Hadoop云计算平台搭建最详细过程(共22页)
基于Hadoop的大数据处理平台搭建与部署

基于Hadoop的大数据处理平台搭建与部署一、引言随着互联网和信息技术的快速发展,大数据已经成为当今社会中不可或缺的重要资源。
大数据处理平台的搭建与部署对于企业和组织来说至关重要,而Hadoop作为目前最流行的大数据处理框架之一,其搭建与部署显得尤为重要。
本文将介绍基于Hadoop的大数据处理平台搭建与部署的相关内容。
二、Hadoop简介Hadoop是一个开源的分布式存储和计算框架,能够高效地处理大规模数据。
它由Apache基金会开发,提供了一个可靠、可扩展的分布式系统基础架构,使用户能够在集群中使用简单的编程模型进行计算。
三、大数据处理平台搭建准备工作在搭建基于Hadoop的大数据处理平台之前,需要进行一些准备工作: 1. 硬件准备:选择合适的服务器硬件,包括计算节点、存储节点等。
2. 操作系统选择:通常选择Linux系统作为Hadoop集群的操作系统。
3. Java环境配置:Hadoop是基于Java开发的,需要安装和配置Java环境。
4. 网络配置:确保集群内各节点之间可以相互通信。
四、Hadoop集群搭建步骤1. 下载Hadoop从Apache官网下载最新版本的Hadoop压缩包,并解压到指定目录。
2. 配置Hadoop环境变量设置Hadoop的环境变量,包括JAVA_HOME、HADOOP_HOME等。
3. 配置Hadoop集群编辑Hadoop配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml等,配置各个节点的角色和参数。
4. 启动Hadoop集群通过启动脚本启动Hadoop集群,可以使用start-all.sh脚本启动所有节点。
五、大数据处理平台部署1. 数据采集与清洗在搭建好Hadoop集群后,首先需要进行数据采集与清洗工作。
通过Flume等工具实现数据从不同来源的采集,并进行清洗和预处理。
2. 数据存储与管理Hadoop提供了分布式文件系统HDFS用于存储海量数据,同时可以使用HBase等数据库管理工具对数据进行管理。
Hadoop的安装与配置及示例wordcount的运行

Hadoop的安装与配置及示例程序wordcount的运行目录前言 (1)1 机器配置说明 (2)2 查看机器间是否能相互通信(使用ping命令) (2)3 ssh设置及关闭防火墙 (2)1)fedora装好后默认启动sshd服务,如果不确定的话可以查一下[garon@hzau01 ~]$ service sshd status (3)2)关闭防火墙(NameNode和DataNode都必须关闭) (3)4 安装jdk1.6(集群中机子都一样) (3)5 安装hadoop(集群中机子都一样) (4)6 配置hadoop (4)1)配置JA V A环境 (4)2)配置conf/core-site.xml、conf/hdfs-site.xml、conf/mapred-site.xml文件 (5)3)将NameNode上完整的hadoop拷贝到DataNode上,可先将其进行压缩后直接scp 过去或是用盘拷贝过去 (7)4)配置NameNode上的conf/masters和conf/slaves (7)7 运行hadoop (7)1)格式化文件系统 (7)2)启动hadoop (7)3)用jps命令查看进程,NameNode上的结果如下: (8)4)查看集群状态 (8)8 运行Wordcount.java程序 (8)1)先在本地磁盘上建立两个文件f1和f2 (8)2)在hdfs上建立一个input目录 (9)3)将f1和f2拷贝到hdfs的input目录下 (9)4)查看hdfs上有没有f1,f2 (9)5)执行wordcount(确保hdfs上没有output目录) (9)6)运行完成,查看结果 (9)前言最近在学习Hadoop,文章只是记录我的学习过程,难免有不足甚至是错误之处,请大家谅解并指正!Hadoop版本是最新发布的Hadoop-0.21.0版本,其中一些Hadoop命令已发生变化,为方便以后学习,这里均采用最新命令。
搭建hadoop集群的步骤

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。
hadoop环境搭建
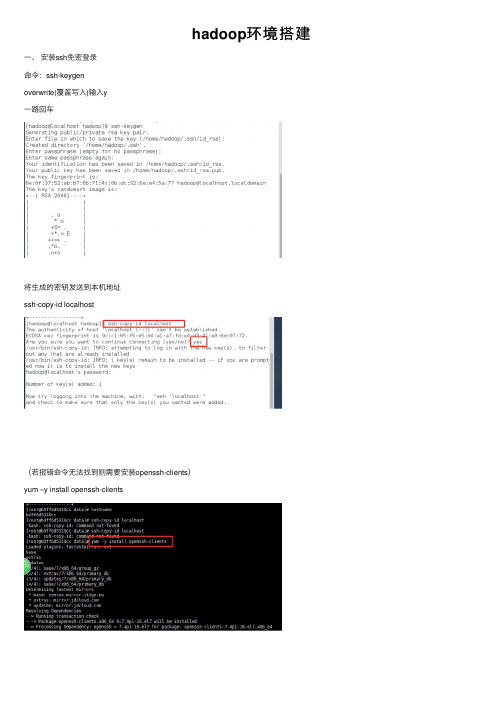
hadoop环境搭建⼀、安装ssh免密登录命令:ssh-keygenoverwrite(覆盖写⼊)输⼊y⼀路回车将⽣成的密钥发送到本机地址ssh-copy-id localhost(若报错命令⽆法找到则需要安装openssh-clients)yum –y install openssh-clients测试免密设置是否成功ssh localhost⼆、卸载已有java确定JDK版本rpm –qa | grep jdkrpm –qa | grep gcj切换到root⽤户,根据结果卸载javayum -y remove java-1.8.0-openjdk-headless.x86_64 yum -y remove java-1.7.0-openjdk-headless.x86_64卸载后输⼊java –version查看三、安装java切换回hadoop⽤户,命令:su hadoop查看下当前⽬标⽂件,命令:ls将桌⾯的hadoop⽂件夹中的java及hadoop安装包移动到app⽂件夹中命令:mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz创建软连接ln –s jdk1.8.0_141 jdk配置jdk环境变量切换到root⽤户再输⼊vi /etc/profile输⼊export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib export PATH=$PATH:$JAVA_HOME/bin保存退出,并使/etc/profile⽂件⽣效source /etc/profile能查询jdk版本号,说明jdk安装成功java -version四、安装hadoop切换回hadoop⽤户,解压缩hadoop-2.6.0.tar.gz安装包创建软连接,命令:ln -s hadoop-2.7.0 hadoop验证单机模式的Hadoop是否安装成功,命令:hadoop/bin/hadoop version此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
Hadoop 搭建

(与程序设计有关)
课程名称:云计算技术提高
实验题目:Hadoop搭建
Xx xx:0000000000
x x:xx
x x:
xxxx
2021年5月21日
实验目的及要求:
开源分布式计算架构Hadoop的搭建
软硬件环境:
Vmware一台计算机
算法或原理分析(实验内容):
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用Java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
三.Hadoop的安装
1.安装并配置环境变量
进入官网进行下载hadoop-2.7.5, 将压缩包在/usr目录下解压利用tar -zxvf Hadoop-2.7.5.tar.gz命令。同样进入 vi /etc/profile 文件,设置相应的HADOOP_HOME、PATH在hadoop相应的绝对路径。
4.建立ssh无密码访问
二.JDK安装
1.下载JDK
利用yum list java-1.8*查看镜像列表;并利用yum install java-1.8.0-openjdk* -y安装
2.配置环境变量
利用vi /etc/profile文件配置环境,设置相应的JAVA_HOME、JRE_HOME、PATH、CLASSPATH的绝对路径。退出后,使用source /etc/profile使环境变量生效。利用java -version可以测试安装是否成功。
3.关闭防火墙并设置时间同步
通过命令firewall-cmd–state查看防火墙运行状态;利用systemctl stop firewalld.service关闭防火墙;最后使用systemctl disable firewalld.service禁止自启。利用yum install ntp下载相关组件,利用date命令测试
Hadoop完全分布式详细安装过程

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
Hadoop集群搭建步骤

Hadoop集群搭建步骤1.先建⽴⼀台虚拟机,分配内存2G,硬盘20G,⽹络为nat 模式,设置⼀个静态的ip 地址: 例如设定3台机器的ip 为192.168.63.167(master) 192.16863.168(slave1) 192.168.63.169 (slave2)2.修改第⼀台主机的⽤户名3.复制master⽂件两次,重命名为slave1和slave2,打开虚拟机⽂件,然后按照同样的⽅法设置两个节点的ip和主机名4.建⽴主机名和ip的映射5.查看是否能ping通,关闭防⽕墙和selinux 配置6.配置ssh免密码登录在root⽤户下输⼊ssh-keygen -t rsa ⼀路回车秘钥⽣成后在~/.ssh/⽬录下,有两个⽂件id_rsa(私钥)和id_rsa.pub(公钥),将公钥复制到authorized_keys并赋予authorized_keys600权限同理在slave1和slave2节点上进⾏相同的操作,然后将公钥复制到master节点上的authoized_keys检查是否免密登录(第⼀次登录会有提⽰)7..安装JDK(省去)三个节点安装java并配置java环境变量8.安装MySQL(master 节点省去)9.安装SecureCRT或者xshell 客户端⼯具,然后分别链接上 3台服务器12.搭建集群12.1 集群结构三个结点:⼀个主节点master两个从节点内存2GB 磁盘20GB12.2 新建hadoop⽤户及其⽤户组⽤adduser新建⽤户并设置密码将新建的hadoop⽤户添加到hadoop⽤户组前⾯hadoop指的是⽤户组名,后⼀个指的是⽤户名赋予hadoop⽤户root权限12.3 安装hadoop并配置环境变量由于hadoop集群需要在每⼀个节点上进⾏相同的配置,因此先在master节点上配置,然后再复制到其他节点上即可。
将hadoop包放在/usr/⽬录下并解压配置环境变量在/etc/profile⽂件中添加如下命令12.4 搭建集群的准备⼯作在master节点上创建以下⽂件夹/usr/hadoop-2.6.5/dfs/name/usr/hadoop-2.6.5/dfs/data/usr/hadoop-2.6.5/temp12.5 配置hadoop⽂件接下来配置/usr/hadoop-2.6.5/etc//hadoop/⽬录下的七个⽂件slaves core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml hadoop-env.sh yarn-env.sh配置hadoop-env.sh配置yarn-env.sh配置slaves⽂件,删除localhost配置core-site.xml配置hdfs-site.xml配置mapred-site.xml配置yarn-site.xml将配置好的hadoop⽂件复制到其他节点上12.6 运⾏hadoop格式化Namenodesource /etc/profile13. 启动集群。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop云计算平台及相关组件搭建安装过程详细教程——Hbase+Pig+Hive+Zookeeper+Ganglia+Chukwa+Eclipse等一.安装环境简介根据官网,Hadoop已在linux主机组成的集群系统上得到验证,而windows平台是作为开发平台支持的,由于分布式操作尚未在windows平台上充分测试,所以还不作为一个生产平台。
Windows下还需要安装Cygwin,Cygwin是在windows平台上运行的UNIX模拟环境,提供上述软件之外的shell支持。
实际条件下在windows系统下进行Hadoop伪分布式安装时,出现了许多未知问题。
在linux系统下安装,以伪分布式进行测试,然后再进行完全分布式的实验环境部署。
Hadoop完全分布模式的网络拓补图如图六所示:(1)网络拓补图如六所示:图六完全分布式网络拓补图(2)硬件要求:搭建完全分布式环境需要若干计算机集群,Master和Slaves 处理器、内存、硬盘等参数要求根据情况而定。
(3)软件要求操作系统64位版本:并且所有机器均需配置SSH免密码登录。
二. Hadoop集群安装部署目前,这里只搭建了一个由三台机器组成的小集群,在一个hadoop集群中有以下角色:Master和Slave、JobTracker和TaskTracker、NameNode和DataNode。
下面为这三台机器分配IP地址以及相应的角色:——master,namenode,jobtracker——master(主机名)——slave,datanode,tasktracker——slave1(主机名)——slave,datanode,tasktracker——slave2(主机名)实验环境搭建平台如图七所示:图七 hadoop集群实验平台并且,Hadoop要求集群上每台的用户账户名和密码相同。
具体安装步骤如下:(1)下载和安装JDK,版本为的安装目录为/usr/lib/jvm,创建此文件夹,在终端输入命令:mkdir /usr/lib/jvm(2)权限不够的话重新改下用户密码就可以了,命令: sudo passwd,之后重新输入密码。
(3)移动jdk到/usr/lib/jvm,并解压,然后为了节省空间删除安装包。
命令: mv /usr/lib/jvm1.tar –zxvf –rf 配置环境变量在终端输入命令:sudo gedit /etc/profile打开profile文件,在文件最下面输入如下内容,如图八所示:图八 JAVA环境变量设置即为:# set java environmentexport JAVA_HOME=/usr/lib/jvm/CLASSPATH=”.:$JAVA_HOME/lib:$CLASSPATH”export PATH=”$JAVA_HOME/:$PATH”这一步的意义是配置环境变量,使系统可以找到jdk。
2.验证JDK是否安装成功(1)输入命令:java –version,如图九所示。
如果出现java版本信息,说明当前安装的jdk并未设置成ubuntu系统默认的jdk,接下来还需要手动将安装的jdk设置成系统默认的jdk。
图九 java版本信息(2)手动设置需输入以下命令:sudo update-alternatives –install /usr/bin/java java /usr/lib/jvm/ 300sudo update-alternatives –install /usr/bin/javac javac /usr/lib/jvm/ 300sudo update-alternatives –config java然后输入java –version就可以看到所安装的jdk的版本信息。
3.三台主机上分别设置/etc/hosts和/etc/hostnameHosts这个文件用于定义主机名和IP地址之间的对应关系,而hostname这个文件用于定义你的Ubuntu的主机名。
(1)修改/etc/hosts,命令sudo gedit /etc/hostslocalhostmasterslave1slave2(2)修改/etc/hostname,命令 sudo gedit /etc/hostname(修改完重启有效) master以及slave1 ,slave24.在这两台主机上安装OpenSSH,并配置SSH可以免密码登录(1)确认已经连接上网,输入命令:sudo apt-get install ssh(2)配置为可以免密码登录本机,接下来输入命令:ssh-keygen –t dsa –P ‘’ –f ~/.ssh/id_dsa解释一下,ssh-keygen 代表生成密匙,-t表示指定生成的密匙类型,dsa是密匙认证的意思,即密匙类型,-P用于提供密语,-f指定生成的密匙文件。
这个命令会在.ssh文件夹下创建id_dsa以及两个文件,这是ssh一对私匙和公匙,把追加到授权的key中。
输入命令:cat ~/.ssh/ >> ~/.ssh/authorized_keys(3)验证ssh是否已经安装成功,输入命令:ssh –version。
将文件复制到slave主机相同的文件夹内,输入命令:scp authorized_keys slave1:~/.ssh/scp authorized_keys slave2:~/.ssh/(4)看是否可以从master主机免密码登录slave,输入命令:ssh slave1ssh slave25.配置两台主机的Hadoop文件首先到Hadoop的官网下载包,默认讲Hadoop解压到 /home/u(你的Ubuntu用户名)/ 目录下(1)进入hadoop内的conf文件夹,找到,修改:export JAVA_HOME=/usr/lib/jvm/,指定JDK的安装位置,如图十所示:图十 JAVA_HOME 路径设置(2)修改,这是Hadoop的核心配置文件,这里配置的是HDFS的地址及端号:<configuration><property><name> <value> <name> <value>/tmp</value></configuration>(3)修改<configuration><property><name></name><value>2</value></property></configuration>(4)修改<configuration><property><name> <value>master:9001</value></property></configuration>(5)修改conf/mastersmaster(6)修改conf/slavesslave1slave26.启动hadoop在启动之前,需要格式化hadoop的文件系统HDFS,进入hadoop文件夹,输入命令格式化:bin/hadoop namenode –format,如图十一所示:图十一 hadoop格式化输入命令,启动所有进程:bin/,如图十二所示:图十二 hadoop启动信息查看是否所有进程启动,输入命令:jps,如图十三所示:图十三 jps查看进程7.最后验证hadoop是否成功启动打开浏览器,查看机器集群状态分别输入网址:(1)输入,如图十四,可看到:图十四 namenode状态点击live nodes,可以看到当前slave1和slave2两个节点信息,如图十五:图十五 datanode节点状态(2)输入,如图十六,可看到:图十六 jobtracker状态点击2 nodes查看tasktracker信息,如图十七:图十七 tasktracker状态(3)输入,如图十八,可看到:图十八 task状态也可以通过命令:hadoop dfsadmin –report查看8.停止hadoop进程:bin/如图十九:图十九停止hadoop集群9.以上为hadoop完全分布式集群配置以上过程为由三台计算机组成的完全分布式Hadoop集群,主要参考《Hadoop实战-第二版》和《Hadoop权威指南》,主要讲解了Hadoop的安装和配置过程,关于更多Hadoop原理的知识不在详述,如果在家在安装的时候遇到问题,或者按以上步骤安装完成却不能运行Hadoop,建议查看Hadoop的日志信息,Hadoop记录了详尽的日志信息,日志文件保存的Hadoop/logs文件夹内。
三.其他组件安装过程简介本Hadoop平台搭建过程中安装的组件及软件环境主要包括以下内容:相关技术作以下介绍:1.Pig和HiveHive是一个基于Hadoop文件系统之上的数据仓库架构,利用Mapreduce编程技术,实现了部分SQL语句,提供了类SQL的编程接口,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能可以将SQL语句转换为Mapreduce任务进行运行,但是这样在执行时会出现延迟现象,但能更好的处理不变的大规模数据集上的批量任务。
此外,Hive的网络接口可以方便直观地对数据进行操作,在命令行下,要执行多个查询就要打开多个终端,而通过网络结构可以同时执行多个查询。
配置Eclipse环境编写Hive 程序Hive的优化策略,针对不同的查询进行优化,优化过程通过配置进行控制图二十 Hive Web 接口界面Pig提供了一个支持大规模数据分析的平台,Pig的基础结构层包括一个产生Mapreduce程序的编译器,能够承受大量的并行任务。
Pig Latin语言更侧重于对数据的查询和分析,而不是对数据进行修改和删除,建立在Hadoop分布式平台之上,能够在短时间内处理海量的数据,比如:系统日志文件,处理大型数据库文件,处理特定web数据等。
2.GangliaGanglia是UC Berkeley发起的一个开源集群监视项目,用于测量数以千计的节点集群。
核心包含两个Daemon:客户端Ganglia Monitoring(gmond)和服务端Ganglia Meta(gmetad),以及一个web前端,主要监控的系统性能有:CPU、memory、硬盘利用率、I/O负载、网络流量情况等,可以帮助合理调整分配系统资源,优化系统性。
图二十一 Ganglia 监控总界面图二十二 Ganglia-cpu监控界面图二十三 Ganglia-cluster cpu 监控界面图二十四 Ganglia-memory监控界面图二十五 Ganglia-network监控界面3.HBase简单地说,hbase是一个分布式的、面向列的开源数据库,不同于一般的关系数据库,是一个适合于非结构化数据存储的数据库。