常用统计量分布表
统计量及其分布

样本均值的抽样分布 (例题分析)
【例】设一个总体含有4 个个体,分别为X1=1、X2=2、 X3=3 、X4=4 。总体的均值、方差及分布如下。
总体均值和方差
总体的频数分布
X
i 1
N
i
N
N
2.5
2
2 ( X ) i i 1
0.02 0 2 1 0.1
21 Φ0.2
0.8414
(4) 样本 k 阶(原点)矩
1 n k Ak X i , k 1, 2, ; n i 1
1 n k 其观察值 k x i , k 1, 2, . n i 1
n n 1 2 1 2 2 E( S ) E X i nX (Xi X ) E n 1 i 1 n 1 i 1
2
1 n 2 2 E ( X i ) nE ( X ) n 1 i 1 2 1 n 2 2 2 ( ) n 2 n 1 i 1 n
n
k 1
n
2
2
n
,
定理 设总体X的期望E(X) = ,方差D(X) = 2,X1, X2,…,Xn为总体X的样本, X,S2分别为样本均值 和样本方差,则
E( X ) E( X )
D( X ) 2 D( X ) n n
E( S 2 ) D( X ) 2
思考:在分组样本场合,样本均值如何计算? 二者结果相同吗?
x1 f1 x n f n 其中 x n
常用统计量与计算方法

代入公式(3—5)得:
Md
L
i
n
15 68
( c) 57 ( 16) 70.5
(天)
f2
20 2
即间隔时间的中位数为70.5天。
L — 频数最多所在组的下限
i — 组距 (即全距/组数)
f — 频数最多所在组的频数
n — 总频数(即总次数)
c — 小于频数最多所在组的累加频数
19
(三)众数 (mode) M0 (书 P17)
26
为 了 准 确 地 表示样本内各个观测值的变异 程度 ,人们 首 先会考虑到以平均数为标准,求 出各个观测值与平均数的离差,(x x) ,称为 离均差。
虽然离均差能表示一个观测值偏离平均数的 性质和程度,但因为离均差有正、有负 ,离均 差之和 为零,即Σx( x ) = 0 ,因 而 不 能 用离均差之和Σ(x x )来 表 示 资料中所有观 测值的总偏离程度。
注: 小样本的自由度为n-1
x x 2
n 1
n 30
35
标准差的计算方法
上述计算方法需先求出平均数(一般为约数),容易 引起计算误差,因此采用原始数据进行计算 (书P20)
大样本: S x 2 x 2 / n
n
小样本: S x 2 x 2 / n
n -1
为简化计算过程,若试验观测数值较大(小)时,可将各观测值
乙组的变异明显低于甲组, R 不能反映 组内其它数据的 变异度 25
二、变异数
缺点
c. 样本较大时, 抽到较大值与较小值的可能性也较大, 因而样本极差也较大,故样本含量相差较大时,不宜用 极差来比较分布的离散度。
当资料很多,而又要迅速对资料的变异程度作出判断 用途 时,有时可先利用极差判断。
第五章-正态分布、常用统计分布和极限定理

的面积, 然后根据1 0.125 0.875查附表4, 对应
Z 1.15,那么录取分数线
x X Z X 74 1.1511 86.65(分)
表5-2
例11:
0Z 图5-11
(1)求Z 1分数以上的概率是多少 ?
解:Z 1时, (Z) 0.34134, Z以上的概率为
(Z) Z
1
t2
e 2 dt
2
(Z 2 ) 图5-8 Z 2
(Z2 Z1)
图5-9Z1 Z 2
例4:已知服从标准正态分布 N(0,1), 求P( 1.3) ? 解:因为() 1,() P( 1.3) P( 1.3) 所以( 1.3) 1 P( 1.3) 1 (1.3) 1 - 0.9032 0.0968
2
如果把u 0, 1代入(x)
1
e
(
xu)2
2 2
2
(x)
1
x2
e2
2
标准正态分布其实是一般正态分布的一个特 例,记作N(0,1),一般正态分布记作N(μ,σ2)。
一般正态分布之所以能变成唯一的标准正态 分布,就是把原来坐标中的零点沿着X轴迁到μ点, 并且以σ为单位记分。
σ=1
0
图5-5
13.6%
13.6%
2.16% 0.11%
3 2 1 图05-6 1
2.16% 0.11%
23
三、标准分的实际意义
例1:甲、乙、丙3个同学《社会统计学》分数 都是80分,甲同学所在班平均成绩μ甲=80分, μ 乙=75分, μ丙=70分,标准差都是10,比较甲、乙、 丙3个同学在班上的成绩。
SPSS统计分析汇总一览表
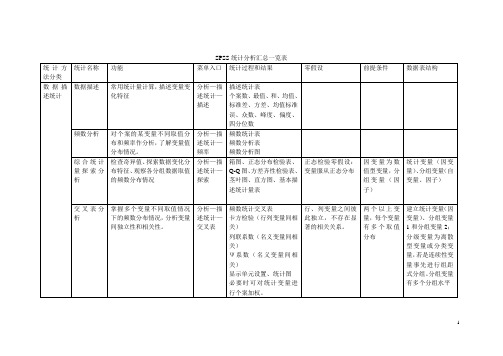
频数统计表
频数分析表
频数分析图
综合统计量探索分析
检查奇异值、探索数据变化分布特征、观察各分组数据取值的频数分布情况
分析—描述统计—探索
箱图、正态分布检验表、Q-Q图、方差齐性检验表、茎叶图、直方图、基本描述统计量表
正态检验零假设:变量服从正态分布
因变量为数值型变量,分组变量(因子)
连续型数值变量作因变量
单样本T检验
检验某个变量的总体均值与某指定值之间是否存在显著差异
分析—比较均值—单样本T检验
单样本统计表
单样本检验表
总体均值的指点定检验值之间不存在显著差异。
样本总体服从正态分布
建立考察指标变量和分组变量
两独立样本T检验
了解两个样本之间是否有显著差异
分析—比较均值—独立样本T检验
两个以上变量,每个变量有多个取值分布
建立统计变量(因变量)、分组变量1和分组变量2;分级变量为离散型变量或分类变量,若是连续性变量事先进行组距式分组。分组变量有多个分组水平
均值比较及参数检验
均值比较过程
按用户指定条件对样本进行分组计算均值和标准差。也可进行方差分析
分析—比较均值—均值
统计量报告表
方差分析表
分析—比较均值—配对样本T检验
分析变量的简单描述统计表
分析变量的相关系数表
两配对样本检验表
两个样本在某变量上不存在显著的线性相关。
两个总体均值间不存在显著差异。
两个样本观察数目相同且观察值顺序不能随意改变;样本来自的两个总体服从正态分布。
按不同总体(组别)建立两个变量,将观察量数据按其顺序对应放在相应的变量名下。
单因素方差分析
用于测试某一个控制变量的不同水平是否给指标变量造成了显著差异和变动。即检验不同水平下各总体均值是否有显著差异(考察不同水平的K个总体是否具有相同的正态分布)。用于两个以上样本均值的差别检测。
spss教程-常用的数据描述统计:频数分布表等--统计学

第二节常用的数据描述统计本节拟讲述如何通过SPSS菜单或命令获得常用的统计量、频数分布表等。
1.数据这部分所用数据为第一章例1中学生成绩的数据,这里我们加入描述学生性别的变量“sex”和班级的变量“class”,前几个数据显示如下(图2-2),将数据保存到名为“2—6—1.sav”的文件中。
图2-2:数据输入格式示例1.Frequencies语句(1)操作打开数据文件“2—6—1。
sav",单击主菜单Analyze /Descriptive Statistics / F requencies…,出现频数分布表对话框如图2-3所示。
图2-3:Frequencies定义窗口把score变量从左边变量表列中选到右边,并请注意选中下方的Display frequency table复选框(要求显示频数分布表)。
如果您只要求得到一个频数分布表,那么就可以点OK按钮了。
如果您想同时获得一些统计量,及统计图表,还需要进一步设置。
①Statistics选项单击Statistics按钮,打开对话框,请按图2—4自行设置。
有关说明如下:(ⅰ)在定义百分位值(percentile value)的矩形框中,选择想要输出的各种分位数,SPSS提供的选项有:●Quartiles四分位数,即显示25%、50%、75%的百分位数。
●Cut points equal 把数据平均分为几份。
如本例中要求平均分为3份.●Percentile显示用户指定的百分位数,可重复多次操作。
本例中要求15%、50%、85%的百分位数。
(ⅱ)在定义输出集中趋势(Central Tendency)的矩形框中,选择想要输出的集中统计量,常用的选项有: ●Mean 算术平均数●Median 中数●Mode 众数●Sum 算术和(ⅲ)在定义输出离散统计量(Dispersion)的矩形框中,选择想要输出的离散统计量,常用的选项有:●Std。
Deviation 标准差●Variance 方差●Range 全距●Minimum 最小值●Maximum 最大值●S。
顺序统计量

−1 ! − !
−1
1−
−
()
证明: 对任意的实数 x ,考虑次序统计量 x(k) 取值
落在小区间 (x , x + x ] 内这一事件,它等价于
“样本容量为 n 的样本中有 1 个观测值落在区间
(x , x + x ] 之间,而有 k-1 个观测值小于等于 x ,
100
•T1 X i 是不合格品率p的充分统计量
i 1
1 n
( X i )2
•来自正态总体的样本,若总体期望已知,
n i 1
1 n
是总体方差的充分统计量,若总体方差已知,n X i
i 1
•是总体期望的充分统计量。
3、分位数
设(1) ≤ (1) ≤ ⋯ ≤ () 为取自总体 X 的
次序统计量,称 Mp为p分位数。
+1 ,
= ൞1
+
2
若不是整数
+1
,
若是整数
4、四分位数:
① 排序后处于25%和75%位置上的值
25%
25%
QL
25%
QM
② 不受极端值的影响
③ 计算公式
布,
X
0
1
2
设总体 X 的分布如下:
p
1/3 1/3 1/3
现抽取容量为 3 的样本, 共有 27 种可能取值, 列表如下
x1
x2 x3 x(1) x(2) x(3) x1 x2 x3 x(1) x(2) x(3) x1 x2 x3 x(1) x(2) x(3)
0
0
0
0
0
0
1
1
0
统计学中常见分布的应用

1引言
在数理统计中,常见的分布包括指数分布,普哇松分布,正态分布, 分布, 分布, 分布.这些常见分布的参数的区间估计和假设检验问题是在日常生产生活中我们常用到的问题,在大部分的文献资料中对正态分布的这一问题讨论较多,本文将就其它五个常见分布的参数的区间估计和假设检验问题进行详细的介绍.其中包括这五种分布的密度函数、性质及其在数理统计中的应用.
那么
~ ,
所以假设拒绝域:对于给定的 和 ,由
,
是自由度为 的 分布之 水平双侧分位数,假设 之 水平的拒绝域是
,
接受域是
.
例某种中药饮片中成分 的含量规定为 ,现在抽验了该药物一批成品中的五个片剂,测得其中成分 的含量分别为: 假设该药物中成分 的含量 服从正态分布,问在 的显著性水平下,抽验结果是否与片剂中成分 的含量为 要求相符?
其中 为常数,这种分布叫作指数分布.显然,我们有
指数分布含有一个参数 ,通常把这分种分布记作 .如果随机变量 服从指数分布 ,则记为 ~ ,因为
(连续随机变量的分布函数 等于概率密度 在区间 上的反常积分)由此可得指数分布 的分布函数为
=
2.5 普哇松分布
定义5[3](P64)称随机变量 服从普哇松分布,如果
2五中常见分布的定义及其相关性质
2.1 分布
定义1[1](P225)称随机变量 服从 分布,自由度为 ,如果它有密度函数
性质假设 独立同标准正态分布,则随机变量
服从 分布,自由度等于 .
2.2 分布
定义2[1](P228)称随机变量 服从 分布,自由度为 ,如果它有密度函数
.
性质假设 服从标准正态分布, 服从 分布,自由度为 ,而且 和 相互独立,那么随机变量 ,服从 分布,自由度为 .
第3节 常用统计分布(三个常用分布)

例2
设X
~
N
(
,
2
),
Y
2
~
2 (n),且X ,Y相互独立,
试求 T X 的概率分布.
Yn
解 因为X ~ N(, 2),所以 X ~ N(0,1)
又Y
2
~
2 (n),且X ,Y独立,则
X
与Y
2
独立,
由定理得
T (X ) / X ~ t(n) (Y / 2) / n Y n
n
事实上,它们受到一个条件的约束:
Xi nX
i 1
n
i 1
Xi
X
1
n
(
i 1
Xi
nX )
1
0
0.
例1
设X1 ,
X 2 ,
,
X
为
6
来
自
正
态
总
体N
(0,1)的
一
组
样
本,
求C1
,
C
使
2
得
Y C1( X1 X 2 )2 C2( X 3 X4 X5 X6 )2
服 从 2分 布.
解
X1
2
4
则C1 1 2 ,C2 1 4 .
3. t 分布 定义 设 X ~ N (0, 1), Y ~ 2 (n), 且 X , Y
独立,则称随机变量 T X 服从自由度为 n Y /n
的 t 分布, 记为T ~ t(n).
t 分布又称学生氏(Student)分布. t(n) 分布的概率密度函数为
2. 2分布(卡方分布)
定义、设 X1, X 2 ,L , X n 相互独立,同服从 N (0, 1)