社会统计学公式总结
统计学 相关系数 判定系数

统计学相关系数判定系数1. 引言统计学是现代社会中广泛应用的一门学科,通过对数据的收集、整理和分析来推断出背后的规律和关系。
其中,相关系数和判定系数是两个非常重要的概念,它们可以帮助我们评估两个变量之间的相关性和预测模型的可靠性。
本文将重点讲述这两个概念的定义、计算方法及其应用。
2. 相关系数相关系数是指用于评价两个变量之间线性相关程度的统计量。
通常用r来表示,其取值范围在-1到1之间。
当r为1时,表示两个变量完全正相关;当r为-1时,表示两个变量完全负相关;当r为0时,表示两个变量之间没有线性相关性。
相关系数的计算公式为:其中,x和y分别代表两个变量的观测值,x̄和ȳ分别是它们的平均值,sx和sy分别是它们的标准差,n是样本容量。
3. 判定系数判定系数是一种用于衡量回归模型拟合程度的指标,通常用r2来表示。
它表示在已知因变量的情况下,由自变量所建立的回归模型能够解释的因变量变化部分所占的比例。
其取值范围在0到1之间,值越接近1,模型的拟合程度越好。
判定系数的计算公式为:其中,SSE是残差平方和,SST是总平方和,而SST=SSE+SSR,其中SSR是回归平方和。
4. 相关系数和判定系数的应用相关系数和判定系数常常在金融、经济、工业、医学等领域得到广泛应用。
其中,相关系数可以帮助我们评估两个变量之间的相关性,例如:评价商品A的销售量和价格之间的关系;研究身高和体重之间的关系等。
而判定系数则可以衡量回归模型的拟合程度,例如:对于经济学家而言,他们可以使用判定系数来衡量GDP与各经济指标的关系,以及它们之间的预测和解释能力。
同样,医学研究者可以使用判定系数来确定疾病与各种治疗方法之间的关系。
5. 结论总之,相关系数和判定系数是统计学中非常重要的两个指标,它们在广泛应用领域有着重要的作用。
社会统计学(卢淑华)-第三章

B=该家庭有电视机 P(A)=0.60 P(B)=0.80 P(AB)=0.60*0.80=0.48
例题2
对同一目标进行3次射击,第一、二、三、 次射击命中的概率分别是:0.3,0.4,0.6,求 在这三次射击中恰有一次命中的概率。
答案
Ai=第i次射击命中 A=恰有一次命中 P(A)
x2
Px1 x2 x dx x1
概率密度 x 存在以下性质:
1)x 0
2)
xdx 1
3、分布函数
1)定义:F(x)=P( x) 意义:随机变量从最远的起点(- )到所研究的x点所有概率的总和。
2)对于离散型随机变量,则:依据概率的加法定理:例
F x P x P xi
1、离散型随机变量
方差:D E E 2 x E 2 Pi
ii
2、连续型随机变量
方差:D
x
E
2
xdx
标准差 : D
3、方差和标准差都反映了随机变量的可能值密集在数学 期望周围的程度。方差值越小,密集程度越高;反之则方
差值较大。
4、计算过程
① 利用公式求 E()=
② 求[ E()]2
例2:两名孕妇,生女婴的概率分布。
性质:1) Pk 0
2) PK 1 K 1
分布列表明全部概率在各可能取值之间的分布规律,全面描叙离散随机变量
的统计规律
2、连续型随机变量及其概率分布 ——概率密度函数
概率密度
:
x
P
lim
x 0
x
x 2
x
x
x
2
任意两点(X1,X2)之间的概率为:
三种情况:
1、不可能事件Ø 概率 P()=0 2、必然事件S 概率 P(S)=1 3、必然与不可能之间E 概率 0 P(E) 1
社会统计学公式总结及要点

3.一个变项,1个样本 :
①(n≥100):
②(n≤30): , df=b-1
4.1个变项,2个样本 1 2
n=n1+n2>100 →
五、归类总结之五:有关消减误差比例
1.
有消减误差比例意义,且对称
、G、Q拉系数、rs2、r2、rxy.12、、Ry.122= Ry.x1x22
2.有无自由度的表达
G、r、F、x2结果解释加上“其显著度水平达到或没有达到……水平”
3.有关r净相关系数
(两个定距变项)
r=rxy.1——引入第三个变项时对X、Y变项产生共同影响。
rx(y-1)——引入第三个变项时,只对Y产生影响,无消减误差意义。
ry(x-1)——引入第三个变项时,只对X产生影响,无消减误差意义。
Q= Q3- Q1
有单个数(n为偶数时会出现偏离)、区间之分。
(有几种Q,就有几种S计算法)
当为区间表格时(n/4)
①计算向上累加数cf;②Q1位置= ,Q3位置= ;
③Q1=L1+ W1,Q3= L3+ W3;④Q= Q3- Q1P57
5.标准差
①单个数:S= ,②区间:S= P60
对S的解释:如以均值来估计各个个案的数值,所犯的错误 平均是S。用均值作估计变项数值时所犯错误的大小。
社会统计学公式汇总及要点2011.09.09-09.10
(仅供参考,如不能显示公式,请安装Microsoft公式3.0)
一、归类总结之一
测量层次
特质
数学特质
单变项:X
定类变项
只分类
Mo、V
比例、比率、对比值、
电大 社会统计学 第六章 正态分布

maxLeabharlann 第一节 正态分布f(x)
二、正态分布的特点 (二)正态分布是对称的
0
µ
正态分布曲线位于横轴上方,呈钟形。中间大,两头小,左 右对称。 正态分布曲线以均数所在处最高,且以均数(x=μ)为中心 左右对称。 在正态分布中,平均数=中数=众数,此点对应y值最大。 X=μ ±σ为图像的拐点,在(μ-σ,μ+σ)内是凹的,其他范 围是秃的。 x轴是渐近线。
( x) 1 ( x).
P(x1<X<x2)=P(X<x2)-P(x1<X)=F(x2)-F(x1)
例题1
• 已知X~N(1.5,4),求P(X<-4)和P(|X|>2)。 • 解:因为X服从μ=1,5,σ=4的正态分布,故:
- 4 1.5 P( X -4 ) ( ) (-2.75 ) 1 (2.75 ) 0.003 2 P ( X 2 ) P ( X 2 ) P ( X 2 )
X
~N(0,1),
Z=(X—μ)/σ
• 某班同学平均体重为50公斤,标准差为10,某同学体重为70 公斤,将这个分数转化为Z值。 • Z=(X—μ)/σ=(70—50)/10= 2 • 表明这个同学的体重在分布中高于均值2个标准差。
68—95—99.7规则(重要)
• 约有68%的数据在平均数加减1个标准差的范围之内; • 约有95%的数据在平均数加减2个标准差的范围之内; • 约有99.7%的数据在平均数加减3个标准差的范围之内。 • 这就是68—95—99.7规则,由此可见,X的取值几乎全部落 在(μ—3σ,μ+3σ)之间,即在均值的3个标准差范围之 内。X值几乎不可能在区间
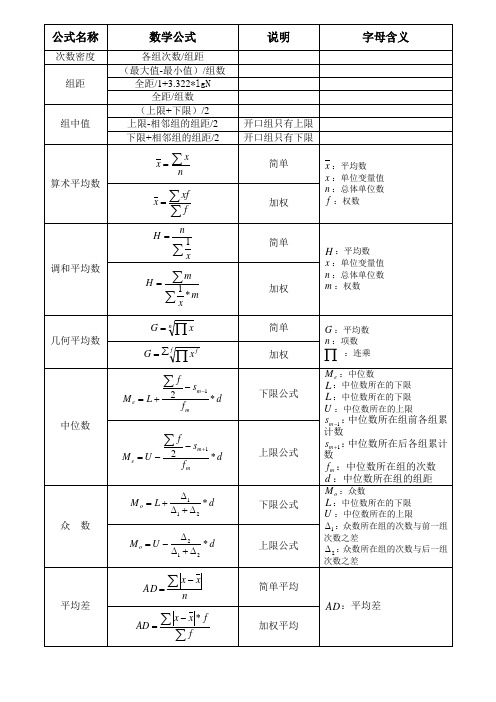
社会统计学常用公式及说明
b
b
i 1
n
i
n
yn y0
平均发展速度-1
回归方程
公式名称
数学公式
yt a bt (方程式)
说明
说明
当 t 0 时:
b
N tY t Y N t 2 ( t ) 2
Y b t N
直线回归
b
N tY t Y N t 2 ( t ) 2
H
调和平均数
H
x
1
简单
H :平均数
m 1 x *m
x x
f
加权
x :单位变量值 n :总体单位数 m :权数
Gn
简单 加权
G :平均数
几何平均数
f G
n :项数
:连乘
f
Me L 2
sm 1 fm
*d
下限公式
中位数
Me U
f
2
sm 1 fm
*d
上限公式
环比
Ai
增长速度
Bi
yi y0 (i 1,2,....n) y0
yi yi 1 (i 1,2,....n) yi 1
n
定基
环比
环比发展速度-1 1、等 于 各 环 比 发 展 速度连乘开 n 次方 根 2、等于 n 次方根下报 告期水平 / 基期水 平
平均发展 速度 平均增长 速度
a
a
Y
N
回归方程
a
yt a bt ct 2 (方程式)
t Y t t Y N t ( t )
4 2 2 4 2 2
b
社会统计学公式总结LIJUN

社会统计学考试必备公式
学院:人文学院
姓名:李军
学号:2011014737
专业:社会学
班级:社会111
时间:2013年6月20日
社会统计学考试必备公式
第二章单变量统计描述分析
直方图:频次密度=频次/组距(条宽)
相对频次密度(频率密度)=相对频次(频率)/组距(条宽)
频次=频率密度*组距
A、集中趋势测量法
众值:m0
B、离散趋势测量法
极值R:观察的最大值-观察的最小值
四分互差Q=Q75-Q25
第三章概率
一、概率的运算
1.当事件A与事件B互不相容时,
P(A+B)=P(A)+P(B)
2. 当事件A与事件B不满足互不相容时,
P(A+B)=P(A)+P(B)-P(AB)
3.A、B相互独立
P(AB)=P(A)P(B)
4. A、B不相互独立
P(AB)=P(A)P(B/A)或P(B)(A/B)
第五章正态分布
第六章参数估计
第七章假设检验的基本概念
1.统计假设
2.原假设与备择假设
3.假设检验的基本原理
4.双边检验与单边检验
第十四章非参数检验。
统计学原理有关公式记忆方法举隅

平均 差式算
资料 已 分组 , 用 加权 式计 算
A. l :二 鱼
.
: 迎
盯:
:
忆问题。
平均 指标 与变异 指标
1 .算术平均数 与调和平均数 算术 平均数 与调和平均 数是平均指标 的两种 表现形式 , 都是用来 反映被研究现 象总体某一数量 标志在一 定的时 间 、 地点 、条件下一般 水平的统计指标。正确理解和熟练掌握这 两个 公式 ,对本课 程后 面章节的学习及公式的记忆具有非常 重要的促 进作用 。将两类公式进行 比较可 以发现 以下异同 : ( )相 同点 都遵循基本计算公式 : I
把算术平 均数作 为学习基础 ,将这两类公式与算术平均 数公式进行对 比可发现有 以下异 同: ( ) 同点 对 未分组 资料都采用 简单公式计算 ,对分组 1相 资料都采用加权公式计算 。 ( )不 同点 算术平均数是 对总体 内各单位标 志值 求平 2 均 。平均差是 对总体内各单位标志值与其算术平均数离差的 绝对值求平均 ,方 差是 对总体内各单位标志值与其算术平均 数离差 的平方求平均 。 另外 , 在学习平均指标和变异指标这 部分 内容时, 还可根 据资料是否分组这两条主线将有关公式分别进行整理后记忆 。
教 研 探 索
统计学原理有关公式记忆方法举隅
] j
习
芮宝宣 _ l _ j
[ 要] 摘 统计学公式的记忆是学习统计学的难点之一 ,使用好的记忆方法,可以收到事半功倍的效果。本文针对有 关统计 公 式探 讨 有针 对性 的记忆 方 法。
[ 关键词】 统计 学 公 式 记 忆 目前 ,在我 国,统计学不仅是教育部 明文规定 的高 等院 校财经类专业核心课程之一 ,而且近年来在 国家公务员 考试 的综合能力测试中 ,也有约 2 %的内容涉及 到对统计基础知 0 识 的运用 。伴随着社会 的发展和科技进步 ,统计学理论 的运 用领域越来越广泛 。即使在我们 的 日常生 活中 ,生动的统计 信息也随处可见 :例如人 口出生率 、 亡率 、国内生产 总值 、 死 消费价格 指数 、高考 录取率 、房 价同 比增 长速度 、环 比增长 速度等统计指标 出现报端 的频率越来越 高。正确解读 这些信 息 ,并能利用 简单 的统计方法对社会 经济 现象数量变化的一 般规律进行分析 ,是时代对我们的客观要求。 统计学是通过研究客观现象 总体数量方 面和数 量关 系对 社会 经济 总体现象进行定量认识 的方 法论科 学。它不仅 内容 丰富 、系统性强 ,而且计算 多 ,公式 复杂 ,难 以记 忆 ,常使 些初学者望 而却 步 ,特别 是那些数 学基础较差的文科学生 更是如此 。笔 者根据 自己多年的教学 经验 ,对该课 程 中的有 关公式进行科学梳理 、总结 、归纳 ,并运用一 定的记忆技巧 , 总结 出一套记忆方 法 ,使学 习者在学 习时既节省时间 ,又可 使公式牢记不忘 ,减轻记忆公式的压力。 心 理学研究成 果表 明,记忆 是通过识 记 、保持 、回忆 、 再现等方式 , 在人 的头脑 中积 累和保持个体经验的心理过程 。 在记忆 活动中 ,识记 与保持 是回忆 与再现 的前 提 ,回忆与再 现是识记 与保 持的结果 。正确 的识记 与理解是记忆 的基础 , 而如何有效地保持则是记忆 的关键环 节。本文将从 如何正确 理解 和有效保持 的角度探讨 统计 学课 程中部分有关公式的记
电大社会统计学

一、基本概念1、众数众数是一组数据中出现频数最多的数值,用Mo表示。
例如,一个城市有多种产业,但如果以旅游业为最多,那么旅游业就是众数,这个城市也被称为旅游城市。
2、中位数中位数是中心趋势的一种测量,是将一组数据排序后,处于中间位置的变量值,用Me表示。
中位数处于中间位置,前后每部分均包括50%的数据,而且前面部分小于中位数、后面部分大于中位数。
例如,在职工收入水平差异比较大的单位,要了解职工收入的一般水平,用职工收入分布的中位数作为收入水平的代表值要比用算术平均数更恰当,因为它排除了极端数据的影响。
3、四分位数四分位数是将一组数据排序后,找出将该组数据等分为四等份的三个点,每份包括25%的数据,这三个点上的数据就是四分位数。
第二个四分位数就是中位数,它前面包括50%数据,后面也包括50%数据,因而,平时所说的四分位数主要是指第一个四分位数和第三个四分位数。
通常,我们将第一个四分位数称为下四分位数(QL),将第三个四分位数称为上四分位数(QU)。
4、均值均值是集中趋势最主要的测量值,它是将全部数据进行加总然后除以数据总个数,也称为算数平均数。
均值包含一组数据中所有数值,它是先将所有数值进行加总,然后进行平均,在均值中所有数值都有所体现。
因而,我们说均值是集中趋势最主要的测量值。
二、基本方法1、众数的计算(1)众数的计算比较简单,就是找出频数最大的即可。
例如“甲城居民对交通满意度调查”,调查者在甲城市随机抽取统计500人调查,调查结果发现,选择“非常不满意”的有50人,“不满意”的有98人,选择“一般”的有204人,选择“满意”的有110人,选择“非常满意”的有38人。
从调查结果可以看出,选择“一般”的居民最多,为204人,占总数的40.8%,因而众数为“一般”这一变量值,即Mo=“一般”。
对于数值型数据,计算众数时,最好先对数据进行排序,有利于计算各变量值频数,避免出错。
(2)对于分组数据,计算具体数值时,根据公式:对于任意一组数据,基本都存在频数最多的数值,这个数值可能有一个,也可能是两个,或者三个甚至更多,不管存在几个,它们均是该组数据的众数。