分布式存储参数
SSTable-分布式存储
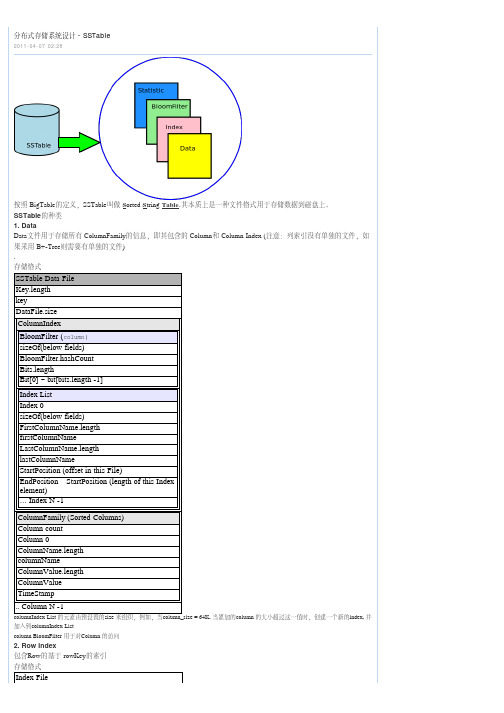
按照BigTable的定义,SSTable叫做S orted S tring Table.其本质上是一种文件格式用于存储数据到磁盘上。
SSTable的种类Key ListKey 0Key.lengthkeyStartPositoin in datafile for the keyKey N-1内存中的数据表示for ReaderKey0StartPosition0 in data file......KeyN-1StartPositionN-1 in data file3. Row Key BloomFilterRow Key BloomFilter用于对基于Row key索引的访问。
Row Key BloomFilter FilesizeOf(below fields)BloomFilter.hashCountBits.lengthBit[0] ~ bit[bits.length -1]4. Statistics统计文件用于统计一个SSTable包含的rowCount,columnCount。
一般情况下会以柱状图的形式出现(Histogram)Statistics FileRow CountSeries [0] ~ Series[n-1]Statistic[0] ~statistic[n-1]Column CountSeries [0] ~ Series[n-1]Statistic[0] ~statistic[n-1]操作1 Write当MemTable达到预设置的极限值时,其内容将依次被flush到磁盘上。
SSTable 的 Data, index, filter, statistic文件将被生成。
write data fileMemTable flush时,写入data文件:- 因为key是按照升序排列的,所以,首先根据key,获得其在文件中的位置- 将key写入- 整个row的大写写入- 写入column index的bloom filter的信息- 写入column index的信息(start position, end position, index size)- 写入column的信息(name, value, timestamp)write Row index file每次向Data文件增加一行记录时,都将向 Row index文件加入以下数据:- 写入Key- 写入key在数据文件中对应的startPositionwrite Row Index BloomFilter每次向Data文件增加一行记录时,都向row Index bloomfilter增加统计信息,当数据文件最终写到磁盘后,对应的BloomFilter文件将生成,原则上是将BloomFilter的Serializer形式写入磁盘即可:- 写入hashCount- 写入bits数据的长度- 依次写bits [0]到bits[n-1]的内容2 Read当系统初始化时,所有的SSTable需要加载到系统.QueryByRowKey1) 首先通过BloomFilter看看key是否存在,如果不存在直接返回(注意:bloomFilter永远不会返回假的不存在)2) 如果存在,则需要进一步证实BloomFilter不是false Positive。
数据服务器参数

数据服务器参数介绍在今天的大数据时代,数据服务器作为存储和处理大量数据的平台,扮演着至关重要的角色。
不同类型的数据和不同的应用场景,都需要不同的数据服务器参数来支持其存储和处理需求。
本文将为您详细介绍数据服务器参数的相关内容。
数据服务器分类常见的数据服务器类型可以分为以下几类:•文件服务器:主要用于文件存储和管理,支持文件共享和访问控制等功能。
•数据库服务器:主要用于数据库存储和管理,支持数据读取、写入、查询、备份等功能。
•缓存服务器:主要用于提高应用程序的性能,存储基于内存的缓存数据,加速数据读取速度。
•分布式存储服务器:主要用于海量数据的分布式存储和管理,支持数据分片、数据冗余、数据迁移等功能。
数据服务器参数不同类型的数据服务器有着不同的参数设置,下面将分别介绍各种数据服务器参数。
文件服务器参数•存储容量:指文件服务器存储的磁盘容量,一般以GB或TB为单位。
•硬盘类型:常见的硬盘类型包括机械硬盘和固态硬盘,机械硬盘读写速度低,价格便宜,而固态硬盘读写速度快,但价格相对较高。
•文件系统:通过文件系统来管理磁盘空间和文件读写,常见的文件系统包括NTFS、FAT32、EXT4等等。
•传输协议:文件服务器通过一些协议来传输文件,如SMB、FTP、SFTP、WebDAV等。
•安全性设置:文件服务器需要设置读取、写入、执行等权限,以确保数据安全性。
•网络带宽:指文件服务器连接网络时的带宽,影响文件传输速度和并发连接数。
数据库服务器参数•存储容量:指数据库服务器存储的数据量,一般以GB或TB为单位。
•数据库类型:常见的数据库类型有MySQL、Oracle、SQL Server、PostgreSQL等。
•硬盘类型:同文件服务器,常见的硬盘类型包括机械硬盘和固态硬盘。
•数据库引擎:决定了数据库的性能和功能特性,如MyISAM、InnoDB、MongoDB等等。
•数据库缓存:通过缓存技术提高查询速度,如使用Redis等内存数据库。
深信服分布式存储 参数

深信服分布式存储的参数主要包括以下几个方面:
1.存储容量:指深信服分布式存储系统能够存储的数据量大小。
通常以字节(B)、千字节(KB)、兆字节(MB)、吉字节(GB)或太字节(TB)为单位进行
表示。
在设计和规划深信服分布式存储系统时,需要根据实际需求来确定所需的存储容量。
2.可扩展性:指深信服分布式存储系统能够根据需要进行水平或垂直扩展的能力。
水平扩展是指通过增加更多的节点来增加系统的容量和性能,而
不影响现有节点的工作负载。
垂直扩展是指通过增加单个节点的处理能力来提高系统的性能。
3.存储节点:每个存储节点都有独立的存储设备和计算资源,可以独立处理数据的读写操作。
存储节点之间通过网络连接进行通信和数据同步,保
证数据的一致性和可靠性。
4.元数据服务:负责存储和管理数据的元数据信息,包括文件的名称、大小、创建时间等。
它可以记录数据的分布和存储位置,提供数据的查找和
访问服务。
这些参数可以帮助您了解深信服分布式存储的特点和功能,从而更好地选择和配置适合您需求的存储解决方案。
请注意,以上信息仅供参考,如有任何具体的技术问题或配置需求,建议咨询深信服的技术支持团队或专业技术人员。
分布式对象存储,块存储,文件存储minio,ceph,glusterfs,openstac。。。

分布式对象存储,块存储,⽂件存储minio,ceph,glusterfs,openstac。
对象存储不是什么新技术了,但是从来都没有被替代掉。
为什么?在这个⼤数据发展迅速地时代,数据已经不单单是简单的⽂本数据了,每天有⼤量的图⽚,视频数据产⽣,在短视频⽕爆的今天,这个数量还在增加。
有数据表明,当今世界产⽣的数据,有80%是⾮关系型的。
那么,对于图⽚,视频等数据的分析可以说是⼤数据与⼈⼯智能的未来发展⽅向之⼀。
但是如何存储这些数据呢?商⽤云⽅案往往价格昂贵,⽽传统的⼤数据解决⽅案并不能充分⽀撑图⽚,视频数据的存储与分析。
本⽂将详细的介绍开源的对象存储解决⽅案Minio的部署与实践,⽂章将分为以下⼏部分进⾏介绍。
本⽂基于2021年10⽉Minio最新版本整理,后续⽂档更新,请关注⼤数据流动⽂档版权所有公众号⼤数据流动,请勿做商⽤,如需转载与作者独孤风联系。
1、对象存储从本质上讲,对象存储是⼀种数据存储架构,允许以⾼度可扩展的⽅式存储⼤量⾮结构化数据。
如今,我们需要在关系或⾮关系数据库中存储的可不仅仅是简单的⽂本信息。
数据类型包括电⼦邮件、图像、视频、⽹页、⾳频⽂件、数据集、传感器数据和其他类型的媒体内容。
也就是⾮结构化的数据。
区别于传统的存储,对象存储⾮常适合图⽚视频等数据的存储。
这⾥就不得不提到另外两种存储⽅式。
⽂件存储 vs 块存储 vs 对象存储⽂件存储是⽹络附加存储,其中数据存储在⽂件夹中。
当需要访问⽂件时,计算机必须知道找到它的完整路径。
块存储将数据保存在原始块中,与⽂件存储不同,它可以通过存储区域⽹络访问,低延迟⾼性能,⼀般⽤于数据库相关操作。
很明显,⽂件存储便于共享,但是性能很差。
块存储性能好,但是⽆法灵活的共享。
那么,有没有⼀种⽅案可以兼顾呢?对象存储对象存储是⼀种全新体系结构,其中每个⽂件都保存为⼀个对象,并且可以通过 HTTP 请求访问它。
这种类型的存储最适合需要管理⼤量⾮结构化数据的场景。
分布式存储解决方案

分布式存储技术架构方案1.需求分析1.1.应用数据流逻辑架构如下图表示,整个系统应用数据流结构。
根据数据流和应用情况,得出下面要求:1)用于存放流数据的存储分为在线、近线和长期归档三部分,容量需求分别不低于150TB、600TB和4PB;2)另有用于管理和索引的数据库、以及服务器虚拟化数据,各占5TB的空间,共10TB空间;3)在线数据保留7天(可根据要求进行灵活修改),7天后自动迁移到近线存储(采用廉价磁盘);迁移后,对应用访问的路径不变。
更长时间的数据(如100天),将按照策略归档到离线光盘库设备;4)流数据的性能需求o在线存储能够支撑3路200MB/s写入流、12路100MB/s写入流和15路100MB/s读取流,即近2GB/s持续写和1.5GB/s持续读的并发读写需求。
o在线到近线的迁移速度,应达到200MB/s。
o近线存储读取速度,可以达到单路80MB/s,支持大于15路读,总共1.2GB/s读。
5)自动解决在线存储上的碎片问题,保证性能;1.2.需求分析1.2.1.管理数据库和虚拟化数据融合部署流数据为典型的顺序I/O,OLTP类型管理数据库根据程序类型,存在随机和顺序I/O多种情况,服务器虚拟化在存储介质中表现为封装好的文件,具备空间局部性特征。
国际主流数据中心建设模式倾向扁平化、大二层组网,融合架构兼具可控性和高扩展性,因此建议合并部署。
1)流数据部署在高性能分布式存储– 提供极高的I/O吞吐性能,并按照在线、近线和离线三部级存储进行署。
下面的文字将主要对这部分需求进行讨论和分析。
2)管理数据库部署在通用磁盘阵列存储上,提供高效的OLTP性能、集成于应用的管理和数据保护功能。
这部分存储容量需求为5TB,主流的企业级存储都可满足要求。
3)服务器虚拟化部署在高性能分布式存储上,充分利用分布式存储性能优势和数据多副本优势,提供高可靠的集群文件系统功能。
由于虚拟化服务器主要使用计算资源,而分布式存储I/O需求较大,有效利用技术优势,利用Hypervisor底层充分整合分布式存储,构建智能的软件定义的数据中心。
CASS参数配置

CASS参数配置CASS(Columnar-All-Scasate-Store)是一款为OLAP(Online Analytical Processing,联机分析处理)而设计的分布式列存储系统。
它的目标是提供高性能的查询和分析能力,同时保持数据的一致性和可靠性。
CASS的参数配置非常重要,它决定了系统的性能、可靠性和扩展性。
下面是一些重要的CASS参数及其配置说明。
1. num_tokens:这个参数决定了集群中每个节点处理的数据量。
每个节点被分配一个或多个token,用于划分数据范围。
适当的num_tokens配置可以实现负载均衡和数据分布的一致性。
通常可以将num_tokens设置为2562. replication_factor:这个参数决定了数据的副本数。
CASS使用副本来保证数据的可靠性和容错能力。
通常可以将replication_factor设置为3,表示每个数据块有3个副本。
4. concurrent_reads和concurrent_writes:这两个参数分别设置了并发读取和并发写入的最大数量。
适当的并发数可以提高系统的吞吐量。
一般可以将concurrent_reads设置为32,concurrent_writes设置为165. memtable_flush_writers和memtable_total_space_in_mb:这两个参数分别设置了Memtable的刷新线程数和总空间。
Memtable是CASS用于缓存数据的内存结构,适当的配置可以提高读写性能。
一般可以将memtable_flush_writers设置为2,memtable_total_space_in_mb设置为10248. phi_convict_threshold:这个参数限制了Gossip协议中的失败检测。
Gossip协议是CASS用于节点之间的通信和状态同步的协议,适当的失败检测可以提高系统的可靠性。
分布参数系统范文
分布参数系统范文
1.分布式参数系统
分布式参数系统是一种将参数存储在多个节点上的方式,它是分布式系统的重要特性之一,用于存储和检索参数信息。
其主要优点在于它可以支持大规模的参数访问和参数查询。
它提供了分布式存储能力,能够同时服务于多种客户端和服务器系统。
2.功能
分布式参数系统的主要功能是支持配置参数的存储和访问。
它可以支持多种存储格式,如XML文件、属性文件、文本文件等,可以支持多种参数格式,如数值、布尔值、字符串等。
此外,它还可以支持参数共享,能够支持用户在多台服务器上共享参数,实现跨机器参数查询。
此外,它还可以支持参数安全,能够为参数提供安全访问控制,以确保参数不能被未经授权的访问者获取。
3.架构
分布式参数系统的架构由一个主服务器和多个客户端组成,通常客户端可以是一台服务器或者由多台服务器组成的集群。
客户端与主服务器之间使用网络通信,客户端可以向主服务器发送参数请求,从而实现参数的存取和查询。
主服务器为管理所有参数的中心,负责接收、处理和响应客户端发出的参数请求,并将参数保存到持久性存储器中。
4.应用。
分布式电源技术参数
分布式电源技术参数分布式电源是指将电力发电、存储和消费系统组织成地理分布较广的多个小规模单元,与传统的集中式电力系统相对应。
分布式电源技术参数包括发电技术参数、存储技术参数和消费技术参数等。
下面将依次介绍这些技术参数。
1.发电技术参数:-发电容量:分布式电源的发电容量通常较小,一般为几十千瓦到几百兆瓦不等。
不同的发电技术对应着不同的发电容量范围。
-发电效率:发电效率是指通过转换能源产生电能的效率,通常以百分比表示。
不同的发电技术具有不同的发电效率水平,例如,光伏发电的效率通常在15%到25%之间。
-发电可靠性:分布式电源的发电可靠性指的是系统故障发生的频率和持续时间。
通过合理的系统设计和备份方案,可以提高分布式电源的发电可靠性。
2.存储技术参数:-存储容量:分布式电源的存储容量是指能够存储的电能量。
不同的存储技术有不同的存储容量,例如,锂离子电池的存储容量可以从几千瓦时到几百兆瓦时不等。
-存储效率:存储效率是指存储系统将电能存储和释放的效率,通常以百分比表示。
高效的存储技术可以提高能量的利用率。
-蓄电池寿命:蓄电池的寿命指的是在正常使用条件下能够提供可接受性能的时间。
蓄电池的使用寿命受到充放电次数、深度充放电和环境温度等因素影响。
3.消费技术参数:-电力需求量:消费技术参数是指分布式电源系统中电力消费者的需求量。
不同的消费者对电力的需求量不同,例如,住宅耗电需求相对较小,而工业厂房的需求量较大。
-消费模式:消费模式是指电力的使用方式和时间分布。
通过合理的消费模式设计,可以更好地匹配电力的供需关系,提高能源的利用效率。
-电力质量:电力质量是指供电系统的稳定性和电力波形的纯净度。
采用分布式电源技术时,需要保证供电系统稳定可靠,同时减小谐波和电压波动等影响电力质量的因素。
总结起来,分布式电源技术参数包括发电技术参数、存储技术参数和消费技术参数等。
这些参数的选择和配置需要根据具体的应用场景和要求进行调整,以满足可靠性、效率和经济性等需求。
glusterFS分布式存储系统
glusterFS分布式存储系统1. glusterfs系统原理 1. glusterfs是什么 分布式⽂件系统 ⽆中⼼架构(⽆元数据服务器) scale-out横向扩展(容量,性能) 集群式NAS存储系统 采⽤异构的标准商业硬件 资源池 全局统⼀命名空间 复制和⾃动修复 易于部署和使⽤ 2. glusterFS基本原理 1. 弹性hash算法 1. 使⽤Davies-Meyer算法计算32位hash值,输⼊参数为⽂件名 2. 根据hash值在集群中选择⼦卷,进⾏⽂件定位 3. 对选择的⼦卷进⾏数据访问 3. glusterFS卷类型 1. 基本卷 1. 哈希卷 ⽂件通过hash算法在所有brick上分布 ⽂件级RAID 0,不具有容错能⼒ 2. 复制卷 ⽂件同步复制到多个brick上 ⽂件级RAID1,具有容错能⼒ 写性能下降,读性能提升 3. 条带卷 单个⽂件分布到多个brick上,⽀持超⼤⽂件 类似RAID 0,以Round-Robin⽅式 2. 复合卷 1. 哈希复制卷 哈希卷和复制卷的复合⽅式 同时具有哈希卷和复制卷的特点 2. 哈希条带卷 3. 复制条带卷 4. 哈希复制条带卷 三种基本卷的复合卷 通常⽤于类map reduce应⽤ 4. glusterFS访问接⼝ ⽀持⽂件存储,块存储,对象存储 5. glusterFS数据修复及添加节点原理 数据修复 1. 发展历程 第⼀代: 按需同步进⾏ 第⼆代: 完全⼈⼯扫描 第三代: 并发⾃动修复(3.3) 第四代: 基于⽇志 2. 触发时机: 访问⽂件⽬录时 3. 判断依据: 扩展属性 添加节点 1. 添加新节点,最⼩化数据重新分配 2. ⽼数据分布模式不变,新数据分布到所有节点上 3. 执⾏rebalance,数据重新分布 容量负载优先 1. 设置容量阈值,优先选择可⽤容量充⾜brick 2. hash⽬标brick上创建⽂件符号链接 3. 访问时解析重定向 2. 主流分布式存储系统对⽐MooseFS(MFS)Ceph GlusterFSLustreMetadata server单个MDS。
vsan参数
vsan参数VSAN(Virtual Storage Area Network)是一种虚拟化存储技术,提供分布式存储功能,并将多个物理存储设备组合成一个虚拟存储池。
这里主要介绍一些与VSAN相关的常见参数:1.存储策略(Storage Policy):VSAN提供了灵活的存储策略设置,可根据应用需求对存储资源进行分配和管理。
存储策略包括冗余级别、性能策略、缓存策略等参数。
2.冗余级别(RAID Level):冗余级别指定了数据在VSAN集群中的冗余方式。
常见的冗余级别包括RAID 1、RAID 5、RAID 6等。
不同的冗余级别提供不同的容错能力和性能特征。
3.缓存策略(Cache Policy):VSAN使用缓存来提高存储性能。
通过设置缓存策略,可以指定将哪些数据存储在缓存中,以加速对数据的访问。
4.存储容量(Storage Capacity):存储容量是指可用于存储数据的总空间。
VSAN允许将多个物理存储设备汇集为一个虚拟存储池,因此存储容量可以根据需要进行扩展和调整。
5.数据亲和性(Data Affinity):数据亲和性是指将特定的虚拟机与特定的存储设备相关联的能力。
通过设置数据亲和性,可以将关键应用的数据存储在性能更高的存储设备上,以提高应用的性能和可靠性。
6.QoS(Quality of Service):VSAN提供了QoS功能,可以对不同虚拟机、虚拟磁盘或虚拟机文件设置不同的性能限制,以确保关键应用的性能。
这些参数可以根据具体环境和需求进行配置和调整,以实现数据存储的可靠性、性能和灵活性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
对象存储桶支持多版本,开启多版本后,桶中的对象都以多版本形式存储。
18
对象存储多中心同步动态感知,支持多中心动态感知功能,能够展示对象存储主站点的业务情况,和实时同步速率;(要求提供界面截图)
19
配置多数据中心部署,通过设置策略可实现多中心的对象数据进行同步或异步复制,当某中心故障,其它数据中心可实现自动接管,保障业务的连续性。当故障中心修复可实现数据反同步,保障数据一致性。多中心可实现统一管理运维。(提供具备CNAS(中国合格评定国家认可委员会)资质的第三方权威评测机构签字盖章的测试报告)
产品参数
类别
序号
参数要求
基本要求
1
国内知名品牌,非OEM产品,非联合产品。拥有自主知识产权,能够提供分布式存储授权软件的自主知识产权证书
2
采用控制器集群全对称冗余架构设计,无独立元数据节点。性能随节点数量的增加而近线性提升。提供多控制器负载均衡及故障自动切换功能。
3
★实配统一容量授权,容量授权不区分块、文件、对象存储服务。要求可灵活分配容量授权到不同存储需求。
配置要求
8
存储节点,本次配置≥4个存储节点;
9
高速缓存,要求至少配置单控制器≥64GB。
10
系统支持千兆、10GE、40GE主机接口,本次要求每个存储节点配置4个千兆口,4个10GE接口(含光模块)。
11
要求每节点配置2块128GB企业级SSD,x块xTB 企业级SSD,x块xT 企业级SATA磁盘。
25
支持Qos功能,可以设置不同用户访问某个bucket的带宽/请求数
26
支持多数据中心部署,统一管理各地数据中心集群,实现数据同步存储;(提供具备CNAS(中国合格评定国家认可委员会)资质的第三方权威评测机构签字盖章的测试报告)
文件存储
27
支持支持NFS V3.0和CIFS 1.0/2.0/3.0 标准接口
20
★配置存储系统支持海量小文件高性能处理功能,支持百亿级海量小文件的高性能处理,可以实现100亿小文件高速写入,且性能衰减不超过5%。(提供具备CNAS(中国合格评定国家认可委员会)资质的第三方权威评测机构签字盖章的测试报告,加盖原厂公章)
21
支持对象存储负载均衡,在保证对象存储高可用的同时,实现负载均衡作用。
12
支持SSD、SAS、NL-SAS、SATA类型硬盘混插;
对象存储
13
支持Amazon S3标准接口,兼容S3生态体系;
14
对象分池处理: 大对象存入EC数据池,有效提高存储空间利用率,小对象和索引数据存入副本性能池
15
支持对象数据网关加密,避免数据通过其他非法途径获取,保证数据安全。
16
支持针对海量小文件存取优化,同时聚合小对象为大数据块整体操作,提升小文件下的空间利用率。
22
支持对象存储整池扩容功能,避免大规模池内扩容导致海量数据重平衡
23
支持bucket的生命周期配置,用于定期清理不需要的旧对象
24
★提供海量小文件快速修复能力,在三节点存储集群100亿小文件规模下,且持续有上传和下载业务,可实现单磁盘损坏,硬盘故障后重建能在15分钟内修复完成,业务不中断,性能下降不超过5%。(提供具备CNAS(中国合格评定国家认可委员会)资质的第三方权威评测机构签字盖章的测试报告)
28ቤተ መጻሕፍቲ ባይዱ
支持文件系统级链接克隆及独立克隆。
块存储
29
支持数据自动重建机制,当主机或者磁盘故障后,自动利用集群内空闲磁盘空间,将故障数据重新恢复,快速恢复数据的冗余度,确保用户数据的可靠性和安全性。(需提供产品功能截图)
30
支持多副本冗余功能,支持2个或以上副本,副本互斥地保存在集群的不同节点,当1个或多个主机或者磁盘故障,确保数据依旧正常访问。
33
故障自动恢复,在主机或者硬盘故障情况下,支持快速数据重建,重建速度1TB/30min,智能感知IO压力,保证运行业务性能;
34
数据自动平衡,支持数据自动和手动进行热平衡,无需中断业务,自动感知业务IO,智能限速。支持设置平衡时间,利用空闲时间平衡数据。(要求提供界面截图)
35
亚健康监测,支持对硬件健康及亚健康状态的检测及管理。通过扫描硬件状态,对故障点做预警分析,同时提出解决方案建议。减少设备故障对信息系统的影响。
4
要求存储系统可提供纯软件版本,纯软件版本兼容主流服务器厂商的X86服务器。
5
要求存储提供高可用能力,在三节点同时提供块/文件/对象三种存储服务时,可实现单节点损坏和单磁盘损坏存储系统依然可读写,且性能稳定。
6
同时提供纠删码、副本做数据保护策略,保障数据冗余安全;
7
★支持在不停机情况下,向集群中添加存储节点,实现业务不中断情况下扩充容量和性能。集群支持节点数不少于4096个。(提供公司产品彩页,并加盖厂商公章)
31
智能缓存,通过基于sraft数据一致性协议实现分布式缓存,提供高性能的I/O读写优化。智能缓存拥有独立的可靠性机制,拥有3副本的容错能力。
32
智能分层,提供数据冷热智能分层,通过SSD缓存针对性提高读写性能。通过智能业务感知,分析判断数据冷热情况,从而实现热数据优先保存性能高的SSD中,从而实现提高存储性能。
36
机械盘加速,通过给机械盘配置缓存空间,提高数据写入磁盘的速度。
37
▲配置界面上提供细化到每个节点的磁盘级监控,在管理界面上每个节点的磁盘与物理服务器真实盘位实现一一对应(要求提供界面截图)
数据安全
38
文件存储,访问审计,对用户访问操作的文件动作进行全量审计,并支持审计日志导出。
39
用户权限管理,支持NFS访问用户鉴权,共享目录访问权限校验,文件修改ACL策略权限校验。