EViews统计分析在计量经济学中的应用--第7章-联立方程模型解析
EViews统计分析在计量经济学中的应用EViews概述

5/7/2023
EViews统计分析在计量经济学中的应用
2
2
EViews历史
EViews是由Quantitative Micro Software 〔QMS〕公司开发的,专门从事数据分析、回归 分析和预测的工具。EViews结合了电子表格和 相关的数据库技术以及传统统计软件分析功能, 并且使用了单击图形用户界面。EViews特点是 对于时间序列数据有较强的分析能力,另外在 预测分析、科学数据分析与评价、金融分析、 经济预测、销售预测和本钱分析等领域应用非 常广泛。
5/7/2023
EViews统计分析在计量经济学中的应用
22 22
图形操作
将图形插入文献中:Eviews可以将图形插入到 Word文档中。首先将图形翻开,然后点击 Eviews主画面顶部主按钮Edit/Copy/click弹出 对话框。选择〞Copy to clipboard〞,点击 OK,然后在Word文档中指指定位置粘贴即可。
EViews统计分析在计量经 济学中的应用EViews概述
1
:EViews简介
o 实验目的:熟悉和掌握Eviews在一元线性回 归模型中的应用。
o 实验数据:2019年中国各地区城市居民人均 年消费支出〔CS〕和可支配收入〔INC〕 〔相关数据在文件夹“书中资料/第3章〞〕 。
o 实验原理:普通最小二乘法(OLS) o 实验预习知识:普通最小二乘法、t检验、
可翻开下拉式菜单〔或再下
一级菜单,如果有的话〕,
点击某个选项电脑就执行对 应的操作响应〔File,Edit的 编辑功能与Word, Excel中的 相应功能相似〕
图1-1 EViews主窗口界面
5/7/2023
计量经济学之联立方程模型

计量经济学之联立方程模型引言联立方程模型(Simultaneous Equation Model,简称SEM)是计量经济学中的一个重要分析工具,用于研究多个经济变量之间的相互关系。
通过建立一组方程,可以理解变量之间的联动效应,并进行预测和政策分析。
本文将介绍联立方程模型的基本概念、建模步骤和常见的估计方法等内容。
基本概念联立方程模型的定义联立方程模型是指由多个方程组成的一种数学模型,用于描述多个经济变量之间的关系。
每个方程都包含一个因变量和若干个解释变量,以及一个误差项。
联立方程模型的核心思想是通过解方程组,得到各个变量的估计值,进而分析它们之间的关系。
基本假设在建立联立方程模型时,需要对变量之间的关系进行假设。
常见的基本假设有:1.线性关系假设:方程中的变量之间的关系是线性的。
2.独立性假设:各个方程中的误差项是独立的,即它们之间不存在相关性。
3.零条件均值假设:解释变量的条件均值为零,即解释变量的期望与误差项无关。
4.同方差假设:各个方程中的误差项方差相等。
建模步骤建立联立方程模型的步骤如下:步骤一:确定变量根据研究主题和数据可获得的变量,确定需要建立模型的变量集合。
步骤二:构建方程根据经济理论和实际问题,构建联立方程模型的方程形式。
每个方程包含一个因变量和若干个解释变量。
步骤三:参数估计通过收集数据,对联立方程模型进行参数估计。
常用的估计方法有最小二乘估计(Ordinary Least Squares,简称OLS)和广义矩估计(Generalized Method of Moments,简称GMM)等。
步骤四:模型诊断对估计得到的模型进行诊断,检验模型的拟合优度、参数显著性和误差项的假设等。
常见的诊断方法有虚拟变量检验、异方差性检验和序列相关性检验等。
步骤五:模型解释与政策分析根据估计得到的模型结果,解释各个变量之间的关系,并进行政策分析。
可以利用模型进行预测和模拟,评估不同政策对经济变量的影响。
eviews使用简单讲解
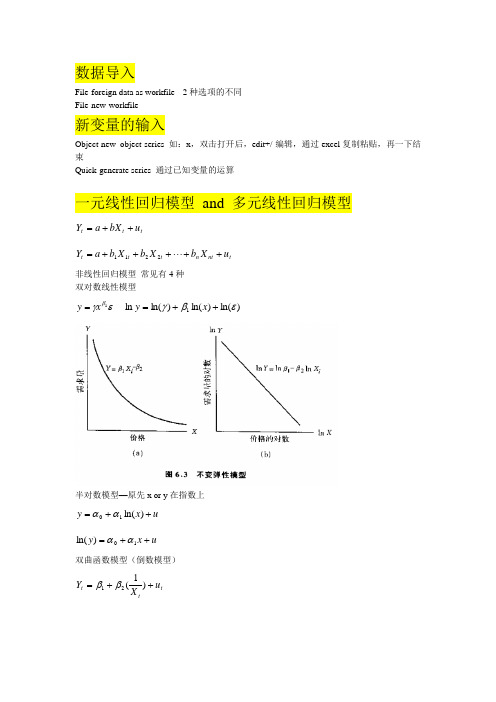
数据导入File-foreign data as workfile --2种选项的不同 File-new-workfile新变量的输入Object-new object-series 如:x ,双击打开后,edit+/-编辑,通过excel 复制粘贴,再一下结束Quick-generate series 通过已知变量的运算一元线性回归模型 and 多元线性回归模型t t t u bX a Y ++=t nt n t t t u X b X b X b a Y +++++= 2211非线性回归模型 常见有4种 双对数线性模型εγβ1x y = )ln()ln()ln(ln 1εβγ++=x y半对数模型—原先x or y 在指数上u x y ++=)ln(10αα u x y ++=10)ln(αα双曲函数模型(倒数模型)t tt u X Y ++=)1(21ββ多项式回归模型u x x x y n n +++++=ββββ 2210非线性回归模型,先用变量替换成为线性(一元or 多元)回归模型,然后做法相同。
虚拟变量模型⎩⎨⎧=另一种状态一种状态10t D eg ⎩⎨⎧=,男性女性1,0t D 研究定性变量的时候引入,比如说性别、种族、宗教、民族、婚姻状况、教育程度等。
一般的,定性变量有m 类,引入m-1个虚拟变量。
分布滞后模型t n t n t t t u x x x y +++++=--ββββ 1210对于时间序列数据,由于经济系统中的经济政策的传导、经济行为的相互影响和渗透都是需要一定时间的。
他们的数值是由某些滞后量决定的。
Eg 消费不仅取决于当期的收入,还取决于以前的收入。
先做图观察一下大体趋势,是否要取对数等。
Quick-graph 建立模型Quick-estimation equation 选择LS 变量第一个是因变量,常数项输入c 注:log (x )表示对x 取自然对数x (-1) 表示滞后一阶 ;x (-1 to -4)表示x (-1)、x (-2)、x (-3)、x (-4)其实,更方便快捷的是用execl进行普通的回归模型工具-加载宏-分析数据库and 分析数据库-vba函数工具-数据分析获取新变量“=”虚拟变量,简单编程eg:=IF(E2>400000,1,0)时间序列分析在处理有关时间序列的数据的时候,首先画图,看看是否需要季节调整Eg 冰激凌销售的例子。
eviews实验报告联立方程模型

Eviews实验报告——联立方程模型一.选题单方程计量经济学模型,是用单一方程描述单一经济变量与影响该变量变化的诸因素之间的数量关系,它适用于单一经济现象的研究。
但是,经济现象是极为复杂的,其中诸因素之间的关系在很多情况下是不能用单一方程描述的。
这时,就必须用一组方程才能描述清楚,即联立方程。
二.模型介绍以一个由国内生产总值(Y)、居民消费总额(C)、投资总额(I)和政府消费额(G)等变量构成的简单的宏观经济为例建立一个联立方程模型,模型如下:消费方程C t = α0 + α1Y t + α2C t-1+ u1t投资方程I t = β0 + β1 Y t + u2t收入方程Y t = C t + I t + G t第一个方程表示居民消费总额由国内生产总值和前一期的消费总额共同决定;第二个方程表示投资总额由国内生产总值决定;第三个方程表示国内生产总值由居民消费总额、投资总额和政府消费额共同决定。
三.数据来源Y I C G2166674778682996814769911259874945565222145596394402该数据取自于1988——2007年中,国内生产总值、居民消费总额、投资总额和政府消费额的数值,具体数值见上表。
四.结果分析首先输入数据;输入数据后,点击“object”下拉菜单下的“new object”选项,显示结果如下:选择“system”,再单击ok,出现系统窗口,再窗口中输入联立方程模型关系式,如下图所示:单击“estimate”,在“method”下拉菜单里选择“ordinary least squares”,然后点击ok,结果显示如下图:由上图可知,系数c(1)——c(5)的数值分别为、、、、,最后一项prob的伴随概率均小于,所以估计结果均有效。
再看两个方程的拟合效果,两个方程的拟合值均接近于1,所以拟合效果较好,方程估计有效。
根据以后分析,可以整理出如下表达式:消费方程:C t = + Y t + C t-1+ u1t投资方程:I t = + Y t + u2t收入方程;Y t = C t + I t + G t。
计量经济学 —理论方法EVIEWS应用--第七章 序列相关性

在其他假设仍然成立的条件下,随机干扰项序列相关意味着
(7-2)
如果仅存在
E ( ) 0 , i 1 , 2 , . . . , n i i 1
(7-3)
则称为一阶序列相关或自相关(简写为AR(1)),这是常见的一种序列相关问题。
D .W .
不存在一阶自相关,构造如下统计量: t
t
( eˆ
t2
n
ˆt 1 ) 2 e
2 t
eˆ
t 1
n
杜宾—沃森证明该统计量的分布与出现在给定样本中的X值有复杂的关系,
其准确的抽样或概率分布很难得到;
因为D.W.值要从
eˆ t 中算出,而 eˆ t
又依赖于给定的X的值。
2 χ 因此D-W检验不同于t、F或 检验,它没有唯一的临界值可以导出拒绝或
用OLS法估计序列相关的模型得到的随机误差项的方差不仅是 有偏的,而且这一偏误也将传递到用OLS方法得到的参数估计 量的方差中来,从而使得建立在OLS参数估计量方差基础上的 变量显著性检验失去意义。
以一元回归模型为例,
Y X i 0 1 i i
2
ˆ) Var ( 1 2 xt
序列相关性及其产生原因序列相关性的影响序列相关性的检验序列相关的补救第一节序列相关性及其产生原因序列相关性的含义对于多元线性回归模型71在其他假设仍然成立的条件下随机干扰项序列相关意味着如果仅存在则称为一阶序列相关或自相关简写为ar1这是常见的一种序列相关问题
—理论· 方法· EViews应用
郭存芝 杜延军 李春吉 编著
二、回归检验法
, eˆ, 以 e ˆ t 为解释变量,以各种可能的相关变量,诸如 t1
面板数据的联立方程模型在eviews中估计的详细图解
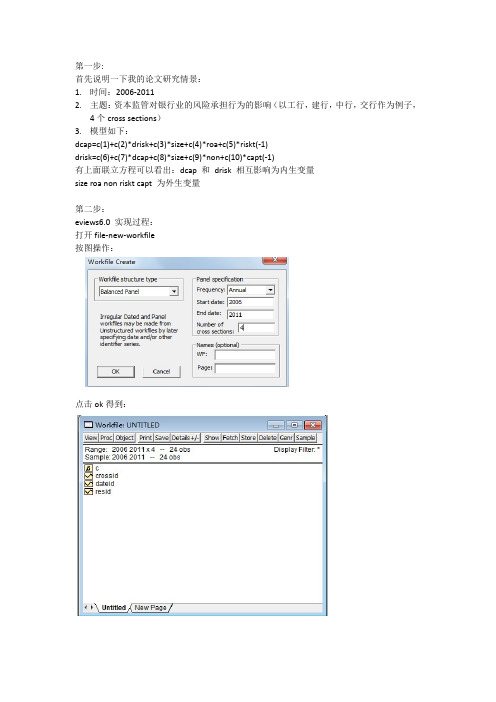
第一步:首先说明一下我的论文研究情景:1.时间:2006-20112.主题:资本监管对银行业的风险承担行为的影响(以工行,建行,中行,交行作为例子,4个cross sections)3.模型如下:dcap=c(1)+c(2)*drisk+c(3)*size+c(4)*roa+c(5)*riskt(-1)drisk=c(6)+c(7)*dcap+c(8)*size+c(9)*non+c(10)*capt(-1)有上面联立方程可以看出:dcap 和drisk 相互影响为内生变量size roa non riskt capt 为外生变量第二步:eviews6.0 实现过程:打开file-new-workfile按图操作:点击ok得到:点击object-new objectType选pool,ok:跳出的横框:Cross Section Identifiers 填入数据变量名称:(这是纵轴的)GSYHJSYHZGYHJTYH(前面提及的四大银行)然后点view-spreadsheet(stacked data)series list小框输入(这是横轴的变量名称)dcap drisk size roa non riskt capt点击edit+/- 手动输入数据或用import导入数据或粘贴复制进去也行:此时点object-new object,这次type选择system 用以联立方程分析:在system框内输入联立方程和工具变量:dcap=c(1)+c(2)*drisk+c(3)*size+c(4)*roa+c(5)*riskt(-1)drisk=c(6)+c(7)*dcap+c(8)*size+c(9)*non+c(10)*capt(-1)inst dcap drisk size roa non riskt(-1) capt(-1)点右上方的estimate,method选择TSLS(两阶段最小二乘估计):整个过程就是先建立workfile再建立panel data最后建立联立方程systemTSLS估计即可。
面板数据的联立方程模型在eviews中估计的详细图解
第一步:首先说明一下我的论文研究情景:1.时间:2006-20112.主题:资本监管对银行业的风险承担行为的影响(以工行,建行,中行,交行作为例子,4个cross sections)3.模型如下:dcap=c(1)+c(2)*drisk+c(3)*size+c(4)*roa+c(5)*riskt(-1)drisk=c(6)+c(7)*dcap+c(8)*size+c(9)*non+c(10)*capt(-1)有上面联立方程可以看出:dcap 和drisk 相互影响为内生变量size roa non riskt capt 为外生变量第二步:eviews6.0 实现过程:打开file-new-workfile按图操作:点击ok得到:点击object-new objectType选pool,ok:跳出的横框:Cross Section Identifiers 填入数据变量名称:(这是纵轴的)GSYHJSYHZGYHJTYH(前面提及的四大银行)然后点view-spreadsheet(stacked data)series list小框输入(这是横轴的变量名称)dcap drisk size roa non riskt capt点击edit+/- 手动输入数据或用import导入数据或粘贴复制进去也行:此时点object-new object,这次type选择system 用以联立方程分析:在system框内输入联立方程和工具变量:dcap=c(1)+c(2)*drisk+c(3)*size+c(4)*roa+c(5)*riskt(-1)drisk=c(6)+c(7)*dcap+c(8)*size+c(9)*non+c(10)*capt(-1)inst dcap drisk size roa non riskt(-1) capt(-1)点右上方的estimate,method选择TSLS(两阶段最小二乘估计):整个过程就是先建立workfile再建立panel data最后建立联立方程systemTSLS估计即可。
《计量经济学》eviews实验报告一元线性回归模型详解
《计量经济学》eviews实验报告一元线性回归模型详解《计量经济学》实验报告一元线性回归模型一、实验内容(一)eviews 基本操作(二)1、利用EViews 软件进行如下操作:(1)EViews 软件的启动(2)数据的输入、编辑(3)图形分析与描述统计分析(4)数据文件的存贮、调用2、查找2000-2014年涉及主要数据建立中国消费函数模型中国国民收入与居民消费水平:表1年份X(GDP)Y(社会消费品总量)2000 99776.3 39105.72001 110270.4 43055.42002 121002.0 48135.92003 136564.6 52516.32004 160714.4 59501.02005 185895.8 68352.62006 217656.6 79145.22007 268019.4 93571.62008 316751.7 114830.12009 345629.2 132678.42010 408903.0 156998.42011 484123.5 183918.62012 534123.0 210307.02013 588018.8 242842.82014 635910.0 271896.1数据来源:/doc/0a16214232.html, 二、实验目的1.掌握eviews的基本操作。
2.掌握一元线性回归模型的基本理论,一元线性回归模型的建立、估计、检验及预测的方法,以及相应的EViews软件操作方法。
三、实验步骤(简要写明实验步骤)1、数据的输入、编辑2、图形分析与描述统计分析3、数据文件的存贮、调用4、一元线性回归的过程点击view中的Graph-scatter-中的第三个获得在上方输入ls y c x回车得到下图在上图中view处点击view-中的actual,Fitted,Residual中的第一个得到回归残差打开Resid中的view-descriptive statistics得到残差直方图打开工作文件第二个中的structure将workfiels选中第一个,将右边改为16个之后打开工作文件xy右键双击,open-as grope在回归方程中有Forecast,残差立为yfse,点击ok后自动得到下图在上方空白处输入ls y c s---之后点击proc 中的forcase 根据公式)|(0^0X Y Y E 得到2015估计量四、实验结果及分析(将本问题的回归模型写出,并作出经济意义检验、统计检验)回归模型为:y?=-8373.702+0.4167x经济意义:斜率系数0.4167表示在其他条件保持不变的情况下,GDP收入每增加1亿元,社会消费品零售总额平均增加0.4167亿元。
计量经济学知识点整理:联立方程
联立方程模型一、概念:联立方程模型系统将变量分为内生变量和外生变量两大类。
内生变量:是具有某种概率分布的随机变量,是由模型系统决定的,取值也是由系统决定的,同时也对模型系统产生影响,它会受到随机项的影响。
一般都是经济变量。
每一个内生变量的值都要利用模型中的全部方程才能决定。
外生变量:是不由系统决定的变量,是系统外变量,取值由系统外决定。
一般是确定性变量,或者是具有临界概率分布的随机变量,其参数不是模型系统研究的元素。
外生变量影响系统,但本身不受系统的影响。
外生变量一般是经济变量、条件变量、政策变量、虚变量。
先决变量:外生变量和滞后内生变量注:联立方程模型中有多少个内生变量就必定有多少个方程结构式模型:根据经济理论和行为规律建立的描述经济变量之间直接结构关系的计量经济学方程系统称为结构式模型。
结构方程的正规形式:将一个内生变量表示为其他内生变量、先决变量和随机干扰项的函数形式完备的结构式模型:g 个内生变量、k 个先决变量、g 个结构方程行为方程:描述变量之间经验关系的方程,含有未知的参数和随机扰动项。
例如:凯恩斯收入决定模型中的消费函数制度方程:由法律、制度、政策等制度性规定的经济变量之间的函数关系,如税收方程。
恒等式:定义方程式和平衡方程。
简化式模型:用所有先决变量作为每个内生变量的解释变量所形成的模型。
参数关系体系:描述简化式参数与结构式参数之间的关系。
二、识别方程之间的关系有严格的要求,一个方程模型想要能估计,必须可识别。
∴进行模型的估计之前需要判断模型是否可以识别(即是否能被估计)。
1、识别的基本定义:是否具有确定的统计形式。
注:识别的定义是针对结构方程而言的。
模型中每个需要估计其参数的随机方程都存在识别问题。
如果一个模型中的所有随机方程都是可以识别的,则认为该联立方程模型系统是可以识别的。
反之不识别。
恒等方程由于不存在参数估计问题,所以也不存在识别问题。
但是,在判断随机方程的识别性问题时,应该将恒等方程考虑在内。
eviews 联立方程模型
2、求解模型
选择proc/solve
model,或者选择view/solve option,或者直接点击model01中工具栏上的 solve按钮,便出现对话框 在绝大多数情形下,只需对基本选项进行设 置,其他选项通常可以采用默认方式。
五、联立性检验
如果方程没有联立性,则OLS估计可以得到
GOV 0 1 AID 2 INC 3 POP AID 0 1GOV 2 PS (2) (1)
对于(1),采用工具变量法估计。选择
TSLS,在Instrument list中输入工具变量名, 因为方程(1)为恰好识别,可将(2)中的 外生变量PS作为工具变量,代替原方程中的 内生变量AID。 命令格式: Tsls gov c aid inc pop @ ps inc pop 对于(2),利用两阶段最小二乘法估计方程 式,两阶段最小二乘法是工具变量法的一个 特例
三、系统方法
最为常用的系统估计法有:似无关回归法、
三阶段最小二乘法和广义矩估计法。 例2 承例1,利用三阶段最小二乘法估计方程 (1)和(2)。
首先需要建立一个系统对象。单击EViews主菜单中 的Object/New Object选项,在所弹出对话框的 Type of object列表中选择System(系统对象), 并为所建立的系统对象命名,本例命名为sys01, 然后单击OK按钮。将生成系统对象sys01,并打开 该对象。 在窗口中输入如下文本,以设定联立方程模型各方 程的形式: Gov=c(1)+c(2)*aid+c(3)*inc+c(4)*pop Aid=c(5)+c(6)*gov+c(7)*ps Inst inc pop ps 在上述方程的设定形式中,”inst”所在的行是设置 联立模型估计的工具变量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
10/12/2018
EViews统计分析在计量经济学中的应用
3
7.2: 联立方程的估计方法及比较
实验目的:通过本次实验,掌握方程2SLS估计的 操作方法和估计步骤;掌握利用2SLS估计方法解 决实际问题,对方程估计结果进行合理的解释说明。 实验数据:1991-2011年我国的全国居民消费 (CSt)、国民生产总值(Yt)、投资(It)、政府消 费(Gt)(相关数据在文件夹 ““Material/Chapter 7/Data和 Material/Chapter 7/Workfile””) 。 实验原理:狭义的工具变量法、间接最小二乘法、 二阶段最小二乘法
14
变量输入对话框
图7.5 变量输入对话R框
10/12/2018 EViews统计分析在计量经济学中的应用 15
间接最小二乘法估计结果
图7.6 间接最小二乘法估计结果
10/12/2018 EViews统计分析在计量经济学中的应用 16
参数模型估计量和结构参数估计值
第 章 联立方程模型
7.1 7.2 7.3 7.4 联立方程的识别 联立方程的估计方法及比较 联立方程的检验 习题(略)
10/12/2018
EViews统计分析在计量经济学中的应用
1
7.1:联立方程的识别
7.1.1结构式方程的识别
假设联立方程系统的结构式 BY+ΓZ=μ 中的第i个方程中包含ki个内生 变量和gi个先决变量,系统中的内生变量先决变量的数目仍用k和g比奥斯, 矩阵(B0 , Γ0)表示第i个方程中未包含的变量(包括内生变量和先决变量) 在其他k-1个方程中对应的系统所组成的矩阵。于是,判断第i个结构方程 识别状态的结构式识别条件为 如果rank(B0 , Γ0)< k-1,则第i个结构方程不可识别; 如果rank(B0 , Γ0)= k-1,则第i个结构方程可以识别,并且 如果g-gi=ki-1,则第i个结构方程恰好识别; 如果g-gi>ki-1,则第i个结构方程过度识别。 式中:符号rank()结构方程是否可以识别;后一部分称为阶条件,用以判断结构方 程的恰好识别或过度识别。
10/12/2018 EViews统计分析在计量经济学中的应用 4
实验一:狭义的工具变量法估计消费方程
选取消费方程中未包含的先决变量Gt作为内生 解释变量Y的工具变量; (1)在工作文件主窗口点击quick/estimate equation,选择估计方法TSLS,在equation specification对话框输入消费方程,在instrument list对话框输入工具变量.如7.1所示
10/12/2018
EViews统计分析在计量经济学中的应用
2
7.1:联立方程的识别
7.1.2简化式方程的识别
联立方程系统的简化式识别条件,是根据联立方程系统的简化式结 构参数进行判断的。对于简化模型Y=ΠZ+E,简化式识别条件为 如果rank(Π2)<ki-1,则第i个结构方程不可识别; 如果rank(Π2)=ki-1,则第i个结构方程可以识别;并且 如果g-gi=ki-1,则第i个结构式方程恰好识别; 如果g-gi>ki-1,则第i个结构式方程过度识别。 式中:Π2是简化式参数矩阵Π 中划去第i个结构方程所不包含的内生变量 所对应的行和第i个结构方程中包含的先决变量所对应的列之后,剩下的参 数按原次序组成的矩阵。其他符号、变量的含义与结构式相同。一般也成 该条件的前一部分称为秩条件,用以判断结构方程是否识别;后一部分称 为阶条件,用以判断结构方程的恰好识别或过度识别。
参数模型估计量
得到结构参数的工具变量法估计量:
10/12/2018
EViews统计分析在计量经济学中的应用
8
实验二:间接最小二乘法估计消费方程
消费方程中包含的内生变量的简化方程为:
CSt 10 11CSt 1 12Gt t Yt 21CSt 1 22Gt 2t
参数关系体系为: 11 1 21 2 0
10 0 1 20 0 12 1 22 0
用普通最小二乘法估计第一个简化式:
CSt 10 11CSt 1 12Gt 1t
10/12/2018 EViews统计分析在计量经济学中的应用 9
10/12/2018 EViews统计分析在计量经济学中的应用 11
用普通最小二乘法估计第二个简化式:
Yt 21CSt 1 22Gt 2t
10/12/2018
EViews统计分析在计量经济学中的应用
12
普通最小乘法估计第一个方程结果
图7.4 普通最小乘法估计第一个方程结果
10/12/2018 EViews统计分析在计量经济学中的应用 13
用普通最小二乘法估计第二个简化式
(2)在Equation Estimation 中Specification 内输入“yt c cst(-1) gt”,如图7.5所示,点 击确定,得到如图7.6所示结果
10/12/2018
EViews统计分析在计量经济学中的应用
实验二:间接最小二乘法估计消费方程
(1)在Equation Estimation 中Specification 内输 入“cst c cst(-1) gt”,如图7.3所示,点击确定, 得到如图7.4所示结果。
10/12/2018
EViews统计分析在计量经济学中的应用
10
变量输入对话框
图7.3 变量输入对话框
10/12/2018
EViews统计分析在计量经济学中的应用
5
变量输入对话框
图7.1
10/12/2018
变量输入对话框
6
EViews统计分析在计量经济学中的应用
狭义工具变量法估计结果
(2)点击确定得 到:图7.2
图7.2 狭义工具变量法估计结果
10/12/2018 EViews统计分析在计量经济学中的应用 7