语音端点检测方法研究
基于语音端点检测的说话人识别技术研究

基于语音端点检测的说话人识别技术研究使用语音技术进行说话人识别已经成为了许多领域中重要的应用,如指挥控制系统,安全验证系统等。
而其中一个重要的技术就是语音端点检测。
本文将会对基于语音端点检测的说话人识别技术进行深入研究。
一、语音端点检测的意义语音信号的端点检测是指确定语音信号开始和结束的时刻点,是语音信号分帧的重要前提。
准确的语音端点检测可以有效地提高语音分析和识别的准确度,同时也对于多媒体信息的处理和储存有重要的意义。
因此,在语音领域中,语音端点检测一直是一个备受关注的领域。
二、常用的语音端点检测算法目前,常见的语音端点检测算法主要分为基于阈值的算法和基于能量的算法。
基于阈值的算法主要是通过设置一个阈值,对于低于这个阈值的部分进行滤除,从而确定语音信号的端点。
这种算法可以适用于噪声较小的环境,但是面对噪声干扰较大的环境时,就很难得到一个较准确的结果。
基于能量的算法主要是对语音信号的能量进行测量,通过设定预定的能量阈值,判断信号的端点位置。
这种算法不仅快速而且准确,还依靠于信号能量,而这对于多噪声环境中的语音信号进行处理来说尤为重要。
三、语音端点检测在说话人识别中的应用说话人识别主要是指通过语音信号,通过一定的分析和算法,来识别说话人的身份信息。
常见的应用场景包括指挥控制系统中的安全验证、电话银行等领域。
语音端点检测可以帮助确定语音信号的开始和结束点,从而有效地提高说话人识别的准确度。
在进行说话人识别之前,首先需要对语音信号进行分帧,并确定语音信号的端点。
通过使用基于能量的语音端点检测算法,可以得到更加准确的结果,从而提高说话人识别的准确度。
同时,在处理多噪声环境中的语音信号时,基于能量的算法也要比基于阈值的算法更加准确。
四、未来的发展趋势随着科技的不断发展,语音端点检测和说话人识别技术也将进一步发展。
未来的发展趋势主要集中在以下几个方面:1. 基于深度学习的语音端点检测算法的应用:近年来,深度学习在语音处理中得到了广泛应用。
基于深度学习的语音端点检测技术研究

基于深度学习的语音端点检测技术研究随着科技发展的不断进步,我们的生活日益方便。
从智能手机到智能音箱,语音交互已经成为了越来越普遍的方式。
作为语音信号处理的核心环节之一的语音端点检测技术,在当前的社会中也扮演着极其重要的角色。
然而,在实际应用中,由于环境的复杂性以及语音信号的多样性,语音端点检测技术还面临着许多的挑战。
而基于深度学习的语音端点检测技术,相较于传统的基于特征工程的方法,具备更好的鲁棒性、准确性和普适性。
本文将从深度学习的原理、语音端点检测中的应用以及未来的发展三方面,探讨基于深度学习的语音端点检测技术。
一、深度学习原理深度学习是机器学习的一种,其核心是对人工神经网络的深度分析和应用。
神经网络中有各种各样的层(Layer),每一层派生出的特征都是在前一层的基础上进行的。
由于每一层都有一定的非线性变换,因此在深层次上,神经网络可以对数据进行更复杂的抽象表示。
此外,深度学习还适用于处理大规模数据和高复杂度任务。
基于深度学习的语音端点检测技术也采用了人工神经网络作为处理的基本模型。
为了实现自动化特征提取和分类,采用了多层原子去混淆(Multiple layer atom separation method,MLASM)特征表示方法。
MLASM采用了层次化的思路,通过对各层原始语音特征进行滤波和下采样,最终生成具有高可区分度和抗干扰性的特征。
二、语音端点检测中的应用语音端点检测是指从音频信号中判断出语音的起始和终止时刻。
它是语音信号处理中的一个非常重要的问题,对于语音识别等领域的应用拥有着广泛的影响。
与此同时,语音端点检测技术的研究也得到了广泛的关注。
基于深度学习的语音端点检测技术在各方面的性能上都优于传统的方法。
首先,基于深度学习的方法具有更好的鲁棒性,例如对于语音信号的噪声环境进行检测时,传统的方法可能会出现误检情况,而基于深度学习的方法则不会受到这种干扰。
其次,基于深度学习的方法具有更好的准确性,可以更自然地判断音频信号的边界。
语音信号端点检测方法研究

是变时的 ,所以.实际计算的是短时频带方差 ,它
的实质 就是 计算 某一 帧信 号 的各 频带 能量 之 间 的方
测翻 。由于采集声音信号的最初的短时段为无语音 段 ,仅有均匀分布的噪声信号 ,因此可 以用 已知为 “ 静态”的最初几帧 ( 一般为 1 O帧)信号计算过零
i( ) 1, ) , o , )L,( } (
Z = i I , c2 f 】 T mn【 z+  ̄z , F c 其 中, 为经验值 ,一般取 2 ; c 尼 分别为根 5 z和 c 据所取最初 l 0帧样值算得的过零率的 “ 均值”和
其中的分量 ( ) 定义为 中心频率为 的滤波器的 输出能量 。它可以根据一帧信号通过一带通滤波器
摘
要: 介绍 了语音信 号的 3种端点检测方法 ,即能量过零率检 测方法、基 于频 带方差 的检测方法和
语 音 短 时信 息 熵检 测 方 法 ,并 对 3种 方 法 的优 缺 点 进 行 分析 。
关键 词 : 音 识 别 ; 点检 测 ; 音 信 号 处 理 语 端 语 中图 分 类 号 : N923 T 1. 4 文献 标 志 码 : A
来计算 ,也可以计算一帧信号的 F ,然后把某几 兀’
个频率分组组合而得。对于数字信号 ,最低频是 0 ,
最 高 频是 1 7 , 余 各 中心频 率 按 一 定 规 则 从 0到 n 。其
递增 。
收稿 日期 :0 8 0 — 5 修 回 日期 :0 8 0 — 6 20 — 8 1 ; 2 0 — 9 1
作 者简 介 : 志 霞 ( 9 9 , , 张 1 7 一)女 山西 原 平 人 。 20 年 9月就 06
噪声背景下语音端点检测方法的研究

噪声背景下语音端点检测方法的研究摘要:在实际环境中,并没有完全纯净的语音信号,一段语音信号往往都伴有噪声信号,所以研究在背景噪声环境中的语音端点检测更为重要。
常用的短时过零率法、短时能量法以及双门限法都存在着一个共同的问题,即对信噪比要求较高。
为了解决这一问题我们提出了一改进算法,即基于谱减法思想的语音端点检测的方法,有效的提高检测的正确率。
关键词:端点检测噪声短时能量短时过零率谱减法1、引言语音端点检测是指用计算机数字处理技术来找出语音信号中的字或词等的起点和终点这俩个端点。
作为语音识别的前端,准确的端点检测可以提高识别的准确率。
语音端点检测的困难在于一段信号中的无声段或者录制一段语音段的前后人为呼吸等产生的杂音、语音开始处的弱摩擦音或弱爆破音以及终点处的鼻音,这些使得语音的端点需要综合利用语音的各种信号特征,从而确保定位的精确性,避免包含噪音信号和丢失语音信号。
常用语音端点检测法有短时过零率法、短时能量法以及双门限法。
但是对于信噪比要求较高,所以本文提出了一种基于谱减法思想的语音端点检测算法,提高语音端点检测的正确率。
2、语音端点检测方法常用方法中的短时能量法,语音和噪声的区别可以体现在它们的能量上,语音段的能量与噪声段能量相比,要大于噪声段的能量,因此可以以此为依据进行检测;短时过零率法,短时过零率可以区别语音是清音还是浊音[1,2],因此它可以从背景噪声中找出语音信号;传统双门限比较法,首先为短时能量和过零率分别确定两个门限,较低的门限对信号的变化比较敏感,较高的门限是用来确定进入语音段。
当低门限被超过时,未必是语音的开始而很有可能是由很小的噪声所引起的波动,但当高门限被超过并且在接下来的时间段内一直超过低门限时,则意味着语音信号的开始[3]。
但是上述三种方法在低信噪比时检测效果就不是很理想了。
因此我们提出了一种改进算法。
3、基于谱减法思想的语音端点检测算法的研究3.1 谱减法概述由于语音生成模型是低速率语音编码的基础,当语音受到噪声干扰时,提取的模型参数将很不准确,重建的语音质量急剧恶化。
语音端点检测方法探析
【 关键词 】复 杂噪声环境 语音端点检测 方法
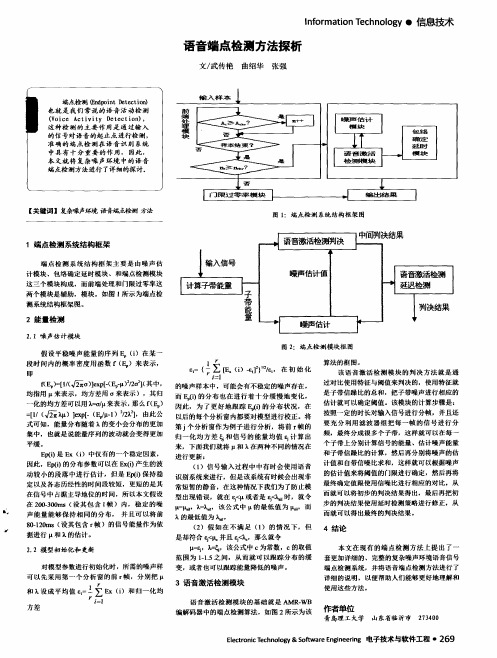
1端点检测系统结构框架
端 点检 测系 统结 构框 架主 要是 由 噪声估
—
- 一 语 音 激 活 喇 决
J L
哭 箔 果
吾音激活检测
计模块 、包 络确 定延时模块、和端点检测模块 这三个模块 构成 ,而前端处理和 门限过零率这 两个模块是辅助 ,模块 。如图 l 所示为端点检
均指用 来表示 ,均方差用 。来表 示 ),其 归 化 的均 方差可 以用 p来表示 , 那么 f ( )
估计就可 以确定阈值 。该模块的计算步骤是 : 要充 分利 用滤波 器 组把每 一帧 的信 号进 行分 频,最终分成很多个子带 ,这样就可 以在每一
个子带上分别计算信号的能量、估计噪声能量 和子带信躁 比的计算 ,然后再分别将噪声 的估 计值和 自带信噪 比求和,这样就可 以根据噪声
=
【 l , ( √
) ] e x p [ 一 ( E / | l ・ 1 ) 2 / 2 ,由 此公 以后的每个分析 窗内都要对 模型进行校正 。将 按照一定的时长对输入信号进行分帧 ,并且还
式可 知,能量分布随着 的变小会分布 的更加 集 中,也就是说能量序列的波动就会变得 更加 平缓 。 E p ( i ) 是E x( i )中仅有 的一个 稳定因素,
即
图2 :端点检测模 块框图
s 。 = ( 1 善 r i ) - £ I 】 2 } , 在 初 始 化
而E 订的分 布也 在进 行着十 分缓慢 地变 化,
因此 ,为 了更好 地跟踪 E n ( i ) 的分布 状况 ,在 第i 个分 析窗作 为例子进 行分析 ,将 前 r 帧的 归一 化均 方差 和信 号 的能量 均值 £ i 计算 出 来 ,下面我们就将 } l 和 在两种不同的情况在
端点检测方法的研究

黑龙江 李野 姬红旭 张磊 张晓雪
引 言
线性预测倒谱 系数( L P C C ) 、 梅尔频率倒谱系数( M F C C ) E 。
3 . 1线性预测 系数 线性 预测分 析是从 发生机理人手 , 全极点数字滤 波器是 线性预测分 析
在 采用 某些设 备对 语音 信号进 行采 集 时有可 能 出现语 音段 已经 结
束, 仍 然会 出现不希 望被采集到 的语 音片段 , 或者在 两段声音信号 之间出 现一段 空 白时 间, 此时 , 人们就希 望可 以通过某些 方法判断 出语音 信号的 起始点 , 即必须对语音信号进行端点检测 。
I s g n [ x ( Ⅲ ) 卜s g n [ x ( 一 1 ) 】 l
‘ …
¨, 、
,
误差为公式f 1 — 5 ) 所示 。
( ) ( ) 一 ( 月 ) ( " ) 一 a  ̄ s ( n — f ) ( 1 — 5 )
短 时过零率可 以粗略估计语音 的频谱特性 。通 过对语音产生 模型 的 分析 可知 , 低频率与低过零率相 对应 , 高频率与高过零率相对应 。
垦垦 垦塾 一 ! ! . ! 。 ! ! . ! ! . ! ! 一 . ! 一 . 。 … 。
端点检测方法的研究
摘 要: 在语音信号前端 处理技 术 中, 端点检测是一项十 分重要 的技术 。端 点检 测的 目的是在 有噪声的情 况
下找到语音信号 的起始 点和终止点 , 为后 续的语音信号研 究奠 定良好 的基础 。但是 由于噪声的存在 , 仅仅从 波形
本科毕业论文-—语音端点检测算法的研究及matla程序仿真与实现

摘要摘要语音端点检测是指从一段语音信号中准确的找出语音信号的起始点和结束点,它的目的是为了使有效的语音信号和无用的噪声信号得以分离,因此在语音识别、语音增强、语音编码、回声抵消等系统中得到广泛应用。
目前端点检测方法大体上可以分成两类,一类是基于阈值的方法,该方法根据语音信号和噪声信号的不同特征,提取每一段语音信号的特征,然后把这些特征值与设定的阈值进行比较,从而达到语音端点检测的目的,该方法原理简单,运算方便,所以被人们广泛使用,本文主要对基于阀值的方法进行研究。
另一类方法是基于模式识别的方法,需要估计语音信号和噪声信号的模型参数来进行检测。
由于基于模式识别的方法自身复杂度高,运算量大,因此很难被人们应用到实时语音信号系统中去。
端点检测在语音信号处理中占有十分重要的地位,直接影响着系统的性能。
本文首先对语音信号进行简单的时域分析,其次利用短时能量和过零率算法、倒谱算法、谱熵算法进行语音端点检测,并对这几种算法进行端点检测,并进行实验分析。
本文首先分别用各算法对原始语音信号进行端点检测,并对各算法检测结果进行分析和比较。
其次再对语音信号加噪,对不同信噪比值进行端点检测,分析比较各算法在不同信噪比下的端点检测结果,实验结果表明谱熵算法语音端点检测结果比其他两种方法好。
关键词语音端点检测;语音信号处理;短时能量和过零率;倒谱;谱熵IAbstractEndpoint detection is a voice signal from the accurate speech signal to the identify start and the end points, the purpose is to enable to separated the effective voice signals and un-useful noise. So, in the speech recognition system, speech enhancement, speech coding, echo cancellation and other systems are widely used.In Current the endpoint detection can be roughly divided into two categories, one is based on the threshold method based on the different characteristics of speech signal and the noise signals, a voice signal for each extracted feature, and then set the values of these thresholds compare with the values to achieve the endpoint detection purposes, This method is simple, it convenient operation, it is widely used, the main in this paper is based on the method of threshold method. Another method is based on the method of pattern recognition , it needs to estimate the speech signal and the noise signal model parameters were detected. Because is based on the method of pattern recognition and high self-complexity, a large amount of computation, so it is difficult to be use in real-time voice signal system for people.The Endpoint detection is take a very important position in the speech recognition, it directly affects the performance of the system. In this article first domain analysis in simple speech signal time, than dual threshold algorithm, cepstrum algorithm, spectral entropy algorithm for endpoint detection, and these types of endpoint detection algorithms, and experimental analysis points. Firstly, the algorithm were used to the original speech signal detection, and the algorithm to analyze and compare results. Secondly, the speech signal and then adding noise, SNR values for different endpoint detection, analysis and comparison of various algorithms under different SNR endpoint detection results, experimental results show that the spectral entropy of speech endpoint detectionIIalgorithm results better than the other two methods.Keywords voice activity detection;Signal processing; Average energy use of short-term and short-time average zero-crossing rat; cepstrum; spectral entropyIII毕业设计(论文)原创性声明和使用授权说明原创性声明本人郑重承诺:所呈交的毕业设计(论文),是我个人在指导教师的指导下进行的研究工作及取得的成果。
一种改进的语音信号端点检测方法研究

一种改进的语音信号端点检测方法研究摘要:在语音识别系统中端点检测有误差会降低系统的识别率,进行有效准确的端点检测是语音识别的重要步骤。
当信噪比较低时,传统的端点检测方法不能有效的工作。
为了提高系统的识别率,本文提出了一种更有效的端点检测算法,基于LPC美尔倒谱特征的端点检测方法。
它是基于倒谱特征方法的一种改进。
实验证明,该算法在低信噪比的情况下,能够准确的检测出语音信号的端点。
通过对三种不同的端点检测算法的比较,证明了基于LPC美尔倒谱特征算法在低信噪比的情况下有较高的检测正确率。
关键词:端点检测;语音识别;Mel倒谱距离;LPC美尔倒谱系数引言语音端点检测是语音识别中一个重要的步骤,进行有效的端点检测能够对语音信号更好的进行分析和训练,这样语音识别才能有好的识别率。
所以进行有效的端点检测是语音信号处理中首先要解决的问题。
传统的端点检测算法口如利用过零率、短时能量和自相关参数,在高信噪比环境下可以获得较好的检测效果,但在低信噪比环境下其检测性能却急剧下降。
当语音信号包含有背景噪音时,从中检测出语音信号的起始点和终止点,可以减少数据的采集量,删除不含语音信号的背景噪声和无声段,从而降低特征提取的计算量和处理时间,提高语音识别的准确性。
因此噪声环境中准确的检测语音起止位置有利于提高语音系统性能。
当语音中含有噪音时,传统的端点检测方法显得有些无能为力。
针对这种情况,提出了基于LPC美尔倒谱特征的端点检测算法。
它是对倒谱特征算法的一种改进。
1 基于倒谱特征的端点检测方法在大多数的语音识别系统中,选用倒谱特征参数作为语音信号的特征参数能够提高语音识别系统的性能。
因此用倒谱系数作为端点检测的参数。
信号倒谱可以看成是信号能量谱密度函数s( )的对数的傅立叶级数展开。
定义如下:(3)式中:Cn 和Cn′分别为对应于谱密度函数S(w)和S′(w)的倒谱系数。
对数谱的均方距离可以表示两个信号谱的区别,故它可以作为一个判决参数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
语音端点检测方法研究1沈红丽,曾毓敏,李平,王鹏南京师范大学物理科学与技术学院,南京(210097)E-mail:orange.2009@摘要: 端点检测是语音识别中的一个重要环节。
有效的端点检测技术不仅能减少系统的处理时间,增强系统处理的实时性,而且能排除无声段的噪声干扰,增强后续过程的识别性。
可以说,语音信号的端点检测至今天为止仍是有待进一步深入的研究课题.鉴于此,本文介绍了语音端点算法的基本研究现状,接着讨论并比较了语音信号端点检测的方法,分析了各种方法的原理及优缺点,如经典的基于短时能量和过零率的检测方法,基于频带方差的检测方法,基于熵的检测方法,基于倒谱距离的检测方法等.并基于这些方法的分析,对端点检测方法做了进行了总结和展望,对语音信号的端点检测的进一步研究具有深远的意义。
关键词:语音信号;端点检测;噪声中图分类号:TP206. 11. 引言语音信号处理中的端点检测技术,是指从包含语音的一段信号中确定出语音信号的起始点及结束点。
语音信号的端点检测是进行其它语音信号处理(如语音识别、讲话人识别等)重要且关键的第一步. 研究表明[1],即使在安静的环境中,语音识别系统一半以上的识别错误来自端点检测器。
因此,作为语音识别系统的第一步,端点检测的关键性不容忽视,尤其是噪声环境下语音的端点检测,它的准确性很大程度上直接影响着后续的工作能否有效进行。
确定语音信号的起止点, 从而减小语音信号处理过程中的计算量, 是众多语音信号处理领域中一个基本而且重要的问题。
有效的端点检测技术不仅能减少系统的处理时间,增强系统处理的实时性,而且能排除无声段的噪声干扰,增强后续过程的识别性。
可以说,语音信号的端点检测至今天为止仍是有待进一步深入的研究课题。
2. 语音端点检测主要方法和分析在很长一段时间里,语音端点检测算法主要是依据语音信号的时域特性[2].其采用的主要参数有短时能量、短时平均过零率等,即通常说的基于能量的端点检测方法。
这些算法在实验室环境下具有良好的性能,但在噪声环境下,则无法达到其应有的效果。
近年来,随着通信业的迅猛发展,又出现了很多的语音端点检测算法。
它们主要是通过采用各种新的特征参数,以提高算法的抗噪声性能。
如基于倒谱系数[3]、频带方差[4]、自相关相似距离[5] 、信息熵[6]等也逐渐的被应用到端点检测中。
有时,还通过将信号的几种特征组合成为一个新的特征参数来进行端点检测。
2.1基于短时能量和短时平均过零率的检测方法该方法也称为双门限比较法,它是在短时能量检测方法的基础上,加上短时平均过零率,利用能量和过零率作为特征来进行检测.在信噪比不是很低的情况下,根据语音信号的能量大于噪声噪声能量的假设,通过比较输入信号的能量与语音能量阈值的大小,可以对语音段和非语音段加以区分[7].输入每帧信号的能量可由下式得到[7-8]:1本课题得到江苏省普通高校自然科学研究计划资助项目(项目批准号:07KJD510110)的资助。
120()N j i E x i −==∑ (1)式中, j E 表示第j 帧的能量, ()x i 为输入的信号, N 为帧长.如果第j 帧信号的短时信号能量j E 大于设定的阈值,就判断当前帧为语音帧,否则判为静音帧.短时过零率的计算可由下式得到:[8]1|sgn[()]sgn[(1)]|Nn n Z x n x n ==−−∑ (2)1,()0sgn[()]1,()0x n x n x n ≥⎧=⎨−<⎩ (3). 语音端点检测方法可采用测试信号的短时能量或短时对数能量、联合过零率等特征参数,并采用双门限判定法来检测语音端点,即利用过零率检测清音,用短时能量检测浊音,两者配合。
首先为短时能量和过零率分别确定两个门限,一个是较低的门限数值较小,对信号的变化比较敏感,很容易超过;另一个是比较高的门限,数值较大。
低门限被超过未必是语音的开始,有可能是很短的噪声引起的,高门限被超过并且接下来的自定义时间段内的语音超过低门限,意味着信号开始。
研究显示[9],清音的过零率较高,浊音和噪声次之,而且浊音和噪声的过零率相当。
因此这种方法对语音信号中的浊音和噪声很难区分,因此在检测时同样会漏掉某些音素[10]。
2.2基于频带方差的检测方法由于系统是时变的,所以实际计算的是短时频带方差,它的实质就是计算某一帧信号的各频带能量之间的方差.频带方差检测法的具体过程如下:定义一个矢量: 023{(),(),(),.....,()}n X x x x x ωωωω=,其中的分量()n x ω定义为中心频率为n ω的滤波器的输出能量,它可以根据一帧信号通过一个带通滤波器来计算,也可以首先计算一帧信号的FFT,然后把某几个频率分量组合而成..定义均值: 111()N ii E x N ω−==∑ (4) 则频带方差为: 1211[()]N ii D x E N ω−==−∑ (5) 式中, ()i x ω是每一帧语音信号FFT 频谱值.从以上计算股市可以看出,频带方差相当于”交流能量”,它包含了2个信息:各频带间的起伏程度和这一帧信号的短时能量.能量越大起伏越激烈,D 值就越大,这正是语音的特点;反之,对于噪声,能量越小,起伏越平缓,D 值越小.因此,完全可以利用短时频带方差来判断语音的起止点.在基于短时能量和过零率端点检测方法中,由于清音和噪声段的能量很相近,造成了一些错误的划分.而采用频带方差法,对于频谱分布比较均匀的噪声,如白噪声,其频谱方差就比较小,而对于清音和浊音,其频带方差都比噪声段大,因此可以更好地检测出语音段.2.3基于熵的检测方法在信息论中,Shanon 为了定量度量信息量,引入了熵的概念。
对于一个随机事件,设它有N 个可能的结局,,2,1......,N S S S ,每一个结局出现的概率分别是,,2,1......,N P P P 为了度量这一随机事件含有不确定性,Shannon 引入了熵函数[11][12]。
))((log )(12∑=−=Ni i i S P S P k H (6)其中,k 是大于零的恒量,一般取k =1,而10≺≺i P 。
且当i P =0时,有:0))((log *)(2=i i S P S P ,∑=iiS P 1)( (7) 根据信息熵的定义,把它用到语音中,用来构造一个语音信息熵函数,以判断语音和噪声。
当把语音帧的标准化幅度谱)(i X 看作一个概率分布时,谱域的熵计算可以用取第i 个幅度谱的概率来代替取第i 个信源符号的概率)(i S P ,即用∑=i i X i X i X P 222)()())((来表示[13]。
那么,语音谱的熵可以表示如下:))((log *))((222i X P i X P H i ∑−= (8)相对于背景噪声而言,语音信号中的语音段幅度的动态范围比较大,因此直观地说,可以认为语音段在信号在中的随机事件多,故平均信息量大,也就是熵值大。
而静音段的幅度变化小,分布相对集中,因而熵值小。
谱熵分布是在语音静音检测算法中有应用前途的特征量。
实验证明,当背景噪声为非平稳噪声或机器噪声时,基于熵的语音活动性检测算法比基于其他特征量的算法更可靠。
这种算法对噪声强度变化并不敏感,而只对噪声谱自然特性的变化敏感。
2.4基于倒谱的检测方法倒谱能很好表示语音的特征[14] ,在强噪声环境下,常常采用倒谱系数来作为端点检测的特征量。
信号的复倒谱定义为信号的能量谱密度函数()S ω的对数的傅里叶级数,log ()S ω的傅里叶级数展开式为[14],log ()()jn N S c n eωω∞−=−∞=∑ (9) 式中,()()c n c n =−为实数,通常称为倒谱系数,且 1(0)log ()2c S d ππωωπ−=∫ (10) 对于一对谱密度函数()S ω与'()S ω ,根据 Parseval 定理,用谱的倒谱距离表示对数谱的均方距离[15]为: 22''1|log ()log ()|()2cep n n n d S S d c c ππωωωπ∞−=−∞=−=−∑∫ (11) 式中,n c 与'n c 分别表示谱密度()S ω和'()S ω的倒谱系数。
对数谱的均方距离表示两个信号谱之间的差别,故可以用来作为判决门限。
实际上,由于0c 包含信号能量信息,基于能量的端点检测可以看作倒谱距离的一个特例。
倒谱距离的测量法步骤类似于基于能量的端点检测,但是将倒谱距离代替短时能量来作为门限。
首先,假设前几帧倒谱矢量的平均值可以估计背景噪声的倒谱矢量,对于非平稳噪声,为了使判决门限适应噪声的变化,在噪声帧应对估计的噪声倒谱系数进行更新,采用平滑的方法[16],更新的原则是:(1)t c pc p c =+− (12) 式中,c 为噪声帧倒谱矢量的近似值,t c 为当前测试帧的倒谱矢量,p 为更新因子。
式(3)表示的倒谱距离可以利用式(5) 可以近似如下[14]:'cep d = (13) 式中'n c 为对应于c 的噪声倒谱系数,计算所有测试帧与背景噪声之间的倒谱距离可以得到倒谱距离轨迹。
事实上,这一方法类似于基于能量的端点检测过程,利用倒谱距离轨迹可以检测语音的端点。
然而当信号存在严重失真时会给端点检测带来困难,难以选择适当的门限。
实验发现[16],倒谱特征参数的语音信号端点检测方法在噪声环境下具有传统的能量方法无法比拟的优越性。
2. 5 其他方法除了以上几种方法之外,还有基于小波方差,小波系数方差,各种综合参数和应用模型匹配的方法。
模型匹配的方法主要是对带噪语音和纯噪声信号分别建立统计模型.根据检测到的某些特征量分别计算出在带噪语音模型和纯噪声模型条件下的概率,最后通过对这两个不同概率的比较做出最后的有声和无声判决.比如基于HMM 模型的检测方法[18],是语音信号端点检测中的重要方法,该方法先用训练的方法生成背景噪声和废料的模型参数,再用Viterbi 解码算法对待测信号进行分解,求出语音的哪些语音帧与背景噪声相匹配,哪些与废料相匹配,从而得出端点所在处。
实验表明[17],这种方法的准确率明显高于基于能量的方法。
但是HMM 的训练环境通常与实际被测信号的语音环境会有很大的差异,即背景噪声模型与实际情况不符合,此时性能会显著下降。
3. 研究方法总结与展望随着越来越多的学者对语音端点检测技术的关注,大量的新的语音端点检测算法相继被提出。
通过大量的文献调研与实际研究发现,现有的各种语音信号端点检测技术都存在各自的不足。
对于语音信号在低信噪比时的端点检测的研究有待进一步深入研究。
根据语音信号的特点可以从两个大的方向入手。
一个是努力寻求新的特征参数,另一个是利用现有的特征参数进行多特征融合。