MapReduce应用场景、原理、基本架构及使用方法
运用实例简述mapreduce原理

运用实例简述mapreduce原理MapReduce是一种编程模型和模型化的方法,用于大规模数据集(如分布式文件系统)的并行处理。
它通常用于处理和转换大数据集,以进行数据挖掘、机器学习、数据库等领域的应用。
MapReduce原理的核心思想是将一个复杂的问题拆解成多个小问题,然后将小问题分配给多个处理器(可以是多个计算机或处理器),最后将处理结果汇总并生成最终结果。
这个过程主要包括两个阶段:Map阶段和Reduce阶段。
1.Map阶段:Map阶段的任务是将输入数据集分解为多个小的数据块,并对每个数据块进行处理,生成中间结果。
这个过程通常是一个用户定义的函数,它接受输入数据块并产生一组键-值对。
这些键-值对随后被合并并发送到Reduce阶段。
举个例子,假设我们要对一个大规模的文本文件进行词频统计。
Map阶段会将文本文件分解为单词,并对每个单词生成一个键值对(键为单词,值为该单词在文本中出现的次数)。
2.Reduce阶段:Reduce阶段的任务是将Map阶段产生的中间结果进行汇总,并执行用户定义的Reduce函数,对汇总后的键值对进行处理并生成最终结果。
Reduce函数通常也是用户自定义的函数,它接受一组键值对并产生一个输出结果。
同样以词频统计为例,Reduce阶段会对所有相同的单词进行计数,并将结果输出为一个新的文本文件,其中包含每个单词及其对应的频数。
MapReduce原理的优势在于它能够充分利用多台计算机或处理器的计算资源,实现大规模数据的并行处理。
同时,MapReduce还提供了简单易用的编程接口,使得用户可以轻松地处理大规模数据集。
在实际应用中,MapReduce已被广泛应用于各种领域,如数据挖掘、机器学习、数据库等。
通过MapReduce,我们可以轻松地处理和分析大规模数据集,从而获得更有价值的信息和知识。
需要注意的是,MapReduce原理并不是适用于所有类型的大规模数据处理任务。
对于一些特定的任务,可能需要使用其他类型的并行处理模型和方法。
mapreduce数据处理原理

MapReduce数据处理原理1. 概述MapReduce是一种用于大规模数据处理的编程模型,由Google首先提出并应用于分布式计算中。
它通过将大规模数据集划分为小的子集,并在多个计算节点上同时进行处理,从而实现高效的数据处理。
MapReduce的核心思想是将复杂的数据处理任务分解成简单的、可并行执行的任务。
2. 基本原理MapReduce模型基于两个基本操作:Map和Reduce。
下面将详细介绍这两个操作以及它们在数据处理中的作用。
2.1 Map操作Map操作是将输入数据集中的每个元素进行转换,并生成一个键值对集合作为输出。
具体来说,Map操作接受一个键值对作为输入,经过转换后输出一个新的键值对。
在Map操作中,用户需要自定义一个Map函数,该函数接受输入键值对作为参数,并根据具体需求进行转换操作。
在词频统计任务中,用户可以定义一个Map函数来将输入文本切分成单词,并为每个单词生成一个键值对(单词,1)。
2.2 Reduce操作Reduce操作是将经过Map操作后生成的键值对集合按照键进行分组,并对每个组进行聚合计算。
具体来说,Reduce操作接受一个键和与该键相关联的一组值作为输入,经过聚合计算后输出一个新的键值对。
在Reduce操作中,用户需要自定义一个Reduce函数,该函数接受输入键和与之相关联的值集合作为参数,并根据具体需求进行聚合计算。
在词频统计任务中,用户可以定义一个Reduce函数来对每个单词出现的次数进行累加。
2.3 数据流MapReduce模型通过Map和Reduce操作将数据流划分为三个阶段:输入阶段、中间阶段和输出阶段。
在输入阶段,原始数据集被划分成多个小的数据块,并分配给不同的计算节点进行处理。
每个计算节点上的Map操作并行处理自己分配到的数据块,并生成中间结果。
在中间阶段,所有计算节点上生成的中间结果被按照键进行分组,相同键的结果被发送到同一个Reduce操作所在的计算节点。
mapreduce结构

MapReduce结构一、概述MapReduce是一种分布式计算模型,用来处理大规模数据集。
它主要用于解决数据处理、分析和挖掘中的各种问题。
MapReduce结构由两个主要部分组成:Map和Reduce。
在Map阶段,数据被分成若干个片段,每个片段被分配给一个Map任务进行处理。
在Reduce阶段,Map任务的输出被收集和聚合,最终得到最终结果。
二、Map阶段Map阶段是MapReduce结构的第一部分。
在这个阶段,数据被拆分成多个片段,并被分配给各个Map任务进行处理。
Map任务是并行执行的,每个任务独立处理自己负责的数据片段。
Map任务的输入通常是一条记录,通过对输入进行处理,可以生成键值对作为输出。
每个键值对都有一个键和一个值,这些键值对将作为Reduce 阶段的输入。
2.1 Map阶段的流程1.数据拆分:输入数据被分成若干个片段,每个片段被分配给一个Map任务。
这个过程称为数据拆分。
2.数据处理:每个Map任务对自己负责的数据片段进行处理。
处理的方式可以是提取关键信息、过滤数据或进行计算等。
3.生成键值对:Map任务根据输入数据,生成键值对作为输出。
每个键值对都包括一个键和一个值。
4.数据分发:生成的键值对根据键,被分发到不同的Reduce任务进行处理。
数据分发的过程可以是基于哈希表或者排序等方式。
2.2 Map阶段的特点1.并行处理:Map任务是并行执行的,每个任务独立处理一部分数据。
2.局部处理:Map任务只处理自己负责的数据片段,通过局部处理,减少了数据传输的开销。
3.输出键值对:Map任务的输出是键值对,这些键值对将成为Reduce阶段的输入。
三、Reduce阶段Reduce阶段是MapReduce结构的第二部分。
在这个阶段,Map任务的输出被收集和聚合,最终得到最终结果。
Reduce任务的数量可以通过参数进行设置,可以灵活控制。
3.1 Reduce阶段的流程1.数据收集:Map任务的输出被收集起来,分组成若干个键值对列表。
MapReduce的原理及执行过程
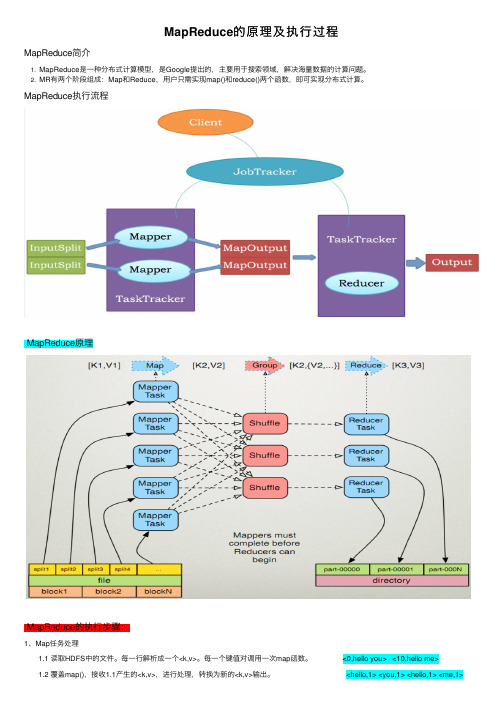
MapReduce的原理及执⾏过程MapReduce简介1. MapReduce是⼀种分布式计算模型,是Google提出的,主要⽤于搜索领域,解决海量数据的计算问题。
2. MR有两个阶段组成:Map和Reduce,⽤户只需实现map()和reduce()两个函数,即可实现分布式计算。
MapReduce执⾏流程MapReduce原理MapReduce的执⾏步骤:1、Map任务处理 1.1 读取HDFS中的⽂件。
每⼀⾏解析成⼀个<k,v>。
每⼀个键值对调⽤⼀次map函数。
<0,hello you> <10,hello me> 1.2 覆盖map(),接收1.1产⽣的<k,v>,进⾏处理,转换为新的<k,v>输出。
<hello,1> <you,1> <hello,1> <me,1> 1.3 对1.2输出的<k,v>进⾏分区。
默认分为⼀个区。
详见《》 1.4 对不同分区中的数据进⾏排序(按照k)、分组。
分组指的是相同key的value放到⼀个集合中。
排序后:<hello,1> <hello,1><me,1> <you,1> 分组后:<hello,{1,1}><me,{1}><you,{1}> 1.5 (可选)对分组后的数据进⾏归约。
详见《》2、Reduce任务处理 2.1 多个map任务的输出,按照不同的分区,通过⽹络copy到不同的reduce节点上。
(shuffle)详见《》 2.2 对多个map的输出进⾏合并、排序。
覆盖reduce函数,接收的是分组后的数据,实现⾃⼰的业务逻辑, <hello,2> <me,1> <you,1> 处理后,产⽣新的<k,v>输出。
MapReduce的应用与实现

MapReduce的应用与实现MapReduce的应用与实现大数据时代的到来,数据量的增长速度越来越快,传统的数据处理方式往往难以胜任,因此新的数据处理方案不断涌现。
MapReduce是其中一种比较常见的数据处理框架,它可应用于各种领域中的数据处理操作,本文将从MapReduce的应用和实现两个方面来进行介绍和分析。
一、MapReduce的应用1.分布式计算MapReduce是一种分布式计算模型,是一种能够把一个大型的任务并行化,分给少量计算机处理的方法。
MapReduce的核心思想就是把计算过程分成两个步骤:Map和Reduce。
在Map的过程中,原始的数据由Map函数进行筛选,这个阶段的主要作用是将原始数据进行初步处理,它会将原始数据转变成一个中间格式,这个格式能够被Reduce所理解。
在Reduce过程中,中间数据由Reduce函数进行处理,得到最终的结果。
由于MapReduce的方式是基于分布式计算的,因此不需要大量的计算资源才能够处理海量数据,在分布式环境下,可以对数据进行快速计算和分析,具有很高的效率和可扩展性。
2.数据挖掘在数据挖掘过程中,需要对数据进行清洗,处理,筛选等操作,还需要计算各种指标,分析数据的特征和规律。
由于海量数据的存在,传统数据处理方式会非常困难,而MapReduce可以很好地解决这个问题。
MapReduce可以通过改进Map和Reduce算法来实现对数据的处理和清洗,并且可以实现分布式计算,从而提高数据挖掘的效率和精度。
3.日志分析在互联网时代中,互联网公司会生成大量的日志数据,如访问量,点击率,搜索关键字等,这些数据是非常重要的,需要进行数据分析和挖掘,来获取有价值信息。
MapReduce可以实现分布式、高性能的计算和分析,从而非常适合日志分析的需求。
4.图像处理在图像处理中,需要对图像进行识别、分类、过滤等操作,不同的算法需要处理海量的图像数据。
MapReduce可以很好地解决这个问题,可以通过MapReduce来实现对图像的分割、特征提取和分类等操作,从而实现对图像的高效处理。
MapReduce应用场景、原理

MapReduce(分布式计算框架)
JobTracker
• Master
• 管理所有作业 • 将作业分解成一系列任务 • 将任务指派给TaskTracker • 作业/任务监控、错误处理
等
TaskTrackers
• Slave • 运行Map Task和 Reduce Task • 与JobTracker交互, 执行命令,并汇报 任务状态
4 2013/10/7
目录
1. MapReduce的应用场景 2. MapReduce编程模型
3. MapReduce的架构 4. MapReduce调度器 5. MapReduce配置与部署 6. 常见MapReduce应用场景 7. 总结
5 2013/10/7
MapReduce的实例—Wordcount
TextInputFormat
Key是行在文件中的偏移量,value是行内容 若行被截断,则读取下一个block的前几个字符
15
2013/10/7
MapReduce编程模型—Split与Block
Block
HDFS中最小的数据存储单位
默认是64MB
Spit
MapReduce中最小的计算单元 默认与Block一一对应
名的网页交给同一个Reduce Task处理
20 2013/10/7
MapReduce编程模型
Map阶段
InputFormat(默认TextInputFormat) Mapper
Combiner(local reducer) Partitioner
Reduce阶段
Reducer OutputFormat(默认TextOutputFormat)
MapReduce的架构及原理

MapReduce的架构及原理MapReduce是⼀种分布式计算模型,是Hadoop的主要组成之⼀,承担⼤批量数据的计算功能。
MapReduce分为两个阶段:Map和Reduce。
⼀、MapReduce的架构演变客户端向JobTracker提交⼀个作业,JobTracker会把这个作业拆分成多份,然后分配给TaskTracker(任务执⾏者)执⾏,TaskTracker会每隔⼀段时间向JobTracker发送⼼跳信息,如果JobTracker在⼀段时间内没有收到TaskTracker的⼼跳信息,JobTracker会认为TaskTracker挂掉,并把TaskTracker的任务分配给其它TaskTracker。
该架构存在的问题:a、JobTracker节点压⼒过⼤;b、单点故障;3、只能跑MapReduce作业。
以上架构,在Hadoop版本中称为MRv2,所解决的问题:1、更⾼的集群利⽤率,⼀个框架未使⽤的资源可由另⼀个框架进⾏使⽤,充分的避免资源浪费;2、很⾼的扩展性;3、yarn通过加⼊ApplicationMaster可变部分,可以编写不同的APPMst;4、监控job的tasks运⾏情况下放到ApplicationMaster中;⼆、MapReduce执⾏过程1、客户端提交作业2、JobClient与JobTracker通信,JobTracker返回⼀个JobID3、JobClient复制作业资源⽂件将运⾏作业所需要的资源赋值到HDFS上,包括MR程序打包的JAR⽂件、配置⽂件和输⼊划分信息。
这些⽂件都存在JobTracker专门为该作业创建的⽂件夹中,⽂件夹名称为该作业的JobID。
4、提交任务5、JobTracker初始化任务,创建作业对象JobTracker接收到作业后,将其放在⼀个作业队列,等待作业调度器进⾏调度。
6、对HDFS上的资源⽂件进⾏分⽚,每个分⽚对应⼀个MapTask当作业调度器根据⾃⼰的调度算法调度到该作业时,会根据输⼊划分信息为每个划分创建⼀个map任务,并将map任务分配给TaskTracker 执⾏7、TaskTracker会向JobTracker返回⼀个⼼跳信息,根据⼼跳信息分配任务TaskTracker每隔⼀段时间会给JobTracker发送⼀个⼼跳,告诉JobTracker它依然在运⾏,同时⼼跳中还携带着任务进度等信息8、TaskTracker从HDFS上获取作业资源⽂件对于map和reduce任务,TaskTracker根据主机核的数量和内存的⼤⼩有固定数量的map槽和reduce槽。
mapreduce的介绍及工作流程

mapreduce的介绍及工作流程MapReduce是一种用于大规模数据处理的编程模型和计算框架。
它可以有效地处理大规模数据集,提供了分布式计算的能力,以及自动化的数据分片、任务调度和容错机制。
本文将介绍MapReduce的基本概念、工作流程以及其在大数据处理中的应用。
一、MapReduce的基本概念MapReduce的基本概念分为两个部分:Map和Reduce。
Map用于对输入数据进行初步处理,将输入数据分解成若干个<key, value>对。
Reduce则对Map的输出进行聚合操作,生成最终的结果。
MapReduce的输入数据通常是一个大型数据集,可以是文件、数据库中的表或者其他形式的数据源。
输入数据被划分为若干个数据块,每个数据块由一个Map任务处理。
Map任务将输入数据块转化为若干个中间结果,每个中间结果都是一个<key, value>对。
Reduce任务负责对Map任务的输出进行进一步处理,将具有相同key的中间结果进行聚合操作,生成最终的结果。
Reduce任务的输出结果通常是一个<key, value>对的集合。
二、MapReduce的工作流程MapReduce的工作流程可以简单概括为以下几个步骤:输入数据的划分、Map任务的执行、中间结果的合并与排序、Reduce任务的执行、最终结果的输出。
1. 输入数据的划分:输入数据被划分成若干个数据块,在分布式环境下,每个数据块都会被分配到不同的节点上进行处理。
数据块的大小通常由系统自动设置,以保证每个Map任务的负载均衡。
2. Map任务的执行:每个Map任务独立地处理一个数据块,将输入数据转化为若干个中间结果。
Map任务可以并行执行,每个任务都在独立的节点上运行。
Map任务的输出中间结果被存储在本地磁盘上。
3. 中间结果的合并与排序:Map任务输出的中间结果需要在Reduce任务执行之前进行合并和排序。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
7
MapReduce的实例—Wordcount
Ø Case 1:整个文件可以加载到内存中; ü sort datafile | uniq -c Ø Case 2:文件太大不能加载到内存中,但 <word, count>可以存放到内存中; Ø Case 3:文件太大无法加载到内存中,且 <word, count>也不行
ü R是Reduce Task数目 ü 允许用户自定义
Ø 很多情况需自定义Partitioner
ü 比如“hash(hostname(URL)) mod R”确保相同域 名的网页交给同一个Reduce Task处理
21
MapReduce编程模型 Ø Map阶段
ü InputFormat(默认TextInputFormat) ü Mapper ü Combiner(local reducer) ü Partitioner
10
MapReduce编程模型—WordCount
Ø Input: 一系列key/value对 Ø 用户提供两个函数实现:
ü map(k,v) à list(k1,v1) ü reduce(k1, list(v1)) à v2
Ø (k1,v1) 是中间key/value结果对 Ø Output:一系列(k2,v2)对
ü 输入数据格式解析:InputFormat ü 输入数据处理:Mapper ü 数据分组:Partitioner
Ø Reduce阶段由一定数量的Reduce Task组成
ü 数据远程拷贝 ü 数据按照key排序 ü 数据处理:Reducer
13 ü 数据输出格式:OutputFormat
⑥
Reduce Task
Container
④ Resource Manager ② Node Manager ③
⑤
MR AppMaster
Client
⑤ ⑤
Client Node Manager
Map Task
Container
⑥
MapReduce概述
MapReduce编程模型
MapReduce基本架构和原理
MapReduce程序设计
MapReduce的实例—Wordcount Ø 场景:有大量文件,里面存储了单词, 且一个单词占一行 Ø 任务:如何统计每个单词出现的次数? Ø 类似应用场景:
ü 搜索引擎中,统计最流行的K个搜索词; ü 统计搜索词频率,帮助优化搜索词提示
Ø Reduce阶段
ü Reducer ü OutputFormat(默认TextOutputFormat)
22
主要内容
1 2 3 4
MapReduce概述
MapReduce编程模型
MapReduce基本架构和原理
MapReduce程序设计
MapReduce 1.0架构
24
MapReduce 1.0(分布式计算框架)
ü 功能类似于 1.0中的JobTracker,但不负责资源管理; ü 功能包括:任务划分、资源申请并将之二次分配个Map Task和Reduce Task、任务状态监控和容错。
28
MapReduce 2.0运行流程
Map Task
Container
Client
Node Manager ①
11
MapReduce编程模型—WordCount
map(key, value): // key: document name; value: text of document for each word w in value: emit(w, 1) reduce(key, values): // key: a word; values: an iterator over counts result = 0 for each count v in values: result += v emit(key,result)
MR MR App App Mstr Mstr Container
27
MapReduce 2.0架构 Ø Client
ü 与MapReduce 1.0的Client类似,用户通过Client与YARN 交互,提交MapReduce作业,查询作业运行状态,管理作 业等。
Ø MRAppMaster
29
MapReduce 2.0容错性 Ø MRAppMaster容错性
ü 一旦运行失败,由YARN的ResourceManager负责重新启 动,最多重启次数可由用户设置,默认是2次。一旦超过 最高重启次数,则作业运行失败。
Ø Map Task/Reduce Task
ü Task周期性向MRAppMaster汇报心跳; ü 一旦Task挂掉,则MRAppMaster将为之重新申请资源, 并运行之。最多重新运行次数可由用户设置,默认4次。
ü 处理跨行问题
Ø 将分片数据解析成key/value对
ü 默认实现是TextInputFormat
Ø TextInputFormat
ü Key是行在文件中的偏移量,value是行内容 ü 若行被截断,则读取下一个block的前几个字符
16
MapReduce编程模型—Split与Block Ø Block
Ø MapReduce特点
ü 易于编程 ü 良好的扩展性 ü 高容错性 ü 适合PB级以上海量数据的离线处理
4
MapReduce的特色—不擅长的方面 Ø 实时计算
Edited by Foxit Reader Copyright(C) by Foxit Software Company,2005-2008 For Evaluation Only.
30
MapReduce计算框架—数据本地性
机架间带宽为2-10Gbps Switch 同一个机架 内任意两个 节点间共享 1Gbps带宽
Resource Scheduler
2 3,8 Node Manager 6 Map Map Task Task Container 7 2 5 5 4 Node Manager Container 6 Reduce Reduce Task Task 7 7 6 Container Map Map Task Task
12
MapReduce编程模型
Edited by Foxit Reader Copyright(C) by Foxit Software Company,2005-2008 For Evaluation Only.
Ø MapReduce将作业的整个运行过程分为两个阶段: Map阶段和Reduce阶段 Ø Map阶段由一定数量的Map Task组成
ü 像MySQL一样,在毫秒级或者秒级内返回结果
Ø 流式计算
ü MapReduce的输入数据集是静态的,不能动态变化 ü MapReduce自身的设计特点决定了数据源必须是静 态的
Ø DAG计算
ü 多个应用程序存在依赖关系,后一个应用程序的 输入为前一个的输出
5
主要内容
1 2 3 4
26
MapReduce 2.0架构
ResourceManager Client Client 1 Applications Manager
Edited by Foxit Reader Copyright(C) by Foxit Software Company,2005-2008 For Evaluation Only.
MapReduce编程模型—内部逻辑
HDFS Split 0
Read (Inputformat)
Split 1
Read (Inputformat)
Split 2
Read (Inputformat)
Split 3
Read (Inputformat)
Mapper
Map Task
Mapper c 1 c 1
18
MapReduce编程模型—Combiner
19
MapReduce编程模型—Combiner Ø Combiner可做看local reducer
ü 合并相同的key对应的value(wordcount例子) ü 通常与Reducer逻辑一样
Ø 好处
ü 减少Map Task输出数据量(磁盘IO) ü 减少Reduce-Map网络传输数据量(网络IO)
ü HDFS中最小的数据存储单位 ü 默认是64MB
Ø Spit
ü MapReduce中最小的计算单元 ü 默认与Block一一对应
Ø Block与Split
ü Split与Block是对应关系是任意的,可由用户控制
17
MapReduce编程模型—InputFormat
Edited by Foxit Reader Copyright(C) by Foxit Software Company,2005-2008 For Evaluation Only.
Shuffle & Sort c 1 c 1 Reducer
Write (Outputformat)
a
Write (Outputformat)
a 1
b 1
c 1
Reduce 阶段
Reducer
HDFS 14
Part-0
Part-1
Part-2
MapReduce编程模型—外部物理结构
15
MapReduce编程模型—InputFormat Ø 文件分片(InputSplit)方法
25
MapReduce 1.0(分布式计算框架)
Map Task
• Map引擎 • 解析每条数据记录,传递给
用户编写的map() • 将map()输出数据写入本地 磁盘(如果是map-only作业, 则直接写入HDFS)