归档日志异常增长处理方法
归档日志空间满

归档⽇志空间满和 ORA-03113 解决今天有⼀个⽤户因为归档⽇志空间满,造成数据库宕机。
在alert⾥⾯会看到类似下⾯的内容:1. ORA-19815: 警告: db_recovery_file_dest_size 字节 (共 4294967296 字节) 已使⽤ 100.00%, 尚有 0 字节可⽤。
2. ************************************************************************3. You have following choices to free up space from recovery area:4. Consider changing RMAN RETENTION POLICY. If you are using Data Guard,5. then consider changing RMAN ARCHIVELOG DELETION POLICY.6. Back up files to tertiary device such as tape using RMAN7. BACKUP RECOVERY AREA command.8. Add disk space and increase db_recovery_file_dest_size parameter to9. reflect the new space.10. Delete unnecessary files using RMAN DELETE command. If an operating11. system command was used to delete files, then use RMAN CROSSCHECK and12. DELETE EXPIRED commands这时,如果只是把快速恢复区的归档⽇志删除,启动数据库会报错ORA-03113⽅法之⼀,按照上⾯第8条的提⽰,增加db_recovery_file_dest_size需要把数据库启动到mount状态sql>startup mountsql>system set db_recovery_file_dest_size=8192m题外话:出现这个问题的原因是开启归档⽇志,⽽快速恢复区(Flash Recovery Area)默认安装的时候⼀般只有4096M,所以很容易就满,按照Oracle的建议,⼀般这个区域的⼤⼩是数据库⽂件⼤⼩总和的两倍,所以建议⼤⼩都设置⼤⼀些。
ORACLE数据库归档日志满后造成系统宕机的处理方法

第一次宕机时,初始以为是系统内存溢出,于是重启应用服务器,发现应用服务器在启动时报错,错误为无法连接到数据库。
于是连接数据库服务器,打开EM后发现系统报错如图:提示归档日志写入失败,检查服务器发现磁盘空间满了,于是清理磁盘空间后,重启数据库问题解决。
随后把服务器磁盘空间扩容,直接给了oracle数据所在盘1TB的磁盘空间。
第二次又出现此问题,经过仔细检查,并与同事确认后,发现是由于ORACLE数据库的归档日志被启用了,而我们系统默认是没有启用ORACLE数据库归档日志这个功能的。
使用sql命令查看:Sql>sqlplus / as nolog;---------------------启动sql*PlusSql> connect sys/password@orcl as sysdba;Sql> archive log list;数据库日志模式存档模式自动存档启用存档终点USE_DB_RECOVERY_FILE_DEST最早的联机日志序列4888下一个存档日志序列4890当前日志序列4890Sql> show parameter db_recovery_file_dest;NAME TYPE VALUE------------------------------------ ----------- ------------------------------db_recovery_file_dest string D:\oracle\product\10.2.0/flash_recovery_area db_recovery_file_dest_size big integer 20G发现默认的归档路径为D:\oracle\product\10.2.0/flash_recovery_area。
而且限制使用空间为20G。
由于每天产生的oracle归档日志差不多就占用2个G的磁盘空间,而且oracle自身并不会自动清理也没有相关设置自动清理归档日志的功能,一段时间不进行清理,20G空间很快就满了。
归档日志满、硬盘满、表空间满的空间不够处理方法

归档日志满、硬盘满、表空间满的空间不够处理方法一、归档日志满,清理归档日志方法 (2)二、硬盘存储空间充足,但数据库表空间不足的扩容方法 (3)三、硬盘存储空间不足,对硬盘进行扩容或增加 (4)四、暂不能增加磁盘,但磁盘已满的处理方法 (6)一、归档日志满,清理归档日志方法archive log 日志已满ORA-00257: archiver error. Connect internal only, until freed 错误的处理方法1. 用sys用户登录sqlplus sys/pass@tt as sysdba2. 看看archiv log所在位置SQL> show parameter log_archive_dest;NAME TY PE VALUE------------------------------------ ----------- ------------------------------ log_archive_dest stringlog_archive_dest_1 stringlog_archive_dest_10 string3. 一般VALUE为空时,可以用archive log list;检查一下归档目录和log sequence SQL> archive log list;Database log mode Archive ModeAutomatic archival EnabledArchive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 360Next log sequence to archive 360Current log sequence 3624. 检查flash recovery area的使用情况,可以看见archivelog已经很大了,达到96.62 SQL> select * from V$FLASH_RECOVERY_AREA_USAGE;FILE_TYPE PERCENT_SPACE_USEDPERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES------------ ------------------ ------------------------- --------------- CONTROLFILE .13 0 1ONLINELOG 2.93 0 3ARCHIVELOG 96.62 0 1415. 计算flash recovery area已经占用的空间SQL> select sum(percent_space_used)*3/100 from v$flash_recovery_area_usage;SUM(PERCENT_SPACE_USED)*3/100-----------------------------2.99046. 找到recovery目录, show parameter recoverSQL> show parameter recover;NAME TYPE VALUE--------------------------- ----------- ------------------------------db_recovery_file_dest string /u01/app/oracle/flash_recovery_areadb_recovery_file_dest_size big integer 5Grecovery_parallelism integer 07 上述结果告诉我们,归档位置用的是默认值,放在flash_recovery_area下(db_recovery_file_dest目录=/u01/app/oracle/flash_recovery_area)[*************.0]#echo$ORACLE_BASE/u01/app/oracle [root@sha3 10.2.0]# cd $ORACLE_BASE/flash_recovery_area/tt/archivelog转移或清除对应的归档日志, 删除一些不用的日期目录的文件,注意保留最后几个文件(比如360以后的)8. 登陆rman准备删除归档日志,rman target sys/pass[root@sha3 oracle]# rman target sys/pass9. 检查一些无用的archivelogRMAN> crosscheck archivelog all;10. 删除过期的归档RMAN> delete expired archivelog all;删除7天前的归档:DELETE ARCHIVELOG ALL COMPLETED BEFORE 'SYSDATE-7';删除全部归档(noprompt不交互):DELETE noprompt ARCHIVELOG ALL COMPLETED BEFORE 'SYSDATE-0';删除从7天前到现在的全部日志:DELETE ARCHIVELOG FROM TIME 'SYSDATE-7';11. 再次查询,发现使用率正常,已经降到23.03SQL> select * from V$FLASH_RECOVERY_AREA7_USAGE;FILE_TYPE PERCENT_SPACE_USED PERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES 二、硬盘存储空间充足,但数据库表空间不足的扩容方法表空间使用情况查询:SELECT a.tablespace_name "表空间名",total/1024/1024/1024 || 'G' 表空间大小,free/1024/1024/1024 || 'G' 表空间剩余大小,(total - free)/1024/1024/1024 || 'G' 表空间使用大小,ROUND((total - free) / total, 4) * 100 "使用率 %"FROM (SELECT tablespace_name, SUM(bytes) freeFROM DBA_FREE_SPACEGROUP BY tablespace_name) a,(SELECT tablespace_name, SUM(bytes) totalFROM DBA_DATA_FILESGROUP BY tablespace_name) bWHERE a.tablespace_name = b.tablespace_name扩容语句,执行如下SQL:alter tablespace MSSCPMIS add datafile '/u02/app/oradata/orcl/msscpmis02.dbf' size 5720M alter tablespace MSSCPMIS add datafile '/u02/app/oradata/JSDBA/MSSCPMIS12.dbf' size 30720M alter tablespace MSSCPMIS add datafile '/u02/app/oradata/JSDBA/MSSCPMIS13.dbf' size 30720M alter tablespace MSSCPMIS add datafile '/u02/app/oradata/JSDBA/MSSCPMIS14.dbf' size 30720M alter tablespace MSSCPMIS add datafile '/u02/app/oradata/JSDBA/MSSCPMIS15.dbf' size 30720M 备注:也可以放在不同的硬盘上附录数据文件最大值上限跟数据块大小相关,数据块大小的默认值一般都是8KB。
数据库日志增长解决方法

数据库⽇志增长解决⽅法
数据库⽇志增长过快解决⽅法:
1: 删除LOG
1:分离数据库企业管理器->服务器->数据库->右键->分离数据库
2:删除LOG⽂件
3:附加数据库企业管理器->服务器->数据库->右键->附加数据库
此法⽣成新的LOG,⼤⼩只有500多K
再将此数据库设置⾃动收缩
或⽤代码:
下⾯的⽰例分离 pubs,然后将 pubs 中的⼀个⽂件附加到当前服务器。
EXEC sp_detach_db @dbname = 'pubs '
EXEC sp_attach_single_file_db @dbname = 'pubs ',
@physname = 'c:\Program Files\Microsoft SQL Server\MSSQL\Data\pubs.mdf '
2:清空⽇志
DUMP TRANSACTION 库名 WITH NO_LOG
再:
企业管理器--右键你要压缩的数据库--所有任务--收缩数据库--收缩⽂件--选择⽇志⽂件--在收缩⽅式⾥选择收缩⾄XXM,这⾥会给出⼀个允许收缩到的最⼩M数,直接输⼊这个数,确定就可以了
3: 果想以后不让它增长
企业管理器->服务器->数据库->属性->事务⽇志->将⽂件增长限制为2M
1、设置数据库为简单模式
--> 数据库的属性
--> “选项”页
--> “模型”选为“简单”
2、截断⽇志,收缩数据库
backup log 数据库名 with no_log
go
dbcc shrinkdatabase(数据库名)
go。
归档日志异常增长处理方法
案例描述:近日湖北运维反应湖北数据库归档日志生成过快,导致磁盘空间占满,引起数据库宕机。
问题看起来很简单,只要清理下归档日志然后重启就能解决,但这只是治标不治本的方法,显然是要找到归档日志增长异常频繁的原因。
最后通过LogMiner分析归档日志发现是运维部署了频繁update的语句,停了后归档日志变为正常.下面是详细步骤1.通过v$archived_log视图查看最近归档日志状态select to_char(COMPLETION_TIME,’yyyymmdd'), count(*)from v$archived_log twhere t。
COMPLETION_TIME 〉sysdate — 20group by to_char(COMPLETION_TIME,’yyyymmdd')order by to_char(COMPLETION_TIME, ’yyyymmdd');2.查看今天的归档日志情况,看到8点左右归档日志增长最大select to_char(FIRST_TIME,'yyyymmddhh24'), count(*)from sys。
v_$archived_log twhere t。
FIRST_TIME 〉 trunc(sysdate)group by to_char(FIRST_TIME,’yyyymmddhh24')order by to_char(FIRST_TIME,'yyyymmddhh24’)3.查看今天八点的归档日志的路径select name, COMPLETION_TIME, t.FIRST_TIME, t.RESETLOGS_TIME from sys.v_$archived_log twhere to_char(FIRST_TIME,’yyyymmddhh24') = 2015081108order by t.FIRST_TIME desc;4.打开toad,连接数据库,打开日志分析工具logminer(database→diagnose→logminer)5.点击next6.把第三步得到的归档日志的路径输入file to mine7。
归档日志满的解决办法

归档日志满的解决办法
1、适当增大日志目录大小:在文件系统范围内扩容,增加虚拟内存空间;
2、定期删除过期存档:删除归档了一段时间的日志文件。
很多时候,由于不知道日志文件的实际用处,往往采用保守策略,定期删除较早的,周期性的删除;
3、采用刷新覆盖的方式:日志文件非常庞大时可以采用这种方式;
4、采用日志归档工具:比如ELK(Elasticsearch、Logstash、Kibana)等日志归档工具,也可以方便,快捷的实现日志收集整理上报;
5、采用云服务进行日志管理:在云环境上直接安装日志管理工具,可以免去很多日志文件定期清理等负担,让日志收集、整理和分析更加高效便捷。
归档日志增长过快处理解决

处理归档日志增加过快一例(2010-08-25 20:03:47)转载▼标签:分类:原创文章oracle归档日志增加过快处理归档日志增加过快一例摘要本文介绍了不久前作者是如何彻底解决一家医院数据库由于归档日志增长过快,导致磁盘剩余空间占满,引起宕机全过程。
通过本案例的描述,我们可以了解到当遇到数据库宕机问题时,应该如何分析现象、找到问题关键、最终彻底解决该问题的一个总体思路,最后还应该深入思考该问题产生的原因,总结出避免以后再出现该问题的建议。
关键字: ORACLE、归档日志、宕机、DML语句初步了解早上一来到公司,XZH就告诉我接到CQ公司的有一个技术申请,大致情况为一家三甲医院,采用Rac+Linux环境,启用了归档模式,但是由于日志增长过快,我们的技术人员设虽然置自动删除归档的任务,但是还是没有避免磁盘空间被占满,已经引起医院2次全院无法使用,虽然CQ公司也安排多名技术人员去现场处理,但是医院认为一直没有解决彻底,因此信息主管对此意见较大,希望公司安排技术支持部现场彻底解决该问题。
通过申请描述,我大致了解到以下几个关键点:1.医院启用了归档,也做了定期自动删除归档日志的任务。
2.由于归档日志增加过快,已经导致医院2号节点宕机。
3.我们的技术人员去了几次,都未彻底解决,用户已经意见很大了。
这只是个初步情况,往往只能了解问题的大概,具体的问题产生的原因还是得到用户那里去才能真正了解,于是立即出发,前往用户处处理问题。
现场分析问题到达医院,同系统管理员互相寒暄了几句,了解大体情况是医院昨天凌晨部分科室反映不能登录导航台,于是系统管理员深夜被叫到医院,查看服务器发现数据库已经宕机,检查磁盘空间,发现其中一个节点的剩余空间为0,于是立即删除部分过去的归档日志,重新启动服务器,下面科室才能够正常登录,谈话间不断听见系统管理员抱怨深夜到医院是如何如何不情愿,看来意见是比较大。
而且同样的问题不久前才出现过一次,当时是中午,询问同去的同事,了解到确实不久前也出现过一次同样的情况,当时认为是归档日志的定期删除保留的日志时间太长,当时保留的是30天的日志,后来改为保留5天的日志,心想不会再出现该问题,没想到还是无法避免。
如何处理高压运维中的日志异常分析和排查

如何处理高压运维中的日志异常分析和排查在运维工作中,日志异常分析和排查是我们经常要面对的挑战之一。
当系统出现异常或故障时,日志记录着系统运行的各个细节,能够帮助我们快速定位问题和解决方案。
然而,在高压运维环境下,日志异常的数量庞大,可能需要花费大量时间和精力来分析和排查。
本文将介绍一些处理高压运维中日志异常的有效方法。
一、收集和整理日志在处理日志异常之前,首先需要收集和整理日志。
通常,运维团队需要配置日志收集系统,将各个服务器上的日志中心化管理。
这样一来,我们可以通过一个统一的界面来查看和搜索日志,极大地提高了处理效率。
在收集和整理日志的过程中,我们需要关注以下几个方面:1. 确保日志采集的全面性:所有关键的系统和组件都要包含在日志采集范围中,以便全面监控和分析。
2. 确认日志的准确性:检查日志记录的格式和内容,确保其准确性和完整性。
3. 创建合适的索引:在日志收集系统中创建适当的索引,以便快速搜索和过滤日志。
二、使用日志分析工具在高压运维环境下,手动分析大量的日志是一项耗时而复杂的任务。
因此,我们可以借助日志分析工具来加速分析过程,提高排查效率。
常用的日志分析工具包括但不限于:1. ELK Stack: 包括Elasticsearch、Logstash和Kibana,可以实现实时日志收集、存储和可视化分析。
2. Splunk: 提供丰富的搜索和可视化功能,可以帮助快速定位和处理日志异常。
这些工具可以帮助我们对日志数据进行搜索、过滤和可视化分析,使得排查工作更加高效和准确。
三、建立异常日志报警机制为了及时发现和响应日志异常,建立一个有效的日志报警机制至关重要。
我们可以通过以下方式来建立异常日志报警机制:1. 设定关键指标和阈值:根据业务需求和系统特点,设定异常指标和阈值,如异常日志数量超过某个阈值或者特定错误码的出现频率超过设定值。
2. 实时监控和报警:利用监控系统或日志分析工具,实时监控日志异常并发送报警通知。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
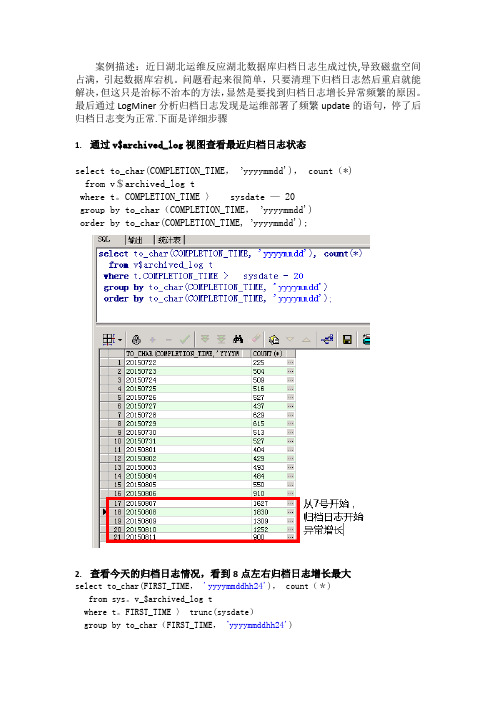
案例描述:近日湖北运维反应湖北数据库归档日志生成过快,导致磁盘空间占满,引起数据库宕机。
问题看起来很简单,只要清理下归档日志然后重启就能解决,但这只是治标不治本的方法,显然是要找到归档日志增长异常频繁的原因。
最后通过LogMiner分析归档日志发现是运维部署了频繁update的语句,停了后归档日志变为正常。
下面是详细步骤
1.通过v$archived_log视图查看最近归档日志状态
select to_char(COMPLETION_TIME, 'yyyymmdd'), count(*)
from v$archived_log t
where PLETION_TIME > sysdate - 20
group by to_char(COMPLETION_TIME, 'yyyymmdd')
order by to_char(COMPLETION_TIME, 'yyyymmdd');
2.查看今天的归档日志情况,看到8点左右归档日志增长最大
select to_char(FIRST_TIME, 'yyyymmddhh24'), count(*)
from sys.v_$archived_log t
where t.FIRST_TIME > trunc(sysdate)
group by to_char(FIRST_TIME, 'yyyymmddhh24')
order by to_char(FIRST_TIME, 'yyyymmddhh24')
3.查看今天八点的归档日志的路径
select name, COMPLETION_TIME, t.FIRST_TIME, t.RESETLOGS_TIME from sys.v_$archived_log t
where to_char(FIRST_TIME, 'yyyymmddhh24') = 2015081108
order by t.FIRST_TIME desc;
4.打开toad,连接数据库,打开日志分析工具logminer
(database→diagnose→logminer)
5.点击next
6.把第三步得到的归档日志的路径输入file to mine
7.点击运行图标,分析日志,得到sql语句。