第二次数学建模作业
数学建模的五次作业

图1中是大学校园一角。
图中标示出道路和两点之间的大致距离(单位:百英尺)。
你的同舍同学说服(convince)你在周末时候在某个道路交叉点(intersections)摆个热狗摊。
你希望小摊尽可能方便同学们。
哪里是最合适的地点呢?表1:校园一角从问题开始问题叙述:假如宿舍位于A,C,D,E和F点,A舍楼有200生,C和D各有300生,E和F楼各有100生。
(1) 如果我们知道A和C是女生楼,D,E和F是男生楼,并且只有30%的女生喜欢在你的小摊上吃热狗,而有80%的男生喜欢吃,那么你的选点会有怎样的改变?(2) 如果B和C点以及E和D点之间的路是上坡路,而上坡路比下坡路难走一倍。
你会怎样选点?A C D E F MAX AVG A 0154017601540176017601320B 660880110088011001100924C 15400220132017601760968D 17602200110015401760924E 15401320110004401540880F 176017601540440017601100G 15401760176066022017601188 A C D E F MAX AVGA04621408123214081408902B198264880704880880585.2C4620176105614081408620.4D52866088012321232541.2E4623968800352880418F528528123235201232528G 46252814085281761408620.4问题分析:问题(1)分析由于学生主要从宿舍到小摊,所以一个方法是算出从每个舍楼到每个可能的小摊地点的距离。
如表1的数据。
列表示所有可能的小摊位置,行表示从宿舍楼到各摊点位置的距离。
同时,在表格中包括了,从舍楼到小摊位置的最大距离和从小摊到舍楼的平均距离。
表1基于表中数据,如果将热狗摊安在B 点,那么没有哪个学生从舍楼到摊点需要走超过500英尺的距离,放在A 点则有学生要走800英尺。
数学建模作业及答案

数学建模作业姓名:叶勃学号:班级:024121一:层次分析法1、 分别用和法、根法、特征根法编程求判断矩阵1261/2141/61/41A ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦11/2433217551/41/711/21/31/31/52111/31/5311A ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦的特征根和特征向量(1)冪法求该矩阵的特征根和特征向量 程序为:#include<iostream> #include<math.h> using namespace std;#define n 3 //三阶矩阵#define N 20 #define err 0.0001 //幂法求特征值特征向量 void main(){cout<<"**********幂法求矩阵最大特征值及特征向量***********"<<endl; int i,j,k;double A[n][n],X[n],u,y[n],max;cout<<"请输入矩阵:\n"; for(i=0;i<n;i++) for(j=0;j<n;j++)cin>>A[i][j]; //输入矩阵 cout<<"请输入初始向量:\n"; for(i=0;i<n;i++)cin>>X[i]; //输入初始向量 k=1; u=0;while(1){ max=X[0]; for(i=0;i<n;i++) {if(max<X[i]) max=X[i]; //选择最大值 }for(i=0;i<n;i++)y[i]=X[i]/max; for(i=0;i<n;i++)X[i]=0;for(j=0;j<n;j++)X[i]+=A[i][j]*y[j]; //矩阵相乘}if(fabs(max-u)<err){cout<<"A的特征值是 :"<<endl; cout<<max<<endl; cout<<"A的特征向量为:"<<endl; for(i=0;i<n;i++) cout<<X[i]/(X[0]+X[1]+X[2])<<" ";cout<<endl;break;}else{if(k<N) {k=k+1;u=max;} else {cout<<"运行错误\n";break;}}} }程序结果为:(2)和法求矩阵最大特征值及特征向量程序为:#include<stdio.h>#include<iostream>#include<math.h> using namespace std;#define n 3 //三阶矩阵#define N 20void main(){int i,j,k;double A[n][n],w[n],M[n],u[n],W[n][n],max;cout<<"********和法求矩阵的特征根及特征向量*******"<<endl;cout<<"请输入矩阵:\n";for(i=0;i<n;i++)for(j=0;j<n;j++)cin>>A[i][j]; //输入矩阵 //计算每一列的元素和M[0]=0;M[1]=0;M[2]=0;for(i=0;i<n;i++)for(j=0;j<n;j++){M[i]+=A[j][i];}//将每一列向量归一化for(i=0;i<n;i++)for(j=0;j<n;j++){W[j][i]=A[j][i]/M[i];}//输出按列归一化之后的矩阵Wcout<<"按列归一化后的矩阵为:"<<endl;for(i=0;i<n;i++)for(j=0;j<n;j++){cout<<W[i][j]<<" ";if(j==2)cout<<endl;} //求特征向量w[0]=0;w[1]=0;w[2]=0;for(i=0;i<n;i++)for(j=0;j<n;j++){w[i]+=W[i][j];}cout<<"特征向量为:"<<endl; for(i=0;i<n;i++){u[i]=w[i]/(w[0]+w[1]+w[2]);cout<<u[i]<<" "<<endl;}//求最大特征值max=0;for(i=0;i<n;i++){w[i] = 0;for(j=0;j<n;j++){w[i] += A[i][j]*u[j];}}for(i = 0;i < n;i++){max += w[i]/u[i];}cout<<"最大特征根为:"<<endl;cout<<max/n<<endl; }运行结果为:(3)根法求矩阵最大特征值及特征向量:程序为:#include<stdio.h>#include<iostream>#include<math.h>using namespace std;#define n 3 //三阶矩阵#define N 20void main(){int i,j;double A[n][n],w[n],M[n],u[n],W[n][n],max;cout<<"********根法求矩阵的特征根及特征向量*******"<<endl; cout<<"请输入矩阵:\n";for(i=0;i<n;i++)for(j=0;j<n;j++)cin>>A[i][j]; //输入矩阵//计算每一列的元素和M[0]=0;M[1]=0;M[2]=0;for(i=0;i<n;i++)for(j=0;j<n;j++){M[i]+=A[j][i];}//将每一列向量归一化for(i=0;i<n;i++)for(j=0;j<n;j++){W[j][i]=A[j][i]/M[i];}//输出按列归一化之后的矩阵Wcout<<"按列归一化后的矩阵为:"<<endl;for(i=0;i<n;i++)for(j=0;j<n;j++){cout<<W[i][j]<<" ";if(j==2)cout<<endl;}//求特征向量//w[0]=A[0][0];w[1]=A[0][1];w[2]=A[0][2];w[0]=1;w[1]=1;w[2]=1;for(i=0;i<n;i++){for(j=0;j<n;j++){w[i]=w[i]*W[i][j];}w[i]=pow(w[i], 1.0/3);}cout<<"特征向量为:"<<endl;for(i=0;i<n;i++){u[i]=w[i]/(w[0]+w[1]+w[2]);cout<<u[i]<<" "<<endl;}//求最大特征值max=0;for(i=0;i<n;i++){w[i] = 0;for(j=0;j<n;j++){w[i] += A[i][j]*u[j];}}for(i = 0;i < n;i++){max += w[i]/u[i];}cout<<"最大特征值为:"<<endl; cout<<max/n;}运行结果为:2、编程验证n阶随机性一致性指标RI:运行结果:3、考虑景色、费用、居住、饮食、旅途五项准则,从桂林、黄山、北戴河三个旅游景点选择最佳的旅游地。
奥鹏福师21年秋季《数学建模》在线作业二_4.doc

1.数学建模的真实世界的背景是可以忽视的A.错误B.正确【参考答案】: A2.恰当的选择特征尺度可以减少参数的个数A.错误B.正确【参考答案】: B3.题面见图片A.错误B.正确【参考答案】: B4.现在公认的科学单位制是SI制A.错误B.正确【参考答案】: B5.蒙特卡罗模拟简称M-C模拟A.错误B.正确【参考答案】: B6.研究新产品销售模型是为了使厂家和商家对新产品的推销速度做到心中有数A.错误B.正确【参考答案】: B7.量纲分析是20世纪提出的在物理领域建立数学模型的一种方法A.错误B.正确【参考答案】: B8.利用数据来估计模型中出现的参数值称为模型参数估计A.错误B.正确【参考答案】: B9.数学建模中常遇到微分方程的建立问题A.错误B.正确【参考答案】: B10.整个数学建模过程是又若干个有明显区别的阶段性工作组成A.错误B.正确【参考答案】: B11.系统模拟是研究系统的重要方法A.错误B.正确【参考答案】: B12.数学建模以模仿为目标A.错误B.正确【参考答案】: A13.没有创新,人类就不会进步A.错误B.正确【参考答案】: B14.论文写作的目的在于表达你所做的事情A.错误B.正确【参考答案】: B15.建模中的数据需求常常是一些汇总数据A.错误B.正确【参考答案】: B16.我们研究染色体模型是为了预防遗传病A.错误B.正确【参考答案】: B17.在解决实际问题时经常对随机现象进行模拟A.错误B.正确【参考答案】: B18.对系统运动的研究不可以归结为对轨线的研究A.错误B.正确【参考答案】: A19.关联词联想法属于发散思维方法A.错误B.正确【参考答案】: B20.图示法是一种简单易行的方法A.错误B.正确【参考答案】: B21.捕食系统的方程是意大利学家Lanchester提出的A.错误B.正确【参考答案】: A22.问题三要素结构是初态,目标态和过程A.错误B.正确【参考答案】: B23.任何一个模型都会附加舍入误差A.错误B.正确【参考答案】: B24.现在世界的科技文献不到2年就增加1倍A.错误B.正确【参考答案】: A25.关键词不属于主题词A.错误B.正确【参考答案】: A26.利用无量纲方法可对模型进行简化A.错误B.正确【参考答案】: B27.赛程安排不属于逻辑分析法A.错误B.正确【参考答案】: A28.建模假设应是有依据的A.错误B.正确【参考答案】: B29.建模主题任务是整个工作的核心部分A.错误B.正确【参考答案】: B30.常用的建模方法有机理分析法和测试分析法A.错误B.正确【参考答案】: B31.量纲齐次原则指任一个有意义的方程必定是量纲一致的A.错误B.正确【参考答案】: B32.电-机类比是同一数学模型在科学上应用最为广泛的一种类比A.错误B.正确【参考答案】: B33.数据的需求是与建立模型的目标密切相关的A.错误B.正确【参考答案】: B34.随机误差不是由偶然因素引起的A.错误B.正确【参考答案】: A35.利用理论分布基于对问题的实际假设选择适当的理论分布可以对随机变量进行模拟A.错误B.正确【参考答案】: B36.数学建模的误差是不可避免的A.错误B.正确【参考答案】: B37.建立一个数学模型与求解一道数学题目没有差别A.错误B.正确【参考答案】: A38.数学建模没有唯一正确答案A.错误B.正确【参考答案】: B39.引言是整篇论文的引论部分A.错误B.正确【参考答案】: B40.数学建模第一步是明确问题A.错误B.正确【参考答案】: B41.采取面向事件法进行系统模拟的步骤是____A.写出实体(实体的特征),状态,活动B.确定系统的运转规则,画出说明事件和活动的流向图C.绘制轨迹表表格,产生随机数进行模拟D.写轨迹表【参考答案】: AB42.系统模拟的方式包括____A.计算机程序B.软件包或专用模拟语言C.列表手算【参考答案】: ABC43.数据作用于模型有以下形式____A.在建立模型的初始研究阶段,对数据的分析有助于我们寻求变量间的关系,形成初步的想法B.可以利用数据来估计模型中出现的参数值,称为模型参数估计C.利用数据进行模型检验【参考答案】: ABC44.分析检验一般有____A.量纲一致性检验B.参数的讨论C.假设合理性检验【参考答案】: ABC45.建立数学模型时可作几方面的假设____A.关于是否包含某些因素的假设B.关于条件相对强弱及各因素影响相对大小的假设C.关于变量间关系的假设D.关于模型适用范围的假设【参考答案】: ABCD46.任意分布随机数的模拟包括____A.离散型随机数的模拟B.连续型随机数的模拟C.正态随机数的模拟【参考答案】: ABC47.数学模型的误差原因有____A.来自建模假设的误差B.来自近似求解方法的误差C.来自计算工具的舍入误差D.来自数据测量的误差【参考答案】: ABCD48.正态随机数的模拟的方法有____A.反函数法B.舍选法模拟正态随机数C.坐标变换法D.利用中心极限定理【参考答案】: ABCD49.对模拟模型的分析包括____A.收集系统长期运转的统计值B.比较系统的备选装置C.研究参数变化对系统的影响D.研究改变假设对系统的影响E.求系统的最佳工作条件【参考答案】: ABCDE50.实验误差有____A.随机误差B.系统误差C.过失误差【参考答案】: ABC。
北京工业大学、薛毅、数学模型作业二、作业2、实验二

实验二解:(1)将线性方程组写成矩阵形式dXdt =AX,A=a11a12a21a22=1001若det(A)≠0,则X0=(0,0)T,是唯一平衡点。
p=-(a11+a22)=-2,q=det(A)=1,因为p<0,q>0,所以平衡点不稳定。
(2)将线性方程组写成矩阵形式dXdt =AX,A=a11a12a21a22=−1002若det(A)≠0,则X0=(0,0)T,是唯一平衡点。
p=-(a11+a22)=-1,q=det(A)=-2,因为p<0,q<0,所以平衡点不稳定。
(3)将线性方程组写成矩阵形式dXdt =AX,A=a11a12a21a22=01−20若det(A)≠0,则X0=(0,0)T,是唯一平衡点。
p=-(a11+a22)=0,q=det(A)=2,因为p=0,q>0,所以平衡点不稳定。
(4)将线性方程组写成矩阵形式dXdt =AX,A=a11a12a21a22=−100−2若det(A)≠0,则X0=(0,0)T,是唯一平衡点。
p=-(a11+a22)=3,q=det(A)=2,因为p>0,q>0,p2>4q,所以平衡点稳定。
解:f(N)=R-KN,令f(N)=0,则N=k/Rf`(N)=-K<0,则N=k/R是稳定的。
当N<k/R时f(N)>0,N`(t)>0,N(t)递增;N>k/R时f(N)<0,N`(t)<0,N(t)递减ð2N ðt2=∂f∂N∙ðNðt=-K(R-KN),表明N=k/R为拐点,当N<k/R时N``(t)<0,N>k/R时N``(t)>0从图中可以看出N=k/R是营养平衡值,无论大于或小于这个值,细胞都会向这个点调整,偏离越大调整速率越大,接近平衡值时速率变小。
解:列满足条件的微分方程∂N=r1N−r2N12求平衡点,令f N=r1N−r2N1=0,解得N1=0,N2=r22r12ð2N ðt =∂f∂N∙ðNðt=(r1−12r2N−12)(r1N−r2N12),解得N=r224r12从图中可以看出N1=0不稳定,N2=r22r12是稳定的解:令f x=r1−xNx−Ex=0得平衡点x1=N1−Er,x2=0f`(x1)=E-r,f`(x2)= r-E.若E<r,则有f`(x1)<0,f`(x2)>0.则x1是稳定的,x2是不稳定的。
数学建模(2)第二次作业word版
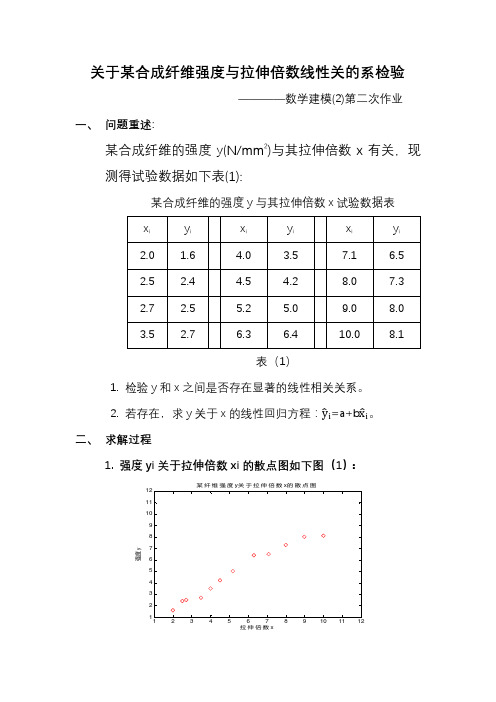
关于某合成纤维强度与拉伸倍数线性关的系检验————数学建模(2)第二次作业一、问题重述:某合成纤维的强度y(N/mm2)与其拉伸倍数x有关,现测得试验数据如下表(1):某合成纤维的强度y与其拉伸倍数x试验数据表表(1)1.检验y和x之间是否存在显著的线性相关关系。
2.若存在,求y关于x的线性回归方程:y i=a+b x i。
二、求解过程1.强度yi关于拉伸倍数xi的散点图如下图(1):图(1)2.样本相关系数计算 (1).计算公式r =nΣxy −ΣxΣynΣx 22nΣy 22(2)计算结果r =12∗382.17−3771.3612∗428.18−64.802∗ 12∗342.86−58.202=0.9859(3)结果分析r >0.8,说明该合成纤维强度y 与拉伸倍数x 成高度线性正相关关系。
2. 回归方程求解 (1).计算公式β1 =n ∑x i y i n i =1− ∑X i n i =1 ∑y i ni =1n x i2ni =1−∑x i n i =12某纤维强度y 关于拉伸倍数x 的散点图拉伸倍数x强度yβ 0=y −β1x (2).计算结果β 1= 12∗382.17−3771.3612∗428.18−64.802=0.8675β0=4.85−0.8675∗5.40=0.1655 (3).回归方程y i =0.1655+0.8675xi (4).回归前后图像对比图(2)回归系数β1=0.8675,表示拉伸倍数每增加一倍,该合成纤维强度增加0.08675。
三、 线性关系检验(1).提出假设123456789101112该纤维强度y 关于拉伸倍数x 的散点图及其线性回归方程拉伸倍数x强度yH0:β1=0线性关系不显著(2).计算检验统计量FF=SSR/1SSE/(n−2)= MSRMSE~F(1,n-2)F =58.89505/11.695902/(12−2)=347.2786(3).显著性水平α=0.05,根据分子自由度1和分母自由度12-2找出临界值Fα=4.965(4).F>Fα,拒绝H0,线性关系显著。
数模第二次作业

数模第二次作业姓名杜永志学号 ********学院理学院1.人员安排某公司的营业时间是上午8 点到22 点,以2 小时为一个时段,共7 个时段,各时段内所需的服务人员人数从早至晚分别为20,25,10,30,20,10,5,每个服务人员可在任一时段开始上班,但要连续工作8 小时,而工资相同,问应如何安排服务人员使公司所付工资总数最少,建立此问题的数学模型。
2、生产裸铜线和塑包线的工艺如下所示:1)拉丝机→裸铜线;2)拉丝机→塑包机→塑包线;3)联合机→塑包线某厂现有I型拉丝机和塑包机各一台,生产两种规格的裸铜线和相应达到两种规格的塑包线,没有联合机。
由于市场需求扩大和现有塑包机设备陈旧,计划新增II型拉丝机或联合机(每种设备最多1台),或改造塑包机,每种设备选用方案及相关数据如下:已知市场对两种规格裸铜线的需求量分别为3000km和2000km,对两种规格塑包线的需求分别为10000km和8000km。
按照规定,新购及改进设备按每年5%提取折旧费,老设备不提;每台机器每年最多只能工作8000小时。
为了满足需求,确定使费用最小的设备选用方案和生产计划。
(只建立规划模型,不必求解)1解:设xi(i=1、2、3、4、5、6、7)为第i个时间段开始工作的员工数优化目标min x1+x2+x3+x4+x5+x6+x7约束条件(1)x1≥20(2)x1+x2≥25(3)x1+x2+x3≥10(4)x1+x2+x3+x4≥30(5)x2+x3+x4+x5≥20(6)x3+x4+x5+x6≥10(7)x4+x5+x6+x7≥5(8)xi为正整数利用lingo软件求解输入:min x1+x2+x3+x4+x5+x6+x7stx1>20x1+x2>25x1+x2+x3>10x1+x2+x3+x4>30x2+x3+x4+x5>20x3+x4+x5+x6>10x4+x5+x6+x7>5endgin 7输出:Global optimal solution found.Objective value: 40.00000Objective bound: 40.00000Infeasibilities: 0.000000Extended solver steps: 0Total solver iterations:Variable Value Reduced CostX1 20.00000 1.000000X2 10.00000 1.000000X3 5.000000 1.000000X4 5.000000 1.000000X5 0.000000 1.000000X6 0.000000 1.000000X7 0.000000 1.000000 即公司安排20个员工第1个时间段开始工作,10个员工第2个时间段开始工作,5个员工第3个时间段开始工作,5个员工第4个时间段开始工作,这样员工数最少,为40人,工资也最少。
(0349)《数学建模》网上作业题及答案

(0349)《数学建模》网上作业题及答案1:第一批次2:第二批次3:第三批次4:第四批次5:第五批次6:第六批次1:[填空题]名词解释13.符号模型14.直观模型15.物理模型16.计算机模拟17.蛛网模型18.群体决策参考答案:13.符号模型:是在一定约束条件或假设下借助于专门的符号、线条等,按一定形式组合起来描述原型。
14.直观模型:指那些供展览用的实物模型以及玩具、照片等,通常是把原型的尺寸按比例缩小或放大,主要追求外观上的逼真。
15.物理模型:主要指科技工作者为一定的目的根据相似原理构造的模型,它不仅可以显示原型的外形或某些特征,而且可以用来进行模拟实验,间接地研究原型的某些规律。
16.计算机模拟:根据实际系统或过程的特性,按照一定的数学规律用计算机程序语言模拟实际运行情况,并依据大量模拟结构对系统或过程进行定量分析。
17.蛛网模型:用需求曲线和供应曲线分析市场经济稳定性的图示法在经济学中称为蛛网模型。
18.群体决策:根据若干人对某些对象的决策结果,综合出这个群体的决策结果的过程称为群体决策。
2:[填空题]名词解释7.直觉8.灵感9.想象力10.洞察力11.类比法12.思维模型参考答案:13.符号模型:是在一定约束条件或假设下借助于专门的符号、线条等,按一定形式组合起来描述原型。
14.直观模型:指那些供展览用的实物模型以及玩具、照片等,通常是把原型的尺寸按比例缩小或放大,主要追求外观上的逼真。
15.物理模型:主要指科技工作者为一定的目的根据相似原理构造的模型,它不仅可以显示原型的外形或某些特征,而且可以用来进行模拟实验,间接地研究原型的某些规律。
16.计算机模拟:根据实际系统或过程的特性,按照一定的数学规律用计算机程序语言模拟实际运行情况,并依据大量模拟结构对系统或过程进行定量分析。
17.蛛网模型:用需求曲线和供应曲线分析市场经济稳定性的图示法在经济学中称为蛛网模型。
18.群体决策:根据若干人对某些对象的决策结果,综合出这个群体的决策结果的过程称为群体决策。
数学建模第二次作业a

数学建模第二次作业a学生:陈耿1.产生一个1x10的随机矩阵,大小位于(-5 5),并且按照从大到小的顺序排列好!解:a=10*rand(1,10)-5;b=sort(a,'descend')b =Columns 1 through 84.5013 3.9130 3.2141 2.6210 1.0684 -0.1402 -0.4353 -0.5530Columns 9 through 10-2.6886 -4.81502.请产生一个100*5的矩阵,矩阵的每一行都是[1 2 3 4 5] repmat(1:5,100,1)ans = 1 2 3 4 51 2 3 4 51 2 3 4 51 2 3 4 51 2 3 4 51 2 3 4 51 2 3 4 51 2 3 4 51 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 51 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 51 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 51 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 51 2 3 4 51 2 3 4 51 2 3 4 53. 已知变量:A='ilovematlab';B=’matlab’, 请找出:(A)B在A中的位置。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4. 根据表1.14 的数据,完成下列数据拟合问题:表 1.14 美国人口统计数据(百万人)年份1790 1800 1810 1820 1830 1840 1850 1860 人口 3.9 5.3 7.2 9.6 12.9 17.1 23.2 31.4年份1870 1880 1890 1900 1910 1920 1930 1940 人口38.6 50.2 62.9 76.0 92.0 106.5 123.2 131.7 年份1950 1960 1970 1980 1990 2000人口150.7 179.3 204.0 226.5 251.4 281.4解答:(1):(i)执行程序:t=1790:10:2000;x=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.2,92.0,106.5,123.2,131.7,150.7,179.3,204 .0,226.5,251.4,281.4];f=@(r,t)3.9.*exp(r(1).*(t-1790));r=nlinfit(t,x,f,0.036)sse=sum((x-f(r,t)).^2)plot(t,x,'k+',1790:10:2000,f(r,1790:10:2000),'k')axis([1790,2000,0,300]),legend('测量值','理论值')xlabel('美国人口/(百万)'),ylabel('年份')title('美国人口指数增长模型图II')运行结果:>> Untitledr =0.0212sse =1.7433e+004即,拟合效果:r =0.0212;误差平方和为:1.7433e+004.拟合效果图(i):(ii)由表1.14我们知道,当t=1800时,有5)101(0≈+r x ,所以我们可以猜测,r=0.1,x =2.5.对待定参数0x ,r 进行数据拟合同时进行绘图,其程序如下:t=1790:10:2000;x=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.2,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4];f=@(r,t)r(1).*exp(r(2).*(t-1790)); r0=[2.5,0.1]; r=nlinfit(t,x,f,r0) sse=sum((x-f(r,t)).^2)plot(t,x,'k+',1790:1:2000,f(r,1790:1:2000),'k')axis([1790,2000,0,300]),legend('测量值','理论值',2) xlabel('美国人口/(百万)'),ylabel('年份') title('美国人口指数增长模型图II')命令窗口显示的计算的结果如下: >> Untitled r =15.0005 0.0142 sse =2.2657e+003即我们知道,拟合结果为:r=r(2)= 0.0142, 0x =r(1)= 15.0005;误差平方和为:2.2657e+003. 拟合效果图(ii ):(iii)由表1.14我们知道,当t=1900时,有()76)-t 1900101(00≈+r x ,所以我们可以猜测,r=0.03,x =19, 0t =1800.对待定参数0t ,0x ,r 进行数据拟合同时进行绘图,其程序如下:t=1790:10:2000;x=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.2,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4];f=@(r,t)r(1).*exp(r(2).*(t-r(3))); r0=[19,0.03,1800]; r=nlinfit(t,x,f,r0) sse=sum((x-f(r,t)).^2)plot(t,x,'k+',1790:1:2000,f(r,1790:1:2000),'k')axis([1790,2000,0,300]),legend('测量值','理论值',2) xlabel('美国人口/(百万)'),ylabel('年份') title('美国人口指数增长模型图III')命令窗口显示的计算的结果如下:>> UntitledWarning: The Jacobian at the solution is ill-conditioned, and some model parameters may not be estimated well (they are not identifiable). Use caution in making predictions. > In nlinfit at 224 In Untitled at 5 r =1.0e+003 *0.0159 0.0000 1.7939 sse =2.2657e+003即,拟合效果:r =0,0x =7.9,0t =1742.5;误差平方和为:2.2657e+003我们由MATLAB9给出的警告信息,知道这个拟合存在病态条件,所以数据可能拟合的不太好。
拟合效果图(iii ):综上,经分析我们应该(ii)才是这个问题的最好的拟合方案,因为(i )和另两个比较他的误差平方和最大,而(iii )则存在不正常的条件,所以这三个中,(ii)是这个问题的最好的拟合方案。
他的增长模型为:x(t)= 15.0005.*exp(0.0142.*(t-1790)).其拟合效果图如下:(2)对指数增长模型x(t)= 0x .*exp(r.*(t-0t ))两边求导数得:ln(x(t))=ln(0x )+r.*(t-0t ) 我们固定0t =1790再令ln(x(t))=y, ln(0x )=b(0),r=b(1), t-1790=x,于是原变式为:y=b(0)+b(1).*x. 转化成线性模型级拟合效果图的MATLAB 命令如下:t=[1790:10:2000]c=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.2,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4];x=t-1790;y=log(c);a=polyfit(x,y,1),x0=exp(a(2)),r=a(1)f=@(k,t)k(1).*exp(k(2).*(t-k(3)));k=[x0,r,1790];sse=sum((c-f(k,t)).^2)plot(-20:1:230,polyval(a,-20:1:230),'r',t-1790,log(c),'k+'),legen d('理论值','测量值',2)窗口计算结果为:a =0.0202 1.7993x0 =6.0456r =0.0202sse =3.4928e+004所以拟合的结果为:x0 =6.0456,r =0.0202;误差平方和为:3.4928e+004。
拟合效果图如下:(3)指数增长模型线性化拟合得误差平方和比非线性拟合大得多,拟合误差比较图的MATLAB命令如下:f=@(r,t)r(1).*exp(r(2).*(t-1790));t=1790:10:2000;c=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.2,92.0,106.5,123.2,131.7,150.7,179.3,204 .0,226.5,251.4,281.4];x=c-f([14.9940,0.0142],t);y=c-f([6.045,0.0202],t);plot(c,x,'ro',c,y,'b+',0:.1:300,0,'k+'),legend('非线性拟合','线性拟合')axis([0,300,-160,40]),xlabel('美国人口(百万)'),ylabel('拟合误差'),title('指数增长模型的拟合误差比较图')图如下:我们从这个拟合误差比较图可以看出,非线性拟合的误差比较稳定,而线性拟合的误差却人口的增长越来越大。
出现这种情况的原因的当x(t)数值越大时,y 的对数带来的损失越大,使得线性拟合的误差越大。
(4)(i )由题目给的表知道,当t=1870时,有393.9-N 3.9 3.9N)17901870(≈+--r e )(,所以我们可以猜测N=40,r=7229.我们拟合待定参数r ,N 绘制拟合效果图的Matlab 命令如下: f=@(h,t)3.9.*h(1)./(3.9+(h(1)-3.9).*exp(-h(2).*(t-1790))); t=1790:10:2000;c=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.2,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4]; h0=[40,9/722]; h=nlinfit(t,c,f,h0)sse=sum((c-f(h,t)).^2),N=h(1),r=h(2)plot(t,c,'b+',1780:.01:2010,f(h,1780:.01:2010),'k'),legend('测量值','理论值',2) axis([1780,2010,0,300])xlabel('美国人口/(百万)'),ylabel('年份') title('美国人口指数增长模型图')命令窗口显示的计算结果: >> Untitled1 h =342.3524 0.0274sse =1.2294e+003 N =342.3524 r =0.0274 >>故,N= 342.3524,r=0.0274;误差平方和是:1.2294e+003。