第三章最小均方(LMS)算法
Lecture.LMS算法介绍

LMS算法介绍最小均方算法(Least Mean Square, LMS)是一种简单、应用为广泛的自适应滤波算法,是在维纳滤波理论上运用速下降法后的优化延伸,早是由Widrow 和Hoff 提出来的。
该算法不需要已知输入信号和期望信号的统计特征,“当前时刻”的权系数是通过“上一时刻”权系数再加上一个负均方误差梯度的比例项求得。
这种算法也被称为Widrow-Hoff LMS 算法,在自适应滤波器中得到广泛应用,其具有原理简单、参数少、收敛速度较快而且易于实现等优点。
1 最小均方误差以及均方误差曲面自适应滤波算法从某种角度也被称为性能表面搜索法,在性能曲面中,它是通过不断测量一个点是否接近目标值,来寻找优解的。
目前,使用为广泛的曲面函数之一是均方误差(MSE)函数,函数表达式如下:。
准则函数设计为求均方误差函数的小值,我们称之为小均方误差准则(MMSE),维纳滤波器就是基于这个准则推到出来的。
公式:,从上式可以看出均方误差与滤波器权向量是成二次函数关系,引入均方误差曲面来描述函数的映射关系,对应的权向量w的二次函数就是一个超抛物曲面。
2 LMS算法基本原理根据小均方误差准则以及均方误差曲面,自然的我们会想到沿每一时刻均方误差的陡下降在权向量面上的投影方向更新,也就是通过目标函数的反梯度向量来反复迭代更新。
由于均方误差性能曲面只有一个唯一的极小值,只要收敛步长选择恰当,不管初始权向量在哪,后都可以收敛到误差曲面的小点,或者是在它的一个邻域内。
这种沿目标函数梯度反方向来解决小化问题的方法,我们一般称为速下降法,表达式如下:,基于随机梯度算法的小均方自适应滤波算法的完整表达式如下:LMS 自适应算法是一种特殊的梯度估计,不必重复使用数据,也不必对相关矩阵和互相关矩阵进行运算,只需要在每次迭代时利用输入向量和期望响应,结构简单,易于实现。
虽然LMS 收敛速度较慢,但在解决许多实际中的信号处理问题,LMS 算法是仍然是好的选择。
最小均方误差算法

最小均方误差算法
最小均方误差算法(Least Mean Squares Algorithm,LMS算法)是一种常用的自适应滤波算法,主要用于信号处理、通信系统、控制系统等领域。
该算法的核心思想是通过不断调整滤波器系数,使得滤波器输出信号与期望信号之间的均方误差最小化。
LMS算法的基本原理是利用梯度下降法不断调整滤波器系数。
具体来说,假设滤波器的系数为w(n),期望输出信号为d(n),实际输出信号为y(n),则LMS 算法的更新公式为:
w(n+1) = w(n) + μe(n)x(n)
其中,μ为步长因子,e(n)为误差信号,即e(n) = d(n) - y(n),x(n)为输入信号。
LMS算法的优点是简单易实现,计算量较小,适用于实时处理。
但是,由于其采用的是梯度下降法,容易陷入局部最优解,收敛速度较慢,需要选择合适的步长因子和初始滤波器系数。
LMS算法的应用十分广泛,例如在通信系统中,可以用于自适应均衡、自适应滤波、自适应降噪等方面;在控制系统中,可以用于自适应控制、自适应识别等方面。
同时,LMS算法也是其他自适应滤波算法的基础,例如最小二乘算法、
递归最小二乘算法等。
总之,最小均方误差算法是一种重要的自适应滤波算法,具有广泛的应用前景和研究价值。
最小均方算法

第3章 最小均方算法3.1 引言最小均方(LMS ,least -mean -square)算法是一种搜索算法,它通过对目标函数进行适当的调整[1]—[2],简化了对梯度向量的计算。
由于其计算简单性,LMS 算法和其他与之相关的算法已经广泛应用于白适应滤波的各种应用中[3]-[7]。
为了确定保证稳定性的收敛因子范围,本章考察了LMS 算法的收敛特征。
研究表明,LMS 算法的收敛速度依赖于输入信号相关矩阵的特征值扩展[2]—[6]。
在本章中,讨论了LMS 算法的几个特性,包括在乎稳和非平稳环境下的失调[2]—[9]和跟踪性能[10]-[12]。
本章通过大量仿真举例对分析结果进行了证实。
在附录B 的B .1节中,通过对LMS 算法中的有限字长效应进行分析,对本章内容做了补充。
LMS 算法是自适应滤波理论中应用最广泛的算法,这有多方面的原因。
LMS 算法的主要特征包括低计算复杂度、在乎稳环境中的收敛性、其均值无俯地收敛到维纳解以及利用有限精度算法实现时的稳定特性等。
3.2 LMS 算法在第2章中,我们利用线性组合器实现自适应滤波器,并导出了其参数的最优解,这对应于多个输入信号的情形。
该解导致在估计参考信号以d()k 时的最小均方误差。
最优(维纳)解由下式给出:其中,R=E[()x ()]T x k k 且p=E[d()x()] k k ,假设d()k 和x()k 联合广义平稳过程。
如果可以得到矩阵R 和向量p 的较好估计,分别记为()R k ∧和()p k ∧,则可以利用如下最陡下降算法搜索式(3.1)的维纳解:w(+1)=w()-g ()w k k k μ∧w()(()()w())k p k R k k μ∧∧=-+2 (3.2) 其中,k =0,1,2,…,g ()w k ∧表示目标函数相对于滤波器系数的梯度向量估计值。
一种可能的解是通过利用R 和p 的瞬时估计值来估计梯度向量,即 10w R p -=(3.1)()x()x ()T R k k k ∧=()()x()p k d k k ∧= (3.3) 得到的梯度估计值为(3.4) 注意,如果目标函数用瞬时平方误差2()e k 而不是MSE 代替,则上面的梯度估计值代表了真实梯度向量,因为2010()()()()2()2()2()()()()T e k e k e k e k e k e k e k w w k w k w k ⎡⎤∂∂∂∂=⎢⎥∂∂∂∂⎣⎦ 2()x()e k k =-()w g k ∧= (3.5) 由于得到的梯度算法使平方误差的均值最小化.因此它被称为LMS 算法,其更新方程为 (1)()2()x()w k w k e k k μ+=+ (3.6) 其中,收敛因子μ应该在一个范围内取值,以保证收敛性。
最小均方算法
第3章 最小均方算法3.1 引言最小均方(LMS ,least -mean -square)算法是一种搜索算法,它通过对目标函数进行适当的调整[1]—[2],简化了对梯度向量的计算。
由于其计算简单性,LMS 算法和其他与之相关的算法已经广泛应用于白适应滤波的各种应用中[3]-[7]。
为了确定保证稳定性的收敛因子范围,本章考察了LMS 算法的收敛特征。
研究表明,LMS 算法的收敛速度依赖于输入信号相关矩阵的特征值扩展[2]—[6]。
在本章中,讨论了LMS 算法的几个特性,包括在乎稳和非平稳环境下的失调[2]—[9]和跟踪性能[10]-[12]。
本章通过大量仿真举例对分析结果进行了证实。
在附录B 的B .1节中,通过对LMS 算法中的有限字长效应进行分析,对本章内容做了补充。
LMS 算法是自适应滤波理论中应用最广泛的算法,这有多方面的原因。
LMS 算法的主要特征包括低计算复杂度、在乎稳环境中的收敛性、其均值无俯地收敛到维纳解以及利用有限精度算法实现时的稳定特性等。
3.2 LMS 算法在第2章中,我们利用线性组合器实现自适应滤波器,并导出了其参数的最优解,这对应于多个输入信号的情形。
该解导致在估计参考信号以d()k 时的最小均方误差。
最优(维纳)解由下式给出:其中,R=E[()x ()]T x k k 且p=E[d()x()] k k ,假设d()k 和x()k 联合广义平稳过程。
如果可以得到矩阵R 和向量p 的较好估计,分别记为()R k ∧和()p k ∧,则可以利用如下最陡下降算法搜索式(3.1)的维纳解:w(+1)=w()-g ()w k k k μ∧w()(()()w())k p k R k k μ∧∧=-+2 (3.2) 其中,k =0,1,2,…,g ()w k ∧表示目标函数相对于滤波器系数的梯度向量估计值。
一种可能的解是通过利用R 和p 的瞬时估计值来估计梯度向量,即 10w R p -=(3.1)()x()x ()T R k k k ∧=()()x()p k d k k ∧= (3.3) 得到的梯度估计值为(3.4) 注意,如果目标函数用瞬时平方误差2()e k 而不是MSE 代替,则上面的梯度估计值代表了真实梯度向量,因为2010()()()()2()2()2()()()()T e k e k e k e k e k e k e k w w k w k w k ⎡⎤∂∂∂∂=⎢⎥∂∂∂∂⎣⎦ 2()x()e k k =-()w g k ∧= (3.5) 由于得到的梯度算法使平方误差的均值最小化.因此它被称为LMS 算法,其更新方程为 (1)()2()x()w k w k e k k μ+=+ (3.6) 其中,收敛因子μ应该在一个范围内取值,以保证收敛性。
毕业设计(论文)-lms及rls自适应干扰抵消算法的比较[管理资料]
![毕业设计(论文)-lms及rls自适应干扰抵消算法的比较[管理资料]](https://img.taocdn.com/s3/m/e45ae55891c69ec3d5bbfd0a79563c1ec4dad715.png)
前言自适应信号处理的理论和技术经过40 多年的发展和完善,已逐渐成为人们常用的语音去噪技术。
我们知道, 在目前的移动通信领域中, 克服多径干扰, 提高通信质量是一个非常重要的问题, 特别是当信道特性不固定时, 这个问题就尤为突出, 而自适应滤波器的出现, 则完美的解决了这个问题。
另外语音识别技术很难从实验室走向真正应用很大程度上受制于应用环境下的噪声。
自适应滤波的原理就是利用前一时刻己获得的滤波参数等结果, 自动地调节现时刻的滤波参数, 从而达到最优化滤波。
自适应滤波具有很强的自学习、自跟踪能力, 适用于平稳和非平稳随机信号的检测和估计。
自适应滤波一般包括3个模块:滤波结构、性能判据和自适应算法。
其中, 自适应滤波算法一直是人们的研究热点, 包括线性自适应算法和非线性自适应算法, 非线性自适应算法具有更强的信号处理能力, 但计算比较复杂, 实际应用最多的仍然是线性自适应滤波算法。
线性自适应滤波算法的种类很多, 有RLS自适应滤波算法、LMS自适应滤波算法、变换域自适应滤波算法、仿射投影算法、共扼梯度算法等[1]。
其中最小均方(Least Mean Square,LMS)算法和递归最小二乘(Recursive Least Square,RLS)算法就是两种典型的自适应滤波算法, 它们都具有很高的工程应有价值。
本文正是想通过这一与我们生活相关的问题, 对简单的噪声进行消除, 更加深刻地了解这两种算法。
我们主要分析了下LMS算法和RLS算法的基本原理, 以及用程序实现了用两种算法自适应消除信号中的噪声。
通过对这两种典型自适应滤波算法的性能特点进行分析及仿真实现, 给出了这两种算法性能的综合评价。
1 绪论自适应噪声抵消( Adaptive Noise Cancelling, ANC) 技术是自适应信号处理的一个应用分支, 年提出, 经过三十多年的丰富和扩充, 现在已经应用到了很多领域, 比如车载免提通话设备, 房间或无线通讯中的回声抵消( AdaptiveEcho Cancelling, AEC) , 在母体上检测胎儿心音, 机载电子干扰机收发隔离等, 都是用自适应干扰抵消的办法消除混入接收信号中的其他声音信号。
matlab 最小均方误差(lms)算法

matlab 最小均方误差(lms)算法The least mean squares (LMS) algorithm in MATLAB is a widely used adaptive filter algorithm that aims to minimize the mean square error between the desired signal and the output of the filter. MATLAB provides convenient tools and functions for implementing and optimizing LMS algorithms, making it a popular choice for researchers and engineers working in signal processing and system identification.MATLAB中的最小均方误差(LMS)算法是一种广泛使用的自适应滤波器算法,旨在最小化期望信号与滤波器输出之间的均方误差。
MATLAB提供了方便的工具和函数,用于实现和优化LMS算法,使其成为信号处理和系统辨识领域的研究人员和工程师的首选。
One of the key advantages of using the LMS algorithm in MATLAB is its simplicity and efficiency. With just a few lines of code, users can implement an LMS filter and start optimizing it for their specific application. This ease of use makes MATLAB a popular choice for beginners and experts alike who are looking to quickly prototype and test adaptive filter solutions.在MATLAB中使用LMS算法的一个重要优势是其简单性和高效性。
神经网络与机器学习笔记—LMS(最小均方算法)和学习率退火
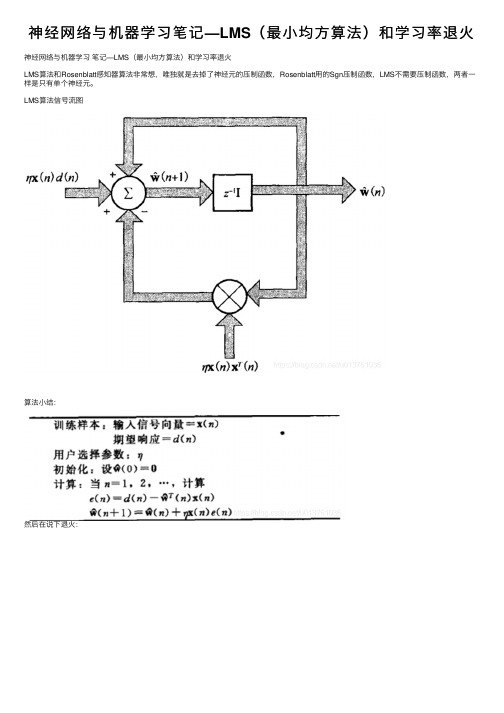
神经⽹络与机器学习笔记—LMS(最⼩均⽅算法)和学习率退⽕神经⽹络与机器学习笔记—LMS(最⼩均⽅算法)和学习率退⽕LMS算法和Rosenblatt感知器算法⾮常想,唯独就是去掉了神经元的压制函数,Rosenblatt⽤的Sgn压制函数,LMS不需要压制函数,两者⼀样是只有单个神经元。
LMS算法信号流图算法⼩结:然后在说下退⽕:#pragma once#include "stdafx.h"#include <string>#include <iostream>using namespace std;int gnM = 0; //训练集空间维度int gnN = 0; //突触权值个数double gdU0 = 0.1; //初始学习率参数,⽤于退⽕,前期可以较⼤double gdT = 1; //控制退⽕⽤的开始降温的时间点double gdN = 0; //当前⼯作时间(神经⽹络学习次数)//退⽕//U=U0/(1+(N/T))double GetNowU() {gdN++;//cout<< gdU0 / (1.0 + (gdN / gdT))<<endl;return gdU0 / (1.0 + (gdN / gdT));}void LMSInit(double *dX, const int &nM, double *dW, const int &nN, const double &dB, const double &dU0 ,const double &dT) { //dX 本次训练数据集//nM 训练集空间维度//dW 权值矩阵//nN 突触权值个数 LMS只有⼀个神经元,所以nM==nM//dB 偏置,正常这个是应该⾛退⽕动态调整的,以后再说,现在固定得了。
//dU0 初始学习率参数,⽤于退⽕,前期可以较⼤//dT控制退⽕⽤的开始降温的时间点if (nM > 0) {dX[0] = 1;//把偏置永远当成⼀个固定的突触}for (int i = 0; i <= nN; i++) {if (i == 0) {dW[i] = dB;//固定偏置}else {dW[i] = 0.0;}}gnM = nM, gnN = nN, gdU0 = dU0, gdT = dT;}double Sgn(double dNumber) {return dNumber > 0 ? +1.0 : -1.0;}//感知器收敛算法-学习void LMSStudy(const double *dX, const double dD, double *dW) {//dX 本次训练数据集//dD 本次训练数据集的期望值//dW 动态参数,突触权值double dY = 0;for (int i = 0; i <= gnM && i <= gnN; i++) {dY = dY + dX[i] * dW[i];}//dY = Sgn(dY); LMS这个地⽅不⽤了,Rosenblatt是需要的if (dD == dY) {return;//不需要进⾏学习调整突触权值}for (int i = 1; i <= gnM && i <= gnN; i++) {dW[i] = dW[i] + GetNowU() * (dD - dY) * dX[i];}}//感知器收敛算法-泛化double LMSGeneralization(const double *dX, const double *dW) { //dX 本次需要泛化的数据集//dW 已经学习好的突触权值//返回的是当前需要泛化的数据集的泛化结果(属于那个域的) double dY = 0;for (int i = 0; i <= gnM && i <= gnN; i++) {dY = dY + dX[i] * dW[i];}return Sgn(dY);}//双⽉分类模型,随机获取⼀组值/* ⾃⼰稍微改了下域1:上半个圆,假设圆⼼位坐标原点(0,0)(x - 0) * (x - 0) + (y - 0) * (y - 0) = 10 * 10x >= -10 && x <= 10y >= 0 && y <= 10域2:下半个圆,圆⼼坐标(10 ,-1)(x - 10) * (x - 10) + (y + 1) * (y + 1) = 10 * 10;x >= 0 && x <= 20y >= -11 && y <= -1*/const double gRegionA = 1.0; //双⽉上const double gRegionB = -1.0;//双⽉下void Bimonthly(double *dX, double *dY, double *dResult) {//dX 坐标x//dY 坐标y//dResult 属于哪个分类*dResult = rand() % 2 == 0 ? gRegionA : gRegionB;if (*dResult == gRegionA) {*dX = rand() % 20 - 10;//在区间内随机⼀个X*dY = sqrt(10 * 10 - (*dX) * (*dX));//求出Y}else {*dX = rand() % 20;*dY = sqrt(10 * 10 - (*dX - 10) * (*dX - 10)) - 1;*dY = *dY * -1;}}int main(){//system("color 0b");double dX[2 + 1], dD, dW[2 + 1]; //输⼊空间维度为3 平⾯坐标系+⼀个偏置double dB = 0;double dU0 = 0.1;double dT = 128; //128之后开始降温LMSInit(dX, 2, dW, 2, dB, dU0, dT);//初始化感知器double dBimonthlyX, dBimonthlyY, dBimonthlyResult;int nLearningTimes = 1024 * 10;//进⾏10K次学习for (int nLearning = 0; nLearning <= nLearningTimes; nLearning++) {Bimonthly(&dBimonthlyX, &dBimonthlyY, &dBimonthlyResult);//随机⽣成双⽉数据dX[1] = dBimonthlyX;dX[2] = dBimonthlyY;dD = dBimonthlyResult;LMSStudy(dX, dD, dW);//cout <<"Study:" << nLearning << " :X= " << dBimonthlyX << "Y= " << dBimonthlyY << " D=" << dBimonthlyResult<< "----W1= " << dW[1] << " W2= " << dW[2] << endl; }//进⾏LMS泛化能⼒测试测试数据量1Kint nGeneralizationTimes = 1 * 1024;int nGeneralizationYes = 0, nGeneralizationNo = 0;double dBlattGeneralizationSuccessRate = 0;for (int nLearning = 1; nLearning <= nGeneralizationTimes; nLearning++) {Bimonthly(&dBimonthlyX, &dBimonthlyY, &dBimonthlyResult);//随机⽣成双⽉数据dX[1] = dBimonthlyX;dX[2] = dBimonthlyY;//cout << "Generalization: " << dBimonthlyX << "," << dBimonthlyY;if (dBimonthlyResult == LMSGeneralization(dX, dW)) {nGeneralizationYes++;//cout << " Yes" << endl;}else {nGeneralizationNo++;//cout << " No" << endl;}}dBlattGeneralizationSuccessRate = nGeneralizationYes * 1.0 / (nGeneralizationNo + nGeneralizationYes) * 100;cout << "Study : " << nLearningTimes << " Generalization : " << nGeneralizationTimes << " SuccessRate:" << dBlattGeneralizationSuccessRate << "%" << endl; getchar();return 0;}执⾏结果:Study : 10240 Generalization : 1024 SuccessRate:96.6797%注意:相对于Rosenblatt算法,LMS如果直接把sgn去掉了可能出现泛化能⼒急剧下降的问题,我就是,直接变成50%了(和没学习⼀样),因为此时的学习率参数恒等于0.1有点⼤(为什么说0.1⼤,因为没有sgn了,算出的XW是⽐较⼤的,⽽这个时候我们训练数据集的期望结果,还是+1和-1)。
最小均方算法(lms)的原理

最小均方算法(lms)的原理
最小均方算法(LMS)是一种用于信号处理和自适应滤波的算法,它是一种迭代算法,
用于最小化预测误差的均方值。
在该算法中,滤波器的系数会根据输入信号实时地调整,
以使得滤波器的输出能够尽可能地接近期望输出。
LMS算法的核心理念是通过不断迭代,不断的调整滤波器的系数,使其能够最大限度
地降低误差。
该算法首先需要确定一组初始系数,并计算出当前的滤波器输出以及误差。
然后,根据误差的大小和方向来调整滤波器的系数,并重复这个过程,直到误差的均方值
达到最小。
这个过程的数学原理可以用一个简单的公式来表示:
w(n+1) = w(n) + µe(n)X(n)
其中, w(n)是当前滤波器的系数,µ是一个可调节的步长参数,e(n)是当前的误差,
X(n)是输入数据的向量。
在该算法中,步长参数µ的大小对LMS算法的性能有重要的影响。
如果其选择过大,
会导致算法不稳定,收敛到一个错误的值;而如果µ的值过小,则算法收敛速度慢。
此外,在使用LMS算法时,还需要进行一些预处理。
比如,在对输入信号进行滤波时,通常需要进行预加重处理,以便在高频段上增强信号的弱化部分。
同时,在为滤波器确定
初始系数时,还需要利用一些特定的算法来进行优化,以使得滤波器的性能能够得到进一
步的提升。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
E{| e(n) |2} E{e(n)e* (n)} E{| d (n) |2} w H rxd (w H rxd )* w H R xxw
E{| d (n) |2} 2 Re{w H rxd } w H R xxw
rxd (0)
rxd
E{x(n)d * (n)}
rxd (1)
x(n)
xT
(n)w*
i 1
e(n) d (n) y(n) d (n) w H x(n)
rxx (i) E{x(n)x* (n i)} rxx (i) rx*x (i) rxd (i) E{x(n)d * (n i)} rdx (i) rd*x (i)
f (w) E{| e(n) |2}
2 11
2 22
1
v'12
v'
2 2
1
(C1 / 1) (C2 / 2 )
1 均方误差椭圆
的长轴正比于
min
短轴正比于 1 max
§3.3 最陡下降法 3.3.1 最陡下降法的递推公式
=E{| d (n) |2} 2 Re{w H rxd } w H R xxw
w 2R xxw 2rxd
v(n) (I 2QΛQ1)n v(0) [Q(I 2Λ)Q1]n v(0)
正交原理
w=w E{| e2 (n) |} 0 e(n) d (n) w H x(n)
e er je j d dr jd j x xr jx j w w r jw j
| e |2 er2 e2j
[dr
(w
T r
x
r
wTj x
j
)]2
[d
j
(wTr x
j
wTj xr )]2
v w w opt = min+v H R xx v
R xxqi
iqi
i 1,2, , M
qiH q j
1 0
i j i j
q11 q1M
Q
q1 ,
,qM
qM1 qMM
Q H Q I, Q H Q1 Q H R xxQ Λ R xx QΛQH QΛQ1
Λ Diag(1, 2 , M ) =min vH QΛQH v
根据正交原理推正规方程
0 E{x(n)e*(n)} E{x(n)[d *(n) xH (n)wopt ]}
E{x(n)d *(n)} E{x(n)xH (n)}wopt
R xxw rxd
§3.2 关于均方误差性能函数的进一步讨论 3.2.1 均方误差性能函数的各种表达式
=min+(w wopt )H Rxx (w wopt )
w opt
R
r 1
xx xd
min
E{e2 (n)}min
E{d
2
(n)}
wH opt
rxd
w(n 1) w(n) w
w(n 1) w(n) [2R xxw(n) 2rxd ]
w(n 1) (I 2R xx )w(n) 2rxd
w(n 1) w opt (I 2R xx )[w(n) w opt ]
v' Q H v [v1 ', , vM ']T
v Qv'
min v'H Λv ' min M i vi' 2
i 1
qi ' QH qi [q1,L , qi ,L , qM ]H qi [0,L ,1,L 0]T
3.2.2 几何意义
w
w1 w2
w opt
wopt1 wopt 2
(正规方程) R xx w opt=rxd
wopt=R-xx1rxd
E{|
d
(n)
|2
}
wH opt
rxd
min
E{| d(n)
|2} 2 Re{woHptrxd }
wH opt
R
xx
wopt
E{|
d (n)
|2}
wH opt
R
w xx opt
正规方程的解
(1) 直接矩阵求逆算法(DMI算法)或采样矩阵求逆(SMI)算法。 (2) 最陡下降法(加权系数的递推)----最小均方算法即LMS算法 (3) Levinson-Durbin算法(加权系数的递推)利用矩阵的埃尔米特 和Toeplitz性质
v
w w opt
v1 v2
'
R xx
rxx (0)
rxx
(1)
rxx (1)
rxx (0) rxx (0) 0
图3.2 均方误差性能面
图3.3 等均方误差椭圆族
min vT R xx v C vT R xxv C1
v' v' C QT
R
xxQ
Λ
1
0
0
2
v'T Λv ' C1
第三章 最小均方(LMS)算法
§3.1 最小均方误差滤波器
图3.1 横式滤波器
w [w1 , w2 ,..., wM ]T
x(n) [x1(n), x2 (n),..., xM (n)]T [x(n), x(n 1))
M
wi* x(n i
1)
wH
3.3.2最陡下降法的性能分析
一、收敛性
w(n 1) w opt (I 2R xx )[w(n) w opt ]
v(n) w(n) w opt v(n 1) (I 2R xx )v(n) v(0) w(0) w opt v(n) (I 2R xx )n v(0) R xx QΛQH QΛQ1
v H R xxv E{v H x(n)x H (n)v} E{| x H (n)v |2} 0
(3)具有Toeplitz性质,即其任意对角线上的元素相等。
最佳解---维纳解
E{| d (n) |2} 2 Re{w H rxd } w H R xxw
f (w) E{| e(n) |2} w w E{e2 (n)} 0
rxd (1 M )
rxx (0)
R xx
E{x(n)x H (n)}
rxx (1)
(1)是埃米尔特矩阵
R
H xx
R xx
rxx (1 M )
rxx (1) rxx (0)
rxx (2 M )
rxx (M 1) rxx (M 2)
rxx (0)
(2)是正定的或半正定的。
w | e |2 wr | e |2 jw j | e |2 2xe*
w E{| e(n) |2} E{w | e(n) |2} E{2e* (n)x(n)} 0
E{x(n)e* (n)} 0 E{p(n)q* (n)} 0
E{x(n i)e* (n)} 0 i 0,1, , M 1