【实验报告】SPSS相关分析实验报告
spss分析实验报告

spss分析实验报告SPSS分析实验报告引言在社会科学研究领域,SPSS(Statistical Package for the Social Sciences)作为一种数据分析工具,被广泛应用于统计分析和数据挖掘。
本实验报告旨在通过SPSS软件对某项研究进行数据分析,探索其背后的数据模式和相关关系。
一、研究背景与目的本次研究旨在探究大学生的学习成绩与睡眠时间之间的关系。
学习成绩和睡眠时间是大学生日常生活中两个重要的方面,通过分析两者之间的关联,可以为学生提供科学的学习指导,提高学习效果。
二、研究设计与数据收集本研究采用问卷调查的方式,通过随机抽样的方法选取了500名大学生作为研究对象。
问卷内容包括学生的学习成绩和每日平均睡眠时间。
收集到的数据以Excel表格的形式整理并导入SPSS软件进行分析。
三、数据预处理在进行数据分析之前,需要对数据进行预处理。
首先,检查数据是否存在缺失值或异常值。
通过SPSS软件的数据清洗功能,将缺失值进行填补或删除,确保数据的完整性和准确性。
其次,对数据进行标准化处理,以消除不同变量之间的量纲差异。
四、描述性统计分析描述性统计分析是对数据的基本特征进行总结和描述。
通过SPSS软件的统计功能,可以计算出学生的学习成绩和睡眠时间的平均值、标准差、最大值、最小值等统计指标。
同时,可以绘制直方图、箱线图等图表来展示数据的分布情况。
五、相关性分析相关性分析是研究不同变量之间相关关系的一种方法。
本研究中,我们使用Pearson相关系数来衡量学习成绩和睡眠时间之间的线性相关性。
通过SPSS软件的相关性分析功能,可以得到相关系数的数值和显著性水平。
如果相关系数接近于1或-1,并且显著性水平小于0.05,则说明学习成绩和睡眠时间之间存在显著的相关关系。
六、回归分析回归分析是研究自变量对因变量影响程度的一种方法。
在本研究中,我们使用线性回归模型来探究睡眠时间对学习成绩的影响。
通过SPSS软件的回归分析功能,可以得到回归方程的系数、显著性水平和模型的拟合优度。
spss实验报告4

spss实验报告4SPSS实验报告4引言:SPSS(Statistical Package for the Social Sciences)是一款广泛应用于社会科学领域的统计分析软件。
它提供了丰富的数据处理和分析功能,帮助研究人员从大量数据中提取有意义的信息。
本实验报告旨在通过使用SPSS软件,进行一系列实验,来探索其在数据分析方面的应用。
实验一:数据导入和清洗在实验一中,我们首先学习了如何将数据导入SPSS软件中。
通过导入实际的数据集,我们可以更好地理解数据的结构和特征。
然后,我们进行了数据清洗的过程,包括处理缺失值、异常值和重复值等。
通过这一步骤,我们可以确保数据的质量和准确性,为后续的分析做好准备。
实验二:描述性统计分析在实验二中,我们学习了描述性统计分析的方法和应用。
通过计算平均值、中位数、标准差等指标,我们可以对数据集的基本特征进行描述和分析。
此外,我们还学习了绘制直方图、散点图和箱线图等图表,以更直观地展示数据的分布和关系。
这些分析方法和图表可以帮助我们初步了解数据的特征和规律。
实验三:推断性统计分析在实验三中,我们进一步学习了推断性统计分析的方法和应用。
通过使用t检验、方差分析和相关分析等统计方法,我们可以从样本数据中推断出总体的特征和关系。
这些方法可以帮助我们验证研究假设、比较不同组别之间的差异和关联性等。
通过实际的案例分析,我们可以更好地理解这些方法的原理和应用场景。
实验四:回归分析在实验四中,我们学习了回归分析的方法和应用。
通过建立回归模型,我们可以探索自变量与因变量之间的关系,并预测因变量的取值。
在实验中,我们使用了线性回归和多元回归等方法,来分析自变量对因变量的影响程度和方向。
此外,我们还学习了如何评估回归模型的拟合优度和解释力,以及如何进行模型的诊断和改进。
实验五:聚类分析在实验五中,我们学习了聚类分析的方法和应用。
聚类分析是一种无监督学习的方法,可以将相似的样本聚集到一起,形成不同的群组。
SPSS实验分析报告四

SPSS实验分析报告四第一篇:SPSS实验分析报告四SPSS实验分析报告四一、地区*日期*销售量(一)、提出假设原假设H0=“不同地区对销售量的平均值没有产生显著影响。
” H2=“不同日期对销售量的平均值没有产生显著影响。
” H3=“不同的地区和日期对销售量没有产生了显著的交互作用。
”(二)、两独立样本t检验结果及分析表(一)主旨間係數地区 2 3 日期 2 3數值標籤地区一地区二地区三周一至周三周四至周五周末N 9 9 9 9 9 9表(一)表示各个控制变量的分组情况,包括三个不同的地区以及三个不同日期的数据。
表(二)销售额多因素方差分析结果主体间效应的检验因變數: 销售量來源第 III 類平方和修正的模型 61851851.852adf 8平均值平方 7731481.481F 8.350顯著性.000 截距地区日期地区 * 日期錯誤總計 844481481.4812296296.296 2740740.741 56814814.8***.667 923000000.000 2 2 4 18 27 26844481481.481 1148148.148 1370370.370 14203703.704 925925.926912.040 1.240 1.480 15.340.000.313.254.000校正後總數 78518518.519 a.R平方 =.788(調整的 R平方 =.693)由表(二)可知,第一列是对观测变量总变差分解的说明;第二列是对观测变量总变差分解的结果;第三列是自由度;第四列是方差;第五列是F检验统计量的观测值;第六列是检验统计量的概率P值。
可以看到:观测变量的总变差SST为78518518.519,它被分解为四个部分,分别是:由地区(x2)不同引起的变差(2296296.296),由日期(x3)不同引起的变差(2740740.741),由地区和日期交互作用(x2*x3)引起的变差(5.681E7),由随机因素引起的变差(Error 1.667E7)。
spss分析实验报告

SPSS分析实验报告引言SPSS(统计包括社会科学)是一种常用的统计分析软件,广泛应用于社会科学领域的数据分析。
本文将以“step by step thinking”为思维导向,详细介绍如何使用SPSS进行实验数据的分析和结果解读。
步骤一:数据导入首先,我们需要将实验数据导入SPSS软件中。
打开SPSS软件,点击“文件”菜单,并选择“导入数据”。
选择数据文件所在位置,并按照指示完成数据导入过程。
确认数据导入完成后,我们可以开始进行下一步分析。
步骤二:数据清洗在进行实验数据分析之前,我们需要对数据进行清洗,以确保数据的准确性和可靠性。
数据清洗的步骤包括删除重复数据、处理缺失值和异常值等。
通过点击SPSS软件中的“数据”菜单,我们可以找到相应的数据清洗工具,并按照指示进行操作。
步骤三:描述性统计描述性统计是对数据进行总体特征描述的过程。
在SPSS软件中,我们可以使用“统计”菜单中的“描述统计”工具进行描述性统计分析。
该工具可以计算数据的均值、标准差、中位数等统计量,为后续的分析提供参考。
步骤四:检验假设在进行实验数据分析时,我们通常需要检验某些假设是否成立。
SPSS软件提供了多种假设检验工具,如t检验、方差分析等。
通过点击“分析”菜单,并选择相应的假设检验工具,我们可以输入所需的参数,并进行假设检验。
根据检验结果,我们可以判断实验数据是否支持或拒绝了我们的假设。
步骤五:相关性分析相关性分析用于研究两个或多个变量之间的关系。
SPSS软件中的“相关”工具可以计算出变量之间的相关系数,并绘制相应的相关图表。
通过相关性分析,我们可以了解变量之间的线性关系,并得出相关系数的显著性程度。
步骤六:回归分析回归分析是一种用于预测和解释变量之间关系的统计方法。
在SPSS软件中,我们可以使用“回归”工具进行回归分析。
通过输入自变量和因变量,并进行回归分析,我们可以得到回归方程和相关统计指标,进而进行预测和解释。
结果解读根据以上分析步骤,我们可以得到一系列实验数据的统计分析结果。
spss对数据进行相关性分析实验报告

spss对数据进行相关性分析实验报告一、实验目的与背景在统计学的研究中,相关性分析是一种常见的分析方法,用于研究两个或多个变量之间的关联程度。
本实验旨在使用SPSS软件对收集到的数据进行相关性分析,并探索变量之间的关系。
二、实验过程1. 数据收集:根据研究目的,我们收集了一份包含多个变量的数据集。
其中,变量包括A、B、C等。
2. 数据准备:在进行相关性分析之前,我们需要对数据进行准备。
首先,我们载入数据集到SPSS软件中。
然后,对于缺失数据,我们根据需要采取相应的填补或删除策略。
接着,我们进行数据的清洗和整理,以确保数据的准确性和一致性。
3. 相关性分析:使用SPSS软件,我们可以轻松地进行相关性分析。
在SPSS的分析菜单中,选择相关性分析功能,并设置相应的参数。
我们将选择Pearson相关系数,该系数用于衡量两个变量之间的线性相关关系。
此外,还可以选择其他类型的相关系数,如Spearman相关系数,用于非线性关系的探索。
设置参数后,我们点击“运行”按钮,即可得到相关性分析的结果。
4. 结果解读:SPSS将为我们提供一份详细的结果报告。
我们可以看到每对变量之间的相关系数及其显著性水平。
如果相关系数接近1或-1,并且P值低于显著性水平(通常为0.05),则可以得出两个变量之间存在显著的线性相关关系的结论。
此外,我们还可以通过散点图、线性回归等方法进一步分析相关性结果。
5. 结论与讨论:根据相关性分析的结果,我们可以得出结论并进行讨论。
如果发现两个变量之间存在显著的相关关系,我们可以进一步探究其原因和意义。
同时,我们还可以提出假设并设计更深入的实验,以验证和解释这些相关性。
三、结果与讨论根据我们的研究目的和数据集,通过SPSS软件进行的相关性分析显示了一些有意义的结果。
我们发现变量A与变量B之间存在显著的正相关关系(Pearson相关系数为0.7,P<0.05)。
这表明随着A的增加,B也会相应增加。
SPSS的相关分析实验报告
第三题:
1打开SPSS软件,建立不同地区不同质量原料数据的文件,并保存为“数据二.sav”,如图
2选择菜单:【Analyze】→【Descriptive Statistics】→【Crosstabs】,将“地区”选入行变量,将“原料质量”选入列变量,在Cells和Statistics中选择需要计算的检验方式。
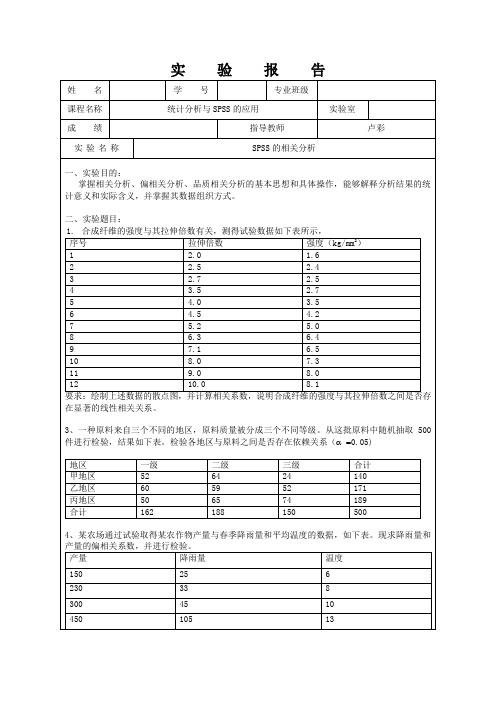
实验报告
姓名
学号
专业班级
课程名称
统计分析与SPSS的应用
实验室
成绩
指导教师
卢彩
实验名称
SPSS的相关分析
一、实验目的:
掌握相关分析、偏相关分析、品质相关分析的基本思想和具体操作,能够解释分析结果的统计意义和实际含义,并掌握其数据组织方式。
二、实验题目:
1.合成纤维的强度与其拉伸倍数有关,测得试验数据如下表所示,
3、一种原料来自三个不同的地区,原料质量被分成三个不同等级。从这批原料中随机抽取500件进行检验,结果如下表。检验各地区与原料之间是否存在依赖关系(0.05)
地区
一级
二级
三级
合计
甲地区
52
64
24
140
乙地区
60
59
52
171
丙地区
50
65
74
189
合计
162
188
150
500
4、某农场通过试验取得某农作物产量与春季降雨量和平均温度的数据,如下表。现求降雨量和产量的偏相关系数,并进行检验。
产量
降雨量
温度
150
spss对数据进行相关性分析实验报告
管理统计实验报告实验一一.实验目的掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。
二.实验原理相关性分析是考察两个变量之间线性关系的一种统计分析方法。
更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。
P值是针对原假设H0:假设两变量无线性相关而言的。
一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p 值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。
越小,则相关程度越低。
而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。
三、实验内容掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。
(1)检验人均食品支出与粮价和人均收入之间的相关关系。
a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击Analyze correlate Bivariate,弹出一个对话窗口。
C.在对话窗口中点击ok,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间显著相关。
人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为0.000<0.01,拒绝零假设,表明两个变量之间也显著相关。
(2)研究人均食品支出与人均收入之间的偏相关关系。
读入数据后:A.点击Analyze correlate partial,系统弹出一个对话窗口。
B.点击OK,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.000<0.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.8665<0.921,说明它们之间的显著性关系稍有减弱。
spss对数据进行相关性分析实验报告
spss对数据进行相关性分析实验报告SPSS数据相关性分析实验报告一、引言数据相关性分析是一种用统计方法来研究变量之间关系的方法。
SPSS作为一种常用的统计软件,具有丰富的功能和灵活性,能够对数据进行多角度的分析和解读。
本报告旨在利用SPSS对一组样本数据进行相关性分析,并通过报告的形式详细介绍分析的步骤和结果。
二、实验设计和数据采集本次实验选取了一个包括X变量和Y变量的数据集,通过观察这两个变量之间的相关关系,探究它们之间是否存在一定的线性关系。
三、数据清洗与统计描述在进行相关性分析之前,需要对数据进行清洗和统计描述。
首先,通过观察数据的分布情况,检查是否存在异常值。
如果出现异常值,可以采取删除或者替换的方式进行处理。
其次,计算数据的均值、标准差、最大值、最小值等统计指标,了解数据的基本特征。
四、Pearson相关系数分析Pearson相关系数是一种常用的衡量两个变量之间的相关性的方法。
它的取值范围在-1到1之间,接近于1表示正相关,接近于-1表示负相关,接近于0则表示无相关性。
在SPSS中,进行Pearson相关系数分析非常简便。
五、Spearman相关系数分析Spearman相关系数是一种非参数检验方法,用于观察变量之间的单调关系。
相比于Pearson相关系数,它对于异常值的鲁棒性更强。
在SPSS中,可以选择Spearman相关系数分析来研究数据集中的变量之间的关系。
六、结果分析与讨论经过Pearson相关系数和Spearman相关系数的分析,我们得出如下结论:X变量与Y变量之间存在显著的正相关关系。
通过相关系数的计算,结果显示相关系数为0.8,说明二者之间具有较强的线性相关性。
这一结果与我们的研究假设相吻合,证明了X变量对Y变量的影响。
七、实验结论通过SPSS对数据进行相关性分析,我们得出结论:X变量与Y变量之间存在显著的正相关关系。
这一结论进一步加深了对于变量之间关系的理解,为后续的研究提供了参考。
spss对应分析实验报告
SPSS对应分析实验报告1. 引言本实验旨在使用SPSS软件对一组数据进行对应分析,以探究不同变量之间的相关性。
对应分析是一种多元统计方法,用于研究两个变量之间的关系,可以帮助我们理解变量之间的相互作用和相关程度。
2. 数据收集与处理在本实验中,我们收集了一组包含两个变量的数据。
变量A表示一个人的年龄,变量B表示他们的学习成绩。
我们通过调查问卷的形式收集了这些数据,并将其导入SPSS软件进行后续的分析。
3. 数据分析步骤1:导入数据首先,我们需要将收集到的数据导入SPSS软件。
在SPSS的菜单栏中选择“文件”->“导入数据”,选择正确的数据文件并进行导入。
步骤2:变量选择在数据导入后,我们需要选择我们要分析的变量。
在SPSS的变量视图中,选择变量A和变量B,并将它们移到分析视图中。
步骤3:描述性统计在开始对应分析之前,我们可以先对数据进行描述性统计。
在SPSS的菜单栏中选择“分析”->“描述统计”->“描述性统计”。
选择变量A和变量B,并点击“确定”按钮,SPSS将生成包含均值、标准差等统计指标的报告。
步骤4:对应分析接下来,我们可以进行对应分析。
在SPSS的菜单栏中选择“分析”->“相关”->“对应分析”。
选择变量A和变量B,并点击“确定”按钮,SPSS将生成对应分析的结果报告。
步骤5:结果解释对应分析的结果报告中,我们能够看到变量A和变量B之间的相关系数,以及相关系数的显著性水平。
通过这些信息,我们可以判断变量A和变量B之间的关系是否显著,以及相关性的方向和强度。
4. 结论通过对应分析实验,我们得出以下结论:1.变量A和变量B之间存在显著的相关性。
2.相关系数为正数,表明变量A的增加与变量B的增加呈正相关关系。
3.相关系数的数值较高,说明变量A和变量B之间的相关性较强。
这些结论对我们理解变量A和变量B之间的关系,以及对进一步研究和分析具有重要意义。
5. 结束语SPSS是一款功能强大的统计软件,可以帮助我们进行各种数据分析。
spss对数据进行相关性分析实验报告
spss对数据进行相关性分析实验报告一、实验目的本次实验旨在运用 SPSS 软件对给定的数据进行相关性分析,以探究不同变量之间的关系,为进一步的研究和决策提供有价值的信息。
二、实验原理相关性分析是一种用于研究两个或多个变量之间线性关系强度和方向的统计方法。
常用的相关性系数包括皮尔逊(Pearson)相关系数、斯皮尔曼(Spearman)相关系数等。
皮尔逊相关系数适用于两个连续变量之间的线性关系分析,要求变量服从正态分布;斯皮尔曼相关系数则适用于有序变量或不满足正态分布的变量。
三、实验数据本次实验使用的数据来源于具体来源,包含了变量数量个变量,分别为变量名称 1、变量名称2……变量名称 n。
每个变量包含了样本数量个观测值。
四、实验步骤1、数据导入打开 SPSS 软件,选择“文件”菜单中的“打开”选项,找到并选中要分析的数据文件。
在弹出的对话框中,根据数据的格式选择相应的导入方式,如CSV、Excel 等。
2、变量定义在“变量视图”中,对导入的变量进行定义,包括变量名称、类型、宽度、小数位数等。
3、相关性分析选择“分析”菜单中的“相关”选项,在弹出的子菜单中选择“双变量”。
将需要分析相关性的变量选入“变量”框中。
根据变量的类型和分布特征,选择合适的相关性系数,如皮尔逊或斯皮尔曼相关系数。
点击“确定”按钮,运行相关性分析。
五、实验结果1、相关性系数矩阵输出的相关性系数矩阵显示了各个变量之间的相关性系数值。
系数值的范围在-1 到 1 之间,-1 表示完全负相关,1 表示完全正相关,0 表示无相关性。
2、显著性水平除了相关性系数值外,还输出了每个相关性系数的显著性水平(p 值)。
p 值小于 005 通常被认为相关性是显著的。
以下是对实验结果的具体分析:变量 1 与变量 2 的相关性分析:相关性系数为具体数值,表明变量 1 和变量 2 之间存在正/负相关关系。
p 值为具体数值,小于 005,说明这种相关性在统计上是显著的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS相关分析实验报告
篇一:spss对数据进行相关性分析实验报告
实验一
一.实验目的
掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。
二.实验原理
相关性分析是考察两个变量之间线性关系的一种统计分析方法。
更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。
P值是针对原假设H0:假设两变量无线性相关而言的。
一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。
越小,则相关程度越低。
而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。
三、实验内容
掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。
(1)检验人均食品支出与粮价和人均收入之间的相关关系。
a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。
C.在对话窗口中点击ok,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.0000.01,拒绝零假设,表明两个变量之间显著相关。
人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为
0.0000.01,拒绝零假设,表明两个变量之间也显著相关。
(2)研究人均食品支出与人均收入之间的偏相关关系。
读入数据后:
A.点击系统弹出一个对话窗口。
B.点击OK,系统输出结果,如下表。
从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.0000.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.86650.921,说明它们之间的显著性关系稍有减弱。
通过相关关系与偏相关关系的比较可以得知:在粮价的影响下,人均收入对人均食品支出的影响更大。
三、实验总结
1、熟悉了用spss软件对数据进行相关性分析,熟悉其操作过程。
2、通过spss软件输出的数据结果并能够分析其相互之间的关系,并且解决实际问题。
3、充分理解了相关性分析的应用原理。
实验二
一、实验目的
掌握用spss软件对数据进行分析,用K-S检验单一样本是否来自某一特定分布,熟悉其操作过程,并能分析其结果。
二、实验原理
K-S检验方法能够利用样本数据推断样本来自的总体是否服从某一理论分布,是一种拟合优度的检验方法,适用于探索连续型随机变量的分布。
单样本K-S检验的原假设是:样本来自得总体与指定的理论分布无显著差异,SPSS的理论分布主要包括正态分布、均匀分布、指数分布和泊松分布等。
它的假设检验问题:H0:样本所来自的总体分布服从某特定分布
H1:样本所来自的总体分布不服从某特定分布
k-s检验是一种非常实用的检验数据分布的方法,应该熟练掌握。
二.实验内容
用k-s检验“回归人均食品支出”数据中的人均收入服从什么分布,并且了解k-s检验的操作过程和原理。
A.打开spss软件,输入“回归人均食品支出”数据。
B.点击nonparametric tests
1-sample k-s,系统弹出一个对话窗口。
C.点击OK,系统输出结果,如下表。
在上面有四个检验,Test1是检验这组数据是否服从标准正态分布,从表中可看出T检验的显著性概率为0.1400.05,接受零假设,即这组数据服从标准正态分布。
Test2是检验这组数据是否服从均匀分布,从表中可看出T检验的显著性概率为0.0000.05,拒绝零假设,即这组数据不服从均匀分布。
Test3是检验这组数据是否服从指数分布,从表中可看出T检验的显著性概率为0.0000.05,拒绝零假设,即这组数据不服从指数分布。
Test4是检验这组数据是否服从泊松分布,从表中可看出T检验的显著性概率为0.0000.05,拒绝零假设,即这组数据不服从泊松分布。
三、实验总结
k-s检验方法是以样本数据的累计频数分布与特定理论分布比较,若两者间的差距很小,则推论该样本取自某特定分布族。
篇二:SPSS相关分析实验报告
实验报告
学生姓名:
一、实验室名称:
二、实验项目名称:
相关分析
三、实验原理
相关关系是不完全确定的随机关系。
在相关关系的情况下,当一个或几个相互联系的变量取一定值得时候,与之相应的另一变量的值虽然不确定,但它仍然按照某种规律在一定的范围内变化。
按照数据度量的尺度不同,相关分析的方法也不同,连续变量之间的相关性常用Pearson简单相关系数测定;定序变量的相关系数常用Spearman秩相关系数和Kendall秩相关系数测定;定类变量的相关分析要使用列连表分析法。
四、实验目的
理解相关分析的基本原理,掌握在SPSS软件中相关分析的主要参数设置及其含义,掌握SPSS软件分析结果的含义及其分析。
五、实验内容及步骤
实验内容:以雇员表为例,共有474条数据,运用相关分析方法对变量间的相关关系进行分析。
1)分析性别与工资之间是否存在相关关系。
2)分析教育程度与工资之间是否存在相关关系。
实验要求:掌握相关分析方法的计算思路及其在SPSS环境下的操作方法,掌握输出结果的解释。
1. 分析性别与工资之间是否存在相关关系。
分析:性别属于定类变量,是离散值,因使用卡方检验。
Step1.操作为Analyze Descriptive Statistics Crosstabs
Step2.将性别(Gender)和收入(Current Salary)分别移入Rows列表框和Columns列表框。
Step3.单击Statistics按钮,在弹出的子对话框中选中默认的Chi-square,进行卡方检验。
退回到主对话框,单击ok。
2. 分析教育程度与工资之间是否存在相关关系。
分析:教育程度为定序变量,工资为连续变量,可使用Spearman和Kendall秩相关系数检验。
Step1. 用散点图初步判断二变量的相关性,操作为Graphs / Legacy Dialogs / Scatter,选择Simple Scatter,教育程度为自变量,工资为因变量,做散点图。