spss聚类分析案例
SPSS聚类分析加具体案例
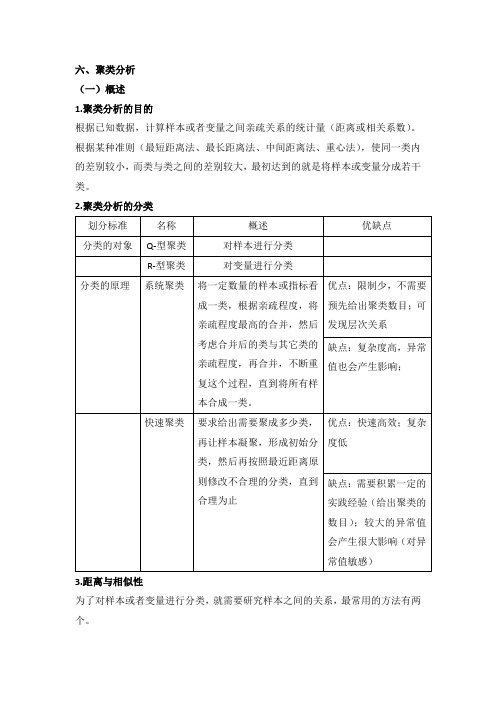
六、聚类分析(一)概述1.聚类分析的目的根据已知数据,计算样本或者变量之间亲疏关系的统计量(距离或相关系数)。
根据某种准则(最短距离法、最长距离法、中间距离法、重心法),使同一类内的差别较小,而类与类之间的差别较大,最初达到的就是将样本或变量分成若干类。
2.聚类分析的分类3.距离与相似性为了对样本或者变量进行分类,就需要研究样本之间的关系,最常用的方法有两个。
(二)系统聚类1.系统聚类的步骤距离的具体定义及计算方式计算n各样本两两之间的距离将距离接近的数据依次合并为一类,再计算,再合并 画聚类图,解释类与类之间的关系2.亲疏程度度量方法3.系统聚类的分类4.SPSS操作及实例SPSS采用的是凝聚法。
案例:根据30个省的23个主要行业的平均工资情况,通过聚类分析来判断哪些地区平均工资水平高。
SPSS操作及结果:打开SPSS上方菜单栏中的分析->分类->系统聚类选择变量->勾选统计量->在绘制里选择树状图和冰柱图勾选方法(通常使用组间联接)->度量区间->选择标准化方式(全距从0到1)下图为近似矩阵表,标注了相关系数,数值越大,距离越接近下图为聚类分析结果表,第一类表示这是聚类分析的第几步,第二三列表示该步中那几个样本或者小类聚成一类,第四列表示距离,第五六列表示本步骤中参与的是个体还是小类(0表示样本,非0表示第n步生成的小类),第七列表示本步骤的聚类结果将在以下第几步中用到。
下面是冰柱图和树状图的结果,根据树状图可以看出,如果分为三类的话,第一类包括北京上海,第二类包括天津、广东、浙江、江苏、西藏,剩下的归为一类。
(三)快速聚类(适合大样本聚类)1.快速聚类的步骤指定聚类数目K确定K个初始类的中心(自定义或者根据数据中心初步确定)根据距离最近的原则进行分类根据新的中心位置,重新计算每一记录距离新的类别中心的的距离,并重新分类重复步骤4,直到达到标准2.SPSS操作及实例打开SPSS上方菜单栏中的分析->分类->K-均值聚类选择变量->勾选统计量->定义变量值选择迭代次数->选项(勾选初始聚类中心、每个个案的聚类信息)->定义变量值->保存(勾选聚类成员、聚类中心距离)下图为输出的初始聚类中心下图为最终距离中心,第一类平均工资最高,第二类次之,第三类最低下图为每个聚类中的案例数和聚类成员。
SPSS聚类分析实例讲解

SPSS聚类分析实例讲解SPSS是一款功能强大的统计分析软件,可用于数据清洗、描述统计分析、假设检验和聚类分析等。
聚类分析是一种无监督学习方法,其目标是按照数据的相似性度量,将样本数据划分为多个不同的群组。
下面将以一个实例来讲解如何使用SPSS进行聚类分析。
实例描述:假设有一个超市的销售数据,包含了不同商品的销售额、销售量和利润等信息。
我们希望将商品进行聚类分析,找出相似销售特征的商品群组。
步骤一:数据准备首先,将销售数据保存为一个.SP文件,然后打开SPSS软件。
在主界面上选择“文件”-“打开”-“数据库”-“从SPSS文件”,打开数据文件。
步骤二:变量选择在数据文件中,选择出要进行聚类分析的变量。
在“数据视图”中,选择那些代表销售特征的变量,例如“销售额”、“销售量”和“利润”。
在变量列上按住“Ctrl”键,同时点击这些变量名,选中它们。
步骤三:聚类分析点击菜单上的“数据”-“服务”-“聚类分析”进行聚类分析操作。
会弹出“聚类分析”对话框。
在对话框中,将选中的变量移到右侧的“变量”框中,并选择“K均值聚类”作为聚类方法。
K值是指要分成的群组数量,可以根据实际情况设定。
这里假设将商品分成3个群组,因此设置为3步骤四:聚类结果解读点击“确定”按钮,SPSS将自动进行聚类分析。
完成后,SPSS会在数据文件中生成一个新的变量,用于表示每个样本所属的群组。
在下方的“结果视图”中,可以看到聚类结果的统计数据、聚类中心和变量间的距离。
此外,在“分类变量资料”中,还可以看到每个样本所属的群组编号。
步骤五:聚类结果可视化为了更好地理解聚类结果,可以进行可视化展示。
点击菜单上的“图形”-“散点图”,在对话框中依次选择所属群组变量和销售额、销售量这两个变量。
点击“确定”按钮,即可生成散点图。
散点图可以清楚地显示出不同群组之间的差异和相似性。
根据散点图,可以对聚类结果进行解读。
例如,如果不同群组之间的点比较分散,则说明聚类效果较差;而如果不同群组之间的点比较集中,则说明聚类效果较好。
spss综合案例分析国家统计局

spss综合案例分析国家统计局
(一)实验目的
近年来随着现代化和工业化的进程,我国大气污染状况十分严重,主要呈现煤烟型污染特征,城市大气环境中总悬浮颗粒浓度普遍超标、二氧化硫污染保持在较高水平、机动车尾气污染物排放总量迅速增加、氮氧化物污染趋势加重、全国形成多个酸雨区等,危害生态环境、影响人民群众身体健康。
从污染物构成来看,我国大气污染来源主要有三个方面:一是生活污染源,包括饮食或取暖时燃料向大气排放有害气体和烟雾;二是工业污染源,包括火力发电、钢铁和有色金属冶炼,各种化学工业给大气造成的污染;三是交通污染源,包括汽车、飞机、火车、船舶等交通工具的煤烟、尾气排放。
本文通过聚类分析和主成分分析法,研究我国主要城市的空气质量,以及各参数对空气质量好坏的影响以及最主要的影响因素。
并据此提出科学合理的对策建议。
(二)问题描述
在2013年之前,大部分人对于雾霾天气的认知都会自然而然觉
得是的事。
然而,12月伊始,我国遭受了入冬以来最大围雾霾天气,今年12月伊始,我国中东部地区迎来了严重雾霾事件,几乎涉及中
东部所有地区。
天津等多地空气质量指数达到六级严重污染级别,使得京津冀与长三角雾霾连成片。
由于能见度过低,导致多处高速公路封道关
闭,给车辆出行带来了不便,也严重影响了市民的正常工作与生活。
(三)数据来源
通过查询“中华人民国国家统计局官方”的“国家统计数据库”,《中国统计年鉴》获得。
(四)案例中使用的SPSS方法
1.描述性分析
2.相关分析
3.聚类分析
4.主成分分析。
spss聚类分析案例

spss聚类分析案例在进行SPSS聚类分析时,我们通常会遵循一系列步骤来确保分析的准确性和有效性。
以下是一个典型的聚类分析案例,展示了如何使用SPSS软件进行数据分析。
首先,我们需要收集数据。
数据可以是定量的,也可以是定性的,但必须与研究问题相关。
例如,如果我们正在研究消费者购买行为,我们可能会收集关于消费者年龄、收入、购买频率和偏好的数据。
接下来,我们将数据导入SPSS。
这可以通过直接输入数据、从Excel文件导入或使用SPSS的数据导入向导来完成。
一旦数据在SPSS中,我们需要检查数据的准确性和完整性,确保没有缺失值或异常值。
在进行聚类分析之前,我们通常需要对数据进行预处理。
这可能包括标准化变量、处理缺失值和异常值,以及可能的变量转换。
标准化是重要的,因为它确保了所有变量在聚类分析中具有相同的权重。
然后,我们选择聚类方法。
SPSS提供了几种聚类方法,包括K-means聚类、层次聚类和双向聚类。
选择哪种方法取决于数据的特性和研究目的。
例如,如果我们有明确的类别数量,K-means聚类可能是合适的;如果我们希望看到数据的层次结构,层次聚类可能更合适。
在选择了聚类方法后,我们需要确定聚类的数量。
这可以通过多种方法来确定,包括肘部方法、轮廓系数或基于信息准则的方法。
确定聚类数量后,我们可以运行聚类算法,并将数据点分配到不同的聚类中。
聚类完成后,我们需要评估聚类的质量。
这可以通过查看聚类的内部一致性和聚类之间的差异来完成。
我们还可以进行统计测试,如ANOVA或卡方检验,来检验聚类是否在统计上显著。
最后,我们解释聚类结果。
这包括识别每个聚类的特征,以及这些特征如何与研究问题相关。
例如,如果我们发现一个聚类主要由高收入、频繁购买的消费者组成,这可能表明这是一个高价值的市场细分。
在整个聚类分析过程中,我们可能会进行多次迭代,调整聚类方法、聚类数量或数据预处理步骤,以获得最佳的聚类结果。
聚类分析是一个动态的过程,需要根据数据和研究目的进行调整。
SPSS教程-聚类分析-附实例操作

各地区各行业工资水平的分析(2009年数据)小组成员:张艺伟、赵月、陈媛、邹莉、朱海龙、曾磊、胡瑛、候银萍1.研究背景及意义1.1 研究背景工资水平是指一定区域和一定时间内劳动者平均收入的高低程度。
生产决定分配,只有经济发展才能提供更多的可分配的社会产品,因此一个地区的工资水平在一定程度上反映了其经济发展的水平。
1.2 研究意义1. 通过多元统计分析方法,探究一个地区的工资水平与其经济发展水平之间的内在联系。
2. 将平均工资水平划分为3类,分析哪些地区、哪些行业的工资水平较高,可以为大学生就业提供宏观上的方向指引。
2.数据来源与描述2.1 数据来源——《中国劳动统计年鉴─2010》(URL:/Navi/YearBook.aspx?id=N2011010069&floor=1###)主编单位:国家统计局人口和就业统计司,人力资源和社会保障部规划财务司出版社:中国统计出版社简介:《中国劳动统计年鉴─2010》是一部全面反映中华人民共和国劳动经济情况的资料性年刊。
本刊收集了2009年全国和各省、自治区、直辖市、香港特别行政区、澳门特别行政区的有关劳动统计数据。
本书资料的取得形式主要有国家和部门的报表统计、行政记录和抽样调查。
2.2 数据描述本数据集记录了全国31个省市(港、澳、台除外)的工资状况,各省市分别记录了其23个主要行业的平均工资水平,这23个主要行业包括:企业、事业、机关、金融业、制造业、建筑业、房地产业、农林牧渔业等等,具体数据格式参见图-0。
图-03.分析方法及原理3.1 通过描述统计分析方法,判断哪些行业平均工资水平较高描述统计分析方法主要是从基本统计量(诸如均值、方差、标准差、极大/小值、偏度、峰度等)的计算和描述开始的,并辅助于SPSS提供的图形功能,能够把握数据的基本特征和整体的分布特征。
在本案例中,通过比较不同行业(诸如企业、事业、机关、建筑业、制造业……)工资的均值、极大/小值,可以从总体上判断哪些行业的平均工资水平较高,哪些行业的较低。
spss样本聚类案例分析

原数据名称总人口从业人员土地面积耕地面积财政收入粮食产量龙固镇58089.0029906.005302.002670.004435.0026564.00杨屯頸56235.0024033.004100.002040.001874.0028327.00大屯镇82418.0035558.007380.003793.005370.0037803.00沛城镇84487.0052675.006600.005161.006085.0050950.00胡寨镇37952.0020190.004594.002727.001779.0032305.00魏庙镇53677.0031875.005200.003706.001974.0029220.00五段镇45860.0021148.004700.002800.002099.0042762.00张庄镇90950.0042858.0011200.006800.001695.0035511.00张寨镇89017.0038344.0010634.006847.003028.004739.00敬安镇63200.0031940.009600.005003.002638.0026260.00河口镇58895.0029580.008257.005324.001655.0010821.00栖山頸63711.0026292.008951.006386.002203.00494.00鹿楼镇71143.0035285.0012540.005991.002250.0040500.00朱寨镇60112.0025776.007900.004482.001449.0033611.00安国镇85083.0051974.0013329.005634.004313.0033911.00------------1・1样本聚类(Q聚类)JJU .00 Ib^.UU Jbbll.UU 30方0D 4739.00.00.00至统嶷类分析:统才蛍.00.00.00.00 ◎无迥)' •单一方买⑤鬆类»(Bj:最小惑数勉:[缝绫II取希II帮助I聚类表通过系数做出其散点图群集成员案例群集数使用平均联接(组间)的树状图重新调整距离聚类合并1.2变量聚类(R 聚类)近似矩阵案例矩阵文件输入总人口从业人 员土地面积耕地面 积 财政收 入粮食产 量总人口 1.000 .857 .698 .714 .512 .043 从业人.8571.000.597.570.643.277员土地面.698.5971.000.856.044-.147积耕地面.714.570.8561.000 -.001-.335积21M8.C0 U70J.C0 2EO3.C0 GEODCO羽丸d 31940 2^60CO 26292 CO劇a 标皿35265 CO®EXal|N):5776 CO 引97」CO卡方血 0计砲• |転瓦ndzn 距阉O 二分卷回:咖SUB忝统蟹凭分析:力链厂沱屯<3丄)I 卿符弓也丄刼碇到01全距归4255B.C011ZOD.CO 咖 3427G2.C01SK.C0 2S511.CO[齢]躺般|/总人口 少丛业人员 少土地面枳 炉辭地而枳细 Q...方法妙财政收.512 .643 .044 001 1.000 .342 入粮食产.043 .277 -147 335 .342 1.000 量聚类表群集成员案例粮您产蜀财政收入耕地面枳土地面枳从业人员总人口使用平均联接(纽间)的树状图2. K—均值聚类原数据描述统计量:均值聚类分析:…冈星H 初始聚类中心(!)ffl gNOVA 表(A)■■“ ••“ ••“ •■“ •••• •■“ ・•••••••••••••••••••••••••• •••• •••• IN极小值 极大值均值 标准差身髙月平均增长19.3411.03 1.88422. 5634率2体重月平均增长19.4950. 30 5. 6363 11. 718率14胸围月平均增长19.1611.81 1.49582. 7933率9坐髙月平均增长19.1411.27 1. 71112. 8070率9有效的N (列表19状态)66153049J714212-.12513K3-.046697卅K 均佰垦艮分・・・区)|E 标准©O[竝]确用|缺失值@按列表排除个案也)O按对排除个案Q输出结果:初始聚类中心迭代历史记录4a.由于聚类中心内没有改动或改动较小而达到收敛。
基于SPSS用K-means聚类做聚类分析
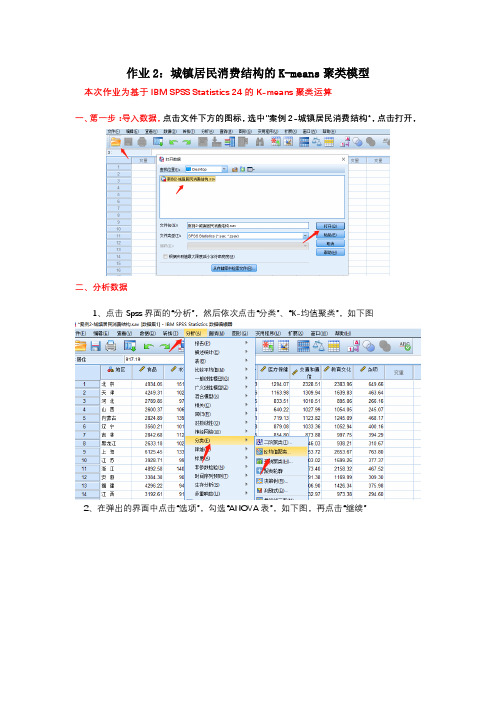
作业2:城镇居民消费结构的K-means聚类模型
本次作业为基于IBM SPSS Statistics 24的K-means聚类运算
一、第一步:导入数据,点击文件下方的图标,选中”案例2-城镇居民消费结构“,点击打开,
二、分析数据
1、点击Spss界面的“分析”,然后依次点击“分类”、“K-均值聚类”,如下图
2、在弹出的界面中点击“选项”,勾选“ANOVA表”,如下图,再点击“继续”
3、在弹出的界面中点击“保存”,勾选“聚类成员”、“与聚类中心距离”,如下图所示,点击“继续”
4、最后在弹出的界面中,把“地区”放入“个案标注依据”,其余的放入“变量”中,如下图所示,点击“确定”。
三、结果展示
ANOVA。
聚类分析 spss

聚类分析聚类分析的目的是将资料按相似程度进行分类。
分类的对象可以是指标(变量)也可以是观测数据。
分类方法大致可分为两类:系统聚类法和非系统聚类法。
一、系统聚类法1.适用范围:可对观测数据或变量进行聚类2.聚类原理:3.聚类方法:组间连接法(类平均法)、组内连接法、最远距离法、ward 法等7 种。
4.Spss 的实现例1 生物学家收集了21种蝴蝶花样本的4个指标:萼片长度()1x ,萼片宽度()2x ,花瓣长度()3x ,花瓣宽度()4x ,数据如下表。
试进行聚类分析。
序号 1x 2x 3x 4x序号 1x 2x 3x 4x序号 1x 2x 3x 4x1 50 24 342 2 55 23 33 2 3 50 47 44 21 4 55 46 35 18 5 55 46 44 21 6 86 24 40 217 83 22 39 248 54 23 76 229 53 24 34 3 10 46 26 40 2 11 58 22 69 23 12 87 23 41 22 13 55 25 43 2 14 54 23 74 20 15 57 45 41 24 16 83 23 42 23 17 53 49 42 20 18 51 23 37 4 19 49 24 44 1 20 57 25 73 23 21 88 25 40 19(1)录入数据点击variable view 定义变量名;点击data view 输入数据(按行输入 一个数据一行);点击file-save 或save as 保存数据。
(2)聚类分析Analyze---classify----hierarchical cluster主对话框界面说明:Variables 框:用于选入进行聚类分析的变量。
Label cases by框:选入标签变量,如果选入,该变量的取值将在分析结果中取代记录号出现。
该框只在样品聚类时可用。
Cluster框:用于选择是进行样品聚类还是变量聚类,默认前者。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
spss聚类分析案例
SPSS聚类分析案例。
在统计学中,聚类分析是一种常用的数据分析方法,它可以将数据集中的个体
或变量进行分组,使得同一组内的个体或变量之间的相似度较高,而不同组之间的相似度较低。
聚类分析在市场分析、社会学调查、医学研究等领域有着广泛的应用。
而SPSS作为一款专业的统计分析软件,提供了丰富的聚类分析功能,能够帮助研
究者对数据进行深入的分析和挖掘。
在本案例中,我们将以一个实际的数据集为例,介绍SPSS中如何进行聚类分析,并对分析结果进行解读和讨论。
首先,我们需要加载数据集,然后选择合适的变量进行聚类分析。
在选择变量时,需要考虑变量之间的相关性,避免出现多重共线性的情况。
在本案例中,我们选择了A、B、C三个变量进行聚类分析。
接下来,我们需要进行聚类分析的设置。
在SPSS软件中,可以选择不同的聚
类算法和距离度量方法,以及设置聚类的个数。
在本案例中,我们选择了K均值
聚类算法,并设置聚类的个数为3。
同时,我们还可以对聚类结果进行验证和评价,以确保聚类结果的准确性和稳定性。
在进行聚类分析后,我们需要对聚类结果进行解读和讨论。
首先,我们可以通
过聚类中心和聚类图表来直观地展示不同组之间的差异和相似度。
然后,我们可以对每一组的特征进行分析,找出不同组之间的显著性差异和共性特征。
最后,我们可以将聚类结果与实际情况进行比较,验证聚类结果的有效性和可解释性。
通过本案例的介绍,相信读者对SPSS中的聚类分析方法有了更深入的了解。
在实际应用中,聚类分析可以帮助研究者发现数据中潜在的规律和结构,为决策提供科学依据。
同时,SPSS作为一款功能强大的统计分析软件,为用户提供了丰富
的数据分析工具和可视化功能,能够满足不同领域的研究需求。
总之,聚类分析是一种重要的数据分析方法,能够帮助研究者理解数据的内在结构和规律。
而SPSS作为一款专业的统计分析软件,为用户提供了便捷的聚类分析工具,能够帮助用户快速准确地进行数据分析和挖掘。
希望本案例的介绍能够对读者有所帮助,同时也欢迎读者在实际应用中进行进一步的探索和实践。