自然语言处理的参考文献
自然语言处理的参考文献

自然语言处理的参考文献自然语言处理(Natural Language Processing,简称NLP)是人工智能领域中的重要研究方向,旨在使计算机能够理解、处理和生成自然语言。
随着互联网的快速发展,NLP正日益成为各个领域的热门研究课题。
本文将为大家介绍一些重要的NLP研究成果和相关的参考文献,并探讨其在实践中的指导意义。
首先,其中一项重要的NLP任务是文本分类。
文本分类的目标是根据给定的文本将其分为不同的类别。
一篇经典的参考文献是由Y. Kim于2014年发表的"Convolutional Neural Networks for Sentence Classification"。
该论文提出了一种基于卷积神经网络(Convolutional Neural Networks,简称CNN)的文本分类方法,该方法在多个标准数据集上取得了较好的结果。
这篇论文在实践中指导着我们如何利用深度学习方法进行文本分类任务,为我们提供了重要的思路和方法。
其次,情感分析也是NLP中的重要任务之一。
情感分析的目标是判断文本的情感倾向,通常包括正面情感、负面情感和中性情感。
一篇重要的参考文献是由A. Go等人于2009年发表的"Twitter sentiment classification using distant supervision"。
该研究利用社交媒体平台Twitter上大量的用户推文作为训练数据进行情感分析,为情感分析提供了一个新的视角和数据源,这对我们进行情感分析研究具有重要的借鉴意义。
另外,机器翻译也是NLP领域中备受关注的一个课题。
机器翻译的目标是将一种语言的文本自动翻译成另一种语言的文本。
一篇开创性的参考文献是由I. Sutskever等人于2014年发表的"Sequence to Sequence Learning with Neural Networks"。
《自然语言处理》课程教学分析与实践

关键词:自然语言处理;实践教学;认知驱动;编程巩固;人工智能
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2021)18-0160-02
开放科学(资源服务)标识码(OSID):
Analysis and Practice of“Natural Language Processing”Course Teaching
4.1“认知驱动”教学
“认知驱动”教学法,即基于学生认知的教学方法。不同于 传统教学方法以教师的角度去执行,该方法从学生的角度去执 行,以学生现有的认知水平为起点并规划学习的内容,让学生 根据自己对自然语言处理的现有认知去探索研究某一子领域 内容,教师在此过程中扮演了观察者以及评估者的角色。”认知 驱动“教学法一方面可以提高学生学习的兴趣和积极性,培养 学生在学习过程中的独立思考能力和创新思维,另一方面可以
帮助教师掌握每一位学生的知识基础,基于因材施教的理念为 学生设计不同的教学策略。
例如,在讲解“文本处理”方法时让每一位学生根据自己的 现有认知表述什么是文本处理,如何对文本进行处理。有些同 学数学基础较强,可以将文本处理的过程用数学公式形式化描 述,还有些同学编程能力较强,用伪代码算法框架描述了文本 处理的流程。
Key words: natural language processing; practical teaching; cognitive drive; programming consolidation; artificial intelligence
1 引言
《自然语言处理》课程属于人工智能专业选修课,是一门融 语言学、计算机科学、数学于一体的科学,它研究能实现人与计 算机之间用自然语言进行有效通信的各种理论和方法,是计算 机科学领域与人工智能领域中的一个重要方向[1-2]。《自然语言 处理》课程理论性较强、知识体系庞大,其主要教学内容包括: 词法分析、句法分析、语义分析、文本分类、对话系统,统计机器 翻译等,传统的教学方法只能使学生了解自然语言处理的理论 知识,难以理论联系实际并灵活运用,此外,固有的理论教学模 式降低了学生学习的兴趣和积极性,也无法培养学生的创造性 思维。针对上述传统教学体系存在的问题,本文在先前的改革 实践教学研究[3-7]的基础上提出了新的“认知驱动+编程巩固”教 学方法,达到了现代教育对教师与时俱进、因材施教的要求。
基于自然语言处理技术的电商商品标题类目分类算法

2023-11-10
目录
• 引言 • 自然语言处理技术概述 • 基于自然语言处理技术的电商商品标题分类算法 • 实验与结果分析 • 结论与展望 • 参考文献
01
引言
研究背景与意义
背景
随着电商行业的快速发展,海量的商品信息涌入电商平台,用户在浏览这些商品信息时,面临着信息 过载的问题,难以快速找到感兴趣的商品。因此,对电商商品标题进行分类,有助于用户根据分类结 果快速定位到感兴趣的商品,提高购物体验。
模型结构
根据任务需求,设计深度学习模型的架构。例如,使用卷积神经网络对文本进行特征提取 ,然后使用全连接层进行分类。或者使用循环神经网络对文本进行编码,然后使用注意力 机制对编码结果进行解码。
损失函数与优化器
根据模型结构,选择合适的损失函数和优化器进行模型训练。常见的损失函数包括交叉熵 损失、均方误差损失等。常见的优化器包括随机梯度下降、Adam等。
目前的研究主要集中在某一特定的电商平台上, 对于跨领域的应用尚未进行充分研究。未来可以 探讨如何将该算法应用到其他电商平台上,以实 现更广泛的应用。
06
参考文献
参考文献
Li, Y., Zhang, B., & Wu, J. (2019). A survey on deep learning for natural language processing. arXiv preprint arXiv:1903.00773.
特殊符号和数字通常不是文本的主要 信息,去除它们可以减少算法的复杂 性。
文本表示方法
基于词袋模型
将文本表示为一个词频矩阵,每个词对应一列,矩阵中的元素表示该词在文本中出现的次数。这种方法简单直观,但忽略了词语的顺序信息。
emnlp参考文献格式

emnlp参考文献格式EMNLP (Empirical Methods in Natural Language Processing) 是自然语言处理领域的一个重要会议,它聚集了全球顶尖的研究人员和学者。
在撰写论文或学术研究时,正确的引用参考文献格式是至关重要的。
下面是关于EMNLP参考文献格式的一些建议和指南。
1. 会议论文:在引用EMNLP会议论文时,一般遵循以下格式:作者. (发布年份). 文章标题. 在Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 页码. 地点: 出版者。
例如:Smith, J., & Johnson, A. (2019). A Novel Approach to Sentiment Analysis. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 100-110. New York, NY: Association for Computational Linguistics.2. 期刊文章:对于EMNLP发布的期刊文章,引用格式通常如下:作者. (发布年份). 文章标题. 期刊名称, 卷号(期号), 页码.例如:Brown, L., & Miller, R. (2018). Neural Machine Translation: A Comprehensive Review. Journal of Natural Language Processing, 15(3), 345-367.3. 博士论文或硕士论文:引用博士论文或硕士论文时,格式如下:作者. (论文完成年份). 论文标题. 学位论文类型, 学位论文所在机构.例如:Johnson, M. (2020). Cross-lingual Named Entity Recognition using Neural Networks. Doctoral dissertation, University of California, Berkeley.4. 书籍:对于EMNLP出版的书籍,引用格式如下:作者. (出版年份). 书名. 出版地点: 出版者.例如:Smith, J. (2017). Introduction to Natural Language Processing. New York, NY: Springer.总之,在引用EMNLP参考文献时,要确保准确列出作者姓名、文章标题、出版年份、会议/期刊名称,以及页码等重要信息。
基于Python的自然语言数据处理系统的设计与实现
基于Python的自然语言数据处理系统的设计与实现打开文本图片集摘要随着云时代的来临,大数据技术将具有越来越重要的战略意义,很多组织通常都会用一种领域特定的计算语言,像Python、R和传统的MATLAB,将其用于对新的想法进行研究和原型构建,之后将其移植到某个使用其他语言编写大的系统中去,如Java、Python等语言慢慢经验的积累人们意识到,Python对于科研和产业两者都适用,这使得即thon变得流行起来,因为研究人员和技术人员使用同一种编程工具将会带来非常高的效益。
本文基于Python语言通过对旅游游记的文本数据的处理分析,来预测大众游客的旅游趋势,并进行个性化推荐。
这样工作有利于了解旅游网站的运行情况,分析游客的需求,以便更加有效地对网站和产品进行改进和升级。
该工作涉及到数据采集、数据挖掘等关键技术。
本文介绍一个基于Python的自然语言数据处理系统,系统通过对旅游游记文本数据进行探索,让人们能更加深入了解文本数据获取和处理的流程和一些实用方法技巧。
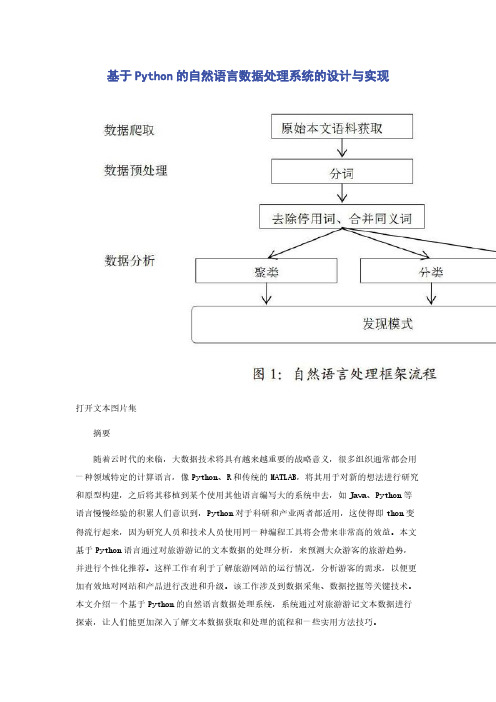
【关键词】Python自然语言数据处理系统设计1自然语言数据处理系统的设计自然语言数据处理是目前非常重要的一个科研和产业任务,自然语言处理被划分为3个阶段,分别是数据爬取,数据预处理和数据分析。
本设计基于Python语言进行具体阐述得。
因为,Python既是一门编程语言,又是一款十分好用的数据处理、统计分析与挖掘的软件框架。
与其他编程语言相比Python具有简单,易学习的特点,通过对Python的学习,能够快速开发统计分析程序。
Python擁有丰富强大的扩展库和成熟的框架特性很好地满足了数据分析所需的基本要求。
1.1自然语言数据处理系统框架本系统框架基于一般产业和科研的自然语言处理方法归纳总结而成,见图I。
1.2数据爬取数据爬取任务通常是基于Robots协议进行,再分析网站DOM树爬取所需要的数据,在解析过程中主要使用正则表达式进行筛选和匹配,针对网站的反爬取机制采取一些措施和手段。
动捕数据和自然语言处理技术

动捕数据和自然语言处理技术引言动捕数据(Motion Capture Data)是指通过采集人体或物体的运动轨迹、姿势等信息,并将其转化为数字化数据的过程。
自然语言处理技术(Natural Language Processing,NLP)是指通过计算机对人类语言进行分析、理解和生成的技术。
本文将探讨动捕数据与自然语言处理技术的关系及应用。
动捕数据的基本原理和应用动捕数据是通过使用传感器设备(如摄像头、惯性测量单元等)来采集人体或物体的运动信息。
这些传感器设备会记录下运动对象在空间中的位置、速度、加速度等参数,并将其转化为数字化数据。
这些数据可以被用于多个领域,例如电影制作、游戏开发、人机交互等。
在电影制作中,动捕技术被广泛应用于特效制作和角色动画。
通过使用动捕设备,演员可以将他们的运动表现转化为数字化的角色动画。
这种方法比传统手工绘制或计算机造型更加真实和高效。
在游戏开发中,动捕技术可以帮助开发者更加快速地创建逼真的角色动画。
通过采集真实人体的运动信息,游戏中的角色可以更加自然地模仿人类的动作。
这提高了游戏的沉浸感和可玩性。
在人机交互领域,动捕技术被用于手势识别和姿势控制。
通过分析人体的运动信息,计算机可以理解用户的手势和姿势,并相应地做出反应。
这种技术广泛应用于虚拟现实、增强现实等领域。
自然语言处理技术的基本原理和应用自然语言处理技术是指通过计算机对人类语言进行分析、理解和生成的技术。
它涉及多个子领域,如文本分类、语义分析、机器翻译等。
在文本分类中,自然语言处理技术可以将一段文本分类到不同的类别中。
例如,在垃圾邮件过滤中,可以使用自然语言处理技术将垃圾邮件与正常邮件进行区分。
在语义分析中,自然语言处理技术可以帮助计算机理解文本背后隐藏的含义和情感。
例如,在情感分析中,可以使用自然语言处理技术判断一段文本表达了积极还是消极的情感。
在机器翻译中,自然语言处理技术可以将一种语言的文本翻译成另一种语言。
自然语言处理外文翻译文献

自然语言处理外文翻译文献
这篇文献介绍了自然语言处理(Natural Language Processing, NLP)的基本概念和应用,以及它在现代社会中的重要性。
NLP 是一门研究如何让计算机能够理解和处理人类语言的学科。
它涵盖了语言识别、文本理解、语义分析等多个方面。
NLP 在多个领域有着广泛的应用,包括机器翻译、语音识别、情感分析、信息检索等。
例如,在机器翻译方面,NLP 的技术使得计算机可以自动将一种语言翻译成另一种语言,为跨语言交流提供了便利。
在情感分析方面,NLP 可以帮助识别文本中的情感倾向,并对用户的情感进行分析。
随着人工智能技术的发展,NLP 在社会中的地位变得越来越重要。
NLP 技术的进步不仅可以提高计算机与人类之间的交流能力,还可以为各个行业带来革新和进步。
未来,NLP 有望在医疗保健、金融、智能客服等领域发挥更大的作用。
总之,NLP 是一门前沿的技术学科,它对于提高计算机与人类之间的交流能力和推动社会进步具有重要意义。
在未来的发展中,NLP 有望产生更大的影响,并在各个领域得到广泛应用。
参考文献:
- Smith, J. (2020). Introduction to Natural Language Processing. Journal of Artificial Intelligence, 25(3), 45-59.。
自然语言处理大纲

课程编号:S0300010Q课程名称:自然语言处理开课院系:计算机科学与技术学院任课教师:关毅刘秉权先修课程:概率论与数理统计适用学科范围:计算机科学与技术学时:40 学分:2开课学期:秋季开课形式:课堂讲授课程目的和基本要求:本课程属于计算机科学与技术学科硕士研究生学科专业课。
计算机自然语言处理是用计算机通过可计算的方法对自然语言的各级语言单位进行转换、传输、存贮、分析等加工处理的科学。
是一门与语言学、计算机科学、数学、心理学、信息论、声学相联系的交叉性学科。
通过本课程的学习,使学生掌握自然语言(特别是中文语言)处理技术(特别是基于统计的语言处理技术)的基本概念、基本原理和主要方法,了解当前国际国内语言处理技术的发展概貌,接触语言处理技术的前沿课题,具备运用基本原理和主要方法解决科研工作中出现的实际问题的能力。
为学生开展相关领域(如网络信息处理、机器翻译、语音识别)的研究奠定基础。
课程主要内容:本课程全面阐述了自然语言处理技术的基本原理、实用方法和主要应用,在课程内容的安排上,既借鉴了国外学者在计算语言学领域里的最新成就,又阐明了中文语言处理技术的特殊规律,还包括了授课人的实践经验和体会。
1 自然语言处理技术概论(2学时)自然语言处理技术理性主义和经验主义的技术路线;自然语言处理技术的发展概况及主要困难;本学科主要科目;本课程的重点与难点。
2 自然语言处理技术的数学基础(4学时)基于统计的自然语言处理技术的数学基础:概率论和信息论的基本概念及其在语言处理技术中的应用。
如何处理文本文件和二进制文件,包括如何对文本形式的语料文件进行属性标注;如何处理成批的文件等实践内容3 自然语言处理技术的语言学基础(4学时)汉语的基本特点;汉语的语法功能分类体系;汉语句法分析的特殊性;基于规则的语言处理方法。
ASCII字符集、ASCII扩展集、汉字字符集、汉字编码等基础知识。
4 分词与频度统计(4学时)中文分词技术的发展概貌;主要的分词算法;中文分词技术的主要难点:切分歧义的基本概念与处理方法和未登录词的处理方法;中外人名、地名、机构名的自动识别方法;词汇的频度统计及统计分布规律。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
自然语言处理的参考文献
自然语言处理(Natural Language Processing,NLP)是人工智能领域中的一个重要分支,其研究目标是让计算机能够理解和处理人类的自然语言。
随着深度学习和大数据的发展,NLP在文本分析、自动问答、机器翻译等领域取得了重要进展。
本文将介绍一些经典的NLP参考文献,包括语言模型、词向量表示、情感分析、文本分类和机器翻译等方面的研究成果。
一、语言模型
语言模型是NLP的基础,它可以用来计算一个句子在语言中出现的概率。
Bengio等人在2003年的论文《A Neural Probabilistic Language Model》中提出了神经网络语言模型(NNLM),通过神经网络建模词语的概率分布,有效提高了语言模型的性能。
二、词向量表示
词向量表示是将词语映射为实数向量的方法,它可以很好地捕捉词语之间的语义关系。
Mikolov等人在2013年的论文《Efficient Estimation of Word Representations in Vector Space》中提出了Word2Vec模型,使用神经网络训练词向量,使得具有相似语义的词在向量空间中距离较近。
三、情感分析
情感分析是对文本情感进行分类的任务,可以用于分析用户评论、
社交媒体内容等。
Pang等人在2002年的论文《Thumbs up? Sentiment Classification using Machine Learning Techniques》中提出了基于机器学习的情感分类方法,采用支持向量机(SVM)对文本进行情感分类,取得了较好的效果。
四、文本分类
文本分类是将文本分配到预定义的类别中的任务,常用于新闻分类、垃圾邮件过滤等。
Zhang等人在2015年的论文《Character-level Convolutional Networks for Text Classification》中提出了基于字符级卷积神经网络(CNN)的文本分类方法,通过卷积操作提取文本的特征,实现了高效的文本分类。
五、机器翻译
机器翻译是将一种语言的文本自动翻译成另一种语言的任务。
Bahdanau等人在2014年的论文《Neural Machine Translation by Jointly Learning to Align and Translate》中提出了基于神经网络的机器翻译方法(NMT),通过引入注意力机制,使得模型能够更好地对齐源语言和目标语言的句子,提高了翻译质量。
总结:本文介绍了一些经典的NLP参考文献,包括语言模型、词向量表示、情感分析、文本分类和机器翻译等方面的研究成果。
这些研究成果为NLP的发展提供了重要的理论基础和实用方法,推动了NLP在文本分析、自动问答、机器翻译等领域的应用。
相信随着技
术的不断进步和研究的深入,NLP将在未来发展出更多颠覆性的应用。