java读写xml文件的方法
xml基本写法和dtdschema的用法,JAVA读写XML

xml基本写法和dtdschema的⽤法,JAVA读写XML1. 标记语⾔ 标记语⾔,是⼀种⽂本(Text)以及⽂本相关的其他信息结合起来,展现出关于⽂档结构和数据处理细节的电脑⽂字编码.当今⼴泛使⽤的标记语⾔是超⽂本标记语⾔(Hyper Text Markup Language,HTML)和可扩展标记语⾔(eXtensible Markup Language,XML). 标记语⾔⼴泛应⽤于⽹页和⽹络应⽤程序.1) 超⽂本标记语⾔HTML(Hyper Text Markup Language)写法格式: <a href="link.html">link</a>关注数据的展⽰与⽤户体验标记是固定的,不可扩展(如<a></a>表⽰超连接)2) 可扩展的标记语⾔XML(eXtensible Markup Language)写法格式:同html样式<a>link</a>仅关注数据本⾝标记可扩展,可⾃定义3) Xml 和 Html语⾔由同⼀种⽗语⾔SGML(Standard Generalized Markup language,标准通⽤标记语⾔)发展出来.4)解析器专业解析器(⽐如:XML SPY 专⽤于解析XML⽂件)浏览器MyEclipse5)W3C(World Wide Web Consortium)W3C:开源的语⾔协会,万维⽹联盟(World Wide Web Consortium)HTML 和 XML 都是W3C制定的语⾔规则官⽹:学习⽹站:2.xml语法规则2.1 xml的声明:xml的声明必须写在⽂件第⼀⾏Encoding(字符集)属性可以省略,默认的字符集是utf-8例⼦:1<?xml version="1.0" encoding="UTF-8"?>2<书>3<武侠⼩说 isbn="1001">4<书名>天龙⼋部</书名>5<作者>⾦庸</作者>6<价格>50</价格>7<简介>⼀本好书</简介>8</武侠⼩说>9<计算机>10<书名>疯狂java</书名>11<作者>李刚</作者>12<价格>50</价格>13<简介>⼀本好书</简介>14</计算机>15</书>常见错误写法:1) "?"和xml之间不能有空格2) 声明必须顶头写,不能有空⾏或空格(⽤FireFox浏览器打开)3) 等号左右不要多写空格(java程序员的习惯)浏览器不会报错,但是在xml解析时会出问题2.2 标记1)诸如<书名></书名>,这样格式的被称为标记2)标记必须成对出现3)标记包含开始标记和结束标记<书名>天龙⼋部</书名>注意:标记⼤⼩写敏感2.3元素(Element)1) 元素: 元素= 标记 + 其中内容 ,如<书名>天龙⼋部</书名>2) 根元素: 最外层的元素 (如 <书></书>)3) 叶⼦元素: 最⾥层(没有⼦元素的)的元素 (如,<书名></书名>,<价格></价格>)4) 空元素: 没有内容的元素叫空元素,⽐如:<a></a> ,<br></br>,可以简写为<a/> <br/>5) 元素必须遵循的语法规则a. 所有的标记都必须有结束b.开始标记和结束标记必须成对出现c.元素必须正确嵌套<a><b>c</b></a> (正确)<a><b>c</a></b> (错误)d.标记的⼤⼩写敏感Hello 和 hello不是同⼀个标记e.有且只能有⼀个根元素2.4 实体引⽤(转义字符)1) ⼩于号(<) : less then --> <2) ⼤于号(>) : great than --> >3) And符号(&) : &4) 双引号 ( ") : "5) 单引号( ') : '注意这些转义字符都是以&开头,以 ; 结尾例如:想给天龙⼋部加上书名号<<天龙⼋部>><?xml version="1.0" encoding="UTF-8"?><书><武侠⼩说 isbn="1001"><书名><<天龙⼋部>></书名><作者>⾦庸</作者><价格>50</价格><简介>⼀本好书</简介></武侠⼩说></书>2.5属性(定义在开始标记中的键值对)1)格式: 属性="属性值"如<武侠⼩说 isbn="1234"></武侠⼩说>isbn是武侠⼩说的属性,值是12342)要求:属性必须有值属性值必须⽤引号引起来,单引号或双引号都可以,但必须⼀致2.6 CDATA 类型的数据:特殊标签1) 格式: <![CDATA[⽂本内容]]>2) 特殊标签中的实体引⽤都被忽略,所有内容被当成⼀整块⽂本数据对待例如<书><武侠⼩说 isbn="1235" lang="zh"><书名 hot="true">笑笑江湖</书名><作者>⾦庸</作者><价格>45</价格><简介><![CDATA[⼀本好书,没有<<笑傲江湖>>好看]]></简介></武侠⼩说></书>2.8 注释(xml和html相同)1)格式: <!-- 这是⼀段注释 -->2) 编译器将忽略注释3) Html和xml注释⽅式相同例⼦:1<?xml version="1.0" encoding="UTF-8"?>2<书>3<!-- 这是⼀段注释 -->4<武侠⼩说 isbn="1001">5<书名><<天龙⼋部>></书名>6<作者>⾦庸</作者>7<价格>50</价格>8<简介>⼀本好书</简介>9</武侠⼩说>10</书>2.8 规则⼩结1) 必须有唯⼀的根元素2) xml标记⼤⼩写敏感3) 标记必须配对出现,有开始有结束4) 元素必须被正确嵌套5) 属性必须有值,值必须⽤引号引起来6) 如果遵循全部上述规则,称作well-formed⽂件(格式良好的xml⽂件) 2.9 使⽤XML⽂件描述数据的例⼦1) 早期属性⽂件描述数据的⽅式url = jdbd:oracle:thin@192.168.0.205:1521:dbsiddbUser = openlabdbPwd = open1232) 现在使⽤xml表⽰⽅式<?xml version="1.0" encoding="UTF-8"?><书><!-- 这是⼀段注释 --><武侠⼩说 isbn="1001"><书名><<天龙⼋部>></书名><作者>⾦庸</作者><价格>50</价格><简介>⼀本好书</简介></武侠⼩说></书>3. DTD/Schema1) DTD/Schema:⽤来规范XML的标记规则2)有效的xml⽂件(valid xml file) = 格式良好的xml⽂件 + 有DTD或Schema规则 + 遵循DTD或Schema规则3.1 DTD/Schema的作⽤⾏业交换数据时要求xml⽂件格式相同,所以需要⼤家遵守规范的xml⽂件格式,⽐如两份xml⽂件要有相同的元素嵌套关系,相同的属性定义,相同的元素顺序,元素出现相同次数等3.2⽂档类型定义DTD(Document Type Difinition)1) DTD⽂档⽤来定义XML⽂件的格式,约束XML⽂件中的标记规则2) DTD类型PUBLIC(⾏业共⽤的)SYSTEM(⼩范围⾃定义的)3.2.1 DTD中的定义规则必须列出所有节点,⼀个都不能少1)元素"*"星号表⽰可以出现0-n次"+"加号表⽰可以出现1-n次"|" 表⽰或(只能出现⼀个)如(phone|mobile)表⽰固话或⼿机⼆选⼀"?"问号: 表⽰出现0或1此#PCDATA 表⽰字符串2)属性:定义在开始标记中的键值对dtd 规则_属性1) <!ATTLIST 标记名称属性名称属性类型>2) isbn CDATA #REQUIRED: 表⽰isbn属性是必须的3) isbn CDATA #IMPLIED: 表⽰isbn属性不是必须的4) hot CDATA"false" :表⽰hot默认值是false例⼦3.2.1⾸先是dtd⽂件book.dtd<!ELEMENT 书 (武侠⼩说, br)*><!ELEMENT 武侠⼩说 (书名,作者+,价格,简介)><!ELEMENT 书名 (#PCDATA)><!ELEMENT 作者 (#PCDATA)><!ELEMENT 价格 (#PCDATA)><!ELEMENT 简介 (#PCDATA)><!ELEMENT br EMPTY><!ATTLIST 武侠⼩说 isbn CDATA #REQUIREDlang CDATA #IMPLIED><!ATTLIST 书名 hot CDATA #IMPLIED>在XML中使⽤<?xml version="1.0"?><!DOCTYPE 书 SYSTEM "book.dtd"><书><武侠⼩说 isbn="1234" lang="zh"><书名 hot="false"><<天龙⼋部>></书名><作者>⾦庸</作者><作者>古龙</作者><价格>45</价格><简介>⼀本好书</简介></武侠⼩说><br></br><武侠⼩说 isbn="1235" lang="zh"><书名 hot="true">笑笑江湖</书名><作者>⾦庸</作者><价格>45</价格><简介><!-- 这是⼀段注释 --><![CDATA[⼀本好书,没有<<笑傲江湖>>好看CDATA中的所有特殊字符都不解释(原样显⽰)]]></简介></武侠⼩说><br></br></书>3.3 Schema ,DTD的升级版与DTD的区别1)命名空间(NameSpace)XML⽂件允许⾃定义标记,所以可能出现来⾃不同源DTD或Schema⽂件的同名标记,为了区分这些标记,就需要使⽤命名空间.命名空间的⽬的是有效的区分来⾃不同DTD的相同标记⽐如xml中⽂件中使⽤了命名空间区分开"表格"和"桌则":<html:table><line><column>这是⼀个表格</column></line></html;table><product:table><type>coff table</type><product:table>2) 因为DTD⽆法解决命名冲突,所以出现Schema,它是DTD 的替代者,dtd和Schema的功能都是描述xml结构的3) Schema使⽤xml语法实现(Schema本⾝就是xml⽂件)因为⽤于规范和描述xml⽂件的定义⽂件(schema)本⾝也是xml⽂件,所也xml也被称为⾃描述的语⾔4) Schema ⽂件的扩展名xds: XML Schema Difinition(简称XSD,遵循W3C标准)5) Schema中的名词:复杂元素(有⼦元素的元素)简单元素(叶⼦元素)例⼦:email.xsd<?xml version="1.0" encoding="UTF-8"?><schema xmlns="/2001/XMLSchema" targetNamespace="/email" xmlns:tns="/email" elementFormDefault="qualified"> <element name="email"><complexType><sequence><element name="from" type="string"/><element name="to" type="string"/><element name="subject" type="string"/><element name="body" type="string"/></sequence></complexType></element></schema>被规范的⽂件email.xml<?xml version="1.0" encoding="UTF-8"?><tns:email xmlns:tns="/email" xmlns:xsi="/2001/XMLSchema-instance" xsi:schemaLocation="/email email.xsd "><tns:from>赵敏</tns:from><tns:to>张⽆忌</tns:to><tns:subject>HIHI</tns:subject><tns:body>看泰坦尼克号</tns:body></tns:email>3.4 根据DTD或者Schema来写xml⽂件的⽅法在MyEclipse中右键New --> xml (Basic Templates) -->输⼊⽂件名-->next-->选择是DTD还是Schema4. java API 解析XML⽂件(读xml⽂件)1) Java 与xml有很多共同点(⽐如跨平台,与⼚商⽆关),⽬前位置java对xml的解析较其他语⾔更完善2) 两种解析⽅式:DOM(Document Object Model ⽂档对象模型)关键字:树(Document)优点: 把xml⽂件在内存中构造树形结构,可以遍历和修改节点缺点: 如果⽂件⽐较⼤,内存有压⼒,解析的时间会⽐较长SAX(Simple API for Xml基于XML的简单API)关键字:流(Stream)把xml⽂件作为输⼊流,触发标记开始,内容开始,标记结束等动作优点:解析可以⽴即开始,速度快,没有内存压⼒缺点:不能对节点做修改3) JDOM/DOM4J : ⽬前市场上常⽤的两种解析XML⽂件的API dom4j-1.6.1.jar 结合了DOM和SAX两种解析⽅式的优点DOM4j解析xml⽂件步骤1) 创建项⽬XMLDemo2) 加⼊dom4j的jar包(dom4j-1.6-1.jar)3) 将要解析的xml⽂件放在路径src/下4) 新建ReadXMLDemo.java4-1)构造document对象SAXReader reader = new SAXReader();Document doc = reader.read(file);4-2)取根元素:Element root = doc.getRootElement();4-3)常⽤⽅法Element elmt;elmt.elements("标记名称"):取出所有指定标记名称的元素elmt.element("标记名称"):取出第⼀个指定标记名称元素elmt.elementText("标记名称"):取elmt指定名字的⼦元素elmt.getText();取当前元素的内容Iterator it = elmt.elementsIterator("标记名称") 返回⼀个Iterator String 属性值 = elmt.attattributeValue("属性名")例⼦:ReadBookdemo源代码package day1;import java.io.*;import java.util.*;import org.dom4j.*;import org.dom4j.io.*;/*** 读⼊book.xml⽂件,取出数据并打印* @author soft01**/public class ReadBookdemo {public static void main(String[] args) {readBook("book.xml");}/*** 读⼊指定的xml⽂件,取出数据并打印* @param string*/private static void readBook(String filename) {//1..读⼊指定的⽂件,构造Document对象File file = new File(filename);SAXReader reader = new SAXReader();//XML⽂件解析器try {Document doc = reader.read(file);//解析器开始解析xml⽂件//2.获得根元素Element root = doc.getRootElement();//3.递归搜索⼦元素/* List<Element> list = root.elements("武侠⼩说");//迭代武侠⼩说的元素集合Iterator<Element> it = list.iterator(); */Iterator<Element> it = root.elementIterator("武侠⼩说");while(it.hasNext()){Element bookElmt = it.next(); //bookEmlt是武侠⼩说元素//取武侠⼩说的⼦元素System.out.println(bookElmt.elementText("书名"));//取⼦元素书名的内容 List<Element> authorList = bookElmt.elements("作者");for (Element element : authorList) {//打印作者元素内容System.out.println(element.getText());}System.out.println(bookElmt.elementText("价格"));System.out.println(bookElmt.elementText("简介"));//取武侠⼩说的属性String isbnValue = bookElmt.attributeValue("isbn");//取武侠⼩说的 lang元素String langValue = bookElmt.attributeValue("lang");System.out.println("isbn="+isbnValue);System.out.println("lang="+langValue);//取⼦元素中的属性Element nameElmt = bookElmt.element("书名");System.out.println(nameElmt.attributeValue("hot"));System.out.println("-----------------");}} catch (DocumentException e) {e.printStackTrace();}}}book.xml如下<?xml version="1.0"?><书><武侠⼩说 isbn="1234" lang="zh"><书名 hot="false"><<天龙⼋部>></书名><作者>⾦庸</作者><作者>古龙</作者><价格>45</价格><简介>⼀本好书</简介></武侠⼩说><br></br><武侠⼩说 isbn="1235" lang="zh"><书名 hot="true">笑笑江湖</书名><作者>⾦庸</作者><价格>45</价格><简介><!-- 这是⼀段注释 --><![CDATA[⼀本好书,没有<<笑傲江湖>>好看CDATA中的所有特殊字符都不解释(原样显⽰)]]></简介></武侠⼩说><br></br></书>5 DOM4j API解析XML⽂件(⽣成)1)常⽤API⽅法:给元素增加⼦元素: elmt.addElement("标记名称");给元素增加属性: elmt.addAttribute("属性名","属性值");给叶⼦元素设值: elmt.setText("元素值");例如:要⽣成以下xml⽂件<book isbn="1001" catalog = "科幻"><name>阿⾥波特</name><author>罗林</author><price>60</price><year>2005</year></book>步骤:1.构造空的Document2.构造根元素3.递归构造⼦元素4.输出WriteBookDemo源代码package day1;import java.io.*;import org.dom4j.*;import org.dom4j.io.*;/*** 利⽤DOM4J写出xml⽂件* @author soft01**/public class WriteBookDemo {static String [][] data={{"1001", "科幻", "阿⾥波特", "罗林","60", "2005","en"},{"1002", "迷幻", "⼩波特", "罗4林","60", "2005","zh"},{"1003", "⽞幻", "中波特", "罗3林","60", "2005","en"},{"1004", "奇幻", "⼤波特", "罗2林","60", "2005","zh"}};public static void main(String[] args) {writeBook("mybook.xml");}/*** 把书的数据⽣成到指定名字的xml⽂件中* @param filename*/public static void writeBook(String filename){// 1.构造空的DocumentDocument doc = DocumentHelper.createDocument();// 2.构造根元素Element rootElmt = doc.addElement("booklist");// 3.递归构造⼦元素for(String[] book:data){Element bookElmt = rootElmt.addElement("book");//book 元素增加属性bookElmt.addAttribute("isbn", book[0]);bookElmt.addAttribute("catalog", book[1]);Element nameElmt = bookElmt.addElement("name");nameElmt.setText(book[2]);//给name 加属性nameElmt.addAttribute("lang", book[6]);Element authorElmt = bookElmt.addElement("author");authorElmt.setText(book[3]);Element priceElmt = bookElmt.addElement("price");priceElmt.setText(book[4]);Element yearElmt = bookElmt.addElement("year");yearElmt.setText(book[5]);}// 4.输出outputXml(doc,filename);}public static void outputXml(Document doc,String filename){try {//定义输出流的⽬的地FileWriter fw = new FileWriter(filename);//定义输出格式和字符集OutputFormat format = OutputFormat.createPrettyPrint();format.setEncoding("UTF-8");//定义⽤于输出xml⽂件的XMLWriter对象XMLWriter xmlWriter = new XMLWriter(fw,format);xmlWriter.write(doc);xmlWriter.close();} catch (IOException e) {e.printStackTrace();}}}注意:运⾏程序⽣成的mybooks.xmlpackage day1;不⾃动装载,需要刷新⼀下程序运⾏通过后,在项⽬上点击右键"refreash"(或F5)如果是从别的⼯作区导⼊的项⽬,需要去别的⼯作区⽬录下找⽣成的XML⽂件6XPath(w3c的标准)1) XPath:在XML⽂件中查找或定位信息的语⾔,相当于SQL中的 selectXPath 可以通过元素/属性/值来定位或导航2) 节点(Node):相当于xml⽂件中的元素3) 指定条件定位元素的⽅式例⼦:package day1;import java.io.*;import java.util.*;import org.dom4j.*;import org.dom4j.io.*;/*** 测试XPath的功能* @author soft01**/public class XPathDemo {public static void main(String[] args) {findBook("mybook.xml");}public static void findBook(String filename){SAXReader reader = new SAXReader();try {//获得⽂档对象Document doc = reader.read(new File(filename));Node node =doc.selectSingleNode("/booklist");//查找所有的catalog="奇幻"的书2//String sql = "book[@catalog ='奇幻']";//价格>50的书//String sql = "book[price>50]";//作者等于罗林的书,并且价格⼤于50//String sql ="book[author='罗林' and price>50]";//价格⼤于50,且语⾔是zhString sql = "book[price>50 and name[@lang='zh']]"; List<Element> books = node.selectNodes(sql);for(Element e:books){System.out.println(e.getStringValue());}} catch (DocumentException e) {e.printStackTrace();}}}。
java读取xml文件内容
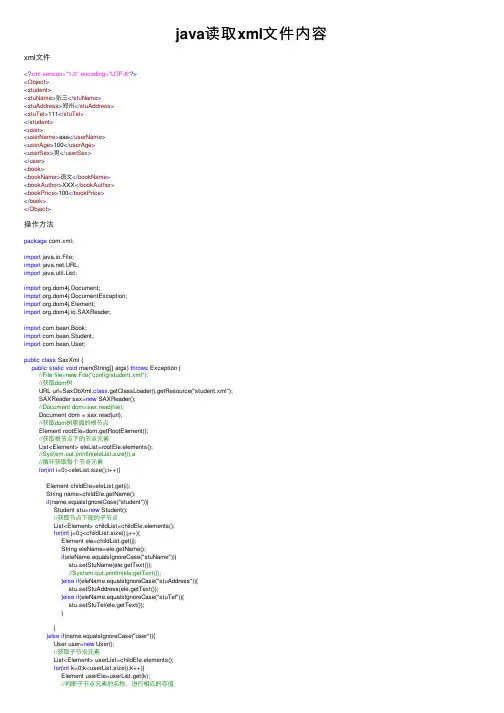
java读取xml⽂件内容xml⽂件<?xml version="1.0" encoding="UTF-8"?><Object><student><stuName>张三</stuName><stuAddress>郑州</stuAddress><stuTel>111</stuTel></student><user><userName>aaa</userName><userAge>100</userAge><userSex>男</userSex></user><book><bookName>语⽂</bookName><bookAuthor>XXX</bookAuthor><bookPrice>100</bookPrice></book></Object>操作⽅法package com.xml;import java.io.File;import .URL;import java.util.List;import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.io.SAXReader;import com.bean.Book;import com.bean.Student;import er;public class SaxXml {public static void main(String[] args) throws Exception {//File file=new File("config/student.xml");//获取dom树URL url=SaxDbXml.class.getClassLoader().getResource("student.xml");SAXReader sax=new SAXReader();//Document dom=sax.read(file);Document dom = sax.read(url);//获取dom树⾥⾯的根节点Element rootEle=dom.getRootElement();//获取根节点下的节点元素List<Element> eleList=rootEle.elements();//System.out.println(eleList.size());a//循环获取每个节点元素for(int i=0;i<eleList.size();i++){Element childEle=eleList.get(i);String name=childEle.getName();if(name.equalsIgnoreCase("student")){Student stu=new Student();//获取节点下⾯的⼦节点List<Element> childList=childEle.elements();for(int j=0;j<childList.size();j++){Element ele=childList.get(j);String eleName=ele.getName();if(eleName.equalsIgnoreCase("stuName")){stu.setStuName(ele.getText());//System.out.println(ele.getText());}else if(eleName.equalsIgnoreCase("stuAddress")){stu.setStuAddress(ele.getText());}else if(eleName.equalsIgnoreCase("stuTel")){stu.setStuTel(ele.getText());}}}else if(name.equalsIgnoreCase("user")){User user=new User();//获取⼦节点元素List<Element> userList=childEle.elements();for(int k=0;k<userList.size();k++){Element userEle=userList.get(k);//判断⼦节点元素的名称,进⾏相应的存值if(userEle.getName().equalsIgnoreCase("userName")){user.setUserName(userEle.getText());}else if(userEle.getName().equalsIgnoreCase("userSex")){ user.setUserSex(userEle.getText());}else if(userEle.getName().equalsIgnoreCase("userAge")){ user.setUserAge(userEle.getText());}}}else if(name.equalsIgnoreCase("book")){Book book=new Book();List<Element> bookList=childEle.elements();for(int k=0;k<bookList.size();k++){Element bookEle=bookList.get(k);String eleName=bookEle.getName();if(eleName.equalsIgnoreCase("bookName")){book.setBookName(bookEle.getText());}else if(eleName.equalsIgnoreCase("bookAuthor")){book.setBookAuthor(bookEle.getText());}else if(eleName.equalsIgnoreCase("bookPrice")){book.setBookPrice(bookEle.getText());}}}}}}。
java实现利用String类的简单方法读取xml文件中某个标签中的内容

java实现利⽤String类的简单⽅法读取xml⽂件中某个标签中的内容1、利⽤String类提供的indexOf()和substring()快速的获得某个⽂件中的特定内容public static void main(String[] args) {// 测试某个词出现的位置String reqMessage = "<?xml version=\"1.0\" encoding=\"ISO-8859-1\"?>" + "<in>" + "<head>" + "<Version>1.0.1</Version>"+ "<InstId>100000000000032</InstId>" + "<AnsTranCode>BJCEBQBIReq</AnsTranCode>" + "<TrmSeqNum>2012082008200931036344</TrmSeqNum>" + "</head>" + "</in>";int indexbegin = reqMessage.indexOf("<TrmSeqNum>");int indexend = reqMessage.indexOf("</TrmSeqNum>");System.out.println("<TrmSeqNum>的位置===" + indexbegin);System.out.println("</TrmSeqNum>的位置===" + indexend);System.out.println(reqMessage.substring(indexbegin + 11, indexend)); // 11是<TrmSeqNum>这个字符串的长度}以上这篇java实现利⽤String类的简单⽅法读取xml⽂件中某个标签中的内容就是⼩编分享给⼤家的全部内容了,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
JAVA写xml文件

JAVA写xml文件随着计算机技术的飞速发展,需要在程序中存储和管理大量的信息,并用众多的语言和工具进行交互。
为了解决这个问题,以及为不同的程序语言提供一致的格式来实现数据交换,XML(超文本标记语言)应运而生,并在软件开发中得到广泛运用。
XML用来描述数据的一种文本语言,它可以存储比如用户及其信息,设置,排列,及其他数据的内容。
XML在许多计算机程序中被广泛使用,它可以被用来传递数据,或者以XML标记格式存储信息。
尽管XML可以使用任何编程语言来解析,但是其最常见的用法是使用Java来写。
接下来我们就使用Java来写XML文件,具体步骤如下:第一步:准备好XML文件所需要的相关信息。
第二步:导入Java标准包(javax.xml.parsers.*)。
第三步:实例化DocumentBuilderFactory。
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();第四步:使用builderFactory来实例化DocumentBuilder。
DocumentBuilder builder =builderFactory.newDocumentBuilder();第五步:使用DocumentBuilder来创建文档并且添加元素。
Document document = builder.newDocument();Element rootElement = document.createElement(rootdocument.appendChild(rootElement);第六步:添加属性并写入XML文件。
Element nameElement = document.createElement(amenameElement.setTextContent(EarthrootElement.appendChild(nameElement);Element sizeElement = document.createElement(sizesizeElement.setTextContent(largerootElement.appendChild(sizeElement);TransformerFactory transformerFactory = TransformerFactory.newInstance();Transformer transformer =transformerFactory.newTransformer();DOMSource source = new DOMSource(document);StreamResult result = new StreamResult(newFile(file.xml);transformer.transform(source, result);以上是Java写入XML文件的实例,从上面可以看出JAVA语言是一种非常强大的程序语言,它结合XML技术,可以用来实现大量复杂的数据存储和交互。
读写XML的四种方法

读写XML的四种方法XML(eXtensible Markup Language)是一种用于表示和传输数据的标记语言。
它具有良好的可读性和扩展性,被广泛应用于Web开发、数据交换和配置文件等领域。
在读写和处理XML数据时,有许多方法可供选择。
本文将介绍四种常见的读写XML的方法:DOM、SAX、JDOM、和XMLStreamReader/XMLStreamWriter。
1. DOM(Document Object Model):DOM是一种基于树形结构的解析器,它将整个XML文档加载到内存中,并将其表示为一个对象树。
在DOM中,每个XML元素都被表示为一个节点(Node),可以通过节点的属性和方法对其进行操作。
读取XML文档时,可以使用DOM解析器将其转换为一个DOM树,然后通过节点的方法访问和修改树结构。
写入XML文档时,可以通过创建和修改节点来构建DOM树,并使用DOM解析器将其保存为XML文档。
使用DOM读取XML文档的基本步骤如下:- 创建一个DocumentBuilderFactory对象。
- 根据DocumentBuilderFactory对象创建一个DocumentBuilder对象。
- 使用DocumentBuilder对象解析XML文档,并返回一个Document对象。
- 通过Document对象的方法遍历和操作XML文档的节点。
使用DOM写入XML文档的基本步骤如下:- 创建一个DocumentBuilderFactory对象。
- 根据DocumentBuilderFactory对象创建一个DocumentBuilder对象。
- 使用DocumentBuilder对象创建一个Document对象。
- 通过Document对象的方法创建和添加元素节点、属性节点等。
- 使用TransformerFactory和Transformer对象将Document对象保存为XML文档。
DOM的优点是易于使用和理解,可以方便地遍历和修改XML文档。
java 通过浏览器读取客户端文件的方法

java 通过浏览器读取客户端文件的方法Java通过浏览器读取客户端文件的方法介绍在Web开发中,经常需要从浏览器读取客户端文件,Java提供了多种方法来实现这一功能。
本文将详细介绍几种常用的方法。
方法一:使用HTML表单上传文件1.在HTML中,使用<input type="file">元素创建一个文件上传表单。
2.在Java中,使用HttpServletRequest对象的getPart方法获取上传的文件。
3.使用Part对象的getInputStream方法获取文件的输入流,进而读取文件的内容。
方法二:使用Apache Commons FileUpload库1.引入Apache Commons FileUpload库的依赖。
2.在Java中,使用ServletFileUpload类解析上传的文件。
3.使用FileItem类获取文件的输入流,进而读取文件的内容。
方法三:使用Spring MVC框架的MultipartResolver1.在Spring MVC配置文件中配置MultipartResolver,例如使用CommonsMultipartResolver。
2.在Java中,使用MultipartFile对象获取上传的文件。
3.使用MultipartFile对象的getInputStream方法获取文件的输入流,进而读取文件的内容。
方法四:使用Servlet的InputStream获取请求体1.在Java中,使用HttpServletRequest对象的getInputStream方法获取请求体的输入流。
2.使用输入流读取请求体的内容。
3.根据请求体的格式解析文件的内容,例如使用multipart/form-data格式。
方法五:使用WebSocket传输文件1.在Java中,使用WebSocket处理客户端的请求。
2.在WebSocket中,使用ByteBuffer对象接收和发送文件的内容。
java 调用返回xml文件 实例
一、介绍在Java编程中,经常会碰到需要调用返回XML文件的情况。
XML (可扩展标记语言)是一种包含标签数据的文本格式,常用于数据交换和存储。
本文将通过实例演示在Java中如何调用返回XML文件的过程,以帮助读者更好地理解和应用相关知识。
二、准备工作在进行实例演示之前,我们需要做一些准备工作:1. 确保已安装Java开发工具包(JDK),并配置好环境变量。
2. 准备一个返回XML文件的API接口或全球信息湾,以便进行调用和获取数据。
三、示例代码下面是一个简单的Java程序,演示了如何调用返回XML文件的过程:```javaimport java.io.BufferedReader;import java.io.InputStreamReader;import .HttpURLConnection;import .URL;public class XMLParser {public static void main(String[] args) {try {// 创建URL对象URL url = new URL("");// 打开连接HttpURLConnection connection = (HttpURLConnection)url.openConnection();// 设置请求方法connection.setRequestMethod("GET");// 读取返回数据BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream()));String line;StringBuffer response = new StringBuffer();while ((line = reader.readLine()) != null) {response.append(line);}reader.close();// 输出XML数据System.out.println(response.toString());} catch (Exception e) {e.printStackTrace();}}}```在这段示例代码中,我们首先创建了一个URL对象,指定了需要调用的返回XML文件的位置区域。
java mybatis 读取xml的方法
java mybatis 读取xml的方法在使用Java开发中,Mybatis是一个强大的ORM框架,能够帮助我们简化操作数据库的过程。
在Mybatis中,我们可以使用xml文件来定义SQL语句,然后通过Java代码来读取这些xml文件。
要读取Mybatis的xml文件,我们首先需要配置Mybatis的环境和数据源。
这可以通过在代码中使用Mybatis的Configuration类来实现。
接着,我们需要创建一个SqlSessionFactory对象,该对象可以通过SqlSessionFactoryBuilder类的实例来构建。
然后,我们可以通过SqlSessionFactory对象来创建一个SqlSession,SqlSession 是Mybatis提供的一个用于执行SQL操作的接口。
一旦我们获取了SqlSession对象,我们就可以通过它来执行数据库的操作。
在执行查询操作时,我们可以使用SqlSession的selectOne或selectList方法,这些方法可以接受一个SQL语句的ID作为参数,从而读取对应的xml文件中定义的SQL 语句。
例如:```javaSqlSession sqlSession = sqlSessionFactory.openSession();List<User> userList =sqlSession.selectList("erMapper.findAllUsers");```在上面的代码中,我们通过SqlSession的selectList方法读取了名为"findAllUsers"的SQL语句。
这个SQL语句对应于一个xml文件中的标签。
返回的结果是一个包含用户信息的列表。
除了查询操作之外,我们还可以通过SqlSession执行插入、更新和删除等操作。
同样地,我们可以在xml文件中定义相应的SQL语句来执行这些操作。
读取xml的五种方法
124 * @throws SAXException */
125 public void endElement(String namespaceURI, String localName,String qName) throws SAXException{
28 System.exit(1);
29 }
30 //获得根节点StuInfo
31 Element elmtStuInfo = doc.getDocumentElement();
32 //得到所有student节点
33 NodeList nlStudent = elmtStuInfo.getElementsByTagNameNS(
23 } catch (DOMException dom) {
24Message());
25 System.exit(1);
26 } catch (IOException ioe) {
27 System.err.println(ioe);
在java环境下读取xml文件的方法主要有5种:DOM、SAX、JDOM、JAXB、dom4j
最常用、最好用的dom4j
1. DOM(Document Object Model)
此 方法主要由W3C提供,它将xml文件全部读入内存中,然后将各个元素组成一棵数据树,以便快速的访问各个节点 。 因此非常消耗系统性能 ,对比较大的文档不适宜采用DOM方法来解析。 DOM API 直接沿袭了 XML 规范。每个结点都可以扩展的基于 Node 的接口,就多态性的观点来讲,它是优秀的,但是在 Java 语言中的应用不方便,并且可读性不强。
java hultool xmlutil用法
java hultool xmlutil用法在Java中,Hutool是一个轻量级的Java工具库,提供了丰富的工具方法和简化开发的功能。
其中,Hutool的XmlUtil类提供了操作XML的方法。
XmlUtil提供了以下一些常用的方法:1. `format(XmlStr)`:格式化XML字符串,将XML字符串进行缩进和换行处理,使其更易读。
2. `parseXml(XmlStr)`:解析XML字符串,将XML字符串解析为Document对象。
可以通过Document对象进行对XML的操作。
3. `getByXPath(Node, xPath)`:通过XPath表达式获取符合条件的节点列表,返回的是一个NodeList对象,可以通过遍历NodeList 获取具体的节点。
4. `elementText(Element, tagName)`:获取指定标签名的节点的文本内容。
5. `addElement(Element, tagName, text)`:在指定的Element节点下面添加新的子节点,可以设置子节点的标签名和文本内容。
6. `removeElement(Element, tagName)`:移除指定标签名的子节点。
除了上述的方法,XmlUtil还提供了其他一些方法来完成对XML的操作,比如添加属性、设置属性值、移除属性等。
同时,Hutool的XmlUtil还提供了对XML和Java Bean之间的转换功能,例如`BeanUtil.xmlToBean()`和`BeanUtil.beanToXml()`方法,可以方便地将XML转换为Java对象,以及将Java对象转换为XML。
需要注意的是,Hutool的XmlUtil对于大型的XML文件可能不适用,它更适用于处理小型的XML文件或者XML数据的简单操作。
对于大型的XML文件,最好使用更高效的XML处理库,如JAXP、DOM4J或者XStream等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
在java环境下读取xml文件的方法主要有4种:DOM、SAX、JDOM、JAXB1. DOM(Document Object Model)此方法主要由W3C提供,它将xml文件全部读入内存中,然后将各个元素组成一棵数据树,以便快速的访问各个节点。
因此非常消耗系统性能,对比较大的文档不适宜采用DOM方法来解析。
DOM API 直接沿袭了 XML 规范。
每个结点都可以扩展的基于 Node 的接口,就多态性的观点来讲,它是优秀的,但是在Java 语言中的应用不方便,并且可读性不强。
实例:Java代码1.import javax.xml.parsers.*;2.//XML解析器接口3.import org.w3c.dom.*;4.//XML的DOM实现5.import org.apache.crimson.tree.XmlDocument;6.//写XML文件要用到7.DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();8. //允许名字空间9. factory.setNamespaceAware(true);10. //允许验证11. factory.setValidating(true);12. //获得DocumentBuilder的一个实例13.try {14. DocumentBuilder builder = factory.newDocumentBuilder();15.} catch (ParserConfigurationException pce) {16.System.err.println(pce);17.// 出异常时输出异常信息,然后退出,下同18.System.exit(1);19.}20.//解析文档,并获得一个Document实例。
21.try {22.Document doc = builder.parse(fileURI);23.} catch (DOMException dom) {24.System.err.println(dom.getMessage());25.System.exit(1);26.} catch (IOException ioe) {27.System.err.println(ioe);28.System.exit(1);29.}30.//获得根节点StuInfo31.Element elmtStuInfo = doc.getDocumentElement();32.//得到所有student节点33. NodeList nlStudent = elmtStuInfo.getElementsByTagNameNS(34. strNamespace, "student");35.for (……){36. //当前student节点元素37. Element elmtStudent = (Element)nlStudent.item(i);38. NodeList nlCurrent = elmtStudent.getElementsByTagNameNS(39. strNamespace, "name");40.}对于读取得方法其实是很简单的,写入xml文件也是一样不复杂。
Java代码1.DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();2.DocumentBuilder builder = null;3.try {4.builder = factory .newDocumentBuilder();5.} catch (ParserConfigurationException pce) {6.System.err.println(pce);7.System.exit(1);8.}9.Document doc = null;10.doc = builder .newDocument();11.//下面是建立XML文档内容的过程,12.//先建立根元素"学生花名册"13.Element root = doc.createElement("学生花名册");14.//根元素添加上文档15.doc.appendChild(root);16.//建立"学生"元素,添加到根元素17.Element student = doc.createElement("学生");18.student.setAttribute("性别", studentBean.getSex());19.root.appendChild(student);20.//建立"姓名"元素,添加到学生下面,下同21.Element name = doc.createElement("姓名");22.student.appendChild(name);23.Text tName = doc.createTextNode(studentBean.getName());.appendChild(tName);25.Element age = doc.createElement("年龄");26.student.appendChild(age);27.Text tAge = doc.createTextNode(String.valueOf(studentBean.getAge()));28.age.appendChild(tAge);2.SAX (Simple API for XML)此方法主要由XML-DEV 邮件列表的成员开发的,SAX是基于事件的方法,它很类似于标签库的处理机制,在标签开始、结束以及错误发生等等地方调用相应的接口实现方法,不是全部文档都读入内存。
SAX具有优异的性能和利用更少的存储空间特点。
SAX 的设计只考虑了功能的强大性,却没有考虑程序员使用起来是否方便。
使用必须扩展ContentHandler、ErrorHandler、DTDHandler等,但是必须扩展ContentHandler(或者DefaultHandler )。
Java代码1.import org.xml.sax.*;2.public class MyContentHandler implements ContentHandler {3.……4.}5./**6. * 当其他某一个调用事件发生时,先调用此方法来在文档中定位。
7. * @param locator8. */9. public void setDocumentLocator(Locator locator){10. }11./**12. * 在解析整个文档开始时调用13. * @throws SAXException14. */15. public void startDocument() throws SAXException{16. System.out.println("** Student information start **");17. }18./**19. * 在解析整个文档结束时调用20. * @throws SAXException21. */22. public void endDocument() throws SAXException{23. System.out.println("**** Student information end ****");24. }25./**26. * 在解析名字空间开始时调用27. * @param prefix28. * @param uri29. * @throws SAXException30. */31. public void startPrefixMapping(String prefix32. , String uri) throws SAXException{33. }34./**35. * 在解析名字空间结束时调用36. * @param prefix37. * @throws SAXException38. */39. public void endPrefixMapping(String prefix) throws SAXException{40. }41./**42. * 在解析元素开始时调用43. * @param namespaceURI44. * @param localName45. * @param qName46. * @param atts47. * @throws SAXException48. */49. public void startElement(String namespaceURI, String localName50. , String qName, Attributes atts) throws SAXException{51. }52./** 在解析元素结束时调用53. * @param namespaceURI54. * @param localName 本地名,如student55. * @param qName 原始名,如LIT:student56. * @throws SAXException */57. public void endElement(String namespaceURI, String localName,String qName) throws SAXException{58. if (localName.equals(“student”)){59. System.out.println(localName+":"+currentData);60. }61.}取得元素数据的方法——characters取得元素数据中的空白的方法——ignorableWhitespace在解析到处理指令时调用的方法——processingInstruction当未验证解析器忽略实体时调用的方法——skippedEntity运行时,只需要使用下列代码:Java代码1.MySAXParser mySAXParser = new MySAXParser();2.mySAXParser.parserXMLFile("SutInfo.xml");3.JDOMJDOM的处理方式有些类似于DOM,但它主要是用SAX实现的。