编译原理第二章-课后题答案
编译原理课后习题答案-清华大学-第二版

《编译原理》课后习题答案第一章
是哪种方式,其加工结果都是源程序的执行结果。目前很多解释程序采取上述两种方式的综 合实现方案,即先把源程序翻译成较容易解释执行的某种中间代码程序,然后集中解释执行 中间代码程序,最后得到运行结果。
广义上讲,编译程序和解释程序都属于翻译程序,但它们的翻译方式不同,解释程序是 边翻译(解释)边执行,不产生目标代码,输出源程序的运行结果。而编译程序只负责把源 程序翻译成目标程序,输出与源程序等价的目标程序,而目标程序的执行任务由操作系统来 完成,即只翻译不执行。
好似滚雪球一样,直到我们所要求的编译程序。 (4)移植:将 A 机器上的某高级语言的编译程序搬到 B 机器上运行。
《编译原理》课后习题答案第一章
第6题
计算机执行用高级语言编写的程序有哪些途径?它们之间的主要区别是什么?
答案: 计算机执行用高级语言编写的程序主要途径有两种,即解释与编译。 像 Basic 之类的语言,属于解释型的高级语言。它们的特点是计算机并不事先对高级语
第4题
对下列错误信息,请指出可能是编译的哪个阶段(词法分析、语法分析、语义分析、 代码生成)报告的。 (1) else 没有匹配的 if (2) 数组下标越界 (3) 使用的函数没有定义 (4) 在数中出现非数字字符
答案: (1) 语法分析 (2) 语义分析 (3) 语法分析 (4) 词法分析
第5题
b∶=10; end (q); procedure s; var c,d; procedure r;
var e,f; begin (r)
call q; end (r); begin (s) call r; end (s); begin (p) call s;
end (p); begin (main)
编译原理第二章习题解答

部分习题解答
© 西安电子科技大学 ·软件学院
难点
第2章习题
1. 根据模式,写出正规式 2. 依据 NFA/DFA,写出正规式
计算量大
3. 正规式NFA 4. NFADFA: ε_闭包,smove 5. DFA最小化
© 西安电子科技大学 ·软件学院
2
1. 根据模式写出正规式
一般思路:(1)分析题意 (2)列举一些最简单的例子 (3)寻找统一规律*,考虑所有可能情况**
© 西安电子科技大学 ·软件学院
13
其它
习题2.9 构造 10*1 的最小DFA
解: 活用 Thompson 算法
(1) 分解为三部分:1,0*,1;
(2) 画出三者的状态转换图:
1
0
1
0 2
1
3
4
(3) 连接运算:子图首尾相连
1
0 1
0
11
4
这已经是最小的DFA
© 西安电子科技大学 ·软件学院
14
11
其它
关于:正规式 -> NFA -> DFA -> DFA最小化: 说明:(一般)逐步计算 正规式->NFA: (1)呆板Thompson算法:
自上而下分解正规式—— 语法树, 自下而上构造NFA —— 后续遍历; 特点:每个运算对应一次构造,繁琐! (2)活用Thompson算法: 分解正规式:得到若干规模适中的子正规式; 为每个子正规式:画出其最简的状态转换图(子图); 按Thompson算法,将子图组合,得到完整的图。
长度为4:0011, 1100,
? 0101, 0110, 1001, 1010
b) 前4个串: 由00和11组成的串 正规式B*, B= 00 | 11
(完整word版)编译原理课后答案

第二章 高级语言及其语法描述4.令+、*和↑代表加,乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值:(1) 优先顺序(从高至低)为+,*和↑,同级优先采用左结合。
(2) 优先顺序为↑,+,*,同级优先采用右结合。
解:(1)1+1*2↑2*1↑2=2*2↑1*1↑2=4↑1↑2=4↑2=16 (2)1+1*2↑2*1↑2=1+1*2*1=2*2*1=2*2=46.令文法G6为 N →D|NDD →0|1|2|3|4|5|6|7|8|9 (1) G6 的语言L (G6)是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
解:(1)L (G6)={a|a ∈∑+,∑=﹛0,1,2,3,4,5,6,7,8,9}}(2)N =>ND => NDD => NDDD => DDDD => 0DDD => 01DD => 012D => 0127 N => ND => N7=> ND7=> N27=> ND27=> N127=> D127=> 0127 N => ND => DD => 3D => 34 N => ND => N4=> D4 =>34N => ND => NDD => DDD => 5DD => 56D => 568 N => ND => N8=> ND8=> N68=> D68=> 5687.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
解:A →SN, S →+|-|∑, N →D|MDD →1|3|5|7|9, M →MB|1|2|3|4|5|6|7|8|9 B →0|1|2|3|4|5|6|7|8|9 8. 文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiEEFT+T F FTiii*i+i+ii-i-ii+i*i*****************/9.证明下面的文法是二义的:S → iSeS|iS|I解:因为iiiiei 有两种最左推导,所以此文法是二义的。
编译原理教程课后习题答案第二章
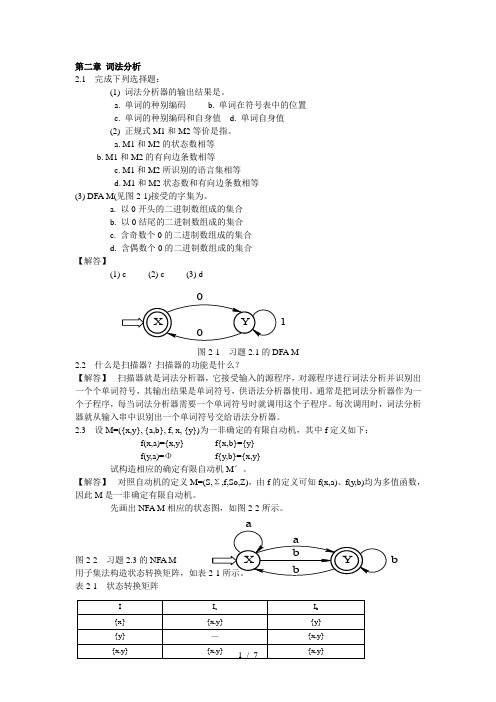
第二章 词法分析2.1 完成下列选择题:(1) 词法分析器的输出结果是。
a. 单词的种别编码b. 单词在符号表中的位置c. 单词的种别编码和自身值d. 单词自身值(2) 正规式M1和M2等价是指。
a. M1和M2的状态数相等b. M1和M2的有向边条数相等c. M1和M2所识别的语言集相等d. M1和M2状态数和有向边条数相等(3) DFA M(见图2-1)接受的字集为。
a. 以0开头的二进制数组成的集合b. 以0结尾的二进制数组成的集合c. 含奇数个0的二进制数组成的集合d. 含偶数个0的二进制数组成的集合【解答】(1) c (2) c (3) d图2-1 习题2.1的DFA M2.2 什么是扫描器?扫描器的功能是什么?【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。
通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。
每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。
2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下:f(x,a)={x,y} f {x,b}={y}f(y,a)=Φ f{y,b}={x,y}试构造相应的确定有限自动机M ′。
【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。
先画出NFA M 相应的状态图,如图2-2所示。
图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表表2-1 状态转换矩阵1b将转换矩阵中的所有子集重新命名,形成表2-2所示的状态转换矩阵,即得到 M ′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图2-3所示。
表2-2 状态转换矩阵将图2-3所示的DFA M ′最小化。
《编译原理》课后习题答案第二章

有代表性的符号串:a,a0,aa,a00,a0a,aa0
习题2
3.(1)E T T/F F/F (E)/F (E+T)/F (T+T)/F (F+F)/F (i+i)/i
(2)E E+T E+T+T E+T*F+F E+T*F+i E+T*T*F+i
M:M(0,a)=1 M(0,b)=2
M(1,a)=1 M(1,b)=4
M(2,a)=1 M(2,b)=3
M(3,a)=3 M(3,b)=2
M(4,a)=0 M(4,b)=5
M(5,a)=5 M(5,b)=1
化简:
1.分化
① {0,1} {2,3,4,5}
② {0,1} {2,4} {3,5}
2.合并
=M(M(D,1),1011)
=M(M(C,1),011)
=M(M(F,0),11)
=M(M(E,1),1)
=M(C,1)
=F
∴DFA D能接受字符串0011011
8.解:将状态转换图列表,即:
由左图可知,该状态转换图直接对应的是确定有穷状态自动机DFA
DFA D=({0,1,2,3,4,5},{a,b},M,0,{0,1})
A::=bc|bAc
(2)Z::=AB
A::=ab|aAb
B::=b|Bb
7. 解:题中要求文法是:
Z::=1|3|5|7|9|Z1|Z3|Z5|Z7|Z9|A1|A3|A5|A7|A9
A::=2|4|6|8|A0|A2|A4|A6|A8|Z0|Z2|Z4|Z6|Z8
编译原理习题解答(第2-3章)_吴蓉

P41 27. 给 出 一 个 产 生 下 列 语 言 L ( G ) = {W|W∈{a,b}*且W中含a的个数是b个数两倍的前 后文无关文法。 解:文法G=({S, A, B}, {a, b}, P, S) P: S::=AAB|ABA|BAA|ε A::=aS B::=bS 或者 S::=Saab|aSab|aaSb|aabS|Saba|aSba|abSa|abaS|Sbaa |bSaa|baSa|baaS|ε 或者 S::=aaB|aBa|Baa|ε B:? 先构造其转换系统:
0 0 ε Z’ Z 1 A 0 S ε S’
根据其转换系统可得状态转换集、状态子集转换矩阵如下表 所示:(其中S’可以忽略,结果是一样的) I I0 I1 S 0 2 2 1 Ф 1
{S’, S}
{A} {A, Z, Z’}
{A}
{A, Z, Z’} {A, Z, Z’}
P41 29. 用扩充的BNF表示以下文法规则: (1) Z::=AB|AC|A (2) A::=BC|BCD|AXZ|AXY (3) S::=aABb|ab (4) A::=Aab|ε 解: (1) Z::=A(B|C|ε)::=A[B|C] (2) A::=BC ( ε|D ) |{X ( Z|Y ) }::= BC[D]|{X ( Z|Y )} (3) A::=a((AB|ε)b) ::= a[AB]b (4) A::={ab|ε}::={ab}
DFA=({S,A,Z},{0,1},M,S,{Z}) 其中M: M(S,0)=Z M(S,1)= A M(A,0)=Z M(Z,0)=Z M(Z,1)=A
该语言的正规文法G[Z]为: 右线性文法://S :: =0|1A|0Z 左线性文法: A :: =0|0Z A :: =1|Z1 Z :: =0|1A|0Z Z :: =0|A0|Z0 若终止状态只引入不引出则适合构造右线性文法 ,若开始状态只引出不引入则适合构造左线性文 法,若终态和初态均既有引入又有引出,则构造 文法要注意。
编译原理第二章习题答案

第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}2.文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D……D3.已知文法G[S]:Sf dAB Af aA|a B|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法? [答案]正规式是daa*b* ;相应的正规文法为(由自动机化简来):G[S]:S —dA A —a|aB B —aB|a|b|bC C —bC|b也可为(观察得来):G[S]:S —dA A —a|aA|aB B —bB| &4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}5.给出语言{a n b n c1 n>=1,m>=0}的上下文无关文法。
[分析]本题难度不大,主要是考上下文无关文法的基本概念。
上下文无关文法的基本定义是:A-> B ,A € Vn ,B€( VnU Vt) *,注意关键问题是保证a n b n的成立,即“ a与b的个数要相等”,为此,可以用一条形如A->aAb|ab的产生式即可解决。
[答案]构造上下文无关文法如下:S->AB|AA->aAb|abB->Bc|c[扩展]凡是诸如此类的题都应按此思路进行,本题可做为一个基本代表。
基本思路是这样的:要求符合a n b n c m,因为a与b要求个数相等,所以把它们应看作一个整体单元进行,而c m做为另一个单位,初步产生式就应写为S->AB,其中A推出a n b n,B推出c m。
编译原理第二章-课后题答案

第二章3.何谓“标志符”,何谓“名字”,两者的区别是什么答:标志符是一个没有意义的字符序列,而名字却有明确的意义和属性。
4.令+、*和↑代表加、乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值。
(1)优先顺序(从高到低)为+、*和↑,同级优先采用左结合。
(2)优先顺序为↑、+、*,同级优先采用右结合。
答:(1)1+1*2↑2*1↑2=2*2↑2*1↑2=4↑2*1↑2=4↑2↑2=16↑2=256(2)1+1*2↑2*1↑2=1+1*2↑2*1=1+1*4*1=2*4*1=2*4=86.令文法G6为N-〉D|NDD-〉0|1|2|3|4|5|6|7|8|9(1)G6的语言L(G6)是什么(2)给出句子0127、34、568的最左推导和最右推导。
答:(1)由0到9的数字所组成的长度至少为1的字符串。
即:L(G6)={d n|n≧1,d∈{0,1,…,9}}(2)0127的最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 0127的最右推导:N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127(其他略)7.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
答:G(S):S->+N|-NN->ABC|CC->1|3|5|7|9A->C|2|4|6|8B->BB|0|A|ε[注]:可以有其他答案。
[常见的错误]:N->2N+1原因在于没有理解形式语言的表示法,而使用了数学表达式。
8.令文法为E->T|E+T|E-TT->F|T*F|T/FF->(E)|i(1)给出i+i*i、i*(i+i)的最左推导和最右推导。
(2)给出i+i+i、i+i*i和i-i-i的语法树,并给出短语,简单短语和句柄。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第二章
3.何谓“标志符”,何谓“名字”,两者的区别是什么?
答:标志符是一个没有意义的字符序列,而名字却有明确的意义和属性。
4.令+、*和↑代表加、乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值。
(1)优先顺序(从高到低)为+、*和↑,同级优先采用左结合。
(2)优先顺序为↑、+、*,同级优先采用右结合。
答:(1)1+1*2↑2*1↑2=2*2↑2*1↑2=4↑2*1↑2=4↑2↑2=16↑2=256
(2)1+1*2↑2*1↑2=1+1*2↑2*1=1+1*4*1=2*4*1=2*4=8
6.令文法G6为
N-〉D|ND
D-〉0|1|2|3|4|5|6|7|8|9
(1)G6的语言L(G6)是什么?
(2)给出句子0127、34、568的最左推导和最右推导。
(1)由0到9的数字所组成的长度至少为1的字符串。
即:L(G6)={d n|n≧1,d∈{0,1,…,9}} 答:
(2)0127的最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 0127的最右推导:N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127
(其他略)
7.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
答:G(S):S->+N|-N
N->ABC|C
C->1|3|5|7|9
A->C|2|4|6|8
B->BB|0|A|ε
[注]:可以有其他答案。
[常见的错误]:N->2N+1
原因在于没有理解形式语言的表示法,而使用了数学表达式。
8.令文法为
E->T|E+T|E-T
T->F|T*F|T/F
F->(E)|i
(1)给出i+i*i、i*(i+i)的最左推导和最右推导。
(2)给出i+i+i、i+i*i和i-i-i的语法树,并给出短语,简单短语和句柄。
答:(1) i*(i+i)的最左推导:
E=>T=>T*F=>F*F=>i*F=>i*(E)=>i*(E+T)=>i*(T+T)=>i*(F+T)=>i*(i+T)=>i*(i+F)=>
i*(i+i)
i*(i+i)的最右推导:
E=>T=>T*F=>T*(E) =>T*(E+T)=>T*(E+F)=>T*(E+i)=>T*(T+i)=>T*(F+i)=> T*(i+i)=> F*(i+i) => i*(i+i)
(其他略)
[注]:要牢记每一步都是对最左(右)的一个非终结符号进行一步推导。
(2) i+i+i的语法树:
(其他略)
9.证明下面的文法是二义的:S->iSeS|iS|i
证明:反例法:
对于该文法的句子iiiei 有两个最右推导如下,所以该文法是二义的: S=>iS=>iiSeS=>iiSei=>iiiei
S=>iSeS=>iSei=>iiSei=>iiiei
10.把下面的文法改写成无二义的:S->SS|(S)|()
答:假设规定左结合的顺序,可以改造成无二义文法如下:
s->s(t)|(s)|()
t->s|ε
[注]:大纲不要求掌握,作为参考
11.给出下面语言的相应文法:
L 1={a n b n c i |n ≧1,i ≧0}
L 2={a i b n c n |n ≧1,i ≧0}
L 3={a n b n a m b m |m,n ≧0}
L 4={1n 0m 1m 0n |m,n ≧0}
答:(1) S->AB A->aAb|ab B->Bc|ε
(2) S->AB B->bBc|bc A->Aa|ε
(3) S->AA A-> aAb|ε
(4) S->1S0|A A-> 0A1|ε
[注]:可以有其他答案。
E E
+ T E
+ T T F i 1 F i 2 F i 3 短语:i 1, i 2, i 3, i 1+ i 2, i 1+i 2+ i 3 简单短语:i 1, i 2, i 3 句柄:i 1。