主成分分析操作步骤
主成分分析法的步骤和原理[技巧]
![主成分分析法的步骤和原理[技巧]](https://uimg.taocdn.com/b03d7b9baef8941ea76e0598.webp)
主成分分析法的步骤和原理[技巧](一)主成分分析法的基本思想主成分分析(Principal Component Analysis)是利用降维的思想,将多个变量转化为少数几个综合变量(即主成分),其中每个主成分都是原始变量的线性组合,各主成分之间互不相关,从而这些主成分能够反映始变量的绝大部分信息,[2]且所含的信息互不重叠。
采用这种方法可以克服单一的财务指标不能真实反映公司的财务情况的缺点,引进多方面的财务指标,但又将复杂因素归结为几个主成分,使得复杂问题得以简化,同时得到更为科学、准确的财务信息。
(二)主成分分析法代数模型假设用p个变量来描述研究对象,分别用X,X…X来表示,这p个变量12p t构成的p维随机向量为X=(X,X…X)。
设随机向量X的均值为μ,协方差矩12p阵为Σ。
假设 X 是以 n 个标量随机变量组成的列向量,并且μk 是其第k个元素的期望值,即,μk= E(xk),协方差矩阵然后被定义为:Σ=E{(X-E[X])(X-E[X])}=(如图对X进行线性变化,考虑原始变量的线性组合:Z1=μ11X1+μ12X2+…μ1pXpZ2=μ21X1+μ22X2+…μ2pXp…… …… ……Zp=μp1X1+μp2X2+…μppXp主成分是不相关的线性组合Z,Z……Z,并且Z是X1,X2…Xp的线性组12p1 合中方差最大者,Z是与Z不相关的线性组合中方差最大者,…,Zp是与Z,211Z ……Z都不相关的线性组合中方差最大者。
2p-1(三)主成分分析法基本步骤第一步:设估计样本数为n,选取的财务指标数为p,则由估计样本的原始数据可得矩阵X=(x),其中x表示第i家上市公司的第j项财务指标数据。
ijm×pij 第二步:为了消除各项财务指标之间在量纲化和数量级上的差别,对指标数据进行标准化,得到标准化矩阵(系统自动生成)。
第三步:根据标准化数据矩阵建立协方差矩阵R,是反映标准化后的数据之间相关关系密切程度的统计指标,值越大,说明有必要对数据进行主成分分析。
主成分分析步骤
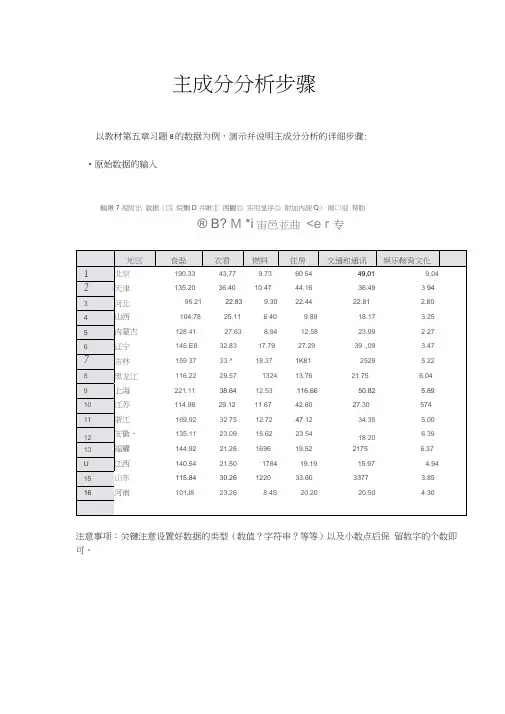
主成分分析步骤以教材第五章习题8的数据为例,演示并说明主成分分析的详细步骤: •原始数据的输入輪锹7 视附出敦据(囚烷飘D 井瞅① 图觀◎ 实用显序◎ 附加内諛Q)爾口迎帮肋® B? M *i宙邑並曲<e r 专注意事项:关键注意设置好数据的类型(数值?字符串?等等)以及小数点后保留数字的个数即可。
•选项操作1. 打开SPSS的“分析”-“降维”-“因子分析” 打开“因子分析”对话框(如下图)倉品女通和通讯选悻变豪(匚Ita(L)£2(R)取清眾助2.把六个变量:食品、衣着、燃料、住房、交通和通讯、娱乐教育文化输入到右边的待分析变量框。
3. 设置分析的统计量打开最右上角的“描述”对话框,选中“统计量”里面的“原始分析结果”和“相关矩阵”里面的“系数”。
(选中原始分析结果,SPSS自动把原始数据标准差标准化,但不显示出来;选中系数,会显示相关系数矩阵。
)。
然后点击“继续”。
统计星□单喪逼椅谨惟(U) 0原赠分忻结果①相关矩阵 ---------------------0 貳数©□ OMN)□泵薯惟水平□ R^(R) □柠列武Q) □反醍數&□ tiMO 和Bartlett 的補誓鹰桧验(K)鍵沽 取消 帮動打开第二个的“抽取”对话框:“方法”里选取“主成分”;“分析”、 和“抽取”这三项都选中各自的第一个选项即可。
然后点击“继续”。
方液血:主磁辞分新 ------------相羌性拒阵〔3)协方遵症阵3抽职特征值大于(&:O 因于的圃定麹・(吵 參槌取的因玖D ; 矗大收皴性电代吹教凶;(25|取请即助第三个的“旋转”对话框里,选取默认的也是第一个选项“无”“输出”输出H 未箍炜的Ema □即石阳鱼]第四个“得分”对话框中,选中“保存为变量”的“回归”;以及“显示因子得分系数矩阵”。
第五个“选项”对话框,默认即可。
这时点击“确定”,进行主成分分析。
主成分分析的步骤与实施方法

主成分分析的步骤与实施方法主成分分析(Principal Component Analysis,简称PCA)是一种常用的降维数据分析方法,常用于数据预处理和特征提取。
本文将介绍主成分分析的基本步骤以及实施方法,帮助读者了解并应用于实际问题。
1. 数据预处理在进行主成分分析之前,首先需要进行数据预处理。
数据预处理包括数据清洗、归一化等操作,以确保数据的准确性和可靠性。
常见的数据预处理方法有:(1)数据清洗:排除异常值和缺失值,保证数据的完整性和一致性;(2)数据归一化:将数据转化为同一尺度,消除因为数据量纲不同而导致的误差;(3)数据标准化:将数据按照均值为0,方差为1进行线性变换,使得数据服从标准正态分布。
2. 计算协方差矩阵主成分分析的核心是通过计算协方差矩阵来确定数据之间的相关性。
协方差矩阵可以帮助我们找到数据的主要变化方向,进而找到主要成分。
协方差矩阵的计算步骤如下:(1)假设我们有m个n维数据,将其组成m×n的矩阵X;(2)计算X的协方差矩阵C,公式为:C = (X - μ)(X - μ)T / m,其中μ为X的均值向量;(3)计算协方差矩阵C的特征值和特征向量。
3. 计算主成分通过计算协方差矩阵的特征值和特征向量,我们可以得到数据的主成分。
主成分是协方差矩阵的特征向量按对应的特征值从大到小排列后所得到的矩阵。
计算主成分的步骤如下:(1)选择特征值较大的前k个特征向量,其中k为需要降维的维数;(2)将选择出的k个特征向量组成一个投影矩阵P;(3)对原始数据进行降维处理,将原始数据矩阵X与投影矩阵P相乘,得到降维后的数据矩阵Y。
4. 数据重构主成分分析完成后,我们可以通过数据重构来验证主成分的有效性。
重构后的数据尽量保持与原始数据的一致性,以确保降维后的数据仍能保持原有信息的完整性。
数据重构的步骤如下:(1)根据降维后的数据矩阵Y和投影矩阵P,计算重构矩阵X',公式为:X' = YP' + μ,其中P'为投影矩阵的转置;(2)将重构矩阵X'与原始数据矩阵X进行对比,评估主成分提取的效果。
因子分析和主成分分析的方法步骤

因子分析和主成分分析的方法步骤
一、主成分分析
步骤(详细步骤见算法大全低二十九章:多元分析)
1)对原始数据进行标准化处理
2)计算相关系数矩阵R
3)计算特征值和特征向量
(要对特征向量进行正则化,即特征向量值/sqrt(对应的特征值),这一步需要自己计算)
4)根据累计贡献率得到主成分P,计算综合评价值
5)②计算综合得分
二、因子分析
步骤(详细步骤见算法大全低二十九章:多元分析)
1.选择分析的变量
2.计算所选原始变量的相关系数矩阵
3.提出公共因子
4.因子旋转
5.计算因子得分
用SPSS解决步骤:
注:以上为主成分分析和因子分析对应的操作步骤,对得到的结果进行相应的分析可以参考《SPSS 统计分析高级教程》中的主成分分析和因子分析。
用SPSS进行主成分分析

用SPSS进行主成分分析首先,我们需要准备输入变量数据。
打开SPSS软件,在工作区中新建一个数据文件,并输入你所需分析的变量数据。
这些变量应该是数值型的,并且具有一定的相关性。
你可以在SPSS的数据视图中输入数据,也可以通过导入外部文件的方式将数据导入SPSS。
接下来,我们需要执行主成分分析。
在SPSS的菜单栏中,选择“分析(Analyze)”-“数据降维(Dimension Reduction)”-“因子(Factor)”,弹出因子分析对话框。
在因子分析对话框中,选择输入变量。
将你所需分析的变量从左边的变量列表中选中,并点击右箭头将其添加到右边的变量列表中。
可以按住Ctrl键,同时选择多个变量。
在选项卡中,选择主成分分析方法。
主成分分析有两种方法可选,即主轴法和最大方差法。
默认情况下,SPSS使用主轴法。
如果你不太了解这两种方法的区别,可以保持默认设置。
在提取方法选项卡中,选择提取的主成分数目。
SPSS会给出每个主成分的特征值大小,你可以根据特征值的大小选择提取的主成分数目。
通常情况下,我们选择特征值大于1的主成分,因为特征值小于1的主成分往往解释的方差较少。
在旋转选项卡中,选择是否进行因子旋转。
因子旋转是为了使每个主成分具有更强的解释力,并且使得主成分之间更容易解释。
SPSS提供了多种旋转方法,包括方差最大旋转(Varimax)、等方差旋转(Equimax)等。
你可以根据具体需求选择合适的旋转方法。
在结果选项卡中,选择输出结果的格式。
SPSS提供了多种结果输出格式,包括表格和图形。
你可以选择你所需的格式并点击确定。
执行完以上步骤后,SPSS会生成主成分分析的结果。
结果包括每个主成分的特征值、解释的方差比例、因子载荷矩阵等。
你可以根据自己的需求来解释这些结果。
最后,我们需要对主成分进行解释和旋转。
根据主成分的因子载荷矩阵,我们可以判断每个主成分与原始变量之间的关系。
载荷值(Factor Loading)表示每个变量对于主成分的贡献程度,绝对值越大,贡献程度越大。
主成分分析操作详细步骤

主成分分析操作详细步骤1.去除均值:对于给定的数据集,先计算每个特征的均值,然后将原始数据减去均值,即进行去均值处理。
这样可以使得数据的中心位于原点附近。
2.计算协方差矩阵:对去均值后的数据集,计算其协方差矩阵。
协方差矩阵描述了各个特征之间的相互关系。
协方差可以通过以下公式计算:cov(X,Y) = Σ((X-μ_X)(Y-μ_Y)) / (n-1)其中,X和Y分别是两个特征向量,μ_X和μ_Y是它们的均值,n 是样本数。
协方差矩阵是一个对称矩阵,对角线上的元素是各个特征的方差。
3.计算特征值和特征向量:对协方差矩阵进行特征值分解,可以得到特征值和对应的特征向量。
特征值表示了数据在特征向量方向上的方差,而特征向量则表示了数据在这个方向上的投影。
特征值和特征向量是成对出现的,每个特征值对应一个特征向量。
4.选择主成分:根据特征值的大小,选择前k个特征值对应的特征向量作为主成分。
这些主成分具有较大的特征值,表示数据在这些方向上的方差较大,所以选择这些主成分可以保留较多的数据信息。
5.数据映射:将原始的数据集映射到选取的主成分所构成的低维空间中。
对于一个样本,可以通过将其与各个主成分进行内积运算,得到其在主成分上的投影。
这样就将高维数据转换为低维数据。
6.可视化和解释:对于得到的低维数据,可以进行可视化展示,以了解数据的分布和结构。
同时,可以通过解释各个主成分的特征向量,来理解数据在不同维度上的重要特征。
7.降维应用:降维后的数据可以应用于其他任务,如数据挖掘、分类、聚类等。
由于降维后的数据具有较低的维度,所以可以提高计算效率,并且可能减小过拟合问题。
需要注意的是,主成分分析假设数据服从线性分布,并且对数据的方差敏感。
因此,在进行主成分分析之前,需要对原始数据进行归一化处理,以避免量纲对结果的影响。
另外,主成分分析还可以通过计算解释方差比例,来评估选择的主成分个数是否合适。
如果选择的主成分个数能够解释大部分的方差,那么可以认为降维后的数据已经保留了原始数据的主要信息。
主成分分析在SPSS中的实现和案例
主成分分析在SPSS中的实现和案例
主成分分析(PCA)是一种常用的数据降维方法,可以将多个相关变量转化为少数几个无关的主成分。
在SPSS中实现PCA的步骤如下:
1. 打开SPSS软件,并打开需要进行PCA分析的数据集。
2. 选择“分析”菜单下的“降维”选项,再选择“因子”。
3. 在弹出的窗口中,选择需要进行PCA分析的变量,添加至“因子”列表中。
4. 点击“提取”按钮,选择提取主成分的方式,可以选择保留的主成分个数或者保留的方差比例。
5. 点击“确定”按钮,返回因子分析结果窗口,可以查看提取的主成分特征根、方差贡献率以及旋转后的载荷矩阵等信息。
下面介绍一个PCA的案例:假设研究人员要对顾客满意度进行研究,数据集包括顾客的年龄、性别、消费金额、服务态度、产品质量等变量。
为了降低变量维度,可以进行PCA分析。
在SPSS 中进行该分析的步骤如上述操作。
结果表明,经过PCA分析,可以选择保留3个主成分,解释总方差达到了80%以上。
第一主成分代表消费水平,第二主成分代表服务品质,第三主成分代表年龄和性别。
这说明顾客的满意度受到这3个方面的影响较大。
总之,主成分分析在SPSS中的实现方法简单易行,可以有效地解决多变量相关性较强的问题,为研究提供更加深入的解释和认识。
(完整版)主成分分析法的步骤和原理
(一)主成分分析法的基本思想主成分分析(Principal Component Analysis )是利用降维的思想,将多个变量转化为少数几个综合变量(即主成分),其中每个主成分都是原始变量的线性组合,各主成分之间互不相关,从而这些主成分能够反映始变量的绝大部分信息,且所含的信息互不重叠。
[2]采用这种方法可以克服单一的财务指标不能真实反映公司的财务情况的缺点,引进多方面的财务指标,但又将复杂因素归结为几个主成分,使得复杂问题得以简化,同时得到更为科学、准确的财务信息。
(二)主成分分析法代数模型假设用p 个变量来描述研究对象,分别用X 1,X 2…X p 来表示,这p 个变量构成的p 维随机向量为X=(X 1,X 2…X p )t 。
设随机向量X 的均值为μ,协方差矩阵为Σ。
对X 进行线性变化,考虑原始变量的线性组合: Z 1=μ11X 1+μ12X 2+…μ1p X pZ 2=μ21X 1+μ22X 2+…μ2p X p…… …… ……Z p =μp1X 1+μp2X 2+…μpp X p主成分是不相关的线性组合Z 1,Z 2……Z p ,并且Z 1是X 1,X 2…X p 的线性组合中方差最大者,Z 2是与Z 1不相关的线性组合中方差最大者,…,Z p 是与Z 1,Z 2 ……Z p-1都不相关的线性组合中方差最大者。
(三)主成分分析法基本步骤第一步:设估计样本数为n ,选取的财务指标数为p ,则由估计样本的原始数据可得矩阵X=(x ij )m ×p ,其中x ij 表示第i 家上市公司的第j 项财务指标数据。
第二步:为了消除各项财务指标之间在量纲化和数量级上的差别,对指标数据进行标准化,得到标准化矩阵(系统自动生成)。
第三步:根据标准化数据矩阵建立协方差矩阵R ,是反映标准化后的数据之间相关关系密切程度的统计指标,值越大,说明有必要对数据进行主成分分析。
其中,R ij (i ,j=1,2,…,p )为原始变量X i 与X j 的相关系数。
主成分分析法的原理应用及计算步骤
主成分分析法的原理应用及计算步骤1.计算协方差矩阵:首先,我们需要将原始数据进行标准化处理,即使每个特征都有零均值和单位方差。
假设我们有m个n维样本,数据集为X,标准化后的数据集为Z。
那么,计算协方差矩阵的公式如下:Cov(Z) = (1/m) * Z^T * Z其中,Z^T为Z的转置。
2.计算特征向量:通过对协方差矩阵进行特征值分解,可以得到特征值和特征向量。
特征值表示了新坐标系中每个特征的重要性程度,特征向量则表示了数据在新坐标系中的方向。
将协方差矩阵记为C,特征值记为λ1, λ2, ..., λn,特征向量记为v1, v2, ..., vn,那么特征值分解的公式如下:C*v=λ*v计算得到的特征向量按特征值的大小进行排序,从大到小排列。
3.选择主成分:从特征向量中选择与前k个最大特征值对应的特征向量作为主成分,即新坐标系的基向量。
这些主成分可以解释原始数据中大部分的方差。
我们可以通过设定一个阈值或者看特征值与总特征值之和的比例来确定保留的主成分个数。
4.映射数据:对于一个n维的原始数据样本x,通过将其投影到前k个主成分上,可以得到一个k维的新样本,使得新样本的方差最大化。
新样本的计算公式如下:y=W*x其中,y为新样本,W为特征向量矩阵,x为原始数据样本。
PCA的应用:1.数据降维:PCA可以通过主成分的选择,将高维数据降低到低维空间中,减少数据的复杂性和冗余性,提高计算效率。
2.特征提取:PCA可以通过寻找数据中的最相关的特征,提取出主要的信息,从而减小噪声的影响。
3.数据可视化:通过将数据映射到二维或三维空间中,PCA可以帮助我们更好地理解和解释数据。
总结:主成分分析是一种常用的数据降维方法,它通过投影数据到一个新的坐标系中,使得投影后的数据具有最大的方差。
通过计算协方差矩阵和特征向量,我们可以得到主成分,并将原始数据映射到新的坐标系中。
PCA 在数据降维、特征提取和数据可视化等方面有着广泛的应用。
主成分分析原理及详解
主成分分析原理及详解PCA的原理如下:1.数据的协方差矩阵:首先计算原始数据的协方差矩阵。
协方差矩阵是一个对称矩阵,描述了不同维度之间的相关性。
如果两个维度具有正相关性,协方差为正数;如果两个维度具有负相关性,协方差为负数;如果两个维度之间没有相关性,协方差为0。
2.特征值分解:对协方差矩阵进行特征值分解,得到特征值和特征向量。
特征值表示该特征向量对应的主成分的方差大小。
特征向量表示数据中每个维度的贡献程度,也即主成分的方向。
3.选择主成分:根据特征值的大小选择前k个主成分,使其对应的特征值之和占总特征值之和的比例达到预定阈值。
这些主成分对应的特征向量构成了数据的新基。
4.数据映射:将原始数据投影到新基上,得到降维后的数据。
投影的方法是将数据点沿着每个主成分的方向上的坐标相加。
PCA的步骤如下:1.数据预处理:对原始数据进行预处理,包括去除均值、缩放数据等。
去除均值是为了消除数据的绝对大小对PCA结果的影响;缩放数据是为了消除数据在不同维度上的量纲差异。
2.计算协方差矩阵:根据预处理后的数据计算协方差矩阵。
3.特征值分解:对协方差矩阵进行特征值分解,得到特征值和特征向量。
4.选择主成分:根据特征值的大小选择前k个主成分,其中k是满足预设的方差百分比的最小主成分数量。
5.数据映射:将原始数据投影到前k个主成分上,得到降维后的数据。
PCA的优缺点如下:2.缺点:PCA是一种线性方法,无法处理非线性数据;PCA对异常值敏感,可能会导致降维后的数据失去重要信息;PCA的解释性较差,不易解释主成分和原始数据之间的关系。
综上所述,PCA是一种常用的数据降维方法,通过保留数据的最大方差,将高维数据映射到低维空间。
它的原理基于协方差矩阵的特征值分解,步骤包括数据预处理、计算协方差矩阵、特征值分解、选择主成分和数据映射。
PCA具有很多优点,如无监督学习、重要特征提取和数据压缩等,但也存在一些缺点,如无法处理非线性数据和对异常值敏感。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
主成分分析操作步骤
1)先在spss中录入原始数据。
2)菜单栏上执行【分析】——【降维】——【因子分析】,打开因素分析对话框,将要分析的变量都放入【变量】窗口中。
3)设计分析的统计量
点击【描述】:选中“Statistics”中的“原始分析结果”和“相关性矩阵”中的“系数”。
(选中原始分析结果,SPSS自动把原始数据标准差标准化,但不显示出来;选中系数,会显示相关系数矩阵)然后点击“继续”。
点击【抽取】:“方法”里选取“主成分”;“分析”、“输出”、“抽取”均选中各自的第一个选项即可。
点击【旋转】:选取第一个选项“无”。
(当因子分析的抽取方法选择主成分法时,且不进行因子旋转,则其结果即为主成分分析)
点击【得分】:选中“保存为变量”,方法中选“回归”;再选中“显示因子得分系数矩阵”。
点击【选项】:选择“按列表排除个案”。
4)结果解读
5)A. 相关系数矩阵:是6个变量两两之间的相关系数大小的方阵。
通过相关系
数可以看到各个变量之间的相关,进而了解各个变量之间的关系。
相關性矩陣
食品衣着燃料住房交通和通讯娱乐教育文化相關食品 1.000 .692 .319 .760 .738 .556 衣着.692 1.000 -.081 .663 .902 .389 燃料.319 -.081 1.000 -.089 -.061 .267 住房.760 .663 -.089 1.000 .831 .387 交通和通讯.738 .902 -.061 .831 1.000 .326 娱乐教育文化.556 .389 .267 .387 .326 1.000
B. 共同度:给出了这次主成分分析从原始变量中提取的信息,可以看出交通和
通讯最多,而娱乐教育文化损失率最大。
Communalities
起始擷取
食品 1.000 .878
衣着 1.000 .825
燃料 1.000 .841
住房 1.000 .810
交通和通讯 1.000 .919
娱乐教育文化 1.000 .584
擷取方法:主體元件分析。
C. 总方差的解释:系统默认方差大于1的为主成分。
如果小于1,说明这个主
因素的影响力度还不如一个基本的变量。
所以只取前两个,且第一主成分的方差
为3.568,第二主成分的方差为1.288,前两个主成分累加占到总方差的80.939%。
說明的變異數總計
元件
起始特徵值擷取平方和載入
總計變異的% 累加% 總計變異的% 累加%
1 3.568 59.474 59.474 3.568 59.474 59.474
2 1.288 21.466 80.939 1.288 21.466 80.939
3 .600 10.001 90.941
4 .358 5.97
5 96.916
5 .142 2.372 99.288
6 .043 .712 100.000
擷取方法:主體元件分析。
特别注意:
该主成分载荷矩阵并不是主成分的特征向量,即不是主成分1和主成分2的系数。
主成分系数的求法:各自主成分载荷向量除以各自主成分特征值得算数平方根。
则第1主成分的各个系数是向量(0.925,0.902,0.880,0.878,0.588,0.093).3后才得到的,即(0.490,0.478,0.466,0.465,0.311,0.049)才是除以568
主成分1的特征向量,满足条件是系数的平方和等于1,分别乘以6个原始变量标准化之后的变量即为第1主成分的函数表达式(作业中不用写公式):
Y1=0.490*Z交+0.478*Z食+0.466*Z衣+0.465*Z住+0.311*Z娱+0.049*Z燃
同理可求出第2主成分的函数表达式。
E.主成分得分系数矩阵
元件評分係數矩陣
元件
1 2
食品.253 .198
衣着.247 -.174
燃料.026 .708
住房.246 -.152
交通和通讯.259 -.196
娱乐教育文化.165 .379
擷取方法:主體元件分析。
元件評分。
该矩阵是主成分载荷矩阵除以各自的方差得来的,实际上是因子分析中各个因子的系数,在主成分分析中可以不考虑它。
元件評分共變異數矩陣
元件 1 2
1 1.000 .000
2 .000 1.000
擷取方法:主體元件分析。
元件評分。
6)因子得分
在之前的“得分”对话框中,由于选中了“保存为变量”,方法中的“回归”;又选中了“显示因子得分系数矩阵”,因此SPSS的输出结果和原始数据一起显示在数据窗口里:
7)主成分得分
特别提醒:
后两列的数据是北京等16个地区的因子1和因子2的得分,不是主成分1和主成分2的得分。
主成分的得分是相应的因子得分乘以相应的方差的算数平方根。
即:主成分1得分=因子1得分乘以3.568的算数平方根
主成分2得分=因子2得分乘以1.288的算数平方根
得出各地区主成分1和主成分2的得分如下表:
后两列就是16个地区主成分1和主成分2的得分。
(有兴趣的同学可以验证一下:上面推导出来的主成分的函数关系式计算出来的主成分得分是否与该数据栏的的得分一致)
8)综合得分及排序:
每个地区的综合得分是按照下列公式计算的:
Y=0.73476*主成分1得分+0.26524*主成分2得分
按照此公式计算出各地区的综合得分Y为:
按照综合得分Y的大小进行16个地区的排序:点击【数据】——【排序个案】
特别提醒:
1.若主成分分析中有n个变量,则特征值(或方差)之和就等于n;
2.特征向量(或主成分的系数)中各个数值的平方和等于1,否则就不是特征向量,也不是主成分系数;
3.主成分载荷向量各系数的平方和等于其对应的主成分的方差;
本例中0.9252 + 0.9022 + 0.8802 + 0.8782 + 0.5882 + 0.0932 = 3.568
4.SPSS没有专门的主成分分析模块,是在因子分析模块进行的。
它只输出主成分载荷矩阵和因子得分值,而我们最想得到的主成分的系数(特征向量)和主成分则需要另外计算。
5.若计算没有错误,因子1、因子2、主成分1、主成分2和综合得分Y,它们各自的数值之和都等于0;
6.主成分分析应该计算出综合得分并排序。