数据结构(c语言版)严蔚敏
严蔚敏《数据结构》(C语言版)笔记和习题(含考研真题)详解

严蔚敏《数据结构》(C语言版)笔记和习题(含考研真题)详解第1章绪论一、什么是数据结构数据结构是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作等的学科。
二、基本概念和术语1数据数据是对客观事物的符号表示,是计算机科学中所有能输入到计算机中并能被计算机程序处理的符号的总称。
2数据元素数据元素是数据的基本单位。
3数据对象数据对象是性质相同的数据元素的集合,是数据的一个子集。
4数据结构数据结构是相互之间存在一种或多种特定关系的数据元素的集合。
(1)数据结构的基本结构根据数据元素之间关系的不同特性,通常有下列四类基本结构:①集合。
数据元素属于“同一个集合”,并无其他复杂关系。
②线性结构。
数据元素之间存在一个对一个的关系。
③树形结构。
数据元素之间存在一个对多个的关系。
④图状结构或网状结构。
数据元素之间存在多个对多个的关系。
【注意】区分这四种基本结构可以根据元素间的对应关系。
如图1-1所示为上述四类基本结构的关系图。
图1-1 四类基本结构的关系图(2)数据结构的形式定义数据结构的形式定义为:Data_Structure=(D,S)其中:D表示数据元素的有限集,S表示D上关系的有限集。
(3)数据结构在计算机中的表示数据结构包括数据元素的表示和关系,在计算机中称为数据的物理结构(又称存储结构)。
其中,关系有两种表示方法:顺序映象和非顺序映象。
这两种表示方法对应两种存储结构:顺序存储结构和链式存储结构。
a.顺序映象:用相对位置来表示数据元素之间的逻辑关系。
b.非顺序映象:用指针表示数据元素之间的逻辑关系。
5数据类型数据类型是一个值的集合和定义在这个值集上的一组操作的总称。
6抽象数据类型抽象数据类型(ADT)由一个值域和定义在该值域上的一组操作组成。
【注意】抽象数据类型是对数据类型架构的一种全局体现,使我们能够更加清晰地看待某一数据类型。
7多形数据类型多形数据类型是指其值的成分不确定的数据类型。
数据结构c语言版严蔚敏习题答案

数据结构c语言版严蔚敏习题答案数据结构是计算机科学中非常重要的一门课程,它研究的是数据的组织、存储和管理方式。
而C语言是一种被广泛应用于系统编程和嵌入式开发的编程语言。
在学习数据结构的过程中,很多人会选择使用严蔚敏编写的《数据结构(C语言版)》一书。
本文将针对该书中的习题,为大家提供一些答案和解析。
1. 顺序表顺序表是一种使用连续的内存空间来存储数据的数据结构。
在《数据结构(C语言版)》一书中,我们可以通过使用结构体来实现顺序表。
下面是一个示例代码:```c#include <stdio.h>#include <stdlib.h>#define MAXSIZE 100typedef struct {int data[MAXSIZE];int length;} SqList;void InitList(SqList *L) {L->length = 0;}void Insert(SqList *L, int pos, int value) {if (L->length >= MAXSIZE) {printf("顺序表已满,无法插入!"); return;}if (pos < 1 || pos > L->length + 1) { printf("插入位置非法!");return;}for (int i = L->length; i >= pos; i--) { L->data[i] = L->data[i - 1];}L->data[pos - 1] = value;L->length++;}void Delete(SqList *L, int pos) {if (pos < 1 || pos > L->length) {printf("删除位置非法!");return;}for (int i = pos - 1; i < L->length - 1; i++) { L->data[i] = L->data[i + 1];}L->length--;}int main() {SqList L;InitList(&L);Insert(&L, 1, 10);Insert(&L, 2, 20);Insert(&L, 3, 30);Delete(&L, 2);for (int i = 0; i < L.length; i++) {printf("%d ", L.data[i]);}return 0;}2. 链表链表是一种使用非连续的内存空间来存储数据的数据结构。
数据结构_(严蔚敏C语言版)_学习、复习提纲.
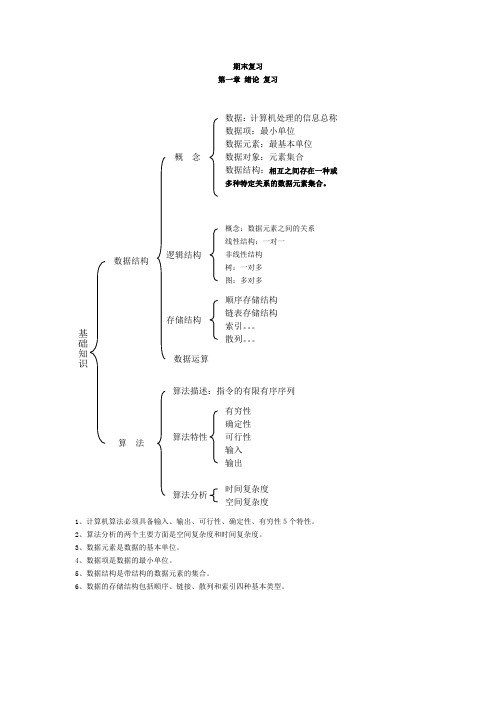
期末复习 第一章 绪论 复习1、计算机算法必须具备输入、输出、可行性、确定性、有穷性5个特性。
2、算法分析的两个主要方面是空间复杂度和时间复杂度。
3、数据元素是数据的基本单位。
4、数据项是数据的最小单位。
5、数据结构是带结构的数据元素的集合。
6、数据的存储结构包括顺序、链接、散列和索引四种基本类型。
基础知识数据结构算 法概 念逻辑结构 存储结构数据运算数据:计算机处理的信息总称 数据项:最小单位 数据元素:最基本单位数据对象:元素集合数据结构:相互之间存在一种或多种特定关系的数据元素集合。
概念:数据元素之间的关系 线性结构:一对一非线性结构 树:一对多 图:多对多顺序存储结构 链表存储结构 索引。
散列。
算法描述:指令的有限有序序列算法特性 有穷性 确定性 可行性 输入 输出 算法分析时间复杂度 空间复杂度第二章 线性表 复习1、在双链表中,每个结点有两个指针域,包括一个指向前驱结点的指针 、一个指向后继结点的指针2、线性表采用顺序存储,必须占用一片连续的存储单元3、线性表采用链式存储,便于进行插入和删除操作4、线性表采用顺序存储和链式存储优缺点比较。
5、简单算法第三章 栈和队列 复习线性表顺序存储结构链表存储结构概 念基本特点基本运算定义逻辑关系:前趋 后继节省空间 随机存取 插、删效率低 插入 删除单链表双向 链表 特点一个指针域+一个数据域 多占空间 查找费时 插、删效率高 无法查找前趋结点运算特点:单链表+前趋指针域运算插入删除循环 链表特点:单链表的尾结点指针指向附加头结点。
运算:联接1、 栈和队列的异同点。
2、 栈和队列的基本运算3、 出栈和出队4、 基本运算第四章 串 复习栈存储结构栈的概念:在一端操作的线性表 运算算法栈的特点:先进后出 LIFO初始化 进栈push 出栈pop队列顺序队列 循环队列队列概念:在两端操作的线性表 假溢出链队列队列特点:先进先出 FIFO基本运算顺序:链队:队空:front=rear队满:front=(rear+1)%MAXSIZE队空:frontrear ∧初始化 判空 进队 出队取队首元素第五章 数组和广义表 复习串存储结构运 算概 念顺序串链表串定义:由n(≥1)个字符组成的有限序列 S=”c 1c 2c 3 ……cn ”串长度、空白串、空串。
严蔚敏数据结构题集(C语言版)答案

任何的限度,都是从自己的心坎开端的。
每一奋发尽力的背地,必有加倍的弥补。
严蔚敏数据结构C语言版答案详解第1章绪论1.1 简述下列术语:数据数据元素、数据对象、数据结构、存储结构、数据类型和抽象数据类型解:数据是对客观事物的符号表示在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称数据元素是数据的基本单位在计算机程序中通常作为一个整体进行考虑和处理数据对象是性质相同的数据元素的集合是数据的一个子集数据结构是相互之间存在一种或多种特定关系的数据元素的集合存储结构是数据结构在计算机中的表示数据类型是一个值的集合和定义在这个值集上的一组操作的总称抽象数据类型是指一个数学模型以及定义在该模型上的一组操作是对一般数据类型的扩展1.2 试描述数据结构和抽象数据类型的概念与程序设计语言中数据类型概念的区别解:抽象数据类型包含一般数据类型的概念但含义比一般数据类型更广、更抽象一般数据类型由具体语言系统内部定义直接提供给编程者定义用户数据因此称它们为预定义数据类型抽象数据类型通常由编程者定义包括定义它所使用的数据和在这些数据上所进行的操作在定义抽象数据类型中的数据部分和操作部分时要求只定义到数据的逻辑结构和操作说明不考虑数据的存储结构和操作的具体实现这样抽象层次更高更能为其他用户提供良好的使用接口1.3 设有数据结构(DR)其中试按图论中图的画法惯例画出其逻辑结构图解:1.4 试仿照三元组的抽象数据类型分别写出抽象数据类型复数和有理数的定义(有理数是其分子、分母均为自然数且分母不为零的分数)解:ADT Complex{数据对象:D={ri|ri为实数}数据关系:R={<ri>}基本操作:InitComplex(&Creim)操作结果:构造一个复数C其实部和虚部分别为re和imDestroyCmoplex(&C)操作结果:销毁复数CGet(Ck&e)操作结果:用e返回复数C的第k元的值Put(&Cke)操作结果:改变复数C的第k元的值为eIsAscending(C)操作结果:如果复数C的两个元素按升序排列则返回1否则返回0IsDescending(C)操作结果:如果复数C的两个元素按降序排列则返回1否则返回0Max(C&e)操作结果:用e返回复数C的两个元素中值较大的一个Min(C&e)操作结果:用e返回复数C的两个元素中值较小的一个}ADT ComplexADT RationalNumber{数据对象:D={sm|sm为自然数且m不为0}数据关系:R={<sm>}基本操作:InitRationalNumber(&Rsm)操作结果:构造一个有理数R其分子和分母分别为s和mDestroyRationalNumber(&R)操作结果:销毁有理数RGet(Rk&e)操作结果:用e返回有理数R的第k元的值Put(&Rke)操作结果:改变有理数R的第k元的值为eIsAscending(R)操作结果:若有理数R的两个元素按升序排列则返回1否则返回0IsDescending(R)操作结果:若有理数R的两个元素按降序排列则返回1否则返回0Max(R&e)操作结果:用e返回有理数R的两个元素中值较大的一个Min(R&e)操作结果:用e返回有理数R的两个元素中值较小的一个}ADT RationalNumber1.5 试画出与下列程序段等价的框图(1) product=1; i=1;while(i<=n){product *= i;i++;}(2) i=0;do {i++;} while((i!=n) && (a[i]!=x));(3) switch {case x<y: z=y-x; break;case x=y: z=abs(x*y); break;default: z=(x-y)/abs(x)*abs(y);}1.6 在程序设计中常用下列三种不同的出错处理方式:(1) 用exit语句终止执行并报告错误;(2) 以函数的返回值区别正确返回或错误返回;(3) 设置一个整型变量的函数参数以区别正确返回或某种错误返回试讨论这三种方法各自的优缺点解:(1)exit常用于异常错误处理它可以强行中断程序的执行返回操作系统(2)以函数的返回值判断正确与否常用于子程序的测试便于实现程序的局部控制(3)用整型函数进行错误处理的优点是可以给出错误类型便于迅速确定错误1.7 在程序设计中可采用下列三种方法实现输出和输入:(1) 通过scanf和printf语句;(2) 通过函数的参数显式传递;(3) 通过全局变量隐式传递试讨论这三种方法的优缺点解:(1)用scanf和printf直接进行输入输出的好处是形象、直观但缺点是需要对其进行格式控制较为烦琐如果出现错误则会引起整个系统的崩溃(2)通过函数的参数传递进行输入输出便于实现信息的隐蔽减少出错的可能(3)通过全局变量的隐式传递进行输入输出最为方便只需修改变量的值即可但过多的全局变量使程序的维护较为困难1.8 设n为正整数试确定下列各程序段中前置以记号@的语句的频度:(1) i=1; k=0;while(i<=n-1){@ k += 10*i;i++;}(2) i=1; k=0;do {@ k += 10*i;i++;} while(i<=n-1);(3) i=1; k=0;while (i<=n-1) {i++;@ k += 10*i;}(4) k=0;for(i=1; i<=n; i++) {for(j=i; j<=n; j++)@ k++;}(5) for(i=1; i<=n; i++) {for(j=1; j<=i; j++) {for(k=1; k<=j; k++)@ x += delta;}(6) i=1; j=0;while(i+j<=n) {@ if(i>j) j++;else i++;}(7) x=n; y=0; // n是不小于1的常数while(x>=(y+1)*(y+1)) {@ y++;}(8) x=91; y=100;while(y>0) {@ if(x>100) { x -= 10; y--; }else x++;}解:(1) n-1(2) n-1(3) n-1(4) n+(n-1)+(n-2)+ (1)(5) 1+(1+2)+(1+2+3)+...+(1+2+3+...+n)===(6) n(7) 向下取整(8) 11001.9 假设n为2的乘幂并且n>2试求下列算法的时间复杂度及变量count的值(以n的函数形式表示)int Time(int n) {count = 0; x=2;while(x<n/2) {x *= 2; count++;}return count;}解:count=1.11 已知有实现同一功能的两个算法其时间复杂度分别为和假设现实计算机可连续运算的时间为秒(100多天)又每秒可执行基本操作(根据这些操作来估算算法时间复杂度)次试问在此条件下这两个算法可解问题的规模(即n值的范围)各为多少?哪个算法更适宜?请说明理由解:n=40n=16则对于同样的循环次数n在这个规模下第二种算法所花费的代价要大得多故在这个规模下第一种算法更适宜1.12 设有以下三个函数:请判断以下断言正确与否:(1) f(n)是O(g(n))(2) h(n)是O(f(n))(3) g(n)是O(h(n))(4) h(n)是O(n3.5)(5) h(n)是O(nlogn)解:(1)对 (2)错 (3)错 (4)对 (5)错1.13 试设定若干n值比较两函数和的增长趋势并确定n在什么范围内函数的值大于的值解:的增长趋势快但在n较小的时候的值较大当n>438时1.14 判断下列各对函数和当时哪个函数增长更快?(1)(2)(3)(4)解:(1)g(n)快 (2)g(n)快 (3)f(n)快 (4) f(n)快1.15 试用数学归纳法证明:(1)(2)(3)(4)1.16 试写一算法自大至小依次输出顺序读入的三个整数XY和Z的值解:int max3(int xint yint z){if(x>y)if(x>z) return x;else return z;elseif(y>z) return y;else return z;}1.17 已知k阶斐波那契序列的定义为...;试编写求k阶斐波那契序列的第m项值的函数算法k和m均以值调用的形式在函数参数表中出现解:k>0为阶数n为数列的第n项int Fibonacci(int kint n){if(k<1) exit(OVERFLOW);int *px;p=new int[k+1];if(!p) exit(OVERFLOW);int ij;for(i=0;i<k+1;i++){if(i<k-1) p[i]=0;else p[i]=1;}for(i=k+1;i<n+1;i++){x=p[0];for(j=0;j<k;j++) p[j]=p[j+1];p[k]=2*p[k-1]-x;}return p[k];}1.18 假设有ABCDE五个高等院校进行田径对抗赛各院校的单项成绩均已存入计算机并构成一张表表中每一行的形式为项目名称性别校名成绩得分编写算法处理上述表格以统计各院校的男、女总分和团体总分并输出解:typedef enum{ABCDE} SchoolName;typedef enum{FemaleMale} SexType;typedef struct{char event[3]; //项目SexType sex;SchoolName school;int score;} Component;typedef struct{int MaleSum; //男团总分int FemaleSum; //女团总分int TotalSum; //团体总分} Sum;Sum SumScore(SchoolName sn Component a[]int n){Sum temp;temp.MaleSum=0;temp.FemaleSum=0;temp.TotalSum=0;int i;for(i=0;i<n;i++){if(a[i].school==sn){if(a[i].sex==Male) temp.MaleSum+=a[i].score;if(a[i].sex==Female) temp.FemaleSum+=a[i].score;}}temp.TotalSum=temp.MaleSum+temp.FemaleSum;return temp;}1.19 试编写算法计算的值并存入数组a[0..arrsize-1]的第i-1个分量中(i=12...n)假设计算机中允许的整数最大值为maxint则当n>arrsize或对某个使时应按出错处理注意选择你认为较好的出错处理方法解:#include<iostream.h>#include<stdlib.h>#define MAXINT 65535#define ArrSize 100int fun(int i);int main(){int ik;int a[ArrSize];cout<<"Enter k:";cin>>k;if(k>ArrSize-1) exit(0);for(i=0;i<=k;i++){if(i==0) a[i]=1;else{if(2*i*a[i-1]>MAXINT) exit(0);else a[i]=2*i*a[i-1];}}for(i=0;i<=k;i++){if(a[i]>MAXINT) exit(0);else cout<<a[i]<<" ";}return 0;}1.20 试编写算法求一元多项式的值的值并确定算法中每一语句的执行次数和整个算法的时间复杂度注意选择你认为较好的输入和输出方法本题的输入为和输出为解:#include<iostream.h>#include<stdlib.h>#define N 10double polynomail(int a[]int idouble xint n);int main(){double x;int ni;int a[N];cout<<"输入变量的值x:";cin>>x;cout<<"输入多项式的阶次n:";cin>>n;if(n>N-1) exit(0);cout<<"输入多项式的系数a[0]--a[n]:";for(i=0;i<=n;i++) cin>>a[i];cout<<"The polynomail value is "<<polynomail(a nxn)<<endl;return 0;}double polynomail(int a[]int idouble xint n)if(i>0) return a[n-i]+polynomail(ai-1xn)*x;else return a[n];}本算法的时间复杂度为o(n)第2章线性表2.1 描述以下三个概念的区别:头指针头结点首元结点(第一个元素结点)解:头指针是指向链表中第一个结点的指针首元结点是指链表中存储第一个数据元素的结点头结点是在首元结点之前附设的一个结点该结点不存储数据元素其指针域指向首元结点其作用主要是为了方便对链表的操作它可以对空表、非空表以及首元结点的操作进行统一处理2.2 填空题解:(1) 在顺序表中插入或删除一个元素需要平均移动表中一半元素具体移动的元素个数与元素在表中的位置有关(2) 顺序表中逻辑上相邻的元素的物理位置必定紧邻单链表中逻辑上相邻的元素的物理位置不一定紧邻(3) 在单链表中除了首元结点外任一结点的存储位置由其前驱结点的链域的值指示(4) 在单链表中设置头结点的作用是插入和删除首元结点时不用进行特殊处理2.3 在什么情况下用顺序表比链表好?解:当线性表的数据元素在物理位置上是连续存储的时候用顺序表比用链表好其特点是可以进行随机存取2.4 对以下单链表分别执行下列各程序段并画出结果示意图解:2.5 画出执行下列各行语句后各指针及链表的示意图L=(LinkList)malloc(sizeof(LNode)); P=L;for(i=1;i<=4;i++){P->next=(LinkList)malloc(sizeof(LNode));P=P->next; P->data=i*2-1;}P->next=NULL;for(i=4;i>=1;i--) Ins_LinkList(Li+1i*2);for(i=1;i<=3;i++) Del_LinkList(Li);解:2.6 已知L是无表头结点的单链表且P结点既不是首元结点也不是尾元结点试从下列提供的答案中选择合适的语句序列a. 在P结点后插入S结点的语句序列是__________________b. 在P结点前插入S结点的语句序列是__________________c. 在表首插入S结点的语句序列是__________________d. 在表尾插入S结点的语句序列是__________________(1) P->next=S;(2) P->next=P->next->next;(3) P->next=S->next;(4) S->next=P->next;(5) S->next=L;(6) S->next=NULL;(7) Q=P;(8) while(P->next!=Q) P=P->next;(9) while(P->next!=NULL) P=P->next;(10) P=Q;(11) P=L;(12) L=S;(13) L=P;解:a. (4) (1)b. (7) (11) (8) (4) (1)c. (5) (12)d. (9) (1) (6)2.7 已知L是带表头结点的非空单链表且P结点既不是首元结点也不是尾元结点试从下列提供的答案中选择合适的语句序列a. 删除P结点的直接后继结点的语句序列是____________________b. 删除P结点的直接前驱结点的语句序列是____________________c. 删除P结点的语句序列是____________________d. 删除首元结点的语句序列是____________________e. 删除尾元结点的语句序列是____________________(1) P=P->next;(2) P->next=P;(3) P->next=P->next->next;(4) P=P->next->next;(5) while(P!=NULL) P=P->next;(6) while(Q->next!=NULL) { P=Q; Q=Q->next; }(7) while(P->next!=Q) P=P->next;(8) while(P->next->next!=Q) P=P->next;(9) while(P->next->next!=NULL) P=P->next;(10) Q=P;(11) Q=P->next;(12) P=L;(13) L=L->next;(14) free(Q);解:a. (11) (3) (14)b. (10) (12) (8) (3) (14)c. (10) (12) (7) (3) (14)d. (12) (11) (3) (14)e. (9) (11) (3) (14)2.8 已知P结点是某双向链表的中间结点试从下列提供的答案中选择合适的语句序列a. 在P结点后插入S结点的语句序列是_______________________b. 在P结点前插入S结点的语句序列是_______________________c. 删除P结点的直接后继结点的语句序列是_______________________d. 删除P结点的直接前驱结点的语句序列是_______________________e. 删除P结点的语句序列是_______________________(1) P->next=P->next->next;(2) P->priou=P->priou->priou;(3) P->next=S;(4) P->priou=S;(5) S->next=P;(6) S->priou=P;(7) S->next=P->next;(8) S->priou=P->priou;(9) P->priou->next=P->next;(10) P->priou->next=P;(11) P->next->priou=P;(12) P->next->priou=S;(13) P->priou->next=S;(14) P->next->priou=P->priou;(15) Q=P->next;(16) Q=P->priou;(17) free(P);(18) free(Q);解:a. (7) (3) (6) (12)b. (8) (4) (5) (13)c. (15) (1) (11) (18)d. (16) (2) (10) (18)e. (14) (9) (17)2.9 简述以下算法的功能(1) Status A(LinkedList L) { //L是无表头结点的单链表if(L && L->next) {Q=L; L=L->next; P=L;while(P->next) P=P->next;P->next=Q; Q->next=NULL;}return OK;}(2) void BB(LNode *sLNode *q) {p=s;while(p->next!=q) p=p->next;p->next =s;}void AA(LNode *paLNode *pb) {//pa和pb分别指向单循环链表中的两个结点BB(papb);BB(pbpa);}解:(1) 如果L的长度不小于2将L的首元结点变成尾元结点(2) 将单循环链表拆成两个单循环链表2.10 指出以下算法中的错误和低效之处并将它改写为一个既正确又高效的算法Status DeleteK(SqList &aint iint k){//本过程从顺序存储结构的线性表a中删除第i个元素起的k个元素if(i<1||k<0||i+k>a.length) return INFEASIBLE;//参数不合法else {for(count=1;count<k;count++){//删除第一个元素for(j=a.length;j>=i+1;j--) a.elem[j-i]=a.elem[j];a.length--;}return OK;}解:Status DeleteK(SqList &aint iint k){//从顺序存储结构的线性表a中删除第i个元素起的k个元素//注意i的编号从0开始int j;if(i<0||i>a.length-1||k<0||k>a.length-i) return INFEASIBLE;for(j=0;j<=k;j++)a.elem[j+i]=a.elem[j+i+k];a.length=a.length-k;return OK;}2.11 设顺序表va中的数据元素递增有序试写一算法将x插入到顺序表的适当位置上以保持该表的有序性解:Status InsertOrderList(SqList &vaElemType x){//在非递减的顺序表va中插入元素x并使其仍成为顺序表的算法int i;if(va.length==va.listsize)return(OVERFLOW);for(i=va.length;i>0x<va.elem[i-1];i--)va.elem[i]=va.elem[i-1];va.elem[i]=x;va.length++;return OK;}2.12 设和均为顺序表和分别为和中除去最大共同前缀后的子表若空表则;若=空表而空表或者两者均不为空表且的首元小于的首元则;否则试写一个比较大小的算法解:Status CompareOrderList(SqList &ASqList &B){int ikj;k=A.length>B.length?A.length:B.length;for(i=0;i<k;i++){if(A.elem[i]>B.elem[i]) j=1;if(A.elem[i]<B.elem[i]) j=-1;}if(A.length>k) j=1;if(B.length>k) j=-1;if(A.length==B.length) j=0;return j;}2.13 试写一算法在带头结点的单链表结构上实现线性表操作Locate(L x);解:int LocateElem_L(LinkList &LElemType x){int i=0;LinkList p=L;while(p&&p->data!=x){p=p->next;i++;}if(!p) return 0;else return i;}2.14 试写一算法在带头结点的单链表结构上实现线性表操作Length(L)解://返回单链表的长度int ListLength_L(LinkList &L){int i=0;LinkList p=L;if(p) p=p-next;while(p){p=p->next;i++;}return i;}2.15 已知指针ha和hb分别指向两个单链表的头结点并且已知两个链表的长度分别为m和n试写一算法将这两个链表连接在一起假设指针hc指向连接后的链表的头结点并要求算法以尽可能短的时间完成连接运算请分析你的算法的时间复杂度解:void MergeList_L(LinkList &haLinkList &hbLinkList &hc){LinkList papb;pa=ha;pb=hb;while(pa->next&&pb->next){pa=pa->next;pb=pb->next;}if(!pa->next){hc=hb;while(pb->next) pb=pb->next;pb->next=ha->next;}else{hc=ha;while(pa->next) pa=pa->next;pa->next=hb->next;}}2.16 已知指针la和lb分别指向两个无头结点单链表中的首元结点下列算法是从表la中删除自第i个元素起共len个元素后将它们插入到表lb中第i个元素之前试问此算法是否正确?若有错请改正之Status DeleteAndInsertSub(LinkedList laLinkedList lbint iint jint len){if(i<0||j<0||len<0) return INFEASIBLE;p=la; k=1;while(k<i){ p=p->next; k++; }q=p;while(k<=len){ q=q->next; k++; }s=lb; k=1;while(k<j){ s=s->next; k++; }s->next=p; q->next=s->next;return OK;}解:Status DeleteAndInsertSub(LinkList &la LinkList &lbint iint jint len){LinkList pqsprev=NULL;int k=1;if(i<0||j<0||len<0) return INFEASIBLE;// 在la表中查找第i个结点p=la;while(p&&k<i){prev=p;p=p->next;k++;}if(!p)return INFEASIBLE;// 在la表中查找第i+len-1个结点q=p; k=1;while(q&&k<len){q=p->next;k++;}if(!q)return INFEASIBLE;// 完成删除注意i=1的情况需要特殊处理if(!prev) la=q->next;else prev->next=q->next;// 将从la中删除的结点插入到lb中if(j=1){q->next=lb;lb=p;}else{s=lb; k=1;while(s&&k<j-1){s=s->next;k++;}if(!s)return INFEASIBLE;q->next=s->next;s->next=p; //完成插入}return OK;}2.17 试写一算法在无头结点的动态单链表上实现线性表操作Insert(Lib)并和在带头结点的动态单链表上实现相同操作的算法进行比较2.18试写一算法实现线性表操作Delete(Li)并和在带头结点的动态单链表上实现相同操作的算法进行比较2.19 已知线性表中的元素以值递增有序排列并以单链表作存储结构试写一高效的算法删除表中所有值大于mink且小于maxk的元素(若表中存在这样的元素)同时释放被删结点空间并分析你的算法的时间复杂度(注意mink和maxk是给定的两个参变量它们的值可以和表中的元素相同也可以不同)解:Status ListDelete_L(LinkList &LElemType minkElemType maxk){LinkList pqprev=NULL;if(mink>maxk)return ERROR;p=L;prev=p;p=p->next;while(p&&p->data<maxk){if(p->data<=mink){prev=p;p=p->next;}else{prev->next=p->next;q=p;p=p->next;free(q);}}return OK;}2.20 同2.19题条件试写一高效的算法删除表中所有值相同的多余元素(使得操作后的线性表中所有元素的值均不相同)同时释放被删结点空间并分析你的算法的时间复杂度解:void ListDelete_LSameNode(LinkList &L){LinkList pqprev;p=L;prev=p;p=p->next;while(p){prev=p;p=p->next;if(p&&p->data==prev->data){prev->next=p->next;q=p;p=p->next;free(q);}}}2.21 试写一算法实现顺序表的就地逆置即利用原表的存储空间将线性表逆置为解:// 顺序表的逆置Status ListOppose_Sq(SqList &L){int i;ElemType x;for(i=0;i<L.length/2;i++){x=L.elem[i];L.elem[i]=L.elem[L.length-1-i];L.elem[L.length-1-i]=x;}return OK;}2.22 试写一算法对单链表实现就地逆置解:// 带头结点的单链表的逆置Status ListOppose_L(LinkList &L){LinkList pq;p=L;p=p->next;L->next=NULL;while(p){q=p;p=p->next;q->next=L->next;L->next=q;}return OK;}2.23 设线性表试写一个按下列规则合并AB为线性表C的算法即使得当时;当时线性表AB和C均以单链表作存储结构且C表利用A表和B表中的结点空间构成注意:单链表的长度值m和n均未显式存储解:// 将合并后的结果放在C表中并删除B表Status ListMerge_L(LinkList &ALinkList &BLinkList &C){LinkList papbqaqb;pa=A->next;pb=B->next;C=A;while(pa&&pb){qa=pa; qb=pb;pa=pa->next; pb=pb->next;qb->next=qa->next;qa->next=qb;}if(!pa)qb->next=pb;pb=B;free(pb);return OK;}2.24 假设有两个按元素值递增有序排列的线性表A和B均以单链表作存储结构请编写算法将A表和B表归并成一个按元素值递减有序(即非递增有序允许表中含有值相同的元素)排列的线性表C并要求利用原表(即A表和B表)的结点空间构造C表解:// 将合并逆置后的结果放在C表中并删除B表Status ListMergeOppose_L(LinkList &ALinkList &BLinkList &C){LinkList papbqaqb;pa=A;pb=B;qa=pa; // 保存pa的前驱指针qb=pb; // 保存pb的前驱指针pa=pa->next;pb=pb->next;A->next=NULL;C=A;while(pa&&pb){if(pa->data<pb->data){qa=pa;pa=pa->next;qa->next=A->next; //将当前最小结点插入A表表头A->next=qa;}else{qb=pb;pb=pb->next;qb->next=A->next; //将当前最小结点插入A表表头A->next=qb;}}while(pa){qa=pa;pa=pa->next;qa->next=A->next;A->next=qa;}while(pb){qb=pb;pb=pb->next;qb->next=A->next;A->next=qb;}pb=B;free(pb);return OK;}2.25 假设以两个元素依值递增有序排列的线性表A和B分别表示两个集合(即同一表中的元素值各不相同)现要求另辟空间构成一个线性表C其元素为A和B中元素的交集且表C中的元素有依值递增有序排列试对顺序表编写求C的算法解:// 将A、B求交后的结果放在C表中Status ListCross_Sq(SqList &ASqList &BSqList &C){int i=0j=0k=0;while(i<A.length && j<B.length){if(A.elem[i]<B.elem[j]) i++;elseif(A.elem[i]>B.elem[j]) j++;else{ListInsert_Sq(CkA.elem[i]);i++;k++;}}return OK;}2.26 要求同2.25题试对单链表编写求C的算法解:// 将A、B求交后的结果放在C表中并删除B表Status ListCross_L(LinkList &ALinkList &BLinkList &C){LinkList papbqaqbpt;pa=A;pb=B;qa=pa; // 保存pa的前驱指针qb=pb; // 保存pb的前驱指针pa=pa->next;pb=pb->next;C=A;while(pa&&pb){if(pa->data<pb->data){pt=pa;pa=pa->next;qa->next=pa;free(pt);}elseif(pa->data>pb->data){pt=pb;pb=pb->next;qb->next=pb;free(pt);}else{qa=pa;pa=pa->next;}}while(pa){pt=pa;pa=pa->next;qa->next=pa;free(pt);}while(pb){pt=pb;pb=pb->next;qb->next=pb;free(pt);}pb=B;free(pb);return OK;}2.27 对2.25题的条件作以下两点修改对顺序表重新编写求得表C的算法(1) 假设在同一表(A或B)中可能存在值相同的元素但要求新生成的表C中的元素值各不相同;(2) 利用A表空间存放表C解:(1)// A、B求交然后删除相同元素将结果放在C表中Status ListCrossDelSame_Sq(SqList &ASqList &BSqList &C){int i=0j=0k=0;while(i<A.length && j<B.length){if(A.elem[i]<B.elem[j]) i++;elseif(A.elem[i]>B.elem[j]) j++;else{if(C.length==0){ListInsert_Sq(CkA.elem[i]);k++;}elseif(C.elem[C.length-1]!=A.elem[i]){ListInsert_Sq(CkA.elem[i]);k++;}i++;}}return OK;}(2)// A、B求交然后删除相同元素将结果放在A表中Status ListCrossDelSame_Sq(SqList &ASqList &B){int i=0j=0k=0;while(i<A.length && j<B.length){if(A.elem[i]<B.elem[j]) i++;elseif(A.elem[i]>B.elem[j]) j++;else{if(k==0){A.elem[k]=A.elem[i];k++;}elseif(A.elem[k]!=A.elem[i]){A.elem[k]=A.elem[i];k++;}i++;}}A.length=k;return OK;}2.28 对2.25题的条件作以下两点修改对单链表重新编写求得表C的算法(1) 假设在同一表(A或B)中可能存在值相同的元素但要求新生成的表C中的元素值各不相同;(2) 利用原表(A表或B表)中的结点构成表C并释放A表中的无用结点空间解:(1)// A、B求交结果放在C表中并删除相同元素Status ListCrossDelSame_L(LinkList &ALinkList &BLinkList &C){LinkList papbqaqbpt;pa=A;pb=B;qa=pa; // 保存pa的前驱指针qb=pb; // 保存pb的前驱指针pa=pa->next;pb=pb->next;C=A;while(pa&&pb){if(pa->data<pb->data){pt=pa;pa=pa->next;qa->next=pa;free(pt);}elseif(pa->data>pb->data){pt=pb;pb=pb->next;qb->next=pb;free(pt);}else{if(pa->data==qa->data){pt=pa;pa=pa->next;qa->next=pa;free(pt);}else{qa=pa;pa=pa->next;}}}while(pa){pt=pa;pa=pa->next;qa->next=pa;free(pt);}while(pb){pt=pb;pb=pb->next;qb->next=pb;free(pt);}pb=B;free(pb);return OK;}(2)// A、B求交结果放在A表中并删除相同元素Status ListCrossDelSame_L(LinkList &A LinkList &B){LinkList papbqaqbpt;pa=A;pb=B;qa=pa; // 保存pa的前驱指针qb=pb; // 保存pb的前驱指针pa=pa->next;pb=pb->next;while(pa&&pb){if(pa->data<pb->data){pt=pa;pa=pa->next;qa->next=pa;free(pt);}elseif(pa->data>pb->data){pt=pb;pb=pb->next;qb->next=pb;free(pt);}else{if(pa->data==qa->data){pt=pa;pa=pa->next;qa->next=pa;free(pt);}else{qa=pa;pa=pa->next;}}}while(pa){pt=pa;pa=pa->next;qa->next=pa;free(pt);}while(pb){pt=pb;pb=pb->next;qb->next=pb;free(pt);}pb=B;free(pb);return OK;}2.29 已知AB和C为三个递增有序的线性表现要求对A表作如下操作:删去那些既在B表中出现又在C表中出现的元素试对顺序表编写实现上述操作的算法并分析你的算法的时间复杂度(注意:题中没有特别指明同一表中的元素值各不相同)解:// 在A中删除既在B中出现又在C中出现的元素结果放在D中Status ListUnion_Sq(SqList &DSqList &ASqList &BSqList &C){SqList Temp;InitList_Sq(Temp);ListCross_L(BCTemp);ListMinus_L(ATempD);}2.30 要求同2.29题试对单链表编写算法请释放A表中的无用结点空间解:// 在A中删除既在B中出现又在C中出现的元素并释放B、CStatus ListUnion_L(LinkList &ALinkList &BLinkList &C){ListCross_L(BC);ListMinus_L(AB);}// 求集合A-B结果放在A表中并删除B表Status ListMinus_L(LinkList &ALinkList &B){LinkList papbqaqbpt;pa=A;pb=B;qa=pa; // 保存pa的前驱指针qb=pb; // 保存pb的前驱指针pa=pa->next;pb=pb->next;while(pa&&pb){if(pb->data<pa->data){pt=pb;pb=pb->next;qb->next=pb;free(pt);}elseif(pb->data>pa->data){qa=pa;pa=pa->next;}else{pt=pa;pa=pa->next;qa->next=pa;free(pt);}}while(pb){pt=pb;pb=pb->next;qb->next=pb;free(pt);}pb=B;free(pb);return OK;}2.31 假设某个单向循环链表的长度大于1且表中既无头结点也无头指针已知s为指向链表中某个结点的指针试编写算法在链表中删除指针s所指结点的前驱结点解:// 在单循环链表S中删除S的前驱结点Status ListDelete_CL(LinkList &S){LinkList pq;if(S==S->next)return ERROR;q=S;p=S->next;while(p->next!=S){q=p;p=p->next;}q->next=p->next;free(p);return OK;}2.32 已知有一个单向循环链表其每个结点中含三个域:predata和next其中data为数据域next为指向后继结点的指针域pre也为指针域但它的值为空试编写算法将此单向循环链表改为双向循环链表即使pre成为指向前驱结点的指针域解:// 建立一个空的循环链表Status InitList_DL(DuLinkList &L){L=(DuLinkList)malloc(sizeof(DuLNode));if(!L) exit(OVERFLOW);L->pre=NULL;L->next=L;return OK;}// 向循环链表中插入一个结点Status ListInsert_DL(DuLinkList &L ElemType e){DuLinkList p;p=(DuLinkList)malloc(sizeof(DuLNode));if(!p) return ERROR;p->data=e;p->next=L->next;L->next=p;return OK;}// 将单循环链表改成双向链表Status ListCirToDu(DuLinkList &L){DuLinkList pq;q=L;p=L->next;while(p!=L){p->pre=q;q=p;}if(p==L) p->pre=q;return OK;}2.33 已知由一个线性链表表示的线性表中含有三类字符的数据元素(如:字母字符、数字字符和其他字符)试编写算法将该线性表分割为三个循环链表其中每个循环链表表示的线性表中均只含一类字符解:// 将单链表L划分成3个单循环链表Status ListDivideInto3CL(LinkList &LLinkList &s1LinkList &s2LinkList &s3){LinkList pqpt1pt2pt3;p=L->next;pt1=s1;pt2=s2;pt3=s3;while(p){if(p->data>='0' && p->data<='9'){q=p;p=p->next;q->next=pt1->next;pt1->next=q;pt1=pt1->next;}elseif((p->data>='A' && p->data<='Z') ||(p->data>='a' && p->data<='z')){q=p;p=p->next;q->next=pt2->next;pt2->next=q;pt2=pt2->next;}else{p=p->next;q->next=pt3->next;pt3->next=q;pt3=pt3->next;}}q=L;free(q);return OK;}在2.34至2.36题中"异或指针双向链表"类型XorLinkedList和指针异或函数XorP定义为:typedef struct XorNode {char data;struct XorNode *LRPtr;} XorNode*XorPointer;typede struct { //无头结点的异或指针双向链表XorPointer LeftRight; //分别指向链表的左侧和右端} XorLinkedList;XorPointer XorP(XorPointer pXorPointer q);// 指针异或函数XorP返回指针p和q的异或值2.34 假设在算法描述语言中引入指针的二元运算"异或"若a和b为指针则a⊕b的运算结果仍为原指针类型且a⊕(a⊕b)=(a⊕a)⊕b=b(a⊕b)⊕b=a⊕(b⊕b)=a则可利用一个指针域来实现双向链表L链表L中的每个结点只含两个域:data域和LRPtr域其中LRPtr域存放该结点的左邻与右邻结点指针(不存在时为NULL)的异或若设指针L.Left指向链表中的最左结点L.Right指向链表中的最右结点则可实现从左向右或从右向左遍历此双向链表的操作试写一算法按任一方向依次输出链表中各元素的值解:Status TraversingLinkList(XorLinkedList &Lchar d){XorPointer pright;if(d=='l'||d=='L'){p=L.Left;left=NULL;while(p!=NULL){VisitingData(p->data);left=p;p=XorP(leftp->LRPtr);}}elseif(d=='r'||d=='R'){p=L.Right;right=NULL;while(p!=NULL){VisitingData(p->data);right=p;p=XorP(p->LRPtrright);}}else return ERROR;return OK;}2.35 采用2.34题所述的存储结构写出在第i个结点之前插入一个结点的算法2.36 采用2.34题所述的存储结构写出删除第i个结点的算法2.37 设以带头结点的双向循环链表表示的线性表试写一时间复杂度O(n)的算法将L改造为解:// 将双向链表L=(a1a2...an)改造为(a1a3...an。
严蔚敏版数据结构题集(C语言版)完整答案

严蔚敏 数据结构C 语言版答案详解第1章 绪论1.1 简述下列术语:数据,数据元素、数据对象、数据结构、存储结构、数据类型和抽象数据类型。
解:数据是对客观事物的符号表示。
在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。
数据元素是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
数据对象是性质相同的数据元素的集合,是数据的一个子集。
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。
存储结构是数据结构在计算机中的表示。
数据类型是一个值的集合和定义在这个值集上的一组操作的总称。
抽象数据类型是指一个数学模型以及定义在该模型上的一组操作。
是对一般数据类型的扩展。
1.2 试描述数据结构和抽象数据类型的概念与程序设计语言中数据类型概念的区别。
解:抽象数据类型包含一般数据类型的概念,但含义比一般数据类型更广、更抽象。
一般数据类型由具体语言系统内部定义,直接提供给编程者定义用户数据,因此称它们为预定义数据类型。
抽象数据类型通常由编程者定义,包括定义它所使用的数据和在这些数据上所进行的操作。
在定义抽象数据类型中的数据部分和操作部分时,要求只定义到数据的逻辑结构和操作说明,不考虑数据的存储结构和操作的具体实现,这样抽象层次更高,更能为其他用户提供良好的使用接口。
1.3 设有数据结构(D,R),其中{}4,3,2,1d d d d D =,{}r R =,()()(){}4,3,3,2,2,1d d d d d d r =试按图论中图的画法惯例画出其逻辑结构图。
解:1.4 试仿照三元组的抽象数据类型分别写出抽象数据类型复数和有理数的定义(有理数是其分子、分母均为自然数且分母不为零的分数)。
解:ADT Complex{ 数据对象:D={r,i|r,i 为实数} 数据关系:R={<r,i>} 基本操作: InitComplex(&C,re,im)操作结果:构造一个复数C ,其实部和虚部分别为re 和im DestroyCmoplex(&C)操作结果:销毁复数C Get(C,k,&e)操作结果:用e 返回复数C 的第k 元的值Put(&C,k,e)操作结果:改变复数C的第k元的值为eIsAscending(C)操作结果:如果复数C的两个元素按升序排列,则返回1,否则返回0 IsDescending(C)操作结果:如果复数C的两个元素按降序排列,则返回1,否则返回0 Max(C,&e)操作结果:用e返回复数C的两个元素中值较大的一个Min(C,&e)操作结果:用e返回复数C的两个元素中值较小的一个}ADT ComplexADT RationalNumber{数据对象:D={s,m|s,m为自然数,且m不为0}数据关系:R={<s,m>}基本操作:InitRationalNumber(&R,s,m)操作结果:构造一个有理数R,其分子和分母分别为s和mDestroyRationalNumber(&R)操作结果:销毁有理数RGet(R,k,&e)操作结果:用e返回有理数R的第k元的值Put(&R,k,e)操作结果:改变有理数R的第k元的值为eIsAscending(R)操作结果:若有理数R的两个元素按升序排列,则返回1,否则返回0 IsDescending(R)操作结果:若有理数R的两个元素按降序排列,则返回1,否则返回0 Max(R,&e)操作结果:用e返回有理数R的两个元素中值较大的一个Min(R,&e)操作结果:用e返回有理数R的两个元素中值较小的一个}ADT RationalNumber1.5 试画出与下列程序段等价的框图。
数据结构(C语言版)清华大学出版社 严蔚敏 吴伟民

吉首大学题库一、一、单选题(每题 2 分,共20分)1. 1.对一个算法的评价,不包括如下()方面的内容。
A.健壮性和可读性B.并行性C.正确性D.时空复杂度2. 2.在带有头结点的单链表HL中,要向表头插入一个由指针p指向的结点,则执行( )。
A. p->next=HL->next; HL->next=p;B. p->next=HL; HL=p;C. p->next=HL; p=HL;D. HL=p; p->next=HL;3. 3.对线性表,在下列哪种情况下应当采用链表表示?( )A.经常需要随机地存取元素B.经常需要进行插入和删除操作C.表中元素需要占据一片连续的存储空间D.表中元素的个数不变4. 4.一个栈的输入序列为1 2 3,则下列序列中不可能是栈的输出序列的是( )A. 2 3 1B. 3 2 1C. 3 1 2D. 1 2 35. 5.AOV网是一种()。
A.有向图B.无向图C.无向无环图D.有向无环图6. 6.采用开放定址法处理散列表的冲突时,其平均查找长度()。
A.低于链接法处理冲突 B. 高于链接法处理冲突C.与链接法处理冲突相同D.高于二分查找7.7.若需要利用形参直接访问实参时,应将形参变量说明为()参数。
A.值B.函数C.指针D.引用8.8.在稀疏矩阵的带行指针向量的链接存储中,每个单链表中的结点都具有相同的()。
A.行号B.列号C.元素值D.非零元素个数9.9.快速排序在最坏情况下的时间复杂度为()。
A.O(log2n) B.O(nlog2n) C.0(n) D.0(n2)10.10.从二叉搜索树中查找一个元素时,其时间复杂度大致为( )。
A. O(n)B. O(1)C. O(log2n)D. O(n2)二、二、运算题(每题 6 分,共24分)1. 1.数据结构是指数据及其相互之间的______________。
当结点之间存在M对N(M:N)的联系时,称这种结构为_____________________。
数据结构(C语言版)(严蔚敏)
31
4、效率与低存储量需求 、
通常,效率指的是算法执行时间;存储量指的是 算法执行过程中所需要的最大存储空间。两者都 与问题的规模有关。
32
算法效率的衡量方法和准则
通常有两种衡量算法效率的方法: 事后统计法 缺点:1、必须执行程序 2、其它因素掩盖算法本质 事后分析估算法 和算法执行时间相关的因素: 1算法选用的策略 2、问题的规模 3、编写程序的语言 4、编译程序产生的机器代码的质量 5、计算机执行指令的速度
5
–例
书目自动检索系统
线性表
书目文件
书目卡片 001 高等数学 樊映川 002 理论力学 罗远祥 登录号: 003 高等数学 华罗庚 004 书名: 线性代数 栾汝书 …… 作者名: …… ……
按书名
高等数学 理论力学 线性代数 ……
S01 L01 S01 S02 ……
索引表
按分类号
分类号: 001, 003… … 樊映川 出版单位: 002, … … .. 华罗庚 出版时间: 004, … … 栾汝书 价格: … … ..
29
2、可读性 、
算法主要是为了人的阅读与交流,其次才是为计 算机执行。因此算法应该易于人的理解;另一方 面,晦涩难读的程序易于隐藏较多错误而难以调 试;
30
3.健壮性 健壮性
当输入的数据非法时,算法应当恰当地作出反映 或进行相应处理,而不是产生莫名奇妙的输出结 果。并且,处理出错的方法不应是中断程序的执 行,而应是返回一个表示错误或错误性质的值, 以便在更高的抽象层次上进行处理。
23
1.3 算法和算法分析
算法的概念和描述: 算法的概念和描述: 什么是算法? 什么是算法? 算法( 算法(Algorithm)是为了解决某类问题而规定的一 是为了解决某类问题而规定的一 个有限长的操作序列。 个有限长的操作序列。一个算法必须满足以下五 个重要特性: 个重要特性:
数据结构(C)严蔚敏——3
Data Structure
2011-1-13
Page 4
串与线性表区别 串的数据对象约束为字符集。 串的数据对象约束为字符集。 字符集 串的基本操作与线性表有很大差别 串的基本操作与线性表有很大差别 基本操作
线性表的基本操作中,大多以“单个元素”作为操作对象, 线性表的基本操作中,大多以“单个元素”作为操作对象,如 查找某个元素、在某个位置上插入一个元素和删除一个元素。 查找某个元素、在某个位置上插入一个元素和删除一个元素。 串的基本操作中,通常以“串的整体”作为操作对象。 串的基本操作中,通常以“串的整体”作为操作对象。如在串 中查找某个子串、 中查找某个子串、在串的某个位置上插入一个子串以及删除一 个子串。 个子串。
Data Structure
2011-1-13
Page 12
定长顺序存储表示串操作的实现: 定长顺序存储表示串操作的实现:
设串的最大长度为10, 设串的最大长度为10, 10 S1=‘ABCDEF ABCDEF’ S1= ABCDEF S2=‘GHIJ GHIJ’ S2= GHIJ S3=‘KLMNOP KLMNOP’ S3= KLMNOP S4=‘QRSTUVWXYZ QRSTUVWXYZ’ S4= QRSTUVWXYZ S1连接S2,结果‘ABCDEFGHIJ 。 S1连接S2,结果‘ABCDEFGHIJ’。 连接S2 S1连接S3,结果‘ABCDEFKLMN’,S3的‘OP’部分被截断。 S1连接S3,结果‘ABCDEFKLMN ,S3的 OP 部分被截断。 连接S3 部分被截断 S4连接S1,结果‘QRSTUVWXYZ ,S1全部被截断 全部被截断。 S4连接S1,结果‘QRSTUVWXYZ’,S1全部被截断。 连接S1
由于我们现今使用的计算机的硬件结构主要是面向数值计 算的需要,基本上没有提供对串进行操作的指令,因此需 算的需要,基本上没有提供对串进行操作的指令, 用软件来实现串数据类型。 要用软件来实现串数据类型。
数据结构C语言版第版习题答案—严蔚敏简化版
数据结构C语言版第版习题答案—严蔚敏简化版 The following text is amended on 12 November 2020.第2章线性表1.选择题(1)顺序表中第一个元素的存储地址是100,每个元素的长度为2,则第5个元素的地址是()。
A.110 B.108 C.100 D.120答案:B解释:顺序表中的数据连续存储,所以第5个元素的地址为:100+2*4=108。
(3)向一个有127个元素的顺序表中插入一个新元素并保持原来顺序不变,平均要移动的元素个数为()。
A.8 B. C.63 D.7答案:B解释:平均要移动的元素个数为:n/2。
(4)链接存储的存储结构所占存储空间()。
A.分两部分,一部分存放结点值,另一部分存放表示结点间关系的指针B.只有一部分,存放结点值C.只有一部分,存储表示结点间关系的指针D.分两部分,一部分存放结点值,另一部分存放结点所占单元数答案:A(5)线性表若采用链式存储结构时,要求内存中可用存储单元的地址()。
A.必须是连续的 B.部分地址必须是连续的C.一定是不连续的 D.连续或不连续都可以答案:D(6)线性表L在()情况下适用于使用链式结构实现。
A.需经常修改L中的结点值B.需不断对L进行删除插入C.L中含有大量的结点D.L中结点结构复杂答案:B解释:链表最大的优点在于插入和删除时不需要移动数据,直接修改指针即可。
(7)单链表的存储密度()。
A.大于1 B.等于1 C.小于1 D.不能确定答案:C解释:存储密度是指一个结点数据本身所占的存储空间和整个结点所占的存储空间之比,假设单链表一个结点本身所占的空间为D,指针域所占的空间为N,则存储密度为:D/(D+N),一定小于1。
(8)将两个各有n个元素的有序表归并成一个有序表,其最少的比较次数是()。
A.n B.2n-1 C.2n D.n-1答案:A解释:当第一个有序表中所有的元素都小于(或大于)第二个表中的元素,只需要用第二个表中的第一个元素依次与第一个表的元素比较,总计比较n次。
数据结构c语言版严蔚敏课后习题答案
数据结构c语言版严蔚敏课后习题答案数据结构是计算机科学中的一个重要领域,它涉及到数据的组织、管理和存储方式,以便可以高效地访问和修改数据。
C语言作为一种广泛使用的编程语言,提供了丰富的数据结构实现方法。
严蔚敏教授编写的《数据结构(C语言版)》是许多计算机专业学生的必读教材。
以下是对该书课后习题的一些参考答案,供学习者参考。
第一章:绪论1. 数据结构的定义:数据结构是计算机中存储、组织数据的方式,它不仅包括数据元素的类型和关系,还包括数据操作的函数。
2. 数据结构的重要性:数据结构对于提高程序的效率至关重要。
合理的数据结构可以减少算法的时间复杂度和空间复杂度。
第二章:线性表1. 线性表的定义:线性表是由n个元素组成的有限序列,其中n称为线性表的长度。
2. 线性表的顺序存储结构:使用数组来存储线性表的元素,元素的存储关系是连续的。
3. 线性表的链式存储结构:使用链表来存储线性表的元素,每个元素包含数据部分和指向下一个元素的指针。
第三章:栈和队列1. 栈的定义:栈是一种特殊的线性表,只能在一端(栈顶)进行插入和删除操作。
2. 队列的定义:队列是一种特殊的线性表,允许在一端(队尾)进行插入操作,在另一端(队首)进行删除操作。
第四章:串1. 串的定义:串是由零个或多个字符组成的有限序列。
2. 串的存储结构:串可以采用顺序存储结构或链式存储结构。
第五章:数组和广义表1. 数组的定义:数组是由具有相同类型的多个元素组成的集合,这些元素按照索引顺序排列。
2. 广义表的定义:广义表是线性表的推广,其中的元素可以是数据也可以是子表。
第六章:树和二叉树1. 树的定义:树是由节点组成的,其中有一个特定的节点称为根,其余每个节点有且仅有一个父节点。
2. 二叉树的定义:二叉树是每个节点最多有两个子节点的树。
第七章:图1. 图的定义:图是由顶点和边组成的数据结构,可以表示复杂的关系。
2. 图的存储结构:图可以用邻接矩阵或邻接表来存储。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一章概论1.数据:信息的载体,能被计算机识别、存储和加工处理。
2.数据元素:数据的基本单位,可由若干个数据项组成,数据项是具有独立含义的最小标识单位。
3.数据结构:数据之间的相互关系,即数据的组织形式。
它包括:1)数据的逻辑结构,从逻辑关系上描述数据,与数据存储无关,独立于计算机;2)数据的存储结构,是逻辑结构用计算机语言的实现,依赖于计算机语言。
3)数据的运算,定义在逻辑结构上,每种逻辑结构都有一个运算集合。
常用的运算:检索/插入/删除/更新/排序。
4.数据的逻辑结构可以看作是从具体问题抽象出来的数学模型。
数据的存储结构是逻辑结构用计算机语言的实现。
5.数据类型:一个值的集合及在值上定义的一组操作的总称。
分为:原子类型和结构类型。
6.抽象数据类型:抽象数据的组织和与之相关的操作。
优点:将数据和操作封装在一起实现了信息隐藏。
7. 抽象数据类型ADT:是在概念层上描述问题;类:是在实现层上描述问题;在应用层上操作对象(类的实例)解决问题。
8.数据的逻辑结构,简称为数据结构,有:(1)线性结构,若结构是非空集则仅有一个开始和终端结点,并且所有结点最多只有一个直接前趋和后继。
(2)非线性结构,一个结点可能有多个直接前趋和后继。
9.数据的存储结构有:1)顺序存储,把逻辑相邻的结点存储在物理上相邻的存储单元内。
2)链接存储,结点间的逻辑关系由附加指针字段表示。
3)索引存储,存储结点信息的同时,建立附加索引表,有稠密索引和稀疏索引。
4)散列存储,按结点的关键字直接计算出存储地址。
10.评价算法的好坏是:算法是正确的;执行算法所耗的时间;执行算法的存储空间(辅助存储空间);易于理解、编码、调试。
11.算法的时间复杂度T(n):是该算法的时间耗费,是求解问题规模n的函数。
记为O(n)。
时间复杂度按数量级递增排列依次为:常数阶O(1)、对数阶O(log2n)、线性阶O(n)、线性对数阶O(nlog2n)、平方阶O(n^2)、立方阶O(n^3)、……k次方阶O(n^k)、指数阶O(2^n)。
13.算法的空间复杂度S(n):是该算法的空间耗费,是求解问题规模n的函数。
12.算法衡量:是用时间复杂度和空间复杂度来衡量的,它们合称算法的复杂度。
13. 算法中语句的频度不仅与问题规模有关,还与输入实例中各元素的取值相关。
第二章线性表1.线性表:是由n(n≥0)个数据元素组成的有限序列。
2.线性表的基本运算有:1)InitList(L),构造空表,即表的初始化;2)ListLength(L),求表的结点个数,即表长;3)GetNode(L,i),取表中第i个结点,要求1≤i≤ListLength(L);4)LocateNode(L,x)查找L中值为x的结点并返回结点在L中的位置,有多个x则返回首个,没有则返回特殊值表示查找失败。
5)InsertList(L,x,i)在表的第i个位置插入值为x的新结点,要求1≤i≤ListLength(L)+1;6)DeleteList(L,i)删除表的第i个位置的结点,要求1≤i≤ListLength(L);3.顺序表:把线性表的结点按逻辑次序存放在一组地址连续的存储单元里。
4.顺序表结点的存储地址计算公式:Loc(ai)=Loc(a1)+(i-1)*C;1≤i≤n5.顺序表上的基本运算(1)插入void insertlist(seqlist *L,datatype x,int i){int j;if(i<1||i>L->length+1)error(“position error”);if(L->length>=listsize)error(“overflow”);for(j=L->length-1;j>=i-1;j--)L->data[j+1]=L->data[j]; 结点后移L->data[i-1]=x;L->length++;}在顺序表上插入要移动表的n/2结点,算法的平均时间复杂度为O(n)。
(2)删除void delete (seqlist *L,int i){int j;if(i<1||i>L->length)error(“position error”);for(j=i;j<=L->length-1;j++)L->data[j-1]=L->data[j]; 结点前移L->length--;}在顺序表上删除要移动表的(n+1)/2结点,算法的平均时间复杂度为O(n)。
6.单链表:只有一个链域的链表称单链表。
在结点中存储结点值和结点的后继结点的地址,data next data是数据域,next是指针域。
(1)建立单链表。
时间复杂度为O(n)。
加头结点的优点:1)链表第一个位置的操作无需特殊处理;2)将空表和非空表的处理统一。
(2)查找运算。
时间复杂度为O(n)。
1)按序号查找。
Listnode * getnode(linklist head,int i){int j;listnode *p;p=head;j=0;while(p->next&&j<i){p=p->next; 指针下移j++;}if(i==j)return p;elsereturn NULL;}2)按值查找。
Listnode * locatenode(linklist head ,datatype key) {listnode *p=head->next;while(p&&p->data!=key)p=p->next;return p;}(3)插入运算。
时间复杂度为O(n)。
Void insertlist(linklist head ,datatype x, int i) {listnode *p;p=getnode(head,i-1);if(p==NULL);error(“position error”);s=(listnode *)malloc(sizeof(listnode));s->data=x;s->next=p->next;p->next=s;}(4)删除运算。
时间复杂度为O(n)。
Void deletelist(linklist head ,int i){listnode *p ,*r;p=getnode(head ,i-1);if(p==NULL||p->next==NULL)error(“position error”);r=p->next;p->next=r->next;free(r);}7.循环链表:是一种首尾相连的链表。
特点是无需增加存储量,仅对表的链接方式修改使表的处理灵活方便。
8.空循环链表仅由一个自成循环的头结点表示。
9.很多时候表的操作是在表的首尾位置上进行,此时头指针表示的单循环链表就显的不够方便,改用尾指针rear来表示单循环链表。
用头指针表示的单循环链表查找开始结点的时间是O(1),查找尾结点的时间是O(n);用尾指针表示的单循环链表查找开始结点和尾结点的时间都是O (1)。
10.在结点中增加一个指针域,prior|data|next。
形成的链表中有两条不同方向的链称为双链表。
1) 双链表的前插操作。
时间复杂度为O(1)。
Void dinsertbefore(dlistnode *p ,datatype x){dlistnode *s=malloc(sizeof(dlistnode));s->data=x;s->prior=p->prior;s->next=p;p->prior->next=s;p->prior=s;}2) 双链表的删除操作。
时间复杂度为O(1)。
Void ddeletenode(dlistnode *p){p->prior->next=p->next;p->next->prior=p->prior;free(p);}11.顺序表和链表的比较1)基于空间的考虑:顺序表的存储空间是静态分配的,链表的存储空间是动态分配的。
顺序表的存储密度比链表大。
因此,在线性表长度变化不大,易于事先确定时,宜采用顺序表作为存储结构。
2)基于时间的考虑:顺序表是随机存取结构,若线性表的操作主要是查找,很少有插入、删除操作时,宜用顺序表结构。
对频繁进行插入、删除操作的线性表宜采用链表。
若操作主要发生在表的首尾时采用尾指针表示的单循环链表。
12.存储密度=(结点数据本身所占的存储量)/(整个结点结构所占的存储总量)存储密度:顺序表=1,链表<1。
第三章栈和队列1.栈是限制仅在表的一端进行插入和删除运算的线性表又称为后进先出表(LIFO表)。
插入、删除端称为栈顶,另一端称栈底。
表中无元素称空栈。
2.栈的基本运算有:1)initstack(s),构造一个空栈;2)stackempty(s),判栈空;3)stackfull(s),判栈满;4)push(s,x),进栈;5)pop (s),退栈;6)stacktop(s),取栈顶元素。
3.顺序栈:栈的顺序存储结构称顺序栈。
4.当栈满时,做进栈运算必定产生空间溢出,称“上溢”。
当栈空时,做退栈运算必定产生空间溢出,称“下溢”。
上溢是一种错误应设法避免,下溢常用作程序控制转移的条件。
5.在顺序栈上的基本运算:1)置空栈。
Void initstack(seqstack *s){s->top=-1;}2)判栈空。
int stackempty(seqstack *s){return s->top==-1;}3)判栈满。
int stackfull(seqstack *s){return s->top==stacksize-1;}4)进栈。
Void push(seqstack *s,datatype x){if(stackfull(s))error(“stack overflow”);s->data[++s->top]=x;}5)退栈。
Datatype pop(seqstack *s){if(stackempty(s))error(“stack underflow”);return S->data[s->top--];}6)取栈顶元素。
Dtatatype stacktop(seqstack *s){if(stackempty(s))error(“stack underflow”);return S->data[s->top];}6.链栈:栈的链式存储结构称链栈。