SPSS因子分析实验报告
因子分析报告

实验名称:因子分分析一、实验目的和要求通过上机操作,完成spss软件的因子分析二、实验内容和步骤7.7R型聚类如图所示选择将6个变量选入变量框中分别点击descriptive rotation 选项,进行以下操作As Factor Analysis: Descri-Statistics -------------------Urii variate descrptiv&s口帕1 solutiorirCor relation Matri»-[可Coefficients 日[v>\9gnifiuwri亡已levels Reproduced0 Dderrtii nent □ Anti -image巨kMO and Bflrtleti'^tesd of sphericrlyContinue |Cancel Help点击extract ion点击optionsMissing ValuesJ Exclude cases listwisBExclude ceses ^air\*iseRepiac亡Mh meanCoefTi cierit Displav FormatSuppress absolute values less thane结果如下所示Correlation Matrix aa. Determinant = .037上表为相关矩阵,给出了6个变量之间的相关系数。
主对角线系数都为1,从表中我们可知,变量与变量之间有的会高度相关,有的相关性比较低,语文与历史,语文与英语,英语与历史都是高度相关的,其他的相关度较低上表为KMO和Bartlett检验表,KMO检验是对变量是否适合做因子分析的检验, 根据Kaiser常用度量标准,由于KMO=0.755 ,表明此时一般适合做因子分析。
Extraction Method: PrincipalComponent Analysis.上表为公因子方差,给出了该次分析中从每个原始变量中提取的信息,从表中可以看出除了化学外,主成分几乎都包含了其余各个变量至少80%的信息。
实验:SPSS主成分分析和因子分析

实验:SPSS主成分分析和因子分析实验:SPSS主成分分析和因子分析实验目的:1、掌握如何确定主成分的个数;2、熟练解释主成分分析的结果:载荷矩阵、共同度、方差贡献率等;3、掌握应用主成分分析进行数据降维和综合评价的方法。
4、了解因子分析法的应用条件5、掌握因子分析法的应用;6、掌握因子分析法输出结果的解释。
实验内容:1、(主成分分析)P253见实验数据8-1 PCA20.sav某公司有20个工厂,现在要对每个工厂作经济效益分析。
从所取得的生产成果和所消耗的人力、物力、财力的比率等指标中,选取5个指标(变量)进行分析。
X1——固定资产的产值率;X2——净产值的劳动生产率;X3——百元产值的流动资金占用率;X4——百元产值的利润率;X5——百元资金的利润率。
现在对这20个工厂同时按照这5项指标收集数据,然后找出1个综合指标对它们的经济效益进行排序,找出经济效益较高的工厂。
应用主成分分析法,要求主成分只要能够反映出全部信息的85%就可以了。
2、(主成分分析)实验数据8-2 给出了中国历年国民经济主要指标统计(2005-2012)。
试用主成分分析法对这些指标提取主成分并写出提取的主成分与这些指标之间的表达式。
3、(因子分析)P281见实验数据8-3 cereals.sav 某市场调查项目需要了解消费者是否偏爱某个谷物品牌。
现有117个受访者对12个销量比较好的谷物产品的25个属性进行评分。
现在用因子分析法对消费者的偏好习惯进行分析。
哪些品牌的谷物产品易受消费者青睐?消费者喜欢哪些属性?这些属性之间有什么关系?4、(因子分析)见实验数据8-4给出了中国历年国民经济主要指标统计(2004-2012)。
试用因子分析法对这些指标提取公因子并写出提取的公因子与这些指标之间的表达式。
实验要求:题目1写一份实验报告;题目3写一份实验报告。
实验数据:见实验八数据文件夹实验步骤、结论:学生填写实验成绩:教师填写。
SPSS因子分析实验报告
实验十一(因子分析)报告一、数据来源各地区年平均收入.sav二、基本结果(1)考察原有变量是否适合进行因子分析首先考察原有变量之间是否存在线性关系,是否采用因子分析提取因子。
借助变量的相关系数矩阵、反映像相关矩阵、巴特利球度检验和KMO检验方法进行分析,结果如表1、表2所示:表1原有变量相关系数矩阵 correlation matrix表1显示原有变量的相关系数矩阵,可以看出大部分的相关系数都比较高,各变量呈较强的线性关系,能够从中提取公共因子,适合进行因子分析。
表2 KMO and Bartlett's Test由表2可知,巴特利特球度检验统计量观测值为,p值接近0,显著性差异,可以认为相关系数矩阵与单位阵有显著差异,同时KMO值为,根据Kaiser给出的KMO度量标准可知原有变量适合进行因子分析。
(2)提取因子进行尝试性分析:根据原有变量的相关系数矩阵,采用主成分分析法提取因子并选取大于1的特征值。
具体结果见表3:可知,initial一列是因子分析初始解下的共同度,表明如果对原有7个变量采用主成分分析法提取所有特征值,那么原有变量的所有方差都可以被解释,变量的共同度均为1。
事实上,因子个数小于原有变量的个数才是因子分析的目的,所以不可以提取全部特征值。
第二列表明港澳台经济单位、集体经济单位以及外商投资经济单位等变量的绝大部分信息(大于83%)可被因子解释。
但联营经济、其他经济丢失较为表3因子分析中的变量共同度(一)严重。
因此,本次因子提取的总体效果不理想。
重新制定提取特征值的标准,指定提取2个因子,分析表4:可以看出,此时所有变量的共同度均较高,各个变量的信息丢失较少。
因此,本次因子提取的总体效果比较理想。
表4因子分析的变量共同度(二)表5中,第一列是因子编号,以后三列组成一组,每组中数据项为特征值、方差贡献率、累计方差贡献率。
第一组数据项(2-4列)描述因子分析初始解的情况。
在初始解中由于提取了7个因子,因此原有变量的总方差均被解释,累计方差贡献率为100%。
主成分分析、因子分析实验报告--SPSS

主成分分析、因子分析实验报告--S P S S对2009年我国88个房地产上市公司的因子分析分析结果:表1 KMO 和 Bartlett 的检验取样足够度的 Kaiser-Meyer-Olkin 度量。
.637 Bartlett 的球形度检验近似卡方398.287df 45Sig. .000 由表1可知,巴特利特球度检验统计量的观测值为398.287,相应的概率p 值接近0,小于显著性水平 (取0.05),所以应拒绝原假设,认为相关系数矩阵与单位矩阵有显著差异。
同时,KMO值为0.637,根据Kaiser给出的KMO度量标准(0.9以上表示非常适合;0.8表示适合;0.7表示一般;0.6表示不太适合;0.5以下表示极不适合)可知原有变量不算特别适合进行因子分析。
表2 公因子方差初始提取市盈率 1.000 .706 净资产收益率 1.000 .609 总资产报酬率 1.000 .822 毛利率 1.000 .280 资产现金率 1.000 .731 应收应付比 1.000 .561 营业利润占比 1.000 .782 流通市值 1.000 .957 总市值 1.000 .928 成交量(手) 1.000 .858 提取方法:主成份分析。
表2为公因子方差,即因子分析的初始解,显示了所有变量的共同度数据。
第一列是因子分析初始解下的变量共同度,它表明,对原有10个变量如果采用主成分分析方法提取所有特征根(10个),那么原有变量的所有方差都可被解释,变量的共同度均为1(原有变量标准化后的方差为1)。
事实上,因子个数小于原有变量的个数才是因子分析的目标,所以不可提取全部特征根;第二列是在按指定提取条件(这里为特征根大于1)提取特征根时的共同度。
可以看到,总资产报酬率、成交量、流通市值、总市值的绝大部分信息可被因子解释,这些变量的信息丢失较少。
但毛利率这一变量的信息丢失相当严重(近70%),净资产收益率、应收应付比率两个变量的信息丢失较为严重(近40%)。
主成分分析、因子分析实验报告--SPSS

主成分分析、因子分析实验报告--SPSS主成分分析、因子分析实验报告SPSS一、实验目的主成分分析(Principal Component Analysis,PCA)和因子分析(Factor Analysis,FA)是多元统计分析中常用的两种方法,旨在简化数据结构、提取主要信息和解释变量之间的关系。
本次实验的目的是通过使用 SPSS 软件对给定的数据集进行主成分分析和因子分析,深入理解这两种方法的原理和应用,并比较它们的结果和差异。
二、实验原理(一)主成分分析主成分分析是一种通过线性变换将多个相关变量转换为一组较少的不相关综合变量(即主成分)的方法。
这些主成分是原始变量的线性组合,且按照方差递减的顺序排列。
主成分分析的主要目标是在保留尽可能多的数据信息的前提下,减少变量的数量,从而简化数据分析和解释。
(二)因子分析因子分析则是一种探索潜在结构的方法,它假设观测变量是由少数几个不可观测的公共因子和特殊因子线性组合而成。
公共因子解释了变量之间的相关性,而特殊因子则代表了每个变量特有的部分。
因子分析的目的是找出这些公共因子,并估计它们对观测变量的影响程度。
三、实验数据本次实验使用了一份包含多个变量的数据集,这些变量涵盖了不同的领域和特征。
数据集中的变量包括具体变量 1、具体变量 2、具体变量 3等,共X个观测样本。
四、实验步骤(一)主成分分析1、打开 SPSS 软件,导入数据集。
2、选择“分析”>“降维”>“主成分分析”。
3、将需要分析的变量选入“变量”框。
4、在“抽取”选项中,选择主成分的提取方法,如基于特征值大于1 或指定提取的主成分个数。
5、点击“确定”,运行主成分分析。
(二)因子分析1、同样在 SPSS 中,选择“分析”>“降维”>“因子分析”。
2、选入变量。
3、在“描述”选项中,选择相关统计量,如 KMO 检验和巴特利特球形检验。
4、在“抽取”选项中,选择因子提取方法,如主成分法或主轴因子法。
主成分分析、因子分析实验报告SPSS
主成分分析、因⼦分析实验报告SPSS⼀、实验⽬的及要求:1、⽬的⽤SPSS软件实现主成分分析、因⼦分析及其应⽤。
2、内容及要求⽤SPSS对2009年我国88个房地产上市公司做因⼦分析,并做出相关解释。
⼆、仪器⽤具:三、实验⽅法与步骤:准备⼯作:把实验所⽤数据从Word⽂档复制到Excel,并进⼀步导⼊到SPSS 数据⽂件中,以备后续分析。
四、实验结果与数据处理:在因⼦分析的SPSS操作中所⽤到的部分选项的设置如下⾯四个图所⽰,其余为软件默认的选项,因此不再列⽰,具体的分析如这些表之后所⽰。
图⼀图⼆图三图四分析结果:由表1可知,巴特利特球度检验统计量的观测值为398.287,相应的概率p值接近0,⼩于显著性⽔平 (取0.05),所以应拒绝原假设,认为相关系数矩阵与单位矩阵有显著差异。
同时,KMO值为0.637,根据Kaiser给出的KMO度量标准(0.9以上表⽰⾮常适合;0.8表⽰适合;0.7表⽰⼀般;0.6表⽰不太适合;0.5以下表⽰极不适合)可知原有变量不算特别适合进⾏因⼦分析。
表2为公因⼦⽅差,即因⼦分析的初始解,显⽰了所有变量的共同度数据。
第⼀列是因⼦分析初始解下的变量共同度,它表明,对原有10个变量如果采⽤主成分分析⽅法提取所有特征根(10个),那么原有变量的所有⽅差都可被解释,变量的共同度均为1(原有变量标准化后的⽅差为1)。
事实上,因⼦个数⼩于原有变量的个数才是因⼦分析的⽬标,所以不可提取全部特征根;第⼆列是在按指定提取条件(这⾥为特征根⼤于1)提取特征根时的共同度。
可以看到,总资产报酬率、成交量、流通市值、总市值的绝⼤部分信息可被因⼦解释,这些变量的信息丢失较少。
但⽑利率这⼀变量的信息丢失相当严重(近70%),净资产收益率、应收应付⽐率两个变量的信息丢失较为严重(近40%)。
因此本次因⼦提取的总体效果并不理想。
表3展⽰了特征根及累积贡献率情况,按照特征根⼤于1的原则,选⼊了4个公共因⼦,其累积⽅差贡献率为72.343%,同时也可以看出,因⼦旋转后,累计⽅差⽐并没有改变,也就是没有影响原有变量的共同度,但却重新分配了各个因⼦解释原有变量的⽅差,改变了各因⼦的⽅差贡献,使各因⼦更易于解释。
因子分析实验报告
电子科技大学政治与公共管理学院本科教学实验报告(实验)课程名称:数据分析技术系列实验电子科技大学教务处制表电子科技大学实验报告学生:晨飞学号:27指导教师:高天鹏一、实验室名称:电子政务可视化实验室二、实验项目名称:因子分析三、实验原理使用SPSS软件的因子分析对数据样本进行分析相关分析的原理:步骤一:将原始数据标准化。
因子分析的第一步是主成分分析,将总量较多的因素通过线性组合的方式组合成几个因素,且这些因素之间相互独立。
步骤二:建立变量的相关系数矩阵RAnalyse->Dimention Ruduction-> Fctor ->Extraction->勾选Correlation matrix可以输出相关系数矩阵,相关系数矩阵计算了变量之间两两的pearson相关系数。
步骤三:适用性检验使用Bartlett球形检验或者KMO球形检验来检验样本是否适合进行因子分析。
评价标准:KMO检验用于检验变量间的偏相关系数是否过小,一般情况下,当KMO大于0.9时效果最佳,小于0.5时不适宜做因子分析。
Bartlett球形检验用于检验相关系数矩阵是否是单位阵,如果结论是不拒绝该假设,则表示各个变量都是各自独立的。
步骤四:根据因子贡献率选取因子,特征值和特征向量构建因子载荷矩阵A。
处于简化和抽取核心的思想,一般会按照某种标准选取前几个对观测结果影响较大的因素构建因子载荷矩阵,一般的标准是选取特征根大于1的因子。
并要求累积贡献率达到90%以上。
步骤五:对A进行因子旋转因子旋转的目的是使因子载荷矩阵的结构发生变化,使每个变量仅在一个因子上有较大载荷。
是将因子矩阵在一个空间里投影,使单个向量的投影在仅在一个变量的方向有较大的值,这样做可以简化分析。
步骤六:计算因子得分:计算因子得分是计算在不同样本水平下观测指标的水平的方式。
计算因子得分需要用到因子得分计算函数,这个计算的结果是无量纲的,仅表示各因子在这个水平下观测指标的值,这也是因子分析的目标,将不可观测的目标观测量用一个函数与可以观测的变量联系起来。
SPSS学习系列31.因子分析报告
31.因子分析一、基本原理因子分析,是用少数起根本作用、相互独立、易于解释通常又是不可观察的因子来概括和描述数据,表达一组相互关联的变量。
通常情况下,这些相关因素并不能直观观测。
因子分析是从研究相关系数矩阵内部的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子的一种多变量统计分析方法。
简言之,即用少数不可观测的隐变量来解释原始变量之间的相关性或协方差关系。
因子分析的作用是减少变量个数,根据原始变量的信息进行重组,能反映原有变量大部分的信息;原始部分变量之间多存在较显著的相关关系,重组变量(因子变量)之间相互独立;因子变量具有命名解释性,即该变量是对某些原始变量信息的综合和反映。
主成分分析是因子分析的特例。
主成份分析的目标是降维,而因子分析的目标是找出公共因素及特有因素,即公共因子与特殊因子。
因子分析模型在形式上与线性回归模型相似,但两者有着本质的区别:回归模型中的自变量是可观测到的,而因子模型中的各公因子是不可观测的隐变量,而且两个模型的参数意义也不相同。
得到估计的因子模型后,还必须对得到的公因子进行解释。
即对每个公共因子给出一种意义明确的名称,用来反映在预测每个可观察变量中这个公因子的重要性。
该公因子的重要程度就是在因子模型矩阵中相应于这个因子的系数。
由于因子载荷阵不惟一,故可对因子载荷阵进行旋转。
目的是使 因子载荷阵的结构简化,使载荷矩阵每列或行的元素平方值向 0和1 两极分化,这样的因子便于解释和命名。
每个样本都可以计算其在各个公因子上的得分, 利用因子得分以 及该公因子的方差贡献比例,又可以计算每个样本的综合得分。
二、因子分析实例例1 (综合评价问题)对我国30个省市经济发展的8个指标进 行分析和排序。
数据文件如下:XI说 ■[总 沁j* IflXT1 11394 09 250&D0 519.01 fl 144 00 玛如 117 30 112.60843 43 22020.112720 00 345 4B fiSOl 0G115.20 110.60582.51 33 2849 521I25B 00 704 B74839 00203 3 3D 115 20 115 SO1234 8543西1W2.43 1250.00 290.30472]曲717.30 11Q.W 115.606&7 25 54 穴薪 A32闕 138 7 00 250咼 跖引00 7B1 70 117 SO lie eo419 39 e卢亠Ji2TO37 2397 Q0 387 99 4911 QQ 1371 ID 116 10 怦001M0L 詞 7112^ 20 1672 M 320 454430 00 ■OT 40115.20 114 20 762 47 872014 53233J M 435734M5OQ 124 80110.10 114 30 1240 37 些3上潯 24C2.57SUB 4B92TO 00 20F 4D IIS TO 113.001&42 45 10菸 515& Z&192GD0 1434 95 5943 00 10M50 115.00 114 30 2026 64 11 10協工3524.7& 2249.00 1006.39561 & O0 754,40 116.60113.9091IS.59 T212 安歳 2CHJ35B12 54 00 47«1 DO4609 DO 9D8 3D BO 112 70 B24 142160 52 2320 00 553.9T 5S57 00 ©09.30 11^.20 114.40 43107 1141205 11 1182.00 28?茁 4211 OQ 小70 116 90 115 90 571 M5002 341527 M)1229 555145QQ11906011700TM ?Q2207 09x1=GDP x2二居民消费水平;x3=固定资产投资;x4二职工平均工资;x5=@物周转量;x6二居民消费价格; x7二商品价格指数;x8二工业总产值1.【分析】一一【降维】一一【因子分析】,打开“因子分析” 窗口,将变量“ x1-x8”选入【变量】框;2•点【描述】,打开“描述统计”子窗口,勾选【统计量】下的“单变量描述性”、“原始分析结果”,【相关矩阵】下的“系数”、“再生”、“ KMO和Bartlett的球形度检验”;点【继续】;3•点【抽取】,打开“抽取”子窗口,【方法】选“主成份”,【分析】选“相关性矩阵”,【输出】勾选“未旋转因子解”、“碎石图”,【抽取】选“基于特征值:特征值大于‘ T”;点【继续】;注1:提取公因子方法有(1)主成份法(默认),假设变量是各因子的线性组合,从解释变量的变异除非,尽量是变量的方差能被主成分所解释,适合大多数情况;(2)未加权的最小平方法:使相关矩阵和再生相关矩阵之差的平方和达到最小;(3)综合最小平方法:同(2),并用单值的倒数对相关系数加权;(4)最大似然法:要求数据服从多变量正态分布,此时生成的参数估计最接近观察到相关矩阵,适宜样本量较大情况;(5)主轴因子分解法:从原始变量的相关性出发,使变量间的相关程度尽可能地被公因子解释,但对变量方差的解释不太重视;(6)o因子分解法:将变量看出从潜在的变量空间中抽取出的样本,计算时尽量使得变量的。
因子分析 数学实验报告
哈尔滨商业大学
数学实验报告
实验题目:_ 因子分析____ ______
姓名:郝宇学号:201111530011
专业:数学与应用数学1班
日期:2013-11-22
一、实验目的
利用SPSS软件对数据进行因子分析
二、实验内容
在此实验中,通过使用SPSS对牙膏的偏好调查结果进行因子分析。
三、实验步骤及结论
(一)1、首先使用SPSS打开“牙膏偏好调查”。
2、将变量视图中名称分别为V1-V6的“标签”一栏中写入防蛀、亮白、保护牙龈、口气清新、治疗坏牙、提升魅力;
-(二)1、选择菜单栏中“分析-降维-因子分析”。
将分组V1-V6移入分组变量列表中
单击确定,执行因子分析过程。
1.该组数据是否适合做因子分析
Sig=0.000<0.05,所以适合做因子分析
X2=-0.301X1+0.795X2+e2;
X3=0.936X1+0.131X2+e3;
X4=-0.342X1+0.789X2+e4;
X5=-0.869X1-0.351X2+e5;
X6=-0.177X1+0.871X2+e6;
4.对因子命名
1、3、5护牙因子
2、4、6美牙因子
5每个指标的共同度方差贡献
方差贡献为82.49%
四、心得体会
通过本次试验,我了解了SPSS的一些基本操作,明白了怎么使用SPSS对数据做因子分析。
对于SPSS,我们有了更进一步的了解。
SPSS因子分析实验报告(精品)
SPSS因子分析实验报告(精品)本文旨在通过SPSS因子分析对数据进行分析,以提高对一组变量的了解。
首先,我们首先对数据进行了可视化和描述性统计分析。
接着,我们使用SPSS的因子分析来简化数据的结构,以找出隐藏的因子,并将所有变量归纳到几个因子中去。
该分析采用假设测试方法,估计了最小平方法和密度估计的参数,使用KMO指标来测量每个变量的内在相关性,使用Bartlett测试来衡量变量之间的统计相关性,以及主成分法和因子载荷法获得因子载荷。
经过这些步骤,可以看出,数据共有三个因子,每个因子包含五个变量,其权重随时间变化而改变。
KMO值为0.746,Bartlett测试p值介于0.000和0.013之间,满足要求,表明变量之间存在显著相关性。
这些因子的含义为:第一个因子被称为奖励;第二个因子表示社会支持;第三个因子则表示工作环境的承诺。
我们发现,在数据中,与绩效关系最密切的变量是第一个因子中的变量,它们取得了最高的因子负荷,分别为0.860、0.740、0.723、0.712和0.665,这些变量被认为是对员工设置奖励的重要变量。
此外,第二个因子中的变量也可以在团队合作当中起到重要作用,它们的因子负荷分别为0.476、0.434、0.411、0.331和0.326,揭示了社会支持对绩效的重要性。
最后,第三个因子中的变量可以代表工作环境的特性,其因子负荷分别为0.534、0.513、0.480、0.395和0.374,表明它们对于员工的表现也有重大影响。
通过本次SPSS因子分析,我们发现,数据背后有三种主要因素:奖励、社会支持和工作环境承诺,而且这三种因素中的每一项都可以在一定程度上影响员工表现。
因此,可以利用本次分析的结果,完善绩效管理,提高工作环境的质量,以期获得更佳的绩效。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验十一(因子分析)报告
、数据来源
各地区年平■均收入.sav
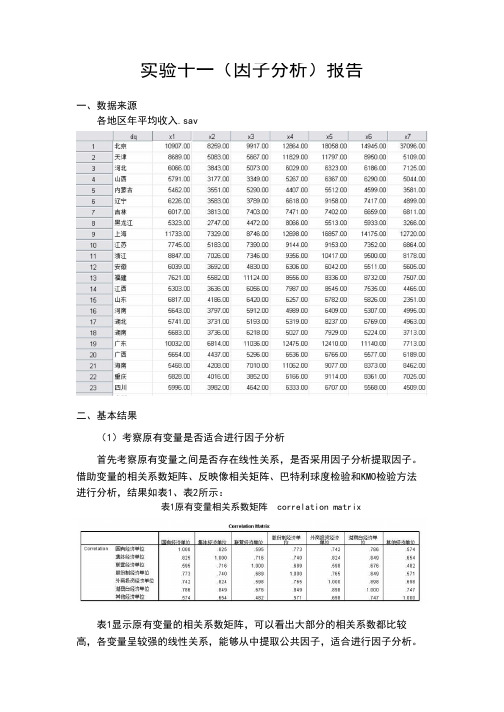
dq 1 招1K2 K J x5 AD JC7 北亨10307 00必9 3D 99170012364 JJ13053 00g5 0C
■J
天津盹即UQ5093 0D 56&7 00 11 股CO 117^7 009950.00 51C9 00 ,
3河牝6066 003043 0D 5073 00 602903 B323 00 ET8&CC 7125 00
4 山西5791 003177 □□33^3 00 涵工0Q &3B7.TO & 290 00 50-1-1 00
5内蒙古5462 00 3551 005290 00 4407 01551200 彻IX街co
iZ宁6226 003503.00 3799 00 6618.0U 9150.X 7J17,0U atyy.uu 6
7吉林601700 3813 Q074mnn7471 Ti7402 00泌g nr Bfil1 R1
5323 002747 3D 1472 00 3366 30 551300 5033 0C32EC00
9 上鲁11733 00 7329.00 874^.00 12^60016BS7.ua 14175.DO 12720.00
n io g7745 0051B3 0D7390 00nuan9151 DO7352 00洛J 00 H8847 007D260D 7346.00 935&001(3417.00 3600.00 eUBOQ
126035 0C 3692 CJD 曲*00 GM&aa 5042 DO5611 00 5eo6co
13福津7K1 QC5眺叩1112^00 3556.00 8336 OQ 6732.C0 7507 00
U■■工西5303 003E36 50 6O5E00 7337 m K45D07535.00 44E5 00
15山莱6617004106 0D &420.00 6257 TO 5702 DO 562&.Q0ZJ51 00 渴南56 的003797 00 €91200&jn9oo 6307 00 4996 00
17 曲比5741.D03731.0D5193 00 S31900 0Q37.OO G7G9.C0 49&3.00
1S5683 003736 0D 621B005027 Tl 7529 005224 DO 3713 00
捋广布10031006BH 00 110X0012475.03 12410.00 11UD CO 7713 CO
30 FS5654 004437 00 5296 00 653BOJ 6765 00 £677 OC 6189 00
215465 004网QD 7Q1Q0Q 1105200 9077 00 @373 00 6462 0Q P 22582BD04D16.Q0 3BS2 00G1SB.009114.00 蹄i加7C125 0D
II5996 003982 00 4S42 00 G33300 6707 00 &%aa)4509 00
23 刨
二、基本结果
(1)考察原有变量是否适合进行因子分析
首先考察原有变量之间是否存在线性关系,是否采用因子分析提取因子。
借助变量的相关系数矩阵、反映像相关矩阵、巴特利球度检验和KMO检验方法
进行分析,结果如表1、表2所示:
表1原有变量相关系数矩阵correlation matrix
表1显示原有变量的相关系数矩阵,可以看出大部分的相关系数都比较高,各变量呈
较强的线性关系,能够从中提取公共因子,适合进行因子分析
表 2 KMO and Bartlett's Test
由表2可知,巴特利特球度检验统计量观测值为182.913 , p值接近0,显著性差异,可以认为相关系数矩阵与单位阵有显著差异,同时KMO值为0.882,根据Kaiser给出的KMO度量标准可知原有变量适合进行因子分析。
(2)提取因子
进行尝试性分析:根据原有变量的相关系数矩阵,采用主成分分析法提取因子并选取大丁1的特征值。
具体结果见表3:可知,initial 一列是因子分析初始解下的共同度,表明如果对原有7个变量采用主成分分析法提取所有特征值,那么原有变量的所有方差都可以被解释,变量的共同度均为1。
事实上,
因子个数小丁原有变量的个数才是因子分析的目的,所以不可以提取全部特征值。
第二歹0表明港澳台经济单位、集体经济单位以及外商投资经济单位等变量的绝大部分信息(大丁83% )可被因子解释。
但联营经济、其他经济丢失较为严重。
因此,本次因子提取的总体效果不理想。
表3
重新制定提取特征值的标准,指定提取2个因子,分析表4:可以看出, 此时所有变量的共同度均较高,各个变量的信息丢失较少。
因此,本次因子提取的总体效果比较理想。
表4因子分析的变量共同度(二)
表5中,第一列是因子编号,以后三列组成一组,每组中数据项为特征值、方差贡献率、累计方差贡献率。
第一组数据项(2-4列)描述因子分析初始解的情况。
在初始解中由丁提取了7个因子,因此原有变量的总方差均被解释,累计方差贡献率为100%。
第二组(5-7列)描述了因子解的情况。
由丁指定提取2个因子,2个因子共解释原有变量宗法差的84%,总体上丢失原有信息量较少,因子分析效果理想。
第三组(8-10列)描述了最终因子解的情况。
因子旋转后,总的累计方差贡献率没有发生改变,也就是没有影响原有变量的共同度,但却重新分配了各个因子的解释原有变量的方差,改变了各因子方差贡献,使得因子更易被解释。
表5因子解释原有变量总方差的情况
图1中,横坐标为因子数目,纵坐标为特征值。
可以看出,第1个因子特征值很高,对解释原有变量的贡献最大,第3个以后的因子特征值都较小,对解释原有变量的贡献很小。
因此提取两个因子是合适的。