计量经济学精要习题参考答案(第四版)
计量经济学(第四版)第三章练习题及答案
第三章练习题及参考解答3.1进入21世纪后,中国的家用汽车增长很快。
家用汽车的拥有量受到经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。
为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量,2016年全国各省市区的有关数据如表3.5。
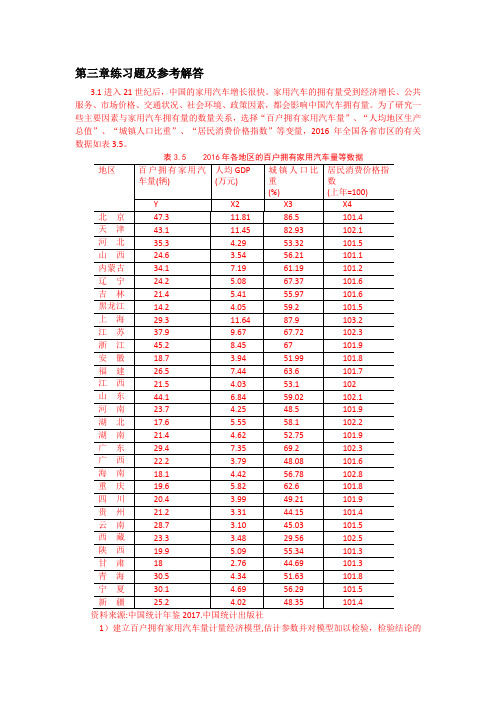
表3.5 2016年各地区的百户拥有家用汽车量等数据资料来源:中国统计年鉴2017.中国统计出版社1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型加以检验,检验结论的依据是什么?。
2)分析模型参数估计结果的经济意义,你如何解读模型估计检验的结果? 3) 你认为模型还可以如何改进?【练习题3.1 参考解答】:1)建立线性回归模型: 1223344t t t t t Y X X X u ββββ=++++ 回归结果如下:由F 统计量为14.69998, P 值为0.000007,可判断模型整体上显著, “人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量联合起来对百户拥有家用汽车量有显著影响。
解释变量参数的t 统计量的绝对值均大于临界值0.025(27) 2.052t =,或P 值均明显小于0.05α=,表明在其他变量不变的情况下,“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”分别对百户拥有家用汽车量都有显著影响。
2)X2的参数估计值为4.8117,表明随着经济的增长,人均地区生产总值每增加1万元,平均说来百户拥有家用汽车量将增加近5辆。
由于城镇公共交通的大力发展,有减少家用汽车的必要性,X3的参数估计值为-0.4449,表明随着城镇化的推进,“城镇人口比重”每增加1%,平均说来百户拥有家用汽车量将减少0.4449辆。
汽车价格和使用费用的提高将抑制家用汽车的使用, X4的参数估计值为-5.7685,表明随着家用汽车使用成本的提高, “居民消费价格指数”每增加1个百分点,平均说来百户拥有家用汽车量将减少5.7685辆。
计量经济学精要第四版课后习题答案.doc
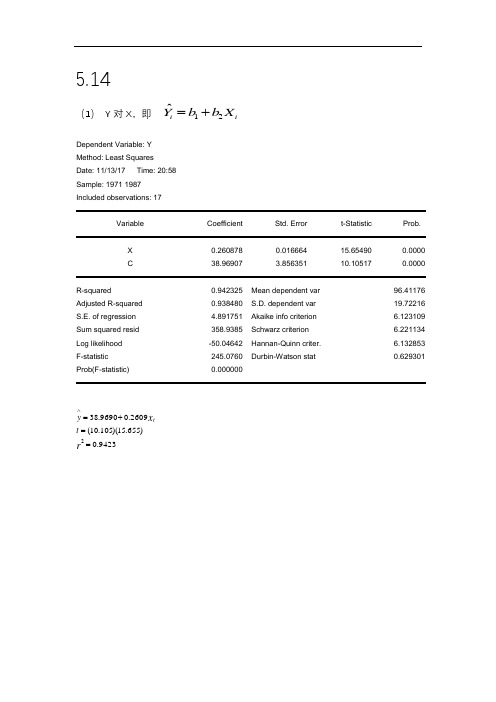
5.14(1) Y 对X ,即12ˆi iY b b X =+Dependent Variable: Y Method: Least Squares Date: 11/13/17 Time: 20:58 Sample: 1971 1987 Included observations: 17VariableCoefficient Std. Error t-Statistic Prob.X 0.260878 0.016664 15.65490 0.0000 C38.969073.85635110.10517 0.0000R-squared0.942325 Mean dependent var 96.41176 Adjusted R-squared 0.938480 S.D. dependent var 19.72216 S.E. of regression 4.891751 Akaike info criterion 6.123109 Sum squared resid 358.9385 Schwarz criterion 6.221134 Log likelihood -50.04642 Hannan-Quinn criter. 6.132853 F-statistic 245.0760 Durbin-Watson stat 0.629301Prob(F-statistic) 0.0000009423.0)655.15)(105.10(2609.09690.382==+=∧r x t y t(2)InY 对InX ,即 12ˆi iInY b b InX =+9642.0)090.20)(954.8(ln 5890.04041.1ln 2==+=∧r x t y tDependent Variable: LNY Method: Least Squares Date: 11/13/17 Time: 21:40 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.C 1.404051 0.156813 8.953649 0.0000 LNX0.5889650.02931720.08981 0.0000R-squared0.964166 Mean dependent var 4.547848 Adjusted R-squared 0.961777 S.D. dependent var 0.213165 S.E. of regression 0.041675 Akaike info criterion -3.407698 Sum squared resid 0.026052 Schwarz criterion -3.309673 Log likelihood 30.96543 Hannan-Quinn criter. -3.397954 F-statistic 403.6007 Durbin-Watson stat 0.734161Prob(F-statistic)0.000000(3)InY 对X ,即 12ˆi iInY b b X =+Dependent Variable: LNY Method: Least Squares Date: 11/13/17 Time: 21:42 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.C 3.931578 0.046430 84.67764 0.0000 X0.0027990.00020113.94972 0.0000R-squared0.928433 Mean dependent var 4.547848 Adjusted R-squared 0.923662 S.D. dependent var 0.213165 S.E. of regression 0.058896 Akaike info criterion -2.715956 Sum squared resid 0.052031 Schwarz criterion -2.617930 Log likelihood 25.08562 Hannan-Quinn criter. -2.706212 F-statistic 194.5946 Durbin-Watson stat 0.529132Prob(F-statistic) 0.0000009284.0)950.13)(678.84(0028.09316.3ln 2==+=∧r X t y t(4)Y 对InX ,即 12ˆi iY b b InX =+Dependent Variable: Y Method: Least Squares Date: 11/13/17 Time: 21:43 Sample: 1971 1987 Included observations: 17Variable Coefficient Std. Error t-Statistic Prob.C -192.9661 16.38000 -11.78059 0.0000 LNX54.212573.06227817.70335 0.0000R-squared0.954325 Mean dependent var 96.41176 Adjusted R-squared 0.951280 S.D. dependent var 19.72216 S.E. of regression 4.353186 Akaike info criterion 5.889824 Sum squared resid 284.2535 Schwarz criterion 5.987849 Log likelihood -48.06350 Hannan-Quinn criter. 5.899568 F-statistic 313.4086 Durbin-Watson stat 0.610822Prob(F-statistic) 0.0000009542.0)703.17)(781.11(ln 2126.549661.1922=-=+-=∧r X t Y t解:1.XY∆∆=1ˆβ斜率说明X 每变动一个单位,Y 的绝对变动量;2. E XX Y Y =∆∆=//ˆ1β斜率便是弹性系数; 3. XY Y ∆∆=/ˆ1β斜率表示X 每变动一个单位,Y 的均值的瞬时增长率; 4,. XX Y/ˆ1∆∆=β斜率表示X 的相对变化对Y 的绝对量的影响。
计量经济学精要习题参考答案(第四版)

计量经济学(第四版)习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学(第四版)习题及参考答案解析详细版

计量经济学(第四版)习题参考答案潘省初第一章 绪论试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
什么是时间序列和横截面数据 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
估计量和估计值有何区别估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间NS S x ==45= 用=,N-1=15个自由度查表得005.0t =,故99%置信限为x S t X 005.0± =174±×=174±也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。
25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/2510/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学第四版习题及参考答案

计量经济学第四版习题及参考答案The final revision was on November 23, 2020计量经济学(第四版)习题参考答案潘省初第一章 绪论试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
什么是时间序列和横截面数据 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
估计量和估计值有何区别估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间NSS x ==45= 用=,N-1=15个自由度查表得005.0t =,故99%置信限为 x S t X 005.0± =174±×=174±也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。
25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体 原假设 120:0=μH备择假设 120:1≠μH 检验统计量查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。
计量经济学(第四版)习题及参考答案详细版知识讲解

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NSS x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
计量经济学第四版习题及参考答案解析

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
计量经济学(第四版)第三章练习题及答案
第三章练习题及参考解答3.1进入21世纪后,中国的家用汽车增长很快。
家用汽车的拥有量受到经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。
为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量,2016年全国各省市区的有关数据如表3.5。
表3.5 2016年各地区的百户拥有家用汽车量等数据资料来源:中国统计年鉴2017.中国统计出版社1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型加以检验,检验结论的依据是什么?。
2)分析模型参数估计结果的经济意义,你如何解读模型估计检验的结果? 3) 你认为模型还可以如何改进?【练习题3.1 参考解答】:1)建立线性回归模型: 1223344t t t t t Y X X X u ββββ=++++ 回归结果如下:由F 统计量为14.69998, P 值为0.000007,可判断模型整体上显著, “人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量联合起来对百户拥有家用汽车量有显著影响。
解释变量参数的t 统计量的绝对值均大于临界值0.025(27) 2.052t =,或P 值均明显小于0.05α=,表明在其他变量不变的情况下,“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”分别对百户拥有家用汽车量都有显著影响。
2)X2的参数估计值为4.8117,表明随着经济的增长,人均地区生产总值每增加1万元,平均说来百户拥有家用汽车量将增加近5辆。
由于城镇公共交通的大力发展,有减少家用汽车的必要性,X3的参数估计值为-0.4449,表明随着城镇化的推进,“城镇人口比重”每增加1%,平均说来百户拥有家用汽车量将减少0.4449辆。
汽车价格和使用费用的提高将抑制家用汽车的使用, X4的参数估计值为-5.7685,表明随着家用汽车使用成本的提高, “居民消费价格指数”每增加1个百分点,平均说来百户拥有家用汽车量将减少5.7685辆。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计量经济学(第四版)习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即此样本不是取自一个均值为120元、标准差为10元的正态总体。
2.4 原假设 : 2500:0=μH备择假设 : 2500:1≠μH()100/1200.83ˆX X t μσ-====查表得 131.2)116(025.0=-t 因为t = 0.83 < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
第三章 双变量线性回归模型3.1 判断题(说明对错;如果错误,则予以更正) (1)对 (2)对 (3)错只要线性回归模型满足假设条件(1)~(4),OLS 估计量就是BLUE 。
(4)对 (5)错R 2 =ESS/TSS 。
(6)对(7)错。
我们可以说的是,手头的数据不允许我们拒绝原假设。
(8)错。
因为∑=22)ˆ(tx Var σβ,只有当∑2tx 保持恒定时,上述说法才正确。
3.2 证明:22222222ˆˆ()ˆˆi ii ii iYXXYiiii i YX XY i i x y y x x yxyyx y x yr x y ββββ===⎛⎫⋅===∑∑∑∑∑∑∑∑∑3.3 (1),得两边除以,=n ˆ0ˆ)ˆ(ˆ∑∑∑∑∑∑∑∑=∴+=⇒+=⇒+=tt t tt t t tt t t t YY e e Y Y e YY e Y YY nY n Y ==∑∑ˆ,即Y 的真实值和拟合值有共同的均值。
(2)的拟合值与残差无关。
,=,即因此,(教材中已证明),由于Y 0ˆˆ),ˆ(0ˆ0,0e ˆˆ)ˆˆ(ˆ22t∑∑∑∑∑∑∑∑∑∑====+=+=tttt tttt tt tt ttttt eY e Y e Y Cov e Ye X e X e e X e Y βαβα 3.4 (1)222222222221112222222ˆˆ,ˆˆ()ˆˆˆ2u()()ˆ()2()()()()ˆ2()()ˆ2()iit tti n n n t ii j i ii j i ji j i jtY X Y X u u X u X X u u x uX X nn xu u u x u x u X X nn x uu u x ux x u u X nn x αβαβααββααββββββββββ≠≠=+=++-=---=--+-=-⋅⋅+-++=-⋅+-+++=-⋅+-∑∑∑∑∑∑∑∑∑∑∑()2X2222222222222222()ˆˆ2E()1(()2())()2i i j i i i j i j i j i j t i i j i j i i j i j i i i j i j i jtu u u x u x x u u E E XE X n n x u u u E E u E u u n n n nx u x x u u XE n x ααββσσ≠≠≠≠≠⎛⎫⎡⎤+++ ⎪⎢⎥-=-⎪⎢⎥ ⎪⎢⎥⎝⎭⎣⎦⎛⎫+ ⎪=+==⎪ ⎪⎝⎭++∑∑∑∑∑∑∑∑∑∑∑∑两边取期望值,有:()-+等式右端三项分别推导如下:22222222222222222222212(()()())200ˆE()()ˆ[]0ii i i j i j ii jt t t t tt tt x Xx E u x x E u u Xx n x n x X X x x nX X X E n x n x n x σσββσσσσαα≠⎛⎫ ⎪ ⎪ ⎪⎝⎭=++==-=+-=-+==∑∑∑∑∑∑∑∑∑∑∑∑∑(=)因此()∑∑=222)ˆ(tt x n X Var σα即(2)2222ˆˆ,ˆˆ()ˆˆˆˆˆˆ(,)[()][(())()]ˆˆ[(()][()]ˆ0()01ˆ()t Y X Y X u u X Cov E E u X E u XE XE XVar X x αβαβααββαβααβββββββββββββσ=+=++-=--=--=---=---=--=-=-∑()(第一项为的证明见本题())3.5(1)X Y 21ˆˆββ-=,注意到 nx n x x x n x Var x n X Var Y x Y x x X X x ii i i ii i i i 22222221222121)()ˆ()ˆ(ˆˆ,0,0,σσσασβαα==-==-==-=∑∑∑∑∑∑∑==则我们有从而由上述结果,可以看到,无论是两个截距的估计量还是它们的方差都不相同。
(2)∑∑∑∑∑∑∑==---==222222222)ˆ()ˆ()())((ˆ,ˆiiiiiiiiii xVar Var xyx x x Y Y x x xyx σαβαβ=容易验证,这表明,两个斜率的估计量和方差都相同。
3.6(1)斜率的值 -4.318表明,在1980-1994期间,相对价格每上升一个单位,(GM/$)汇率下降约4.32个单位。
也就是说,美元贬值。
截距项6.682的含义是,如果相对价格为0,1美元可兑换6.682马克。
当然,这一解释没有经济意义。
(2)斜率系数为负符合经济理论和常识,因为如果美国价格上升快于德国,则美国消费者将倾向于买德国货,这就增大了对马克的需求,导致马克的升值。
(3)在这种情况下,斜率系数被预期为正数,因为,德国CPI 相对于美国CPI 越高,德国相对的通货膨胀就越高,这将导致美元对马克升值。
3.7(1)78.16982.187*31.126.76ˆ86.13998.164*31.126.76ˆ49.15667.177*31.126.76ˆ=+-==+-==+-=eight Weight Weight W(2)99.481.3*31.1*31.1ˆ==∆=∆height eight W6.910/96===∑Y Y t 810/80===∑n X X t75.028/21ˆ2===∑∑t tt x y x β 6.38*75.06.9*ˆˆ=-=-=X Y βα估计方程为: tt X Y 75.06.3ˆ+= (2)222ˆˆ(2)()(2)(30.40.75*21)/8 1.83125t t t te n y x y n σβ=-=--=-=∑∑∑934.2ˆˆ)ˆ(/ˆ2===∑txSe t σββββ733.1ˆˆ)ˆ(/ˆ22===∑∑ttx n X Se t σαααα518.0)4.30*28/21()(22222===∑∑∑t tt t y x y x R回归结果为(括号中数字为t 值):tt X Y 75.06.3ˆ+= R 2=0.518 (1.73) (2.93)说明:X t 的系数符号为正,符合理论预期,0.75表明劳动工时增加一个单位,产量增加0.75个单位,拟合情况。
R 2为0.518,作为横截面数据,拟合情况还可以.系数的显著性。
斜率系数的t 值为2.93,表明该系数显著异于0,即X t 对Y t 有影响. (3) 原假设 : 0.1:0=βH备择假设 : 0.1:1≠βH检验统计量 ˆˆ( 1.0)/()(0.75 1.0)/0.25560.978t Se ββ=-=-=- 查t 表, 0.025(8) 2.306ct t == ,因为│t │= 0.978 < 2.306 ,故接受原假设:0.1=β。
3.9对于x 0=250 ,点预测值 0ˆy=10+0.90*250=235.0 0ˆy的95%置信区间为: 00.025ˆ(122)*yt σ±-2352350.29=±=±即 234.71 - 235.29。
也就是说,我们有95%的把握预测0y 将位于234.71 至235.29 之间.35/15===∑n Y Y t 115/55===∑n X X t365.074/27ˆ2===∑∑ttt xy x β015.111*365.03*ˆˆ-=-=-=X Y βα我们有:t tX Y 365.0015.1ˆ+-=(2)048.03/)27*365.010()2()ˆ()2222=-=--=-=∑∑∑n y x y n e tt t t βσ 985.0)10*74/27()(22222===∑∑∑t tt t y x y x R(3) 对于0X =10 ,点预测值 0ˆY =-1.015+0.365*10=2.635 0Y 的95%置信区间为:∑-++-±220025.00)(/11ˆ*)25(ˆxX X n t Y σ=770.0635.274/)1110(5/11*048.0*182.3635.22±=-++± 即 1.895 -3.099,也就是说,我们有95%的把握预测0Y 将位于1.865 至3.405 之间. 3.11 问题可化为“预测误差是否显著地大?”当X 0 =20时,285.620365.0015.1ˆ0=⨯+-=Y预测误差335.1285.662.7ˆ000=-=-=Y Y e 原假设0H :0)(0=e E备择假设1H :0)(0≠e E检验:若0H 为真,则021.4332.0335.174)1120(511048.00335.1)(11ˆ)(222000==-++-=-++-=∑x X X n e E e t σ对于5-2=3个自由度,查表得5%显著性水平检验的t 临界值为:182.3=c t结论:由于 4.021 3.182t =>故拒绝原假设0H ,接受备则假设H 1,即新观测值与样本观测值来自不同的总体。