chp10数据库原理
Chp10
R1 uS
i1 L1
M
R2 L2
i2 RL
Z11 = R1 + jω L1 1 Y22 = R2 + RL + jω L2
由图( ), ),得 由图(a),得 一次侧等效电路如图( ) 解:一次侧等效电路如图(a)所示
I 1 Z11
US
& US I&= = 0.11∠ − 64.8o A 1 Z11 + (ω M ) 2 Y22
M 21 = M 12 = M
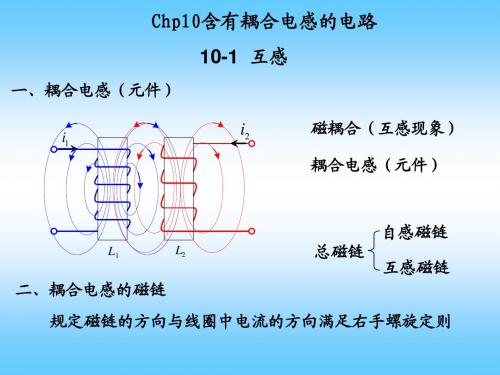
反向耦合“ 反向耦合“-”(相互削弱 同向耦合“ (相互增强) 同向耦合“+”(相互增强)
Ψ1 = Ψ11 − Ψ12 = L1i1 − M 12i2 Ψ 2 = Ψ 22 − Ψ 21 = L2i2 − M 21i1
三、同名端与异名端 同向耦合时电流的入端称为耦合电感的同名端 同名端 同向耦合 反向耦合时电流的入端称为耦合电感的异名端 异名端 反向耦合
I 2
I 1 US
ZL
Z11
(ω M ) 2 Y22
US
jω L1
R1
*
*
jω L2
R2
一次侧等效电路
& US I&= 1 Z11 + (ω M ) 2 Y22 & jω MY11U S I& = − 2 Z 22 + (ω M ) 2 Y11 & &' = U S = Y U & I1 11 S Z11
ZL
US
Z 22 I&+ Z M I&= 0 (次级) 次级) 2 1
解方程, 解方程,得:
R2
变压器电路模型
数据库 ChpA_Integrity

实现方法:
8直接在关系模式中定义,存储在数据字典中 8利用CHECK子句定义规则
静态元组约束
静态元组约束就是规定元组的各个列之间的约束关 系。例如:
8规定发货量不得超过定货量 8教授的工资不低于1000元
实现方法:
8直接在关系模式中定义,存储在数据字典中 8利用CHECK子句实现 8利用触发器(Trigger)实现 8利用事件(Event)实现
确发器注意事项(Sybase为例)
1.一个表确发器最多三个(insert/update/delete) 2.最多16层嵌套(修改表引发另外确发器),不能递归 3.确发器系统开销很小 4.确发器中rollback将引发的批语句一起rollback; 5.表的dbo才能建立确发器;
完整性约束条件分类
对象状态
动态列级约 束 动态 静态列级约束 静态
动态元组约束
动态关系约束
静态元组约束
静态关系约束
列
元组
关系
关 系 粒 度
静态列级约束
静态列级约束是对一个列的取值域的定义。
8对数据类型的约束(类型、长度、单位、精度...) 8对数据格式的约束(如日期、时间) 8对取值范围或取值集合的约束 8对空值的约束 8其它约束(排序、组合列等)
用户定义完整性:not null /unique dname varchar(9) constraint u1 unique sname varchar(20) constraint c2 not null 应发工资<=3000 constraint c1 check(sal + deduct <=3000) create trigger 触发器
静态关系约束
静态关系约束就是在一个关系的元组之间或多个关 系之间定义的联系或约束。
自动控制原理及其实例

先进控制理论及其应用院系:班级:姓名:学号:前言20世纪70年代以来,随着计算机即使的广泛应用,自动控制技术有了很大的发展,先进过程控制(advanced process control,pac)应运而生。
先进过程控制也称先进控制。
它是具有比常规控制更好的控制效果的控制策略的系统,是提高过程控制质量、解决复杂赴欧成问题的理论和技术。
先进控制理论是建立在状态空间法基础上的一种控制理论,是自动控制理论的一个主要组成部分。
在先进控制理论中,对控制系统的分析和设计主要是通过对系统的状态变量的描述来进行的,基本的方法是时间域方法。
先进控制理论比经典控制理论所能处理的控制问题要广泛得多,包括线性系统和非线性系统,定常系统和时变系统,单变量系统和多变量系统。
先进控制理论的名称是在1960年以后开始出现的,用以区别当时已经相当成熟并在后来被称为经典控制理论的那些方法。
先进控制理论是在20世纪50年代中期迅速兴起的空间技术的推动下发展起来的。
空间技术的发展迫切要求建立新的控制原理,以解决诸如把宇宙火箭和人造卫星用最少燃料或最短时间准确地发射到预定轨道一类的控制问题。
这类控制问题十分复杂,采用经典控制理论难以解决。
1958年,苏联科学家Л.С.庞特里亚金提出了名为极大值原理的综合控制系统的新方法。
在这之前,美国学者R.贝尔曼于1954年创立了动态规划,并在1956年应用于控制过程。
他们的研究成果解决了空间技术中出现的复杂控制问题,并开拓了控制理论中最优控制理论这一新的领域。
1960~1961年,美国学者R.E.卡尔曼和R.S.布什建立了卡尔曼-布什滤波理论,因而有可能有效地考虑控制问题中所存在的随机噪声的影响,把控制理论的研究范围扩大,包括了更为复杂的控制问题。
几乎在同一时期内,贝尔曼、卡尔曼等人把状态空间法系统地引入控制理论中。
状态空间法对揭示和认识控制系统的许多重要特性具有关键的作用。
其中能控性和能观测性尤为重要,成为控制理论两个最基本的概念。
drupal10 数据库结构

一、概述Drupal是一个开源的内容管理系统(CMS),在全球信息站开发中得到了广泛的应用。
作为一个功能强大的CMS,Drupal 需要一个强大的数据库来支持其各种功能和模块。
Drupal 10数据库结构的设计和优化将对全球信息站的性能和扩展性产生深远的影响。
二、数据库概述1. 数据库引擎:Drupal 10 默认使用 MySQL 或 MariaDB 作为其数据库引擎,也可以支持 PostgreSQL、SQLite 或 Microsoft SQL Server。
2. 数据表和字段:Drupal 10 的数据库中包含了大量的数据表和字段,用来存储全球信息站的内容、配置、用户信息等。
其中,最常见的包括节点(node)、用户(user)、角色(role)、权限(permission)等。
三、数据库设计原则1. 规范化:Drupal 10 的数据库设计遵循了数据库规范化的原则,以减少数据冗余,提高数据的一致性和完整性。
2. 引用完整性:数据库中的外键和引用关系被严格控制,保证数据的准确性和一致性。
3. 性能优化:针对 Drupal 10 的特点,数据库的设计需要考虑性能优化,包括索引的设计、查询语句的优化等。
四、节点(node)数据表结构1. node 表:node 表存储了全球信息站中的各种内容节点,包括文章、页面、评论等。
字段包括:nid(节点 ID)、type(节点类型)、title(标题)、created(创建时间)等。
2. node_revision 表:node_revision 表存储了节点的历史版本信息。
字段包括:vid(版本 ID)、nid(节点 ID)、title(标题)、timestamp(时间戳)等。
五、用户(user)数据表结构1. users 表:users 表存储了全球信息站的用户信息。
字段包括:uid(用户 ID)、name(用户名)、m本人l(电流新箱位置区域)、created(注册时间)等。
网络设备安装与调试chp10bgp

• AS.IGP在一个AS内操作(IGPs operate within an)
• BGP在AS之间操作。(BGP is used between autonomous systems. ) • 确保无环路的路由信息的交换(Exchange of loop-free routing information is guaranteed.)
2
第一节 BGP基本原理和基本配置
3
使用BGP连接到Internet (Using BGP to Connect to the Internet)
4
BGP自治系统(BGP Autonomous Systems)
• AS是一组被统一管理的路由器,他们使用相同的内部网关路由协议和统一的度量值来决定在AS内 部路由数据包,并使用EGP决定如何把数据包路由到其他的AS。 • An AS is a collection of networks under a single technical administration.
5
路径向量路由(BGP Path-Vector Routing)
• IGP通告网络,并描述到达这些网络的度量值 • IGPs announce networks and describe the metric to reach those networks. BGP通告路径和网络的可达信息。BGP通过属性(类似度量值)来描述路径信息 BGP announces paths and the networks that are reachable at the end of the path. BGP describes the path by using attributes, which are similar to metrics. • BGP允许管理员定义策略来决定数据怎样通过AS • BGP allows administrators to define policies or rules for how data will flow through the autonomous systems.
CHP10 指标分析

3.平滑异同移动平均线 (MACD)
• 平滑异同移动平均线(MACD)其原理是运用 快速与慢速的移动平均线聚合与分离的征 兆功能,加以双重平滑运算以便判断股票 的买进与卖出时机和信号。
2019/12/28
MACD(12,26,9)的计算原理
1、计算快(慢)速指数平滑线(EMA) (注:第一个EMA值等于第一天收盘价)
2019/12/28
3、随机指标(KDJ) • KDJ指标度量了高、低价位与收盘价的关系
,反映了当前收市价在近期价格区域中的相 对位置,看偏向于最高或最低价格带的哪一 边。
2019/12/28
KDJ指标的计算方法
• 以9日周期的KDJ线为例。 首先,计算出最近n日的“RSV值”( ROW STOCHASTIC VALUE,
2019/12/28
技术指标的应用法则
• (1)指标的背离; • (2)指标的交叉; • (3)指标的取值; • (4)指标的形态; • (5)指标的转折; • (6)指标的盲点。
2019/12/28
应用技术指标注意事项
• 不可能永远对,只可能经常错 • 切忌频繁的使用技术指标 • 技术指标是一批工具:选择 4个---5个技术指标
1.ADL只看相对走势,不看取值大小 2.ADL只适用于大盘,不能对个股提出有益的帮助。 3.加权股指数持续下降,并创新低点,腾落指数下降,
2019/12/28
三元股份(600429)
2019/12/28
MACD的应用
买卖股票的MACD判断准则:
• DIF向上突破DEA为买进信号,但在0轴以下交叉 时,仅适宜空头补仓。
• DIF向下跌破DEA为卖出信号,但在0轴以上交叉 时,则仅适宜多头平仓。
CH10VPN

需要在专用网连接到因特网的路由器上 安装 NAT 软件。装有 NAT 软件的路由 器叫做 NAT路由器,它至少有一个有效 的外部全球地址 IPG。
所有使用本地地址的主机在和外界通信 时都要在 NAT 路由器上将其本地地址转 换成 IPG 才能和因特网连接。
虚拟专用网协议
PPTP协议 ·
(PointtoPointTunnelingProtocol,点到点 隧道协议)
PPTP协议是PPP协议与TCP/IP协议的结 合,它吸取了PPP的多协议、用户身份认 证及数据报压缩等优点以及TCP/IP通过 Internet路由数据报的能力。PPTP协议包 含两种类型的通信:用于发送状态、信号 等的控制包和发送载荷的数据报。
使用第三层隧道技术的公司网络不需要IP 地址,也具有安全性;服务提供商网络能 够隐藏公司网络和远端节点地址。
VPN的编址
• VPN所提供的编址选择与专用网络 所提供的是一样的,可以根据需要 选择:
• 本地地址——仅在机构内部使用的 IP 地址,可以由本机构自行分配,而不需 要向因特网的管理机构申请。
虚拟专用网协议
L2F协议
Layer 2 Forwarding,第二层转发协议
L2F协议是Cisco公司于1996年开发 的,用于适应日益增长的拨号服务和 非IP协议信息的应用,在Internet上 开辟一条传输该类信息的虚拟通道, 使IPX和SNA等非IP信息也能分享 Internet这种公共网络所提供的利 益。
虚拟专用网 VPN
虚拟专用网综合了专用和公用网络的 优点,允许有多个站点的公司拥有一 个假想的完全专有的网络,而使用公 用网络作为其站点之间交流的线路。
将VPN定义为虚信道,该信道:
ApacheHadoop的原理和应用

ApacheHadoop的原理和应用Apache Hadoop的原理和应用Apache Hadoop是一个由Apache软件基金会开发的开源框架。
Hadoop可以让用户在分布式计算环境中存储和分析大规模的数据集。
Hadoop包含了两个核心模块,分别是Hadoop Distributed File System (HDFS)和MapReduce计算模型。
本文将讨论Apache Hadoop的原理及其在现实生活中的应用。
一、Hadoop的原理1.1 Hadoop Distributed File SystemHadoop Distributed File System (HDFS)是为大规模数据处理而设计的分布式文件系统。
该文件系统可以在集群内的节点间存储大型数据文件,并能够在高容错性的情况下快速地读取和写入这些文件。
HDFS的设计采用了一种主从式的结构,其中包含名为NameNode的主节点和多个DataNode的从节点。
NameNode负责管理文件系统的命名空间和文件的访问控制,而DataNode则存储实际的数据块,同时向NameNode汇报自己的状况。
HDFS的优点在于其高可靠性和高效性。
如果某个节点出现故障,它存储的数据块可以被自动复制到其他节点上,从而缓解了单点故障的问题。
同时,HDFS的数据读取速度比较快,这是由于数据块被分散存储在多个节点上,可以并行地读取数据。
然而,基于HDFS的应用程序面临一定的限制,例如无法对存储在HDFS上的数据进行修改,只能进行添加和删除操作。
1.2 MapReduce计算模型MapReduce是Hadoop另一个核心部分,它是一种用于处理大型数据集的编程模型和算法。
MapReduce模型能够扩展到数以千计的计算机上,从而允许在强大的分布式计算资源上并行地运行数据处理任务。
MapReduce计算模型由两个主要部分组成:Map和Reduce。
Map任务负责将输入数据划分为若干个小的数据集,每个小数据集都被交给Reduce任务进行处理。