北邮数据结构第六章答案详解 图(1)
数据结构与算法第6章图答案

第 6 章图课后习题讲解1. 填空题⑴设无向图G中顶点数为n,则图G至少有()条边,至多有()条边;若G为有向图,则至少有()条边,至多有()条边。
【解答】0,n(n-1)/2,0,n(n-1)【分析】图的顶点集合是有穷非空的,而边集可以是空集;边数达到最多的图称为完全图,在完全图中,任意两个顶点之间都存在边。
⑵任何连通图的连通分量只有一个,即是()。
【解答】其自身⑶图的存储结构主要有两种,分别是()和()。
【解答】邻接矩阵,邻接表【分析】这是最常用的两种存储结构,此外,还有十字链表、邻接多重表、边集数组等。
⑷已知无向图G的顶点数为n,边数为e,其邻接表表示的空间复杂度为()。
【解答】O(n+e)【分析】在无向图的邻接表中,顶点表有n个结点,边表有2e个结点,共有n+2e个结点,其空间复杂度为O(n+2e)=O(n+e)。
⑸已知一个有向图的邻接矩阵表示,计算第j个顶点的入度的方法是()。
【解答】求第j列的所有元素之和⑹有向图G用邻接矩阵A[n][n]存储,其第i行的所有元素之和等于顶点i的()。
【解答】出度⑺图的深度优先遍历类似于树的()遍历,它所用到的数据结构是();图的广度优先遍历类似于树的()遍历,它所用到的数据结构是()。
【解答】前序,栈,层序,队列⑻对于含有n个顶点e条边的连通图,利用Prim算法求最小生成树的时间复杂度为(),利用Kruskal 算法求最小生成树的时间复杂度为()。
【解答】O(n2),O(elog2e)【分析】Prim算法采用邻接矩阵做存储结构,适合于求稠密图的最小生成树;Kruskal算法采用边集数组做存储结构,适合于求稀疏图的最小生成树。
⑼如果一个有向图不存在(),则该图的全部顶点可以排列成一个拓扑序列。
【解答】回路⑽在一个有向图中,若存在弧、、,则在其拓扑序列中,顶点vi, vj, vk的相对次序为()。
【解答】vi, vj, vk【分析】对由顶点vi, vj, vk组成的图进行拓扑排序。
数据结构课后习题答案第六章

第六章树和二叉树(下载后用阅读版式视图或web版式可以看清)习题一、选择题1.有一“遗传”关系:设x是y的父亲,则x可以把它的属性遗传给y。
表示该遗传关系最适合的数据结构为( )。
A.向量B.树C图 D.二叉树2.树最合适用来表示( )。
A.有序数据元素 B元素之间具有分支层次关系的数据C无序数据元素 D.元素之间无联系的数据3.树B的层号表示为la,2b,3d,3e,2c,对应于下面选择的( )。
A. la (2b (3d,3e),2c)B. a(b(D,e),c)C. a(b(d,e),c)D. a(b,d(e),c)4.高度为h的完全二叉树至少有( )个结点,至多有( )个结点。
A. 2h_lB.h C.2h-1 D. 2h5.在一棵完全二叉树中,若编号为f的结点存在右孩子,则右子结点的编号为( )。
A. 2iB. 2i-lC. 2i+lD. 2i+26.一棵二叉树的广义表表示为a(b(c),d(e(,g(h)),f)),则该二叉树的高度为( )。
A.3B.4C.5D.67.深度为5的二叉树至多有( )个结点。
A. 31B. 32C. 16D. 108.假定在一棵二叉树中,双分支结点数为15,单分支结点数为30个,则叶子结点数为( )个。
A. 15B. 16C. 17D. 479.题图6-1中,( )是完全二叉树,( )是满二叉树。
1 / 1710.在题图6-2所示的二叉树中:(1)A结点是A.叶结点 B根结点但不是分支结点C根结点也是分支结点 D.分支结点但不是根结点(2)J结点是A.叶结点 B.根结点但不是分支结点C根结点也是分支结点 D.分支结点但不是根结点(3)F结点的兄弟结点是A.EB.D C.空 D.I(4)F结点的双亲结点是A.AB.BC.CD.D(5)树的深度为A.1B.2C.3D.4(6)B结点的深度为A.1B.2C.3D.4(7)A结点所在的层是A.1B.2C.3D.411.在一棵具有35个结点的完全二叉树中,该树的深度为( )。
数据结构 第6章习题答案

第6章树和二叉树习题解答一、下面是有关二叉树的叙述,请判断正误(每小题1分,共10分)(√)1. 若二叉树用二叉链表作存贮结构,则在n个结点的二叉树链表中只有n—1个非空指针域。
(×)2.二叉树中每个结点的两棵子树的高度差等于1。
(√)3.二叉树中每个结点的两棵子树是有序的。
(×)4.二叉树中每个结点有两棵非空子树或有两棵空子树。
(×)5.二叉树中每个结点的关键字值大于其左非空子树(若存在的话)所有结点的关键字值,且小于其右非空子树(若存在的话)所有结点的关键字值。
(应当是二叉排序树的特点)(×)6.二叉树中所有结点个数是2k-1-1,其中k是树的深度。
(应2i-1)(×)7.二叉树中所有结点,如果不存在非空左子树,则不存在非空右子树。
(×)8.对于一棵非空二叉树,它的根结点作为第一层,则它的第i层上最多能有2i—1个结点。
(应2i-1)(√)9.用二叉链表法(link-rlink)存储包含n个结点的二叉树,结点的2n个指针区域中有n+1个为空指针。
(正确。
用二叉链表存储包含n个结点的二叉树,结点共有2n个链域。
由于二叉树中,除根结点外,每一个结点有且仅有一个双亲,所以只有n-1个结点的链域存放指向非空子女结点的指针,还有n+1个空指针。
)即有后继链接的指针仅n-1个。
(√)10. 〖01年考研题〗具有12个结点的完全二叉树有5个度为2的结点。
最快方法:用叶子数=[n/2]=6,再求n2=n0-1=5二、填空(每空1分,共15分)1.由3个结点所构成的二叉树有5种形态。
2. 【计算机研2000】一棵深度为6的满二叉树有n1+n2=0+ n2= n0-1=31 个分支结点和26-1 =32个叶子。
注:满二叉树没有度为1的结点,所以分支结点数就是二度结点数。
3.一棵具有257个结点的完全二叉树,它的深度为9。
(注:用⎣ log2(n) ⎦+1= ⎣ 8.xx ⎦+1=94.【全国专升本统考题】设一棵完全二叉树有700个结点,则共有350个叶子结点。
北邮数字电路与逻辑设计(第一版)刘培植习题答案第06章习题解答
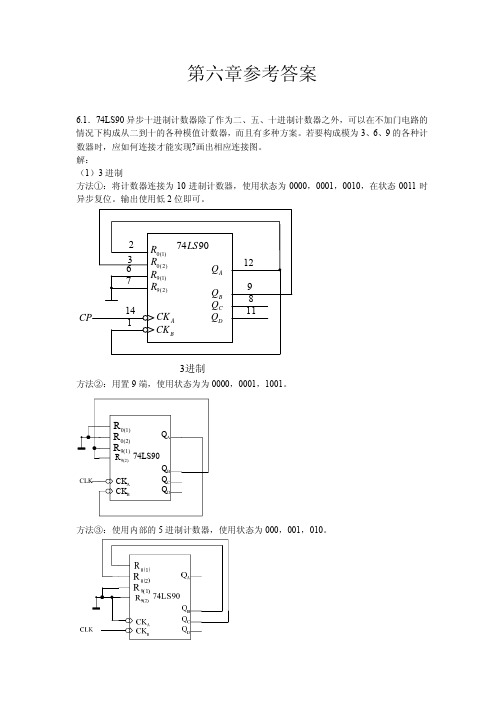
2 R0(1) 74LS90
3 6
7
R0(2) R9(1) R9(2)
CP
14 1
CK A
QA
12
QB QC
QD
9 8 11
CK B
9进制
方法②:用置 9 端,使用状态为 0000,0001,0010,0011,0100,1001。
CLK
R 0(1)
R 0(2)
QA
R9(1)
R9(2) 74LS90
解:74160 为 10 进制异步复位、同步预置计数器。在输出 Q3Q2Q1Q0 = 0101时产生复位。
因此使用的状态为:0000,0001,0010,0011,0100。
Qn+1 = Q1n f0 = Qn ⋅ Q1n = Qn + Q1n
注意:Q 的状态变换时刻比 74161 的状态变换时刻延迟半个时钟周期。
当预置 CBA=010 时,M=14;(初始预置值为 0010,0011,0100,0101,0110,0111,1000, 预置到 1010,1011,1100,1101,1110,1111,0000,再次预置为 0010……)
当预置 CBA=011 时,M=12;(初始预置值为 0011,0100,0101,0110,0111,1000,预置 到 1011,1100,1101,1110,1111,0000,再次预置为 0011……)
当 A=0 时,当 Q3Q2Q1Q0 = 1001时, Y = 1。因此使用的状态为:
0000,0001……1001。计数周期为 10。 状态转移表为:
Q3nQ2nQ1nQ0n
Q Q Q Q n+1 n+1 n+1 n+1 3 21 0
数据结构答案第6章

数据结构答案第6章第6章数据结构答案1. 栈的应用栈是一种常见的数据结构,其特点是先进后出。
下面是一些关于栈的应用场景。
1.1 函数调用栈在程序中,每当一个函数被调用时,相关的变量和状态信息会被存储在一个称为函数调用栈的栈中。
1.2 表达式求值栈也常用于表达式求值,特别是中缀表达式转后缀表达式的过程中。
通过使用栈,我们可以很方便地进行算术运算。
1.3 逆序输出如果我们需要逆序输出一段文本、字符串或者其他数据,可以使用栈来实现。
将数据依次压入栈中,然后再逐个弹出即可。
2. 队列的实现与应用队列是另一种常见的数据结构,其特点是先进先出。
下面是一些关于队列的实现和应用。
2.1 数组实现队列队列可以使用数组来实现。
我们可以使用两个指针分别指向队列的前端和后端,通过移动指针来实现入队和出队的操作。
2.2 链表实现队列队列还可以使用链表来实现。
我们可以使用一个指针指向队列的头部,并在尾部添加新元素。
通过移动指针来实现出队操作。
2.3 广度优先搜索(BFS)队列常用于广度优先搜索算法。
在BFS中,我们需要按照层级来访问节点。
使用队列可以帮助我们按照顺序存储和访问节点。
3. 树的遍历和应用树是一种非常重要的数据结构,在计算机科学中应用广泛。
下面是一些关于树的遍历和应用的介绍。
3.1 深度优先搜索(DFS)深度优先搜索是树的一种遍历方式。
通过递归或者使用栈的方式,可以按照深度优先的顺序遍历树的所有节点。
3.2 广度优先搜索(BFS)广度优先搜索也可以用于树的遍历。
通过使用队列来保存要访问的节点,可以按照层级的顺序遍历树。
3.3 二叉搜索树二叉搜索树是一种特殊的二叉树,它的每个节点的值都大于左子树中的值,小于右子树中的值。
这种结构可以用于高效地进行数据查找。
4. 图的表示与遍历图是由节点和边组成的一种数据结构。
下面是一些关于图的表示和遍历的说明。
4.1 邻接矩阵表示法邻接矩阵是一种常见的图的表示方法。
使用一个二维数组来表示节点之间的连接关系。
数据结构第六章图理解练习知识题及答案解析详细解析(精华版)

图1. 填空题⑴设无向图G中顶点数为n,则图G至少有()条边,至多有()条边;若G为有向图,则至少有()条边,至多有()条边。
【解答】0,n(n-1)/2,0,n(n-1)【分析】图的顶点集合是有穷非空的,而边集可以是空集;边数达到最多的图称为完全图,在完全图中,任意两个顶点之间都存在边。
⑵任何连通图的连通分量只有一个,即是()。
【解答】其自身⑶图的存储结构主要有两种,分别是()和()。
【解答】邻接矩阵,邻接表【分析】这是最常用的两种存储结构,此外,还有十字链表、邻接多重表、边集数组等。
⑷已知无向图G的顶点数为n,边数为e,其邻接表表示的空间复杂度为()。
【解答】O(n+e)【分析】在无向图的邻接表中,顶点表有n个结点,边表有2e个结点,共有n+2e个结点,其空间复杂度为O(n+2e)=O(n+e)。
⑸已知一个有向图的邻接矩阵表示,计算第j个顶点的入度的方法是()。
【解答】求第j列的所有元素之和⑹有向图G用邻接矩阵A[n][n]存储,其第i行的所有元素之和等于顶点i的()。
【解答】出度⑺图的深度优先遍历类似于树的()遍历,它所用到的数据结构是();图的广度优先遍历类似于树的()遍历,它所用到的数据结构是()。
【解答】前序,栈,层序,队列⑻对于含有n个顶点e条边的连通图,利用Prim算法求最小生成树的时间复杂度为(),利用Kruskal 算法求最小生成树的时间复杂度为()。
【解答】O(n2),O(elog2e)【分析】Prim算法采用邻接矩阵做存储结构,适合于求稠密图的最小生成树;Kruskal算法采用边集数组做存储结构,适合于求稀疏图的最小生成树。
⑼如果一个有向图不存在(),则该图的全部顶点可以排列成一个拓扑序列。
【解答】回路⑽在一个有向图中,若存在弧、、,则在其拓扑序列中,顶点vi, vj, vk的相对次序为()。
【解答】vi, vj, vk【分析】对由顶点vi, vj, vk组成的图进行拓扑排序。
数据结构与算法第六章课后答案第六章 树和二叉树
第6章 树和二叉树(参考答案)6.1(1)根结点a6.2三个结点的树的形态: 三个结点的二叉树的形态:(1) (1) (2) (4) (5)6.3 设树的结点数是n ,则n=n0+n1+n2+……+nm+ (1)设树的分支数为B ,有n=B+1n=1n1+2n2+……+mnm+1 (2)由(1)和(2)有:n0=n2+2n3+……+(m-1)nm+16.4(1) k i-1 (i 为层数)(2) (n-2)/k+1(3) (n-1)*k+i+1(4) (n-1)%k !=0; 其右兄弟的编号 n+16.5(1)顺序存储结构注:#为空结点6.6(1) 前序 ABDGCEFH(2) 中序 DGBAECHF(3) 后序 GDBEHFCA6.7(1) 空二叉树或任何结点均无左子树的非空二叉树(2) 空二叉树或任何结点均无右子树的非空二叉树(3) 空二叉树或只有根结点的二叉树6.8int height(bitree bt)// bt是以二叉链表为存储结构的二叉树,本算法求二叉树bt的高度{ int bl,br; // 局部变量,分别表示二叉树左、右子树的高度if (bt==null) return(0);else { bl=height(bt->lchild);br=height(bt->rchild);return(bl>br? bl+1: br+1); // 左右子树高度的大者加1(根) }}// 算法结束6.9void preorder(cbt[],int n,int i);// cbt是以完全二叉树形式存储的n个结点的二叉树,i是数// 组下标,初始调用时为1。
本算法以非递归形式前序遍历该二叉树{ int i=1,s[],top=0; // s是栈,栈中元素是二叉树结点在cbt中的序号 // top是栈顶指针,栈空时top=0if (n<=0) { printf(“输入错误”);exit(0);}while (i<=n ||top>0){ while(i<=n){visit(cbt[i]); // 访问根结点if (2*i+1<=n) s[++top]=2*i+1; //若右子树非空,其编号进栈i=2*i;// 先序访问左子树}if (top>0) i=s[top--]; // 退栈,先序访问右子树} // END OF while (i<=n ||top>0)}// 算法结束//以下是非完全二叉树顺序存储时的递归遍历算法,“虚结点”用‘*’表示void preorder(bt[],int n,int i);// bt是以完全二叉树形式存储的一维数组,n是数组元素个数。
数据结构课后习题答案第六章
所以
n=n1+2×n2+…+m×nm+1 由(1)(2)可知 n0= n2+2×n3+3×n4+…+(m-1) ×nm+1
(2)
八、证明:一棵满 K 叉树上的叶子结点数 n0 和非叶子结点数 n1 之间满足以下关 系:n0=(k-1)n1+1。 证明:n=n0+n1
n=n1k+1 由上述式子可以推出 n0=(k-1)n1+1 十五、请对右图所示的二叉树进行后序线索化,为每个空指针建立相应的前驱或 后继线索。
四十三、编写一递归算法,将二叉树中的所有结点的左、右子树相互交换。 【分析】 依题意,设 t 为一棵用二叉链表存储的二叉树,则交换各结点的左右子树的
运算基于后序遍历实现:交换左子树上各结点的左右子树;交换右子树上各结点 的左右子树;再交换根结点的左右子树。
【算法】 void Exchg(BiTree *t){ BinNode *p; if (t){ Exchg(&((*t)->lchild)); Exchg(&((*t)->rchild)); P=(*t)->lchild; (*t)->lchild=(*t)->rchild; (*t)->rchild=p; } }
(4)编号为 i 的结点的有右兄弟的条件是什么? 其右兄弟的编号是多少? 解:
(1) 层号为 h 的结点数目为 kh-1 (2) 编号为 i 的结点的双亲结点的编号是:|_ (i-2)/k _|+1(不大于(i-2)/k 的最大整数。也就是(i-2)与 k 整除的结果.以下/表示整除。 (3) 编号为 i 的结点的第 j 个孩子结点编号是:k*(i-1)+1+j; (4) 编号为 i 的结点有右兄弟的条件是(i-1)能被 k 整除
数据结构第6章作业参考答案
第6章图一、选择题1、设有6个结点的无向图,该图至少应有( A )条边才能确保是一个连通图。
A.5B.6C.7D.82、若非连通无向图G含有21条边,则G的顶点个数至少为( B )。
A.7 B.8 C.21 D.223、一个有n个顶点的连通无向图,其边的个数最少为(B )。
A. nB. n-1C. n+1D. nlog2n4、设有向图的顶点个数为n,则该图最多有( B )条弧。
A.n-1 B.n(n-1) C.n(n+1) D. n25、对下面给定的有向图,从顶点1出发,其深度优先搜索序列为(A )。
A. 1,2,5,3,4B. 1,2,4,3,5C. 1,4,3,2,5D. 1,2,3,4,56、具有10个顶点的连通图的深度优先生成树,其边数为(B )。
A. 11B. 9C. 10D. 87、下列说法不正确的是(C )。
A. 图的广度遍历适用于有向图B. 无向图的邻接矩阵是对称矩阵C. 图的深度遍历不适用于有向图D. 图的深度遍历是一个递归过程8、下列说法中正确的是(D )。
A. 一个具有n个顶点的无向完全图的边数为n(n-1)B. 连通图的生成树是该图的一个极大连通子图C. 图的深度优先搜索是一个非递归过程D. 非连通图遍历过程中,每调用一次深度优先搜索算法都得到该图的一个连通分量9、对于有向图,其邻接矩阵表示相比邻接表表示更易于进行的操作为(C )。
A. 求一个顶点的邻接点B. 深度优先遍历C. 求一个顶点的度D. 广度优先遍历10、下列说法正确的是( C )。
A. 图的广度遍历不适用于有向图B. 有向图的邻接矩阵是对称矩阵C. 图的深度遍历适用于有向图D. 图的广度遍历是一个递归过程11、连通网的最小生成树是其所有生成树中(A )。
A. 边权值之和最小的生成树B. 边集最小的生成树C. 顶点权值之和最小的生成树D. 顶点集最小的生成树12、有n个顶点的连通图G的最小生成树有(B )条边。
数据结构课后习题及解析第六章
1.分画出具有3个点的和3个点的二叉的所有不同形。
2.1所得各种形的二叉,分写出前序、中序和后序遍的序列。
3.一棵度k的中有n1个度1的点,n2个度2的点,⋯⋯,nk个度k的点,中有多少个叶子点并明之。
假一棵二叉的先序序列EBADCFHGIKJ,中序序列ABCDEFGHIJK,画出二叉。
5.二叉有50个叶子点,二叉的点数至少有多少个?6.出足以下条件的所有二叉:①前序和后序相同②中序和后序相同③前序和后序相同7.n个点的K叉,假设用具有k个child 域的等点存的一个点,空的Child域有多少个?8.画出与以下序列的T:的先根次序序列GFKDAIEBCHJ;的后根次序序列DIAEKFCJHBG。
9.假用于通的文由8个字母成,字母在文中出的率分:,,,,,,,8个字母哈夫曼。
10.二叉采用二叉表存放,要求返回二叉T的后序序列中的第一个点指,是否可不用且不用来完成?述原因.11.画出和以下的二叉:12.二叉树按照二叉链表方式存储,编写算法,计算二叉树中叶子结点的数目。
13.编写递归算法:对于二叉树中每一个元素值为x的结点,删去以它为根的子树,并释放相应的空间。
14.分别写函数完成:在先序线索二叉树T中,查找给定结点*p在先序序列中的后继。
在后序线索二叉树T中,查找给定结点*p在后序序列中的前驱。
15.分别写出算法,实现在中序线索二叉树中查找给定结点*p在中序序列中的前驱与后继。
16.编写算法,对一棵以孩子-兄弟链表表示的树统计其叶子的个数。
17.对以孩子-兄弟链表表示的树编写计算树的深度的算法。
18.二叉树按照二叉链表方式存储,利用栈的根本操作写出后序遍历非递归的算法。
19.设二叉树按二叉链表存放,写算法判别一棵二叉树是否是一棵正那么二叉树。
正那么二叉树是指:在二叉树中不存在子树个数为 1的结点。
20.计算二叉树最大宽度的算法。
二叉树的最大宽度是指:二叉树所有层中结点个数的最大值。
21.二叉树按照二叉链表方式存储,利用栈的根本操作写出先序遍历非递归形式的算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1
5
1
54 3
42
5 66
图 6-8 图 G 答案:根据不同算法构造的最小生成树如图 6-9 所示的图(a)和(b)
2
④
⑤ 5
1
①
4 3
②
③
6
2
⑤
③ 5
1
①
4 3
④
②
6
(a) Prim 生成树
(b) Kruskal 生成树
图 6-9 最小生成树
5、算法设计
(1)以邻接表为存储结构,设计实现深度优先遍历的非递归算法。
int top = -1; cout<<v<<’\t’; bVisited[v] = true; stack[++top] = v;
//访问结点 v //设置访问标记 //结点 v 入栈
while (top!=-1)
{
v=stack[top];
ArcNode<T> *p = adjlist[v]. firstarc; ①
)
A.1
B. n/2
C.n-1
D.n
解析:若超过 n-1,则路径中必存在重复的顶点
答案:C
(5) 若一个图中包含有 k 个连通分量,若按照深度优先搜索的方法访问所有顶点,则必
须调用(
)次深度优先搜索遍历的算法。
A.k
B.1
C.k-1
D.k+1
解析:一次深度优先搜索可以访问一个连通分量中的所有结点,因此 k 个连通分量需要 调用 k 次深度优先遍历算法。
④
} if (p==NULL) top--;
⑤//若是找不到未访问的结点,出栈
}
}
注:上述代码中标记①~⑤的黑体代码部分为基于邻接矩阵和基于邻接表两种不同的存
储结构实现非递归深度遍历算法的不同之处,请自行对比 6.2.1 小节的代码学习邻接矩阵和
邻接表在处理结点时的区别。
解析:连通分量的定义是极大连通子图,即该子图包含所有的顶点和与这些顶点相连的 所有的边。生成树的定义是极小连通子图,是子图的一种,并且本书所有的图均是无环图,
因此 A、C、D 是正确的。
答案:B
3、画出图 6-7 所示的无向图 G 的邻接表(顶点按照 ASCII 排列),并根据所得邻接表 给出从 A 点开始的深度优先和广度优先搜索遍历该图所的顶点序列。
B
C
D
A
G
E
H
F
答案:邻接表如下图所示:
图 6-7 无向图 G
0A
1
7
1B
0
2
6
7
2C
1
3
6
3D
2
4
6
4E
3
5
6
5F
4
6
7
6G
1
2
3
4
5
7
7H
0
1
5
6
深度优先:ABCDEFGH 广度优先:ABHCGFDE
4、分别使用普里姆算法和克鲁斯卡尔算法构造出如图 6-8 所示图 G 的一棵最小生成树
6 25 36
)。
A.先序遍历
B.中序遍历
C.后序遍历
D.按层遍历。
答案:D
(10) 设有一个无向图 G=(V,E)和 G'=(V',E')如果 G'为 G 的生成树,则下面不正确的说法
是(
)
A.G'为 G 的子图
B.G'为 G 的连通分量
C.G'为 G 的极小连通子图且 V'=V D.G'为 G 的一个无环子图
答案:C
(2) 在一个具有 n 个顶点的有向图中,若所有顶点的出度数之和为 S,则所有顶点的度
数之和为(
)。
A.S
B.S-1
C.S+1
D.2S
答案:A
(3) 具有 n 个顶点的有向图最多有(
)条边。
A.n
B.n(n—1)
C.n(n+1)
D.n2
答案:B
(4) 含 n 个顶点的连通图中任意一条简单路径,其长度不可能超过(
vertex firstarc 顶点结点
};
struct ArcNode{ int adjvex;
//弧结点 //数据域:邻接顶点下标
adjvex nextarc
ArcNode * next;
//指针域:指向下一条弧结点
弧结点
};
const int MAXSIZE =10;
template <class T> class ALGraph //邻接表类
(10) 一棵具有 n 个顶点的生成树有且仅有(______)条边。 答案:n-1
2、 单选题
(1) 在一个无向图中,所有顶点的度数之和等于所有边数的(
)倍
A.1/2
B.1
C.2
D.4
解析:顶点的度指的是与该顶点相连的边数,每一条边和两个顶点相连,因此该条边被 相邻的两个顶点各计算 1 次,因此图的总度数是边数的两倍。
解析:根据图的边集信息可得如图 6-6 所示的无向图,从 A 点开始广度遍历则为 A、B、 C、D、E、F。
B A
D E
C
F
图 6-6 构造无向图
答案:A
(8) 存储无向图的邻接矩阵是(
),存储有向图的邻接矩阵是(
)。
A.对称的
B.非对称的
答案:A B
(9) 采用邻接表存储的图的广度优先遍历算法类似于二叉树的(
{
private:
VertexNode adjlist[MAXSIZE]; //结点
和弧的数目
……
};
程序代码实现:
template <class T>
void AGraph<T>::DFS(int v)
{ int stack[MAXSIZE];
//定义顺序栈
while(p!=NULL)
②
{
int i = p-> adjvex;
③
if(!bVisited[i]) //查找未访问过的邻接点
{
cout<< i <<’\t’; bVisited[i] = true;
//访问结点 i //设置访问标记
stack[++top] = i;
//i 入栈
break;
}
p = p->next;
1
4
2
5
3
图 6-5 构造有向图
答案:A
(7) 若一个图的边集为{(A,B),(A,C),(B,D),(C,F),(D,E),(D,F)},则从顶点 A 开始对该图进
行广度优先遍历,得到的顶点序列可能是(
)。
A. A,B,C,D,E,F B. A,B,C,F,D,E C. A,B,D,C,E,F D. A,B,C, D,F, E
第六章 图
1、填空题
(1) n 个顶点的无向图,最多能有(__________)条边。 解析:完全图是边数最多的图,参考完全图的定义即可。 答案:n*(n-1)/2 (2) 有 n 个顶点的连通无向图 G 至少有(________)条边。 解析:生成树是连通图中边数最少的图,参考生成树的定义即可。 答案:n-1 (3) 有 n 个顶点的强连通有向图 G 至少有(________)条弧。 答案:n (4) G 为无向图,如果从 G 的某个顶点出发,进行一次广度优先遍历,即可访问图的每 个顶点,则该图一定是(_______)图。 解析:若一次遍历能访问所有的结点,说明各个结点之间都可达。 答案:连通 (5) 若采用邻接矩阵结构存储具有 n 个顶点的图,则对该图进行广度优先遍历的算法时 间复杂度为______。 解析:广度优先遍历需要遍历 n 个结点,对于每一个结点需要遍历邻接矩阵的一行以找 出该结点的所有连接点,即循环 n 次,因此,总的时间复杂度是 O(n2)。 答案:O(n2) (6) n 个顶点的连通图的生成树有(______)条边。 答案:n-1 (7) 图的深度优先遍历类似于树的(______)遍历;图的广度优先遍历类似于树的(______) 遍历。 答案:前序 层序 (8) 对于含有 n 个顶点 e 条边的连通图,得用 Prim 算法求最小生成树的时间复杂度为 (______)。 答案:O(n2) (9) 已知无向图 G 的顶点数为 n,边数为 e,其邻接表表示的空间复杂度为(______)。 答案:O(n+e)
答案:A
(6) 若一个图的边集为{<1,2>,<1,4>,<2,5>,<3,1>,<3,5>,<4,3>},则从顶点 1 开始对该图进
行深度优先遍历,得到的顶点序列可能为(
)。
A.1,2,5,4,3
B.1,2,3,4,5
C.1,2,5,3,4
D.1,4,3,2,5。
解析:根据图的边集信息可得如图 6-5 所示的有向图,因此从 1 点开始遍历的顺序可以 为 1、2、5、4、3。
答案:参考 5.2.1 小节基于邻接矩阵实现深度优先遍历的非递归算法,修改查找未访问
过的邻接点的方法即可。实现该算法的邻接表的存储结构如下,包括顶点结点、弧结点和邻
接表类结构:
struct VertexNode{ char Vertex;
ArcNode *firstarc;
//顶点结点 //数据域:顶点信息 //指针域:指向第一条弧