统计学第四章测试答案
统计学习题_第四章_数据分布特征的描述习题答案

统计学习题_第四章_数据分布特征的描述习题答案第四章静态指标分析法(⼀)⼀、填空题1、数据分布集中趋势的测度值(指标)主要有、和。
其中和⽤于测度品质数据集中趋势的分布特征,⽤于测度数值型数据集中趋势的分布特征。
2、标准差是反映的最主要指标(测度值)。
3、⼏何平均数是计算和的⽐较适⽤的⼀种⽅法。
4、当两组数据的平均数不等时,要⽐较其数据的差异程度⼤⼩,需要计算。
5、在测定数据分布特征时,如果M M e X 0==,则认为数据呈分布。
6、当⼀组⼯⼈的⽉平均⼯资悬殊较⼤时,⽤他们⼯资的⽐其算术平均数更能代表全部⼯⼈⼯资的总体⽔平。
⼆.选择题单选题:1.反映的时间状况不同,总量指标可分为()A 总量指标和时点总量指标B 时点总量指标和时期总量指标C 时期总量指标和时间指标D 实物量指标和价值量指标2、某⼚1999年完成产值200万元,2000年计划增长10%,实际完成了231万元,超额完成( )A 5.5%B 5%C 115.5%D 15.5%3、在同⼀变量数列中,当标志值(变量值)⽐较⼤的次数较多时,计算出来的平均数()A 接近标志值⼩的⼀⽅B 接近标志值⼤的⼀⽅C 接近次数少的⼀⽅D 接近哪⼀⽅⽆法判断4、在计算平均数时,权数的意义和作⽤是不变的,⽽权数的具体表现()A 可变的B 总是各组单位数C 总是各组标志总量D 总是各组标志值 5、1998年某⼚甲车间⼯⼈的⽉平均⼯资为520元,⼄车间⼯⼈的⽉平均⼯资为540元,1999年各车间的⼯资⽔平不变,但甲车间的⼯⼈占全部⼯⼈的⽐重由原来的40%提⾼到了60%,则1999年两车间⼯⼈的总平均⼯资⽐1998年()A 提⾼D 不能做结论 6、在变异指标(离散程度测度值)中,其数值越⼩,则()A 说明变量值越分散,平均数代表性越低B 说明变量值越集中,平均数代表性越⾼C 说明变量值越分散,平均数代表性越⾼D 说明变量值越集中,平均数代表性越低7、有甲、⼄两数列,已知甲数列:07.7,70==甲甲σX ;⼄数列:41.3,7==⼄⼄σX 根据以上资料可直接判断( )A 甲数列的平均数代表性⼤B ⼄数列的平均数代表性⼤C 两数列的平均数代表性相同D 不能直接判别8、杭州地区每百⼈⼿机拥有量为90部,这个指标是()A 、⽐例相对指标B 、⽐较相对指标C 、结构相对指标D 、强度相对指标9、某组数据呈正态分布,计算出算术平均数为5,中位数为7,则该数据分布为() A 、左偏分布 B 、右偏分布 C 、对称分布 D 、⽆法判断10、加权算术平均数的⼤⼩() A 主要受各组标志值⼤⼩的影响,与各组次数多少⽆关; B 主要受各组次数多少的影响,与各组标志值⼤⼩⽆关; C 既与各组标志值⼤⼩⽆关,也与各组次数多少⽆关; D 既与各组标志值⼤⼩有关,也受各组次数多少的影响11、已知⼀分配数列,最⼩组限为30元,最⼤组限为200元,不可能是平均数的为() A 、50元 B 、80元 C 、120元 D 、210元12、⽐较两个单位的资料,甲的标准差⼩于⼄的标准差,则()A 两个单位的平均数代表性相同B 甲单位平均数代表性⼤于⼄单位C ⼄单位平均数代表性⼤于甲单位D 不能确定哪个单位的平均数代表性⼤ 13、若单项数列的所有标志值都增加常数9,⽽次数都减少三分之⼀,则其算术平均数() A 、增加9 B 、增加6 C 、减少三分之⼀ D 、增加三分之⼆ 14、如果数据分布很不均匀,则应编制 ( )A 开⼝组B 闭⼝组C 等距数列D 异距数列 15、计算总量指标的基本原则是:( )A 总体性B 全⾯性16、某企业的职⼯⼯资分为四组:800元以下;800-1000元;1000—1500元;1500以上,则1500元以上这组组中值应近似为 ( )A1500元 B 1600元 C 1750元 D 2000元 17、统计分组的⾸要问题是 ( )A 选择分组变量和确定组限B 按品质标志分组C 运⽤多个标志进⾏分组,形成⼀个分组体系D 善于运⽤复合分组18、某连续变量数列,其末组为开⼝组,下限为200,⼜知其邻组的组中值为170,则末组组中值为 ( )A 230B 260C 185D 215 19、分配数列中,靠近中间的变量值分布的次数少,靠近两端的变量值分布的次数多,这种分布的类型是 ( )A 钟型分布B U 型分布C J 型分布D 倒J 型分布 20、要了解上海市居民家庭的开⽀情况,最合适的调查⽅式是:() A 普查 B 抽样调查 C 典型调查 D 重点调查21、已知两个同类企业的职⼯平均⼯资的标准差分别为5元和6元,⽽平均⼯资分别为3000元,3500元则两企业的⼯资离散程度为 ( )A 甲⼤于⼄B ⼄⼤于甲C ⼀样的D ⽆法判断 22、加权算术平均数的⼤⼩取决于 ( )A 变量值B 频数C 变量值和频数D 频率23、如果所有标志值的频数都减少为原来的1/5,⽽标志值仍然不变.那么算术平均数 ( ) A 不变 B 扩⼤到5倍 C 减少为原来的1/5D 不能预测其变化 24、计算平均⽐率最好⽤ ( )A 算术平均数B 调和平均数C ⼏何平均数D 中位数25、若两数列的标准差相等⽽平均数不同,在⽐较两数列的离散程度⼤⼩时,应采⽤ ( ) A 全距 B 平均差 C 标准差 D 标准差系数26、若n=20,∑∑==2080,2002x x ,标准差为 ( )A 2B 4C 1.5D 327、已知某总体3215,3256==eMM,则数据的分布形态为( )A左偏分布 B 正态分布 C 右偏分布 D U型分布28、⼀次⼩型出⼝商品洽谈会,所有⼚商的平均成交额的⽅差为156.25万元,标准差系数为14.2%,则平均成交额为( )万元A11 B 177.5 C 22.19 D 8826、欲粗略了解我国钢铁⽣产的基本情况,调查了上钢、鞍钢等⼗⼏个⼤型的钢铁企业,这是()A普查B重点调查C典型调查D抽样调查多选题:1.某企业计划2000年成本降低率为8%,实际降低了10%。
统计学第四章答案
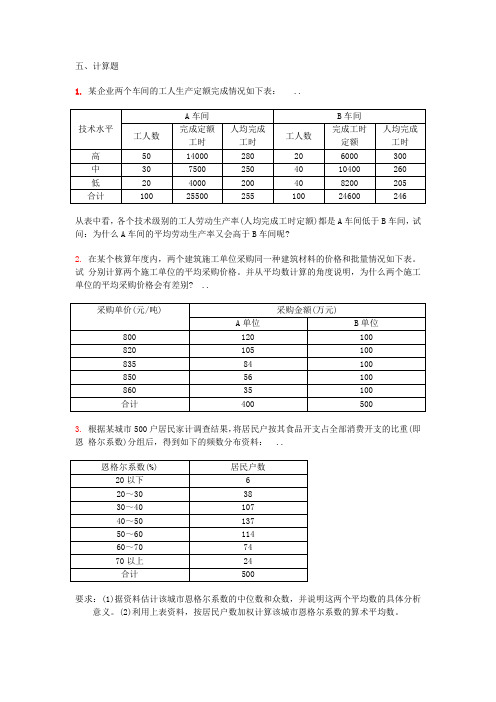
五、计算题1.某企业两个车间的工人生产定额完成情况如下表: ..技术水平A车间B车间工人数完成定额工时人均完成工时工人数完成工时定额人均完成工时高50 14000 280 20 6000 300 中30 7500 250 40 10400 260 低20 4000 200 40 8200 205 合计100 25500 255 100 24600 246从表中看,各个技术级别的工人劳动生产率(人均完成工时定额)都是A车间低于B车间,试问:为什么A车间的平均劳动生产率又会高于B车间呢?2.在某个核算年度内,两个建筑施工单位采购同一种建筑材料的价格和批量情况如下表。
试分别计算两个施工单位的平均采购价格。
并从平均数计算的角度说明,为什么两个施工单位的平均采购价格会有差别?..采购单价(元/吨) 采购金额(万元)A单位B单位800 120 100820 105 100835 84 100850 56 100860 35 100合计400 5003.根据某城市500户居民家计调查结果,将居民户按其食品开支占全部消费开支的比重(即恩格尔系数)分组后,得到如下的频数分布资料:..恩格尔系数(%) 居民户数20以下 620~30 3830~40 10740~50 13750~60 11460~70 7470以上24合计500要求:(1)据资料估计该城市恩格尔系数的中位数和众数,并说明这两个平均数的具体分析意义。
(2)利用上表资料,按居民户数加权计算该城市恩格尔系数的算术平均数。
(3)试考虑,上面计算的算术平均数能否说明该城市恩格尔系数的一般水平?为什么?4.某年某月份甲、乙两农贸市场某农产品价格及成交量、成交额的资料如下:品种价格(元/斤) 甲市场成交额(万元) 乙市场成交量(万斤)甲 1.2 1.2 2乙 1.4 2.8 1丙 1.5 1.5 1合计— 5.5 4试问哪一个市场农产品的平均价格高,并说明其原因。
统计学第四章课后题及答案解析

第四章一、单项选择题1.由反映总体单位某一数量特征的标志值汇总得到的指标是()A.总体单位总量B.质量指标C.总体标志总量D.相对指标2.各部分所占比重之和等于1或100%的相对数()A.比例相对数B.比较相对数C.结构相对数D.动态相对数3.某企业工人劳动生产率计划提高5%,实际提高了10%,则提高劳动生产率的计划完成程度为()A.104.76%B.95.45%C.200%D.4.76%4.某企业计划规定产品成本比上年度降低10%实际产品成本比上年降低了14.5%,则产品成本计划完成程度()A.14.5%B.95%C.5%D.114.5%5.在一个特定总体内,下列说法正确的是( )A.只存在一个单位总量,但可以同时存在多个标志总量B.可以存在多个单位总量,但必须只有一个标志总量C.只能存在一个单位总量和一个标志总量D.可以存在多个单位总量和多个标志总量6.计算平均指标的基本要求是所要计算的平均指标的总体单位应是()A.大量的B.同质的C.有差异的D.不同总体的7.几何平均数的计算适用于求()A.平均速度和平均比率B.平均增长水平C.平均发展水平D.序时平均数8.一组样本数据为3、3、1、5、13、12、11、9、7这组数据的中位数是()A.3B.13C.7.1D.79.某班学生的统计学平均成绩是70分,最高分是96分,最低分是62分,根据这些信息,可以计算的测度离散程度的统计量是()A.方差B.极差C.标准差D.变异系数10.用标准差比较分析两个同类总体平均指标的代表性大小时,其基本的前提条件是( )A.两个总体的标准差应相等B.两个总体的平均数应相等C.两个总体的单位数应相等D.两个总体的离差之和应相等11.已知4个水果商店苹果的单价和销售额,要求计算4个商店苹果的平均单价,应采用()A.简单算术平均数B.加权算术平均数C.加权调和平均数D.几何平均数12.算术平均数、众数和中位数之间的数量关系决定于总体次数的分布状况。
统计学课后习题答案_(第四版)4.5.7.8章

《统计学》第四版 第四章练习题答案4.1 (1)众数:M 0=10; 中位数:中位数位置=n+1/2=5.5,M e =10;平均数:6.91096===∑nxx i(2)Q L 位置=n/4=2.5, Q L =4+7/2=5.5;Q U 位置=3n/4=7.5,Q U =12 (3)2.494.1561)(2==-=∑-n i s x x (4)由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
4.2 (1)从表中数据可以看出,年龄出现频数最多的是19和23,故有个众数,即M 0=19和M 0=23。
将原始数据排序后,计算中位数的位置为:中位数位置= n+1/2=13,第13个位置上的数值为23,所以中位数为M e =23(2)Q L 位置=n/4=6.25, Q L ==19;Q U 位置=3n/4=18.75,Q U =26.5(3)平均数==∑nx x i600/25=24,标准差65.612510621)(2=-=-=∑-n i s x x(4)偏态系数SK=1.08,峰态系数K=0.77(5)分析:从众数、中位数和平均数来看,网民年龄在23-24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大差异。
从偏态系数来看,年龄分布为右偏,由于偏态系数大于1,所以,偏斜程度很大。
由于峰态系数为正值,所以为尖峰分布。
4.3 (1(2)==∑nx x i63/9=7,714.0808.41)(2==-=∑-n i s x x (3)由于两种排队方式的平均数不同,所以用离散系数进行比较。
第一种排队方式:v 1=1.97/7.2=0.274;v 2=0.714/7=0.102.由于v 1>v 2,表明第一种排队方式的离散程度大于第二种排队方式。
(4)选方法二,因为第二种排队方式的平均等待时间较短,且离散程度小于第一种排队方式。
4.4 (1)==∑nx x i8223/30=274.1中位数位置=n+1/2=15.5,M e =272+273/2=272.5(2)Q L 位置=n/4=7.5, Q L ==(258+261)/2=259.5;Q U 位置=3n/4=22.5,Q U =(284+291)/2=287.5(3) 17.211307.130021)(2=-=-=∑-n i s x x4.5 (1)甲企业的平均成本=总成本/总产量=41.193406600301500203000152100150030002100==++++乙企业的平均成本=总成本/总产量=29.183426255301500201500153255150015003255==++++原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。
《统计学原理》第四章习题

《统计学原理》第四章习题及答案一.判断题部分题目1:同一个总体,时期指标值的大小与时期长短成正比,时点指标值的大小与时点间隔成反比。
()题目2:全国粮食总产量与全国人口对比计算的人均粮食产量是平均指标。
()题目3:根据分组资料计算算术平均数,当各组单位数出现的次数均相等时,按加权算数平均数计算的结果与按简单算数平均数计算的结果相同。
()题目4:同一总体的一部分数值与另一部分数值对比得到的相对指标是比较相对指标。
()题目5:某年甲、乙两地社会商品零售额之比为1:3,这是一个比例相对指标。
()题目6:某企业生产某种产品的单位成本,计划在上年的基础上降低2%,实际降低了3%,则该企业差一个百分点,没有完成计划任务。
()题目7:标准差系数是标准差与平均数之比,它说明了单位标准差下的平均水平。
()题目8:1999年与1998年相比,甲企业工人劳动生产率是乙企业的一倍,这是比较相对指标。
()题目9:中位数与众数都是位置平均数,因此用这两个指标反映现象的一般水平缺乏代表性。
()题目10:对两个性质相同的变量数列比较其平均数的代表性,都可以采用标准差指标。
()题目11:利用变异指标比较两总体平均数的代表性时,标准差越小,说明平均数的代表性越大;标准差系数越小,则说明平均数的代表性越小。
()题目12:标志变异指标数值越大,说明总体中各单位标志值的变异程度越大,则平均指标的代表性越小。
()题目13:权数对算数平均数的影响作用只表现为各组出现次数的多少,与各组次数占总次数的比重无关。
()题目14;能计算总量指标的总体必须是有限总体。
()二.单项选择题题目1:反映社会经济现象发展总规模、总水平的综合指标是()。
A、质量指标B、总量指标C、相对指标D、平均指标题目2:总量指标按反映时间状况的不同,分为()。
A、数量指标和质量指标B、时期指标和时点指标C、总体单位总量和总体标志总量D、实物指标和价值指标题目3:总量指标是用()表示的。
统计学第四章测试答案

第四章1、一组数据中出现频数最多的变量值称为()A。
众数 B.中位数 C。
四分位数 D。
平均数2、下列关于众数的叙述,不正确的是()A。
一组数据可能存在多个众数 B.众数主要适用于分类数据C.一组数据的众数是唯一的 D。
众数不受极端值的影响3、一组数据排序后处于中间位置上的变量值称为()A。
众数 B。
中位数 C。
四分位数 D。
平均数4、一组数据排序后处于25%和75%位置上的值称为( )A。
众数 B.中位数 C。
四分位数 D。
平均数5、非众数组的频数占总频数的比例称为()A。
异众比率 B。
离散系数 C。
平均差 D.标准差6、四分位差是()A。
上四分位数减下四分位数的结果B.下四分位数减下四分位数的结果C。
下四分位数加上四分位数D。
下四分位数与上四分位数的中间值7、一组数据的最大值与最小值之差称为()A。
平均差 B.标准差 C.极差 D。
四分位差8、各变量值与其平均数离差平方的平均数称为( )A.极差B.平均差C。
方差 D.标准差9、变量值与其平均数的离差除以标准差后的值称为( )A。
标准分数 B.离散系数 C.方差 D.标准差10、如果一个数据的标准分数是—2,表明该数据( )A。
比平均数高出2个平均差B。
比平均数低2个标准差C.等于2倍的平均数 D。
等于2倍的标准差11-15AABCA11、如果一个数据的标准分数是3,表明该数据( )A。
比平均数高出3个标准差 B。
比平均数低3个标准差C.等于3倍的平均数D.等于3倍的标准差12、经验法则表明,当一组数据对称分布时,在平均数加减1个标准差的范围内大约有( )A。
68%的数据 B。
95%的数据 C.99%的数据 D.100%的数据13、经验法则表明,当一组数据对称分布时,在平均数加减2个标准差的范围内大约有( )A.68%的数据B.95%的数据C.99%的数据 D。
100%的数据14、经验法则表明,当一组数据对称分布时,在平均数加减3个标准差的范围内大约有()A。
统计学第四章习题答案
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing0Mean9.60Median10.00Mode10Std. Deviation 4.169Percentiles25 6.255010.0075单位:周岁19152925242321382218302019191623272234244120311723要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数: ()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
为比较哪种排队方式使顾客等待的时间更短.两种排队方式各随机抽取9名顾客。
统计学第四章答案
应用统计学(答案)第四章P834.19解:依题意提出假设:01:82;:82.μμ≥<H H 由Excel 中的ZTEST 函数得到的检验P 值为:()011:32,820.00850.01,拒绝α=-=<=P ZTESE A A H , 该城市空气中悬浮颗粒的平均值显著低于过去的平均值。
4.20解:依题意提出假设:01:=25;:25.H H μμ≠ 由于是小样本,采取t 检验。
计算得到的统计量为: 1.036905t =.由Excel 中的TDIST 函数得到的检验p 值为:()1.039905,19,20.3114370.05,α==>=P TDIST 0H 不拒绝, 没有证据表明该企业生产的金属板不符合要求。
4.21解:依题意提出假设:01:17;:17.%%ππ≤>H H 检验统计量为:()0,1 2.440.0070.05,拒绝H α=-=<=P NORMSDIST该生产商的说法是属实的。
4.23解:依题意提出假设:012112:-=0;:0.H H μμμμ-≠(1)用Excel 【数据分析】工具中的【t-检验:双样本等方差假设】进行检验,结果为:t-检验:双样本等方差假设2.44z ===(2)用Excel 【数据分析】工具中的【t-检验:双样本异方差假设】进行检验,结果为:t-检验:双样本异方差假设由于“()=t 双尾<P T ”小于0=0.05H α,拒绝,表明两种方法的培训效果有显著差异。
4.24解:依题意提出假设:2222012112:=1: 1.H H σσσσ≠,利用Excel 【数据分析】工具中的【F-检验:双样本方差分析】进行检验得到的结果为:F-检验:双样本方差分析由于“()=f 单尾<P F ”小于0=0.025H α,拒绝,表明两部机器生产的袋装茶重量的方差存在显著差异。
4.25解:(1)依题意提出假设:012112:-0;:0.μμμμ≤->H H用Excel 【数据分析】工具中的【t-检验:双样本等方差假设】进行检验,结果为: t-检验:双样本异方差假设由于“()=t 单尾<P T ”小于0=0.025H α,拒绝,表明新肥料获得的平均产量显著地高于旧废料。
统计学课后第四章习题答案
第4章练习题1、一组数据中出现频数最多的变量值称为()A.众数B.中位数C.四分位数D.平均数2、下列关于众数的叙述,不正确的是()A.一组数据可能存在多个众数B.众数主要适用于分类数据C.一组数据的众数是唯一的D.众数不受极端值的影响3、一组数据排序后处于中间位置上的变量值称为()A.众数B.中位数C.四分位数D.平均数4、一组数据排序后处于25%和75%位置上的值称为()A.众数B.中位数C.四分位数D.平均数5、非众数组的频数占总频数的比例称为()A.异众比率B.离散系数C.平均差D.标准差6、四分位差是()A.上四分位数减下四分位数的结果B.下四分位数减上四分位数的结果C.下四分位数加上四分位数D.下四分位数与上四分位数的中间值7、一组数据的最大值与最小值之差称为()A.平均差B.标准差C.极差D.四分位差8、各变量值与其平均数离差平方的平均数称为()A.极差B.平均差C.方差D.标准差9、变量值与其平均数的离差除以标准差后的值称为()A.标准分数B.离散系数C.方差D.标准差10、如果一个数据的标准分数-2,表明该数据()A.比平均数高出2个标准差B.比平均数低2个标准差C.等于2倍的平均数D.等于2倍的标准差11、经验法则表明,当一组数据对称分布时,在平均数加减2个标准差的范围之内大约有()A.68%的数据B.95%的数据C.99%的数据D.100%的数据12、如果一组数据不是对称分布的,根据切比雪夫不等式,对于k=4,其意义是()A.至少有75%的数据落在平均数加减4个标准差的范围之内B. 至少有89%的数据落在平均数加减4个标准差的范围之内C. 至少有94%的数据落在平均数加减4个标准差的范围之内D. 至少有99%的数据落在平均数加减4个标准差的范围之内13、离散系数的主要用途是()A.反映一组数据的离散程度B.反映一组数据的平均水平C.比较多组数据的离散程度D.比较多组数据的平均水平14、比较两组数据离散程度最适合的统计量是()A.极差B.平均差C.标准差D.离散系数15、偏态系数测度了数据分布的非对称性程度。
统计学第4章练习题及答案
第4章 练习题 一、单项选择题1.平均指标反映了( )①总体次数分布的集中趋势 ②总体分布的特征③总体单位的集中趋势 ④总体次数分布的离中趋势2.某单位的生产小组工人工资资料如下:90元、100元、110元、120元、128元、148元、200元,计算结果均值为128=X 元,标准差为( )①σ=33 ②σ=34 ③σ=34.23 ④σ=35 3.众数是总体中下列哪项的标志值( ) ①位置居中 ②数值最大 ③出现次数较多 ④出现次数最多4.某工厂新工人月工资400元,工资总额为200000元,老工人月工资800元,工资总额80000元,则平均工资为( )①600元 ②533.33元 ③466.67元 ④500元5.标志变异指标说明变量的( )①变动趋势 ②集中趋势 ③离中趋势 ④一般趋势 6.标准差指标数值越小,则反映变量值( )①越分散,平均数代表性越低 ②越集中,平均数代表性越高 ③越分散,平均数代表性越高 ④越集中,平均数代表性越低 7.在抽样推断中应用比较广泛的指标是( )①全距 ②平均差 ③标准差 ④标准差系数二、多项选择题1.根据标志值在总体中所处的特殊位置确定的平均指标有( ) ①算术平均数 ②调和平均数 ③几何平均数 ④众数 ⑤中位数2.影响加权算术平均数的因素有( )①总体标志总量 ②分配数列中各组标志值③各组标志值出现的次数 ④各组单位数占总体单位数比重 ⑤权数3.标志变异指标有( )①全距 ②平均差 ③标准差 ④标准差系数 ⑤相关系数 4.在组距数列的条件下,计算中位数的公式为( )①i f S fL M mm e ⋅-+=+∑12②i f S fU M m m e ⋅-=∑12--③i f S fL M mm e ⋅-+=∑12- ④i f S fU M mm e ⋅-=+∑12-⑤i f S fU M mm e ⋅-=∑12-+5.几何平均数的计算公式有( )①n n n X X X X ⋅⋅⋅121-Λ ②nX X X X nn ⋅⋅⋅121-Λ③122121-++++n X X X X nn -Λ ④∑f fIIX ⑤n IIX三、计算题1.某企业360名工人生产某种产品的资料如表1:试分别计算7、8月份平均每人日产量,并简要说明8月份平均每人日产量变化的原因。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第四章1、一组数据中出现频数最多的变量值称为()A.众数B.中位数C.四分位数D.平均数2、下列关于众数的叙述,不正确的是()A.一组数据可能存在多个众数B.众数主要适用于分类数据C.一组数据的众数是唯一的D.众数不受极端值的影响3、一组数据排序后处于中间位置上的变量值称为()A.众数B.中位数C. 四分位数D.平均数4、一组数据排序后处于25%和75%位置上的值称为()A.众数B.中位数C. 四分位数D.平均数5、非众数组的频数占总频数的比例称为()A.异众比率B.离散系数C.平均差D.标准差6、四分位差是()A.上四分位数减下四分位数的结果B.下四分位数减下四分位数的结果C.下四分位数加上四分位数D.下四分位数与上四分位数的中间值7、一组数据的最大值与最小值之差称为()A.平均差B.标准差C.极差D.四分位差8、各变量值与其平均数离差平方的平均数称为()A.极差B.平均差C.方差D.标准差9、变量值与其平均数的离差除以标准差后的值称为()A.标准分数B.离散系数C.方差D.标准差10、如果一个数据的标准分数是-2,表明该数据()A.比平均数高出2个平均差B.比平均数低2个标准差C.等于2倍的平均数D.等于2倍的标准差11-15AABCA11、如果一个数据的标准分数是3,表明该数据()A.比平均数高出3个标准差B. 比平均数低3个标准差C.等于3倍的平均数D.等于3倍的标准差12、经验法则表明,当一组数据对称分布时,在平均数加减1个标准差的范围内大约有()A.68%的数据B.95%的数据C.99%的数据D.100%的数据13、经验法则表明,当一组数据对称分布时,在平均数加减2个标准差的范围内大约有()A.68%的数据B.95%的数据C.99%的数据D.100%的数据14、经验法则表明,当一组数据对称分布时,在平均数加减3个标准差的范围内大约有()A.68%的数据B.95%的数据C.99%的数据D.100%的数据15、如果一组数据不是对称分布的,根据切比雪夫不等式,对于k=2,其意义是()A.至少有75%的数据落在平均数加减2个标准差的范围之内B.至少有89%的数据落在平均数加减2个标准差的范围之内C. 至少有94%的数据落在平均数加减2个标准差的范围之内D. 至少有99%的数据落在平均数加减2个标准差的范围之内16-20BCCDA16、如果一组数据不是对称分布的,根据切比雪夫不等式,对于k=3,其意义是()A.至少有75%的数据落在平均数加减2个标准差的范围之内B.至少有89%的数据落在平均数加减2个标准差的范围之内C.至少有94%的数据落在平均数加减2个标准差的范围之内D.至少有99%的数据落在平均数加减2个标准差的范围之内17、如果一组数据不是对称分布的,根据切比雪夫不等式,对于k=3,其意义是()A.至少有75%的数据落在平均数加减2个标准差的范围之内B.至少有89%的数据落在平均数加减2个标准差的范围之内C.至少有94%的数据落在平均数加减2个标准差的范围之内D.至少有99%的数据落在平均数加减2个标准差的范围之内18、离散系数的主要用途是()A.反映一组数据的离散水平B.反映一组数据的平均水平C.比较多组数据的离散程度D.比较多组数据的平均水平19、比较两组数据的离散程度最适合的统计量是()A.极差B.平均差C.标准差D.离散系数20、偏态系数测度了数据分布的非对称性程度。
如果一组数据的分布是对称的,则偏态系数()A.等于0B.等于1C.大于0D.大于121-25 BAABB21、如果一组数据分布的偏态系数在0.5~1或-1~-0.5之间,则表明该组数据属于()A.对称分布B.中等偏态分布C.高度偏态分布D.轻微偏态分布22、峰态通常是与标准正态分布相比较而言的。
如果一组数据服从标准正态分布,则峰态系数的值()A. 等于0B.等于1C.大于0D.大于123、如果峰态系数k>0,表明该组数据是()A.尖峰分布B.扁平分布C.左偏分布D.右偏分布24,某大学经济管理学院有1200名学生,法学院有800名学生,医学院有320名学生,理学院有200学生。
在上面的描述中,众数是()A.1200B.经济管理学院C.200D.理学院25,某小区准备采取新的物业管理措施,随机抽取了100户居民进行调查,其中赞成的有69户,中立的有22户,反对的有9户,描述该组数据的集中趋势宜采用()A.众数B.中位数C.四分位数D.平均数26-30AABAC26. 某小区准备采取新的物业管理措施,随机抽取了100户居民进行调查,其中赞成的有69户,中立的有22户,反对的有9户,该组数据的中位数是()A.赞成B.69 C。
中立 D.2227.某班有25名学生,期末统计学课程的考试分数分别为:68,73,66,76,86,74,61,89,65,90,69,67,76,62,81,63,68,81,70,73,60,87,75,64,56,该班考试分数的下四分位数和上四分位数分别为()A.64.5和78.5B.67.5和71.5C.64.5和71.5D.64.5和67.528.假定一个样本由5个数据组成:3,7,8,9,13,该样本的方差为()A.8B.13C.9.7D.10.429.对于右偏分布,平均数、中位数和众数之间的关系是()A.平均数>中位数>众数 B.中位数>平均数>众数C. 众数>中位数>平均数D.众数>平均数>中位数30.在某行业中随机抽取10家企业,第一季度的利润额(万元)分别为:72,63.1,54.7,54.3,29,26.9,25,23.9,23,20.该组数据的中位数为()A.28.46B.30.20C.27.95D.28.1231-35DBBAC31. 在某行业中随机抽取10家企业,第一季度的利润额(万元)分别为:72,63.1,54.7,54.3,29,26.9,25,23.9,23,20.该组数据的平均数为()A.28.46B.30.20C.27.95D.39.1932. 在某行业中随机抽取10家企业,第一季度的利润额(万元)分别为:72,63.1,54.7,54.3,29,26.9,25,23.9,23,20.该组数据的平均数为()A.28.46B.19.54C.27.95D.381.9433.某班学生的统计学平时成绩是70分,最高96,最低62,根据这些信息,可以计算的测度离散程度的统计量是()A.方差B.极差C.标准差D.变异系数34.某班学生的平均成绩为80分,标准差是10分,如果已知该班学生的考试分数对称分布,可以判断成绩在60~100分之间的学生大约占()A. 95%B.89%C.68%D.99%35. 某班学生的平均成绩为80分,标准差是10分,如果已知该班学生的考试分数对称分布,可以判断成绩在70~90分之间的学生大约占()A. 95%B.89%C.68%D.99%36-40DBBDA36. 某班学生的平均成绩为80分,标准差是5分,如果已知该班学生的考试分数非对称分布,可以判断成绩在70~90分之间的学生至少占()A.95%B.89%C.68%D.75%37.在某公司进行的计算机水平测试中,新员工的平均分为80分,标准差是5分,假设新员工得分的分布是未知的,则得分在65~95分的新员工至少占()A.75%B.89%C.94%D.95%38. 在某公司进行的计算机水平测试中,新员工的平均分为80分,标准差是5分,中位数是86分,则新员工得分的分布形状是()A.对称的B.左偏得C.右偏的D.无法确定39.对某个高速公路段行驶过的120辆汽车的车速进行测量后发现,平均车速是85公里/小时,标准差是4公里/小时,下列哪个车速可以看做异常值()A.78公里/小时B.82公里/小时C.91公里/小时D.98公里/小时40.下列叙述中正确的是()A.如果计算每个数据与平均数的离差,则这些离差的和总是等于零B.如果考试成绩的分布是对称的,平均数为75,标准差为12,则考试成绩在63-75分之间的比例大约为95%C.平均数和中位数相等D.中位数大于平均数41-46DADDDA41.一组样本数据为3,3,1,5,13,12,11,9,7.这组数据的中位数是()A.3B.13C.7.1D.742.在离散程度得测度中,最容易受极端值影响的是()A.极差B.四分位差C.标准差D.平均差43.测度数据离散程度的相对统计量是()A.极差B.平均差C.标准差D.离散系数44.一组数据的离散系数为0.4,平均数为20,则标准差为()A.80B.0.02C.4D.845.在比较两组数据的离散程度时,不能直接比较它们的标准差,因为两组数据的()不同A.标准差B.方差C.数据个数D.计量单位46.两组数据的平均数不等,但标准差相等,则()A.平均数小的,离散程度大B.平均数大的,离散程度大C.平均数小的,离散程度小D.两组数据的离散程度相同答案:1-5 ACBCA 6-10 ACCAB 11-15AABCA 16-20BCCDA21-25 BAABB 26-30AABAC 31-35DBBAC 36-40DBBDA41-46DADDDA。