统计学教材课后答案 第三版 袁卫 庞皓 曾五一 贾俊平主编
人大版 贾俊平_统计学_第三版 课后习题答案
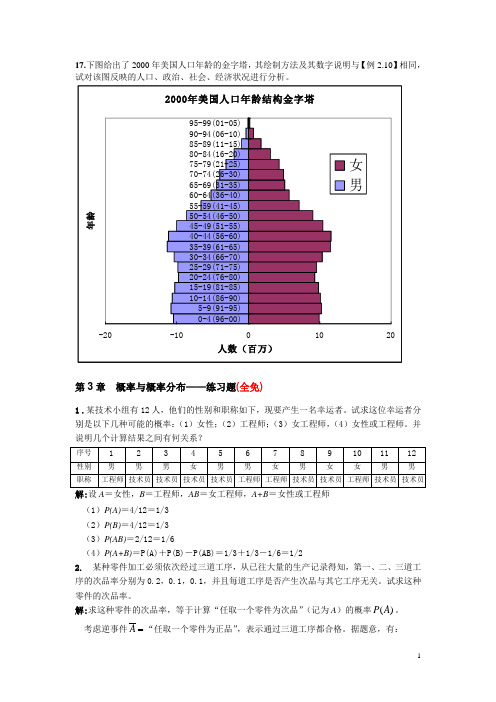
17.下图给出了2000年美国人口年龄的金字塔,其绘制方法及其数字说明与【例2.10】相同,试对该图反映的人口、政治、社会、经济状况进行分析。
第3章概率与概率分布——练习题(全免)1 .某技术小组有12人,他们的性别和职称如下,现要产生一名幸运者。
试求这位幸运者分别是以下几种可能的概率:(1)女性;(2)工程师;(3)女工程师,(4)女性或工程师。
并说明几个计算结果之间有何关系?解:设A=女性,B=工程师,AB=女工程师,A+B=女性或工程师(1)P(A)=4/12=1/3(2)P(B)=4/12=1/3(3)P(AB)=2/12=1/6(4)P(A+B)=P(A)+P(B)-P(AB)=1/3+1/3-1/6=1/22. 某种零件加工必须依次经过三道工序,从已往大量的生产记录得知,第一、二、三道工序的次品率分别为0.2,0.1,0.1,并且每道工序是否产生次品与其它工序无关。
试求这种零件的次品率。
P A。
解:求这种零件的次品率,等于计算“任取一个零件为次品”(记为A)的概率()考虑逆事件A “任取一个零件为正品”,表示通过三道工序都合格。
据题意,有:()(10.2)(10.1)(10.1)0.648P A =---=于是 ()1()10.6480.352P A P A =-=-=3. 已知参加某项考试的全部人员合格的占80%,在合格人员中成绩优秀只占15%。
试求任一参考人员成绩优秀的概率。
解:设A 表示“合格”,B 表示“优秀”。
由于B =AB ,于是)|()()(A B P A P B P ==0.8×0.15=0.124. 某项飞碟射击比赛规定一个碟靶有两次命中机会(即允许在第一次脱靶后进行第二次射击)。
某射击选手第一发命中的可能性是80%,第二发命中的可能性为50%。
求该选手两发都脱靶的概率。
解:设A =第1发命中。
B =命中碟靶。
求命中概率是一个全概率的计算问题。
再利用对立事件的概率即可求得脱靶的概率。
计量经济学-庞皓-第三版课后答案

第二章简单线性回归模型2.1(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: YMethod: Least SquaresDate: 12/27/14 Time: 21:00Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 56.64794 1.960820 28.88992 0.0000X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:10Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 38.79424 3.532079 10.98340 0.0000X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:14Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 31.79956 6.536434 4.864971 0.0001X3 0.387276 0.080260 4.825285 0.0001R-squared 0.537929 Mean dependent var 62.50000Adjusted R-squared 0.514825 S.D. dependent var 10.08889S.E. of regression 7.027364 Akaike info criterion 6.824009Sum squared resid 987.6770 Schwarz criterion 6.923194Log likelihood -73.06409 Hannan-Quinn criter. 6.847374F-statistic 23.28338 Durbin-Watson stat 0.952555Prob(F-statistic) 0.000103由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
统计学(第三版课后习题答案
18.29(元);原因:尽管两个企业的单位成本相同,但单位
成本较低的产品在乙企业的产量中所占比重较大,因此拉低了
总平均成本。
2.11 =426.67(万元);(万元)。
2.12 (1)(2)两位调查人员所得到的平均身高和标准差应该差不
多相同,因为均值和标准差的大小基本上不受样本大小的影
响。
(3)具有较大样本的调查人员有更大的机会取到最高或最低者,因
错误。
6.5 (1)检验统计量,在大样本情形下近似服从标准正态分布;
Hah 和网速是无形的
1:各章练习题答案
2.1 (1) 属于顺序数据。
(2)频数分布表如下:
服务质量等级评价的频数分布
服务质 家庭数 频率%
量等级 (频率)
A
14
14
B
21
21
C
32
32
D
18
18
E
15
15
合计 100
100
(3)条形图(略)
2.2 (1)频数分布表如下:
40个企业按产品销售收入分组表
幼儿组身高的离散系数:;
由于幼儿组身高的离散系数大于成年组身高的离散系数,说明幼儿
组身高的离散程度相对较大。
2.15 下表给出了一些主要描述统计量,请读者自己分析。
方法
方法
方法
A
B
C
平均 165.6 平均 128.73 平均 125.53
中位
中位
中位
数 165 数 129 数 126
众数 164 众数 128 众数 126
为样本越大,变化的范围就可能越大。
2.13 (1)女生的体重差异大,因为女生其中的离散系数为0.1大于
统计学教材(贾俊平版)课后习题详细答案

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
应用统计学(第三版袁卫-庞皓-曾五一-贾俊平主编)各章节课后习题答案
附录1:各章练习题答案第1章绪论(略)第2章统计数据的描述2.1 (1)属于顺序数据。
(2)频数分布表如下:服务质量等级评价的频数分布服务质量等级家庭数(频率)频率%A1414B2121C3232D1818E1515合计100100(3)条形图(略)2.2 (1)频数分布表如下:(2)某管理局下属40个企分组表按销售收入分组(万元)企业数(个)频率(%)先进企业良好企业一般企业落后企业11119927.527.522.522.5合计40 100.0 2.3 频数分布表如下:某百货公司日商品销售额分组表按销售额分组(万元)频数(天)频率(%)25~30 30~35 35~40 40~45 45~5046159610.015.037.522.515.0合计40 100.0 直方图(略)。
2.4 (1)排序略。
(2)频数分布表如下:100只灯泡使用寿命非频数分布按使用寿命分组(小时)灯泡个数(只)频率(%)650~660 2 2660~670 5 5670~680 6 6680~690 14 14690~700 26 26700~710 18 18710~720 13 13720~730 10 10730~740 3 3740~750 3 3合计100 100 直方图(略)。
2.5 (1)属于数值型数据。
(2)分组结果如下:分组天数(天)-25~-20 6-20~-15 8-15~-10 10-10~-5 13-5~0 120~5 45~10 7合计60(3)直方图(略)。
2.6 (1)直方图(略)。
(2)自学考试人员年龄的分布为右偏。
2.7 (1(2)A 班考试成绩的分布比较集中,且平均分数较高;B 班考试成绩的分布比A 班分散,且平均成绩较A 班低。
2.82.9 (1)x =274.1(万元);Me=272.5 ;Q L =260.25;Q U =291.25。
(2)17.21=s (万元)。
2.10 (1)甲企业平均成本=19.41(元),乙企业平均成本=18.29(元);原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。
统计学(第三版课后习题答案
1:各章练习题答案2.1 (1)属于顺序数据。
(2)频数分布表如下:服务质量等级评价的频数分布服务质量等级家庭数(频率)频率%A1414B2121C3232D1818E1515合计100100(3)条形图(略)2.2 (1)频数分布表如下:40个企业按产品销售收入分组表按销售收入分组(万元)企业数(个)频率(%)向上累积向下累积企业数频率企业数频率100以下100~110 110~120 120~130 130~140 140以上591274312.522.530.017.510.07.55142633374012.535.065.082.592.5100.04035261473100.087.565.035.017.57.5合计40 100.0 ————(2)某管理局下属40个企分组表按销售收入分组(万元)企业数(个)频率(%)先进企业良好企业一般企业落后企业11119927.527.522.522.5合计40 100.0 2.3 频数分布表如下:某百货公司日商品销售额分组表按销售额分组(万元)频数(天)频率(%)25~30 30~35 35~40 40~45 45~5046159610.015.037.522.515.0合计40 100.0 直方图(略)。
2.4 (1)排序略。
(2)频数分布表如下:100只灯泡使用寿命非频数分布按使用寿命分组(小时)灯泡个数(只)频率(%)650~660 2 2660~670 5 5670~680 6 6680~690 14 14690~700 26 26700~710 18 18710~720 13 13720~730 10 10730~740 3 3740~750 3 3合计100 100 直方图(略)。
(3)茎叶图如下:65 1 866 1 4 5 6 867 1 3 4 6 7 968 1 1 2 3 3 3 4 5 5 5 8 8 9 969 0 0 1 1 1 1 2 2 2 3 3 4 4 5 5 6 6 6 7 7 8 8 8 8 9 970 0 0 1 1 2 2 3 4 5 6 6 6 7 7 8 8 8 971 0 0 2 2 3 3 5 6 7 7 8 8 972 0 1 2 2 5 6 7 8 9 973 3 5 674 1 4 72.5 (1)属于数值型数据。
统计学第三版练习+答案 袁卫 庞皓
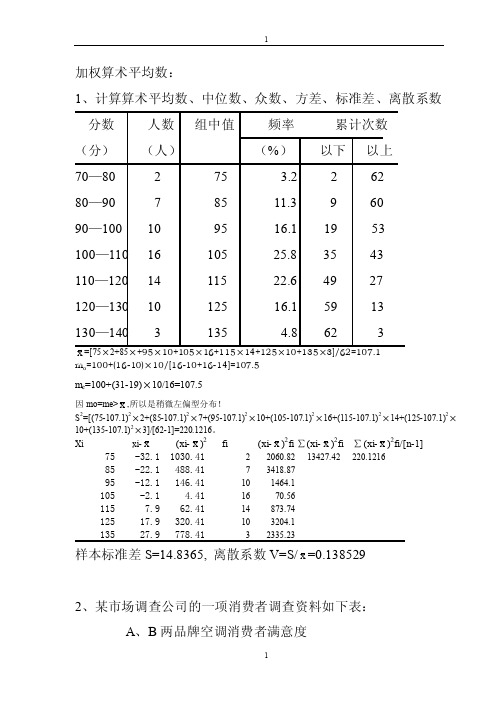
(2).P(X>2)=1-P(X≤2)=C6 0 0.20 0.86 + C6 1 0.21 0.85 + C62 0.22 0.84 = 0.90112
5
6
第五章
抽样分布课堂练习
抽样分布:全部可能样本统计量的概率分布叫做抽样分布。以下是一个极端的例子: ▲ 案例 1:假定一个实验小组有四人 N=4,其写作成绩分别为:21、20、19、18(分) (25 为满分) 。若样本容量 n=2,则全部可能样本(不重复抽样)是 6 个,6 个样本及它们 的平均数、标准差如下表: 21+20; 21+19; 21+18; 20+19; 20+18; 19+18
x ~N(50,18 /36),P(48≤ x <52)=2Ф0(2/3)-1=„„
2
▲习题 3:从阿根廷、加拿大、美国到货三批玉米,分别为 600 包、6000 包、60000 包。 合同规定三批玉米平均每包重量都是 80 公斤,标准差都是 4 公斤。要求: (1)若从每批 玉米中都抽取 300 包为样本,分别计算它们的平均数分布。有何启示?(要求都使用修 正系数) (2)分别计算三批玉米平均重量少于 79.5 公斤的概率?
750 1750 2700 9625 4875 3000
22700 263.9535
4:极差 某商场两类商品半年净收入如下: SE : (万美元/月) 23 PM: (万美元/月)29 5:方差与标准差 (1) 总体方差与标准差 某项心理测试(被试者年龄 18—35 岁)分数如下表:
测试分数(分)被试者 f 组中值 40—60 60—80 80—100 100—120 120—140 140—160 160—180 合计 1 4 12 16 9 5 3 50 50 70 90 110 130 150 Xf 50 280 1080 1760 1170 750 (X-112 )2f
计量经济学第三版(庞浩)版课后答案全

第二章之迟辟智美创作(1)①对浙江省预算收入与全省生产总值的模型,用Eviews分析结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/03/14 Time: 17:00Sample (adjusted): 1 33Included observations: 33 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.XCR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)③关于浙江省财政预算收入与全省生产总值的模型,检验模型的显著性:1)可决系数为0.983702,说明所建模型整体上对样本数据拟合较好.2)对回归系数的t检验:t(β2)=43.25639>t0.025(31)=2.0395,对斜率系数的显著性检验标明,全省生产总值对财政预算总收入有显著影响.④用规范形式写出检验结果如下:(0.004072) (39.08196)t= (43.25639) (-3.948274)R2=0.983702 F=1871.115 n=33⑤经济意义是:全省生产总值每增加1亿元,财政预算总收入增加0.176124亿元.(2)当x=32000时,①进行点预测,由上可知Y=0.176124X—154.3063,代入可得:②进行区间预测:先由Eviews分析:由上表可知,当Xf=32000时,将相关数据代入计算获得:5481.6617—2.0395x175.2325x√1/33+1852223.473/675977068. 2≤即Yf的置信区间为(5481.6617—64.9649,5481.6617+64.9649)(3) 对浙江省预算收入对数与全省生产总值对数的模型,由Eviews分析结果如下:Dependent Variable: LNYMethod: Least SquaresDate: 12/03/14 Time: 18:00Sample (adjusted): 1 33Included observations: 33 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.LNXCR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)③关于浙江省财政预算收入与全省生产总值的模型,检验其显著性:1)可决系数为0.963442,说明所建模型整体上对样本数据拟合较好.2)对回归系数的t检验:t(β2)=28.58268>t0.025(31)=2.0395,对斜率系数的显著性检验标明,全省生产总值对财政预算总收入有显著影响.④经济意义:全省生产总值每增长1%,财政预算总收入增长0.980275%(1)对建筑面积与建造单元本钱模型,用Eviews分析结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/01/14 Time: 12:40Sample: 1 12Included observations: 12Variable Coefficient Std. Error t-Statistic Prob.XCR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)由上可得:建筑面积与建造本钱的回归方程为:(2)经济意义:建筑面积每增加1万平方米,建筑单元本钱每平方米减少64.18400元.(3)②再进行区间估计:用Eviews分析:由上表可知,当Xf=4.5时,将相关数据代入计算获得:1556.647—2.228x31.73600x√1/12+43.5357/0.95387843≤即Yf的置信区间为(1556.647—478.1231, 1556.647+478.1231)第三章1)对出口货物总额计量经济模型,用Eviews分析结果如下::Dependent Variable: YMethod: Least SquaresDate: 12/01/14 Time: 20:25Sample: 1994 2011Included observations: 18Variable Coefficient Std. Error t-Statistic Prob.X2X3CR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid8007316. Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)①由上可知,模型为:②对模型进行检验:1)可决系数是0.985838,修正的可决系数为0.983950,说明模型对样本拟合较好2)F检验,F=522.0976>F(2,15)=4.77,回归方程显著3)t检验,t统计量分别为X2的系数对应t值为10.58454,年夜于t(15)=2.131,系数是显著的,X3的系数对应t值为1.928512,小于t(15)=2.131,说明此系数是不显著的.(2)对对数模型,用Eviews分析结果如下:Dependent Variable: LNYMethod: Least SquaresDate: 12/01/14 Time: 20:25Sample: 1994 2011Included observations: 18Variable Coefficient Std. Error t-Statistic Prob.LNX2LNX3CR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)①由上可知,模型为:LNY=-20.52048+1.564221 LNX2+1.760695 LNX3②对模型进行检验:1)可决系数是0.986295,修正的可决系数为0.984467,说明模型对样本拟合较好.2)F检验,F=539.7364> F(2,15)=4.77,回归方程显著.3)t检验,t统计量分别为-3.777363,17.57789,2.581229,均年夜于t(15)=2.131,所以这些系数都是显著的.(3)①(1)式中的经济意义:工业增加1亿元,出口货物总额增加0.135474亿元,人民币汇率增加1,出口货物总额增加18.85348亿元.②(2)式中的经济意义:工业增加额每增加1%,出口货物总额增加1.564221%,人民币汇率每增加1%,出口货物总额增加1.760695%(1)对家庭书刊消费对家庭月平均收入和户主受教育年数计量模型,由Eviews分析结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/01/14 Time: 20:30Sample: 1 18Included observations: 18Variable Coefficient Std. Error t-Statistic Prob.XTCR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)②对模型进行检验:1)可决系数是0.951235,修正的可决系数为0.944732,说明模型对样本拟合较好.2)F检验,F=539.7364> F(2,15)=4.77,回归方程显著. 3)t检验,t统计量分别为2.944186,10.06702,均年夜于t (15)=2.131,所以这些系数都是显著的.③经济意义:家庭月平均收入增加1元,家庭书刊年消费支出增加0.086450元,户主受教育年数增加1年,家庭书刊年消费支出增加52.37031元.(2)用Eviews分析:①Dependent Variable: YMethod: Least SquaresDate: 12/01/14 Time: 22:30Sample: 1 18Included observations: 18Variable Coefficient Std. Error t-Statistic Prob.TCR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)②Dependent Variable: XMethod: Least SquaresDate: 12/01/14 Time: 22:34Sample: 1 18Included observations: 18Variable Coefficient Std. Error t-Statistic Prob.TCR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid4290746. Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)以上分别是y与T,X与T的一元回归模型分别是:(3)对残差进行模型分析,用Eviews分析结果如下:Dependent Variable: E1Method: Least SquaresDate: 12/03/14 Time: 20:39Sample: 1 18Included observations: 18Variable Coefficient Std. Error t-Statistic Prob.E2CR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)模型为:(3)由上可知,β2与α2的系数是一样的.回归系数与被解释变量的残差系数是一样的,它们的变动规律是一致的.第五章(1)由Eviews软件分析得:Dependent Variable: YMethod: Least SquaresDate: 12/10/14 Time: 16:00Sample: 1 31Included observations: 31Variable Coefficient Std. Error t-Statistic Prob.XCR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid12220196 Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)由上表可知,2007年我国农村居民家庭人均消费支出(x)对人均纯收入(y)的模型为:(2)①由图形法检验由上图可知,模型可能存在异方差.②Goldfeld-Quanadt检验1)界说区间为1-12时,由软件分析得:Dependent Variable: Y1Method: Least SquaresDate: 12/10/14 Time: 11:34Sample: 1 12Included observations: 12Variable Coefficient Std. Error t-Statistic Prob.X1CR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid1772245. Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)得∑e1i2=1772245.2)界说区间为20-31时,由软件分析得:Dependent Variable: Y1Method: Least SquaresDate: 12/10/14 Time: 16:36Sample: 20 31Included observations: 12Variable Coefficient Std. Error t-Statistic Prob.X1CR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid7909670. Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)得∑e2i2=7909670.3)根据Goldfeld-Quanadt检验,F统计量为:在α=0.05水平下,分子分母的自由度均为10,查分布表得临界值F0.05(10,10)=2.98,因为F=4.4631> F0.05(10,10)=2.98,所以拒绝原假设,此检验标明模型存在异方差.(3)1)采纳WLS法估计过程中,①用权数w1=1/X,建立回归得:Dependent Variable: YMethod: Least SquaresDate: 12/09/14 Time: 11:13Sample: 1 31Included observations: 31Weighting series: W1Variable Coefficient Std. Error t-Statistic Prob.XCWeighted StatisticsR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid8352726. Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)Unweighted StatisticsR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Sum squared resid14484289 Durbin-Watson stat对此模型进行White检验得:Heteroskedasticity Test: WhiteF-statistic Prob. F(2,28)Obs*R-squared Prob. Chi-Square(2)Scaled explained SS Prob. Chi-Square(2)Test Equation:Dependent Variable: WGT_RESID^2Method: Least SquaresDate: 12/10/14 Time: 21:13Sample: 1 31Included observations: 31Collinear test regressors dropped from specificationVariable Coefficient Std. Error t-Statistic Prob.C1045682.WGT^21173622.X*WGT^2R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid 1.40E+13 Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)从上可知,nR2=0.649065,比力计算的统计量的临界值,因为nR2=0.649065<0.05(2)=5.9915,所以接受原假设,该模型消除异方差.估计结果为:t=(11.97157)(-0.972298)②用权数w2=1/x2,用回归分析得:Dependent Variable: YMethod: Least SquaresDate: 12/09/14 Time: 21:08Sample: 1 31Included observations: 31Weighting series: W2Variable Coefficient Std. Error t-Statistic Prob.XCWeighted StatisticsR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid6320554. Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)Unweighted StatisticsR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Sum squared resid19268334Durbin-Watson stat对此模型进行White检验得:Heteroskedasticity Test: WhiteF-statistic Prob. F(3,27)Obs*R-squared Prob. Chi-Square(3)Scaled explained SS Prob. Chi-Square(3)Test Equation:Dependent Variable: WGT_RESID^2Method: Least SquaresDate: 12/10/14 Time: 21:29Sample: 1 31Included observations: 31Variable Coefficient Std. Error t-Statistic Prob.CWGT^22240181.X^2*WGT^2X*WGT^2R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid 5.10E+12 Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)从上可知,nR2=0.999322,比力计算的统计量的临界值,因为nR2=0.999322<0.05(2)=5.9915,所以接受原假设,该模型消除异方差.估计结果为:t=(10.70922)(-1.841272)③用权数w3=1/sqr(x),用回归分析得:Dependent Variable: YMethod: Least SquaresDate: 12/09/14 Time: 21:35Sample: 1 31Included observations: 31Weighting series: W3Variable Coefficient Std. Error t-Statistic Prob.XCWeighted StatisticsR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid9990985. Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)Unweighted StatisticsR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Sum squared resid12717412 Durbin-Watson stat对此模型进行White检验得:Heteroskedasticity Test: WhiteF-statistic Prob. F(2,28)Obs*R-squared Prob. Chi-Square(2)Scaled explained SS Prob. Chi-Square(2)Test Equation:Dependent Variable: WGT_RESID^2Method: Least SquaresDate: 12/09/14 Time: 20:36Sample: 1 31Included observations: 31Collinear test regressors dropped from specificationVariable Coefficient Std. Error t-Statistic Prob.C1212308.2141958.WGT^21301839.X^2*WGT^2R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid 2.17E+13 Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)从上可知,nR2=0.911022,比力计算的统计量的临界值,因为nR2=0.911022<0.05(2)=5.9915,所以接受原假设,该模型消除异方差.估计结果为:t=(13.52507)(-0.151390)经过检验发现,用权数w1的效果最好,所以综上可知,即修改后的结果为:t=(11.97157)(-0.972298)第六章(1)建立居民收入-消费模型,用Eviews分析结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/20/14 Time: 14:22Sample: 1 19Included observations: 19Variable Coefficient Std. Error t-Statistic Prob.XCR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)所得模型为:Se=(0.012877)(12.39919)t=(53.62068)(6.446390)(2)1)检验模型中存在的问题①做出残差图如下:残差的变动有系统模式,连续为正和连续为负,标明残差项存在一阶自相关.②该回归方程可决系数较高,回归系数均显著.对样本量为19,一个解释变量的模型,5%的显著水平,查DW统计表可知,dL=1.180,dU=1.401,模型中DW=0.574663,<dL,显然模型中有自相关.③对模型进行BG检验,用Eviews分析结果如下:Breusch-Godfrey Serial Correlation LM Test:F-statistic Prob. F(2,15)Obs*R-squared Prob. Chi-Square(2)Test Equation:Dependent Variable: RESIDMethod: Least SquaresDate: 12/20/14 Time: 15:03Sample: 1 19Included observations: 19Presample missing value lagged residuals set to zero.Variable Coefficient Std. Error t-Statistic Prob.XCRESID(-1)RESID(-2)R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)如上表显示,LM=TR2=7.425088,其p值为0.0244,标明存在自相关.2)对模型进行处置:①采用广义差分法a)为估计自相关系数ρ.对et进行滞后一期的自回归,用EViews分析结果如下:Dependent Variable: EMethod: Least SquaresDate: 12/20/14 Time: 15:04Sample (adjusted): 2 19Included observations: 18 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.E(-1)R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.Durbin-Watson statb)对原模型进行广义差分回归,用Eviews进行分析所得结果如下:Dependent Variable: Y-0.657352*Y(-1)Method: Least SquaresDate: 12/20/14 Time: 15:04Sample (adjusted): 2 19Included observations: 18 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.CX-0.657352*X(-1)R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)由上图可知回归方程为:Yt*=35.97761+0.668695Xt*Se=(8.103546)(0.020642)t=(4.439737)(32.39512)由于使用了广义差分数据,样本容量减少了1个,为18个.查5%显著水平的DW统计表可知,dL=1.158,dU=1.391模型中DW=1,830746,du<DW<4- dU,说明在5%的显著水平下广义差分模型中已无自相关.可决系数R2,t,F统计量也均到达理想水平.由此最终的消费模型为:Yt=104.9987+0.668695Xt②用科克伦-奥克特迭代法,用EVIews分析结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/20/14 Time: 15:15Sample (adjusted): 2 19Included observations: 18 after adjustmentsConvergence achieved after 5 iterationsVariable Coefficient Std. Error t-Statistic Prob.CXAR(1)R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)Inverted AR Roots .63所得方程为:(3)经济意义:人均实际收入每增加1元,平均说来人均时间消费支出将增加0.669262元.(1)针对对数模型,用Eviews分析结果如下:Dependent Variable: LNYMethod: Least SquaresDate: 12/27/14 Time: 16:13Sample: 1980 2000Included observations: 21Variable Coefficient Std. Error t-Statistic Prob.LNXCR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)所得模型为:se=(0.038897) (0.241025)t=(24.45123) (9.007529)2)检验模型的自相关性该回归方程可决系数较高,回归系数均显著.对样本量为21,一个解释变量的模型,5%的显著水平,查DW统计表可知,dL=1.221,dU=1.420,模型中DW=1.159788<dL,显然模型中有自相关.(2)用广义差分法处置模型:1)为估计自相关系数ρ.对et进行滞后一期的自回归,用EViews分析结果如下:Dependent Variable: EMethod: Least SquaresDate: 12/27/14 Time: 16:18Sample (adjusted): 1982 2000Included observations: 19 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.E(-1)R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid2848090. Schwarz criterionLog likelihood Hannan-Quinn criter.Durbin-Watson stat2)对原模型进行广义差分回归,用Eviews进行分析所得结果如下:Dependent Variable: Y+0.012872*Y(-1)Method: Least SquaresDate: 12/27/14 Time: 21:06Sample (adjusted): 1981 2000Included observations: 20 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.CX+0.012872*X(-1)R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid2882022. Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)由上图可知回归方程为:Yt*=-104.9645+6.653757Xt*Se=(197.7928)( 0.304157)t=(-0.530679)( 21.87605)由于使用了广义差分数据,样本容量减少了1个,为20个.查5%显著水平的DW统计表可知,dL=1.201,dU=1.411模型中DW=1.8222596,du<DW<4- dU,说明在5%的显著水平下广义差分模型中已无自相关.可决系数R2,t,F统计量也均到达理想水平.由此最终的模型为:(3)对此模型,用Eviews分析结果如下:Dependent Variable: LNY1Method: Least SquaresDate: 12/27/14 Time: 22:16Sample (adjusted): 1981 2000Included observations: 20 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.LNX1CR-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)由题目可知,此模型样本容量为20,查5%显著水平的DW 统计表可知,dL=1.201,dU=1.411模型中DW=1.590363,du<DW<4- dU,说明在5%的显著水平此模型中无自相关.可决系数R2,t,F统计量也均到达理想水平。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第四章、参数估计
1.简述评价估计量好坏的标准
答:评价估计量好坏的标准主要有:无偏性、有效性和相合性。
设总体参数θ的
估计量有1ˆθ和2ˆθ,如果()1ˆE θθ=,称1ˆθ是无偏估计量;如果1ˆθ和2
ˆθ是无偏估计量,且()1ˆD θ小于()
2ˆD θ,则1ˆθ比2ˆθ更有效;如果当样本容量n →∞,1ˆθθ→,则1ˆθ是相合估计量。
2.说明区间估计的基本原理
答:总体参数的区间估计是在一定的置信水平下,根据样本统计量的抽样分布计算出用样本统计量加减抽样误差表示的估计区间,使该区间包含总体参数的概率为置信水平。
置信水平反映估计的可信度,而区间的长度反映估计的精确度。
3.解释置信水平为95%的置信区间的含义
答:总体参数是固定的,未知的,置信区间是一个随机区间。
置信水平为95%的置信区间的含义是指,在相同条件下多次抽样下,在所有构造的置信区间里大约有95%包含总体参数的真值。
4.简述样本容量与置信水平、总体方差、允许误差的关系
答:以估计总体均值时样本容量的确定公式为例:()22/22
z n E ασ= 样本容量与置信水平成正比、与总体方差成正比、与允许误差成反比。
练习题:
●1.
解:已知总体标准差σ=5,样本容量n =40,为大样本,样本均值x =25,
(1)样本均值的抽样标准差
σ5=0.7906 (2)已知置信水平1-α=95%,得 α/2Z =1.96,
于是,允许误差是E =
α/2Z 6×0.7906=1.5496。
●2.
解:(1)已假定总体标准差为σ=15元,
则样本均值的抽样标准误差为
x σ15=2.1429
(2)已知置信水平1-α=95%,得 α/2Z =1.96,
于是,允许误差是E
=α/2Z 6×2.1429=4.2000。
(3)已知样本均值为x =120元,置信水平1-α=95%,得 α/2Z =1.96,
这时总体均值的置信区间为
±α/2x Z 0±4.2=124.2115.8 可知,如果样本均值为120元,总体均值95%的置信区间为(115.8,124.2)元。
●3. 解:⑴计算样本均值x :将上表数据复制到Excel 表中,并整理成一列,点击最后数据下面空格,选择自动求平均值,回车,得到x =3.316667,
⑵计算样本方差s :删除Excel 表中的平均值,点击自动求值→其它函数→STDEV →选定计算数据列→确定→确定,得到s=1.6093
也可以利用Excel 进行列表计算:选定整理成一列的第一行数据的邻列的单元格,输入“=(a7-3.316667)^2”,回车,即得到各数据的离差平方,在最下行求总和,得到:
∑2
i
(x -x )=90.65 再对总和除以n-1=35后,求平方根,即为样本方差的值。
⑶计算样本均值的抽样标准误差:
已知样本容量 n =36,为大样本,
得样本均值的抽样标准误差为 x σ
s
1.6093⑷分别按三个置信水平计算总体均值的置信区间:
① 置信水平为90%时:
由双侧正态分布的置信水平1-α=90%,通过2β-1=0.9换算为单侧正态分
布的置信水平β=0.95,查单侧正态分布表得 α/2Z =1.64,
计算得此时总体均值的置信区间为
±α/2s x Z 7±1.64×0.2682= 3.75652.8769 可知,当置信水平为90%时,该校大学生平均上网时间的置信区间为(2.87,3.76)小时;
② 置信水平为95%时:
由双侧正态分布的置信水平1-α=95%,得 α/2Z =1.96,
计算得此时总体均值的置信区间为
±α/2s x Z 7±1.96×0.2682= 3.84232.7910 可知,当置信水平为95%时,该校大学生平均上网时间的置信区间为(2.79,3.84)小时;
③ 置信水平为99%时:
若双侧正态分布的置信水平1-α=99%,通过2β-1=0.99换算为单侧正态分布的置信水平β=0.995,查单侧正态分布表得 α/2Z =2.58,
计算得此时总体均值的置信区间为
±α/2s x Z 7±2.58×0.2682= 4.00872.6247 可知,当置信水平为99%时,该校大学生平均上网时间的置信区间为(2.62,4.01)小时。
●5解:假设距离服从正态分布,16,9.375, 4.113n x s ===
平均距离的95%的置信区间为((
0.0250.0251515x t x t ⎛-+ ⎝
=(7.18,11.57)
●6.
解:已知样本容量n =200,为大样本,拥有该品牌电视机的家庭比率p =23%,
拥有该品牌电视机的家庭比率的抽样标准误差为
p σ⑴双侧置信水平为90%时,通过2β-1=0.90换算为单侧正态分布的置信水平β=0.95,查单侧正态分布表得 α/2Z =1.64,
此时的置信区间为 p ±αZ %±1.64×2.98%=27.89%18.11% 可知,当置信水平为90%时,拥有该品牌电视机的家庭总体比率的置信区间为(18.11%,27.89%)。
⑵双侧置信水平为95%时,得 α/2Z =1.96,
此时的置信区间为 p ±αZ %±1.96×2.98%=28.8408%17.1592%
可知,当置信水平为95%时,拥有该品牌电视机的家庭总体比率的置信区间为 ;(17.16%,28.84%)。
●7.
解: 已知总体单位数N =500,重复抽样,样本容量n =50,为大样本,
样本中,赞成的人数为n 1=32,得到赞成的比率为 p = n 1n =3250
=64%
(1)赞成比率的抽样标准误差为 =6.788% 由双侧正态分布的置信水平1-α=95%,得 α/2Z =1.96,
计算得此时总体户数中赞成该项改革的户数比率的置信区间为
p ±αZ 64%±1.96×6.788%=77.304%50.696% 可知,置信水平为95%时,总体中赞成该项改革的户数比率的置信区间为(50.70%,77.30%)。
(2)如预计赞成的比率能达到80%,即 p =80%,
由 得样本容量为 n =
20.80.2(6.788%)⨯= 34.72 取整为35, 即可得,如果小区管理者预计赞成的比率能达到80%,应抽取35户进行调查。
●8.此题需先检验两总体的方差是否相等:
2222012112
:,:H H σσσσ=≠ 在5%的显著性水平下,2212/96.8/102.00.949F s s ===
0.0250.9750.025(13,6) 5.37,(13,6)1/(6,13)1/3.60.28F F F ====,不拒绝原假设 认为两总体方差是相同的。
(1)
()(
120.05190%,199.89.8 1.729*4.55x x t α-=-±=±±即(1.93,17.669)
(2)
()(
120.025195%,199.89.8 2.093*4.55x x t α-=-±=±±即(0.27,19.32)
●11.大样本的情况 ()
12p p z α-±(1)90%
置信度下
()40%30%10% 6.979%-±=±(3.021%,16.979) (2)95%
置信度下 ()40%30%10%8.316%-±=±(1.684%,18.316%) ●12.解:由题可计算:2222120.242,0.076s s ==
两个总体方差比2212/σσ在95%的置信区间为:
()()()22221212/21
21/212//, 4.06,14.351,11,1s s s s F n n F n n αα-⎛⎫= ⎪ ⎪----⎝⎭ ●13.
解:已知总体比率π=2%=0.02,由置信水平1-α=95%,得置信度α/2Z =1.96,允许误差E ≤
4%
即由允许误差公式 E=/2Z ασ整理得到样本容量n 的计算公式:
n=2()E α
/2P Z σ=2=2E 2α/2Z π(1-π)≥20.020.980.04⨯⨯21.96=47.0596 由于计算结果大于47,故为保证使“≥”成立,至少应取48个单位的样本。
●14. ?
解:已知总体标准差x σ=120,由置信水平1-α=95%,得置信度α/2Z =1.96,允许误差E ≤ 20 即由允许误差公式 E=/2Z x ασ整理得到样本容量n 的计算公式:
n=2()E α/2x
Z σ≥2()20
⨯1.96120=138.2976 由于计算结果大于47,故为保证使“≥”成立,至少应取139个顾客作为样本。