《编译原理(实验部分)》实验2_PL0词法分析
编译原理实验报告

编译原理实验报告一、实验目的和要求本次实验旨在对PL_0语言进行功能扩充,添加新的语法特性,进一步提高编译器的功能和实用性。
具体要求如下:1.扩展PL_0语言的语法规则,添加新的语法特性;2.实现对新语法的词法分析和语法分析功能;3.对扩展语法规则进行语义分析,并生成中间代码;4.验证扩展功能的正确性。
二、实验内容1.扩展语法规则本次实验选择扩展PL_0语言的语句部分,添加新的控制语句,switch语句。
其语法规则如下:<switch_stmt> -> SWITCH <expression> CASE <case_list><default_stmt> ENDSWITCH<case_list> -> <case_stmt> , <case_stmt> <case_list><case_stmt> -> CASE <constant> : <statement><default_stmt> -> DEFAULT : <statement> ,ε2.词法分析和语法分析根据扩展的语法规则,需要对新的关键字和符号进行词法分析,识别出符号类型和记号类型。
然后进行语法分析,建立语法树。
3.语义分析在语义分析阶段,首先对switch语句的表达式进行求值,判断其类型是否为整型。
然后对case语句和default语句中的常量进行求值,判断是否与表达式的值相等。
最后将语句部分生成中间代码。
4.中间代码生成根据语法树和语义分析的结果,生成对应的中间代码。
例如,生成switch语句的跳转表,根据表达式的值选择相应的跳转目标。
5.验证功能的正确性设计一些测试用例,验证新语法的正确性和扩展功能的实用性。
三、实验步骤与结果1.扩展语法规则,更新PL_0语法分析器的词法规则和语法规则。
编译原理实验报告

编译原理实验报告一、实验目的本次编译原理实验的主要目的是通过实践加深对编译原理中词法分析、语法分析、语义分析和代码生成等关键环节的理解,并提高实际动手能力和问题解决能力。
二、实验环境本次实验使用的编程语言为 C/C++,开发工具为 Visual Studio 2019,操作系统为 Windows 10。
三、实验内容(一)词法分析器的设计与实现词法分析是编译过程的第一个阶段,其任务是从输入的源程序中识别出一个个具有独立意义的单词符号。
在本次实验中,我们使用有限自动机的理论来设计词法分析器。
首先,我们定义了单词的种类,包括关键字、标识符、常量、运算符和分隔符等。
然后,根据这些定义,构建了相应的状态转换图,并将其转换为程序代码。
在实现过程中,我们使用了字符扫描和状态转移的方法,逐步读取输入的字符,判断其所属的单词类型,并将其输出。
(二)语法分析器的设计与实现语法分析是编译过程的核心环节之一,其任务是在词法分析的基础上,根据给定的语法规则,判断输入的单词序列是否构成一个合法的句子。
在本次实验中,我们采用了自顶向下的递归下降分析法来实现语法分析器。
首先,我们根据给定的语法规则,编写了相应的递归函数。
每个函数对应一种语法结构,通过对输入单词的判断和递归调用,来确定语法的正确性。
在实现过程中,我们遇到了一些语法歧义的问题,通过仔细分析语法规则和调整函数的实现逻辑,最终解决了这些问题。
(三)语义分析与中间代码生成语义分析的任务是对语法分析所产生的语法树进行语义检查,并生成中间代码。
在本次实验中,我们使用了四元式作为中间代码的表示形式。
在语义分析过程中,我们检查了变量的定义和使用是否合法,类型是否匹配等问题。
同时,根据语法树的结构,生成相应的四元式中间代码。
(四)代码优化代码优化的目的是提高生成代码的质量和效率。
在本次实验中,我们实现了一些基本的代码优化算法,如常量折叠、公共子表达式消除等。
通过对中间代码进行分析和转换,减少了代码的冗余和计算量,提高了代码的执行效率。
编译原理实验词法分析实验报告

编译原理实验词法分析实验报告一、实验目的词法分析是编译过程的第一个阶段,其主要任务是从左到右逐个字符地对源程序进行扫描,产生一个个单词符号。
本次实验的目的在于通过实践,深入理解词法分析的原理和方法,掌握如何使用程序设计语言实现词法分析器,提高对编译原理的综合应用能力。
二、实验环境本次实验使用的编程语言为_____,开发工具为_____。
三、实验原理词法分析的基本原理是根据编程语言的词法规则,将输入的字符流转换为单词符号序列。
单词符号通常包括关键字、标识符、常量、运算符和界符等。
词法分析器的实现方法有多种,常见的有状态转换图法和正则表达式法。
在本次实验中,我们采用了状态转换图法。
状态转换图是一种有向图,其中节点表示状态,有向边表示在当前状态下输入字符的可能转移。
通过定义不同的状态和转移规则,可以实现对各种单词符号的识别。
四、实验步骤1、定义单词符号的类别和编码首先,确定实验中要识别的单词符号种类,如关键字(if、else、while 等)、标识符、整数常量、浮点数常量、运算符(+、、、/等)和界符(括号、逗号等)。
为每个单词符号类别分配一个唯一的编码,以便后续处理。
2、设计状态转换图根据单词符号的词法规则,绘制状态转换图。
例如,对于标识符的识别,起始状态为“起始状态”,当输入为字母时进入“标识符中间状态”,在“标识符中间状态”中,若输入为字母或数字则继续保持该状态,直到遇到非字母数字字符时结束识别,确定为一个标识符。
3、编写词法分析程序根据状态转换图,使用所选编程语言实现词法分析器。
在程序中,通过不断读取输入字符,根据当前状态进行转移,并在适当的时候输出识别到的单词符号。
4、测试词法分析程序准备一组包含各种单词符号的测试用例。
将测试用例输入到词法分析程序中,检查输出的单词符号是否正确。
五、实验代码以下是本次实验中实现词法分析器的核心代码部分:```include <stdioh>include <ctypeh>//单词符号类别定义typedef enum {KEYWORD,IDENTIFIER,INTEGER_CONSTANT,FLOAT_CONSTANT,OPERATOR,DELIMITER} TokenType;//关键字列表char keywords ={"if","else","while","for","int","float","void"};//状态定义typedef enum {START,IN_IDENTIFIER,IN_INTEGER,IN_FLOAT,IN_OPERATOR} State;//词法分析函数TokenType getToken(char token, int tokenLength) {State state = START;int i = 0;while (1) {char c = getchar();switch (state) {case START:if (isalpha(c)){state = IN_IDENTIFIER;tokeni++= c;} else if (isdigit(c)){state = IN_INTEGER;tokeni++= c;} else if (c =='+'|| c ==''|| c ==''|| c =='/'|| c =='('|| c ==')'|| c ==';'|| c ==','){state = IN_OPERATOR;tokeni++= c;} else if (c ==''){state = IN_FLOAT;tokeni++= c;} else if (c == EOF) {tokeni ='\0';tokenLength = i;return -1;} else {tokeni ='\0';tokenLength = i;return -2;}break;case IN_IDENTIFIER:if (isalpha(c) || isdigit(c)){tokeni++= c;} else {ungetc(c, stdin);tokeni ='\0';tokenLength = i;//检查是否为关键字for (int j = 0; j < sizeof(keywords) / sizeof(keywords0); j++){if (strcmp(token, keywordsj) == 0) {return KEYWORD;}}return IDENTIFIER;}break;case IN_INTEGER:if (isdigit(c)){tokeni++= c;} else if (c ==''){state = IN_FLOAT;tokeni++= c;} else {ungetc(c, stdin);tokeni ='\0';tokenLength = i;return INTEGER_CONSTANT;}break;case IN_FLOAT:if (isdigit(c)){tokeni++= c;} else {ungetc(c, stdin);tokeni ='\0';tokenLength = i;return FLOAT_CONSTANT;}break;case IN_OPERATOR: tokeni ='\0';tokenLength = i;return OPERATOR; break;}}}int main(){char token100;int tokenLength;TokenType tokenType;while ((tokenType = getToken(token, &tokenLength))!=-1) {switch (tokenType) {case KEYWORD:printf("Keyword: %s\n", token);break;case IDENTIFIER:printf("Identifier: %s\n", token);break;case INTEGER_CONSTANT:printf("Integer Constant: %s\n", token);break;case FLOAT_CONSTANT:printf("Float Constant: %s\n", token);break;case OPERATOR:printf("Operator: %s\n", token);break;case DELIMITER:printf("Delimiter: %s\n", token);break;}}return 0;}```六、实验结果对准备的测试用例进行输入,得到的词法分析结果如下:测试用例 1:```int main(){int num = 10;float pi = 314;if (num > 5) {printf("Hello, World!\n");}}```词法分析结果:```Keyword: int Identifier: main Delimiter: (Delimiter: ){Identifier: num Operator: =Integer Constant: 10;Identifier: float Identifier: pi Operator: =Float Constant: 314;Keyword: ifDelimiter: (Identifier: numOperator: >Integer Constant: 5){Identifier: printfDelimiter: (String: "Hello, World!\n" Delimiter: );}```测试用例 2:```for (int i = 0; i < 10; i++){double result = i 25;```词法分析结果:```Keyword: for Delimiter: (Keyword: int Identifier: i Operator: =Integer Constant: 0;Identifier: i Operator: <Integer Constant: 10;Identifier: i Operator: ++)Identifier: doubleIdentifier: resultOperator: =Identifier: iOperator:Float Constant: 25;}```通过对多个测试用例的分析,词法分析器能够正确识别出各种单词符号,实验结果符合预期。
【编译原理】词法分析(CC++源代码+实验报告)

【编译原理】词法分析(CC++源代码+实验报告)⽂章⽬录1 实验⽬的和内容1.1实验⽬的(1)根据 PL/0 语⾔的⽂法规范,编写PL/0语⾔的词法分析程序;或者调研词法分析程序的⾃动⽣成⼯具LEX或FLEX,设计并实现⼀个能够输出单词序列的词法分析器。
(2)通过设计调试词法分析程序,实现从源程序中分离出各种类型的单词;加深对课堂教学的理解;提⾼词法分析⽅法的实践能⼒。
(3)掌握从源程序⽂件中读取有效字符的⽅法和产⽣源程序的内部表⽰⽂件的⽅法。
(4)掌握词法分析的实现⽅法。
(5)上机调试编出的词法分析程序。
1.2实验内容根据PL/0语⾔的⽂法规范,编写PL/0语⾔的词法分析程序。
要求:(1)把词法分析器设计成⼀个独⽴⼀遍的过程。
(2)词法分析器的输出形式采⽤⼆元式序列,即:(单词种类, 单词的值)2 设计思想2.1单词种类及其正规式(1)基本字单词的值单词类型正规式rbegin beginsym begincall callsym callconst constsym constdo dosym doend endsym endif ifsym ifodd oddsym oddprocedure proceduresym procedureread readsym readthen thensym thenvar varsym varwhile whilesym whilewrite writesym write(2)标识符单词的值单词类型正规式r标识符ident(字母)(字母|数字)*(3)常数单词的值单词类型正规式r常数number(数字)(数字)*(4)运算符单词的值单词类型正规式r+plus+-minus-*times*/slash/=eql=<>neq<><lss<<=leq<=>gtr>>=geq>=:=becomes:=(5)界符单词的值单词类型正规式r(lparen()rparen),comma,;semicolon;.period.2.2 根据正规式构造NFA下⾯我们根据上述的正规式来构造该⽂法的NFA,如下图所⽰,其中状态0为初态,凡带双圈的状态均为终态,状态24是识别不出单词符号的出错情形,其他状态的识别情况如下图中右边的注释所⽰。
编译原理实验报告

编译原理实验报告一、实验目的编译原理是计算机科学中的重要学科,它涉及到将高级编程语言转换为计算机能够理解和执行的机器语言。
本次实验的目的是通过实际操作和编程实践,深入理解编译原理中的词法分析、语法分析、语义分析以及中间代码生成等关键环节,提高我们对编译过程的认识和编程能力。
二、实验环境本次实验使用的编程语言为C++,开发环境为Visual Studio 2019。
此外,还使用了一些相关的编译工具和调试工具,如 GDB 等。
三、实验内容(一)词法分析器的实现词法分析是编译过程的第一步,其任务是将输入的源程序分解为一个个单词符号。
在本次实验中,我们使用有限自动机的理论来设计和实现词法分析器。
首先,定义了各种单词符号的类别,如标识符、关键字、常量、运算符等。
然后,根据这些类别设计了相应的状态转换图,并将其转换为代码实现。
在实现过程中,使用了正则表达式来匹配输入字符串中的单词符号。
对于标识符和常量等需要进一步处理的单词符号,使用了相应的规则进行解析和转换。
(二)语法分析器的实现语法分析是编译过程的核心环节之一,其任务是根据给定的语法规则,分析输入的单词符号序列是否符合语法结构。
在本次实验中,我们使用了递归下降的语法分析方法。
首先,根据实验要求定义了语法规则,并将其转换为相应的递归函数。
在递归函数中,通过对输入单词符号的判断和处理,逐步分析语法结构。
为了处理语法错误,在分析过程中添加了错误检测和处理机制。
当遇到不符合语法规则的输入时,能够输出相应的错误信息,并尝试进行恢复。
(三)语义分析及中间代码生成语义分析的目的是对语法分析得到的语法树进行语义检查和语义处理,生成中间代码。
在本次实验中,我们使用了三地址码作为中间代码的表示形式。
在语义分析过程中,对变量的定义和使用、表达式的计算、控制流语句等进行了语义检查和处理。
对于符合语义规则的语法结构,生成相应的三地址码指令。
四、实验步骤(一)词法分析器的实现步骤1、定义单词符号的类别和对应的正则表达式。
编译原理实验--词法分析器
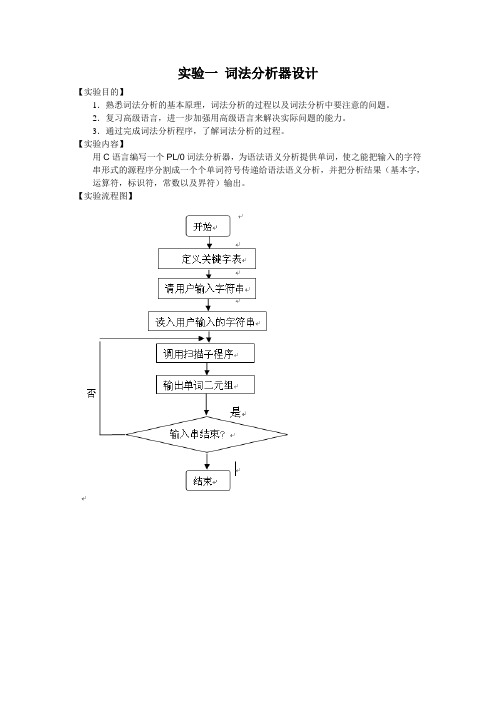
实验一词法分析器设计【实验目的】1.熟悉词法分析的基本原理,词法分析的过程以及词法分析中要注意的问题。
2.复习高级语言,进一步加强用高级语言来解决实际问题的能力。
3.通过完成词法分析程序,了解词法分析的过程。
【实验内容】用C语言编写一个PL/0词法分析器,为语法语义分析提供单词,使之能把输入的字符串形式的源程序分割成一个个单词符号传递给语法语义分析,并把分析结果(基本字,运算符,标识符,常数以及界符)输出。
【实验流程图】【实验步骤】1.提取pl/0文件中基本字的源代码while((ch=fgetc(stream))!='.'){int k=-1;char a[SIZE];int s=0;while(ch>='a' && ch<='z'||ch>='A' && ch<='Z'){if(ch>='A' && ch<='Z') ch+=32;a[++k]=(char)ch;ch=fgetc(stream);}for(int m=0;m<=12&&k!=-1;m++)for(int n=0;n<=k;n++){if(a[n]==wsym[m][n]) ++s;else s=0;if(s==(strlen(wsym[m]))) {printf("%s\t",wsym[m]);m=14;n=k+1;} }2.提取pl/0文件中标识符的源代码while((ch=fgetc(stream))!='.'){int k=-1;char a[SIZE]=" ";int s=0;while(ch>='a' && ch<='z'||ch>='A' && ch<='Z'){if(ch>='A' && ch<='Z') ch+=32;a[++k]=(char)ch;ch=fgetc(stream);}for(int m=0;m<=12&&k!=-1;m++)for(int n=0;n<=k;n++){if(a[n]==wsym[m][n]) ++s;else s=0;if(s==(strlen(wsym[m]))) {m=14;n=k+1;}}if(m==13) for(m=0;a[m]!=NULL;m++) printf("%c ",a[m]);3.提取pl/0文件中常数的源代码while((ch=fgetc(stream))!='.'){while(ch>='0' && ch<='9'){num=10*num+ch-'0';ch=fgetc(stream);}if(num!=0) printf("%d ",num);num=0;}4.提取pl/0文件中运算符的源代码int ch=fgetc(stream);while(ch!='.'){switch(ch){case'+': printf("+ ");break;case'-': printf("- ");break;case'*': printf("* ");break;case'/': printf("/ ");break;case'>': if(fgetc(stream)=='=')printf(">= "); else printf("> ");break;case'<': if(fgetc(stream)=='=')printf("<= "); else printf("< ");break;case':': printf(":= ");break;case'#': printf("# ");break;case'=': printf("= ");break;default: break;}ch=fgetc(stream);5.提取pl/0文件中界符的源代码int ch=fgetc(stream);while(ch!='.'){switch(ch){case',': printf(", ");break;case';': printf("; ");break;case'(': printf("( ");break;case')': printf(") ");break;default: break;}ch=fgetc(stream);}【实验结果】1.pl/0文件(222.txt)内容const a=10;var b,c;procedure p;beginc:=b+a;end;beginread(b);while b#0 dobegincall p;write(2*c);read(b)endend .2.实验运行结果【实验小结】1.了解程序在运行过程中对词法分析,识别一个个字符并组合成相应的单词,是机器能过明白程序,定义各种关键字,界符。
编译原理实验整体(2)词法分析器实验报告
int index = stIndexOf("//");
String tmpstr=line.substring(index);
int tmpint = tmpstr.length();
for(int k=0;k<tmpint;k++)
{
i++;
}
token = tmpstr;
{"if",6,"IF"}, {"int",7,"INT"}, {"return",8,"RETURN"},
{"void",9,"VOID"}, {"while",10,"WHILE"},
{"printf",41,"OUTPUT"}, {"scanf",42,"INPUT"},
{"main",43,"MAIN"}, {"function",44,"function"}
if (ch == '\0') {
haveMistake = true;
break;
}
for (int k = 0; k < 4; k++) {
char tmpstr[] = stConDFA[s].toCharArray();
if (in_stConDFA(ch, tmpstr[k])) {
token1 += ch;
理论基础:有限自动机、正规文法
词法分析器:执行词法分析的程序
编译原理词法分析实验
编译原理词法分析实验一、实验目的本实验旨在通过编写一个简单的词法分析器,了解编译原理中词法分析的基本原理和实现方法。
二、实验材料1. 计算机编程环境2. 编程语言三、实验步骤1. 了解词法分析的概念和作用。
词法分析是编译器中的第一个阶段,它的主要任务是将源代码中的字符序列转化为有意义的标识符,如关键字、操作符、常量和标识符等。
2. 设计词法分析器的流程和算法。
词法分析器的主要原理是通过有限状态自动机来识别和提取标识符。
在设计过程中,需考虑各种可能出现的字符序列,并定义相应的状态转移规则。
3. 根据设计的流程和算法,使用编程语言编写词法分析器的代码。
4. 编译并运行词法分析器程序,输入待分析的源代码文件,观察程序的输出结果。
5. 分析输出结果,检查程序是否正确地提取了源代码中的标识符。
四、实验结果经过词法分析器的处理,源代码将被成功地转化为有意义的标识符。
结果可以通过以下几个方面来验证:1. 关键字和操作符是否被正确识别和提取。
2. 常量和标识符是否被正确识别和提取。
3. 检查程序的错误处理能力,如能否发现非法字符或非法标识符。
4. 输出结果是否符合预期,可与自己编写的语法规则进行对比。
5. 对于特殊情况,如转义字符等是否正确处理。
五、实验总结通过本次实验,我深入了解了编译原理中词法分析的重要性和基本原理。
编写词法分析器的过程中,我学会了使用有限状态自动机来识别和提取标识符,并通过实践巩固了相关知识。
此外,我还对源代码的结构有了更深入的了解,并且掌握了如何运用编程语言来实现词法分析器。
通过本次实验,我不仅提升了自己的编程技术,也对编译原理有了更深入的认识和理解。
六、实验心得通过实验,我深刻体会到了词法分析在编译过程中的重要性。
合理设计和实现词法分析器,可以大大提高编译器的效率和准确性。
同时,通过编写词法分析器的代码,我不仅锻炼了自己的编程能力,还提升了对编译原理的理解和掌握。
这次实验让我更加深入地了解了编译原理中的词法分析,也为我今后在编程领域的发展打下了坚实的基础。
编译原理实验词法分析实验报告
编译技术实验报告实验题目:词法分析学院:信息学院专业:计算机科学与技术学号:姓名:一、实验目的(1)理解词法分析的功能;(2)理解词法分析的实现方法;二、实验内容PL0的文法如下‘< >’为非终结符。
‘::=’ 该符号的左部由右部定义,可读作“定义为”。
‘|’ 表示‘或’,为左部可由多个右部定义。
‘{ }’ 表示花括号内的语法成分可以重复。
在不加上下界时可重复0到任意次数,有上下界时可重复次数的限制。
‘[ ]’ 表示方括号内的成分为任选项。
‘( )’ 表示圆括号内的成分优先。
上述符号为“元符号”,文法用上述符号作为文法符号时需要用引号‘’括起。
〈程序〉∷=〈分程序〉.〈分程序〉∷= [〈变量说明部分〉][〈过程说明部分〉]〈语句〉〈变量说明部分〉∷=V AR〈标识符〉{,〈标识符〉}:INTEGER;〈无符号整数〉∷=〈数字〉{〈数字〉}〈标识符〉∷=〈字母〉{〈字母〉|〈数字〉}〈过程说明部分〉∷=〈过程首部〉〈分程序〉{;〈过程说明部分〉};〈过程首部〉∷=PROCEDURE〈标识符〉;〈语句〉∷=〈赋值语句〉|〈条件语句〉|〈过程调用语句〉|〈读语句〉|〈写语句〉|〈复合语句〉|〈空〉〈赋值语句〉∷=〈标识符〉∶=〈表达式〉〈复合语句〉∷=BEGIN〈语句〉{;〈语句〉}END〈条件〉∷=〈表达式〉〈关系运算符〉〈表达式〉〈表达式〉∷=〈项〉{〈加法运算符〉〈项〉}〈项〉∷=〈因子〉{〈乘法运算符〉〈因子〉}〈因子〉∷=〈标识符〉|〈无符号整数〉|'('〈表达式〉')'〈加法运算符〉∷=+|-〈乘法运算符〉∷=*〈关系运算符〉∷=<>|=|<|<=|>|>=〈条件语句〉∷=IF〈条件〉THEN〈语句〉〈字母〉∷=a|b|…|X|Y|Z〈数字〉∷=0|1|2|…|8|9实现PL0的词法分析三、实验分析与设计PL0词法分析程序是一个独立的过程,其功能是为语法语义分析提供单词,把输入的字符串形式的源程序分割成一个个单词符号传递给语法语义分析。
编译原理实验报告-pl0
《编译原理》实验报告———编写编译程序实现多行表达式的<表达式序列>的文法语言的编译执行组长:组员:一、实验项目名称:有表示多行表达式的<表达式序列>文法如下:<表达式序列>-> <表达式> ↙<表达式序列> |<表达式>↙↙<表达式> -> [<变量>=] [+|-]<项>{(+|-)<项>}<项> -> <因子>{(* | /)<因子>}<因子> -> <无符号实数>|<变量>|<标准函数>…(‟<表达式>…)‟|…(‟ <表达式>…)‟<标准函数> -> sin | cos | tan | exp其中的变量无需定义且其作用域为第一次赋值处至最后。
试按递归下降方式设计其编译程序,生成PL/0栈式指令代码,然后解释执行。
二、实验要求:·将编译和解释执行分成完全独立的两个阶段;·对栈式指令进行适当扩充,使之能处理标准函数的调用;·剔除本题目不需要的PL/0栈式指令,并说明理由;·简化PL/0运行栈,使之满足本题目要求既可;·注意<表达式>定义中的可选项[变量=]引起的歧义性:如a=1+2与a+2,前一个a属于<表达式>,而后一个a属于<项>,思考如何解决;·以“表达式↙目标码序列↙结果↙”方式输出运行结果;·设计一个测试,使之能充分测试你的实现;·对正确列出的目标码、执行并按适当方式演示运行栈的变化,计算出值;对错误的指出其出错位置和错误性质三、设计概述:·实现平台:VC++6.0·运行平台:xindows xp四、结构设计说明:结构图:五、具体实现过程:1、词法分析(斯琴)词法分析子程序名为getsym,功能是从源程序中读出一个单词符号,把它的信息放入全局变量sym,值放入id中,语法分析需要单词时,直接从变量中获得。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《编译原理》(实验部分)实验2_PL0 词法分析一、实验目的加深和巩固对于词法分析的了解和掌握;初步认识PL/0 语言的基础和简单的程序编写;通过本实验能够初步的了解和掌握程序词法分析的整个过程;提高自己上机和编程过程中处理具体问题的能力。
二、实验设备1、P C兼容机一台;操作系统为WindowsWindowsX P2、Visual C++ 6.0 或以上版本,Windows 2000 或以上版本,汇编工具 (在Software 子目录下)。
三、实验原理PL/O语言的编译程序,是用高级语言PASCAL语言书写的。
整个编译过程是由一些嵌套及并列的过程或函数完成。
词法分析程序是独立的过程GETSY完成,供语法分析读单词时使用。
四、实验步骤阅读所给出的词法分析程序( pl0_lexical.c ),搞懂程序中每一个变量的含义,以及每一个过程的作用,并在该过程中进行中文注释;阅读完程序后,画出各过程的流程图;给出的程序包含两处输入错误,利用所给的pl/0 源程序(test.pl0) 对程序进行调试,使其能正确对所给文件进行分析并能够解释运行;在阅读懂所给出的词法分析程序后,将你对词法分析的理解写在实验报告上。
实验代码#include<stdio.h>main(){ printf ("my name is 08061118 yuchaofeng ");}主程序:#include <stdio.h>#include <ctype.h>#include <alloc.h>#include <stdlib.h>#include <string.h>#define NULL 0FILE *fp;char cbuffer;char *key[8]={"DO","BEGIN","ELSE","END","IF","THEN","VAR","WHILE"}; char *border[6]={",",";",":=",".","(",")"};char *arithmetic[4]={"+","-","*","/"};char *relation[6]={"<","<=","=",">",">=","<>"};char *consts[20];char *label[20];int constnum=0,labelnum=0;int search(char searchchar[],int wordtype){int i=0;switch (wordtype) {case 1:for (i=0;i<=7;i++){if (strcmp(key[i],searchchar)==0)return(i+1);};case 2:{for (i=0;i<=5;i++){if (strcmp(border[i],searchchar)==0)return(i+1);};return(0);}case 3:{for (i=0;i<=3;i++){ if (strcmp(arithmetic[i],searchchar)==0){};};return(0);};case 4:{for (i=0;i<=5;i++){ if (strcmp(relation[i],searchchar)==0){return(i+1);};};return(0);};case 5:{for (i=0;i<=constnum;i++){ if (strcmp(consts[i],searchchar)==0){return(i+1);};}consts[i-1]=(char *)malloc(sizeof(searchchar));strcpy(consts[i-1],searchchar);constnum++;return(i);};case 6:{for (i=0;i<=labelnum;i++){ if (strcmp(label[i],searchchar)==0){ return(i+1);};}label[i-1]=(char *)malloc(sizeof(searchchar)); strcpy(label[i-1],searchchar);return(i);};}}char alphaprocess(char buffer){int atype;int i=-1;char alphatp[20];while ((isalpha(buffer))||(isdigit(buffer))){ alphatp[++i]=buffer; buffer=fgetc(fp);}; alphatp[i+1]='\0';if (atype=search(alphatp,1)) printf("%s (1,%d)\n",alphatp,atype-1); else { atype=search(alphatp,6);printf("%s (6,%d)\n",alphatp,atype-1); };return(buffer);char digitprocess(char buffer){int i=-1;char digittp[20];int dtype;while ((isdigit(buffer))){ digittp[++i]=buffer;buffer=fgetc(fp);}digittp[i+1]='\0';dtype=search(digittp,5);printf("%s (5,%d)\n",digittp,dtype-1); return(buffer);}char otherprocess(char buffer){int i=-1;char othertp[20];int otype,otypetp;othertp[0]=buffer;othertp[1]='\0';if (otype=search(othertp,3)){printf("%s (3,%d)\n",othertp,otype-1);buffer=fgetc(fp);goto out;};if (otype=search(othertp,4)){buffer=fgetc(fp);othertp[1]=buffer;othertp[2]='\0';if (otypetp=search(othertp,4)){printf("%s (4,%d)\n",othertp,otypetp-1); goto out;}elseothertp[1]='\0';printf("%s (4,%d)\n",othertp,otype-1);goto out;};if (buffer==':'){ buffer=fgetc(fp);if (buffer=='=')printf(":= (2,2)\n");buffer=fgetc(fp);goto out;}else{if (otype=search(othertp,2)){ printf("%s (2,%d)\n",othertp,otype-1); buffer=fgetc(fp); goto out;}};if ((buffer!='\n')&&(buffer!=' '))printf("%c error,not a word\n",buffer); buffer=fgetc(fp);out: return(buffer);} void main(){ int i;for (i=0;i<=20;i++){label[i]=NULL; consts[i]=NULL;};if ((fp=fopen("skh.c","r"))==NULL) printf("error");else{ cbuffer = fgetc(fp);while (cbuffer!=EOF){if (isalpha(cbuffer)) cbuffer=alphaprocess(cbuffer);else if (isdigit(cbuffer))cbuffer=digitprocess(cbuffer); else cbuffer=otherprocess(cbuffer); };printf("over\n");};}。