第八章 卡方检验与交互分析
卡方检验的原理和步骤

卡方检验的原理和步骤卡方检验(Chi-squared test)是一种用于统计学中的假设检验方法,主要用于检验两个或更多个分类变量之间是否存在相关性。
它的原理和步骤可以概括如下:原理:卡方检验是基于卡方统计量的方法,卡方统计量是通过计算实际观察值与期望理论值之间的差异来判断变量间是否存在相关性。
具体来说,卡方统计量是通过计算每个观察值与对应期望值之间的差异平方的总和来衡量的。
如果差异较小,说明实际观察值与期望值之间较为接近,两个变量间可能不存在相关性;如果差异较大,则说明实际观察值与期望值之间存在较大差异,两个变量间可能存在相关性。
步骤:1.建立假设:在进行卡方检验之前,需要明确两个变量之间的假设。
通常有两种假设:原假设(H0)和备择假设(Ha)。
原假设是指两个变量之间没有相关性,备择假设是指两个变量之间存在相关性。
2.构建列联表:列联表(Contingency table)是用来统计两个或多个分类变量的交叉频次分布的表格。
在卡方检验中,我们需要根据实际观察数据构建列联表。
3.计算期望值:在卡方检验中,我们需要计算期望理论值。
期望理论值是指如果两个变量之间不存在相关性,那么我们可以根据边际总计与变量间的分布来计算出的预期频次。
一般情况下,期望理论值可以通过边际总计和整体频率来计算。
4.计算卡方统计量:在有了观察值和期望理论值后,我们可以通过计算卡方统计量来判断两个变量之间是否存在相关性。
卡方统计量的计算公式为:χ2=∑((O-E)^2/E),其中χ2为卡方统计量,O为观察值,E为期望理论值。
计算出卡方统计量后,可以根据自由度去查找对应的临界值。
5.决策:根据卡方统计量的计算结果,我们可以通过比较卡方统计量与对应自由度的临界值来进行决策。
如果卡方统计量小于临界值,则接受原假设,即认为两个变量之间没有相关性;如果卡方统计量大于临界值,则拒绝原假设,即认为两个变量之间存在相关性。
6.结论:最后,根据决策结果,我们可以得出结论,即两个变量之间是否存在相关性。
生物统计学课件ch8考虑交互作用的实验设计

.012 .092 -.003 .044 .870 0 .870
Std. Error Sig. 95% Confidence Interval for Difference a. Reference category =3
Lower Bound Upper Bound
.012 .000 .846 .893
Std. Error Sig. 95% Confidence Lower Bound Interval for Upper Bound Level 2 vs. Level 3 Difference Contrast Estimate Hypothesized Value Difference (Estimate - Hypothesized)
Model: Full factorial
Tests of Between-Subj ects Effects Dep enden tV ariable: 丝裂霉素浓度 Type III Sum Source of Squares df Corrected Model 45.899a 11 Intercept 23.622 1 drug 5.026 1 time 9.855 2 organ 4.660 1 drug * time 4.847 2 drug * organ 9.843 1 time * organ 5.791 2 drug * time * organ 5.876 2 Error .066 48 Total 69.586 60 Corrected Total 45.964 59 a. R Squared = .999 (Adjusted R Squared = .998)
不考虑交互作用的实验设计:
1.完全随机设计的ANOVA
卡方检验及交互分析-Excel计算实例
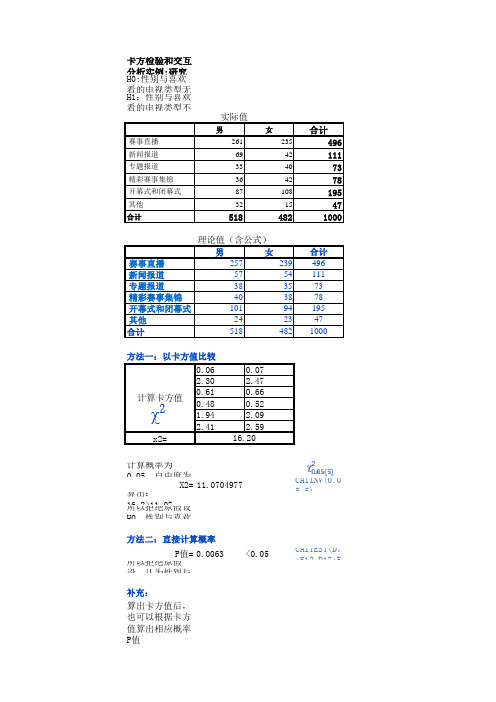
0.07 2.47 0.66 0.52 2.09 2.59 16.20
计算概率为
0.05,自由度为
算出:
X2= 11.0704977
1所6以.2拒>1绝1.原07假设
H0,性别与喜欢
方法二:直接计算概率
P值= 0.0063 所以拒绝原假 设,认为性别与
<0.05
补充:
算出卡方值后, 也可以根据卡方 值算出相应概率 P值
1000
理论值(含公式)
男
女
赛事直播
257
239
新闻报道
57
54
专题报道
38
35
精彩赛事集锦
40
38
开幕式和闭幕式
101
94
其他
24
23
合计
Hale Waihona Puke 518482合计 496 111 73 78 195 47 1000
方法一:以卡方值比较
计算卡方值
0.06 2.30 0.61 0.48 1.94
2.41
x2=
卡方检验和交互 分析实例:研究 H0:性别与喜欢 看的电视类型无 H1:性别与喜欢 看的电视类型不
赛事直播 新闻报道 专题报道 精彩赛事集锦 开幕式和闭幕式 其他 合计
实际值
男 261 69 33 36 87 32
518
女 235 42 40 42 108 15
482
合计 496 111 73 78 195 47
CHIINV(0.0 5,5)
CHITEST(D7 :E12,D17:E
P值=
0.0063
CHIDIST(16 .2,5)
第八章卡方检验ppt课件

2 (A T )2
T
2
(ad bc)2 n
(a b)(c d)(a c)(b d)
当n ≥40 ,且某格子出现1≤ T<5时,用校正公式:
2 ( A T 0.5)2 T
( ad bc n)2 n
2
2
(a b)(c d )(a c)(b d )
如果样本例数不是很大,计算时应先估计表中最小的T值。
17
设有k个相互独立的标准正态分布随机变量Z1、Z2…..Zν ,则Z12+Z22+…+Zν2的分 布服从自由度为ν的x2分布,记为x2(v)。 ν是指上式中包含的独立变量的个数。
当ν趋于∞时, x2分布逼近正态分布。各种自由度的x2分布右侧尾部面积为α时 的临界值记为x2(α,v)
=1 =2
=3 =4
组对象其它方面“同质”的前提下才能比较两个频率,才能进行2×2列联表 的x2检验。
26
小结
1、2检验的基本思想
2、四格表资料2检验,通常规定: (1) n ≥ 40,且T ≥ 5时,用2 检验基本公式和专用公式 (2) n ≥ 40,但有1≤ T<5时,用四格表2检验校正公式 (3) n< 40,或T<1时,改用fisher确切概率法 (4)连续性校正仅用于ν=1的四格表资料。
表 8-6 儿童急性白血病患者与成年人急性白血病患者的血型分布
分组 A 型 B 型 O 型 AB 型
合计
儿童 30 38 32 12
112
成人
19 30 19
9
77
合计 49 68 51 21
2 0.005,2
10.60
32.74 2
2
• 认为因三而种P<药0物.0的05治,在疗α效=0果.05不水全准相上同拒。绝H0.00,05接,2受H1,差别有统计学意义。可以
第八章卡方检验与交互分析

第八章卡方检验与交互分析交互分析是社会调查研究中常用方法之一,用于研究两个定类变量的关系。
交互分析中用于检验两个变量是否相关的方法叫做卡方检验,也叫独立性检验。
卡方检验是建立在观测频次和期望频次之差基础上的一种检验。
一、卡方检验的原理例:一项调查得到890个样本的与收入和所处地区的数据,希望分析收入和地区的关系。
表1要检验的H0:收入和地区之间没有相关性,即每一地区的收入分布模式应该是相同的,收入的高低不应随着地区的不同而有所差异。
也就是说,如果东部城市的四个收入类别各自比重和中西北部城市的四个收入类别各自比重一致,那么,收入和地区之间是相互独立的。
如果这个890人的样本能够反应总体的独立性特征,那么就应该能够观测到两个地区具有相同的收入分布模式,称为期望模式,样本的期望观测频次如下:表2接下来,计算观测频次f0与期望频次f e之间的偏差(f0-f e),如果这些偏差比较小,则有利于证明原假设即总体的独立性。
反之,则可能推翻原假设。
但偏差之和为0,所以对偏差进行平方。
但是,为了说明每一个偏差的相对重要性,每一偏差平方和都需要和本组中的期望频次相比较,计算相对(f0-f e)2/f e。
然后,将所有组的贡献相加,从而得到度量全部偏差的一个量,叫做卡方χ2=∑∑(fo−fe)2,fe服从自由度为(c-1)(r-1)的卡方分布。
如用c 和r 分别表示表中的列数和行数,自由度为(c-1)(r-1)。
f 0 f e(f 0-f e )(f 0-f e )2/f e计算出卡方值后,可根据已知的显著性水平和自由度查卡方分布表,找出临界值,与之作对比。
反过来,也可以计算出概值,再根据我们所希望的显著性水平做比较。
该例题中计算出χ2为31.6,查表发现对应自由度为3的那一行的所有临界值都小于χ2,因此,概值小于0.001。
由于概值如此小,检验水平可以是1%甚至更小,所以一定可以拒绝原假设。
也就是说,在总人口中,收入与地区有显著的相关性,二者并不独立。
卡方检验的原理和使用

卡方检验的原理和使用卡方检验(Chi-Square Test)是一种常用的统计方法,用于检验两个或多个分类变量之间是否存在相关性。
它的原理基于统计学中的卡方分布,通过比较实际观测值与期望理论值之间的差异来判断变量之间的关联性。
在实际应用中,卡方检验被广泛用于医学、社会科学、市场调研等领域,帮助研究人员验证假设、分析数据,从而做出科学的决策。
一、卡方检验的原理卡方检验的原理基于卡方分布,其核心思想是通过比较实际观测值与期望理论值之间的差异来判断变量之间是否存在相关性。
在进行卡方检验时,首先需要建立零假设(H0)和备择假设(H1)。
零假设通常是假定两个变量之间不存在相关性,备择假设则是假定两个变量之间存在相关性。
卡方检验的步骤如下:1. 收集数据并建立列联表:将研究对象按照不同的分类变量进行分组,并统计各组的频数,建立列联表。
2. 计算期望频数:根据总体频数和各组的比例计算期望频数,即在零假设成立的情况下,每个组的理论频数。
3. 计算卡方值:通过比较实际观测频数与期望频数的差异,计算得到卡方值。
4. 确定显著性水平:根据卡方分布表确定显著性水平,一般取0.05。
5. 比较卡方值与临界值:如果计算得到的卡方值大于临界值,则拒绝零假设,认为两个变量之间存在相关性;反之,则接受零假设。
二、卡方检验的使用卡方检验在实际应用中具有广泛的用途,主要包括以下几个方面: 1. 分类变量相关性检验:用于检验两个或多个分类变量之间是否存在相关性,例如性别与偏好、教育程度与收入水平等。
2. 拟合优度检验:用于检验观测频数与期望频数之间的拟合程度,例如检验实际抽样数据是否符合某种理论分布。
3. 独立性检验:用于检验两个分类变量之间是否独立,例如检验药物治疗对疾病痊愈的影响是否独立于患者的年龄。
4. 方差分析:在多组分类变量比较中,可以使用卡方检验进行方差分析,判断不同组别之间的差异是否显著。
在使用卡方检验时,需要注意以下几点:1. 样本量要足够大:样本量过小会影响检验结果的可靠性,一般要求每个单元格的期望频数不低于5。
统计学中的卡方检验

统计学中的卡方检验卡方检验是一种常用的统计学方法,用于判断两个或多个变量之间是否存在显著性差异。
本文将介绍卡方检验的原理、应用场景以及实际操作步骤。
一、卡方检验原理卡方检验基于观察数据与理论数据之间的差异来判断变量之间的相关性。
它通过计算卡方值来衡量观察值与理论值之间的偏离程度,进而判断差异是否具有统计学意义。
二、卡方检验的应用场景卡方检验广泛应用于以下几个方面:1. 样本观察与理论值比较:用于比较观察数据与理论数据之间的差异,例如检验一个硬币是否是公平的。
2. 不同群体之间的差异性:用于比较不同群体之间某一属性的差异,例如男性和女性在某一疾病患病率上是否存在显著性差异。
3. 假设检验:用于判断两个或多个变量之间是否存在显著性关联,例如是否存在两个变量之间的相关性。
三、卡方检验的基本思路卡方检验的基本思路是建立原假设和备择假设,通过计算卡方值和查表得到结果。
具体步骤如下:1. 建立假设:设立原假设H0和备择假设H1。
原假设通常假定两个变量之间不存在显著性关联,备择假设则相反。
2. 构建列联表:将观察数据按照行和列分别分类计数,得到列联表。
3. 计算期望频数:根据原假设计算每个单元格的期望频数,即在假设成立的条件下,各个单元格的理论频数。
4. 计算卡方值:根据观察频数和期望频数计算卡方值,计算公式为Χ²=∑[(O-E)^2/E],其中O为观察频数,E为期望频数。
5. 查找临界值:根据自由度和显著性水平,在卡方分布表中找到对应的临界值。
6. 判断结果:比较计算得到的卡方值与临界值,若卡方值大于临界值,则拒绝原假设,认为差异具有统计学意义。
四、卡方检验的实例分析假设我们想要研究吸烟和肺癌之间的关系,我们收集了300人的数据,包括是否吸烟和是否患有肺癌的情况。
观察数据如下:吸烟非吸烟总计患有肺癌 80 40 120未患肺癌 100 80 180总计 180 120 300根据这些数据,我们想要判断吸烟与肺癌之间是否存在显著性关联。
卡方检验详述

卡方检验什么是卡方检验卡方检验是一种用途很广的计数资料的假设检验方法。
它属于非参数检验的范畴,主要是比较两个及两个以上样本率( 构成比)以及两个分类变量的关联性分析。
其根本思想就是在于比较理论频数和实际频数的吻合程度或拟合优度问题。
它在分类资料统计推断中的应用,包括:两个率或两个构成比比较的卡方检验;多个率或多个构成比比较的卡方检验以及分类资料的相关分析等。
卡方检验的基本原理卡方检验是以χ2分布为基础的一种常用假设检验方法,它的无效假设H0是:观察频数与期望频数没有差别。
该检验的基本思想是:首先假设H0成立,基于此前提计算出χ2值,它表示观察值与理论值之间的偏离程度。
根据χ2分布及自由度可以确定在H0假设成立的情况下获得当前统计量及更极端情况的概率P。
如果P值很小,说明观察值与理论值偏离程度太大,应当拒绝无效假设,表示比较资料之间有显著差异;否则就不能拒绝无效假设,尚不能认为样本所代表的实际情况和理论假设有差别。
卡方值的计算与意义χ2值表示观察值与理论值之问的偏离程度。
计算这种偏离程度的基本思路如下。
(1)设A代表某个类别的观察频数,E代表基于H0计算出的期望频数,A与E之差称为残差。
(2)显然,残差可以表示某一个类别观察值和理论值的偏离程度,但如果将残差简单相加以表示各类别观察频数与期望频数的差别,则有一定的不足之处。
因为残差有正有负,相加后会彼此抵消,总和仍然为0,为此可以将残差平方后求和。
(3)另一方面,残差大小是一个相对的概念,相对于期望频数为10时,期望频数为20的残差非常大,但相对于期望频数为1 000时20的残差就很小了。
考虑到这一点,人们又将残差平方除以期望频数再求和,以估计观察频数与期望频数的差别。
进行上述操作之后,就得到了常用的χ2统计量,由于它最初是由英国统计学家Karl Pearson在1900年首次提出的,因此也称之为Pearson χ2,其计算公式为:其中,Ai为i水平的观察频数,Ei为i水平的期望频数,n为总频数,pi为i水平的期望频率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第八章卡方检验与交互分析
交互分析是社会调查研究中常用方法之一,用于研究两个定类变量的关系。
交互分析中用于检验两个变量是否相关的方法叫做卡方检验,也叫独立性检验。
卡方检验是建立在观测频次和期望频次之差基础上的一种检验。
一、卡方检验的原理
例:一项调查得到890个样本的与收入和所处地区的数据,希望分析收入和地区的关系。
表1
要检验的H0:收入和地区之间没有相关性,即每一地区的收入分布模式应该是相同的,收入的高低不应随着地区的不同而有所差异。
也就是说,如果东部城市的四个收入类别各自比重和中西北部城市的四个收入类别各自比重一致,那么,收入和地区之间是相互独立的。
如果这个890人的样本能够反应总体的独立性特征,那么就应该能够观测到两个地区具有相同的收入分布模式,称为期望模式,样本的期望观测频次如下:表2
接下来,计算观测频次f0与期望频次f e之间的偏差(f0-f e),如果这些偏差比较小,则有利于证明原假设即总体的独立性。
反之,则可能推翻原假设。
但偏差之和为0,所以对偏差进行平方。
但是,为了说明每一个偏差的相对重要性,每一偏差平方和都需要和本组中的期望频次相比较,计算相对(f0-f e)2/f e。
然后,将所有组的贡献相加,从而得到度量全部偏差的一个量,叫做卡方χ2=∑∑(fo−fe)2
,
fe
服从自由度为(c-1)(r-1)的卡方分布。
如用c 和r 分别表示表中的列数和行数,自由度为(c-1)(r-1)。
f 0 f e
(f 0-f e )
(f 0-f e )2/f e
计算出卡方值后,可根据已知
的显著性
水平和自由度查卡方分布表,找出临界值,与之作对比。
反过来,也可以计算出概值,再根据我们所希望的显著性水平做比较。
该例题中计算出χ2为31.6,查表发现对应自由度为3的那一行的所有临界值都小于χ2,因此,概值小于0.001。
由于概值如此小,检验水平可以是1%甚至更小,所以一定可以拒绝原假设。
也就是说,在总人口中,收入与地区有显著的相关性,二者并不独立。
练习题:在电视的收视率调查中,得到性别与收视习惯的联列表如下,试分析性别和收视习惯的关系。
解:原假设为“性别和收视习惯相互独立”,如果原假设成立,那么两列期望凭此应通过0.69和0.31分别乘以最后一列总频次而得到。
(f 0-f e )
(f0-f e)2/f e
卡方值=4.57。
自由度为(2-1)(2-1)=1。
卡方值大于χ0.052=3.84,所以概值小于0.05。
可以认为在5%的显著性水平下拒绝原假设,认为性别与收视习惯并不是相互独立的。
二、卡方检验的局限性和补救办法
1、卡方值随分类的不同而不同
交互分析将数据按类别整理,分类的不同可改变卡方值,甚至导致相反结果。
在例题中,收入如果分成高、中、低三类,结果必然不同。
因此,在分类时最好有理论(统计上的)依据。
如果没有,则需要有统计上的依据,例如利用中位数,将数据平分两类。
2、样本量不能太小,也不宜过大
样本量应大于30或50,一般调查中都会超过50。
样本量太大,检验结果也可能会失去意义。
因为卡方值受样本量影响很大,样本量越大,越容易得到拒绝原假设的结果。
比如将样本量增大10倍,各种对应关系不变,则卡方值也会增大10倍。
原来的不拒绝结果可能就会变成拒绝原假设的结果。
为了解决这一问题,要采用补救办法,常用的是联列系数C,可以消除样本量的影响,解释变量间真正关系的密切程度。
因此,当卡方检验显著单样本量有很大时,最好参照C值的大小,如果C 值也比较大,才可以拒绝原假设。
遗憾的是,对于C值的显著程度没有可行的统计检验方法,有些学者认为C 值至少要超过0.16,最好达到0.25,才可以考虑两个变量相关。
同时,C值还受到连列表规模影响。
对于2*2的表,C值不会超过0.707,但对于4*6的表,C 值上限可达到0.877。
所以,也有学者建议将C值与其理论上限值作比较,如果接近上限,关系显著。
但后一种方法过于严格,对很多大样本调查,C值都很难达到显著程度。
因此,在统计分析时,应根据问题性质灵活掌握,对于那些要求精密的自然科学来说,概值界定为0.001,而对于一般的社会调查来说,概值小
于0.05或小于0.1就可以认为达到了显著相关了。