3-时序数据分析解析
金融时序数据分析报告(3篇)

第1篇一、引言随着金融市场的快速发展,数据已成为金融行业的重要资产。
时序数据分析作为金融数据分析的核心方法之一,通过对金融时间序列数据的分析,可以帮助我们理解市场趋势、预测未来走势,从而为投资决策提供科学依据。
本报告旨在通过对某金融时间序列数据的分析,揭示市场规律,为投资者提供参考。
二、数据来源与处理1. 数据来源本报告所使用的数据来源于某金融交易所,包括股票、债券、期货等金融产品的历史价格、成交量、市场指数等数据。
数据时间跨度为过去五年,数据频率为每日。
2. 数据处理(1)数据清洗:对数据进行初步清洗,剔除异常值和缺失值。
(2)数据转换:将原始数据转换为适合时序分析的形式,如对数变换、标准化等。
(3)数据分割:将数据分为训练集和测试集,用于模型训练和验证。
三、时序分析方法本报告主要采用以下时序分析方法:1. 时间序列描述性分析通过对时间序列数据进行描述性统计分析,如均值、标准差、自相关系数等,了解数据的整体特征。
2. 时间序列平稳性检验使用ADF(Augmented Dickey-Fuller)检验等方法,判断时间序列是否平稳,为后续建模提供基础。
3. 时间序列建模(1)ARIMA模型:根据时间序列的自相关性,构建ARIMA模型,对数据进行拟合和预测。
(2)SARIMA模型:在ARIMA模型的基础上,考虑季节性因素,构建SARIMA模型。
(3)LSTM模型:利用深度学习技术,构建LSTM模型,对时间序列数据进行预测。
四、结果与分析1. 时间序列描述性分析通过对股票价格、成交量等数据的描述性分析,我们发现:(1)股票价格波动较大,存在明显的周期性波动。
(2)成交量与价格波动存在正相关关系。
(3)市场指数波动相对平稳。
2. 时间序列平稳性检验通过ADF检验,我们发现股票价格、成交量等时间序列均为非平稳时间序列,需要进行差分处理。
3. 时间序列建模(1)ARIMA模型:根据自相关图和偏自相关图,确定ARIMA模型参数,对数据进行拟合和预测。
时序分析
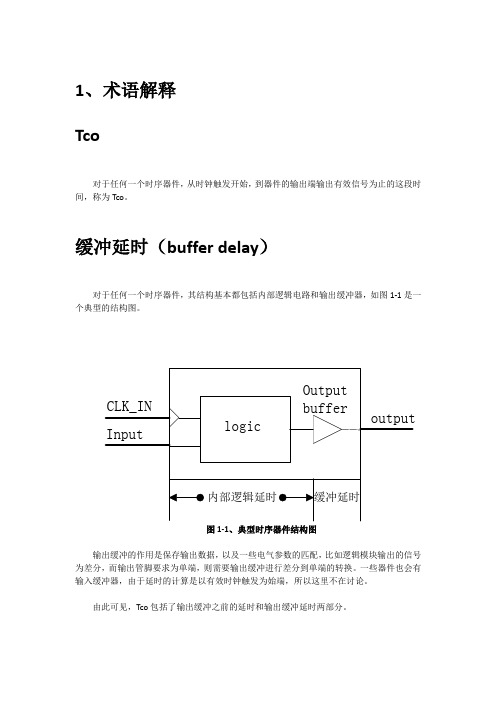
1、术语解释Tco对于任何一个时序器件,从时钟触发开始,到器件的输出端输出有效信号为止的这段时间,称为Tco。
缓冲延时(buffer delay)对于任何一个时序器件,其结构基本都包括内部逻辑电路和输出缓冲器,如图1-1是一个典型的结构图。
图1-1、典型时序器件结构图输出缓冲的作用是保存输出数据,以及一些电气参数的匹配,比如逻辑模块输出的信号为差分,而输出管脚要求为单端,则需要输出缓冲进行差分到单端的转换。
一些器件也会有输入缓冲器,由于延时的计算是以有效时钟触发为始端,所以这里不在讨论。
由此可见,Tco包括了输出缓冲之前的延时和输出缓冲延时两部分。
传播延时(propagation delay)信号从器件输出后就要经过传输线进行传输,信号在传输线上的延时就称为传播延时。
它只与信号传输速度和线长有关。
飞行时间(Flight time)飞行时间是,接收端的信号电平达到输出端信号电平所需的时间,这里的信号电平是指设计者所关心的信号点,记为Vmeas。
大多数的时序设计里,我们更关心的参数是飞行时间而不是传播延时,包括最大飞行时间和最小飞行时间。
飞行时间包含了传播延时和信号上升沿变化这两个因素。
图1-2为传播延时和飞行时间波形图,红线为接收端波形,黑色为输出端波形。
图1-2、传播延时和飞行时间在较轻的负载(如单负载)情况下,驱动端的上升沿几乎和接收端的信号的上升沿平行,所以这时候平均飞行时间和传播延迟相差不大;但如果在重负载(如多负载)的情况下,接收信号的上升沿明显变缓,这时候平均飞行时间就会远远大于信号的传播延迟。
这里说的平均飞行时间是指Buffer波形的Vms到接收端波形Vms之间的延时,这个参数只能用于时序的估算,准确的时序分析一定要通过仿真测量最大/最小飞行时间来计算。
最小飞行时间(或称First Switch Delay)和最大飞行时间(或称First Settle Delay)则是指接收端信号第一次达到参考信号电平和最后一次达到参考信号电平作用的时间。
CTCS3-300T车载设备VDX时序问题分析与解

CTCS3-300T车载设备VDX时序问题分析与解决措施常 斌(上海铁路通信有限公司,上海 200071)摘要:安全数字输入/输出单元(VDX)在CTCS3-300T 列控车载ATP 系统中至关重要,列车在运行中发生V D X 故障,将直接导致故障停车。
为保障300T 型A T P 系统的正常运行,提高运营维护效率,结合V D X 单元的功能原理,针对V D X 时序问题,分析产生的原因,探讨解决措施,得到处理VDX 时序问题的方案。
关键词:停车故障;安全数字输入/输出单元;冗余系统;时序问题中图分类号:U284.48 文献标志码:A 文章编号:1673-4440(2023)01-0105-05Analysis and Solutions of VDX Time Sequence Problems ofCTCS3-300T Onboard EquipmentChang Bin(Shanghai Railway Communication Co., Ltd., Shanghai 200071, China)Abstract: Vital Digital Input/Output units (VDX) are very important in a CTCS3-300T onboard train control ATP system. When a train runs, the VDX time sequence problems will directly lead to the stopping of the train due to failure. In order to ensure the normal operation of 300T ATP systems and improve the efficiency of operation and maintenance, the causes of VDX time sequence problems are analyzed, the solutions are discussed with consideration of the functions and principle of VDX units. And the scheme for dealing with VDX time sequence problem is obtained.Keywords: train stopping failure; Vital Digital I/O unit; redundant system; time sequence problemsDOI: 10.3969/j.issn.1673-4440.2023.01.020收稿日期:2021-10-19;修回日期:2022-12-20作者简介: 常斌(1984—),男,工程师,本科,主要研究方向:列控车载系统设备生产调试故障分析,邮箱:****************。
时序数据处理

时序数据处理时序数据处理时序数据是指按时间顺序排列的数据,通常包括时间戳和值。
时序数据处理是指对这些数据进行分析、建模、预测和可视化的过程。
在当今大数据时代,时序数据处理已经成为许多行业中不可或缺的一部分,如金融、物流、医疗等领域。
本文将介绍时序数据处理的基本概念、方法和工具。
一、时序数据的基本概念1. 时间戳时间戳是指标识某个事件发生时间的标记。
在时序数据中,每个记录都有一个唯一的时间戳,用于表示该记录所对应的时间点。
2. 值值是指与时间戳相对应的数值或其他类型的信息。
在时序数据中,值可以是连续型变量(如温度、湿度等)、离散型变量(如状态码等)或文本型变量(如日志信息等)。
3. 时间间隔时间间隔是指两个相邻时间戳之间的距离。
在有些情况下,不同记录之间的时间间隔可能不一致,需要根据实际需求进行处理。
4. 采样率采样率是指每秒钟采集到的样本数量。
在某些场合下,需要根据采样率来确定时序数据的精度和可靠性。
二、时序数据处理的方法1. 数据清洗时序数据中常常存在缺失值、异常值和噪声等问题,需要进行数据清洗。
常用的方法包括插值法、滤波法和异常检测等。
2. 特征提取特征提取是指从原始时序数据中提取有用的特征信息。
常用的方法包括小波变换、傅里叶变换、自相关函数等。
3. 时间序列分析时间序列分析是指对时序数据进行统计学分析和建模,以便预测未来趋势。
常用的方法包括ARIMA模型、季节性分解法、指数平滑法等。
4. 机器学习机器学习是指利用算法和模型从数据中学习规律,并预测未来趋势。
在时序数据处理中,常用的机器学习算法包括支持向量机(SVM)、神经网络(NN)和决策树(DT)等。
三、时序数据处理工具1. MATLABMATLAB是一种基于数值计算和可视化的语言环境,广泛应用于工程、科学和金融领域。
MATLAB提供了丰富的函数库和工具箱,方便进行时序数据处理和分析。
2. R语言R语言是一种开源的统计软件,具有强大的数据分析和可视化能力。
时序数据及时序数据库概述

综合以上对于时序数据写入、查询和存储的特点的分析,我们可以归纳总结下对于时序数据库的基本要求:
1.能够支撑高并发、高吞吐的写入:如上所说,时序数据具有典型的写多读少特征,其中95%-99%的操作都是写。在读和写上,首要权衡的是写的能力。由于其场景的特点,对于数据库的高并发、高吞吐写入能力有很高的要求。
背景
结合时序数据的特点和时序数据库的基本要求的分析,使用基于LSM树存储引擎的NoSQL数据库(例如HBase、Cassandra或阿里云表格存储等)相比使用B+树的RDBMS,具有显著的优势。LSM树的基本原理不在这里赘述,它是为优化写性能而设计的,写性能相比B+树能提高一个数量级。但是读性能会比B+树差很多,所以极其适合写多读少的场景。目前开源的几个比较著名的时序数据库中,OpenTSDB底层使用HBase、BlueFlood和KairosDB底层使用Cassandra,InfluxDB底层是自研的与LSM类似的TSM存储引擎,Prometheus是直接基于LevelDB存储引擎。所以可以看到,主流的时序数据库的实现,底层存储基本都会采用LSM树加上分布式架构,只不过有的是直接使用已有的成熟数据库,有的是自研或者基于LevelDB自己实现。
2.测量值: 一个主体可能有一个或多个测量值,每个测量值对应一个具体的指标。还是拿服务器状态监控场景举例,测量的指标可能会有CPU使用率,IOPS等,CPU使用率对应的值可能是一个百分比,而IOPS对应的值是测量周期内发生的IO次数。
3.时间戳: 每次测量值的汇报,都会有一个时间戳属性来表示其时间。
八、
本篇文章主要分析了时序数据的特性、模型和基本的查询和处理操作,以及对时序数据库的基本要求。在下一篇文章中,会对当前比较流行的几个开源的时序数据库的实现做分析。你会发现,虽然目前存在那么多的时序数据库,但是在基本功能上都是大同小异的。各个时序数据库各有特色,实现方式也各不同,但是都是围绕在对时序数据的写入、存储、查询和分析这几个维度的设计方案的权衡和取舍。没有一个万能的时序数据库解决了所有的问题,在你选择用何种时序数据库的时候,需要从业务角度出发,选择一款最合适的时序数据库。
时间序列分析基础预测与建模时序数据的方法介绍

时间序列分析基础预测与建模时序数据的方法介绍时间序列分析是一种重要的数据分析方法,用于预测和建模时序数据。
它广泛应用于经济、金融、气象等领域,帮助我们理解和解释数据背后的规律与趋势。
本文将介绍时间序列分析的基本概念,以及常用的预测和建模方法。
一、时间序列分析基础概念时间序列是指按时间顺序排列的数据序列。
它通常包括一个或多个定量变量的观测值,这些观测值是按照固定时间间隔记录的。
时间序列分析的目的是通过对过去的数据进行统计学分析,来预测未来的趋势和模式。
二、时间序列分析方法1. 描述性分析首先,对时序数据进行描述性分析是时间序列分析的重要一步。
描述性统计方法包括计算平均值、方差、标准差等统计指标,以及绘制线性图、直方图和自相关图等图表来揭示数据的基本特征和趋势。
2. 平稳性检验平稳性是时间序列分析的一个基本假设,它意味着数据的统计特性不随时间而变化。
平稳性检验可以通过观察数据的均值和方差是否变化,以及利用单位根检验等方法来进行。
3. 分解模型分解模型是将时间序列分解成不同的组成部分,通常包括趋势、季节性和残差。
这种分解有助于我们理解时间序列的长期趋势和周期性变动。
4. 自回归移动平均模型(ARIMA)ARIMA模型是时间序列分析中最常用的一种预测模型。
它结合了自回归(AR)和移动平均(MA)两种方法,用于描述时间序列数据中的自相关和移动平均性质。
ARIMA模型具有较强的预测能力,可以应用于多种类型的时间序列数据。
5. 季节性自回归移动平均模型(SARIMA)SARIMA模型是ARIMA模型的一种扩展,用于建模和预测具有季节性的时间序列数据。
它考虑了季节性差分和季节性拉格滞后等因素,更适用于具有明显季节性模式的数据。
6. 广义自回归条件异方差模型(GARCH)GARCH模型用于建模和预测具有异方差性的时间序列数据。
它能够反映数据波动的变化性质,并具有很好的风险度量和预测能力。
GARCH模型在金融领域得到广泛应用,尤其适用于股票市场和期货市场等高波动性的数据。
使用MySQL进行时序数据处理和分析

使用MySQL进行时序数据处理和分析Introduction时序数据(time series data)是一类按时间顺序采集的数据,它在许多领域中都具有重要的应用价值。
例如,在金融市场中,时序数据可以用于预测股票价格走势;在物联网领域,时序数据可以用于监控和预测设备的运行状况。
MySQL作为一种高效的关系数据库管理系统,提供了强大的功能和灵活的查询语言,可以用于处理和分析时序数据。
本文将探讨如何使用MySQL进行时序数据处理和分析,并介绍一些可行的解决方案。
1. 时序数据的特点时序数据有以下几个特点:- 时间顺序性:时序数据是按时间顺序采集的,数据点之间存在明确的时间间隔。
- 数据趋势性:时序数据通常具有一定的趋势性,可以用于预测未来的发展趋势。
- 季节性:某些时序数据可能存在季节性的变化模式,例如每年的销售额在圣诞节时会有明显的增长。
- 周期性:某些时序数据可能会出现固定周期的波动,例如股票价格的日内交易波动。
2. 时序数据的存储结构对于时序数据的存储,一种常见的方式是使用关系型数据库管理系统(RDBMS),如MySQL。
MySQL使用表格的形式来存储数据,每一行代表一个数据点,每一列代表一个属性。
为了支持时序数据的处理和分析,可以将时间列作为主键,这样可以方便地按时间顺序进行查询和排序。
下面是一个示例表格的结构:```CREATE TABLE `time_series_data` (`timestamp` datetime NOT NULL,`value` float NOT NULL,PRIMARY KEY (`timestamp`));```3. 时序数据的导入和导出在使用MySQL进行时序数据处理和分析之前,首先需要将数据导入到数据库中。
MySQL提供了多种导入数据的方式,例如使用LOAD DATA INFILE语句、使用MySQL Workbench工具等。
对于导入的数据进行预处理可以提高后续分析的效果,例如去除异常值、补全缺失值等。
时序数据分析方法综述

时序数据分析方法综述时序数据是一种特殊类型的数据,它是按时间顺序排列的观测数据。
时序数据具有时间相关性,不同时间点上的观测值之间存在一定的关联性,因此需要使用特定的方法进行分析。
时序数据分析广泛应用于金融、气象、交通等领域,通过对时序数据的分析,可以发现数据中隐藏的规律,预测未来的趋势和变化。
时间序列分析是时序数据分析的基础方法,它通过对时间序列中的数据进行建模和预测。
常用的时间序列建模方法包括自回归移动平均模型(ARMA)、自回归积分移动平均模型(ARIMA)和季节性自回归综合模型(SARIMA)等。
这些模型可以捕捉时间序列数据中的趋势、季节性和随机部分,从而提供准确的预测结果。
回归分析是一种常用的统计方法,用于研究自变量与因变量之间的关系。
在时序数据分析中,回归分析可以用于建立时间序列数据与其他影响因素之间的关系,从而预测未来的趋势。
常用的回归模型包括线性回归模型和非线性回归模型等。
滤波分析是一种信号处理方法,用于从时序数据中提取出感兴趣的信号成分。
在时序数据分析中,滤波分析可以用于去除噪声和平滑数据。
常用的滤波方法包括均值滤波、中值滤波和卡尔曼滤波等。
机器学习方法在时序数据分析中也得到了广泛的应用。
神经网络是一种常用的机器学习方法,通过多层次的神经元之间的连接来模拟人脑的学习和决策过程。
在时序数据分析中,神经网络可以用于建立时间序列数据与其他影响因素之间的复杂关系,从而实现更精确的预测。
支持向量机是一种非常强大的分类和回归分析工具,可以用于解决非线性问题。
在时序数据分析中,支持向量机可以用于建立时间序列数据与其他影响因素之间的关系,从而提供准确的预测。
深度学习是一种新兴的机器学习方法,它通过多层次的神经网络模型来学习高层次的抽象特征,并实现更准确的预测。
在时序数据分析中,深度学习可以用于建立时间序列数据与其他影响因素之间的复杂关系,从而提供更准确的预测结果。
综上所述,时序数据分析方法包括传统方法和机器学习方法两大类。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
传统的统计分析
内容:从发展和增长两个角度,对绝对量(水平) 和相对量(速度)进行比较。相关概念如下:
水平 发展 速度
增长
定比 环比 同比 定比 环比 同比
平均发 展水平 平均增 长水平
平均发 展速度 平均增 长速度
时间序列的水平分析
一、发展水平 直接观察 在一个时间序列中,各时间上的发展水平按时间顺序 可记为基期、报告期 定比,环比,同比 比较大小,说明增加了还是减少了。
三、增长量和平均增长量
增长量是某种现象在一定时期内所增长的绝对数量。 它是报告期水平与基期水平之差,反映报告期比基期 增长的水平。 累计增长量(定比)与逐期增长量(环比)
平均增长量是某种现象在一定时期内平均每期增长的 数量。
时间序列的速度分析
反映变量发展速度快慢的速度的主要指标有发展速度、 增长速度、平均发展速度和平均增长速度。
三、什么是时间序列分析?
寻找时间序列的数量特征, 分析手段:建模
四、分析的目的是什么? 关系、预测、控制
时间序列分析的目的
分析目的
分析过去
描述动态变化
认识规律
揭示变化规律
预测未来
未来的数量趋势
五、分析方法的分类 描述性 统计性:传统的、现代的(时域和频域) 六、什么是模型? 总体所具有的特征、规律 七、建模的含义 假定总体的特征、规律 确认/识别、估计、评价、预测
本期发展水平 年距发展速度 上年同期发展水平
同比发展速度(年距发展速度):主要是为了消除季节 变动的影响,用以说明本期发展水平与去年同期发展水 平对比而达到的相对发展速度。 大于1还是小于1,说明增加了还是减少了
二、增长速度
由增长量与基期水平的对比可计算增长速度,说明报告期水 平较基期水平增长的相对程度.
中国五部门产出
5,000
4,000
3,000
2,000
1,000
0 1955 1960 1965 NONGYE JIANZOUYE SHANGYE 1970 1975 1980 1985
GONGYE JIAOTONGYUESHUYE
荷兰摩托车销售量
MOTO
280
240
200
160
120
80
40 1950 1955 1960 1965 1970 1975 1980 1985 1990
各环比发展速度的连乘积等于相应时期的定基发展速度; 相邻的两个定基发展速度之商的等于相应时期的环比发 展速度,即
xi xn x x i 1 0
xi xi 1 xi x0 x0 xi 1
同比(year-on-year)就是今年第n月与去年第n月之比。 如,本期2月比去年2月,本期6月比去年6月等。 在实际工作中,经常使用这个指标,如某年、某季、某 月与上年同期对比计算的发展速度,就是同比发展速度。 同比发展速度(年距发展速度):
Series
11000.
10000.
9000.
8000.
7000.
0
10
20
30
40
50
60
70
季节模式:7月最多,2月最少。趋势不明显。
美国1951-1980年的每年罢工人数
Series
6000.
5500.
5000.
4500.
4000.
3500.
5
10
15
20
25
30
波动地很不规律,有一个变化的一般水平。
描述性时序分析
通过直观的数据比较或绘图观测,寻找序列中蕴含 的发展规律,这种分析方法就称为描述性时序分析 描述性时序分析方法具有操作简单、直观有效的特 点,它通常是人们进行统计时序分析的第一步。 股票市场上的图学家
描述性时序分析案例
德国业余天文学家施瓦尔发现太阳黑子的活动具有11年左 右的周期
可以分析动态的发展变化情况
一、时间序列的含义
二、时间序列的例子与特征
14 Y 12
10
8
6
4 50 55 60 65 70 75 80 85 90 95 00
中国人口时间序列折线图/走势图/时序图
美国1790-1990人口数量
Series 2.50E+08
2.00E+08
1.50E+08
1.00E+08
一、发展速度
时间序列中报告期水平与基期水平之比,称为发展速度,说明现 象报告期水平较基期水平的相对发展程度。
报告期水平 xi 发展速度 基期水平 x0
定基发展速度 环比发展速度
同比发展速度
环比发展速度是报告期水平与前一时期水平之比,表明 现象逐期的发展速度。如计算一年内各月与前一个月对 比,即2月比1月,3月比2月,4月比3月 ……12月比11 月,说明逐月的发展程度。
二、平均发展水平——序时平均数
x x1 x2 n xn x n
xn1 xn f n1 2
绝序 对时 数平 序均 列数
时期数列
时点序列
x2 x3 x1 x2 f1 f2 2 x 2 n 1 fi
i 1
相对数或平均数序列 计算序时平均数
a x b
1.变化性 变化是世界上唯一不变的真理。这是分析的基础。 2.相关性 时间序列是其它因素影响的结果。背后有驱动力量。驱动 力量的变化引起序列的变化。驱动力量的影响隐含在过去 值里面,使得序列前后值之间具有了相关性。如何描述、 分析这种相关性? 3.趋势性:随机性趋势、确定性趋势 4.季节性:周期性 5.异常观测值 6. 非线性(只能进行短期预测) 7.依存性(多变量序列)多变量序列关注的焦点转移到序列 和序列之间的相关性上。
5.00E+07
0.00E+00
2
4
6
8
10
12
14
16
18
20
含有二次或指数趋势。
澳大利亚红酒销售量
Series
3000.
2500.
2000.
1500.
1000.
500.
0
20
40
60
80
100
120
1பைடு நூலகம்0
1980.01-1991.0.向上的趋势和季节模式(7月高峰,1月低 谷)。
美国1973-1978年月度死亡数量
xi / xi 1
定基比发展速度也叫总速度。是报告期水平与某一固定 时期水平之比,表明这种现象在较长时期内总的发展速 度。如,"九五"期间各年水平都以1995年水平为基期进行 对比,一年内各月水平均以上年12月水平为基期进行对 比,就是定基发展速度。
xi / x0
环比发展速度与定基发展速度的关系是 :