数学建模论文——图书馆的馆藏图书分配
图书馆的合理分配与利用资源

配和服务,提高图书馆的整体服务水平和资源利用率。
04
图书馆管理与服务
图书馆管理理念
人本理念
以读者为中心,提供人性 化服务,满足读者需求。
资源共享
推动图书馆之间的资源共 享,提高资源利用效率。
持续发展
注重图书馆的可持续发展 ,不断优化管理方式和服 务模式。
提高图书馆服务质量
优化馆藏结构
根据读者需求调整馆藏结构,提 高馆藏质量和利用效率。
图书馆的合理分配与利用
资源
汇报人:可编辑
2024-01-09
• 图书馆资源概述 • 图书馆资源的合理分配 • 图书馆资源的有效利用 • 图书馆管理与服务 • 图书馆资源的社会价值
01
图书馆资源概述
图书馆资源的种类
纸质图书
图书馆最传统的资源, 包括各类书籍、期刊等
。
电子资源
包括电子书籍、数据库 、在线课程等,便于检
建立资源使用反馈机制
反馈渠道
01
建立多渠道的资源使用反馈机制,包括在线反馈、电话反馈和
面对面反馈等,以便及时收集读者的意见和建议。
定期评估
02
定期对图书馆的资源使用情况进行评估,分析资源的使用率、
读者满意度等指标,为图书馆的改进提供依据。
调整优化
03
根据读者的反馈和评估结果,及时调整和优化图书馆的资源分
优化馆藏结构
根据读者需求和学科特点 ,合理配置图书馆的纸质 和电子资源,以满足不同 读者的阅读和学习需求。
定期更新资源
及时更新和补充图书馆的 馆藏资源,包括图书、期 刊、数据库等,确保资源 的时效性和完整性。
推广资源利用
通过举办培训、讲座和宣 传活动,提高读者对图书 馆资源的认识和利用能力 。
图书馆藏书统计分析

图书馆藏书统计分析图书馆作为知识的宝库,其藏书是服务读者、推动学术研究和文化传承的重要资源。
对图书馆藏书进行科学、系统的统计分析,有助于了解藏书的构成、质量、利用情况等,从而为图书馆的管理和发展提供有力的依据。
一、藏书规模统计藏书规模是衡量图书馆实力的重要指标之一。
首先,我们需要统计图书馆的总藏书量,包括纸质图书、期刊、报纸、电子图书、音像资料等各种类型的文献。
通过对不同类型文献数量的统计,可以清晰地了解图书馆的资源储备情况。
在统计过程中,我们发现纸质图书仍然占据了较大的比例,但随着数字化时代的到来,电子图书的数量也在逐年增加。
此外,期刊和报纸对于及时获取最新的学术和时事信息具有重要作用,其数量和更新频率也需要关注。
通过对历年藏书规模的比较,可以看出图书馆的发展趋势。
如果藏书量持续增长,说明图书馆在资源建设方面投入较大,能够满足读者不断增长的需求;反之,如果藏书量增长缓慢甚至停滞,可能需要反思资源采购策略和经费投入是否合理。
二、藏书分类统计为了更好地管理和利用藏书,图书馆通常会按照一定的分类体系对图书进行分类。
常见的分类法有《中国图书馆分类法》《杜威十进制分类法》等。
对藏书进行分类统计,可以了解不同学科领域的藏书分布情况。
例如,在自然科学类藏书中,物理学、化学、生物学等学科的图书数量各有多少;在社会科学类藏书中,经济学、法学、历史学等学科的分布情况如何。
通过这种分类统计,可以发现某些学科领域的藏书是否丰富,是否存在薄弱环节。
对于重点学科和热门学科,图书馆往往会加大藏书采购力度,以满足教学和科研的需求。
通过统计分析,可以评估图书馆在支持重点学科方面的成效,为进一步优化藏书结构提供参考。
三、藏书年代统计藏书的年代分布也具有重要意义。
了解不同年代出版的图书在馆藏中的比例,可以反映出图书馆藏书的更新程度。
早期出版的图书具有一定的历史价值和学术价值,但随着时间的推移,知识不断更新,新出版的图书往往更能反映当前的研究成果和学术动态。
数学建模心得与体会[终稿]
![数学建模心得与体会[终稿]](https://img.taocdn.com/s3/m/cb0a2507f08583d049649b6648d7c1c708a10b05.png)
数学建模心得与体会数学建模心得与体会——陈保成自学校举行大学生首届数学建模比赛,我就积极参与,在比赛过程中我学的很多,也使我感觉自己所学知识有用,并体会了搞建模的艰辛,也意识到自己的知识匮乏,应该增深自己知识面。
与队友密切合作,培养了自己团队意识,并意识与他人合作重要性。
在通过学校选拔以后,接着就是‘痛苦’的培训。
在培训期间,正值高温期,有许多同学吃不下苦,而中途放弃了,现在想想都挺佩服自己的,不知是怎么坚持下来的。
既然在这样艰苦条件下都能坚持下来,以后还有什么坚持不下来呢!虽然培训是痛苦的,但也学到很多东西。
老师讲的内容都比较精彩生动,在课堂上,老师充分调动我们的积极性。
我们不仅学到了许多知识,也加强了动手能力和实践能力。
如在学习MATLAB过程中,通过自己动手操作,都能基本上掌握MATLAB,这对我来说,为了以后的后续课程打下基础。
还有图论、优化、聚类、统计等一些知识,增宽了我的知识面。
还有LINGO,SPSS 软件,如果没有参加建模的话,我也许一辈子都不会去接触这些东西。
这段时间的培训之后,会明显感觉自己的进步以及对问题的数学思维能力的加强,但个人认为要参加比赛,就要博览全书,仅仅把自己的知识局限于此是不够。
培训的过程是相当辛苦的,每天除了吃饭、睡觉,其余时间基本上都是在机房度过的,不断学习、练习,几天下来就会感觉相当疲劳,培训的过程也是对我们队员吃苦耐力的考验。
但是苦中有乐,每天大家过的都很充实,大家相互交流着想法,共同讨论,共同进步。
在参加全国赛的三天内,第一天,我们拿到题目,并结合自身的优点,选择题目,分析题目,指导老师给我们指导和建议,不过一天下来我们几乎毫无进展,我感觉很沮丧,多亏了队友的鼓励和帮助,我才能坚持下来。
第二天,我们又打起精神继续奋战接下来主要进行合理假设与参数说明,把题目转化成数学问题的形式,开始是肯定是建立初等模型,考虑的不全面,队友也有不同想法,这就需要队友相互交流,然后一起完善模型,这就体现团队重要性。
图书馆馆藏图书流通分析

jc o ba o s u t ni epoes f d l col o s ut n et firr cnt ci t rc s o e sh nt c o . l y r o nh mo c r i
Ke r y wo ds:i r r ;q n iy i ic a in;s g s o lb a y ua tt n cr ulto ug e t n i
越大。而随着形 势的发展和高职学 院 自身专业发
展 的要求 , 职 学 院 图 书 馆 的藏 书 资 料 越 来 越 多 , 高 图书资料 的形式 不 断 增 加 , 为读 者 服 务 的 方式 也 多
程系、 经济管理 系、 信息工 程系、 基础部 、 想政治 思
部、 成人 教 育 部 等 ; 办 专 业 近 4 开 0个 , 有 在 校 生 现 70 00多人 。图书 馆 在 学 院评 估 和示 范 性 院 校 建 设
有的图书馆藏类特别丰富, 但复本量小 , 读者借 阅 多, 损耗较大 , 已经破 旧, 并 需及 时剔 除, 由于要 但
提升 , 0 年 的借 阅量 比 20 2 9 0 08年 的同期 明显 的增 大, 这就要求图书馆必须紧随学院办学水平的提升
而加 大建 设力 度 , 更好地 服务 师生 。
馆 20 — 09 0 8 2 0 年的图书外借情况基本相同 , 都是在
每年 3月 份 出现借 阅 高峰 , 次 是 9月份 。 之所 以 其 在这 两个 月 出现借 阅高 峰 , 主要 是 因为 这 两个 月是 新学期 开 始之 际 , 一方 面 与学 生 课程 学 习 的 需要 有 关, 另一方 面 与新 学期 开 始学 生 的学 习积 极性 较 高 有关 。图书馆 应抓 住 这两 个 阅读 高 峰期 , 做好 读 者 服务 工作 , 而提 升 图书馆 的形 象 。 从 另外 , 随着 我 院办 学规模 的 扩大 和 办 学水 平 的
数学建模论文——图书馆的馆藏图书分配

承诺书我们仔细阅读了中国大学生数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题.我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出.我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性.如有违反竞赛规则的行为,我们将受到严肃处理.我们参赛选择的题号是(从A/B/C/D中选择一项填写): A我们的参赛报名号为(如果赛区设置报名号的话):所属学校(请填写完整的全名):宁波工程学院参赛队员(打印并签名) :1.李瑜苗2.杨路捷3.吴建明指导教师或指导教师组负责人(打印并签名):数模组日期: 2010 年 8 月 7 日赛区评阅编号(由赛区组委会评阅前进行编号):编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):图书馆的馆藏图书分配摘要本文根据题意将数据进行分析处理,建立三个模型得到各类图书的综合权重,以综合权重来确定应有的册数比例,给图书馆提供合理的图书采购方案.对于问题一,利用已知的信息,采用AHP层次分析法[1]和模糊综合评价法[2],综合考虑各类图书的重点实验室和重点学科建设的需求与否、常用和热门程度、重要公共课与否、技能课图书与否、上年的出借册次分布五个指标,确定各指标对各类图书隶属度关系和模糊矩阵,从而得到相对重要程度的权重.即各类书的相对重要程度的权向量分别为:0.0484 0.0508 0.0367 0.0418 0.0405 0.0564 0.03680.0621 0.0554 0.0418 0.0375 0.0472 0.0357 0.05560.0495 0.0362 0.0414 0.0448 0.0673 0.0521 0.0357对于问题二,采用和问题一类似的方法,对确定了的一年内的相对流通量、图书平均借用时间、图书利用率三个指标进行处理,从而得到书籍在该校的实际使用价值的相应权重.但值得注意的是,在问题二的处理过程中,采用了熵值法对三个指标赋权,减少了主观因素对反映实际使用价值过程的影响.即各类书的实际使用价值的权向量分别为:0.0415 0.0533 0.0402 0.0432 0.0506 0.0542 0.03890.0582 0.0497 0.0468 0.0421 0.0581 0.0436 0.05640.0549 0.0354 0.0473 0.0447 0.0585 0.0535 0.0288由上数据可知对应的权值越大相应的价值越大.对于问题三,引进了一种“席位分配[4]”的数学模型,在满足各类图书的最低更新率的基础上,使得结果的相对不公平指标最小,从而得到了最优化的购书分配方法.即A、B类书增加270册,C、N类书增加520册,D类书增加164册,E、R、S、U、V类书增加218册,X类书增加1773册,F类书增加1058册,G类书增加191册,H3类书增加599册,I类书增加898册,J类书增加213册,K类书增加234册,Q类书增加247册,P类书增加1987册,O类书增加966册,TH类书增加1068册,TM、TS类书增加109册,TN类书增加143册,TQ类书增加483册,TP类书增加693册,TU、TV类书增加315册,Z类书增加965册.对于问题四,通过所编写的MATLAB的程序,不善于数学建模的人只需要输入上一年该普通高校图书馆的馆藏图书的分布及流通情况和下一年计划投入的总资金额这两个数据,就可以得到图书馆下一年的购书资金分配方案.关键词:AHP层次分析法熵值法图书分配席位分配一、问题的提出现代化图书馆馆藏图书,主要目的不是为了收藏而是为了使用.除了国家图书馆等特大型的图书馆以外,一般图书馆都有特定的服务群体,办馆宗旨就是要尽量好地为这些特定群体服务,提高馆藏资源的利用率、读者文献信息需求的满足率以及对图书馆服务功能的满意率.图书馆每年用于购书的经费是有限的,如何合理分配使用,以便使有限的购书经费最大限度地发挥其特定的经济效益是图书馆工作的重要环节之一.以某学校图书馆为例,要实现办馆效益,必须做到入藏文献合乎本校教师、学生(有时也兼顾社会)的需求,使图书馆藏书结构(学科结构、文种结构、文献类型结构等)能满足本校教学科研的要求,以求藏书体系与本校专业设置相适应.所购图书要能够真实地反映读者的实际需要,使读者结构和藏书结构尽量吻合,以便减少读者借不到图书的现象,即降低读者拒借的比率、增加满足率.文献只有在流通中才能传播信息,产生效益.文献资料得不到利用,购置文献资料所耗费的资金就体现不出其价值.因此,图书馆在增加藏书规模的同时,要千方百计地把文献提供给读者,以增加图书的出借次数、出借时间以及在借图书的数量等,力求使有限的价值投入获得最大的办馆效益.该校图书馆每学年都要投入大量资金购置图书,图书覆盖全院各学科专业、具有较完整的中外文文献资源.如何合理分配资金用于各种图书的购置成为一个非常有价值的问题.二、基本假设1、假设该校各专业学生比例大致不会变且总人数相对稳定;2、假设所借的图书没有不归还或丢失;3、假设每年借书人数相对稳定;4、假设题目给的数据真实有效.三、定义符号说明四、模型的分析、模型的建立及求解4.1 问题一的分析及模型建立:4.1.1 问题一的提出和分析已知:①该普通高校的重点学科、重点专业的设置情况;②上一年该普通高校图书馆的馆藏图书的分布及流通情况表.要求:同时考虑重点实验室和重点学科建设的需求、常用书籍和流行热门书籍、重要公共课、技能课图书(如英语、计算机类)的普通要求等几个方面,以确定各类图书对于该校图书馆的相对重点程度(即相对权重).分析:根据题目要求,我们以各类图书的重点实验室和重点学科建设的需求与否、常用和热门程度、重要公共课与否、技能课图书与否、上年的出借册次分布这五个指标来衡量各类图书对于该校图书馆的相对重点程度(即相对权重).首先,通过层次分析法[1]确定个指标之间的权重,利用方根法计算出反映各指标相对权重的权向量,并进行一致性检验;然后,确定各类图书与各指标之间的隶属度关系,最后,利用加权平均型合成算子确定模糊综合评价[2]结果,得到各类图书对于该学校图书馆的相对重要程度(即相对权重).4.1.2模型一的建立及求解首先,用层次分析法确定权重,判断矩阵由A.L.Saaty的1~9比率标度方法确定,结果见下关系表如下表1:由表可得14/32453/412341/21/21231/41/31/213/21/51/41/32/31R ⎛⎫ ⎪⎪ ⎪= ⎪⎪⎪ ⎭⎝用方根法计算得出权向量:)(12345{,,,,}0.36470.29410.17950.09460.0672ωωωωωω== 进行一致性检验:最大特征根0166.5m a x =λ,一致性指标0042.01m a x =--=n nCI λ,平均随机一致性指标12.1=RI ,随机一致性比率CR=1.000375.0<=RICI,因此该判断矩阵具有满意的一致性.故通过一致性检验.利用MATLAB 软件对其进行归一化处理:确定各指标对各类图书的隶属度,得到模糊矩阵R⎝⎛⎪⎪⎪⎪⎪⎪⎭⎫=0.02060.0388640.0964220.0316690.0465120.0465120.0465120.0465120.0340910.0340910.0340910.0681820.0303030.0606060.0606060.04545510.0422535250.0704225310.0422535210.04225352 R利用加权平均型合成算子,将权向量ω与模糊关系矩阵R 合成,得到模糊综合评价结果向量B :)0.03570.05210.0508 0.0484( =⋅=R B ω即各类书的相对重要程度的权向量分别为:0.0484 0.0508 0.0367 0.0418 0.0405 0.0564 0.03680.0621 0.0554 0.0418 0.0375 0.0472 0.0357 0.05560.0495 0.0362 0.0414 0.0448 0.0673 0.0521 0.03574.2 问题二的分析及模型建立:4.2.1 问题二的提出及分析已知:①图书最终的实现价值应取决于图书的被利用率;②上一年该普通高校图书馆的馆藏图书的分布及流通情况表.要求:评价一本书的真正价值必须考虑到它的流通量大小和借用时间的长短等,并根据该校上一年各类图书的出借情况,提出一种评价图书在该校实际使用价值的方法.分析:与问题一类似,我们同样先给出用来评价图书在该校的实际使用价值的三个指标:一年内的相对流通量、图书平均借用时间、图书利用率.然后,我们采用熵值法[3]对这三个指标进行赋权处理,从而得到指标的权向量;利用MATLAB软件对各类图书的三个评价指标数据表中的数据进行归一化,从而得到各指标对各类图书的隶属度模糊矩阵.最后,利用加权平均型合成算子确定模糊综合评价结果,得到各类图书在该学校图书馆的实际使用价值.4.2.2 模型二的建立及求解图书最终的实现价值应取决于图书的被利用率.因而评价一本书的真正价值必须考虑到它的流通量大小和借用时间的长短等多方面的指标.在模型二的评价中,设定了三个指标来评价图书在该校的实际使用价值,三个指标如下:一年内的相对流通量(出借册数/册数)、图书平均借用时间(出借总时间/出借册数)、图书利用率(出借种类数/内容种类数)(数据见下表).采用熵值法对三个指标进行赋权处理:1.对原始数据进行标准化处理,得到标准矩阵321)(⨯=ij y Y 计算公式为)3,2,1;21,,2,1(===j i Mx y jij ij 其中j M 为第j 个指标的最大值.得到Y 矩阵(见附录1)2.将各指标同度量化,计算第j 项指标下第i 类书指标值的比重)31,21(211≤≤≤≤=∑=j i i y y p i ijijij得到p 矩阵(见附录2) 3.计算第j 项指标的熵值211ln (1)j ij iji e k p p j n ω==-≤≤∑ 其中21ln 1=k 则2111ln (13)ln 21j ij ij i e p p j ω=-=≤≤∑.得到e ω矩阵(见附录3)4.计算第j 项指标的差异性系数1(13)j j g e j ω=-≤≤,其值越大,指标就越重要;5.确定指标权重,第j 项指标的权数211'(13)jj jj g j gω==≤≤∑.得到'ω的一个指标权重向量 '(0.3297 0.3322 0.3382)ω=.利用MATLAB 软件对模型二中各类图书的三个评价指标数据表中的数据进0.04346410.06133970.05723880.021782'0.0367540.0486470.0497270.0324120.0443670.0500980.0536740.032131R ⎛⎫ ⎪= ⎪⎪⎭⎝利用加权平均型合成算子,将权向量'ω与模糊关系矩阵'R 合成,得到模糊综合评价结果向量'B :'''(0.04150.05330.05350.0288)B R ω==即各类书的实际使用价值的权向量分别为:0.0415 0.0533 0.0402 0.0432 0.0506 0.0542 0.0389 0.0582 0.0497 0.0468 0.0421 0.0581 0.0436 0.0564 0.0549 0.0354 0.0473 0.0447 0.0585 0.0535 0.0288由上数据可知对应的权值越大相应的价值越大.4.3 问题三的分析及模型建立 4.3.1 问题三的提出及分析已知:①通过前两问研究,我们得到了各类图书的相对重要程度和其在该校的实际使用价值所对应的权重;②上一年该普通高校图书馆的馆藏图书的分布及流通情况表;③图书馆计划投入100万元用于购置各种图书.要求:在所确定的购书资金分配方案应尽可能符合学校学科发展的需要和教学科研需要,又应当尽可能提高读者的满意率,与此同时,图书馆自然还应当注意到各类馆藏图书的更新率,以及用于购书的总经费是有限制的这四个条件的约束下,尽可能满足目标函数(所购图书实际效益最大).分析:在前两问的研究基础之上,我们引进两个新概念———读者满意度((册数/内容种类数)/(出借册数/出借种类数))和实际效益的综合评价值.但由于读者满意度越大,图书所需更新的比率应该相对越小,所以用读者满意度的倒数来作为衡量综合评价值的第三指标.于是,就有了衡量综合评价值的三项指标,即图书相对重要权重、图书实际使用价值权重、读者满意度的倒数.然后,利用熵值法来可以确定综合评价实际效益中三个指标之间的相对权重,继而得到各类图书综合评价值.在制定购书资金的分配方案时,我们又引进一个称为“席位分配”的数学模型.这个模型从每个席位对应的人数出发,定义了一个相对不公平指标,将有限的代表席位逐个分配到各个小组,结果使得相对不公平指标最小.而不公平程度以各类图书的i ice (每个综合评价值所对应的图书册数)的方差值来衡量,方差值越小,不公平程度也越小.而在图书更新过程中,还应该注意到各类书的更新率.通过资料查找,我们发现图书馆的各类图书的更新率至少应达到3%.所以,采用在满足最低更新率的基础上,进行“席位分配”的方法,利用MATLAB 软件所编程序,最终得到最优的购书资金分配方案. 4.3.2 模型三的建立及求解应用模型二提到的熵值法,确定该三项指标在综合评价中的权重.(附录) 得到三项指标的权向量:''( 0.3314 0.3323 0.3363)ω=再运用模糊综合评价的方法,求得21类书的综合评价值e 为:0.0461 0.0548 0.0397 0.0452 0.0497 0.0537 0.0391 0.0585 0.0552 0.0444 0.0430 0.0505 0.0390 0.0537 0.0533 0.0374 0.0456 0.0460 0.0593 0.0528 0.0327在本模型中,以该类书的综合权重反映书的应有册数比重. 要考虑21类书的购书比例,假设有A 、B 两类书的综合评价值为1e 、2e ,该类书原有的册数为1c 、2c ,模型希望达到的是2211e c e c =,若2211e ce c <,则认为A 书是亏欠的,应补.推广到21类书,为了保证每类书都有一定更新率,在满足各类图书最低分配率的基础上,将剩余的经费分配给其余亏欠的图书,直到达到资金上限(100万).具体步骤如下:1.先满足每类书3%的更新率,判断剩余的资金M 是否大于零,若0>M ,则转步骤2;若0M <=,则转步骤4.2.比较所有的)213,2,1( =i e cii ,值最小的那类书,所对应的1+i c ,即购一本书,然后1+=i i c c ,i p M M -=,对更新的比值计算方差. 3.再判断M ,若0>M ,则转步骤2;若0M <=,则转步骤4.4.各类书的购书过程结束,输出每类书所购的册数,及每循环一次所得的方差.选择方差最小的所对应的购书比值(即最符合各类书应有的册数比),剩余的资金再按照册数符合综合权重的原则分配.5.输出最终各类书的所购的册数以及所花费的资金.4.4 问题四的分析及求解问题四是前三问的分析综合得到的权重以确定图书的采购方案,根据题意只要简要的阐述馆方输入哪些数字,怎样操作获得合理的购书方案即可.我们决定编一个小系统,馆方只需两个数据的txt 文件(其中第一个txt 数据为:重点学科和重点专业 常用 重要公共课 技能课图书 出借册书;第二个txt 数据为:出借册数 册数 出借时总时间 出借种类 内容种类)和一个计划投入总资金,利用MATLAB 软件读取上面的数据就可以得到比较合适的购书方案.(matlab 程序见附录问题四)五、结果分析由综合评价值e 矩阵可知“自动化技术、计算机技术综合权重”最大,“常用外国语”“文学”“ 经济”“数理科学和化学” “机械仪表工业” “建筑科学、水利工程”也较大,将模型出来的结果与题目给出的数据进行比较,可知权重大的重点类建设对象或是重点学科.而“综合性图书”权重最小,与题目给的数据也较符合.根据综合权重的柱状图与原册数的实际比例作对比综合权重大的原有册数也多,但有存在例外.并且模型得出的权重大小波动较小,而原有册数差距较大.分析原因:1:图书馆现有图书分布并不合理; 2:模型中设置的权重并不很合理.六、模型推广本题不仅可以用于优化图书的采购方案问题,也可以用于各类相似的评价问题中.模型三用到的席位分配模型,可以用以解决生活、工作中可能产生的资源分配公平与否的问题.与此同时,本文涉及的模型可以用以评价多种属性(指标)的对象.七、模型的评价与改进优点:1、利用多种方法确定权重,一定程度上减少了主观因素对结果的影响.2、基于层次分析、模糊综合评价模型并进行改进,结果符合实际.3、模型三的算法逻辑清晰、易懂,运用软件,减少大量计算量.缺点:1、模型一中,运用层次分析法确定五个指标的权重,带有主观因素,一定程度上影响结果.2、多次运用模糊综合评价,算法较单一.参考文献:[1]吴祈宗,运筹学与最优化方法,北京:机械工业出版社,2003年;[2]张秀兰,基于模糊综合评判法的研究及应用,科技信息2008年14期:91—92,2008年;[3]沈红丽,因子分析法和熵值法在高校科技创新评价中的应用,河北工业大学学报第38卷第1期,2009年2月;[4]靖培栋刘忠厚,图书馆外文核心期刊购买模型探讨,中国图书馆学报(双月刊)1999年第4期第25卷44-48,1999年;[5]臧秀平李萍张建丁声铎,改进的模糊综合评判法在评标中的应用,江苏科技大学学报(自然科学版)第21卷第6期,2007年12月.附件问题一MATLAB代码:%Maxlmta.m%和法求最大特征根clcclear alldisp('please choose the filename you want toplot'); %查找数据的文件夹[filename,pathname]= uigetfile(' *.txt', 'choose the file you want to plot');ifpathname==0 %pathname返回0说明文件打开失败,可能是取消了,或是文件不存在等等原因return %return用于退出整个程序endname =[pathnamefilename]; %文件的路径和名字fid=fopen(name,'r+'); %读取文件x=fscanf(fid,'%c'); %count得到数据个数,A是列向量,用于存放所有数据A=str2num(x);%下面的A是一个测试的程序矩阵%A=[1 1/2 4 3 3;% 2 1 7 5 5;% 1/4 1/7 1 1/2 1/3;% 1/3 1/5 2 1 1;% 1/3 1/5 3 1 1];%RI--随机一致性指标%n--A的列长度%w--权向量%lmta--最大特征根%CI--一致性指标%CR--一致性比率%RIn--A的一致性指标%flag--标志变量%Wij Wi W--临时变量RI=[0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45,1.49,1.51];%将A的每一列向量归一化Asum=sum(A);n=length(A);for j=1:nfor i=1:nWij(i,j)=A(i,j)./Asum(1,j);endend%将Wij按行求和Wij=Wij';Wi=sum(Wij);Wi=Wi';%将Wi归一化W=sum(Wi);disp('权向量');w=Wi./W%计算lmtadisp('最大特征根\n');lmta=sum(1/n*(A*w)./w)%计算CRdisp('A的一致性指标');RIn=RI(1,n);disp('一致性指标');CI=(lmta-n)/(n-1)CR=CI/RIn;%判断一致性检验if CR<0.1|n<=2disp('通过一致性检验')flag=1;elsedisp('不能通过一致性检验')flag=0;end问题二MATLAB代码:%shuangzhifa.m%层次分析法中的熵值法function tclear allclc%输入数据[filename pathname]=uigetfile('*.txt','please choose the file'); name=[pathname filename];if filename==0returnendfid=fopen (name,'r+');x=fscanf (fid,'%c');x=str2num(x);%对x标准化得到yxsize=size(x);temp=max(x);for i=1:xsize(1)y(i,:)=x(i,:)./temp;endclear temp;%计算p(i,j)temp=y';temp=sum(temp);for i=1:xsize(1)for j=1:xsize(2)p(i,j)=y(i,j)/temp(j);endendclear temp;%计算e(j)k=1/log(xsize(1));for j=1:xsize(2)tempsum=0;for i=1:xsize(1)temp=p(i,j)*log(p(i,j));tempsum=tempsum+temp;ende(j)=-k*tempsum;end%求差异性系数g(j)g=1-e;clear temp;temp=sum(g);for j=1:xsize(2)w(j)=g(j)./temp;endwreturn问题三MATLAB代码:%shijixiaoyiguihua.mfunction tempclear allclcc=[8991 17322 5481 7266 1731 35256 6375 19983 29946 7101 7794 8220 744 2850 2715 3645 4767 2796 23112 10503 1347];e=[0.0461 0.0548 0.0397 0.0452 0.0497 0.0537 0.0391 0.0585 0.0552 0.0444 0.043 0.0505 0.039 0.0537 0.0533 0.0374 0.0456 0.046 0.0593 0.0528 0.0327];price=[225674.1 486748.2 121130.1 189916 65951.1 1131718 128137.5 561522.3 7339765 199538.1 304745.4 206322 20162.4 100035 98011.5 102424.5 185913 64587.6 834343.2 305637.3 60749.7];tmp=c./e;ptmp=tmp;pc=c;eachprice=price./c;x=zeros(1,21);ppx=round(c*0.03);x=ppx+x;pprice=ppx.*eachprice;px=x;STD=std(ptmp);while sum(eachprice.*px)<=(1000000-sum(pprice)) [pnumber pindex]=min(ptmp);px(pindex)=px(pindex)+1;pc(pindex)=pc(pindex)+1;ptmp=pc./e;ptemp=std(ptmp);STD=[STD ptemp];endn=size(STD,2);STD=STD(1,[1:n-1]);[number index]=min(STD);for i=1:index[pnumber pindex]=min(tmp);x(pindex)=x(pindex)+1;c(pindex)=c(pindex)+1;tmp=c./e;endxsumprice=sum(x.*eachprice)+sum(pprice)return问题四MATLAB代码:%wenti4.mfunction tempclear allclcdisp('读入一个txt的矩阵数据文件\n');disp('数据的顺序为:重点学科和重点专业常用重要公共课技能课图书出借册书\n');[filename pathname]=uigetfile('*.txt','请选择数据');name=[pathname filename];dif=fopen(name,'r');x1=fscanf (dif,'%f');n=size(x,1);w=[0.3647 0.2941 0.1795 0.0946 0.0672];%人为定义的一个奴隶度关系得到的权向量xsum=sum(x1);for i=1:nx1(i,:)=x1(i,:)./xsum;endx1=x1';w1=w*x1; %得到第一个w1disp('请输入第二个数的txt文件的矩阵数据\n');[filename pathname]=uigetfile('*.txt','输入的数据格式为:出借册数册数出借时总时间出借种类内容种类\n');name=[pathname filename];if filename==0returnendfid=fopen (name,'r+');data=fscanf (fid,'%c');data=str2num(data);x2=[data(1)/data(2) data(3)/data(1) data(4)/data(5)];%对x2标准化得到yxsize=size(x2);temp=max(x2);for i=1:xsize(1)y(i,:)=x2(i,:)./temp;endclear temp;%计算p(i,j)temp=y';temp=sum(temp);for i=1:xsize(1)for j=1:xsize(2)p(i,j)=y(i,j)/temp(j);endendclear temp;%计算e(j)k=1/log(xsize(1));for j=1:xsize(2)tempsum=0;for i=1:xsize(1)temp=p(i,j)*log(p(i,j));tempsum=tempsum+temp;ende(j)=-k*tempsum;end%求差异性系数g(j)g=1-e;clear temp;temp=sum(g);for j=1:xsize(2)w(j)=g(j)./temp;endxxsum=sum(x2);for i=1:xsize(1)x2=x2./xxsum;endx2=x2';w2=w*x2; %得到第二w2数据w3=(data(1)/data(4))/(data(2)/data(5));pw=[w1 w2 w3];ppw=pw;ppwsum=sum(ppw);n=size(ppw,1);for i=1:nppw(i,:)=pw(i,:)./ppwsum;R=ppw';%对pw标准化得到ypwsize=size(pw);temp=max(pw);for i=1:pwsize(1)y(i,:)=pw(i,:)./temp;endclear temp;%计算p(i,j)temp=y';temp=sum(temp);for i=1:pwsize(1)for j=1:pwsize(2)p(i,j)=y(i,j)/temp(j); endendclear temp;%计算e(j)k=1/log(pwsize(1));for j=1:pwsize(2)tempsum=0;for i=1:pwsize(1)temp=p(i,j)*log(p(i,j)); tempsum=tempsum+temp;ende(j)=-k*tempsum;end%求差异性系数g(j)g=1-e;clear temp;temp=sum(g);for j=1:pwsize(2)ppw(j)=g(j)./temp;pxxsum=sum(ppw);for i=1:xsize(1)ppw=ppw./pxxsum;endppw=ppw';w=ppw*pw; %得到w数据e=w*R;c=data(1);disp('请输入一个txt的图书总价数据的矩阵');[filename pathname]=uigetfile('*.txt','请择择文件');name=[pathname filename];dif=fopen(name,'r');price=fscanf (dif,'%f');%c=[8991 17322 5481 7266 1731 35256 6375 19983 29946 7101 7794 8220 744 2850 2715 3645 4767 2796 23112 10503 1347];%e=[0.0461 0.0548 0.0397 0.0452 0.0497 0.0537 0.0391 0.0585 0.0552 0.0444 0.043 0.0505 0.039 0.0537 0.0533 0.0374 0.0456 0.046 0.0593 0.0528 0.0327];%price=[225674.1 486748.2 121130.1 189916 65951.1 1131718 128137.5 561522.3 7339765 199538.1 304745.4 206322 20162.4 100035 98011.5 102424.5 185913 64587.6 834343.2 305637.3 60749.7];tmp=c./e;ptmp=tmp;pc=c;eachprice=price./c;x=zeros(1,21);ppx=round(c*0.03);x=ppx+x;pprice=ppx.*eachprice;sum(pprice)px=x;STD=std(ptmp);zongzijin=input('请输入总资金数:(单位\元)');while sum(eachprice.*px)<=(zongzijin-sum(pprice))[pnumber pindex]=min(ptmp);px(pindex)=px(pindex)+1;pc(pindex)=pc(pindex)+1;ptmp=pc./e;ptemp=std(ptmp);STD=[STD ptemp];endn=size(STD,2);STD=STD(1,[1:n-1]);[number index]=min(STD);for i=1:index[pnumber pindex]=min(tmp);x(pindex)=x(pindex)+1;c(pindex)=c(pindex)+1;tmp=c./e;endxsumprice=sum(x.*eachprice)+sum(pprice) return。
数学建模资源分配方案
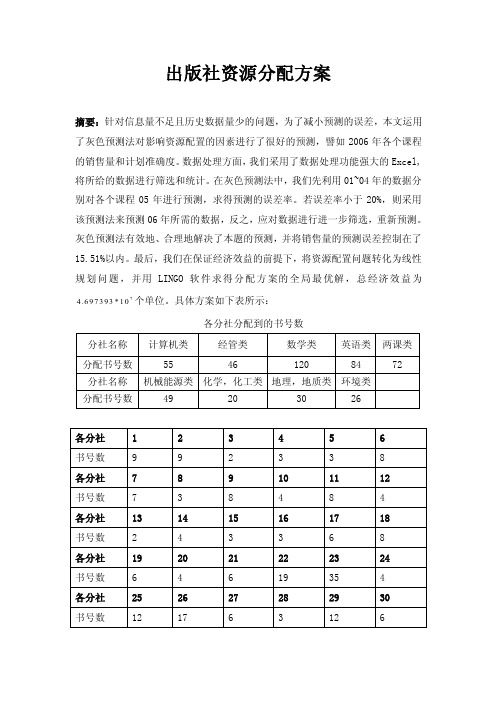
出版社资源分配方案摘要:针对信息量不足且历史数据量少的问题,为了减小预测的误差,本文运用了灰色预测法对影响资源配置的因素进行了很好的预测,譬如2006年各个课程的销售量和计划准确度。
数据处理方面,我们采用了数据处理功能强大的Excel,将所给的数据进行筛选和统计。
在灰色预测法中,我们先利用01~04年的数据分别对各个课程05年进行预测,求得预测的误差率。
若误差率小于20%,则采用该预测法来预测06年所需的数据,反之,应对数据进行进一步筛选,重新预测。
灰色预测法有效地、合理地解决了本题的预测,并将销售量的预测误差控制在了15.51%以内。
最后,我们在保证经济效益的前提下,将资源配置问题转化为线性规划问题,并用LINGO软件求得分配方案的全局最优解,总经济效益为74.697393*10个单位。
具体方案如下表所示:各分社分配到的书号数关键词:灰色预测线性规划市场竞争力计划准确度满意度一、问题的重述1.1背景知识随着党中央国务院“十一五”发展规划的提出,我国的文化产业也受到了前所未有的重视,同时,“十一五”也宣告了出版产业面临着前所未有的挑战。
“十一五”期间,出版发行业将面临因特网、手机短信、数字出版等科技发展引发的对出版环境的影响,不少出版社和发行单位已经或者正在开始着手对自身未来发展的思考和规划,这种现象本身也是出版业理性回归的一个重要标志。
对于出版发行单位而言,战略规划的最大价值在于它的过程,在于培养一种在市场经济环境中的系统思考与应变能力,而不仅仅是规划的结果。
根据加入WTO的承诺,2006年是我国出版分销行业全面放开的最后一年,深化体制改革以应对入世,正在成为出版发行行业的重中之重。
行业对竞争力的关注前所未有的重视,任何研究报告、市场调查、行业排名都会触动出版社敏感的神经。
教育出版对出版社的竞争力影响大,经营成为最主要的提高竞争力的手段,形成了相对稳定的竞争力优势。
因此,占据出版业优势地位的教材出版业更注重对市场的调查研究,对市场做出科学的评估和预测,需要的就是一种科学的调查、评估和预测方法。
高校图书馆馆藏分布调查分析

高校图书馆馆藏分布调查分析[提要]本文调查遵义市四所高校:遵义师范学院、遵义医学院、遵义航天技术学院、遵义医药高等专科学校等图书馆藏资源分布情况,在此基础上展开分析,从而对今后图书馆的馆藏建设提出合理化建议。
关键词:高校图书馆;馆藏,分布高校图书馆的根本宗旨就是为教学与科研服务,调查分析馆藏分布是图书馆自身发展的需要,合理的馆藏分布能提高读者对图书馆的利用率,也能缓解购书经费紧缺的问题。
现在,高校图书馆的服务对象中大部分是90后的读者,他们追求的是快捷、高效而又成本低的信息来源。
因此,提出合理的馆藏分布势在必行。
为了适应21世纪信息时代的需要,使遵义市各高校图书馆的馆藏文献更好地为教学、科研服务,笔者针对遵义市四所高校图书馆的馆藏文献分布情况进行调查,并提出一些合理化建议。
一、调查情况(一)遵义医学院图书馆。
该馆总面积10,634平方米,图书馆现有馆藏纸质图书60余万册,电子图书42.1万册;藏书结构以生物、医学类图书为主,同时兼顾学校新办学科和专业。
现有馆藏期刊6,640种,其中外文期刊1,732种;现刊1,374种,其中外文现刊131种。
经过多年的发展,图书馆构建了以16台服务器、52TB存储阵列以及586个信息点为支撑,拥有各种类型计算机280余台的自动化平台,并引进各类数据库29个,自建特色数据库7个。
该馆是“贵州省科技文献资源共享平台”及“中国高校人文社会科学文献中心”等资源共享平台成员馆,同时还与CALIS全国医学中心、首都医科大学、四川大学等高校图书馆建立了文献传递与馆际交流关系。
现在该馆已经建立了能够满足该校广大读者基本需求的馆藏资源体系,并为学校教学、科研、医疗提供了有力的资源保障。
馆藏资源分布大致如表1所示。
(表1)(二)遵义师范学院图书馆。
该图书馆现有独立馆舍14,770平方米,纸质藏书70余万册,电子图书30万册,年订报刊820余种。
从2007年新馆投入使用后,就建立了图书馆管理系统局域网,全面实行计算机管理和开架借阅服务,拥有160台客户机电子阅览室一间。
学校图书馆资源配置方案

学校图书馆资源配置方案一、引言学校图书馆是学习、研究和知识传播的重要场所,为提供优质的教育资源,图书馆资源配置方案至关重要。
本文将探讨学校图书馆资源如何进行合理的配置,以满足学生和教职员工的不同需求。
二、图书馆藏书的多样性要满足学校内不同专业的学生需求,图书馆的藏书需要具备多样性。
首先,图书馆应收藏相关专业的经典著作、参考书籍和教科书,为学生提供系统性的学习材料。
其次,图书馆应该鼓励订购最新的学术期刊和研究报告,以便学生能够了解最新的学术动态。
此外,图书馆还应提供丰富的中外文文学作品、科普读物、报纸杂志等通俗读物,以满足读者的休闲阅读需求。
三、数字化资源的重要性随着信息技术的快速发展,数字化资源已成为图书馆资源配置中不可或缺的部分。
数字化资源包括电子图书、期刊数据库、在线学习平台等。
通过购买订阅权或与其他图书馆合作共享资源,学校图书馆可以提供更广泛、更深入的学术资源给学生和教职员工。
此外,数字化资源还能够提供个性化的学习支持和远程学习的便利性,为用户提供更灵活的学习方式。
四、图书馆空间规划在资源配置方案中,图书馆空间的规划也需要被重视。
首先,学校应确保图书馆有足够的阅览座位,以便学生在图书馆内有一个安静、舒适的学习环境。
其次,图书馆应设有独立的研究空间和小组学习区域,以促进学生之间的合作学习和知识交流。
此外,还可以设置创客空间或多功能演示区,方便学生进行科研实践、展示和创新创业活动。
五、图书馆服务的改进资源配置方案还应考虑图书馆服务的改进。
学校图书馆应加强文献传递和互借服务,与其他图书馆建立联盟合作,以提供更多种类的图书和期刊资源。
此外,图书馆应开展信息素养培训,帮助学生和教职员工学习如何高效地利用各类学术资源和数据库。
另外,引入先进的图书馆管理系统,实现自动化借还书、预约资源等服务,提高图书馆工作效率。
六、多元化的文化活动为了更好地丰富学生的学习生活,图书馆资源配置方案还应包括多元化的文化活动。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
承诺书我们仔细阅读了中国大学生数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题.我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出.我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性.如有违反竞赛规则的行为,我们将受到严肃处理.我们参赛选择的题号是(从A/B/C/D中选择一项填写): A我们的参赛报名号为(如果赛区设置报名号的话):所属学校(请填写完整的全名):宁波工程学院参赛队员(打印并签名) :1.李瑜苗2.杨路捷3.吴建明指导教师或指导教师组负责人(打印并签名):数模组日期: 2010 年 8 月 7 日赛区评阅编号(由赛区组委会评阅前进行编号):编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):图书馆的馆藏图书分配摘要本文根据题意将数据进行分析处理,建立三个模型得到各类图书的综合权重,以综合权重来确定应有的册数比例,给图书馆提供合理的图书采购方案.对于问题一,利用已知的信息,采用AHP层次分析法[1]和模糊综合评价法[2],综合考虑各类图书的重点实验室和重点学科建设的需求与否、常用和热门程度、重要公共课与否、技能课图书与否、上年的出借册次分布五个指标,确定各指标对各类图书隶属度关系和模糊矩阵,从而得到相对重要程度的权重.即各类书的相对重要程度的权向量分别为:0.0484 0.0508 0.0367 0.0418 0.0405 0.0564 0.03680.0621 0.0554 0.0418 0.0375 0.0472 0.0357 0.05560.0495 0.0362 0.0414 0.0448 0.0673 0.0521 0.0357对于问题二,采用和问题一类似的方法,对确定了的一年内的相对流通量、图书平均借用时间、图书利用率三个指标进行处理,从而得到书籍在该校的实际使用价值的相应权重.但值得注意的是,在问题二的处理过程中,采用了熵值法对三个指标赋权,减少了主观因素对反映实际使用价值过程的影响.即各类书的实际使用价值的权向量分别为:0.0415 0.0533 0.0402 0.0432 0.0506 0.0542 0.03890.0582 0.0497 0.0468 0.0421 0.0581 0.0436 0.05640.0549 0.0354 0.0473 0.0447 0.0585 0.0535 0.0288由上数据可知对应的权值越大相应的价值越大.对于问题三,引进了一种“席位分配[4]”的数学模型,在满足各类图书的最低更新率的基础上,使得结果的相对不公平指标最小,从而得到了最优化的购书分配方法.即A、B类书增加270册,C、N类书增加520册,D类书增加164册,E、R、S、U、V类书增加218册,X类书增加1773册,F类书增加1058册,G类书增加191册,H3类书增加599册,I类书增加898册,J类书增加213册,K类书增加234册,Q类书增加247册,P类书增加1987册,O类书增加966册,TH类书增加1068册,TM、TS类书增加109册,TN类书增加143册,TQ类书增加483册,TP类书增加693册,TU、TV类书增加315册,Z类书增加965册.对于问题四,通过所编写的MATLAB的程序,不善于数学建模的人只需要输入上一年该普通高校图书馆的馆藏图书的分布及流通情况和下一年计划投入的总资金额这两个数据,就可以得到图书馆下一年的购书资金分配方案.关键词:AHP层次分析法熵值法图书分配席位分配一、问题的提出现代化图书馆馆藏图书,主要目的不是为了收藏而是为了使用.除了国家图书馆等特大型的图书馆以外,一般图书馆都有特定的服务群体,办馆宗旨就是要尽量好地为这些特定群体服务,提高馆藏资源的利用率、读者文献信息需求的满足率以及对图书馆服务功能的满意率.图书馆每年用于购书的经费是有限的,如何合理分配使用,以便使有限的购书经费最大限度地发挥其特定的经济效益是图书馆工作的重要环节之一.以某学校图书馆为例,要实现办馆效益,必须做到入藏文献合乎本校教师、学生(有时也兼顾社会)的需求,使图书馆藏书结构(学科结构、文种结构、文献类型结构等)能满足本校教学科研的要求,以求藏书体系与本校专业设置相适应.所购图书要能够真实地反映读者的实际需要,使读者结构和藏书结构尽量吻合,以便减少读者借不到图书的现象,即降低读者拒借的比率、增加满足率.文献只有在流通中才能传播信息,产生效益.文献资料得不到利用,购置文献资料所耗费的资金就体现不出其价值.因此,图书馆在增加藏书规模的同时,要千方百计地把文献提供给读者,以增加图书的出借次数、出借时间以及在借图书的数量等,力求使有限的价值投入获得最大的办馆效益.该校图书馆每学年都要投入大量资金购置图书,图书覆盖全院各学科专业、具有较完整的中外文文献资源.如何合理分配资金用于各种图书的购置成为一个非常有价值的问题.二、基本假设1、假设该校各专业学生比例大致不会变且总人数相对稳定;2、假设所借的图书没有不归还或丢失;3、假设每年借书人数相对稳定;4、假设题目给的数据真实有效.三、定义符号说明四、模型的分析、模型的建立及求解4.1 问题一的分析及模型建立:4.1.1 问题一的提出和分析已知:①该普通高校的重点学科、重点专业的设置情况;②上一年该普通高校图书馆的馆藏图书的分布及流通情况表.要求:同时考虑重点实验室和重点学科建设的需求、常用书籍和流行热门书籍、重要公共课、技能课图书(如英语、计算机类)的普通要求等几个方面,以确定各类图书对于该校图书馆的相对重点程度(即相对权重).分析:根据题目要求,我们以各类图书的重点实验室和重点学科建设的需求与否、常用和热门程度、重要公共课与否、技能课图书与否、上年的出借册次分布这五个指标来衡量各类图书对于该校图书馆的相对重点程度(即相对权重).首先,通过层次分析法[1]确定个指标之间的权重,利用方根法计算出反映各指标相对权重的权向量,并进行一致性检验;然后,确定各类图书与各指标之间的隶属度关系,最后,利用加权平均型合成算子确定模糊综合评价[2]结果,得到各类图书对于该学校图书馆的相对重要程度(即相对权重).4.1.2模型一的建立及求解首先,用层次分析法确定权重,判断矩阵由A.L.Saaty的1~9比率标度方法确定,结果见下关系表如下表1:由表可得14/32453/412341/21/21231/41/31/213/21/51/41/32/31R ⎛⎫ ⎪⎪ ⎪= ⎪⎪⎪ ⎭⎝用方根法计算得出权向量:)(12345{,,,,}0.36470.29410.17950.09460.0672ωωωωωω== 进行一致性检验:最大特征根0166.5m a x =λ,一致性指标0042.01m a x =--=n nCI λ,平均随机一致性指标12.1=RI ,随机一致性比率CR=1.000375.0<=RICI,因此该判断矩阵具有满意的一致性.故通过一致性检验.利用MATLAB 软件对其进行归一化处理:确定各指标对各类图书的隶属度,得到模糊矩阵R⎝⎛⎪⎪⎪⎪⎪⎪⎭⎫=0.02060.0388640.0964220.0316690.0465120.0465120.0465120.0465120.0340910.0340910.0340910.0681820.0303030.0606060.0606060.04545510.0422535250.0704225310.0422535210.04225352 R利用加权平均型合成算子,将权向量ω与模糊关系矩阵R 合成,得到模糊综合评价结果向量B :)0.03570.05210.0508 0.0484( =⋅=R B ω即各类书的相对重要程度的权向量分别为:0.0484 0.0508 0.0367 0.0418 0.0405 0.0564 0.03680.0621 0.0554 0.0418 0.0375 0.0472 0.0357 0.05560.0495 0.0362 0.0414 0.0448 0.0673 0.0521 0.03574.2 问题二的分析及模型建立:4.2.1 问题二的提出及分析已知:①图书最终的实现价值应取决于图书的被利用率;②上一年该普通高校图书馆的馆藏图书的分布及流通情况表.要求:评价一本书的真正价值必须考虑到它的流通量大小和借用时间的长短等,并根据该校上一年各类图书的出借情况,提出一种评价图书在该校实际使用价值的方法.分析:与问题一类似,我们同样先给出用来评价图书在该校的实际使用价值的三个指标:一年内的相对流通量、图书平均借用时间、图书利用率.然后,我们采用熵值法[3]对这三个指标进行赋权处理,从而得到指标的权向量;利用MATLAB软件对各类图书的三个评价指标数据表中的数据进行归一化,从而得到各指标对各类图书的隶属度模糊矩阵.最后,利用加权平均型合成算子确定模糊综合评价结果,得到各类图书在该学校图书馆的实际使用价值.4.2.2 模型二的建立及求解图书最终的实现价值应取决于图书的被利用率.因而评价一本书的真正价值必须考虑到它的流通量大小和借用时间的长短等多方面的指标.在模型二的评价中,设定了三个指标来评价图书在该校的实际使用价值,三个指标如下:一年内的相对流通量(出借册数/册数)、图书平均借用时间(出借总时间/出借册数)、图书利用率(出借种类数/内容种类数)(数据见下表).采用熵值法对三个指标进行赋权处理:1.对原始数据进行标准化处理,得到标准矩阵321)(⨯=ij y Y 计算公式为)3,2,1;21,,2,1(===j i Mx y jij ij 其中j M 为第j 个指标的最大值.得到Y 矩阵(见附录1)2.将各指标同度量化,计算第j 项指标下第i 类书指标值的比重)31,21(211≤≤≤≤=∑=j i i y y p i ijijij得到p 矩阵(见附录2) 3.计算第j 项指标的熵值211ln (1)j ij iji e k p p j n ω==-≤≤∑ 其中21ln 1=k 则2111ln (13)ln 21j ij ij i e p p j ω=-=≤≤∑.得到e ω矩阵(见附录3)4.计算第j 项指标的差异性系数1(13)j j g e j ω=-≤≤,其值越大,指标就越重要;5.确定指标权重,第j 项指标的权数211'(13)jj jj g j gω==≤≤∑.得到'ω的一个指标权重向量'(0.3297 0.3322 0.3382)ω=.利用MATLAB 软件对模型二中各类图书的三个评价指标数据表中的数据进0.04346410.06133970.05723880.021782'0.0367540.0486470.0497270.0324120.0443670.0500980.0536740.032131R ⎛⎫ ⎪= ⎪⎪ ⎭⎝利用加权平均型合成算子,将权向量'ω与模糊关系矩阵'R 合成,得到模糊综合评价结果向量'B :'''(0.04150.05330.05350.0288)B R ω==即各类书的实际使用价值的权向量分别为:0.0415 0.0533 0.0402 0.0432 0.0506 0.0542 0.0389 0.0582 0.0497 0.0468 0.0421 0.0581 0.0436 0.0564 0.0549 0.0354 0.0473 0.0447 0.0585 0.0535 0.0288由上数据可知对应的权值越大相应的价值越大.4.3 问题三的分析及模型建立 4.3.1 问题三的提出及分析已知:①通过前两问研究,我们得到了各类图书的相对重要程度和其在该校的实际使用价值所对应的权重;②上一年该普通高校图书馆的馆藏图书的分布及流通情况表;③图书馆计划投入100万元用于购置各种图书.要求:在所确定的购书资金分配方案应尽可能符合学校学科发展的需要和教学科研需要,又应当尽可能提高读者的满意率,与此同时,图书馆自然还应当注意到各类馆藏图书的更新率,以及用于购书的总经费是有限制的这四个条件的约束下,尽可能满足目标函数(所购图书实际效益最大).分析:在前两问的研究基础之上,我们引进两个新概念———读者满意度((册数/内容种类数)/(出借册数/出借种类数))和实际效益的综合评价值.但由于读者满意度越大,图书所需更新的比率应该相对越小,所以用读者满意度的倒数来作为衡量综合评价值的第三指标.于是,就有了衡量综合评价值的三项指标,即图书相对重要权重、图书实际使用价值权重、读者满意度的倒数.然后,利用熵值法来可以确定综合评价实际效益中三个指标之间的相对权重,继而得到各类图书综合评价值.在制定购书资金的分配方案时,我们又引进一个称为“席位分配”的数学模型.这个模型从每个席位对应的人数出发,定义了一个相对不公平指标,将有限的代表席位逐个分配到各个小组,结果使得相对不公平指标最小.而不公平程度以各类图书的i ice (每个综合评价值所对应的图书册数)的方差值来衡量,方差值越小,不公平程度也越小.而在图书更新过程中,还应该注意到各类书的更新率.通过资料查找,我们发现图书馆的各类图书的更新率至少应达到3%.所以,采用在满足最低更新率的基础上,进行“席位分配”的方法,利用MATLAB 软件所编程序,最终得到最优的购书资金分配方案. 4.3.2 模型三的建立及求解应用模型二提到的熵值法,确定该三项指标在综合评价中的权重.(附录)得到三项指标的权向量:''( 0.3314 0.3323 0.3363)ω=再运用模糊综合评价的方法,求得21类书的综合评价值e 为:0.0461 0.0548 0.0397 0.0452 0.0497 0.0537 0.0391 0.0585 0.0552 0.0444 0.0430 0.0505 0.0390 0.0537 0.0533 0.0374 0.0456 0.0460 0.0593 0.0528 0.0327在本模型中,以该类书的综合权重反映书的应有册数比重. 要考虑21类书的购书比例,假设有A 、B 两类书的综合评价值为1e 、2e ,该类书原有的册数为1c 、2c ,模型希望达到的是2211e c e c =,若2211e ce c <,则认为A 书是亏欠的,应补.推广到21类书,为了保证每类书都有一定更新率,在满足各类图书最低分配率的基础上,将剩余的经费分配给其余亏欠的图书,直到达到资金上限(100万).具体步骤如下:1.先满足每类书3%的更新率,判断剩余的资金M 是否大于零,若0>M ,则转步骤2;若0M <=,则转步骤4.2.比较所有的)213,2,1( =i e cii ,值最小的那类书,所对应的1+i c ,即购一本书,然后1+=i i c c ,i p M M -=,对更新的比值计算方差. 3.再判断M ,若0>M ,则转步骤2;若0M <=,则转步骤4.4.各类书的购书过程结束,输出每类书所购的册数,及每循环一次所得的方差.选择方差最小的所对应的购书比值(即最符合各类书应有的册数比),剩余的资金再按照册数符合综合权重的原则分配.5.输出最终各类书的所购的册数以及所花费的资金.4.4 问题四的分析及求解问题四是前三问的分析综合得到的权重以确定图书的采购方案,根据题意只要简要的阐述馆方输入哪些数字,怎样操作获得合理的购书方案即可.我们决定编一个小系统,馆方只需两个数据的txt 文件(其中第一个txt 数据为:重点学科和重点专业 常用 重要公共课 技能课图书 出借册书;第二个txt 数据为:出借册数 册数 出借时总时间 出借种类 内容种类)和一个计划投入总资金,利用MATLAB 软件读取上面的数据就可以得到比较合适的购书方案.(matlab 程序见附录问题四)五、结果分析由综合评价值e 矩阵可知“自动化技术、计算机技术综合权重”最大,“常用外国语”“文学”“ 经济”“数理科学和化学” “机械仪表工业” “建筑科学、水利工程”也较大,将模型出来的结果与题目给出的数据进行比较,可知权重大的重点类建设对象或是重点学科.而“综合性图书”权重最小,与题目给的数据也较符合.根据综合权重的柱状图与原册数的实际比例作对比综合权重大的原有册数也多,但有存在例外.并且模型得出的权重大小波动较小,而原有册数差距较大.分析原因:1:图书馆现有图书分布并不合理; 2:模型中设置的权重并不很合理.六、模型推广本题不仅可以用于优化图书的采购方案问题,也可以用于各类相似的评价问题中.模型三用到的席位分配模型,可以用以解决生活、工作中可能产生的资源分配公平与否的问题.与此同时,本文涉及的模型可以用以评价多种属性(指标)的对象.七、模型的评价与改进优点:1、利用多种方法确定权重,一定程度上减少了主观因素对结果的影响.2、基于层次分析、模糊综合评价模型并进行改进,结果符合实际.3、模型三的算法逻辑清晰、易懂,运用软件,减少大量计算量.缺点:1、模型一中,运用层次分析法确定五个指标的权重,带有主观因素,一定程度上影响结果.2、多次运用模糊综合评价,算法较单一.参考文献:[1]吴祈宗,运筹学与最优化方法,北京:机械工业出版社,2003年;[2]张秀兰,基于模糊综合评判法的研究及应用,科技信息2008年14期:91—92,2008年;[3]沈红丽,因子分析法和熵值法在高校科技创新评价中的应用,河北工业大学学报第38卷第1期,2009年2月;[4]靖培栋刘忠厚,图书馆外文核心期刊购买模型探讨,中国图书馆学报(双月刊)1999年第4期第25卷44-48,1999年;[5]臧秀平李萍张建丁声铎,改进的模糊综合评判法在评标中的应用,江苏科技大学学报(自然科学版)第21卷第6期,2007年12月.附件问题一MATLAB代码:%Maxlmta.m%和法求最大特征根clcclear alldisp('please choose the filename you want toplot'); %查找数据的文件夹[filename,pathname]= uigetfile(' *.txt', 'choose the file you want to plot');ifpathname==0 %pathname返回0说明文件打开失败,可能是取消了,或是文件不存在等等原因return %return用于退出整个程序endname =[pathnamefilename]; %文件的路径和名字fid=fopen(name,'r+'); %读取文件x=fscanf(fid,'%c'); %count得到数据个数,A是列向量,用于存放所有数据A=str2num(x);%下面的A是一个测试的程序矩阵%A=[1 1/2 4 3 3;% 2 1 7 5 5;% 1/4 1/7 1 1/2 1/3;% 1/3 1/5 2 1 1;% 1/3 1/5 3 1 1];%RI--随机一致性指标%n--A的列长度%w--权向量%lmta--最大特征根%CI--一致性指标%CR--一致性比率%RIn--A的一致性指标%flag--标志变量%Wij Wi W--临时变量RI=[0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45,1.49,1.51];%将A的每一列向量归一化Asum=sum(A);n=length(A);for j=1:nfor i=1:nWij(i,j)=A(i,j)./Asum(1,j);endend%将Wij按行求和Wij=Wij';Wi=sum(Wij);Wi=Wi';%将Wi归一化W=sum(Wi);disp('权向量');w=Wi./W%计算lmtadisp('最大特征根\n');lmta=sum(1/n*(A*w)./w)%计算CRdisp('A的一致性指标');RIn=RI(1,n);disp('一致性指标');CI=(lmta-n)/(n-1)CR=CI/RIn;%判断一致性检验if CR<0.1|n<=2disp('通过一致性检验')flag=1;elsedisp('不能通过一致性检验')flag=0;end问题二MATLAB代码:%shuangzhifa.m%层次分析法中的熵值法function tclear allclc%输入数据[filename pathname]=uigetfile('*.txt','please choose the file'); name=[pathname filename];if filename==0returnendfid=fopen (name,'r+');x=fscanf (fid,'%c');x=str2num(x);%对x标准化得到yxsize=size(x);temp=max(x);for i=1:xsize(1)y(i,:)=x(i,:)./temp;endclear temp;%计算p(i,j)temp=y';temp=sum(temp);for i=1:xsize(1)for j=1:xsize(2)p(i,j)=y(i,j)/temp(j);endendclear temp;%计算e(j)k=1/log(xsize(1));for j=1:xsize(2)tempsum=0;for i=1:xsize(1)temp=p(i,j)*log(p(i,j));tempsum=tempsum+temp;ende(j)=-k*tempsum;end%求差异性系数g(j)g=1-e;clear temp;temp=sum(g);for j=1:xsize(2)w(j)=g(j)./temp;endwreturn问题三MATLAB代码:%shijixiaoyiguihua.mfunction tempclear allclcc=[8991 17322 5481 7266 1731 35256 6375 19983 29946 7101 7794 8220 744 2850 2715 3645 4767 2796 23112 10503 1347];e=[0.0461 0.0548 0.0397 0.0452 0.0497 0.0537 0.0391 0.0585 0.0552 0.0444 0.043 0.0505 0.039 0.0537 0.0533 0.0374 0.0456 0.046 0.0593 0.0528 0.0327];price=[.1 .2 .1 65951.1 .5 .3 .1 .4 20162.4 98011.5 .564587.6 .2 .3 60749.7];tmp=c./e;ptmp=tmp;pc=c;eachprice=price./c;x=zeros(1,21);ppx=round(c*0.03);x=ppx+x;pprice=ppx.*eachprice;px=x;STD=std(ptmp);while sum(eachprice.*px)<=(-sum(pprice))[pnumber pindex]=min(ptmp);px(pindex)=px(pindex)+1;pc(pindex)=pc(pindex)+1;ptmp=pc./e;ptemp=std(ptmp);STD=[STD ptemp];endn=size(STD,2);STD=STD(1,[1:n-1]);[number index]=min(STD);for i=1:index[pnumber pindex]=min(tmp);x(pindex)=x(pindex)+1;c(pindex)=c(pindex)+1;tmp=c./e;endxsumprice=sum(x.*eachprice)+sum(pprice)return问题四MATLAB代码:%wenti4.mfunction tempclear allclcdisp('读入一个txt的矩阵数据文件\n');disp('数据的顺序为:重点学科和重点专业常用重要公共课技能课图书出借册书\n');[filename pathname]=uigetfile('*.txt','请选择数据');name=[pathname filename];dif=fopen(name,'r');x1=fscanf (dif,'%f');n=size(x,1);w=[0.3647 0.2941 0.1795 0.0946 0.0672];%人为定义的一个奴隶度关系得到的权向量xsum=sum(x1);for i=1:nx1(i,:)=x1(i,:)./xsum;endx1=x1';w1=w*x1; %得到第一个w1disp('请输入第二个数的txt文件的矩阵数据\n');[filename pathname]=uigetfile('*.txt','输入的数据格式为:出借册数册数出借时总时间出借种类内容种类\n');name=[pathname filename];if filename==0returnendfid=fopen (name,'r+');data=fscanf (fid,'%c');data=str2num(data);x2=[data(1)/data(2) data(3)/data(1) data(4)/data(5)];%对x2标准化得到yxsize=size(x2);temp=max(x2);for i=1:xsize(1)y(i,:)=x2(i,:)./temp;endclear temp;%计算p(i,j)temp=y';temp=sum(temp);for i=1:xsize(1)for j=1:xsize(2)p(i,j)=y(i,j)/temp(j);endendclear temp;%计算e(j)k=1/log(xsize(1));for j=1:xsize(2)tempsum=0;for i=1:xsize(1)temp=p(i,j)*log(p(i,j));tempsum=tempsum+temp;ende(j)=-k*tempsum;end%求差异性系数g(j)g=1-e;clear temp;temp=sum(g);for j=1:xsize(2)w(j)=g(j)./temp;endxxsum=sum(x2);for i=1:xsize(1)x2=x2./xxsum;endx2=x2';w2=w*x2; %得到第二w2数据w3=(data(1)/data(4))/(data(2)/data(5));pw=[w1 w2 w3];ppw=pw;ppwsum=sum(ppw);n=size(ppw,1);for i=1:nppw(i,:)=pw(i,:)./ppwsum;endR=ppw';%对pw标准化得到ypwsize=size(pw);temp=max(pw);for i=1:pwsize(1)y(i,:)=pw(i,:)./temp;endclear temp;%计算p(i,j)temp=y';temp=sum(temp);for i=1:pwsize(1)for j=1:pwsize(2)p(i,j)=y(i,j)/temp(j); endendclear temp;%计算e(j)k=1/log(pwsize(1));for j=1:pwsize(2)tempsum=0;for i=1:pwsize(1)temp=p(i,j)*log(p(i,j)); tempsum=tempsum+temp;ende(j)=-k*tempsum;end%求差异性系数g(j)g=1-e;clear temp;temp=sum(g);for j=1:pwsize(2)ppw(j)=g(j)./temp;endpxxsum=sum(ppw);for i=1:xsize(1)ppw=ppw./pxxsum;endppw=ppw';w=ppw*pw; %得到w数据e=w*R;c=data(1);disp('请输入一个txt的图书总价数据的矩阵');[filename pathname]=uigetfile('*.txt','请择择文件');name=[pathname filename];dif=fopen(name,'r');price=fscanf (dif,'%f');%c=[8991 17322 5481 7266 1731 35256 6375 19983 29946 7101 7794 8220 744 2850 2715 3645 4767 2796 23112 10503 1347];%e=[0.0461 0.0548 0.0397 0.0452 0.0497 0.0537 0.0391 0.0585 0.0552 0.0444 0.043 0.0505 0.039 0.0537 0.0533 0.0374 0.0456 0.046 0.0593 0.0528 0.0327];%price=[.1 .2 .1 65951.1 .5 .3 .1 .4 20162.4 98011.5 .5 64587.6 .2 .3 60749.7];tmp=c./e;ptmp=tmp;pc=c;eachprice=price./c;x=zeros(1,21);ppx=round(c*0.03);x=ppx+x;pprice=ppx.*eachprice;sum(pprice)px=x;STD=std(ptmp);zongzijin=input('请输入总资金数:(单位\元)');while sum(eachprice.*px)<=(zongzijin-sum(pprice))[pnumber pindex]=min(ptmp);px(pindex)=px(pindex)+1;pc(pindex)=pc(pindex)+1;ptmp=pc./e;ptemp=std(ptmp);STD=[STD ptemp];endn=size(STD,2);STD=STD(1,[1:n-1]);[number index]=min(STD);for i=1:index[pnumber pindex]=min(tmp);x(pindex)=x(pindex)+1;c(pindex)=c(pindex)+1;tmp=c./e;endxsumprice=sum(x.*eachprice)+sum(pprice) return。