【八爪鱼采集攻略】提取数据如何设置自定义抓取方式
八爪鱼采集器采集数据的基本方法和流程

八爪鱼采集器采集数据的基本方法和流程下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!一、概述八爪鱼采集器是一款功能强大的数据采集工具,能够帮助用户快速高效地获取所需数据。
【八爪鱼采集教程】提取数据如何使用备用位置

【八爪鱼采集教程】提取数据如何使用备用位置八爪鱼提取字段时,默认每个字段都是在页面里固定的位置,但是某些特殊情况,当某字段在不同的页面是不同的位置时,也可以用八爪鱼的备选位置功能。
当需要提取的字段在网页两个不同位置,即一个Xpath无法定位到该字段时,我们便需要使用备选功能。
下面为你演示如何设置备选位置:示例网站:https:///12079776060.htmlhttps://item.jd.hk/1958056917.html步骤一:自定义采集任务→输入网址提取数据使用备用位置-图1提取数据使用备用位置-图2步骤二:提取元素字段(商品名、店铺名)提取数据使用备用位置-图3步骤三:保存并启动 直接单机运行可以看到第二个网页店铺名空白,提取不到提取数据使用备用位置-图4这时我们回到流程界面,手动运行一下规则。
提取数据使用备用位置-图5提取数据使用备用位置-图6发现第一个网页的字段2可以提取到,第二个网页则为空白,提取不到。
说明两个网页店铺名的字段Xpath不一样,我们用第一个网页的Xpath提取不到第二个网页的信息。
这时我们需要用到备用位置。
步骤四:选中店铺名字段→点击自定义字段→自定义定位元素方式→设置备用位置提取数据使用备用位置-图7 提取数据使用备用位置-图8提取数据使用备用位置-图9提取数据使用备用位置-图10说明:点击需要设置备用位置的元素,选择将这个元素设为备选即可。
也可以自己通过Xpath 进行修改。
提取数据使用备用位置-图11提取数据使用备用位置-图12单机运行一次,发现可以采集到,设置备用位置成功。
提取数据使用备用位置-图13相关采集教程:淘宝评论采集新浪微博数据采集搜狗微信文章采集八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
如何利用八爪鱼爬虫爬取图片

如何利用八爪鱼爬虫爬取图片很多电商、运营等行业的朋友,工作中需要用到大量的图片,手动复制太麻烦,现在市面上有一款自动化爬虫工具:八爪鱼采集器,可以帮助大家用最简单的方式自动爬取大量图片,上万张图片几个小时即可轻松搞定。
八爪鱼先将网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。
下面以ebay网站为例,给大家介绍八爪鱼爬虫爬取图片的方法。
采集网站:https:///使用功能点:●分页列表信息采集●执行前等待●图片URL转换步骤1:创建采集任务1)进入主界面,选择“自定义采集”八爪鱼爬取图片步骤12)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”八爪鱼爬取图片步骤23)系统自动打开网页,红色方框中的图片是这次演示要采集的内容八爪鱼爬取图片步骤3步骤二:创建翻页循环1)点击右上角的“流程”,即可以看到配置流程图。
将页面下拉到底部,找到下一页的大于号标志按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接”八爪鱼爬取图片步骤4由于该网页每次翻页网址随之变化,所以不是ajax页面,不需要设置ajax。
如果有网站每次翻页,网址不变,则需要在高级选项设置ajax加载。
步骤三:图片链接地址采集1)选中页面内第一个图片,系统会自动识别同类图片。
在操作提示框中,选择“选中全部”八爪鱼爬取图片步骤52)选择“采集以下图片地址”八爪鱼爬取图片步骤5由左上角流程图中可见,八爪鱼对本页全部图片进行了循环,并在“提取数据”中对图片链接地址进行了提取。
此时可以用鼠标随意点击循环列表中的某一条,再点击“提取数据”,验证一下是否都有正常提取。
如果有的循环项没有提取到,说明该xpath定位不准,需要修改。
(多次测试,尚未发现不准情况。
)八爪鱼爬取图片步骤6如还想提取其他字段,如标题,可选择“提取数据”,在下方的商品列表上点击一个商品的标题,选择“采集该链接的文本”八爪鱼爬取图片步骤7修改下字段的名称,如网页加载较慢,可设置“执行前等待”八爪鱼爬取图片步骤8点击“开始采集,免费版用户点击“启动本地采集”,旗舰版用户可点击“启动云采集”八爪鱼爬取图片步骤9说明:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。
如何利用八爪鱼爬虫抓取数据

如何利用八爪鱼爬虫抓取数据听说很多做运营的同学都用八爪鱼采集器去抓取网络数据,最新视频,最热新闻等,但还是有人不了解八爪鱼爬虫工具是如何使用的。
所以本教程以百度视频为例,为大家演示如何采集到页面上的视频,方便工作使用。
常见场景:1、遇到需要采集视频时,可以采集视频的地址(URL),再使用网页视频下载器下载视频。
2、当视频链接在标签中,可切换标签进行采集。
3、当视频链接在标签中,也可采集源码后进行格式化数据。
操作示例:采集要求:采集百度视频上综艺往期视频示例网址:/show/list/area-内地+order-hot+pn-1+channel-tvshow操作步骤:1、新建自定义采集,输入网址后点击保存。
注:点击打开右上角流程按钮。
2、创建循环翻页,找到采集页面中下一页按钮,点击,执行“循环点击下一页”。
在流程中的点击翻页勾选Ajax加载数据,时间设置2-3秒。
3、创建循环点击列表。
点击第一张图片,选择“选中全部”(由于标签可能不同,会导致无法选中全部,可以继续点击没被选中的图片)继续选择循环点击每个元素4、进入详情页后,点击视频标题(从火狐中可以看到视频链接在A标签中,如图所示),所以需要手动更换到相应的A标签。
手动更换为A标签:更换为A标签后,选择“选中全部”,将所有视频标题选中,此时就可以采集视频链接地址。
5、所有操作设置完毕后,点击保存。
然后进行本地采集,查看采集结果。
6、采集完成后将URL导出,使用视频URL批量下载工具将视频下载出来就完成了。
相关采集教程:公告信息抓取/tutorial/hottutorial/qita/gonggao网站源码抓取/tutorial/hottutorial/qita/qitaleixing网页抓取工具新手入门/tutorial/xsksrm八爪鱼网站抓取入门功能介绍/tutorial/xsksrm/rmgnjsajax网页数据抓取/tutorial/gnd/ajaxlabel模拟登录并识别验证码抓取数据/tutorial/gnd/dlyzmxpath抓取网页文字/tutorial/gnd/xpath八爪鱼抓取AJAX滚动页面爬虫教程/tutorial/ajgd_7网页采集提取数据教程,以自定义抓取方式为例/tutorial/zdytq_7八爪鱼——90万用户选择的网页数据采集器。
八爪鱼采集数据导出mysql数据库(手动、自动两种方式)

八爪鱼采集数据导出mysql数据库(手动、自动两种方式)本教程将为大家讲解如何将采集好的数据导出到mysql数据库中,这里给大家讲两种导出方式一、手动导出数据库这种方式只能在任务采集完毕之后将采集之后的数据导出到数据库中。
二、自动导出数据库这种方式可以实现边采集边导,按照设置的时间间隔启动导出计划,这种方式只支持云采集。
目前八爪鱼支持导出数据库有Mysql、SqlServer、Oracle中,本地采集和云采集的数据均可以导出到数据库中,教程以云采集的数据为示例为大家讲解。
小贴士:导出前需要先建好数据库和数据表手动导出mysql数据库的步骤如下:步骤1: 点击任务→选择一个要导出的任务数据点击更多操作→查看数据→云采集数据数据导出mysql数据库-图1步骤2:选择导出数据→在弹出的操作界面上选择导出所有数据或者未导出数据→选择导出到数据库→点击确定进入到数据导出向导→选择下一步进入到数据库配置界面数据导出mysql数据库-图2数据导出mysql数据库-图3步骤3:进入数据库配置界面后,对数据库的相关信息进行配置。
配置好如下字段:∙数据库类型:选择Mysql∙服务器:Mysql服务器地址∙端口:Mysql实例的端口∙用户名:登录Mysql的用户名∙密码:登录Mysql的密码∙数据库编码:填写数据库的编码,不指定可能会出现导入后为乱码的情况例如导出的是中文,可设置成utf8,另外用户自己的数据库表、字段都需设置成utf8.∙数据库名称:选择已有的数据库配置好后可点击测试连接,验证配置是否正确。
这里的配置都是正确的,因此下方显示为连接可用。
如果配置不正确,下方将会显示错误信息。
数据导出mysql数据库-图4数据库连接配置完毕之后,点击下一步,进入数据字段映射界面步骤4:数据库连接配置完毕之后点击下一步进入数据字段映射界面→选择数据表→选择目标数据字段(这里如果源数据字段和目标数据字段名称一样会自动进行配置,如果不一样就需要手动选择一下)→如果其中某个字段不想要重复的可以勾选设置为唯一标识,勾选后在导入的时候将会根据这个字段确定是数据库新增记录还是覆盖原有的记录→点击下一步,进入数据导出页面数据导出mysql数据库-图5小贴士:如果需要下次继续导出,这里可以设置保存配置。
采集器软件使用
1.访问“八爪鱼”采集器官方网站,完成注册,并下载安装“八爪鱼”采集器软件。
2.启动“八爪鱼”采集器软件,登录,并打开“自定义采集”功能。
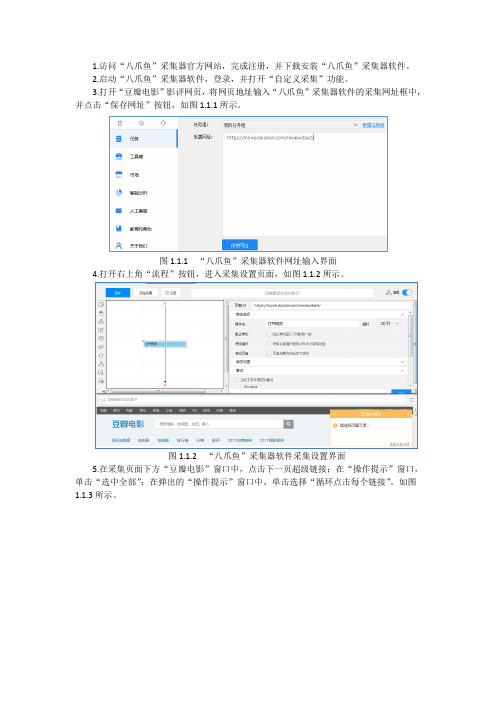
3.打开“豆瓣电影”影评网页,将网页地址输入“八爪鱼”采集器软件的采集网址框中,并点击“保存网址”按钮,如图1.1.1所示。
图1.1.1 “八爪鱼”采集器软件网址输入界面4.打开右上角“流程”按钮,进入采集设置页面,如图1.1.2所示。
图1.1.2 “八爪鱼”采集器软件采集设置界面5.在采集页面下方“豆瓣电影”窗口中,点击下一页超级链接;在“操作提示”窗口,单击“选中全部”;在弹出的“操作提示”窗口中,单击选择“循环点击每个链接”。
如图1.1.3所示。
图1.1.3 “八爪鱼”采集器软件操作提示选择界面6.选择页面元素。
点击影评用户名,在“操作提示”窗口,单击“选中全部”;在一次弹出的“操作提示”窗口中,单击选择“采集以下链接文本”。
此时,配置抓取模板中添加了提取的数据样式,如图1.1.4所示。
图1.1.4 “八爪鱼”采集器软件数据样式呈现界面7.重复上一步骤操作,把电影名、影评内容添加到“配置抓取模板”中。
并在“配置抓取模板”中单击字段名称,更改字段名称。
然后,单击“操作提示”窗口中“保存并开始采集”,如图1.1.5所示。
图1.1.5 “八爪鱼”采集器软件配置抓取模板8.在“运行任务”窗口选择“启动本地采集”,开始数据采集,如图1.1.6所示。
图1.1.6 “八爪鱼”采集器软件运行任务界面9.在“提取到的数据”窗口,选择“导出数据”按钮;然后选择需要的导出方式,完成数据的收集与保存,如图1.1.7所示。
图1.1.7 “八爪鱼”采集器软件导出方式选择界面。
八爪鱼采集文章具体内容

八爪鱼采集文章具体内容
八爪鱼采集文章的具体内容需要使用八爪鱼采集器来实现。
以下是使用八爪鱼采集文章内容的步骤:
1. 打开八爪鱼采集器,并选择“自定义采集”模式。
2. 在“自定义采集”模式下,需要输入网址,并点击“下一步”。
3. 在网页元素编辑页面,可以观察到网页的结构,需要采集的标题和内容可以通过拖拽选择网页元素的方式来选择。
4. 选中文本后,在右侧的属性列表中,可以设置要采集的内容,例如标题、正文、作者等。
5. 点击“保存并开始采集”按钮,八爪鱼采集器会自动采集网页中的内容,并保存到本地文件中。
需要注意的是,在使用八爪鱼采集文章内容时,需要遵守相关法律法规和网站的使用协议,不得采集涉及隐私、版权等敏感信息,也不能对网站的正常运行造成影响。
八爪鱼提取网页数据的方法

视频教程PPT
提取数据
一、添加特殊字段、上移下移、抓取模板导入导出
二、找不到时如何处理
三、自定义抓取方式 四、自定义定位元素方式 五、备用位置 六、格式化数据
七、自定义合并方式
一、 添加特殊字段、上移下移、抓取模板导入导出
1、添加特殊字段 当前时间 固定字段 空字段 当前页面信息 2、字段上移下移 3、抓取模板导入导出 示例网址: /fang1/
五、备用位置
八爪鱼提取字段时,默认每个字段都是在页面里固定的位置。 但是某些特殊情况,当某字段在不同的页面,是处于不同的位置时,可以用八爪鱼 的备选位置功能。 示例网址: https:///item.htm?spm=a1z10.1-c-s.w1201073114573359259.1.1c3577c8vTygcq&id=566814688341(淘宝商品详情页) https:///item.htm?spm=a230r.1.14.27.2e932897hyfHKC&id= 565712872904&ns=1&abbucket=4(天猫商品详情页)
二、找不到时如何处理
找不到数据时的三种处理办法 使用默认值 在找不到数据时默认填写一个字段,以补充没有采集到的内容 该字段留空 可以在结果中明显的看到哪里有数据没采集到 该步骤所有字段留空 一个字段找不到数据时,便忽略该信息所有字段,相当于跳过该条信息的采集 示例网址:https:///subject/25862578/ https:///subject/1858513/
六、格式化数据
利用格式化数据对需要的字段进行修改 替换 正则表达式替换 去除空格 添加前缀 添加后缀 日期时间格式化 Html转码 示例网址: https:///subject/25862578/
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
【八爪鱼采集攻略】提取数据如何设置自定义抓取方式
自定义抓取方式包含“从页面中提取数据”’、“从浏览器提取数据”、“生成数据”三部分。
八爪鱼提取数据-自定义抓取方式图1
1、从页面中提取数据
(1)抓取元素的指定属性值:首先要先选中InnerHtml和OuterHtml查看要提取的属性值是否存在,再选中抓取元素的指定属性值。
例如源码:
<a id="hot-comments-tab" class="on" href="comments">热门</a> 中,id、class、href就是A标签的属性,在下拉选项中选取要提取的属性名称,即可提取到该属性的属性值,演示如下:
八爪鱼提取数据-自定义抓取方式图2
八爪鱼提取数据-自定义抓取方式图3
(2)抓取文本:提取网页中展示的内容,可见的文字信息。
(3)抓取地址:一般用于抓取图片地址或Iframe地址,首先字段的Xpath定位到的是IMG标签或者Iframe标签,提取其中的src属性值。
(4)抓取选中项的文本:配合循环下拉框试用,提取当前选中项的文本
(5)抓取这个元素的OuterHtml,InnerHtml:提取网页源码
(6)抓取值:一般用于抓取输入框的文字,首先字段的Xpath定位到的是input 标签,提取其中的value值,演示如下:
八爪鱼提取数据-自定义抓取方式图4
八爪鱼提取数据-自定义抓取方式图5
(7)抓取超链接:首先字段的Xpath定位到的是A标签,从A标签中提取href
的属性值。
演示如下:
八爪鱼提取数据-自定义抓取方式
图
6
八爪鱼提取数据-自定义抓取方式 图7
2、从浏览器提取数据
八爪鱼提取数据-自定义抓取方式图8
(1)页面网址:同添加其他特殊字段中的抓取当前页面的网址效果
(2)页面标题:同添加其他特殊字段中的抓取当前页面的标题效果
(3)从页面源码里抓取:可直接用正则表达式提取网页源码里匹配到的数据3、生成数据
八爪鱼提取数据-自定义抓取方式图9
(1)生成固定的值:同添加其他特殊字段中的生成固定值效果,常用于发布到网站时设置发布的用户名,发布到的版块等固定字段
(2)使用当前时间:同添加其他特殊字段中的使用当前时间效果,用于记录采集时间,此设置有可能会导致八爪鱼采集器去重功能检测失效
相关采集教程:
美团商家信息采集
1688热门商品采集
搜狗微信文章采集
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。
配置好采集任务后可关机,任务可在云端执行。
庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。
免费版具备所有功能,能够满足用户的基本采集需求。
同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。