电话拨号音的合成与识别
电话的原理是什么

电话的原理是什么
电话的原理是通过电信号传输声音信号。
当我们拨号时,声音信号会被麦克风转换为电信号,然后通过电话线路传输到接收端。
接收端的电话机会将电信号转换为声音信号,使得我们能够听到对方的声音。
电话的原理主要涉及到以下几个组成部分:
1. 麦克风:负责将声音转换为电信号。
当我们讲话时,声波通过麦克风的振动使得麦克风中的微小磁铁或电容器发生变化,进而产生电流。
2. 电路:在电话线路中,电流被传输到接收端。
电路负责传送电流,并保证电信号的质量不受损失。
3. 电话线路:电话信号通过有线电路传输。
电话线路连接发信方和收信方,使得声音信号能够传递。
4. 扬声器:接收端的电话机中的扬声器负责将电信号转换为声音信号。
电信号通过扬声器振动产生听得见的声音。
整个过程中,声音信号在发信方和收信方之间通过电话线路进行传输,并通过麦克风和扬声器的转换,使得通话双方能够沟通。
需要注意的是,现代电话系统多数使用数字信号传输,而不是传统的模拟信号。
数字信号通过将声音转换为二进制数据进行
传输,提高了通信质量和可靠性。
所以,当我们拨打电话时,声音信号被转换为数字信号后传输,然后在接收端再转换回声音信号。
简述语音合成和语音识别的基本原理

简述语音合成和语音识别的基本原理语音合成和语音识别是两个相互关联但又各自独立的技术领域,用于处理人类语音的生成和识别。
本文将简述语音合成和语音识别的基本原理。
语音合成(Text-to-Speech, TTS)是将文本转换为语音的技术,通过计算机自动生成自然流畅的语音。
语音合成的基本原理可以分为文本处理、音素转换和波形生成三个阶段。
首先,在文本处理阶段,输入的文本会经过分词、语法分析等处理流程,将文本转换为可理解的形式。
这一步骤有助于理解文本的词义和文法关系。
接下来,在音素转换阶段,文本会被转换为对应的音素序列。
音素是语音单元的最小单位,而不同的语言和发音习惯会对应不同的音素系统。
音素转换的目标是确定如何将文本中的单词和语音单位相对应,并生成相应的音素序列。
最后,在波形生成阶段,音素序列将被合成为语音波形。
这一步骤涉及到声音的合成、音调、语速等的参数控制,以及去除噪音、增加音色等信号处理技术。
生成的语音波形可以通过扬声器或其它音频输出设备播放出来。
语音合成的方法有多种,包括基于规则的方法,基于拼接的方法和基于统计的方法等。
基于规则的方法通过预设的语音规则和规则库进行合成;基于拼接的方法则是将大量录制的人类语音片段进行拼接;而基于统计的方法则是利用统计模型对大量语音数据进行建模,来实现合成。
语音识别(Automatic Speech Recognition, ASR)是将人类语音转换为电脑可理解的文本形式的技术,使计算机能够通过语音输入来理解和处理信息。
语音识别的基本原理可以分为信号的前端处理、声学模型、语言模型和解码器等步骤。
首先,在信号的前端处理阶段,会对人类语音信号进行特征提取。
这些特征可以是声谱图、梅尔频率倒谱系数等,在频率和时间上对语音信号进行切割和量化。
接下来,在声学模型阶段,将音频信号特征与对应的声学模型进行匹配。
声学模型可以是隐马尔可夫模型(HMM)或深度学习模型,用于将语音信号特征与音素序列进行对齐和建模。
拨号的原理讲解

拨号的原理讲解拨号的原理是一种用于电话通信的技术,通过拨打电话号码来建立通信连接。
它是电话通信的核心基础,也是现代通信技术的重要组成部分。
下面我将详细讲解拨号的原理。
拨号的原理主要包括以下几个步骤:录音、编码、传输、解码和呼叫建立。
首先是录音。
当我们拨打电话时,通过电话机的麦克风,我们的声音会被转换成电信号。
这些电信号包含了我们说话的声音信息。
接下来是编码。
录音得到的电信号需要经过编码处理,以便能够在传输过程中被有效传送和解码。
编码需要将声音信号转换成数字信号。
这个过程被称为“模拟到数字转换”(Analog-to-Digital Conversion,简称ADC)。
然后是传输。
编码完成后的数字信号将通过电话线路或其他通信媒介进行传输。
在传输过程中,数字信号会被转换成电信号,并通过电缆、光纤等媒介传输到目标终端。
接下来是解码。
接收端的终端设备会对传输过来的电信号进行解码处理,将其从数字信号转换为模拟信号。
这个过程一般称为“数字到模拟转换”(Digital-to-Analog Conversion,简称DAC)。
最后是呼叫建立。
一旦被拨打号码的终端接收到解码后的声音信号,它会发出响应,通知用户电话已建立连接。
通常这一步需要进行信令的传输,以协商连接的参数。
整个拨号过程中还涉及到开关设备和电话交换机的工作。
在拨号开始前,电话交换机会接收到用户拨打的电话号码,它会根据该号码找到对应的目标终端设备。
电话交换机会根据号码和目标终端设备的状态,来决定是否要接通这个电话连接。
在电话连接建立后,音频信号可以双向传输,即可实现双方的语音通信。
对于手机而言,通常还会涉及到天线、基站等基础设施,以实现无线通信。
总结一下,拨号的原理包括录音、编码、传输、解码和呼叫建立。
通过这一系列的过程,我们可以实现电话的拨号和通信连接,实现语音通信的目的。
拨号技术在现代通信中起到了重要的作用,成为人们进行交流的重要手段之一。
频谱分析的应用--话拨号音合成与识别
WNm = e
−
2π N
m
。
由于对 DTMF 信号解码只需其频谱的幅值信息,因而可舍去相位信息,输出频谱的 幅度平方值,即
X [m = ]
2ห้องสมุดไป่ตู้
ym [ N = Qm [ N ] + Qm [ N − 1] − 2 cos ]
2.DTMF 信号识别 DTMF 信号的检测是将两个信号频率提取出来,从而确定所接收的 DTMF 是哪个数 字。利用 DFT 对 DTMF 信号进行 N 点的频谱分析,根据谱峰出现的频率点位置 Ni 就可
以确定 DTMF 信号的频率 fi:
f = Ni × f s / N i
DTMF 信号的解码要求快速、简单、准确,Goertzel 算法比 FFT 算法更为有效适用。 因为 FFT 涉及较多的复数乘法和加法,Goertzel 算法可以将复数运算转化为实数运算,从 而减少了计算量,提高了计算速度。Goertzel 算法的基本思想是对 DFT 公式进行转换, 使其成为一个二阶传输函数:
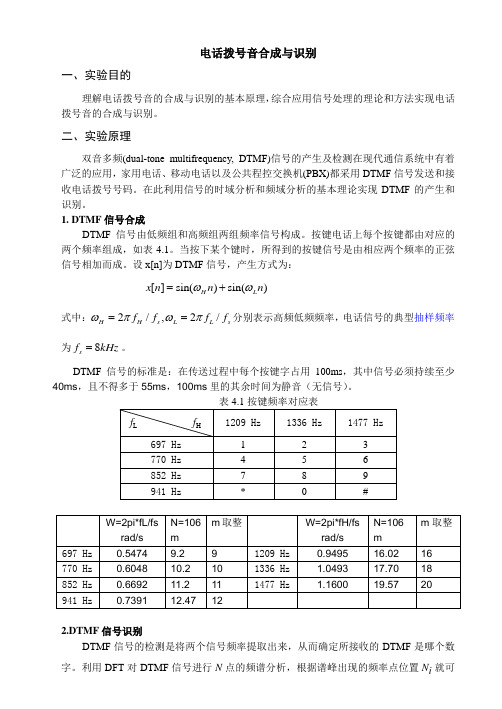
= x[n] sin(ωH n) + sin(ωL n)
式中:ωH 2 = = π f H / f s , ωL 2π f L / f s 分别表示高频低频频率,电话信号的典型抽样频率 为 f s = 8kHz 。 DTMF 信号的标准是:在传送过程中每个按键字占用 100ms,其中信号必须持续至少 40ms,且不得多于 55ms,100ms 里的其余时间为静音(无信号) 。 表 4.1 按键频率对应表 fL 697 Hz 770 Hz 852 Hz 941 Hz W=2pi*fL/fs rad/s 697 Hz 770 Hz 852 Hz 941 Hz 0.5474 0.6048 0.6692 0.7391 N=106 m 9.2 10.2 11.2 12.47 fH 1209 Hz 1 4 7 * m 取整 9 10 11 12 1209 Hz 1336 Hz 1477 Hz 1336 Hz 2 5 8 0 W=2pi*fH/fs rad/s 0.9495 1.0493 1.1600 1477 Hz 3 6 9 # N=106 m 16.02 17.70 19.57 m 取整 16 18 20
自动语音识别技术在智能电话中的应用教程

自动语音识别技术在智能电话中的应用教程在智能电话领域,自动语音识别(Automatic Speech Recognition,ASR)技术已经成为一种不可或缺的技术。
自动语音识别技术允许计算机通过语音输入来识别和理解人类语言,实现语音转文字的功能。
本文将介绍自动语音识别技术在智能电话中的应用教程,包括其原理、优势以及相关应用案例。
一、自动语音识别技术的原理和工作原理自动语音识别技术是一种利用计算机和声学模型进行语音识别的技术。
其基本的工作原理是将输入的语音信号转换为对应的文字信息。
1.语音信号的采集和预处理:首先需要采集用户的语音信号。
智能电话会通过麦克风等音频设备采集用户的语音,然后对采集到的语音信号进行预处理,如去除噪声和音频增益控制等。
2.特征提取:在语音信号的预处理后,需要对语音信号进行特征提取。
一般采用的特征提取方法是梅尔频率倒谱系数(Mel Frequency Cepstral Coefficients,MFCC),它可以提取语音信号的频谱特征。
3.声学模型训练:声学模型是自动语音识别技术中的重要组成部分,它主要用于建立语音特征与语音单位(如音素)之间的映射关系。
在训练阶段,需要使用大量的标注语音数据来训练声学模型。
4.声学模型的应用:一旦完成声学模型的训练,就可以将其应用于自动语音识别。
在智能电话中,当用户说话时,输入的语音信号将被送入声学模型进行识别。
声学模型会将语音信号映射为对应的文字。
5.语言模型和后处理:为了提高语音识别的准确性,通常会使用语言模型来进一步优化识别结果。
语言模型是基于文本数据建立的,用于根据上下文信息来指导语音识别系统的输出。
同时,后处理技术也可以用于进一步优化语音识别的结果,如错误纠正和语义解析等。
二、自动语音识别技术在智能电话中的优势自动语音识别技术在智能电话领域有着诸多优势,使其成为一种不可或缺的技术。
1.提高用户体验:使用自动语音识别技术可以大大提高用户与智能电话之间的交互体验。
dtmf拨号原理

DTMF拨号原理1. 简介DTMF(Dual Tone Multi-Frequency)是一种用于电话系统中的拨号信号传输方法。
它使用了两个频率合成的音调来表示数字、字母和特殊字符,以实现电话号码的拨号和其他控制功能。
在本文中,我们将详细解释DTMF拨号原理的基本原理,包括DTMF信号的产生、传输和解码过程。
2. DTMF信号的产生DTMF信号由两个基本频率合成而成,分别称为行频和列频。
行频由4个低频音调组成,分别为697 Hz、770 Hz、852 Hz和941 Hz;列频由4个高频音调组成,分别为1209 Hz、1336 Hz、1477 Hz和1633 Hz。
每个按键都对应着一个唯一的行列频率组合。
例如,在电话键盘上按下数字“5”时,会同时发送行频852 Hz和列频1336 Hz的信号。
生成DTMF信号的方法有多种,其中最常见的是使用一个称为双音多路复用器(Dual Tone Multi-Frequency Generator)的集成电路芯片。
该芯片接收输入的数字或字符,并根据对应的行列频率生成相应的DTMF信号。
3. DTMF信号的传输DTMF信号在电话系统中通过音频通道传输,也就是说,它被转换为模拟音频信号后通过电话线路传输。
在拨号过程中,当用户按下电话键盘上的按键时,电话机会将对应的DTMF信号发送到电话交换机或基站。
电话交换机或基站会解码接收到的DTMF信号,并根据解码结果执行相应的操作。
由于DTMF信号是以模拟音频形式传输的,因此在传输过程中可能会受到一些干扰和失真。
为了减少这些干扰和失真对信号识别造成的影响,通常会对DTMF信号进行一些预处理和增强处理。
4. DTMF信号的解码接收到DTMF信号后,需要对其进行解码以获取用户所拨打的数字、字母或特殊字符。
解码过程通常由一个称为双音多路复用解码器(Dual Tone Multi-Frequency Decoder)的集成电路芯片完成。
如何使用AI技术进行声音识别与合成

如何使用AI技术进行声音识别与合成一、引言声音是人类沟通的重要方式之一,而随着人工智能(AI)技术的快速发展,声音识别与合成领域也取得了巨大的进步。
本文将介绍如何使用AI技术进行声音识别与合成,并探讨其应用于语音识别、语音合成和语音助手等相关领域的优势。
二、声音识别1. 声音信号的采集与预处理声音信号是通过麦克风等设备采集得到的,但由于环境噪声和信号失真等因素,需要进行预处理以提高信号质量。
预处理包括去除噪声、滤波、增益调整等操作。
2. 特征提取与模型训练在声音识别中,基于AI技术的主要方法是使用深度学习模型进行特征提取和分类。
常用的深度学习模型包括卷积神经网络(CNN)、长短时记忆网络(LSTM)和注意力机制等。
通过对大量标注好的声音样本进行训练,建立准确的模型。
3. 声音识别应用声音识别广泛应用于语音命令控制、语音搜索、语音转写等场景。
例如,智能音箱可以根据用户的语音指令播放音乐、查询天气等;语音识别技术被应用于电话客服系统中,实现自动化的问题解答。
三、声音合成1. 文本到语音的转换声音合成是将文本信息转化为可听的声音信号。
通过AI技术,将文字转换为具有自然流畅和情感色彩的声音成为可能。
主要步骤包括文本分析、发音规则处理和波形生成等。
2. 合成模型训练与改进与声音识别类似,使用深度学习模型可以提取特征并进行声音合成。
常用的方法有基于循环神经网络(RNN)和生成对抗网络(GAN)等。
训练好的模型可以生成逼真的语音输出。
3. 声音合成应用声音合成广泛应用于电子书阅读、无障碍辅助功能、机器人交互等领域。
例如,在电子书阅读中,通过将文本内容以朗读的方式呈现给用户,使阅读更加便捷舒适;在无障碍辅助功能中,将文字转为语言帮助视觉障碍者获取信息。
四、语音助手1. 语音识别与合成的结合AI技术使得语音识别和声音合成能够相互结合,形成智能的语音助手。
通过在设备或系统中集成语音助手,用户可以通过声音进行交互,实现更加便捷、高效的操作。
MATLAB电话拨号音的合成与识别

知识就昱力量MATLAB 电话拨号音的合成与识别1. 实验目的1.本实验内容基于对电话通信系统中拨号音合成与识别的仿真实现。
主要涉及到电话拨号音合成的基本原 理及识别的主要方法,利用 MATLAB 软件以及FFT 算法实现对电话通信系统中拨号音的合成与识别。
并进一步利用 MATLAB 中的图形用户界面 GUI 制作简单直观的模拟界面。
使其对电话通信系统拨号音 的合成与识别有个基本的了解。
2. 能够利用矩阵不同的基频合成 0 — 9不同按键的拨号音,并能够对不同的拨号音加以正确的识别,实 现由拨号音解析出电话号码的过程。
进一步利用 GUI 做出简单的图形操作界面。
要求界面清楚,画面简洁,易于理解,操作简单。
从而实现对电话拨号音系统的简单的实验仿真。
2.实验原理 1. DTMF 信号的组成双音多频 DTMF ( Dual Tone Multi-Frequency )信号,是用两个特定的单音频率信号的组合来代表数 字或功能。
在DTMF 电话机中有16个按键,其中10个数字键0 — 9, 6个功能键*、#、A 、D 。
其中12个按键是我们比较熟悉的按键,另外由第4列确定的按键作为保留,作为功能 1209Hz 、 1336Hz 、 1477H:、 1633Hz 高频群。
从低频群和高频群任意各抽出一种频率进行组合, 共有16种组合,代表16种不同的数字键或功能,每个按键唯一地由一组行频和列频组成,如表 示。
V4 Z Z.+DTMF 的组合功能3. 实验步骤1. DTMF 信号的产生合成现在将对上节制作的图形电话拨号面板上的各控件单位的动作和变化进行设置, 即对tu1.m 文件进行编辑。
其主要的功能是使对应的按键,按照表1的对应关系产生相应的拨号音,完成对应行频及列频的叠加输岀。
此外,对于图形界面的需要,还要使按键的号码数字显示在拨号显示窗口中。
键留为今后他用。
根据CCITT 建议,国际上采用 697Hz 、770Hz 、 852Hz 、 941Hz 低频群及■I知识就昱力量鉴于CCITT对DTMF信号规定的指标,这里每个数字信号取1000个采样点模拟按键信号,并且每两个数字之间用100个0来表示间隔来模拟静音。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
获取信号 判断号码数 是
是否识别完? 否 取出当前号码对应 的410个采样点
进行 8192 个点 的FFT变换
找到行频和列频
根据图1判断 当前号码
显示号码
双音多频信号的识别流程图
1209Hz 697Hz
1336Hz
1477Hz
1633Hz
1 4 7 *
2 5 8 0
3 6 9 #
A B C D
770Hz
数字键对应的信号的产生
• 以产生0为例: • 已知声音取样频率 别是 f 941Hz 和 fH
L
fS
8192Hz,0键对应来自行频与列频分1336Hz
,
2 fH / fS 1.0247 。
• 则取样后 wL 2 fL / fS • 则0对应的信号产生为
0.7217 和 wH
d0 sin(0.7217n )
实验原理
• 双音多频的拨号键盘是4×4的矩阵,每一行代表一个低频, 每一列代表一个高频。每按一个键就发送一个高频和低频 的正弦信号组合,比如‘1’相当于频率为697Hz和1209Hz两 个正弦信号的组合。交换机可以解码这些频率组合并确定 所对应的按键。
双音多频信号的产生
• CCITT(国际电报电话咨询委员会) 对 DTMF 信号规定的 指标是,传送/接接收率为每秒10个数字,即每个数字 100ms。代表数字的音频信号必须持续至少45ms,但不超 过55ms。100ms内其他时间为静音,以便区别连续的两个 按键信号。 • 图1所示典型DTMF信号频率范围是700-1700Hz,为满足 Nyquist条件,选取8192Hz的采样频率。即1秒采样8192个 点,则100ms采样820个点模拟按键信号。假设用410个点 作为产生的DTMF信号,其他410个点的0 来表示间隔来模 拟静音。以便区别连续的两个按键信号。
• 在 DTMF 电话机中有 16 个按键,其中 10 个数字键 0 — 9 , 6 个功能键 * 、 # 、 A 、 B 、 C 、 D 。其中 12 个按键 是我们比较熟悉的按键,另外由第 4 列确定的按键作为保 留,作为功能键留为今后他用。
实验原理
• 双音多频 DTMF ( Dual Tone Multi-Frequency )信号,是 用两个特定的单音频率信号的组合来代表数字或功能。 • 双音多频信号(Dual-Tone Multi-Frequency, DTMF)是电话 系统中电话机与交换机之间的一种用户信令,通常用于发 送被叫号码。 • 在使用双音多频信号之前,电话系统中使用一连串的断续 脉冲来传送被叫号码,称为脉冲拨号。脉冲拨号需要电信 局中的操作员手工完成长途接续。 • 双音多频信号是贝尔实验室发明的,其目的是为了自动完 成长途呼叫。
sin(1.0247n )
• 产生0的matlab代码
• • • • n=[1:410]; % 每个数字用 410 个采样点表示 d0=sin(0.7217*n)+sin(1.0247*n); % 对应行频列频叠加 space=zeros(1,410); %410 个 0 模拟静音信号 phone=[d0, space];
852Hz
941Hz
f=fft(d,8192); % 以 N=2048 作 FFT 变换 d是取出来每位拨号音的采样点 a=abs(f); p=a.*a/handles.fs; % 计算功率谱 num(1)=find(p(1:1000)==max(p(1:1000))); % 找行频 num(2)=1000+find(p(1000:1700)==max(p(1000:1700))); % 找列频 if (num(1) < 730) row=1; % 确定行数 elseif (num(1) < 810) row=2; elseif (num(1) < 900) row=3; else row=4; end
• 删除键实现代码
• • • • • • • • • • n=[1:1000]; num=get(handles.edit1,'string'); l=length(num); n11=strrep(num,num,num(1:l-1)); d11=sin(0.7217*n)+sin(0.9273*n); set(handles.edit1,'string',n11); global NUM L=length(NUM); NUM=NUM(1:L-1100); wavplay(d11,8192);
功能键对应的信号的产生
• 对于保留的两个功能键“ * ”“#”,按照现行键盘式拨号电 话的习惯,将“ * ”作为删除键,“#”作为确认键。 • “ * ”删除键的作用是将前面拨错的号码删除退回,表现为 将显示窗口已经显示的错误号码退回一位数字,并且将连 续拨号音信号的存储单元 中退回一位拨号音信号和静音 信号。删除可以进行连续的操作。 • “#”确认键的作用是将前面拨过的号码进行确认保留,意 味着此时连续拨号音信号的存储单元 中的信号即为最后 用于识别的连续拨号音 DTMF 信号,并在显示窗口中显示 “#”号作为标记。
双音多频信号的识别
• 对电话拨号音( DTMF )信号的检测识别可以直接计算付 里叶变换得到输入的信号频率。这里采用 FFT 算法对信号 进行解码分析。 • 首先对接收到的数字信号作 FFT 分析,计算出其幅频谱, 进而得到功率谱。对于连续的双音多频( DTMF )信号, 需要把有效的数字拨号信号从静音间隔信号中分割提取出 来,然后再用 FFT 算法对信号进行解码分析。
电话拨号音合成与识别
实验目的
• 本实验内容基于对电话通信系统中拨号音合成与 识别的仿真实现。 • 实验目的
– 电话拨号音合成的基本原理及识别的主要方法 – 利用 MATLAB 软件以及 FFT 算法实现对电话通信系统中 拨号音的合成与识别 – 并进一步利用 MATLAB 中的图形用户界面 GUI 制作简 单直观的模拟界面。