节点对应一个字符。
通过遍历二叉树,我们可以根据输入的二进制编码逐步还原出原始文本。
4. 编码和解码效果验证为了验证哈夫曼编码的有效性,我们需要对编码和解码的结果进行比较。
通过计算编码后的二进制数据长度和原始文本长度的比值,我们可以得到压缩率,进一步评估哈夫曼编码的效果。
四、实验结果经过实验,我们得到了以下结果:1. 哈夫曼编码表根据实验文本统计得到的字符-频率映射表,我们构建了哈夫曼树,并生成了相应的编码表。
编码表中每个字符对应的编码长度不同,频率较高的字符编码长度较短,频率较低的字符编码长度较长。
2. 编码结果将实验文本使用哈夫曼编码进行压缩后,得到了一串二进制数据。
C语言-哈夫曼编码实验报告

福建工程学院课程设计课程:数据结构题目:哈夫曼编码和译码专业:信息管理信息系统班级: 1002班座号: 15号姓名:林左权2011年 6月 27日实验题目:哈夫曼编码和译码一、要解决的问题利用哈夫曼编码进行信息通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
二、算法基本思想描述:根据给定的字符和其中每个字符的频度,构造哈夫馒树,并输出字符集中每个字符的哈夫曼编码.将给定的字符串根据其哈夫曼编码进行编码,并进行相应的译码.三、设计1. 数据结构的设计(1)哈夫曼树的表示设计哈夫曼树的结构体(htnode),其中包含权重、左右孩子、父母和要编码的字符。
用这个结构体(htnode)定义个哈夫曼数组(hfmt[])。
迷宫定义如下:typedef struct{int weight;int lchild;int rchild;int parent;char key;}htnode;typedef htnode hfmt[MAXLEN];(2)对原始字符进行编码初始化哈夫曼树(inithfmt)。
从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树。
并显示出每个字符的编码。
inithfmt(hfmt t)ey)hfmtpath(t,i,j);printf("\n");}(4)对用户输入的字符进行编码void decoding(hfmt t)child;if(t[j].lchild==-1){printf("%c",t[j].key);j=2*n-2;}}else if(r[i]=='1'){j=t[j].rchild;if(t[j].rchild==-1){printf("%c",t[j].key); j=2*n-2;}}}printf("\n\n");}四、源程序清单:#include <>#include <>#include <>#define MAXLEN 100typedef struct{int weight;int lchild;int rchild;int parent;char key;}htnode;typedef htnode hfmt[MAXLEN];int n;void inithfmt(hfmt t)eight=0;t[i].lchild=-1;t[i].rchild=-1;t[i].parent=-1;}printf("\n");}void inputweight(hfmt t)ey=k;printf("请输入第%d个字符的权值:",i+1); scanf("%d",&w);getchar();t[i].weight=w;printf("\n");}}void selectmin(hfmt t,int i,int *p1,int *p2)arent==-1)if(min1>t[j].weight){min1=t[j].weight;*p1=j;}for(j=0;j<=i;j++)arent==-1)if(min2>t[j].weight && j!=(*p1))eight;*p2=j;}}void creathfmt(hfmt t)arent=i;t[p2].parent=i;t[i].lchild=p1;t[i].rchild=p2;t[i].weight=t[p1].weight+t[p2].weight;}}void printhfmt(hfmt t)eight,t[i].parent,t[i].lchild,t[i].rchild,t[i].key); }printf("\n------------------------------------------------------------------\n");printf("\n\n");}void hfmtpath(hfmt t,int i,int j)arent;if(t[j].parent!=-1){i=j;hfmtpath(t,i,j);}if(t[b].lchild==a)printf("0");elseprintf("1");}void phfmnode(hfmt t)ey,t[i].weight);hfmtpath(t,i,j);}printf("\n------------------------------------------------------------------\n") ;}void encoding(hfmt t)ey)hfmtpath(t,i,j);printf("\n");}void decoding(hfmt t)child;if(t[j].lchild==-1){printf("%c",t[j].key);j=2*n-2;}}else if(r[i]=='1'){j=t[j].rchild;if(t[j].rchild==-1){printf("%c",t[j].key);j=2*n-2;}}}printf("\n\n");}int main(){int i,j;hfmt ht;char flag;printf(" |----------------------|\n"); printf(" |信管1002--林左权--15号|\n");printf(" |**********************|\n");printf(" | 哈夫曼编码课程设计 |\n");printf(" |**********************|\n");printf(" |设计完成时间:2011/6/27|\n");printf(" |----------------------|\n");creathfmt(ht);printhfmt(ht);phfmnode(ht);printf("\n------------------------------------------------------------------\n") ;printf("***************************编码&&译码&&退出***********************");printf("\n【1】编码\t【2】\t译码\t【0】退出");printf("\n您的选择:");flag=getchar();getchar();while(flag!='0'){if(flag=='1')encoding(ht);else if(flag=='2')decoding(ht);elseprintf("您的输入有误,请重新输入。
哈夫曼编译码的设计与实现实验报告
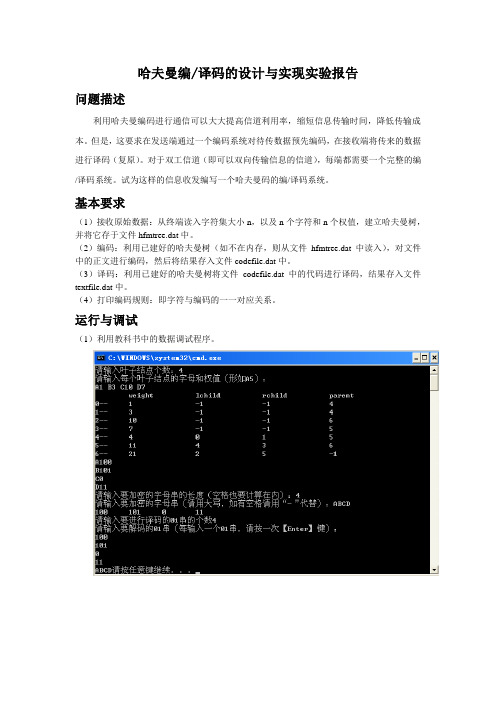
哈夫曼编/译码的设计与实现实验报告问题描述利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
试为这样的信息收发编写一个哈夫曼码的编/译码系统。
基本要求(1)接收原始数据:从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树,并将它存于文件hfmtree.dat中。
(2)编码:利用已建好的哈夫曼树(如不在内存,则从文件hfmtree.dat中读入),对文件中的正文进行编码,然后将结果存入文件codefile.dat中。
(3)译码:利用已建好的哈夫曼树将文件codefile.dat中的代码进行译码,结果存入文件textfile.dat中。
(4)打印编码规则:即字符与编码的一一对应关系。
运行与调试(1)利用教科书中的数据调试程序。
(2)用下表给出的字符集和频度的实际统计数据建立哈夫曼树,并实现以下报文的编码和译码:“THIS-PROGRAM-IS-MY-FA VORITE”。
字符 A B C D E F G H I J K L M 频度186 64 13 22 32 103 21 15 47 57 1 5 32 20 字符N O P Q R S T U V W X Y Z频度57 63 15 1 48 51 80 23 8 18 1 16 1实验小结通过这次实验,让我对于树的应用多了认识,在读取文件时,遇到的一些困难,不过在和同学交流的过程中,解决了这个问题,我觉的自己对于树及文件的应用又有了一些进步。
通过这次实验,感觉收获很大。
源程序// 哈夫曼编译码的设计与实现.cpp : 定义控制台应用程序的入口点。
//#include "stdafx.h"#include<iostream>#include<fstream>#include<string>#define Maxvalue 10000#define MAXBIT 200using namespace std;struct node{char letter;string num;};typedef struct{char letter;int weight; //结点权值int parent;int lchild;int rchild;}HnodeType;typedef struct{int bit[MAXBIT];int start;}HcodeType;HnodeType *HaffmanTree(int n){HnodeType *HuffNode;HuffNode=new HnodeType[2*n-1];int i,j;int m1,m2,x1,x2;for(i=0;i<2*n-1;i++) //数组HuffNode[]初始化{HuffNode[i].weight=0;HuffNode[i].parent=-1;HuffNode[i].lchild=-1;HuffNode[i].rchild=-1;}cout<<"请输入每个叶子结点的字母和权值(形如A5):"<<endl;for(i=0;i<n;i++)cin>>HuffNode[i].letter>>HuffNode[i].weight; //输入n个叶子结点的权值for(i=0;i<n-1;i++) //构造哈夫曼树{m1=m2=Maxvalue;x1=x2=0;for(j=0;j<n+i;j++) //选取最和次小两个权值{if(HuffNode[j].parent==-1&&HuffNode[j].weight<m1){m2=m1;x2=x1;m1=HuffNode[j].weight;x1=j;}else{if(HuffNode[j].parent==-1&&HuffNode[j].weight<m2){m2=HuffNode[j].weight;x2=j;}}}//将找出的两棵子树合并为一棵子树HuffNode[x1].parent=n+i;HuffNode[x2].parent=n+i;HuffNode[n+i].weight=HuffNode[x1].weight+HuffNode[x2].weight;HuffNode[n+i].lchild=x1;HuffNode[n+i].rchild=x2;}cout<<" weight"<<" lchild"<<" rchild"<<" parent"<<endl; for(i=0;i<2*n-1;i++)cout<<i<<"--"<<" "<<HuffNode[i].weight<<" "<<HuffNode[i].lchild<<" "<<HuffNode[i].rchild<<" "<<HuffNode[i].parent<<endl;ofstream outFile("hfmtree.dat",ios::out);if(!outFile)cerr<<"文件打开失败!"<<endl;else{outFile<<" weight"<<" lchild"<<" rchild"<<"parent"<<endl;for(i=0;i<2*n-1;i++)outFile<<i<<"--"<<" "<<HuffNode[i].weight<<""<<HuffNode[i].lchild<<" "<<HuffNode[i].rchild<<""<<HuffNode[i].parent<<endl;outFile.close();}return HuffNode;}void HaffmanCode(HnodeType *HuffNode,int n){HcodeType *HuffCode,cd;HuffCode=new HcodeType[2*n-1];int c,p,i,j;for(i=0;i<n;i++){cd.start=n-1;c=i;p=HuffNode[c].parent;while(p!=-1){if(HuffNode[p].lchild==c)cd.bit[cd.start]=0;elsecd.bit[cd.start]=1;cd.start--;c=p;p=HuffNode[c].parent;}for(j=cd.start+1;j<n;j++)HuffCode[i].bit[j]=cd.bit[j];HuffCode[i].start=cd.start;}for(i=0;i<n;i++){cout<<HuffNode[i].letter;for(j=HuffCode[i].start+1;j<n;j++)cout<<HuffCode[i].bit[j];cout<<endl;}ofstream outFile1("codefile.dat",ios::out|ios::binary);if(!outFile1)cerr<<"文件打开失败!"<<endl;else{for(i=0;i<n;i++){outFile1<<HuffNode[i].letter;for(j=HuffCode[i].start+1;j<n;j++)outFile1<<HuffCode[i].bit[j];outFile1<<endl;}outFile1.close();}}int _tmain(int argc, _TCHAR* argv[]){HnodeType *HuffNode;int n,i;cout<<"请输入叶子结点个数:";cin>>n;if(cin.fail()){cout<<"输入有误!"<<endl;return 0;}HuffNode=HaffmanTree(n);HaffmanCode(HuffNode,n);int num;cout<<"请输入要加密的字母串的长度(空格也要计算在内):";cin>>num;char *l1;char l;node l2[27];l1=new char[num];cout<<"请输入要加密的字母串(请用大写,如有空格请用“-”代替):";for(int n=0;n<num;n++)cin>>l1[n];ofstream outFile2("bianma.dat",ios::out|ios::binary);if(!outFile2)cerr<<"文件打开失败!"<<endl;else{for(i=0;i<num;i++)outFile2<<l1[i];outFile2.close();}ifstream inFile1("codefile.dat",ios::in|ios::binary);ifstream inFile2("bianma.dat",ios::in|ios::binary);cerr<<"读取文件失败!"<<endl;if(!inFile2)cerr<<"读取文件失败!"<<endl;else{while(inFile2.peek ()!=EOF){inFile2>>l;for(i=0;i<2*n-1;i++){inFile1>>l2[i].letter;inFile1>>l2[i].num;}for(i=0;i<n;i++){if(l2[i].letter==l)cout<<l2[i].num<<" ";}}inFile1.close();inFile2.close();}delete []l1;cout<<endl;int a;cout<<"请输入要进行译码的串的个数:";cin>>a;string *s;s=new string[a];cout<<"请输入要解码的串(每输入一个串,请按一次【Enter】键):"<<endl; for(i=0;i<a;i++)cin>>s[i];ofstream outFile4("yima.dat",ios::out);if(!outFile4)cerr<<"文件打开失败!"<<endl;else{for(i=0;i<a;i++)outFile4<<s[i]<<endl;outFile4.close();}ifstream inFile3("codefile.dat",ios::in|ios::binary);cerr<<"读取文件失败!"<<endl;else{for(i=0;i<2*n-1;i++){inFile3>>l2[i].letter;inFile3>>l2[i].num;}ifstream inFile4("yima.dat",ios::in);if(!inFile4)cerr<<"读取文件失败!"<<endl;else{for(int j=0;j<a;j++)inFile4>>s[j];}for(int j=0;j<a;j++){for(i=0;i<n;i++){if(l2[i].num==s[j])cout<<l2[i].letter;}}inFile3.close();}return 0;}。
哈夫曼编码解码实验报告

哈夫曼编码解码实验1.实验要求掌握二叉树的相关概念掌握构造哈夫曼树,进行哈夫曼编码。
对编码内容通过哈夫曼树进行解码。
2.实验内容通过二叉树构造哈夫曼树,并用哈夫曼树对读取的txt文件进行哈夫曼编码。
编码完成后通过哈夫曼树进行解码。
#include<>#include<>#define MAX 100arent=ht[i].lch=ht[i].rch=0;}j=0;for(i=1;i<=n;i++){/*getchar();printf("输入第%d个叶子节点的值:",i);scanf("%c",&ht[i].data);printf("输入该节点的权值:");scanf("%d",&ht[i].weight);*/for(;j<127;j++){if(Coun[j]!=0){ht[i].data=j;ata);ht[i].weight=Coun[j];eight);break;}}j++;}printf("\n");for(i=1;i<=n;i++){printf("%c",ht[i].data);}printf("\n");for(i=n+1;i<=2*n-1;i++){arent==0)eight<min1){min2=min1;right=left;min1=ht[k].weight;left=k;else if (ht[k].weight<min2){min2=ht[k].weight;right=k;}}ht[left].parent=i;ht[right].parent=i;ht[i].weight=ht[left].weight+ht[right].weight;ht[i].lch=left;ht[i].rch =right;}}arent;while(f!=0){if(ht[f].lch==c)[]='0';else[]='1';;f=ht[f].parent;}hcd[i]=cd;}printf("输出哈夫曼编码:\n");for(i=1;i<=n;i++){printf("%c:",ht[i].data);for(k=hcd[i].start+1;k<=n;k++)printf("%c",hcd[i].bit[k]);printf("\n");}}ata){for(k=hcd[j].start+1;k<=n;k++){s1[h]=hcd[j].bit[k];h++;}break;}}i++;}ch;if(ht[f].lch==0&&ht[f].rch==0){C=ht[f].data;printf("%c",C);f=2*n-1;}}else if(s1[i]=='1'){f=ht[f].rch;if(ht[f].lch==0&&ht[f].rch==0){C=ht[f].data;printf("%c",C);f=2*n-1;}}}printf("\n"); }验总结通过本次实验,对二叉树的应用有了相应的了解,掌握了如何构造哈夫曼编码,如何对编码结果进行解码。
哈夫曼编码译码器---课程设计报告.docx

目录目⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯ (2)1 程的目的和意⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯32 需求分析⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯43 概要⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯4 4⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯.85 分析和果⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯.11 6⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯127致⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯138附⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯13参考文献⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯..201课程设计目的与意义在当今信息爆炸时代,如何采用有效的数据压缩技术来节省数据文件的存储空间和计算机网络的传送时间已越来越引起人们的重视。
哈夫曼编码正是一种应用广泛且非常有效的数据压缩技术。
哈夫曼编码的应用很广泛,利用哈夫曼树求得的用于通信的二进制编码称为哈夫曼编码。
树中从根到每个叶子都有一条路径,对路径上的各分支约定:指向左子树的分支表示“0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“ 1”的序列作为和各个对应的字符的编码,这就是哈夫曼编码。
通常我们把数据压缩的过程称为编码,解压缩的过程称为解码。
电报通信是传递文字的二进制码形式的字符串。
但在信息传递时,总希望总长度尽可能最短,即采用最短码。
作为计算机专业的学生,我们应该很好的掌握这门技术。
在课堂上,我们能过学到许多的理论知识,但我们很少有过自己动手实践的机会!课程设计就是为解决这个问题提供了一个平台。
在课程设计过程中,我们每个人选择一个课题,认真研究,根据课堂讲授内容,借助书本,自己动手实践。
这样不但有助于我们消化课堂所讲解的内容,还可以增强我们的独立思考能力和动手能力;通过编写实验代码和调试运行,我们可以逐步积累调试 C 程序的经验并逐渐培养我们的编程能力、用计算机解决实际问题的能力。
哈夫曼编译码器实验报告
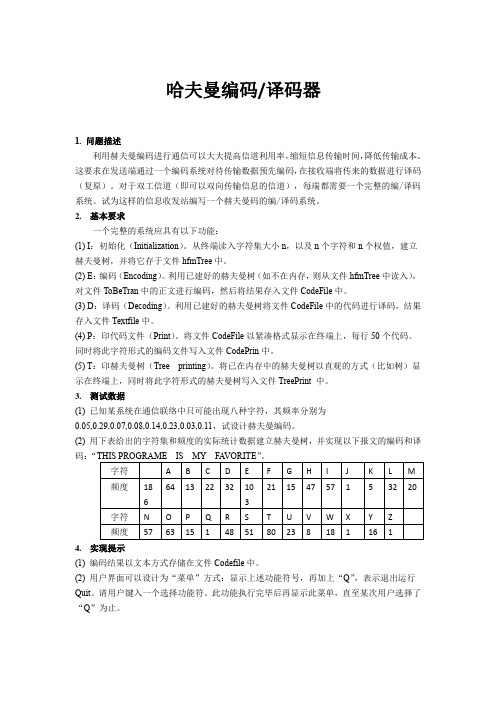
哈夫曼编码/译码器1. 问题描述利用赫夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
这要求在发送端通过一个编码系统对待传输数据预先编码,在接收端将传来的数据进行译码(复原)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
试为这样的信息收发站编写一个赫夫曼码的编/译码系统。
2.基本要求一个完整的系统应具有以下功能:(1) I:初始化(Initialization)。
从终端读入字符集大小n,以及n个字符和n个权值,建立赫夫曼树,并将它存于文件hfmTree中。
(2) E:编码(Encoding)。
利用已建好的赫夫曼树(如不在内存,则从文件hfmTree中读入),对文件ToBeTran中的正文进行编码,然后将结果存入文件CodeFile中。
(3) D:译码(Decoding)。
利用已建好的赫夫曼树将文件CodeFile中的代码进行译码,结果存入文件Textfile中。
(4) P:印代码文件(Print)。
将文件CodeFile以紧凑格式显示在终端上,每行50个代码。
同时将此字符形式的编码文件写入文件CodePrin中。
(5) T:印赫夫曼树(Tree printing)。
将已在内存中的赫夫曼树以直观的方式(比如树)显示在终端上,同时将此字符形式的赫夫曼树写入文件TreePrint 中。
3.测试数据(1) 已知某系统在通信联络中只可能出现八种字符,其频率分别为0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11,试设计赫夫曼编码。
(2) 用下表给出的字符集和频度的实际统计数据建立赫夫曼树,并实现以下报文的编码和译码:“4.实现提示(1) 编码结果以文本方式存储在文件Codefile中。
(2) 用户界面可以设计为“菜单”方式:显示上述功能符号,再加上“Q”,表示退出运行Quit。
请用户键入一个选择功能符。
此功能执行完毕后再显示此菜单,直至某次用户选择了“Q”为止。
哈夫曼编码译码器实验报告

哈夫曼编码译码器实验报告实验名称:哈夫曼编码译码器实验一、实验目的:1.了解哈夫曼编码的原理和应用。
2.实现一个哈夫曼编码的编码和译码器。
3.掌握哈夫曼编码的编码和译码过程。
二、实验原理:哈夫曼编码是一种常用的可变长度编码,用于将字符映射到二进制编码。
根据字符出现的频率,建立一个哈夫曼树,出现频率高的字符编码短,出现频率低的字符编码长。
编码过程中,根据已建立的哈夫曼树,将字符替换为对应的二进制编码。
译码过程中,根据已建立的哈夫曼树,将二进制编码替换为对应的字符。
三、实验步骤:1.构建一个哈夫曼树,根据字符出现的频率排序。
频率高的字符在左子树,频率低的字符在右子树。
2.根据建立的哈夫曼树,生成字符对应的编码表,包括字符和对应的二进制编码。
3.输入一个字符串,根据编码表将字符串编码为二进制序列。
4.输入一个二进制序列,根据编码表将二进制序列译码为字符串。
5.比较编码前后字符串的内容,确保译码正确性。
四、实验结果:1.构建哈夫曼树:-字符出现频率:A(2),B(5),C(1),D(3),E(1) -构建的哈夫曼树如下:12/\/\69/\/\3345/\/\/\/\ABCDE2.生成编码表:-A:00-B:01-C:100-D:101-E:1103.编码过程:4.译码过程:5.比较编码前后字符串的内容,结果正确。
五、实验总结:通过本次实验,我了解了哈夫曼编码的原理和应用,并且实现了一个简单的哈夫曼编码的编码和译码器。
在实验过程中,我充分运用了数据结构中的树的知识,构建了一个哈夫曼树,并生成了编码表。
通过编码和译码过程,我进一步巩固了对树的遍历和节点查找的理解。
实验结果表明,本次哈夫曼编码的编码和译码过程正确无误。
在实验的过程中,我发现哈夫曼编码对于频率较高的字符具有较短的编码,从而实现了对字符串的高效压缩。
同时,哈夫曼编码还可以应用于数据传输和存储中,提高数据的传输效率和存储空间的利用率。
通过本次实验,我不仅掌握了哈夫曼编码的编码和译码过程,还深入了解了其实现原理和应用场景,加深了对数据结构和算法的理解和应用能力。
huffman哈夫曼树编码译码课程设计报告

数据结构课程设计信息科学与工程学院:学院计算机科学与技术专业:1601 计卓级:班号:学:学生姓名指导教师:23/ 1年月日题目名称一、实验内容哈夫曼编码译码系统【问题描述】用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
试为这样的信息收发站写一个哈夫曼码的编/译码系统。
【基本要求】1)初始化。
从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树。
2)编码。
利用已建好的哈夫曼树对输入英文进行编码,编码结果存储在数组中。
3)译码。
利用已建好的哈夫曼树将数组中的代码进行译码,结果存入一个字符数组。
4)输出编码。
将编码结果显示在终端上,每行50个代码。
5)输出哈夫曼树。
将哈夫曼树以直观的方式(树或凹入表形式)显示出来。
【实现提示】用户界面可以设计为“菜单”方式,再加上一个“退出”功能。
请用户键入一个选择功能符。
此功能执行完毕后再显示此菜单,直至某次用户选择了“退出”为止。
参考教材P240-246【选做内容】将哈夫曼树保存到文件中,编码和译码的结果也分别存放在两个文本文件中。
23/ 2二、数据结构设计储存结构struct HNodeType {//字符结构体类型int weight;//权int parent;//双亲位置int lchild;//左孩子int rchild;//右孩子char inf;// 字符};struct HcodeType {存储编码int bit[MaxBit];// int start;// 起始位置};三、算法设计1、在构造哈夫曼树时,设计一个结构体数组HuffNode保存哈夫曼树中各结点的信息,根据二叉树的性质可知,具有n个叶子结点的哈夫曼树共有2n-1个结点,所以数组HuffNode的大小设置为2n-1。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
目录摘要 (II)Abstract (II)第一章课题描述 (1)1.1 问题描述 (1)1.2 需求分析…………………………………………………..……………………………11.3 程序设计目标……………………………………………………………………………第二章设计简介及设计方案论述 (2)2.1 设计简介 (2)2.2 设计方案论述 (2)2.3 概要设计 (2)第三章详细设计 (4)3.1 哈夫曼树 (4)3.2哈夫曼算法 (4)3.2.1基本思想 (4)3.2.2存储结构 (4)3.3 哈夫曼编码 (5)3.4 文件I/O 流 (6)3.4.1 文件流 (6)3.4.2 文件的打开与关闭 (7)3.4.3 文件的读写 (7)3..5 C语言文件处理方式……………………………………………………………………第四章设计结果及分析 (8)4.1 设计系统功能 (8)4.2 进行系统测试 (8)总结 (13)致谢 (14)参考文献 (15)附录主要程序代码 (16)摘要在这个信息高速发展的时代,每时每刻都在进行着大量信息的传递,到处都离不开信息,它贯穿在人们日常的生活生产之中,对人们的影响日趋扩大,而利用哈夫曼编码进行通信则可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
在生产中则可以更大可能的降低成本从而获得更大的利润,这也是信息时代发展的趋势所在。
本课程设计的目的是使学生学会分析待加工处理数据的特性,以便选择适当的逻辑结构、存储结构以及进行相应的算法设计。
学生在学习数据结构和算法设计的同时,培养学生的抽象思维能力、逻辑推理能力和创造性的思维方法,增强分析问题和解决问题的能力。
此次设计的哈夫曼编码译码系统,实现对给定报文的编码和译码,并且任意输入报文可以实现频数的统计,建立哈夫曼树以及编码译码的功能。
这是一个拥有完备功能的系统程序,对将所学到的知识运用到实践中,具有很好的学习和研究价值.关键词:信息;通讯;编码;译码;程序AbstractThis is a date that information speeding highly development and transmitinformation every time, everywhere cannot leave the information, it passes through during the people daily life production, the influence expands day by day to the people, but codes using Huffman carries on the correspondence to be possible to raise the channel use factor greatly, reduces the intelligence transmission time, reduces the transmission cost. May greatly possible reduce the cost in the production, thus obtains a bigger profit, this is also the information age development tendency is. This curriculum project's goal is makes the student academic society to analyze treats the processing data the characteristic, with the aim of choosing the suitable logical organization, the memory structure as well as carries on the corresponding algorithm design. The student during the study construction of data and algorithm design’s raises student's abstract thinking ability, logic reasoning ability and the creative thought method, the enhancement analysis question and solves the question ability. This design's Huffman codes the code recognition system, realizes to assigns the text the code and the decoding, and the arbitrary input text may realize the frequency statistics, establishes the Huffman tree as well as the code decoding function. This is one has the complete function system program, to the knowledge which will learn utilizes in the practice, has the very good study and the research value.Keywords:Information; Communication; Coding; Decoding; Procedure第一章课题描述1.1问题描述利用哈夫曼编码进行通信,可以压缩通信的数据量,提高传输效率,缩短信息的传输时间,还有一定的保密性。
现在要求编写一程序模拟传输过程,实现在发送前将要发送的字符信息进行编码,然后进行发送,接收后将传来的数据进行译码,即将信息还原成发送前的字符信息。
1.2需求分析在本例中设置发送者和接受者两个功能,1.2.1发送者的功能:①输入待传送的字符信息;②统计字符信息中出现的字符种类数和各字符出现的次数(频率);②根据字符的种类数和各自出现的次数建立哈夫曼树;③利用以上哈夫曼树求出各字符的哈夫曼编码;④将字符信息转换成对应的编码信息进行传送。
1.2.2接受者的功能:①接收发送者传送来的编码信息;②利用上述哈夫曼树对编码信息进行翻译,即将编码信息还原成发送前的字符信息。
从以上分析可发现,在本例中的主要算法有三个:(1)哈夫曼树的建立;(2)哈夫曼编码的生成;(3)对编码信息的翻译。
1.3程序设计目标层次一:编程从文件中读取一段报文,首先统计字符的频度,然后建立哈夫曼树,并给出报文的编码,然后根据使用者的需要对指定文件里的任意二进制编码进行译码并显示。
层次二:使用者从系统界面输入字符串,统计从键盘输入的字符串信息,然后建立哈夫曼树,并给出报文的编码,然后根据使用者的需要对指定文件里的或者使用者从系统界面输入任意二进制编码的进行译码并显示。
第二章设计简介及设计方案论述2.1设计简介文字处理是现代计算机应用的重要领域。
文本由字符组成,字符以某种编码形式存储在计算机中。
每个字符的编码可以是相等长度的,也可以是不等长度的。
ASCII编码是等长编码。
为了提高存储和处理文本的效率,在一些计算机应用场合,如数据通信,常采用不等长的编码,对常用的字符用较少的码位,不常出现的字符用较多的码位编码,从而减少文本的存储长度。
哈夫曼编码就是用于此目的的不等长编码方法。
所以本次设计就是通过构造哈夫曼树来生成哈夫曼编码,最终完成设计要求。
2.2设计方案论述哈夫曼编码/译码程序主要由主函数、哈夫曼树类和各种功能函数组成,程序运行时首先进入主函数,对各种功能函数进行调用,从而实现了整个程序的运行。
将各种不同的函数分别包含在各自的结构体中,使整个程序结构更加的清晰明了,各功能相互独立且紧密联系,有利于编程的实现,同时也体现了面向对象设计语言的封装性。
在主菜单中运用了switch()函数和“case”语句,便于对整个程序操作和控制;对数据保存在文档中,则运用了文件I/O流和C语言的文件处理方式,进行文件与存之间输入,输出数据。
2.3概要设计2.3.1第一部分功能的实现在主函数声明HuffmanTree1类的对象HuffmanNode,然后用HuffmanNode调用它的成员函数TranslatedCode(),此函数能读取Adata.txt里的字符串并统计,然后建立哈夫曼树并对各个字符编码和保存相关信息。
然后对象HuffmanNode再调用成员函数TranslateArtcle()对指定文件得到的二进制编码进行译码,并保存翻译得到的信息。
2.3.1第二部分功能的实现获取并保存从键盘输入的字符串,并统计其信息。
然后利用这些信息建立哈夫曼树对各个字符进行编码和保存相关信息。
接着可以调用函数HuffmanTranslateCoding2()对指定文件得到的二进制编码信息进行译码和保存得到的翻译信息,或者可以调用HuffmanTranslateCoding()对从系统页面输入的二进制编码进行翻译并保存翻译信息第三章 详细设计3.1 哈夫曼树哈夫曼树也称最优二叉树.给定一组具有确定权值的叶子结点,可以构造出不同的二叉树,将其中带权路径长度最小的二叉树称为哈夫曼树.其中,叶子结点的权值(weight)是对叶子结点赋予的一个有意义的数值量.设二叉树具有n 个带权值的叶子结点,从根结点到各个叶子结点的路径长度与相应叶子结点权值的乘积之和叫做二叉树的带权路径长度(weighted path length),记为:WPL=Wklk 1∑=nk ,w k 为第k 个叶子结点的权值,l k 为从根结点到第k 个叶子结点的路径长度.3.2 哈夫曼算法3.2.1 基本思想根据,哈夫曼的定义,一棵二叉树要使其带权路径长度最小,必须使权值越大的叶子结点越靠近根结点,而权值越小的叶子结点越远离根结点.依据这个特点便提出了哈夫曼算法,其基本思想是:(1) 初始化:由给定的n 个权值{w 1, w 2,…, w n }构造n 棵只有一个根结点的二叉树,从而得到一个二叉树集合F={ T 1,T 2,…,T n };(2) 选取与合并:在F 中选取根结点的权值最小的两棵二叉树分别作为左、右子树构造一颗新的二叉树,这棵新二叉树的根结点的权值为其左、右子树根结点的权值之和;(3) 删除与加入:在F 中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到F 中;(4) 重复(2)、(3)两步,当集合F 中只剩下一棵二叉树时,这棵二叉树便是哈夫曼树.3.2.2 存储结构在由哈夫曼算法构造的哈夫曼树中,非叶子结点的度均为2,根据二叉树的性质可知,具有n个叶子结点的哈夫曼树共有2n-1个结点,其中有n-1个非叶子结点,它们是在n-1次的合并过程中生成的.为了便于选取根结点权值最小的二叉树以及合并操作,设置一个数组HuffmanNode[2n-1]保存哈夫曼树中各结点的信息,数组元素的结点结构如图3-1所示.图3-1 哈夫曼树的结点结构其中,weight:权值域,保存该结点的权值;lchild:指针域,保存该结点的左孩子结点在数组中的下标;rchild:指针域,保存该结点的右孩子结点在数组中的下标;parent:指针域,保存该结点的双亲结点在数组中的下标.Inf:存储相关的字符信息可以用C中的结构类型定义上述结点.struct HuffmanNode{char inf;int weight;int parent;int lchild,rchild;};3.3 哈夫曼编码哈夫曼树可用于构造最短的不等长编码方案,具体做法如下:设需要编码的字符集合为{d1,d2,…,dn},它们在字符串中出现的频率为{w1, w2,…, wn},以d1,d2,…,dn作为叶子结点, w1, w2,…, wn作为叶子结点的权值,构造一颗哈夫曼编码树,规定哈夫曼编码树的左分支代表0,右分支代表1,则从根结点到每个叶子结点所经过的路径组成的0和1的序列便为该叶子结点对应字符的编码,称为哈夫曼编码(Huffman Code).在哈夫曼编码树中,数的带权路径长度的含义是各个字符的码长与其出现次数的乘积之和,所以采用哈夫曼树构造的编码是一种能使字符串的编码总长度最短的不等长编码.由于哈夫曼编码树的每个字符结点都是叶子结点,它们不可能在根结点到其他字符结点的路径上,所以一个字符的哈夫曼编码不可能是另一个字符的哈夫曼编码的前缀,从而保证了解码的唯一性.3.4 C++文件I/O流3.4.1 文件的打开与关闭本程序中,建立流对象调用成员函数open和close进行文件的打开和关闭。