WEKA实验教程
数据挖掘实验报告-实验1-Weka基础操作

数据挖掘实验报告-实验1-W e k a基础操作学生实验报告学院:信息管理学院课程名称:数据挖掘教学班级: B01姓名:学号:实验报告课程名称数据挖掘教学班级B01 指导老师学号姓名行政班级实验项目实验一: Weka的基本操作组员名单独立完成实验类型■操作性实验□验证性实验□综合性实验实验地点H535 实验日期2016.09.281. 实验目的和要求:(1)Explorer界面的各项功能;注意不能与课件上的截图相同,可采用打开不同的数据文件以示区别。
(2)Weka的两种数据表格编辑文件方式下的功能介绍;①Explorer-Preprocess-edit,弹出Viewer对话框;②Weka GUI选择器窗口-Tools | ArffViewer,打开ARFF-Viewer窗口。
(3)ARFF文件组成。
2.实验过程(记录实验步骤、分析实验结果)2.1 Explorer界面的各项功能2.1.1 初始界面示意其中:explorer选项是数据挖掘梳理数据最常用界面,也是使用weka最简单的方法。
Experimenter:实验者选项,提供不同数值的比较,发现其中规律。
KnowledgeFlow:知识流,其中包含处理大型数据的方法,初学者应用较少。
Simple CLI :命令行窗口,有点像cmd 格式,非图形界面。
2.1.2 进入Explorer 界面功能介绍(1)任务面板Preprocess(数据预处理):选择和修改要处理的数据。
Classify(分类):训练和测试分类或回归模型。
Cluster(聚类):从数据中聚类。
聚类分析时用的较多。
Associate(关联分析):从数据中学习关联规则。
Select Attributes(选择属性):选择数据中最相关的属性。
Visualize(可视化):查看数据的二维散布图。
(2)常用按钮Openfile:打开文件Open URL:打开URL格式文件Open DB:打开数据库文件Generate:数据生成Undo:撤销操作Edit:编辑数据Save:保存数据文件,可实现文件格式的转换,比如csv 格式文件向ARFF格式文件转换等等。
weka使用-徐延昆
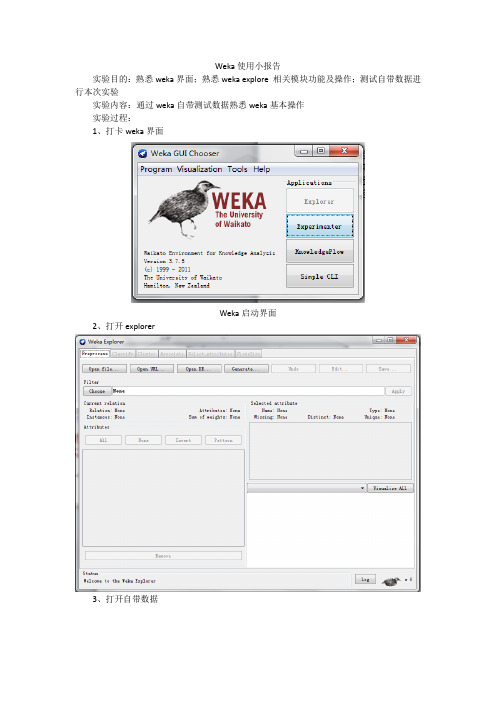
Weka使用小报告实验目的:熟悉weka界面;熟悉weka explore 相关模块功能及操作;测试自带数据进行本次实验实验内容:通过weka自带测试数据熟悉weka基本操作实验过程:1、打卡weka界面Weka启动界面2、打开explorer3、打开自带数据打开一个名为contact-lenses的arff数据文件,可以从基本界面发现这个数据里的一些特征:(1)数据关系名称:contact-lenses(2)数据实例个数:24(3)数据每个实例属性个数:5(4)总权重:243、观察基本数据信息红色标注的部分就是数据属性,可以看到这组数据共有五个属性:(1)Age(2)Spectacle-prescrip(3)Astigmatism(4)Tear-prod-rate(5)Contact-lenses这个标注的是所选属性的一些信息:属性名称:age属性取值个数:3丢失率:0单值个数:0属性类型:分类型表中是属性具体取值,比如说age:(1)年轻(2)接近老年(3)老年右下角的直方图就是具体属性中包含其他属性的图,比如说上图所选就是age属性,每个age里包括contact比例就是蓝、红、浅蓝的比例。
这些可以更换,只要class属性中选择其他的类。
上面这个直方图就可以完全显示各种类之间比例的关系。
4、使用过滤器5、使用分类器选择分类器为one-B 6选择完分类器选项之后可以选择测试方式,我使用了3种测试方法,对5个属性都进行了测试6、聚类操作7、关联分析8、可视化分析9、收获和问题:(1)熟悉了基本操作(2)对一些术语还不是很理解,分类聚类等(3)在进行一次聚类操作的时候出现了不能停止的情况(4)测试的数据个数太少,没有尝试使用一个大数据,导致最后可视化看不出什么关系。
数据挖掘-WEKA实验报告一

数据挖掘-WEKA 实验报告一一、实验内容1、Weka 工具初步认识(掌握weka程序运行环境)2、实验数据预处理。
(掌握weka中数据预处理的使用)对weka自带测试用例数据集weather.nominal.arrf文件,进行一下操作。
1)、加载数据,熟悉各按钮的功能。
2)、熟悉各过滤器的功能,使用过滤器Remove、Add对数据集进行操作。
3)、使用weka.unsupervised.instance.RemoveWithValue 过滤器去除humidity属性值为high的全部实例。
4)、使用离散化技术对数据集glass.arrf中的属性RI和Ba 进行离散化(分别用等宽,等频进行离散化)。
(1)打开已经安装好的weka,界面如下,点击openfile即可打开weka自带测试用例数据集weather.nominal.arrf文件(2)打开文件之后界面如下:(3)可对数据进行选择,可以全选,不选,反选等,还可以链接数据库,对数据进行编辑,保存等。
还可以对所有的属性进行可视化。
如下图:(4)使用过滤器Remove、Add对数据集进行操作。
(5)点击此处可以增加属性。
如上图,增加了一个未命名的属性unnamed.再点击下方的remove按钮即可删除该属性.(5)使用weka.unsupervised.instance.RemoveWithValue过滤器去除humidity属性值为high的全部实例。
没有去掉之前:(6)去掉其中一个属性之后:(7)选择choose里的removewithvalue:(8)选择huminity属性:(9)使用离散化技术对数据集glass.arrf中的属性RI和Ba进行离散化(分别用等宽,等频进行离散化)。
RI等宽:(10)Ba等频:二、思考与分析.1.使用数据集编辑器打开weather.nominal.arrf文件,实例编号为2的分类属性值是多少?如图所示:实例编号为2的分类值属性为no加载weather.nomina.arrf文件后,temperature属性可以有哪些合法值?Temperature可以取值为:hot、mild、coolWord 资料。
weka 数据挖掘实验报告

weka 数据挖掘实验报告Weka 数据挖掘实验报告引言数据挖掘是一种从大量数据中发现隐藏模式、关系和规律的技术。
Weka 是一款流行的开源数据挖掘软件,它提供了丰富的算法和工具,可以帮助用户进行数据挖掘分析。
本实验旨在使用Weka软件对一个真实数据集进行挖掘分析,并得出相关结论。
实验设计本次实验选择了一个关于房价预测的数据集,其中包含了房屋的各种属性(如面积、地理位置、建筑年代等)以及其对应的销售价格。
我们将使用Weka软件中的不同算法来对这个数据集进行挖掘分析,比较它们的效果和性能。
实验步骤1. 数据预处理:首先,我们对数据集进行了清洗和预处理,包括处理缺失值、标准化数据等操作,以确保数据的质量和一致性。
2. 特征选择:接着,我们使用Weka中的特征选择算法来确定哪些属性对于房价预测是最重要的,从而减少模型的复杂度和提高预测准确性。
3. 模型建立:然后,我们尝试了不同的机器学习算法(如决策树、支持向量机、神经网络等)来建立房价预测模型,并使用交叉验证等方法来评估模型的性能。
4. 结果分析:最后,我们对比了不同算法的预测效果和性能指标,得出了相关结论并提出了改进建议。
实验结果经过实验分析,我们发现决策树算法在这个数据集上表现较好,其预测准确性和泛化能力都较高。
而支持向量机和神经网络算法虽然在训练集上表现良好,但在测试集上的表现并不理想。
此外,特征选择对于模型的性能和复杂度也有着重要的影响。
结论与展望本实验通过Weka软件对房价预测数据集进行了挖掘分析,得出了不同算法的性能比较和结论。
未来,我们将进一步探索更多的数据挖掘技术和算法,以提高模型的预测准确性和实用性。
总结Weka 数据挖掘实验报告通过对房价预测数据集的挖掘分析,展示了Weka软件在数据挖掘领域的应用和优势。
通过本次实验,我们不仅对数据挖掘的流程和方法有了更深入的理解,也为未来的数据挖掘工作提供了一定的参考和借鉴。
数据挖掘实验报告Weka的数据聚类分析

甘肃政法学院本科生实验报告(2)姓名:学院:计算机科学学院专业:信息管理与信息系统班级:实验课程名称:数据挖掘实验日期:指导教师及职称:实验成绩:开课时间:2013—2014 学年一学期甘肃政法学院实验管理中心印制二.实验环境Win 7环境下的Eclipse三、实验内容在WEKA中实现K均值的算法,观察实验结果并进行分析。
四、实验过程与分析一、实验过程1、添加数据文件打开Weka的Explore,使用Open file点击打开本次实验所要使用的raff格式数据文件“auto93.raff”2、选择算法类型点击Cluster中的Choose,选择本次实验所要使用的算法类型“SimpleKMeans”3、得出实验结果选中“Cluster Mode”的“Use training set”,点击“Start”按钮,观察右边“Clusterer output”给出的聚类结果如下:=== Run information ===Scheme: weka.clusterers.SimpleKMeans -N 2 -S 10Relation: sInstances: 93Attributes: 23ManufacturerTypeCity_MPGHighway_MPGAir_Bags_standardDrive_train_typeNumber_of_cylindersEngine_sizeHorsepowerRPMEngine_revolutions_per_mile5528.8462 2622.3077 1 15.1346 4.7115 174.8654 100.2692 67.0385 36.8462 26.891 12.6069 2722.3077 0 16.4019Std Devs: N/A N/A 6.0746 5.7467 N/A N/A 0.7301 0.5047 40.8149 484.7019 377.1753 N/A 3.0204 0.848 11.2599 5.5735 2.4968 2.338 2.7753 2.3975 492.4971 N/A 7.9863Clustered Instances0 41 ( 44%)52 ( 56%)4、修改Seed值5、得出修改Seed值后的实验结果=== Run information ===Scheme: weka.clusterers.SimpleKMeans -N 2 -S 8Relation: sInstances: 93Attributes: 23ManufacturerTypeCity_MPGHighway_MPG二、实验分析本次实验采用的数据文件是“1993NewCarData ”。
数据挖掘WEKA实验报告

数据挖掘-WAKA实验报告一、WEKA软件简介在我所从事的证券行业中,存在着海量的信息和数据,但是这些数据日常知识发挥了一小部分的作用,其包含了大量的隐性的信息并不为所用,但是却可以为一些公司的决策和对客户的服务提供不小的价值。
因此,我们可以通过一些数据采集、数据挖掘来获得潜在的有价值的信息。
数据挖掘就是通过分析存在于数据库里的数据来解决问题。
在数据挖掘中计算机以电子化的形式存储数据,并且能自动的查询数据,通过关联规则、分类于回归、聚类分析等算法对数据进行一系列的处理,寻找和描述数据里的结构模式,进而挖掘出潜在的有用的信息。
数据挖掘就是通过分析存在于数据库里的数据来解决问题。
WEKA的出现让我们把数据挖掘无需编程即可轻松搞定。
WEKA是由新西兰怀卡托大学开发的开源项目,全名是怀卡托智能分析环境(WaikatoEnvironmentforKnowledgeAnalysis)。
WEKA是由JAVA编写的,WEKA得到,并且限制在GBU通用公众证书的条件下发布,可以运行在所有的操作系统中。
是一款免费的,非商业化的机器学习以及数据挖掘软件WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
如果想自己实现数据挖掘算法的话,可以看一看WEKA的接口文档。
在WEKA中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
安装WEKA也十分简单,首相要下载安装JDK环境,JDK在这个页面可以找到它的下载。
点击JDK6之后的Download按钮,转到下载页面。
选择Accepct,过一会儿页面会刷新。
我们需要的是这个WindowsOfflineInstallation,Multi-languagejdk-6-windows-i586.exe5 3.16MB,点击它下载。
也可以右键点击它上面的链接,在Flashget等工具中下载。
WEKA数据分析实验
WEKA 数据分析实验1.实验简介借助工具Weka 3.6 ,对数据样本进行测试,分类测试方法包括:朴素贝叶斯、决策树、随机数三类,聚类测试方法包括:DBScan,K均值两种;2.数据样本以熟悉数据分类的各类常用算法,以及了解Weka的使用方法为目的,本次试验中,采用的数据样本是Weka软件自带的“Vote”样本,如图:3.关联规则分析1)操作步骤:a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面b)选择“Associate”选项卡;c)点击“Choose”按钮,选择“Apriori”规则d)点击参数文本框框,在参数选项卡设置参数如:e)点击左侧“Start”按钮2)执行结果:=== Run information ===Scheme: weka.associations.Apriori -I -N 10 -T 0 -C 0.9 -D 0.05 -U 1.0 -M 0.5 -S -1.0 -c -1 Relation: voteInstances: 435Attributes: 17handicapped-infantswater-project-cost-sharingadoption-of-the-budget-resolutionphysician-fee-freezeel-salvador-aidreligious-groups-in-schoolsanti-satellite-test-banaid-to-nicaraguan-contrasmx-missileimmigrationsynfuels-corporation-cutbackeducation-spendingsuperfund-right-to-suecrimeduty-free-exportsexport-administration-act-south-africaClass=== Associator model (full training set) ===Apriori=======Minimum support: 0.5 (218 instances)Minimum metric <confidence>: 0.9Number of cycles performed: 10Generated sets of large itemsets:Size of set of large itemsets L(1): 12Large Itemsets L(1):handicapped-infants=n 236adoption-of-the-budget-resolution=y 253physician-fee-freeze=n 247religious-groups-in-schools=y 272anti-satellite-test-ban=y 239aid-to-nicaraguan-contras=y 242synfuels-corporation-cutback=n 264education-spending=n 233crime=y 248duty-free-exports=n 233export-administration-act-south-africa=y 269Class=democrat 267Size of set of large itemsets L(2): 4Large Itemsets L(2):adoption-of-the-budget-resolution=y physician-fee-freeze=n 219adoption-of-the-budget-resolution=y Class=democrat 231physician-fee-freeze=n Class=democrat 245aid-to-nicaraguan-contras=y Class=democrat 218Size of set of large itemsets L(3): 1Large Itemsets L(3):adoption-of-the-budget-resolution=y physician-fee-freeze=n Class=democrat 219Best rules found:1. adoption-of-the-budget-resolution=y physician-fee-freeze=n 219 ==> Class=democrat 219 conf:(1)2. physician-fee-freeze=n 247 ==> Class=democrat 245 conf:(0.99)3. adoption-of-the-budget-resolution=y Class=democrat 231 ==> physician-fee-freeze=n 219 conf:(0.95)4. Class=democrat 267 ==> physician-fee-freeze=n 245 conf:(0.92)5. adoption-of-the-budget-resolution=y 253 ==> Class=democrat 231 conf:(0.91)6. aid-to-nicaraguan-contras=y 242 ==> Class=democrat 218 conf:(0.9)3)结果分析:a)该样本数据,数据记录数435个,17个属性,进行了10轮测试b)最小支持度为0.5,即至少需要218个实例;c)最小置信度为0.9;d)进行了10轮搜索,频繁1项集12个,频繁2项集4个,频繁3项集1个;4.分类算法-随机树分析1)操作步骤:a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面b)选择“Classify ”选项卡;c)点击“Choose”按钮,选择“trees” “RandomTree”规则d)设置Cross-validation 为10次e)点击左侧“Start”按钮2)执行结果:=== Run information ===Scheme:weka.classifiers.trees.RandomTree -K 0 -M 1.0 -S 1Relation: voteInstances:435Attributes:17handicapped-infantswater-project-cost-sharingadoption-of-the-budget-resolutionphysician-fee-freezeel-salvador-aidreligious-groups-in-schoolsanti-satellite-test-banaid-to-nicaraguan-contrasmx-missileimmigrationsynfuels-corporation-cutbackeducation-spendingsuperfund-right-to-suecrimeduty-free-exportsexport-administration-act-south-africaClassTest mode:10-fold cross-validation=== Classifier model (full training set) ===RandomTree==========el-salvador-aid = n| physician-fee-freeze = n| | duty-free-exports = n| | | anti-satellite-test-ban = n| | | | synfuels-corporation-cutback = n| | | | | crime = n : republican (0.96/0)| | | | | crime = y| | | | | | handicapped-infants = n : democrat (2.02/0.01) | | | | | | handicapped-infants = y : democrat (0.05/0)| | | | synfuels-corporation-cutback = y| | | | | handicapped-infants = n : democrat (0.79/0.01)| | | | | handicapped-infants = y : democrat (2.12/0)| | | anti-satellite-test-ban = y| | | | adoption-of-the-budget-resolution = n| | | | | handicapped-infants = n : democrat (1.26/0.01)| | | | | handicapped-infants = y : republican (1.25/0.25)| | | | adoption-of-the-budget-resolution = y| | | | | handicapped-infants = n| | | | | | crime = n : democrat (5.94/0.01)| | | | | | crime = y : democrat (5.15/0.12)| | | | | handicapped-infants = y : democrat (36.99/0.09)| | duty-free-exports = y| | | crime = n : democrat (124.23/0.29)| | | crime = y| | | | handicapped-infants = n : democrat (16.9/0.38)| | | | handicapped-infants = y : democrat (8.99/0.02)| physician-fee-freeze = y| | immigration = n| | | education-spending = n| | | | crime = n : democrat (1.09/0)| | | | crime = y : democrat (1.01/0.01)| | | education-spending = y : republican (1.06/0.02)| | immigration = y| | | synfuels-corporation-cutback = n| | | | religious-groups-in-schools = n : republican (3.02/0.01)| | | | religious-groups-in-schools = y : republican (1.54/0.04)| | | synfuels-corporation-cutback = y : republican (1.06/0.05)el-salvador-aid = y| synfuels-corporation-cutback = n| | physician-fee-freeze = n| | | handicapped-infants = n| | | | superfund-right-to-sue = n| | | | | crime = n : democrat (1.36/0)| | | | | crime = y| | | | | | mx-missile = n : republican (1.01/0)| | | | | | mx-missile = y : democrat (1.01/0.01)| | | | superfund-right-to-sue = y : democrat (4.83/0.03)| | | handicapped-infants = y : democrat (8.42/0.02)| | physician-fee-freeze = y| | | adoption-of-the-budget-resolution = n| | | | export-administration-act-south-africa = n| | | | | mx-missile = n : republican (49.03/0)| | | | | mx-missile = y : democrat (0.11/0)| | | | export-administration-act-south-africa = y| | | | | duty-free-exports = n| | | | | | mx-missile = n : republican (60.67/0)| | | | | | mx-missile = y : republican (6.21/0.15)| | | | | duty-free-exports = y| | | | | | aid-to-nicaraguan-contras = n| | | | | | | water-project-cost-sharing = n| | | | | | | | mx-missile = n : republican (3.12/0)| | | | | | | | mx-missile = y : democrat (0.01/0)| | | | | | | water-project-cost-sharing = y : democrat (1.15/0.14) | | | | | | aid-to-nicaraguan-contras = y : republican (0.16/0)| | | adoption-of-the-budget-resolution = y| | | | anti-satellite-test-ban = n| | | | | immigration = n : democrat (2.01/0.01)| | | | | immigration = y| | | | | | water-project-cost-sharing = n| | | | | | | mx-missile = n : republican (1.63/0)| | | | | | | mx-missile = y : republican (1.01/0.01)| | | | | | water-project-cost-sharing = y| | | | | | | superfund-right-to-sue = n : republican (0.45/0)| | | | | | | superfund-right-to-sue = y : republican (1.71/0.64) | | | | anti-satellite-test-ban = y| | | | | mx-missile = n : republican (7.74/0)| | | | | mx-missile = y : republican (4.05/0.03)| synfuels-corporation-cutback = y| | adoption-of-the-budget-resolution = n| | | superfund-right-to-sue = n| | | | anti-satellite-test-ban = n| | | | | physician-fee-freeze = n : democrat (1.39/0.01)| | | | | physician-fee-freeze = y| | | | | | water-project-cost-sharing = n : republican (1.01/0)| | | | | | water-project-cost-sharing = y : democrat (1.05/0.05)| | | | anti-satellite-test-ban = y : democrat (1.13/0.01)| | | superfund-right-to-sue = y| | | | education-spending = n| | | | | physician-fee-freeze = n| | | | | | crime = n : democrat (0.09/0)| | | | | | crime = y| | | | | | | handicapped-infants = n : democrat (1.01/0.01)| | | | | | | handicapped-infants = y : democrat (1/0)| | | | | physician-fee-freeze = y| | | | | | immigration = n| | | | | | | export-administration-act-south-africa = n : democrat(0.34/0.11)| | | | | | | export-administration-act-south-africa = y| | | | | | | | crime = n : democrat (0.16/0)| | | | | | | | crime = y| | | | | | | | | mx-missile = n| | | | | | | | | | handicapped-infants = n : republican (0.29/0) | | | | | | | | | | handicapped-infants = y : republican (1.88/0.87) | | | | | | | | | mx-missile = y : democrat (0.01/0)| | | | | | immigration = y : republican (1.01/0)| | | | education-spending = y| | | | | physician-fee-freeze = n| | | | | | handicapped-infants = n : democrat (1.51/0.01)| | | | | | handicapped-infants = y : democrat (2.01/0)| | | | | physician-fee-freeze = y| | | | | | crime = n : republican (1.02/0)| | | | | | crime = y| | | | | | | export-administration-act-south-africa = n| | | | | | | | handicapped-infants = n| | | | | | | | | immigration = n| | | | | | | | | | mx-missile = n| | | | | | | | | | | water-project-cost-sharing = n : democrat (1.01/0.01)| | | | | | | | | | | water-project-cost-sharing = y : republican (1.81/0)| | | | | | | | | | mx-missile = y : democrat (0.01/0)| | | | | | | | | immigration = y| | | | | | | | | | mx-missile = n : republican (2.78/0)| | | | | | | | | | mx-missile = y : democrat (0.01/0)| | | | | | | | handicapped-infants = y| | | | | | | | | mx-missile = n : republican (2/0)| | | | | | | | | mx-missile = y : democrat (0.4/0)| | | | | | | export-administration-act-south-africa = y| | | | | | | | mx-missile = n : republican (8.77/0)| | | | | | | | mx-missile = y : democrat (0.02/0)| | adoption-of-the-budget-resolution = y| | | anti-satellite-test-ban = n| | | | handicapped-infants = n| | | | | crime = n : democrat (2.52/0.01)| | | | | crime = y : democrat (7.65/0.07)| | | | handicapped-infants = y : democrat (10.83/0.02)| | | anti-satellite-test-ban = y| | | | physician-fee-freeze = n| | | | | handicapped-infants = n| | | | | | crime = n : democrat (2.42/0.01)| | | | | | crime = y : democrat (2.28/0.03)| | | | | handicapped-infants = y : democrat (4.17/0.01)| | | | physician-fee-freeze = y| | | | | mx-missile = n : republican (2.3/0)| | | | | mx-missile = y : democrat (0.01/0)Size of the tree : 143Time taken to build model: 0.01seconds=== Stratified cross-validation ====== Summary ===Correctly Classified Instances 407 93.5632 %Incorrectly Classified Instances 28 6.4368 %Kappa statistic 0.8636Mean absolute error 0.0699Root mean squared error 0.2379Relative absolute error 14.7341 %Root relative squared error 48.8605 %Total Number of Instances 435=== Detailed Accuracy By Class ===TP Rate FP Rate Precision Recall F-Measure ROC Area Class0.955 0.095 0.941 0.955 0.948 0.966 democrat0.905 0.045 0.927 0.905 0.916 0.967 republicanWeighted Avg. 0.936 0.076 0.936 0.936 0.935 0.966 === Confusion Matrix ===a b <-- classified as255 12 | a = democrat16 152 | b = republican3)结果分析:a)该样本数据,数据记录数435个,17个属性,进行了10轮交叉验证b)随机树长143c)正确分类共407个,正确率达93.5632 %d)错误分类28个,错误率6.4368 %e)测试数据的正确率较好5.分类算法-随机树分析1)操作步骤:a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面b)选择“Classify ”选项卡;c)点击“Choose”按钮,选择“trees” “J48”规则d)设置Cross-validation 为10次e)点击左侧“Start”按钮2)执行结果:=== Run information ===Scheme:weka.classifiers.trees.J48 -C 0.25 -M 2Relation: voteInstances:435Attributes:17handicapped-infantswater-project-cost-sharingadoption-of-the-budget-resolutionphysician-fee-freezeel-salvador-aidreligious-groups-in-schoolsanti-satellite-test-banaid-to-nicaraguan-contrasmx-missileimmigrationsynfuels-corporation-cutbackeducation-spendingsuperfund-right-to-suecrimeduty-free-exportsexport-administration-act-south-africaClassTest mode:10-fold cross-validation=== Classifier model (full training set) ===J48 pruned tree------------------physician-fee-freeze = n: democrat (253.41/3.75)physician-fee-freeze = y| synfuels-corporation-cutback = n: republican (145.71/4.0)| synfuels-corporation-cutback = y| | mx-missile = n| | | adoption-of-the-budget-resolution = n: republican (22.61/3.32) | | | adoption-of-the-budget-resolution = y| | | | anti-satellite-test-ban = n: democrat (5.04/0.02)| | | | anti-satellite-test-ban = y: republican (2.21)| | mx-missile = y: democrat (6.03/1.03)Number of Leaves : 6Size of the tree : 11Time taken to build model: 0.06seconds=== Stratified cross-validation ====== Summary ===Correctly Classified Instances 419 96.3218 % Incorrectly Classified Instances 16 3.6782 % Kappa statistic 0.9224Mean absolute error 0.0611Root mean squared error 0.1748Relative absolute error 12.887 %Root relative squared error 35.9085 %Total Number of Instances 435=== Detailed Accuracy By Class ===TP Rate FP Rate Precision Recall F-Measure ROC Area Class0.97 0.048 0.97 0.97 0.97 0.971 democrat0.952 0.03 0.952 0.952 0.952 0.971 republicanWeighted Avg. 0.963 0.041 0.963 0.963 0.963 0.971=== Confusion Matrix ===a b <-- classified as259 8 | a = democrat8 160 | b = republican3)结果分析:a)该样本数据,数据记录数435个,17个属性,进行了10轮交叉验证b)决策树分6级,长度11c)正确分类共419个,正确率达96.3218 %d)错误分类16个,错误率3.6782 %e)测试结果接近随机数,正确率较高6.分类算法-朴素贝叶斯分析1)操作步骤:a)点击“Explorer”按钮,弹出“Weka Explorer”控制界面b)选择“Classify ”选项卡;c)点击“Choose”按钮,选择“bayes” “Naive Bayes”规则d)设置Cross-validation 为10次e)点击左侧“Start”按钮2)执行结果:=== Stratified cross-validation ====== Summary ===Correctly Classified Instances 392 90.1149 %Incorrectly Classified Instances 43 9.8851 %Kappa statistic 0.7949Mean absolute error 0.0995Root mean squared error 0.2977Relative absolute error 20.9815 %Root relative squared error 61.1406 %Total Number of Instances 435=== Detailed Accuracy By Class ===TP Rate FP Rate Precision Recall F-Measure ROC Area Class0.891 0.083 0.944 0.891 0.917 0.973democrat0.917 0.109 0.842 0.917 0.877 0.973republicanWeighted Avg. 0.901 0.093 0.905 0.901 0.902 0.973 === Confusion Matrix ===a b <-- classified as238 29 | a = democrat14 154 | b = republican3)结果分析a)该样本数据,数据记录数435个,17个属性,进行了10轮交叉验证b)正确分类共392个,正确率达90.1149 %c)错误分类43个,错误率9.8851 %d)测试正确率较高7.分类算法-RandomTree、决策树、朴素贝叶斯结果比较:RandomTree 决策树朴素贝叶斯正确率93.5632% 96.3218 % 90.1149 %混淆矩阵 a b <-- classified as255 12 | a = democrat16 152 | b = republican a b <-- classified as259 8 | a = democrat8 160 | b = republicana b <-- classified as238 29 | a = democrat14 154 | b =republican标准误差48.8605 % 35.9085 % 61.1406 % 根据以上对照结果,三类分类算法对样板数据Vote测试准确率类似;8.。
数据挖掘weka实验报告

数据挖掘weka实验报告数据挖掘Weka实验报告引言:数据挖掘是一门利用统计学、人工智能和机器学习等技术从大量数据中提取有用信息的学科。
Weka是一款强大的数据挖掘工具,它提供了丰富的算法和功能,使得数据挖掘变得更加容易和高效。
本文将对Weka进行实验,探索其在数据挖掘中的应用。
一、数据集选择和预处理在本次实验中,我们选择了一个关于房价的数据集作为实验对象。
该数据集包含了房屋的各种属性,如面积、位置、卧室数量等,以及对应的房价。
首先,我们需要对数据集进行预处理,以便更好地进行数据挖掘。
1. 缺失值处理在数据集中,我们发现了一些缺失值。
为了保证数据的完整性和准确性,我们采用了Weka提供的缺失值处理方法,如删除缺失值、插补缺失值等。
通过比较不同方法的效果,我们选择了最适合数据集的缺失值处理方式。
2. 特征选择数据集中可能存在一些冗余或无关的特征,这些特征对于数据挖掘的结果可能没有太大的贡献。
因此,我们使用Weka中的特征选择算法,如信息增益、卡方检验等,来选择最具有代表性和相关性的特征。
二、数据挖掘算法应用在预处理完成后,我们开始应用各种数据挖掘算法,探索数据集中隐藏的规律和模式。
1. 分类算法我们首先尝试了几种分类算法,如决策树、朴素贝叶斯等。
通过比较不同算法的准确率、召回率和F1值等指标,我们找到了最适合该数据集的分类算法,并对其进行了优化。
2. 聚类算法除了分类算法,我们还尝试了一些聚类算法,如K均值聚类、层次聚类等。
通过可视化聚类结果,我们发现了数据集中的一些簇,从而更好地理解了数据集的结构和分布。
3. 关联规则挖掘关联规则挖掘是一种发现数据集中项集之间关系的方法。
我们使用了Apriori算法来挖掘数据集中的关联规则,并通过支持度和置信度等指标进行评估。
通过发现关联规则,我们可以了解到不同属性之间的相关性和依赖性。
三、实验结果分析通过实验,我们得到了一系列数据挖掘的结果。
根据实验结果,我们可以得出以下结论:1. 分类算法的准确率较高,可以用于预测房价等问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
WEKA 3-5-3 Experimenter 指南原文版本3.5.3原文链接翻译王娜校对 C6H5NO2Pentaho 中文讨论组QQ 群:12635055论坛:/bipub/index.aspDavid ScusePeter ReutemannJune 8, 20061 简介 (1)2 标准试验 (2)2.1 简单模式 (2)2.1.1 新试验 (2)2.1.2 结果的目的文件 (2)2.1.3 试验类型 (4)2.1.4 数据集 (5)2.1.5 迭代控制 (6)2.1.6 算法 (6)2.1.7 保存设置 (8)2.1.8 运行试验 (8)2.2 高级模式 (9)2.2.1 定义试验 (9)2.2.2 运行试验 (12)2.2.3 改变试验参数 (13)2.2.4 其他结果的产生 (19)3 远程试验 (23)3.1 准备 (23)3.2 数据库服务器设置 (23)3.3 远程引擎安装 (23)3.4 配置 Experimenter (24)3.5 疑难问题解答 (24)4 分析结果 (25)4.1 设置 (25)4.2 保存结果 (28)4.3 改变基准算法 (28)4.4 统计显著性 (29)4.5 描述性检验 (29)4.6 排序检验 (29)5 参考文献 (30)1简介Weka 试验(Experiment)环境可以让用户创建,运行,修改和分析算法试验,这也许比单独的分析各个算法更加方便。
例如,用户可创建一次试验,在一系列数据集上运行多个算法(schemes),然后分析结果以判断是否某个算法比其他算法(在统计意义下)更好。
可以通过 Simple CLI 在命令行的方式下运行试验环境。
例如,在 CLI 上键入以下命令,将通过一个基本的训练和测试步骤在 Iris 数据集上运行 OneR 算法。
(注意该命令应放在同一行中输入CLI。
)java weka.experiment.Experiment -r -T data/iris.arff−D weka.experiment.InstancesResultListener−P weka.experiment .RandomSplitResultProducer --−W weka. experiment .ClassifierSplitEvaluator --−W weka. classifiers. rules. OneR然而直接把命令直接输入 CLI 这种方式并不是很方便,且试验不容易修改。
Experimenter 有两种模式:一种具有较简单的界面,并提供了试验所需要的大部分功能,另一种则提供了一个可以使用 Experimenter 所有功能的界面。
你可使用Experiment Configuration Mode 单选按钮在这两者间进行选择。
¾Simple¾Advanced在两种模式下,你都进行在本地单一机器上的标准试验,或者分布在几台主机上的远程试验。
分布式的试验减少了完成试验本身所需的时间,但是另一方面,设置这样的试验需要更多的时间。
以下的章节节将介绍标准试验(包括simple 和 advanced模式),然后是远程试验,最后部分是结果的分析。
这个手册也可在WekaDoc Wiki [5] 上找到。
2标准试验2.1Simple(简单)模式2.1.1新试验在点击 New 后,就定义了一次试验的默认参数。
2.1.2Result Destination (结果的目的文件)一个 ARFF 文件将默认作为结果输出的目的文件。
但你也可选择:¾ARFF file (ARFF 文件)¾CSV file (CSV 文件)¾JDBC database (JDBC 数据库)以下章节将详细讨论 ARFF 文件和 JDBC 数据库。
CSV 类似于 ARFF,但它可以用其他的电子表格程序加载。
2.1.2.1ARFF file如果文件名为空,将在系统的 TEMP 目录下创建一个临时文件。
如果你想显式的指定一个结果文件,只需点击 Browse,并选一个文件名,例如 Experiment1.arff。
点击 Save,文件路径将出现在 ARFF file 旁的文本框中。
ARFF 或 CSV 文件的优点是它们的创建不需要 Weka 之外的类文件。
它们的缺点则是试验一被中断就无法继续进行,所谓中断包括出现错误,添加数据集或添加算法。
尤其对于那些相当耗时的试验,这一不足会增加很多麻烦。
2.1.2.2JDBC database有了 JDBC,就可以很容易的把结果存储在数据库中。
要使用某种特定数据库的 JDBC 功能,必须在CLASSPATH 中指定相应的 jar 文件。
把 ARFF file 改成 JDBC database 后,点击 User... 来指定访问数据库的 JDBC URL 和用户帐号。
在提供了必要的数据并点击 OK 后,主窗口中的 URL将会更新。
注意:这个时候还没有测试数据库连接;启动试验时才会进行连接测试。
JDBC 数据库的优点是可以继续运行那些被中止的或扩展了的试验。
它不用重新运行那些已试验过的算法/数据集组合,而仅计算还没有被试验的那些。
2.1.3Experiment type(试验类型)用户可选择以下三种不同的类型:¾Cross-validation (交叉验证)(默认):根据给定的折数执行分层交叉验证¾Train/Test Percentage Split (data randomized) (按比例分割训练/测试集,随机挑选数据):把数据打乱顺序并确定层次后,根据给定的百分比把这个数据集分割成一个训练文件和一个测试文件(在 Experimenter 中,不能显式的指定训练文件和测试文件)¾Train/Test Percentage Split (order preserved) (按比例分割训练/测试集,按顺序挑选数据):因为不能显式的指定训练/测试文件对,可以利用这个试验类型把合并过的训练和测试文件还原(只需找到正确的比例)而且,可在 Classification(分类,又称判别)和 Regression(回归)间进行选择,这依赖于所用的数据集和分类器1(classifiers)。
对于像J48 (即 Quinlan 的 C4.5 算法 [3] 在 Weka 中的实现) 这样的决策树算法和 iris 数据集,Classification 是必需的;另一方面,对于 M5P 这样的数值型分类器,则需要选用Regression。
默认选中的是 Classification。
注意:如果使用了按比例分割,必须确保修正过的成对 T 检验在给定的比值下仍能产生有意义的结果 [2]。
2.1.4Datasets (数据集)可以通过绝对路径或相对路径添加数据集文件。
后者使得在不同的机器上运行试验更加方便,因此你在点击 Add new....之前,应该勾选Use relative paths (使用相对路径)。
在这个例子中,打开 data 目录,选择 iris.arff 数据集。
1 WEKA 把用于分类和回归的算法都叫做分类器--译注。
在点击 Open 后,文件将显示在数据集列表中。
如果选中一个目录点击 Open,那么将递归的添加所有 ARFF 文件。
从列表删除文件时,可选中那些文件,然后点击 Delete selected。
2.1.5Iteration control (迭代控制)¾Number of repetitions (重复次数):为了获得统计上有意义的结果,默认的迭代数量是 10。
在10折交叉验证的情形下,这意味着对一个分类器要进行100次调用——从训练集计算它,并在测试集上测试。
¾Data sets first/Algorithms first (数据集优先/算法优先):当存在多个数据集和算法的时候,切换成优先迭代数据集的模式可能会有用。
举个例子,会有人把结果存储在数据库中,并且想尽早完成某个算法在所有数据集上的结果。
2.1.6Algorithms (算法)可以通过 Add new... 按钮添加新算法。
如果是第一次打开这个对话框,将出现 ZeroR;否则将出现上次选中的那个。
可以用 Choose 按钮打开 GenericObjectEditor 来选择别的分类器。
有的分类器仅针对某种特定类型的属性(attribute)和目标属性(class),使用Filter... 按钮能够加亮显示它们。
点击Remove filter,加亮显示又会被取消。
可使用 Add new... 按钮继续添加其他的算法,如 J48 决策树。
在设置好分类器的参数后,可点击 OK 将之添加进算法列表。
使用 Load options... 和 Save options... 按钮,你可从 XML 加载或保存选中分类器的设置。
这对配置相当复杂的分类器(如 nested meta-分类器)尤其有用,因为手动设置它们需要一些时间,却又经常要用到。
2.1.7保存设置为了将来能重复使用,可将试验的当前设置保存进一个文件,点击窗口顶部的 Save... 即可。
试验文件默认的的格式是 Java 序列化提供的二进制文件。
这个格式的缺点是不同版本的 Weka 间可能存在格式的不兼容性。
还有一种更加健壮的XML格式可供选择。
可通过 Open... 按钮重新装载之前保存的 experiments。
2.1.8运行试验要运行当前试验,需点击试验环境窗口中的 Run 标签页。
当前试验将使用 ZeroR 和 J48 算法在Iris 数据集上执行十次10折的分层交叉验证。
点击 Start 运行试验。
如果试验定义正确,在 Log 面板上将显示如上 3 条信息。
试验结果保存在 Experiment1. arff 数据集里。
2.2Advanced (高级)模式2.2.1定义试验切换到 Setup 标签页,在高级模式下开始试验。
点击 New 以初始化一次试验。
这样为试验给定了默认的参数。
要给定由算法所处理的数据集,先在 Setup 标签页的 Datasets 面板上选择 Use relative paths,然后点击 Add new... 打开一个对话框窗口。
可以双击 data 文件夹查看可用的数据集,也可以浏览到其它的位置。
选择 iris.arff,点击 Open 选择 Iris 数据集。
数据集名现在显示在 Setup 标签页的 Datasets 面板。
2.2.1.1保存试验结果要指定结果保存的数据集,点击 Destination面板上的 InstancesResultListener 条目。