基于短时特征双阈值检测的话音信号端点检测算法
基于短时能量的语音信号端点检测_石海燕

( 4) 智能化语音虚拟现实建模。虚拟现实建模是一个比较繁复的过程, 需要大量的时间和精力。如果将 VR 技术与智能技术、语 音识别技术结合起来, 可以很好地解决这个问题。我们对模型的属性、方法和一般特点的描述通过语音识别技术转化成建模所需的 数据, 然后利用计算机的图形处理技术和人工智能技术进行设计、导航以及评价 , 将模型用对象表示出来, 并且将各种基本模型静 态或动态地连接起来, 最终形成系统模型。人工智能一直是业界的难题, 人工智能在各个领域十分有用, 在虚拟世界也大有用武之 地, 良好的人工智能系统对减少乏味的人工劳动具有非常积极的作用。
( 1)
( 2)
( 3) 公式( 2) 中的 δ为一个无穷小量, 是为防止对 0 取对数而加入的, 公式( 3) 中的 median 为每帧帧向量的中位值。我们往往对语音 信号进行加窗后再进行分帧、特征提取等处理, 其中窗函数可采用方窗、哈明窗[5]。
方窗函数:
收稿日期: 2008- 04- 16
1704 电脑知识与技术
近几十年来, 通信技术、计算机的同步发展和相互促进成为世界上信息技术与产业飞速发展的主要特征。特别是网络技术的迅 速崛起与普及, 使得信息应用系统在深度和广度上发生了质的变化。虚拟现实主要依靠人机交互的发展, 目前技术上已初步解决人 脑数据的读取, 在不久的将来, 开发者将完全解决通过神经系统自动进入虚拟现实环境的“人脑— ——计算机接口”问题, 通过对人脑 提取和反馈神经信号使人完全融入“虚拟现实”世界。当然从技术角度, 我们应该对基于多用户虚拟环境进行必要的技术研究。因为 将来的 VR 技术将越来越重视人在其中的交互。虚拟现实充满活力、具有无限的应用前景的高新技术领域, 但仍然存在许多有待解 决与突破的问题。为了提高系统的交互性、逼真性和沉侵性 , 在新型传感和感知肌理、几何与建模新方法、高性能计算, 特别是高速 图形图像处理, 以及人工智能、心理学、社会学等方面都有许多具有挑战性的问题有待我们进一步解决。
端点检测——精选推荐

端点检测语⾳信号处理实验⼀:端点检测姓名:XXX 学号:XXXX 班级:XX⼀、实验⽬的:理解语⾳信号时域特征和倒谱特征求解⽅法及其应⽤。
⼆、实验原理与步骤:任务⼀:语⾳端点检测。
语⾳端点检测就是指从包含语⾳的⼀段信号中确定出语⾳的起始点和结束点。
正确的端点检测对于语⾳识别和语⾳编码系统都有重要的意义。
采⽤双门限⽐较法的两级判决法,具体如下第⼀级判决:1. 先根据语⾳短时能量的轮廓选取⼀个较⾼的门限T1,进⾏⼀次粗判:语⾳起⽌点位于该门限与短时能量包络交点所对应的时间间隔之外(即AB段之外)。
2. 根据背景噪声的平均能量(⽤平均幅度做做看)确定⼀个较低的门限T2,并从A点往左、从B点往右搜索,分别找到短时能量包络与门限T2相交的两个点C和D,于是CD段就是⽤双门限⽅法根据短时能量所判定的语⾳段。
第⼆级判决:以短时平均过零率为标准,从C点往左和从D点往右搜索,找到短时平均过零率低于某个门限T3的两点E和F,这便是语⾳段的起⽌点。
门限T3是由背景噪声的平均过零率所确定的。
注意:门限T2,T3都是由背景噪声特性确定的,因此,在进⾏起⽌点判决前,T1,T2,T3,三个门限值的确定还应当通过多次实验。
任务⼆:利⽤倒谱⽅法求出⾃⼰的基⾳周期。
三、实验仪器:Cooledit、Matlab软件四、实验代码:取端点流程图⼀:clc,clear[x,fs,nbits]=wavread('fighting.wav'); %x为0~N-1即1~Nx = x / max(abs(x)); %幅度归⼀化到[-1,1]%参数设置FrameLen = 240; %帧长,每帧的采样点inc = 80; %帧移对应的点数T1 = 10; %短时能量阈值,语⾳段T2 = 5; %短时能量阈值,过渡段T3 = 1; %过零率阈值,起⽌点minsilence = 6; %⽆声的长度来判断语⾳是否结束silence = 0; %⽤于⽆声的长度计数minlen = 15; %判断是语⾳的最⼩长度state = 0; %记录语⾳段状态0 = 静⾳,1 = 语⾳段,2 = 结束段count = 0; %语⾳序列的长度%计算短时能量shot_engery = sum((abs(enframe(x, FrameLen,inc))).^2, 2);%计算过零率tmp1 = enframe(x(1:end-1), FrameLen,inc);%tmp1为⼆维数组=帧数*每帧的采样点FrameLen tmp2 = enframe(x(2:end) , FrameLen,inc);%signs = (tmp1.*tmp2)<0;%signs为⼀维数组,符合的置1,否则置0zcr = sum(signs,2);%开始端点检测,找出A,B点for n=1:length(zcr)if state == 0 % 0 = 静⾳,1 = 可能开始if shot_engery(n) > T1 % 确信进⼊语⾳段x1 = max(n-count-1,1); % 记录语⾳段的起始点state = 2; silence = 0;count = count + 1;elseif shot_engery(n) > T2|| zcr(n) > T3 %只要满⾜⼀个条件,可能处于过渡段status = 1;count = count + 1;x2 = max(n-count-1,1);else % 静⾳状态state = 0; count = 0;endendif state = =2 % 1 = 语⾳段if shot_engery(n) > T2 % 保持在语⾳段count = count + 1;elseif zcr(n) > T3 %保持在语⾳段x3 = max(n-count-1,1);else % 语⾳将结束silence = silence+1;if silence < minsilence %静⾳还不够长,尚未结束count = count + 1;elseif count < minlen % 语⾳段长度太短,认为是噪声state = 0;silence = 0;count = 0;else % 语⾳结束state = 3;endendendif state = =3 % 2 = 结束段break;endendx1,x2,x3 %A、C、E坐标x11 = x1 + count -1 %B坐标x22 = x2 + count -1 %D坐标x33 = x3 + count -1 %F坐标%画图subplot(3,1,1)plot(x)axis([1 length(x) -1 1])%标定横纵坐标title('原始语⾳信号','fontsize',17);xlabel('样点数'); ylabel('Speech');line([x3*inc x3*inc], [-1 1], 'Color', 'red'); %画竖线line([x33*inc x33*inc], [-1 1], 'Color', 'red');subplot(3,1,2)plot(shot_engery);axis([1 length(shot_engery) 0 max(shot_engery)])title('短时能量','fontsize',17);xlabel('帧数'); ylabel('Energy');line([x1 x1], [min(shot_engery),T1], 'Color', 'red'); %画竖线line([x11 x11], [min(shot_engery),T1], 'Color', 'red'); % line([x2 x2], [min(shot_engery),T2], 'Color', 'red'); %line([x22 x22], [min(shot_engery),T2], 'Color', 'red'); %line([1 length(zcr)], [T1,T1], 'Color', 'red', 'linestyle', ':'); %画横线line([1 length(zcr)], [T2,T2], 'Color', 'red', 'linestyle', ':'); % text(x1,-5,'A'); %标写A、B、C、Dtext(x11-5,-5,'B');text(x2-10,-5,'C');text(x22-5,-5,'D');subplot(3,1,3)plot(zcr);axis([1 length(zcr) 0 max(zcr)])title('过零率','fontsize',17);xlabel('帧数'); ylabel('ZCR');line([x3 x3], [min(zcr),max(zcr)], 'Color', 'red'); %画竖线line([x33 x33], [min(zcr),max(zcr)], 'Color', 'red'); %line([1 length(zcr)], [T3,T3], 'Color', 'red', 'linestyle', ':'); %画横线text(x3-10,-3,'E起点'); %标写E、Ftext(x33-40,-3,'F终点');运⾏结果与分析:x1 = 650,x11 = 734,x2 = 646,x22 = 752,x3 = 643,x33 = 763得出的值x3<x2 <x1="" <x11<="" x22<="" x33="" ,基本符合要求<="" p="" bdsfid="194">。
动态阈值双门限语音端点检测研究
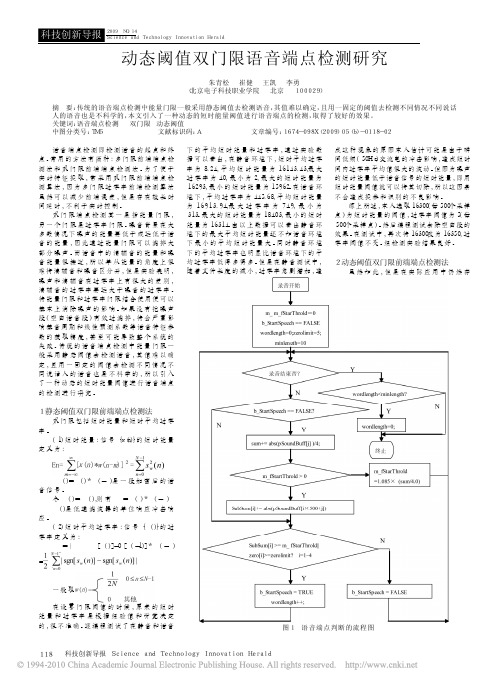
(上接117页)
连 接 ,现 在 刚 性 连 接 。 (2)其 他 部 位 裂 缝 :裂 缝 产 生 的 主 要 原
因 是 温 度 和 应 力 综 合 作 用 ,不 是 结 构 性 裂 缝 ,对 安 全 构 造 功 能 不 会 重 大 有 影 响 ,以 后 产生的裂缝不是很重要。
( 3)室 外 及 室 内 局 部 裂 缝 碳 纤 维 和 钢 筋混凝土补强。
4 结论
实 验 证 明 ,在 双 门 限 语 音 前 端 端 点 检 测 中 ,用 动 态 短 时 能 量 阈 值 代 替 静 态 短 时 能 量 阈 值 进 行 语 音 端 点 检 测 ,能 够 较 好 地 去 掉 噪 声 ,为 提 高 语 音 特 征 参 数 及 识 别 系
统的顽健性奠定了坚实的基础。
语音端点检测即检测语音的起点和终 点 。常 用 的 方 法 有 两 种 :多 门 限 前 端 端 点 检 测 法 和 双 门 限 前 端 端 点 检 测 法 。为 了 便 于 实 时 特 征 提 取 ,常 采 用 双 门 限 前 端 端 点 检 测 算 法 ,因 为 多 门 限 过 零 率 前 端 检 测 算 法 虽 然 可 以 减 少 前 端 误 差 ,但 是 存 在 较 长 时 间 延 时 ,不 利 于 实 时 控 制 。
参考文献
[1] 王 炳 锡 .语 音 编 码 . 西 安 :西 安 电 子 科 技 大 出 版 社 ,2001.
[ 2 ] 易 克 初 ,田 斌 ,付 强 . 语 音 信 号 处 理 . 北 京 :国 防 工 业 出 版 社 ,2001.
[3] 边 肇 祺,张 学 工.模 式 识 别 .北 京 :清 华 大 学 出 版 社 ,2001.
成这种现象的原因本人估计可能是由于瞬 间低频(50Hz)交流电的冲击影响,造成短时 间内过零率平均值很大的波动。但因为噪声 的 短 时 能 量 低 于 语 音 信 号 的 短 时 能 量 ,即 用 短时能量阈值就可以将其切除,所以这因素 不会造成提参和识别的不良影响。
一种改进的多特征值语音端点检测方法研究

一种改进的多特征值语音端点检测方法研究李申【摘要】为了提高语音识别系统中语音端点检测的准确性,提出一种改进的多特征值语音端点检测方法.新方法首先对信号进行小波分解及小波去噪处理,对去噪后小波子带系数进行短时能量与基音周期两特征值的提取,综合考虑两特征值的大小来进行语音端点检测.实验证明,改进的检测方法提高了端点检测的抗噪性及准确度.【期刊名称】《电声技术》【年(卷),期】2015(039)006【总页数】5页(P45-48,77)【关键词】端点检测;小波阈值去噪;短时能量;基音周期【作者】李申【作者单位】江西理工大学信息工程学院,江西赣州341000【正文语种】中文【中图分类】TN912.341 引言随着科技的发展,语音识别技术已广泛应用于语音分析、语音合成、物联网智能家居、人机语音交互等领域。
在语音识别中只有准确地检测出接收信号的语音起止时间,建立有效的语音模型,才能识别出语音内容。
然而在实际环境中,语音经常夹杂着各种噪声,如何在噪声环境下准确地检测出语音的起止时间,成为现在研究的一个热点。
针对语音识别系统中端点检测的问题,文献[1]提出了采用短时能量阈值法,以接收语音信号的短时能量大小为检测的依据,当能量大于设定的阈值时,则判定为语音段,此方法简单易行,但误报率高;为了提高检测的准确率,文献[2]基于短时能量和短时过零率相结合的方法,采用多特征值,提高了检测的准确率,但是当噪声存在时,检测性能将会下降;为了提高抗噪性,文献[3]结合语音的能量与倒谱特征进行语音端点检测,在稳定噪声环境中取得了较好效果,但是倒谱特征提取会因噪声的变化而受到干扰,因而该方法也不适用于实际的语音环境;文献[4]提出利用分带谱熵和谱能量相结合的方法,划分了语音与噪声之间的边界,提高了端点检测的正确率,但随着信噪比的下降效果仍不够理想。
针对以上方法存在的问题,本文提出一种改进的多特征值语音端点检测算法,该方法首先对接收到的语音信号进行小波分解及小波阈值去噪处理,然后对去噪后的小波子带系数进行语音信号多特征值的提取,采用多特征值相结合的方法进行语音端点检测。
基于短时能量的语音信号端点检测

基于短时能量的语音信号端点检测作者:石海燕来源:《电脑知识与技术·学术交流》2008年第18期摘要:语音信号端点检测是语音信号的预处理,正确的语音信号端点检测结果直接影响语音识别等后续工作的运算量和准确率。
本文介绍了时域方法中基于短时能量的语音信号端点检测方法,并用三种不同的短时能量计算方式和五种短时能量阈值进行了端点检测实验。
关键词:短时能量;端点检测;阈值中图分类号:TP311文献标识码:A文章编号:1009-3044(2008)18-20ppp-0cSpeech Signal End Point Detection Based on Short-term EnergySHI Hai-yan(Computer Center, Shaoxing University, Shaoxing 312000, China)Abstract: Speech signal end point detection is the speech signal pre-processing. The correct speech signal end point detection will straightforward affect speech recognitioncomputational and correct rate. This paper introduce the end point detection based on short-term energy of time-domain methods. In our experiments, we use three ways to calculate the short-term energy and five ways to determine the short-term energy threshold. The experiments’ results show the differents short-term energy calculate way and short-term energy threshold produce the differents end point detection.Key words: short-term energy; end point detection; threshold1 引言在语音处理中,端点检测是一个关键问题,端点检测(End Point Detection,简称EPD)的目的是要决定语音信号开始和结束的位置,以去除信号开始和结束时的空白噪声。
基于短时能量特征的语音端点检测技术研究

L l e n g t h ( M1 ;
s u b p l o t ( 3 ,1 ,1 ) , p l o t ( M) ;t i t l e ( ’ o r i g i n a l s i g n a l ’ ) ;
d
N=2 5 6; k =0;
察学院”频谱信号及其短时能量图。通过短时能量可以较为
g r i d
f o r P =1: M 1 or f q =1 :N
s u b p l o t ( 4 ,l ,1 ) ,
p l o t ( a ) ;t i t l e ( ’ o r i g i n a l s i g n a l ’ ) ;
g r i d
N= 3 2;
究对相关研究人员具有一定借鉴意义。
参考文献
吨
p l o t ( b ) ;t i t l e ( ’ 加汉明窗信号’ ) ;
g r i d
二 、端点检 测
短 时能量 是有 用信 号 与噪声 区别 的重要特 征之 一 。通 过
【 1 】 胡立波 带噪语 音端点检测 算法研 究[ D ] 南京信 息工程 大学 系统 分析 与集成 , 2 0 0 9 .
M= l i n s p a c e ( 1 ,1 ,2 . 3 N) ; E n = c o n v ( M ,b . b 1 ; s u b p l o t ( 2 ,1 ,2 ) ,p l o t ( E n ) ;t i t l e ( ’ 短 时能量’ )
g r i d
AC A DE MI C R E S E AR C H 学术研究
基子短B 稍趄 星特征韵语音端点检测技术研究
◆ 刘 琦
端点检测

,即得
至此,求得了x1(n),即规则部分时间序列。 (4)利用公式
求得复杂度C0 。
不同语音端点检测方法的实验结果 对比
实验条件
(1)英文数据库
(2)中文数据库
中文数据库的采集由学生,都说普通话,个别人略带地方色彩。因 语音信号主要集中在300一3400Hz,所以采用44100Hz的采样率,采样位 数16位,采样通道选用立体声,每人读5次,每次通读十个词语一遍。共 有250个有效测试session共有830MB的数据量。说话内容选择的词语考虑 到了汉语中各个元音、辅音、摩擦音、爆破音和鼻音等各个不同的汉语 因素。
式中,sgn为符号函数,即:
过零率有两类重要的应用:第一,用于粗略地描述信号的频谱特 性;第二,用于判别清音和浊音、有话和无话。从上面提到的定义出 发计算过零率容易受低频干扰,特别是50Hz交流干扰的影响。解决这 个问题的办法,一个是做高通滤波器或带通滤波,减小随机噪声的影 响;另一个有效方法是对上述定义做一点修改,设一个门限T,将过 零率的含义修改为跨过正负门限。 于是,有定义:
根据Lmapel和Ziv的研究,对几乎所有的x属于[0,1]区间的c(n) 都会趋向一个定值:
其中b(n)是随机序列的渐进行为,用它来使c(n)归一化,称为 “相对复杂度”。 定义相对复杂度:
通常就是用这个函数来表达时间序列的复杂性变化。从这种算法 可以看出,完全随机的序列C(n)值趋向于1,而有规律的周期运动的 C(n)值则趋向于0。
式中,Cn与C’n分别代表谱密度函数S(w)与S’(w)的倒谱系数。
方法: 倒谱距离的测量法步骤类似于基于能量的端点检测,只是将倒谱 距离代替短时能量来作为特征参数。首先,假定前几帧信号是背景噪 声,计算这些帧的倒谱系数,利用前几帧倒谱系数的平均值可估计背 景噪声的倒谱系数,噪声倒谱系数的近似值可按下述规则进行更新, 即当前帧被认为是非语音帧:
基于短时自相关及过零率的语音端点检测算法

基于短时自相关及过零率的语音端点检测算法
纪振发;杨晖;李然;金银超
【期刊名称】《电子科技》
【年(卷),期】2016(029)009
【摘要】传统的基于短时能量端点检测算法,在高信噪比环境下可以比较准确地检测出语音端点,但在低信噪比环境下检测效果不理想.文中提出了基于短时自相关最大值与短时过零率之积的改进算法.利用短时自相关最大值可以有效地区分出语音段和噪音段,利用短时过零率可有效地检测出清音信号,将两参数相结合可有效地检测出低信噪比语音信号的端点.实验证明,在低信噪比环境下该改进算法相比短时能量算法减小了检测误差,可以有效地检测出语音端点.
【总页数】4页(P52-55)
【作者】纪振发;杨晖;李然;金银超
【作者单位】上海理工大学光电信息与计算机工程学院,上海200093;上海理工大学光电信息与计算机工程学院,上海200093;上海理工大学光电信息与计算机工程学院,上海200093;上海理工大学光电信息与计算机工程学院,上海200093
【正文语种】中文
【中图分类】TN912.34
【相关文献】
1.基于短时能量和短时过零率的VAD算法及其FPGA实现 [J], 李昱;林志谋;黄云鹰;卢贵主
2.基于短时能量加过零率的实时语音端点检测方法 [J], 吕卫强;黄荔
3.基于短时平均能量和短时过零率的藏语语音端点检测研究 [J], 卓嘎;边巴旺堆;姜军
4.基于短时平均幅度和短时平均过零率的藏语语音端点检测研究 [J], 武光利;戴玉刚;马宁
5.一种结合短时过零率的快速语音端点检测算法 [J], 蔡萍
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于短时特征双阈值检测的话音信号端点检测算法郑璐【摘要】通过分析话音信号的时域特征,发现其具有短时能量对浊音敏感、短时平均过零率对清音敏感的特点,可以准确判断有声段和静音段.在此基础上提出以静音能量阈值和静音时延阈值作为双门限判定参数的话音信号端点检测算法.实验表明,该方法简单、准确率高、鲁棒性好.【期刊名称】《陇东学院学报》【年(卷),期】2018(029)005【总页数】5页(P4-8)【关键词】端点检测;短时特征;双阈值【作者】郑璐【作者单位】陇东学院信息工程学院,甘肃庆阳 745000【正文语种】中文【中图分类】TP391.9语言是我们获取外界信息的主要方式。
话音信号作为语言的声学表现,是由人的发音器官发出的、具有特定语法和含义的声音[1],是人进行信息交换最重要、最有效、最直接、最自然的手段。
现代科学和计算机技术的蓬勃发展,使得人类社会越来越显示出信息化的特点,同时数字信号处理技术为话音信号的处理提供了强有力的工具。
由于受录音环境和技术的影响,一段话音信号的起止处总会受到噪声的干扰。
话音端点检测(Voice Endpoint Detection,VED)技术就是指在各类环境噪声的存在下,准确地提取一段话音信号的特征参数,找到其中有效话音段或单词的起始点和结束点,确定哪部分包含话音成分,哪部分属于非话音段。
近几十年来,端点检测各类算法层出不穷,常用的有:(1)时域分析法,其中最具代表性的是短时特征法;(2)频域分析法,包括基音检测、频谱分析、倒谱分析以及LPC(Linear Prediction Coefficients)预测残差法等;(3)基于人工神经网络的算法,将所有特征参数进行神经网络训练,但数据量太大,且不一定能得到好的分类效果[2-3]。
本文的研究根据后续话音识别系统的特点,选定短时能量和过零率来完成信号端点特征提取,提出了一种基于短时特征双阈值检测的话音信号端点检测算法,实验验证了该算法的检测效率,讨论了算法的适用范围。
1 数字话音信号采集与处理1.1 话音信号产生模型声音是通过人的多个发音器官协调共同作用产生的,包括肺部、气管、喉咙、口腔和鼻腔,这些功能器官组成一个复杂多变的通路,进一步产生不同的声音。
简单来说,话音的产生就是空气被肺部挤压由气管进入喉咙产生气流,气流经过声带进入声道,声道相当于一个可变谐振腔,再由口腔和鼻腔辐射出声波,即话音信号。
这个过程可以用数学模型来模拟,该模型由激励、声道和辐射三个模型串联组成,其中气流对应激励模型,声带对应声道模型,口腔和鼻腔对应辐射模型[4],如图1所示。
则其传输函数可以表示为:H(z)=A*U(z)V(z)R(z)图1 话音信号产生模型1.2 话音信号预处理由数学模型分析可知,话音信号十分的复杂多变,是一种非线性、时变的复杂信号,不仅包括高频成分和低频成分,还有清音和浊音。
在端点检测之前必须对其进行预处理,提取出可表示话音信号本质的特征参数并进行有效的处理,以便更好地进行后续识别。
预处理环节一般包括预加重、分帧和加窗函数[5]等,是端点检测过程中的关键。
(1)预加重由话音信号产生模型可知,话音从口腔中出来后,高频部分会有所衰减,预加重主要是为了提升高频分量,滤除低频干扰,特别是电源频率。
从某种程度来说,预加重可看作是一种补偿技术,增大高频信噪比,便于对声道参数分析时减少分析误差。
其函数如下:H(z)=1-αz-1,0.9<α<1上式中,α为预加重系数。
(2)分帧与加窗虽然从话音信号的整体波形特征来看它是非稳态时变的,但是人在说话过程中口腔肌肉的运动是缓慢变化、有惯性的,不会发生突变。
因此,在非常短的时间内可以把话音信号近似为特性平稳的时不变信号。
分帧即利用了这一特点,把一段完整的话音信号分成多个小段,每段称为一帧,帧长约10~30ms。
一般采用给话音信号加窗的方式进行分段,常用的窗函数有矩形窗、哈明窗和汉宁窗,根据不同种类的话音信号选择不同的窗函数。
为了保证分帧后信号依旧是连续的,相邻两帧间必然会有一定的重合,重合的这部分称为帧移,分帧示意图如图2所示。
图2 分帧示意图2 话音信号特征参数提取2.1 短时能量由于话音信号具有“短时平稳”的特点,定义分帧后每帧信号的平均能量为短时能量[6]。
首先设原始数字话音信号为x(n),xi(n)是x(n)被分帧加窗后的第i帧信号,满足:xi(n)=w(n)*x((i-1)*inc+n),1≤n≤L,1≤i≤fn(2.1)式(2.1)中,inc指帧移长度,w(n)指窗函数,本文选用汉明窗,L指每帧的帧长,fn指分帧后的总帧数。
由此得到xi(n)信号的短时能量公式为:,1≤i≤fn(2.2)设定一个门限,根据式(2.2)计算出某帧信号的短时能量,超过该门限的即被判定为有效话音信号。
短时能量描述的是话音信号的幅度变化,可以对有声段和无声段以及清音和浊音进行判定,但是仅仅依靠短时能量单一特征的判断不够准确。
因为清音和浊音能量分布不同,浊音能量较高,是人说话时由声带振动所发出的话音,在波形上表现出幅度较高、周期性的特点,可以用短时能量特征检测。
而清音能量较低,是说话时口腔运动与空气产生的摩擦音,其波形幅度随时间变化比较剧烈,用短时能量容易漏检,需引入其他的特征来完善检测效果。
2.2 短时过零率时域分析中除了对话音信号的能量进行分析,还可以从信号波形的角度分析。
音频信号输入会随时间上下波动,形成其特有的波形,这一特征可以用一帧话音信号的波形穿越零电平的次数来描述,称为短时过零率[7]。
其数学定义为:(2.3)式(2.3)中,sgn()是符号函数。
不同类型的音频信号短时过零率表示方式不同。
对于连续话音信号而言,过零率即一帧信号的时域波形通过时间轴的总次数;而对离散话音信号来说,相邻两个采样点的代数符号变化一次则表示一次“过零”,一帧中符号变化的总次数即过零率[8]。
研究表明,清音的短时过零率较高,环境噪声和浊音次之。
实验中采用短时平均过零率具有一定的抗干扰能力。
研究是结合短时能量和短时平均过零率两种特征进行话音信号端点检测的。
2.3 双阈值的确定通过对话音信号波形分析可知,有声段起止点的幅度会发生跃变,可利用短时特征来检测这一变化。
针对各类音频统计出一个门限,当某一帧的能量低于该门限时则认为这一帧话音结束,我们称此门限为静音能量阈值。
理论上,静音时刻的话音信号是没有能量的,但在实际中总是存在一定的背景噪声,并且音频种类不同背景噪声也各有特点。
所以为了精准地检测效果,应提取不同种类音频的特定静音能量阈值。
静音能量阈值能检测出话音边界,但是一段话音中总会出现不同时长的停顿,包括段与段之间,句与句之间,甚至字与字之间的短暂停顿都会使能量呈现一定程度的衰减,区别只是衰减时长的不同而已。
现实生活中,就人的听觉习惯而言,段落之间的停顿相对较长,而字词与句子之间的停顿和衰减可以忽略不计。
针对这一特征我们提出静音延时阈值来作为另一个门限。
手动标记音频中字词与句子之间的静音段,统计每类音频信号的最短段长,除以窗长,结果就是静音延时阈值。
3 算法描述算法的流程如图3所示,具体步骤为:图3 算法流程图(1)对数字话音信号进行预处理,分帧加窗使其具有较稳定的特征;(2)分帧后以帧为单位提取短时能量和短时平均过零率特征,得到离散的能量序列{E(n)};(3)根据经验设定静音能量阈值τ1和静音时延阈值τ2,依次检测{E(n)}中每一帧能量值与静音能量的关系,若第i帧能量E(i)<τ1,表示进入静音段,则帧计数器加一,若E(i)>τ1,表示进入话音段,并且计数器清零;(4)循环步骤(3),一直到帧计数器的值满足静音时延阈值τ2,此时把最近一次满足静音时延阈值的能量序列作为话音信号端点的候选序列。
(5)直到遍历完所有能量序列,算法结束。
4 实验结果与分析在Win10系统下基于MATLAB 2017a进行仿真。
实验数据来源于兰州大学信息工程学院的LZ201话音数据库,包括300人的录音,音频信息丰富,有男性和女性录音。
音频格式为wav。
信号采样频率为1.6kHz,精度为16bit,窗函数选用汉明窗,帧长取30ms。
为了验证端点检测算法在不同噪声下的准确率,采用人为添加白噪声的方式让待检测话音信号处于不同的噪声环境中。
以话音库中名为“今天星期一”的话音信号为例,首先通过Audacity音频处理软件将原始话音信号的端点标记出来作为groundtruth,图4是原始话音信号的基准切割图。
图4 基准切割示意图图5展示了“今天星期一”这段话音信号在不同信噪比(61dB、51dB、41dB、31dB、21dB、11dB)情况下采用基于短时特征双阈值话音信号端点检测算法的检测结果,包括不同信噪比信号的幅值、对应的短时特征值以及算法切割结果。
实验结果表明,该算法的检测结果全部包含有效的话音信息。
对于噪声干扰小,即信噪比较高的话音信号,端点检测准确度十分高,如图5.a、5.b、5.c、5.d所示。
同时,由于使用了静音能量阈值和静音延时阈值,双阈值条件使得算法对于话音信号中的无声段比较敏感,所以在信噪较低的情况下,端点检测的结果呈分段式。
其原因是“今天星期一”这段话音信号中不同的语义信息有不同时长的停顿,图5.e 和5.f分别以“今天~~星期一”和“今~~天~~星期一”的方式做了话音分割,对比原始录音,表明该结果有效。
图5 不同信噪比的话音信号端点检测结果实验处理了大量样本并分析了不同信噪比下本研究提出的算法的误差,如图6所示。
可以看出本研究提出的算法对应不同信噪比检测结果误差率的变化,在高信噪比时检测精度很高,误差率基本保证在1%以下,然而在低信噪比的情况下,算法的误差有所增加,但依旧可以满足90%以上的准确率。
因此,可以根据误差率选择该方法所适用的范围。
图6 算法误差率随信噪比的变化5 结论本研究基于话音短时能量和短时平均过零率两个特征参数,引入双阈值判决机制。
理论研究和实验表明,该算法简单有效、准确率高。
端点检测在语音识别、编码和传输等话音信号处理中的重要性不言而喻。
大量的研究和实验证明,语音信号识别过程中出现的50%以上错误都源于不正确的端点检测。
高效精准的端点检测算法不仅能准确地标识话音端点,更能降低系统对后续数据的处理时间、提高效率和节省数据存储空间,是话音信号识别过程中非常关键的一步。
参考文献:【相关文献】[1]赵力.语音信号处理[M].第1版.北京机械工业出版社,2003:1-4.[2]张仁志,崔慧娟.基于短时能量的语音端点检测算法研究[J].电声技术,2005(7):52-54.[3]JIN Li,CHENG Jiang.An Improved Speech Endpoint Detection Based on SpectralSubtraction and Adaptive Sub-band Spectral Entropy[C]//Proceedings of Inter-national Conference on Intelligent Computation Tech-nology and Automation.WashingtonA:IEEE Press,2010:591-594.[4]冉国敬,夏秀渝,张凤仪.信道失配环境下鲁棒说话人识别[J].计算机系统应用,2015,24(3):1-5.[5]韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004:32-50.[6]夏敏磊.语音端点检测技术研究[C].杭州:浙江大学,2005:11-20.[7]路青起,白燕燕.基于双门限两级判决的语音端点检测方法[J].电子科技,2012,25(1):13-15.[8]G.Suvarna Kumar,K. A.Prasad Raju,et al.Speaker Recognition UsingGMM[J].International Journal of Engineering Science and Technology,2010,2(6):2428-2436.。