5因子分析解析
5-安全因子分析

FATIGUE ANALYSIS IN HYPERLIFE CHAPTER 5: FACTOR OF SAFETY ANALYSISHYPERLIFE疲劳分析内容1.疲劳分析流程及HyperLife界面介绍2.疲劳分析基本概念3.高周疲劳(S-N)4.低周疲劳(E-N)5.安全因子分析6.焊缝疲劳安全因子分析•Dang Van安全因子评价准则•采用HyperLife进行安全因子计算DANG VAN方法介绍•Dang Van方法用来预测结构能否经历无限寿命•可以使用Dang Van方法进行分析的部件包括:➢承受多轴循环载荷的汽车零部件➢螺旋桨轴➢喷气式涡轮叶片DANG VAN CRITERION AND THE FACTOR OF SAFETY (FOS)•安全系数采用Dang Van准则进行分析•Dang Van分析中的安全系数(FOS)的计算为一系列微观偏剪应力(Microscopic Deviatoric Shear Stress )和宏观静应力(Macroscopic Hydrostatic Stress )计算的FOS 值的最小值•FOS计算涉及整个加载历程,将微观偏剪应力和宏观静应力作为时间的函数来计算。
is the Microscopic Shear Stressis the Macroscopic hydrostatic Stressare material constants•如果FOS 小于1,零部件将不能经历无限寿命•当前仅支持Dang Van 方法计算多轴疲劳安全系数•设置有限元模型单位:➢选择有限元模型单位,以便有限元应力到SN曲线应力的转换。
•可采用多种方法定义安全区域•失效线可以指定为一个单一的线段,也可以通过剪切应力与静压力的多个连续连接点(曲线)来指定•可以在“Assign Material ”模块中设置扭转疲劳极限值和静压力灵敏度值•在HyperLife中通过TFL值设置安全边界•TFL 为实数•TFL为曲线•TFL为实数TFL= HSS * HP + τ;When τ = 0, HP = Tfl/ HSSTFL: 扭转疲劳极限, HP:静水压力,T (tau):微观剪应力, HSS:静水压力敏感系数•TFL为曲线➢x值为静水压力,y值为剪切力➢STHETA:安全区角度。
5因子分析

华中农业大学数学建模基地 网站
6 因子分析
由于F1、F2与每一个Xi都有关,因此,研究这 5个指标变量之间的关系可以转化为研究这两个潜 在因子之间的关系。 因子分析的基本原理就是依据可测指标变量 之间的相关关系,把一些具有错综复杂关系的变 量归结为少数几个有实际意义的潜在因子,并估 计出潜在因子对可测指标变量的影响程度。
6 因子分析
因子分析模型是主成分分析的推广。它也是利用 降维的思想,由研究原始变量相关矩阵内部的依赖关 系出发,把一些具有错综复杂关系的变量归结为少数 几个综合因子的一种多变量统计分析方法。 因子分析的思想始于1904年Charles Spearman对 学生考试成绩的研究。近年来,随着电子计算机的高 速发展,人们将因子分析的理论成功地应用于心理学、 医学、气象、地质、经济学等各个领域,也使得因子 分析的理论和方法更加丰富。
华中农业大学数学建模基地 网站
data ex842; input objects$ pop school employ services house@@; cards; /*数据省略*/ ; proc factor data=ex842 method=principal rotate=varimax /*rotate表示因子旋转*/ percent=0.8 /*要求累计贡献率大于0.8*/ score outstat=ex1; /*计算因子得分*/ var pop school employ services house; run; proc score data=ex842 score=ex1 out=ex2; var pop school employ services house; run; proc print data=ex1; proc print data=ex2; run;
5因子分析

2、因子特征值及百分比
Initial Eigenvalues Compon er Craction Sums of Squared Loadings Rotation Sums of Squared Loadings
Total
% of Varia nce 31.900 15.933 13.402 10.139 8.536 8.024 6.856 5.209
2、基本步骤: 1)选择基础变量,并对基础变量的适合状况 进行分析(相关关系测量); 2)从基础变量中提取因子(公共因子法与主 成分法),涉及因子个数判别,因子个数应 少于基础变量; 3)进行因子旋转,即通过坐标变换使因子两 两独立,以得到更合理的因子解。不旋转, 因子负荷有时可能过分偏低。可注意对比转 轴前后的因子负荷矩阵; 4)计算每个样本在各个因子上的因子得分, 该得分即是每个样本在各因子变量上的取值。
• 重要概念: 因子负荷是一个矩阵,表示公因子与基 础变量间的相关系数。负荷大,表示 该公因子与某基础变量间存在较大关 系。观察负荷矩阵,可以看出公因子 在哪些变量上有较大负荷,可以据此 说明公因子的实际含义。若矩阵缺乏 规律,不能看出某个含义,还需要进 行因子旋转,(增加因子变量)以求得更好 的解释。
五、因子分析应用范例 1、问卷题目删留情况: 问卷的第三部分关于“群体身份认同”的调查采用里克特五 等级尺度总加量表,在问卷录入时,根据回答强态度的强 弱对回答结果进行赋值,具体赋值情况是:完全不同意为1, 有点不同意为2,说不清为3,基本同意为4,完全同意为5。 项目分析的目的是为了对项目进行筛选和修订,项目的选 择采用双重标准,首先计算项目鉴别系数,然后计算单项 与总分的相关系数。项目鉴别度的计算公式为:项目鉴别 指数=(RH-RL)/N 在此公式中,RH表示高分组在每个项目上的平均得分(高分 组之和除以N),RL表示低分组在每个项目上的平均得分 (低分组之和除以N),N表示抽出的项目数。从数据分析 结果看,有2项的鉴别指数达不到0.25(第21题和第26题), 首先删除;再进行单项与总分的相关系数计算(本量表采 用Pearson相关系数),结果显示有一项(第25题)相关系 数达不到显著性程度(P<0.05),最后保留8项。
实验五 因子分析
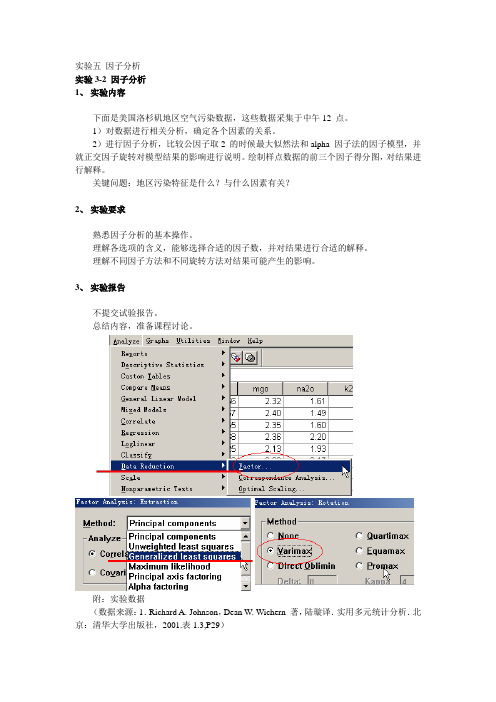
实验五因子分析
实验3-2 因子分析
1、实验内容
下面是美国洛杉矶地区空气污染数据,这些数据采集于中午12 点。
1)对数据进行相关分析,确定各个因素的关系。
2)进行因子分析,比较公因子取2 的时候最大似然法和alpha 因子法的因子模型,并就正交因子旋转对模型结果的影响进行说明。
绘制样点数据的前三个因子得分图,对结果进行解释。
关键问题:地区污染特征是什么?与什么因素有关?
2、实验要求
熟悉因子分析的基本操作。
理解各选项的含义,能够选择合适的因子数,并对结果进行合适的解释。
理解不同因子方法和不同旋转方法对结果可能产生的影响。
3、实验报告
不提交试验报告。
总结内容,准备课程讨论。
附:实验数据
(数据来源:1.Richard A. Johnson,Dean W. Wichern 著,陆璇译.实用多元统计分析.北京:清华大学出版社,2001.表1.3,P29)。
因子分析中的因子结构验证方法(五)

因子分析是一种常用的数据分析方法,用于发现变量间的潜在结构和关系。
在因子分析中,因子结构验证是非常重要的一部分,它帮助研究人员确定所提取的因子是否能够合理地解释观察到的变量之间的关系。
本文将介绍因子分析中的因子结构验证方法,并探讨其在实际研究中的应用。
一、探索性因子分析探索性因子分析是一种旨在探索变量之间潜在结构的方法。
在这种分析中,研究人员首先提取潜在因子,并根据因子载荷矩阵来解释这些因子和变量之间的关系。
在因子结构验证中,研究人员通常会使用各种统计方法来确定所提取的因子是否合理。
二、验证性因子分析验证性因子分析是用于验证由探索性因子分析提取的因子结构的方法。
在这种分析中,研究人员会根据理论假设提出一个模型,并使用统计方法来检验这个模型是否与观察数据相匹配。
常用的检验方法包括卡方检验、比较拟合指数(CFI)、增量拟合指数(IFI)等。
三、因子旋转因子旋转是一种常用的因子结构验证方法,它旨在提高因子载荷的解释性和可解释性。
常用的因子旋转方法包括方差最大化旋转(VARIMAX)、等方差最小化旋转(EQUAMAX)、极大似然旋转等。
通过因子旋转,研究人员可以更清晰地解释所提取的因子结构,从而提高研究结果的可信度。
四、交叉验证交叉验证是一种常用的因子结构验证方法,它通过将样本数据随机分成两个部分,一部分用于提取因子结构,另一部分用于验证提取的因子结构。
通过交叉验证,研究人员可以确保所提取的因子结构是稳健的,并且具有较好的泛化能力。
五、拆分样本验证拆分样本验证是一种常用的因子结构验证方法,它通过将样本数据分成两个部分,一部分用于提取因子结构,另一部分用于验证提取的因子结构。
拆分样本验证可以帮助研究人员检验因子结构在不同样本中的稳定性,从而提高研究结果的可信度。
六、交叉验证因子分析交叉验证因子分析是一种结合了交叉验证和验证性因子分析的方法,它旨在提高因子结构验证的稳健性和泛化能力。
通过交叉验证因子分析,研究人员可以在保证模型的合理性的同时,确保因子结构具有较好的泛化能力,从而提高研究结果的可信度。
因子分析中的变量筛选与因子提取方法(五)

因子分析是一种常用的多变量统计方法,它用于探索和解释变量之间的关系。
在因子分析中,变量的选择和因子的提取方法对最终结果有很大的影响。
因此,对于因子分析中的变量筛选和因子提取方法的选择,需要进行深入的讨论和研究。
变量筛选是因子分析的第一步,其目的是选择对因子分析有意义的变量。
在变量筛选的过程中,可以采用多种方法。
一种常用的方法是基于相关性分析来选择变量。
通过计算变量之间的相关系数,可以确定哪些变量之间存在较强的相关性,从而选择具有代表性的变量进行因子分析。
另一种方法是基于专家判断来选择变量。
专家可以根据自己的经验和知识,选择与研究问题相关的变量进行因子分析。
此外,还可以利用统计方法来选择变量,如主成分分析和聚类分析等。
这些方法都可以帮助研究者选择合适的变量进行因子分析,从而提高因子分析的效果和准确性。
在变量筛选的基础上,因子提取方法是因子分析的关键步骤之一。
因子提取方法的选择直接影响到最终提取的因子结构。
常用的因子提取方法包括主成分分析法(PCA)和最大似然方法等。
主成分分析法是一种基于变量之间的线性关系进行因子提取的方法。
它通过将原始变量进行线性变换,得到一组新的主成分,从而实现降维和提取因子的目的。
最大似然方法是一种基于统计假设的因子提取方法。
它假设样本数据服从多变量正态分布,并通过最大化似然函数来估计因子载荷矩阵,从而得到最大似然估计的因子结构。
除了这些常用的因子提取方法外,还有许多其他因子提取方法,如最小平方法、主轴法等。
这些方法都有各自的特点和适用范围,研究者需要根据研究问题的具体情况来选择合适的因子提取方法。
在选择因子提取方法的同时,还需要考虑因子数的确定。
因子数的确定对因子分析的结果有很大的影响。
一般情况下,可以通过因子数的特征值、累积方差贡献率和平行分析等方法来确定因子数。
特征值是指因子解释的方差大小,通常情况下,特征值大于1的因子被认为是有效的因子。
累积方差贡献率是指因子提取后能够解释的总方差比例。
因子分析法详细步骤-因子分析法操作步骤

心理学研究
在心理学研究中,因子分析法 常用于人格特质、智力等方面 的研究。
社会学研究
在社会学研究中,因子分析法 可用于社会结构、文化等方面
的研究。
02 因子分析法操作步骤
数据标准化
总结词
消除量纲和数量级的影响
详细描述
在进行因子分析之前,需要对数据进行标准化处理,即将原始数据转换为均值为0、标准差为1的标准化数据,以 消除不同量纲和数量级对分析结果的影响。
案例三:品牌定位研究
总结词
通过因子分析法,明确品牌的定位和竞争优 势,以便更好地进行市场推广和竞争策略制 定。
详细描述
首先,收集市场上同类竞争品牌的定位和竞 争优势数据。然后,利用因子分析法对这些 数据进行处理,提取出几个主要的因子,这 些因子代表了不同品牌的定位和竞争优势。 最后,根据因子分析的结果,明确自己品牌 的定位和竞争优势,制定相应的市场推广和 竞争策略,以提高品牌的市场份额和竞争力
要点二
详细描述
首先,收集大量关于消费者行为和偏好的数据,包括购买 行为、品牌选择、价格敏感度等。然后,利用因子分析法 对这些数据进行降维处理,提取出几个主要的因子,这些 因子代表了消费者不同的需求和偏好。最后,根据这些因 子对市场进行细分,将消费者划分为不同的群体,并为每 个群体制定相应的营销策略。
计算相关系数矩阵
总结词
评估变量间的相关性
详细描述
计算标准化数据的相关系数矩阵,用于评估变量之间的相关性。相关系数矩阵 是一个对称矩阵,矩阵中的元素表示不同变量之间的相关系数,用于衡量变量 间的关联程度。
因子提取
总结词
找出主要因子
详细描述
通过因子提取的方法,从相关系数矩阵中找出主要因子。常用的因子提取方法有主成分分析法和公因 子分析法等。这一步的目标是找出能够解释原始数据变异的少数几个公共因子。
第五章 因子分析

模型中的 aij 称为因子“载荷” ,是第 i 个变量在第 j 个因子上 的负荷,如果把变量 X i 看成 m 维空间中的一个点,则 aij 表 示它在坐标轴 Fj 上的投影,因此矩阵 A 称为因子载荷矩阵。 (二)Q 型因子分析 类似地,Q 型因子分析的数学模型可表示为:
X i ai1F1 ai 2 F2 aim Fm i , ( i 1, 2,, n )
(7.3) Q 型因子 分析与 R 型因子 分析模 型的差 异体现在 , X 1 , X 2 ,, X n 表示的是 n 个样品。
无论是R型或Q型因子分析,都用公共因子F代替X,一般要求 m<p,m<n,因此,因子分析与主成分分析一样,也是一种降 低变量维数的方法。我们下面将看到,因子分析的求解过程同 主成分分析类似,也是从一个协方差阵出发的。 因子分析与主成分分析有许多相似之处,但这两种模型又存在 明显的不同。 主成分分析的数学模型本质上是一种线性变换,是将原始坐标 变换到变异程度大的方向上去,相当于从空间上转换观看数据 的角度,突出数据变异的方向,归纳重要信息。 而因子分析从本质上看是从显在变量去“提练”潜在因子的过 程。正因为因子分析是一个提练潜在因子的过程,因子的个数 m取多大是要通过一定规则确定的,并且因子的形式也不是唯 一确定的。一般说来,作为“自变量”的因子F1,F2,…,Fm 是不可直接观测的。这里我们应该注意几个问题。
由模型(7.2)式所满足的条件知
Σ AA D
(7.4)
如果 X 为标准化了随机向量,则 Σ 就是相关矩阵 R ( ij ) , 即
R AA D
(7.5)
第二,因子载荷是不唯一的。这是因为对于 m m 的正交矩 阵 T ,令 A* AT , F * T F ,则模型可以表示为 X A* F * ε 由于 D(F * ) T D(F )T T T I mm
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二、因子分析的数据要求和基本步骤 1、数据要求: 1)进行因子分析的各基础变量应是定距变 量,虚拟变量可以同时引入,但结果可 能不好(Why?数量级的影响); 2)各基础变量间应存在较强的相关关系。 可以计算各变量的相关矩阵(两两变量之间的 相关系数),最好相关矩阵中的所有相关系 数大于0.3;SPSS提供巴雷特球体检验和 KMO值,要求检验通过且KMO值大于 0.5,否则不能进行因子分析,KMO值大 于0.9时效果最好 。
2、基本步骤: 1)选择基础变量,并对基础变量的适合状况 进行分析(相关关系测量); 2)从基础变量中提取因子(公共因子法与主 成分法),涉及因子个数判别,因子个数应 少于基础变量; 3)进行因子旋转,即通过坐标变换使因子两 两独立,以得到更合理的因子解。不旋转, 因子负荷有时可能过分偏低。可注意对比转 轴前后的因子负荷矩阵; 4)计算每个样本在各个因子上的因子得分, 该得分即是每个样本在各因子变量上的取值。
5)在路径分析模型(缺乏总的解释力)向 结构方程模型Lisrel(可以有总解释力) 转化中,潜在变量的影响作用常需作因子 处理(因为太多了),结构分析因此由回归 和因子分析组成。 如经典的研究子女收入的路径分析中,子 女教育程度被单向认为是决定子女收入的, 但实际上子女收入也会反过来影响子女教 育程度,且在子女收入上除教育程度外, 个人各种能力也会影响收入,这时只能使 用结构分析模型,个人能力影响部分就需 先作因子分析。
Extract:控制提取过程和提取结果。 Eigenvalues over中默认值为1,即提取特 征值(根)大于1的因子(小于1,说明该 因子解释力度还不如直接引入一个原变量 的平均解释力度大);利用number of factors可指定提取因子的数目。 Display:结果显示。Unrotated factor sol种方法:主成分法与公共因子法(数学原 理完全不同,具体的差异可见郭P101102)。早期人们使用主成分法,它对变 量的分布没有要求。后期发展出因子法, 更灵活有效。 Extraction因子提取对话框 Method中的principal components即为主成 分法,为系统默认; 如果数据良好,则各个方法提取因子的结果 相同;若样本数超过1500,极大似然法会 更精确;若数据不好,后两种方法更适用; 如果条件不明,仍用主成分法。
• 重要概念: 因子负荷是一个矩阵,表示公因子与基 础变量间的相关系数。负荷大,表示 该公因子与某基础变量间存在较大关 系。观察负荷矩阵,可以看出公因子 在哪些变量上有较大负荷,可以据此 说明公因子的实际含义。若矩阵缺乏 规律,不能看出某个含义,还需要进 行因子旋转,(增加因子变量)以求得更好 的解释。
命令执行后输出: Communalities变量共同度表(公因子方差 比):表示各变量中所含信息被K个公因子 所表示的程度,取值0-1,值越大说明该变量 被因子说明的程度越高; Total variance explained总方差解释表:表示 提取因子在总方差中的贡献率,注意特征值 在1以上的各因子的累积贡献率。特征值大 于1的因子被默认为提取的公因子,但同时 还可以观察累积贡献率,一般最好高于80% 时为止。特征值与累积贡献率常综合考虑; Component Matrix因子负荷矩阵:即各因子 对各变量的影响度,根据此矩阵可初步判断 各基础变量与公因子的关系,并以此说明公 因子的性质,是公因子命名的根据。
3)数据样本量应达到一定水平 一般要求样本量至少是变量数的5倍以上, 最好达到10倍以上; 理论上要求样本量不应该少于100。样本量 越大越好。 4)社会学中多见李克特量表(五级)用于 因子分析,使用时应注意该量表应具有一 定的鉴别力(鉴别力不强的要删掉,即某一问题的回答基 本一致),否则因子分析效果不佳。
独立用,做单变量;做双变量)
因子分析独立使用时通过少量的因子可以更 清楚地把握诸多变量的本质,另外它常是 一种数据整理或准备。
具体作用: 1)有些变量实际观察不到,但又确实发挥影响, 如价值观、能力、爱好等,只能使用抽象的 因子来测量; 2)变量太多,需要简化; 3)多元回归(毛病:自变量的相关性不能太强)中常出现多 重共线性,需要去掉一些变量,但无法有充 分理由选择去除某个变量,故可将这些变量 合并成因子,使用因子代替原有变量进行回 归分析,即无多重共线性。如将收入和受教 育程度合并为社会经济地位(SES)一个变量; 4)评价问卷的结构效度;
三、SPSS因子分析操作与结果解释 analyze——data reduction——factor 1、选择并描述基础变量,并对基础变量进 行检验判断: Descriptives 对话框 Univariate descriptives:单变量描述统计 量,输出各基础变量的均值和标准差; coefficients:输出基础变量间的相关系数 矩阵,注意各值是否大于0.3; KMO and Bartlett’s test of sphericity:输 出检验显著度及KMO值。
例,结构效度 情绪及情绪应对量表: 1=完全没有 2=很少有 3=有时有 4=经常有 5=每 天都有 1 我感到愉快 2 我感到郁闷 3 我情绪不好时会想办法让自己高兴起来 4 我感到自己不知怎么做才好 5 我感到有压力 6 我想哭就哭,我哭出来感觉好多了 7 我感到没人能帮助我
8 我感到精力旺盛 9 我感到轻松 10 我会把烦心的事情放在心里 11 我遇到不高兴的事总是难以忘掉 12 我把烦心事说给别人听,之后感觉好多了 13 我感到紧张 14 我感到疲乏 积极情绪:1、8、9 消极情绪:2、4、5、7、13、14 外向应对:3、6、12 内向应对:10、11
第五章 因子分析
Factor Analysis
一、因子分析的作用 最重要的作用:减少变量,缩减数据。 通过研究多个变量间的内部关系,探寻变量 中的基本结构,并用少数几个假想变量来 表示基本的数据结构。 这些假想变量即是因子factors,它们能够反 映原来多个基础变量所表示的主要信息。 因子出现后,即可代表原来的多个基础变 量使用,以达到减少变量数的目的。(意义: