实验1数据文件的编辑与整理
实习中的数据处理与统计分析

实习中的数据处理与统计分析一、引言在本次实习中,我主要负责数据处理与统计分析工作。
通过对各类数据的收集、整理和分析,我深入了解了数据处理与统计分析的重要性,并积累了一定的实践经验。
本文将对我在实习中的工作进行总结。
二、数据收集与整理在数据处理与统计分析的过程中,数据的质量和准确性是保证研究结论有效性的关键。
我首先学习并掌握了常见的数据收集方法,包括问卷调查、实地观察以及公开数据的获取。
通过学习调查设计和问卷编写的技巧,我能够根据研究需求制定合适的问卷,并通过实地调查获得样本数据。
同时,我还学习了数据清洗的方法,通过剔除异常值、去除重复数据等手段,提高了数据的可信度和可用性。
三、数据预处理与分析在数据处理与统计分析的过程中,数据预处理是至关重要的一步。
通过对数据进行清洗、标准化和归一化等处理,可以排除背景噪声和数据偏差,确保后续分析的准确性。
在实习期间,我学习并应用了常见的数据预处理方法,例如缺失值处理、异常值处理、数据平滑和数据变换等。
这些方法使得我能够更加准确地分析数据,发现数据中潜在的规律和趋势。
四、统计分析方法的应用在数据预处理完成后,我运用了统计分析方法对数据进行了进一步的探索和挖掘。
根据研究目标和数据类型的不同,我灵活运用了常见的统计分析方法,包括描述性统计分析、频率分析、相关分析、回归分析以及聚类分析等。
通过这些统计方法,我能够对数据的特征进行全面的分析,揭示数据之间的内在联系和规律,帮助研究者做出合理的决策。
五、数据可视化与报告撰写为了更好地向管理层和决策者传达分析结果,我学习并掌握了数据可视化的技巧。
通过使用数据可视化工具和技术,如数据图表、统计图表和地理信息系统等,我将复杂的数据转化为直观、易懂的可视化报告。
这不仅使分析结果更具影响力,也提高了决策者的理解度和参与度。
除此之外,我还学习了撰写技术报告的规范和要点,通过报告的撰写,我能够将分析结果清晰、准确地传达给相关人员。
六、实践心得与展望通过这次实习,我不仅掌握了数据处理与统计分析的基本方法和技巧,还提升了自己的沟通和团队合作能力。
SPSS上机实验报告一
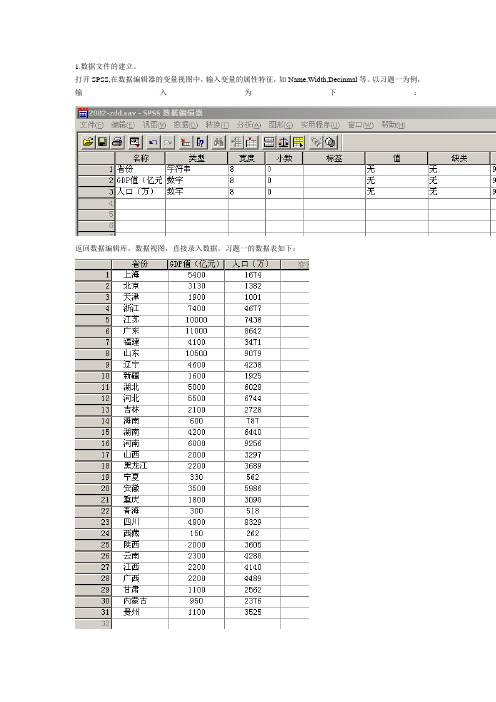
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。
SAS编程基础

data sy2_9_0; set mylib.sy2_2; if (zc = '工人');
run;
(2) 建立两个数据集:
data sy2_9_1; set sy2_9_0; keep bh xm jbgz;
run; data sy2_9_2;
set sy2_9_0; keep bh sfgz; run;
jbgz='基本工资' glgz='工龄工资' jj='奖金' kk='扣款' sfgz='实发工资';
cards;
3003 王以平 男 1992-8-1 助工
生产
620 300 500 0 1420
3004 林红
女 1993-8-1 助工
供销
620 280 500 200 1200
3005 吕兴良 男 1982-1-30 工程师 技术
代码如下:
data sy2_5; set mylib.sy2_2; drop gzrq; if jbgz < 600 then jbgz = 600;
run;
2. 增加新变量
【实验 2-6】在 mylib.sy2_2 中增加变量 yfgz(应发工资=基本工资+工龄工资+奖金)、生 成新的数据集 work.sy2_6。
data sy2_7_1 sy2_7_2;
4
SAS 软件与统计应用实验
set mylib.sy2_2; select;
when (jbgz<600) output sy2_7_1; when (jbgz>=600) out据集的纵向合并
1.SPSS数据文件的建立和编辑
实验一 SPSS数据文件的建立和编辑
1.熟悉SPSS16.O运行环境:(1)安装SPSS统计分析软件;(2)启动SPSS统计分析软件,熟悉其操作界面环境;(3)停止SPSS统计分析软件服务。
2.试利用统计教练功能浏览SPSS的主要统计分析方法。
3.请用“员工满意度”文件夹中的三份问卷,建立文件名为员工满意度的SPSS 数据文件。
其中,仅录入每份问卷第一部分的1-2题、12-14题,第三部分的1-5题。
4.试以下表中学号200203-200205的学生数据建立SPSS数据文件,并按要求进行变量定义。
学生信息表
1)变量名用英文,表格名作为变量标签。
对性别(Sex)设值标签“男=0;女=1”。
2)正确设定变量类型。
其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。
3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
5.课后练习第5题(p55)。
6.把“住房状况调查(两页数据)”的Excel格式文件转化为SPSS数据文件。
(有两种途径可实现)
7. 在住房调查问卷案例数据文件中,分别用自动定位功能定位个案号码为888,1001,2100的个案和变量名为家庭收入的变量所在位置;查找出现住面积在45平米的被调查者;在第123号个案前插入一个新个案;把计划户型变量从数据文件中删除。
Get格雅SPSS实验上机题

SPSS实验上机题实验1 数据文件建立与管理某航空公司38名职员性别和工资情况的调查数据,如下表所示,试在SPSS 中进行如下操作:〔1〕定义变量,将gender定义为字符型变量,salary定义为数值型变量,在数据窗口录入数据,并保存数据文件,将其命名为“data1_1.sav〞。
〔2〕翻开文件,练习增加一个个案,删除一个个案,增加一个变量、删除一个变量,以及个案和变量的复制、粘贴操作。
〔3〕将数据文件按性别分组;将数据文件按工资进行组距分组。
〔4〕查找工资大于40000美元的职工。
〔5〕按工资进行升序和降序排列,比拟升序和降序排列结果有什么不同。
〔6〕练习数据的分类汇总操作,要求按照性别分类汇总样本的总数。
〔7〕练习数据选取操作,要求随机选取70%的数据。
〔8〕当工资大于40000美元时,职工的奖金是工资的20%;当工资小于40000美元时,职工的奖金是工资的10%,假设实际收入=工资+奖金,计算所有职工的实际收入,并将结果添加到income变量中。
Id Gender Salary Id Gender Salary1 M $ 57000 20 F $ 262502 M $ 40200 21 F $ 388503 F $ 21450 22 M $ 217504 F $ 21900 23 F $ 240005 M $ 45000 24 F $ 169506 M $ 32100 25 F $ 211507 M $ 36000 26 M $ 310508 F $ 21900 27 M $ 603759 F $ 27900 28 M $ 3255010 F $ 24000 29 M $ 13500011 F $ 30300 30 M $ 3120012 M $ 28350 31 M $ 3615013 M $ 27750 32 M $ 11062514 F $ 35100 33 M $ 4200015 M $ 27300 34 M $ 9200016 M $ 40800 35 M $ 8125017 M $ 46000 36 F $ 3135018 M $103750 37 M $ 2910019 M $ 42300 38 M $ 31350实验2 数据特征的描述统计分析1.下表是一电脑公司某年连续120天的销售量数据(单位:台)。
实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构

实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构和定义方法;2.掌握spss数据的录入与编辑:数据的录入、数据的定位、插入和删除一个个案、插入和删除一个变量、数据的移动、复制和删除;3.掌握spss数据的保存,保存为excel文件格式和spss文件格式;4.掌握读取excel文件格式和txt文件格式的数据;5.掌握spss数据文件的纵向与横向的合并。
二.实验基本方法1. spss数据的结构和定义方法操作步骤:参阅教材第24页。
2. spss数据的录入与编辑操作步骤:(1)数据的录入:参阅教材第29页。
(2)数据的定位:参阅教材第30页。
(3)插入和删除一个个案:参阅教材第31页。
(4)插入和删除一个变量:参阅教材第31页。
(5)数据的移动、复制和删除:参阅教材第32页。
3. spss数据的保存操作步骤:参阅教材第33页。
4. 读取excel文件格式和txt文件格式的数据操作步骤:参阅教材第35页。
5. spss数据文件的纵向与横向的合并操作步骤:(1)纵向合并数据文件:参阅教材第40页。
(2)横向合并数据文件:参阅教材第42页。
三.实验内容(一)验证性实验(1)教材第25页“关于居民储户调查问卷的spss变量的设计”(2)教材第38页“职工基本情况数据的纵向合并和横向合并”(二)实践性实验(1)针对“零散数据”文件夹中的若干excel数据和txt数据,将其转换为spss的数据文件,要求转换为spss数据后,根据变量的类型正确定义数据结构。
(2)针对“经管学院考试成绩”文件夹中的数据,首先,通过spss软件将“成绩1”和“成绩2”的excel文档打开,并保存为相同文件名的spss数据文件。
要求:spss读取excel的变量名,数据结构定义准确。
其次,利用横向合并的功能,将“成绩1”和“成绩2”进行合并,并存为“三次考试成绩汇总表.sav”的文件。
最后,将“三次考试成绩汇总表.sav”的文件保存一份txt本文数据和excel文件数据。
数据的整编和分析

常用统计分析方法——SPSS应用General Method of Statistical AnalysisSPSS Application杜志渊编著前言《统计学》是一门计算科学,是自然科学在社会经济各领域中的应用学科,是许多学科的高校在校本科生的必修课程。
在统计学原理的学习和统计方法的实际应用中,经常需要进行大量的计算。
因此,统计分析软件问世使强大的计算机功能得到充分发挥,不仅能够减轻计算工作量,计算结果非常准确,而且还节省了统计分析时间。
因此,应用统计分析软件进行数据处理已经成为社会学家和科学工作者必不可少的工作内容。
为了使高校的学生能够更好的适应社会的发展和需求,学习和使用统计软件已经成为当前管理学、社会学、自然科学、生物医学、工程学、农业科学、运筹学等学科的本科生或研究生所面临的普遍问题。
为了使大学生和专业人员在掌握统计学原理的基础上能够正确地运用计算机做各种统计分析,掌握统计分析软件的操作是非常有必要的。
现将常用的SPSS统计分析软件处理数据和分析数据的基本方法编辑成册,供高校学生及对统计分析软件有兴趣的人员学习和参考,希望能够对学习者有所帮助。
本书以统计学原理为理论基础,以高等学校本科生学习的常用的统计方法为主要内容,重点介绍这些统计分析方法的SPSS 软件的应用。
为了便于理解,每一种方法结合一个例题解释SPSS软件的操作步骤和方法,并且对统计分析的输出结果进行相应的解释和分析。
同时也结合工业、农业、商业、医疗卫生、文化教育等实际问题,力求使学生对统计分析方法的应用有更深刻的认识和理解,以提高学生学习的兴趣和主动性。
另外,为了方便学习者的查询,将常用统计量的数学表达式作为附录1,SPSS 中所用的主要函数释义作为附录2,希望对学习者能够的所帮助。
编者目录第一章数据文件的建立及基本统计描述 (1)§1.1 SPSS的启动及数据库的建立 (1)§1.1.2 SPSS简介 (1)§1.1.2 启动SPSS软件包 (3)§1.1.3 数据文件的建立 (5)§1.2 数据的编辑与整理 (8)§1.2.1 数据窗口菜单栏功能操作 (8)§1.2.2 Date数据功能 (9)§1.2.3 Transform 变换及转换功能 (10)§1.2.4 数据的编辑 (12)§1.2.5 SPSS对变量的编辑 (20)§1.3 基本统计描述 (26)§1.3.1 描述统计分析过程 (26)§1.3.2 频数分析 (28)§1.4 交叉列联表分析 (44)§1.4.1 交叉列联表的形成 (44)§1.4.2 两变量关联性检验(Chi-square Test卡方检验) (47)第二章均值比较检验与方差分析 (54)§2.1 单个总体的t 检验(One-Sample T Test)分析 (55)§2.2 两个总体的t 检验 (58)§2.2.1 两个独立样本的t检验(Independent-sample T Test) (58)§2.2.2 两个有联系总体间的均值比较(Paired-Sample T Test) (61)§2.3 单因素方差分析 (64)§2.4 双因素方差(Univariate)分析过程 (69)第三章相关分析与回归模型的建立与分析 (80)§3.1 相关分析 (80)§3.1.1 简单相关分析 (81)§3.1.1.1 散点图 (81)§3.1.1.2 简单相关分析操作 (83)§3.1.2 偏相关分析 (85)§3.2 线性回归分析 (89)§3.3 曲线估计 (100)第四章时间序列分析 (111)§4.1 实验准备工作 (111)§4.1.1 根据时间数据定义时间序列 (111)§4.1.2 绘制时间序列线图和自相关图 (112)§4.2 季节变动分析 (118)§4.2.1 季节分析方法 (118)§4.2.2 进行季节调整 (121)第五章非参数检验 (125)§5.1 Chi-Square Test 卡方检验 (127)§5.2 一个样本的K-S检验 (131)§5.3 两个独立样本的检验(Test for Two Independent Sample) (135)§5.4 两个有联系样本检验(Test for Two related samples) (138)§5.6 多个样本的非参数检验(K Samples Test) (141)§5.6 游程检验(Runs Test) (148)附录1 部分常用统计量公式 (154)§6.1 数据的基本统计特征描述 (154)§6.2 总体均值检验统计量 (156)§6.3 方差分析中的统计量 (158)§6.4 回归分析模型 (161)§6.5 非参数检验 (168)附录2 SPSS函数 (175)第一章数据文件的建立及基本统计描述在社会各项经济活动和科学研究过程中,经常获得许多数据,而这些数据中包含着大量有用的信息。
SPSS实验

《统计实验》实验报告姓名:方兆运专业:经济学学号:2012127131日期:2015年 3 月20 日地点:实验中心508实验一统计数据整理一、实验类型二、实验目的熟悉SPSS的菜单和窗口界面及SPSS的数据管理和预处理功能。
三、实验内容(1)定义变量,建立数据文件(2)输入数据(直接输入)(3)数据的增删(4)变量重新赋值(5)数据的运算与新变量的生成(6)数据排序(7)数据的行列互换。
四、实验数据某航空公司38名职员性别和工资情况的调查数据,如下表所示,试在SPSS中进行如下操作:(1)将表1数据输入到SPSS的数据编辑窗口中,将gender定义为字符型变量,保存数据文件,命名为“gender.sav”。
(2)将表2数据输入到SPSS的数据编辑窗口中,将salary定义为数值型变量,保存数据文件,命名为“salary.sav”。
(3)将两个数据文件合成一个数据文件,命名为“Employee Data.sav”。
(4)要求将数据文件“Employee Data.sav”按照变量salary(收入)进行升序排序,并建立一个新数据文件“Employee Data(sorted).sav”放置排序以后的结果。
(5)要求将数据文件“Employee Data.sav”按照变量gender(性别)进行分组,对每一组的变量salary计算其算术平均数,并计算其最大观察值,并建立一个新数据文件“Employee Data(aggregate).sav”放置分类汇总以后的结果。
(6)要求以gender(性别)对数据文件“Employee Data.sav”进行拆分,并要求在以后的统计分析中可以将各拆分文件的统计分析结果放在同一表格中显示。
(看不出操作结果,熟悉该操作过程即可)。
(7)要求在“Employee Data.sav”文件中,标识工资在30000元以上的员工。
标识变量名设为s_ed变量标签为工资学历标识。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一、数据文件的编辑与整理在SPSS中,数据文件的编辑、整理等功能被集中在了Data和Transform两个菜单项中,这两个菜单的内容如下所示:Data 菜单项 Transform 菜单项2.1 进一步整理数据文件--Data 菜单【Sort Cases 对话框】例2.1 对数据集li1_1.sav 按group 升序,x 降序的次序排列。
解:选择菜单Data==>Sort Cases,系统弹出Sort Cases 对话框,该对话框并不复杂,其中比较特殊的是下方的Sort Order 单选钮,有升序和降序两种选择。
请注意,该单选钮是和上方的Sort By 框一起使用的,具体方法如下:1. 确认升序单选钮被选择,将Group 选入Sort By 框;2. 选择降序单选钮,将x 选入Sort By 框。
【Merge Files 对话框】用于对数据文件进行合并。
有纵向合并和横向合并两种。
纵向合并——增加观测量到当前数据;Data==>Merge File ==> Add Cases横向合并——增加变量到当前数据文件。
Data==>Merge File ==> Add Variables【Aggregate 对话框】用于对数据进行分类汇总,所谓分类汇总就是按指定的分类变量对观测值进行分组,对每组记录的各变量值求指定的描述统计量,结果可以存入新数据文件,也可以替换当前数据文件。
例2.2 计算Li1_1.sav中两组的血磷值标准差。
解:该题完全可以用更简单的方法完成,这里只是演示一下汇总对话框的用法。
1.Break Variables框:Group2.Aggregate Variables框:x3.Function钮:(Standard deviation单选钮:Continue钮)4.Replace working data file单选钮:选中5. OK【 Select Cases 对话框】很多时候我们不需要分析全部的数据,而是按某种要求分析其中的一部分(比如只分析男性的身高、只对前200个数据进行分析以了解大概情况),这时使用Select Cases对话框可以大大简化工作。
该对话框界面如下所示:z All cases单选钮:和下面的4个单选钮为一组,选中它则分析所 有的记录;z If condition is satisfied单选钮:只分析满足条件的记录;z If按钮:和If单选钮一起使用,单击后弹出If对话框;z Random sample of cases单选钮:从原数据中随机抽样;z Sample按钮:和Random单选钮一起使用,可以设定按百分比抽取记录,或者精确设定从前若干个记录中抽取多少个记录;z Based on time or case range单选钮:基于记录序号来选择记录;z Range按钮:和Based单选钮一起使用,用于输入记录序号范围;z Use filter variable单选钮:使用筛选指示变量来选择记录,必需在下面选入一个筛选指示变量,该变量取值为非0的记录将被选中,进入以后的分析;z Filtered单选钮:和下面的Deleted单选钮为一组,表示未被选中的记录只是被隔离,这些记录的记录号会被加上斜杠以示区别;z Deleted单选钮:未被选中的记录将被删除,一般不要使用。
当对数据集做出筛选后,所做的筛选将在以后的分析中一直有效,直到再次改变选择条件为止。
同时在多数情况下,系统会自动产生一个名为filter_$的筛选指示变量,被选中的记录该变量取值为1,反之则为0。
【Weight Cases对话框】用于对数据进行加权处理,如计算加权平均数,尤其用于处理一些频数信息等等。
1、选择菜单Data==>Weight cases;2、选择Weight cases by选项,并将某变量作为加权变量选到Weight cases by 框中。
至此便完成了加权变量的指定。
一旦指定了加权变量,那么以后的分析处理中加权是一直有效的,直到取消加权为止。
取消加权应在同一窗口中选择DO not weight cases选项。
【Split File对话框】用于对数据进行拆分,不仅按指定变量进行简单排序,更重要的是根据变量对数据进行分组,为以后所进行的分组统计分析提供便利。
1、选择菜单Data==>Split File;2、将拆分变量选择到Groups Based on框中;3、拆分会使后面的分组统计产生两种不同格式的结果。
其中Compare groups表示将分组统计结果输出在同一张表格中,以便于不同组之间的比较;Organize output by groups表示将分组统计结果分别输出在不同的表格中,通常选择第一种输出方式。
4、如果数据编辑窗口中的数据已经事先按所指定的拆分变量进行了排序,则可以选择File is already sorted 项,可以提高拆分执行的速度,否则,选择另一项。
数据拆分将对后面的分析一直起作用,即无论进行哪种统计分析,都将按拆分变量的不同组别分别进行分析计算。
如果希望对所有数据进行整体分析,则需要重新执行数据拆分,即在窗口中选择Analyze all cases项。
2.2 从原有变量计算新变量(Transform功能)【Compute Variable对话框】例2.2 在li1_1.sav中建立新变量temp,令其值当血磷值大于1时为2。
解:选择菜单Transform==>Compute,系统弹出记录选择对话框如下:单击中下部的“If”按钮,系统弹出记录选择对话框如下:由于我们这里不是对所有记录做变换,因此选中第二个单选钮“Include if case statisfies confition:”,此时下方的所有窗口变亮,表明现在可用;而“Continue”按钮变灰,表明当前还没有提供所需的信息,在左侧选中血磷值(x),然后单击“”,x就被引入了右侧的变量框,任你用键盘或者用鼠标,总之将下面这个算式补充完:x>1。
现在可见“Continue”按钮再度变黑。
系统回到Compute Variable对话框,请注意If按钮右侧的变化:x>2。
最后单击“OK”按钮。
软键盘上几个奇奇怪怪的符号的含义如下:~=&|**~不等号,等价于<>逻辑符号AND逻辑符号OR乘方,相当于函数EXP()逻辑符号NOT【Count对话框】Count对话框用于计算某个值或某些值在某个变量的取值中是否出现 例2.3 在li1_1.sav中看看有哪些记录的血磷值在2~3之间。
选择菜单Transform==>Count,系统弹出Count对话框如下:Target Variable框中用于指定记录变量值是否出现的变量名,在这里输入temp2;选中血磷值(x),将其选入Variables窗口,此时“Define Values”按钮变黑,单击它,系统弹出变量值定义窗口如下:左半部为变量值定义窗口,可以定义某个值、系统缺失值、系统或用户定义缺失值、变量值范围、小于某值或大于某值。
我们这里是第四种情况:选择Range,在through两侧分别键入2、3,然后单击已变黑的“Add”按钮,“2 thru 3”就会被加入“Values to Count”框内。
然后单击“Continue”,再单击Count 对话框的“OK”,可以看到系统自动生成变量temp2,其中10、11号记录因血磷值介于2和3之间,temp2取值为1,其余的记录temp2取值均为0。
【Recode对话框】Recode对话框用于从原变量值按照某种一一对应的关系生成新变量值,可以将新值赋给原变量,也可以生成一个新变量。
例2.4在Li1_1.sav中生成新变量temp3,当血磷值小于1时取值为0,1~2时取值为10,大于2时取值为20。
选择菜单Transform==>Record==>Into Different Variables,1.Output Variable框:选入x2.Output Variable Name框:键入temp3:单击Change钮3.选中x->temp3:单击Old and New Values钮:4.Range:Lowest through单选钮:键入1:New Value Value单选钮:键入0:单击Add钮5.Range: through单选钮:两侧分别键入1、2:New Value Value单选钮:键入10:单击Add钮6.Range: All other values单选钮:New Value Value单选钮:键入20:单击Add钮7.单击Continue8.单击OK【Categorize Variables对话框】Categorize Variables对话框用于将连续性变量自动按要求分成等间距的几类。
通常用于分位数分组。
1.Create Categories框:选入x2.Number of categories框:43.OK案例1:步骤:Data=>sort case1、数据文件:数据加工(职工数据).sav按照年龄排序;按照基本工资排序;先后按年龄和基本工资排序。
2、数据文件:学生成绩调查表.sav按照年龄排序;找出数学成绩最高分和物理成绩最低分。
3、利用居民储蓄调查数据,通过数据排序功能分别找到城镇户口和农村户口储户一次存款金额的最大值和最小值。
案例2:利用职工数据文件演示数据文件的纵向合并和横向合并。
案例3:步骤:Data=>Aggregate1、利用居民储蓄调查数据,分析城镇储户和农村储户的一次平均存(取)款金额是否有显著的差异(计算各自的均值和标准差)。
2、利用学生成绩调查表数据,分析数学、物理、化学、英文各科成绩的平均成绩和标准方差。
案例4:利用居民储蓄调查数据,根据不同的分析要求采用不同的数据选取方法抽样:z 如果只希望分析城镇储户的情况,则可以通过数据选择功能采用指定条件的抽样方法进行抽样;z 如果只希望对其中的70%的数据进行分析,可通过数据选择功能采用随机抽样中的近似抽样方法进行抽样。
案例5:步骤:Transform=>Compute1、利用学生成绩调查表计算每位同学的总分和平均分,并排名;2、利用职工基本情况数据,假设职称1至4级职工的工资分别上调50%,30%,20%,10%,依据职称级别计算实发工资。
提示:定义实发工资变量名:sfgz,并输入计算方法:(sr-bx)×系数,系数因职称不同而不同。
案例6:步骤:Transform=>Count1、利用学生成绩调查表,找出各科成绩在85分以上的人数各有多少?2、利用数据加工(职工数据),找出年龄在20-30,30-40,40-50以及50以上的人数各有多少?基本工资在1000以上的有多少人?3、利用居民储蓄调查数据,分析近些年储户收入的总体状况。