深搜广搜遍历算法
的遍历算法深度优先搜索与广度优先搜索的实现与应用

的遍历算法深度优先搜索与广度优先搜索的实现与应用遍历算法是计算机科学中常用的一种算法,其作用是按照一定的规则,对数据结构中的每个节点进行访问,以达到查找、遍历或搜索的目的。
在遍历算法中,深度优先搜索(Depth First Search,简称DFS)和广度优先搜索(Breadth First Search,简称BFS)是两种常见的策略。
它们分别以不同的顺序访问节点,并且在实际应用中具有各自的优势和局限性。
一、深度优先搜索深度优先搜索是一种采用堆栈(Stack)的先进后出策略,将节点的全部子节点遍历完毕后再回溯到上层节点进行进一步的遍历。
通过这种方式,深度优先搜索能够较快地到达树的叶子节点,并可以在较短时间内找到一条从根节点到达目标节点的路径。
深度优先搜索的实现可以使用递归或者显式模拟栈来完成。
下面是一个使用递归实现深度优先搜索的示例:```pythondef dfs(node):if node is None:return# 访问节点visit(node)# 递归遍历子节点for child in node.children:dfs(child)```深度优先搜索广泛应用于图的遍历、迷宫求解、拓扑排序等场景。
由于其递归的特性,深度优先搜索可能会导致堆栈溢出问题,因此在处理大规模数据时需要注意栈空间的限制。
二、广度优先搜索广度优先搜索是一种采用队列(Queue)的先进先出策略,从根节点开始逐层遍历,先访问离根节点最近的节点,再访问离根节点更远的节点。
通过这种方式,广度优先搜索能够逐层地向外扩展,并可以在较短时间内找到根节点到目标节点的最短路径。
广度优先搜索的实现需要使用队列来保存待访问的节点。
下面是一个使用队列实现广度优先搜索的示例:```pythondef bfs(node):if node is None:returnqueue = []# 将根节点入队queue.append(node)while queue:# 出队节点curr_node = queue.pop(0)# 访问节点visit(curr_node)# 将子节点入队for child in curr_node.children:queue.append(child)```广度优先搜索常用于寻找最短路径、社交网络分析等场景。
第7章图的深度和广度优先搜索遍历算法
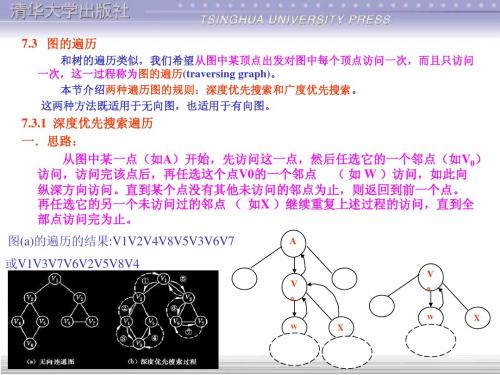
和树的遍历类似,我们希望从图中某顶点出发对图中每个顶点访问一次,而且只访问 一次,这一过程称为图的遍历(traversing graph)。 本节介绍两种遍历图的规则:深度优先搜索和广度优先搜索。 这两种方法既适用于无向图,也适用于有向图。
7.3.1 深度优先搜索遍历 一.思路: 从图中某一点(如A)开始,先访问这一点,然后任选它的一个邻点(如V0) 访问,访问完该点后,再任选这个点V0的一个邻点 ( 如 W )访问,如此向 纵深方向访问。直到某个点没有其他未访问的邻点为止,则返回到前一个点。 再任选它的另一个未访问过的邻点 ( 如X )继续重复上述过程的访问,直到全 部点访问完为止。 图(a)的遍历的结果:V1V2V4V8V5V3V6V7 或V1V3V7V6V2V5V8V4
p
v0 w x v 1
V
0
v 2
V
0
typedef struct {VEXNODE adjlist[MAXLEN]; // 邻接链表表头向量 int vexnum, arcnum; // 顶点数和边数 int kind; // 图的类型 }ADJGRAPH;
W W
X
X
7.3.2 广度优先搜索遍历 一.思路:
V
0
A V
0
W W
XXΒιβλιοθήκη 二.深度优先搜索算法的文字描述: 算法中设一数组visited,表示顶点是否访问过的标志。数组长度为 图的顶点数,初值均置为0,表示顶点均未被访问,当Vi被访问过,即 将visitsd对应分量置为1。将该数组设为全局变量。 { 确定从G中某一顶点V0出发,访问V0; visited[V0] = 1; 找出G中V0的第一个邻接顶点->w; while (w存在) do { if visited[w] == 0 继续进行深度优先搜索; 找出G中V0的下一个邻接顶点->w;} }
树的深度广度优先搜索算法

深度优先搜索算法(Depth First Search),是搜索算法的一种。
是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。
当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。
这一过程一直进行到已发现从源节点可达的所有节点为止。
如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
如右图所示的二叉树:A 是第一个访问的,然后顺序是B、D,然后是E。
接着再是C、F、G。
那么,怎么样才能来保证这个访问的顺序呢?分析一下,在遍历了根结点后,就开始遍历左子树,最后才是右子树。
因此可以借助堆栈的数据结构,由于堆栈是后进先出的顺序,由此可以先将右子树压栈,然后再对左子树压栈,这样一来,左子树结点就存在了栈顶上,因此某结点的左子树能在它的右子树遍历之前被遍历。
深度优先遍历代码片段//深度优先遍历void depthFirstSearch(Tree root){stack<Node *> nodeStack; //使用C++的STL标准模板库nodeStack.push(root);Node *node;while(!nodeStack.empty()){node = nodeStack.top();printf(format, node->data); //遍历根结点nodeStack.pop();if(node->rchild){nodeStack.push(node->rchild); //先将右子树压栈}if(node->lchild){nodeStack.push(node->lchild); //再将左子树压栈}}}广度优先搜索算法(Breadth First Search),又叫宽度优先搜索,或横向优先搜索。
是从根节点开始,沿着树的宽度遍历树的节点。
如果所有节点均被访问,则算法中止。
dfs和bfs算法代码

dfs和bfs算法代码深度优先搜索(DFS)和广度优先搜索(BFS)是常用的图遍历算法,它们可以帮助我们解决很多实际问题。
本文将详细介绍这两种算法的实现原理和应用场景。
一、深度优先搜索(DFS)深度优先搜索是一种递归的搜索算法,它从图的某个顶点开始,沿着一条路径尽可能深地搜索,直到无法继续为止,然后回溯到上一级节点,继续搜索其他路径。
DFS一般使用栈来实现。
DFS的代码实现如下:```def dfs(graph, start):visited = set() # 用一个集合来记录已访问的节点stack = [start] # 使用栈来实现DFSwhile stack:node = stack.pop() # 取出栈顶元素if node not in visited:visited.add(node) # 将节点标记为已访问neighbors = graph[node] # 获取当前节点的邻居节点stack.extend(neighbors) # 将邻居节点入栈return visited```DFS的应用场景很多,比如迷宫问题、拓扑排序、连通分量的计算等。
在迷宫问题中,我们可以使用DFS来寻找从起点到终点的路径;在拓扑排序中,DFS可以用来确定任务的执行顺序;在连通分量的计算中,DFS可以用来判断图是否连通,并将图分割成不同的连通分量。
二、广度优先搜索(BFS)广度优先搜索是一种逐层遍历的搜索算法,它从图的某个顶点开始,先访问该顶点的所有邻居节点,然后再访问邻居节点的邻居节点,依次进行,直到遍历完所有节点。
BFS一般使用队列来实现。
BFS的代码实现如下:```from collections import dequedef bfs(graph, start):visited = set() # 用一个集合来记录已访问的节点queue = deque([start]) # 使用队列来实现BFSwhile queue:node = queue.popleft() # 取出队首元素if node not in visited:visited.add(node) # 将节点标记为已访问neighbors = graph[node] # 获取当前节点的邻居节点queue.extend(neighbors) # 将邻居节点入队return visited```BFS的应用场景也很广泛,比如寻找最短路径、社交网络中的人际关系分析等。
深度优先搜索和广度优先搜索

深度优先搜索和⼴度优先搜索 深度优先搜索和⼴度优先搜索都是图的遍历算法。
⼀、深度优先搜索(Depth First Search) 1、介绍 深度优先搜索(DFS),顾名思义,在进⾏遍历或者说搜索的时候,选择⼀个没有被搜过的结点(⼀般选择顶点),按照深度优先,⼀直往该结点的后续路径结点进⾏访问,直到该路径的最后⼀个结点,然后再从未被访问的邻结点进⾏深度优先搜索,重复以上过程,直⾄所有点都被访问,遍历结束。
⼀般步骤:(1)访问顶点v;(2)依次从v的未被访问的邻接点出发,对图进⾏深度优先遍历;直⾄图中和v有路径相通的顶点都被访问;(3)若此时图中尚有顶点未被访问,则从⼀个未被访问的顶点出发,重新进⾏深度优先遍历,直到图中所有顶点均被访问过为⽌。
可以看出,深度优先算法使⽤递归即可实现。
2、⽆向图的深度优先搜索 下⾯以⽆向图为例,进⾏深度优先搜索遍历: 遍历过程: 所以遍历结果是:A→C→B→D→F→G→E。
3、有向图的深度优先搜索 下⾯以有向图为例,进⾏深度优先遍历: 遍历过程: 所以遍历结果为:A→B→C→E→D→F→G。
⼆、⼴度优先搜索(Breadth First Search) 1、介绍 ⼴度优先搜索(BFS)是图的另⼀种遍历⽅式,与DFS相对,是以⼴度优先进⾏搜索。
简⾔之就是先访问图的顶点,然后⼴度优先访问其邻接点,然后再依次进⾏被访问点的邻接点,⼀层⼀层访问,直⾄访问完所有点,遍历结束。
2、⽆向图的⼴度优先搜索 下⾯是⽆向图的⼴度优先搜索过程: 所以遍历结果为:A→C→D→F→B→G→E。
3、有向图的⼴度优先搜索 下⾯是有向图的⼴度优先搜索过程: 所以遍历结果为:A→B→C→E→F→D→G。
三、两者实现⽅式对⽐ 深度优先搜索⽤栈(stack)来实现,整个过程可以想象成⼀个倒⽴的树形:把根节点压⼊栈中。
每次从栈中弹出⼀个元素,搜索所有在它下⼀级的元素,把这些元素压⼊栈中。
并把这个元素记为它下⼀级元素的前驱。
深度遍历和广度遍历例题

深度遍历和广度遍历例题深度遍历(Depth First Search, DFS)和广度遍历(Breadth First Search, BFS)是图遍历的两种常用方法。
在本文中,将介绍深度遍历和广度遍历的定义、原理、应用以及两种方法的例题。
一、深度遍历(DFS)深度遍历使用堆栈(Stack)实现,其基本思想是先访问根节点,然后再递归地访问其相邻节点,直到所有节点都被访问。
深度遍历能够搜索到最深层次的节点,但可能会陷入死循环。
1. 深度遍历的应用场景:深度遍历常用于解决图的连通性问题、拓扑排序、求解图中的环等。
另外,也可以应用于解决迷宫问题、数独等。
2. 深度遍历的基本过程:(1)首先访问初始节点,并标记为已访问。
(2)递归地访问初始节点的相邻节点,对于每一个相邻节点,若未被访问,则进行递归访问。
(3)重复步骤(2),直到所有节点都被访问。
3. 深度遍历的例题:假设有以下有向图:A -> B,A -> C,B -> D,B -> E,C -> F,D -> G,E -> H,F -> G,G -> E,H -> E现在要求从节点A开始进行深度遍历,从A到E的路径请写出所有可能的路径。
答案:A -> B -> D -> G -> E,A -> B -> E,A -> C -> F -> G -> E,A -> C -> F -> G -> E,A -> B -> D -> G -> E -> H -> E,A -> C -> F -> G -> E -> H -> E二、广度遍历(BFS)广度遍历使用队列(Queue)实现,其基本思想是先访问根节点,然后再按照层次逐层访问其相邻节点,直到所有节点都被访问。
广度优先和深度优先的例子

广度优先和深度优先的例子广度优先搜索(BFS)和深度优先搜索(DFS)是图遍历中常用的两种算法。
它们在解决许多问题时都能提供有效的解决方案。
本文将分别介绍广度优先搜索和深度优先搜索,并给出各自的应用例子。
一、广度优先搜索(BFS)广度优先搜索是一种遍历或搜索图的算法,它从起始节点开始,逐层扩展,先访问起始节点的所有邻居节点,再依次访问其邻居节点的邻居节点,直到遍历完所有节点或找到目标节点。
例子1:迷宫问题假设有一个迷宫,迷宫中有多个房间,每个房间有四个相邻的房间:上、下、左、右。
现在我们需要找到从起始房间到目标房间的最短路径。
可以使用广度优先搜索算法来解决这个问题。
例子2:社交网络中的好友推荐在社交网络中,我们希望给用户推荐可能认识的新朋友。
可以使用广度优先搜索算法从用户的好友列表开始,逐层扩展,找到可能认识的新朋友。
例子3:网页爬虫网页爬虫是搜索引擎抓取网页的重要工具。
爬虫可以使用广度优先搜索算法从一个网页开始,逐层扩展,找到所有相关的网页并进行抓取。
例子4:图的最短路径在图中,我们希望找到两个节点之间的最短路径。
可以使用广度优先搜索算法从起始节点开始,逐层扩展,直到找到目标节点。
例子5:推荐系统在推荐系统中,我们希望给用户推荐可能感兴趣的物品。
可以使用广度优先搜索算法从用户喜欢的物品开始,逐层扩展,找到可能感兴趣的其他物品。
二、深度优先搜索(DFS)深度优先搜索是一种遍历或搜索图的算法,它从起始节点开始,沿着一条路径一直走到底,直到不能再继续下去为止,然后回溯到上一个节点,继续探索其他路径。
例子1:二叉树的遍历在二叉树中,深度优先搜索算法可以用来实现前序遍历、中序遍历和后序遍历。
通过深度优先搜索算法,我们可以按照不同的遍历顺序找到二叉树中所有节点。
例子2:回溯算法回溯算法是一种通过深度优先搜索的方式,在问题的解空间中搜索所有可能的解的算法。
回溯算法常用于解决组合问题、排列问题和子集问题。
例子3:拓扑排序拓扑排序是一种对有向无环图(DAG)进行排序的算法。
实现深度优先搜索和广度优先搜索算法

实现深度优先搜索和广度优先搜索算法深度优先(DFS)和广度优先(BFS)是两种最常用的图遍历算法。
它们在图中寻找路径或解决问题时非常有用。
以下是DFS和BFS算法的实现以及它们的应用场景。
首先,我们来实现DFS算法。
深度优先(DFS)是一种不断沿着图的深度方向遍历的算法。
DFS使用堆栈来跟踪遍历的路径。
下面是DFS算法的实现步骤:1.选择一个起始顶点作为当前顶点,并将其标记为已访问。
2.检查当前顶点的邻居顶点:-如果邻居顶点未被访问,则将其标记为已访问,并将其入栈。
-如果邻居顶点已被访问,则继续检查下一个邻居顶点。
3.如果当前顶点没有未访问的邻居顶点,则出栈一个顶点作为新的当前顶点。
4.重复步骤2和步骤3,直到栈为空。
下面是DFS算法的Python实现:```pythondef dfs(graph, start):visited = set( # 用于存储已访问的顶点stack = [start] # 用于存储待访问的顶点while stack:vertex = stack.popif vertex not in visited:visited.add(vertex)for neighbor in graph[vertex]:stack.append(neighbor)return visited```接下来,我们来实现BFS算法。
广度优先(BFS)是一种逐层遍历图的算法。
BFS使用队列来跟踪遍历的顺序。
下面是BFS算法的实现步骤:1.选择一个起始顶点作为当前顶点,并将其标记为已访问。
2.将当前顶点入队。
3.检查队列中下一个顶点的邻居顶点:-如果邻居顶点未被访问,则将其标记为已访问,并将其入队。
-如果邻居顶点已被访问,则继续检查下一个邻居顶点。
4.重复步骤3,直到队列为空。
下面是BFS算法的Python实现:```pythonfrom collections import dequedef bfs(graph, start):visited = set( # 用于存储已访问的顶点queue = deque([start]) # 用于存储待访问的顶点while queue:vertex = queue.popleftif vertex not in visited:visited.add(vertex)for neighbor in graph[vertex]:queue.append(neighbor)return visited```DFS和BFS算法在许多问题和应用场景中都有广泛的应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
深度优先搜索遍历算法深度优先搜索的过程深度优先搜索所遵循的搜索策略是尽可能“深”地搜索图。
在深度优先搜索中,对于最新发现的节点,如果它还有以此为起点而未搜索的边,就沿此边继续搜索下去。
当节点v的所有边都己被探寻过,搜索将回溯到发现节点v有那条边的始节点。
这一过程一直进行到已发现从源节点可达的所有节点为止。
如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被发现为止。
即⒈以给定的某个顶点V0为起始点,访问该顶点;⒉选取一个与顶点V0相邻接且未被访问过的顶点V1,用V1作为新的起始点,重复上述过程;⒊当到达一个其所有邻接的顶点都已被访问过的顶点Vi时,就退回到新近被访问过的顶点Vi- 1,继续访问Vi-1尚未访问的邻接点,重复上述搜索过程;⒋直到从任意一个已访问过的顶点出发,再也找不到未被访问过的顶点为止,遍历便告完成。
这种搜索的次序体现了向纵深发展的趋势,所以称之为深度优先搜索。
深度优先搜索算法描述:程序实现有两种方式--递归与非递归。
一、递归递归过程为:Procedure DEF-GO(step)for i:=1 to max doif 子结点符合条件 then产生新的子结点入栈;if 子结点是目标结点 then 输出else DEF-GO(step+1);栈顶结点出栈;endif;enddo;主程序为:Program DFS;初始状态入栈;DEF-GO(1);二、非递归Program DEF(step);step:=0;repeatstep:=step+1;j:=0;p:=falserepeatj:=j+1;if 结点符合条件 then产生子结点入栈;if 子结点是目标结点 then 输出else p:=true;elseif j>=max then 回溯 p:=false;endif;until p=true;until step=0;回溯过程如下:Procedure BACK;step:=step-1;if step>0 then 栈顶结点出栈else p:=true;例如八数码难题--已知8个数的起始状态如图1(a),要得到目标状态为图1(b)。
2831231648■47■5765(a)(b)求解时,首先要生成一棵结点的搜索树,按照深度优先搜索算法,我们可以生成图1的搜索树。
图中,所有结点都用相应的数据库来标记,并按照结点扩展的顺序加以编号。
其中,我们设置深度界限为5。
粗线条路径表示求得的一个解。
从图中可见,深度优先搜索过程是沿着一条路径进行下去,直到深度界限为止,回溯一步,再继续往下搜索,直到找到目标状态或OPEN 表为空为止。
图1 深度优先搜索图程序:program No8_DFS; {八数码的深度优先搜索算法}ConstDir : array[1..4,1..2]of integer = ((1,0),(-1,0),(0,1),(0,-1));maxN = 15;{可以承受的最大深度}TypeT8No = array[1..3,1..3]of integer;tList = recordstate : T8No;x0,y0 : integer;end;VarSource,Target : T8No;List,Save : array[0..maxN]of tList;{综合数据库,最优解路径}Open,Best : integer;procedure GetInfo;{见程序1}Function Same(A,B : T8No):Boolean; {见程序1}function Not_Appear(New : tList):boolean; {见程序1}procedure Move(N : tList;d : integer;var ok : boolean;var New : tList);{见程序1}procedure GetOutInfo;{输出}var i,x,y : integer;beginwriteln('total = ',best);for i:=1 to best+1 do beginfor x:=1 to 3 do beginfor y:=1 to 3 do write(Save[i].State[x,y],' ');writeln;end;writeln;end;end;Procedure Recursive;{递归搜索过程}Var i : integer;New: tList;ok : boolean;BeginIf Open-1>=Best then exit;If Same(List[Open].state,Target) then begin{如果找到解,保存当前最优解}Best:=Open-1;Save:=List;end;For i:=1 to 4 do begin{依次选用规则}Move(List[Open],i,OK,New);if ok and not_Appear(New) then begin{如果没有重复}inc(open);{插入综合数据库}List[Open]:=New;Recursive; {继续搜索}dec(Open);{退栈}End;End;End;procedure Main; {搜索主过程}var x,y : integer;beginList[1].state:=Source; {初始化}for x:=1 to 3 dofor y:=1 to 3 do if Source[x,y]=0 then beginList[1].x0:=x;List[1].y0:=y;end;Best:=MaxN;Open:=1;Recursive; {开始搜索}If Best=maxint then writeln('No answer')Else GetOutInfo;end;BeginAssign(Input,'input.txt');ReSet(Input);Assign(Output,'Output.txt');ReWrite(Output);GetInfo;Main;Close(Input);Close(Output);End.上面的八数码程序利用到了递归来实现,其实深度优先搜索还有一种无需递归的实现方式,下面我们介绍一下深度优先的一般实现方法:递归算法和非递归算法。
递归算法伪代码:procedure DFS_ recursive(N);1.if N=target then 更新当前最优值并保存路径;2.for r:=1 to 规则数do [3.New:=Expand(N,r)4.if 值节点New符合条件then [5.产生的子节点New压入栈;6.DFS_recursive(i+1);7.栈顶元素出栈;8.]9.]program DFS;1.初始化;2.DFS_recursive(N);非递归算法伪代码:procedure Backtracking;1.dep:=dep-1;2.if dep>0 then 取出栈顶元素3.else p:=true;program DFS;1.dep:=0;2.Repeat3.dep:=dep+1;4.j:=0;brk:=false;5.Repeat6.j:=j+1;7.New=Expand(Track[dep],j);8.if New 符合条件then [9.产生子节点New并将其压栈;10. If 子节点New=target then 更新最优值并出栈11. else brk:=true;12. ]13. else if j>=规则数then Backtracking14. else brk:=false;15. Until brk=true16.Until dep=0;两种方式本质上是等价,但两者也时有区别的。
1.递归方式实现简单,非递归方式较之比较复杂;递归方式需要利用栈空间,如果搜索量过大的话,可能造成栈溢出,所以在栈空间无法满足的情况下,选用非递归实现方式较好。
(二)广度优先搜索遍历算法一.宽度优先搜索的过程宽度优先搜索算法(又称宽度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。
Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。
宽度优先算法的核心思想是:从初始节点开始,应用算符生成第一层节点,检查目标节点是否在这些后继节点中,若没有,再用产生式规则将所有第一层的节点逐一扩展,得到第二层节点,并逐一检查第二层节点中是否包含目标节点。
若没有,再用算符逐一扩展第二层的所有节点……,如此依次扩展,检查下去,直到发现目标节点为止。
即⒈从图中的某一顶点V0开始,先访问V0;⒉访问所有与V0相邻接的顶点V1,V2,......,Vt;⒊依次访问与V1,V2,......,Vt相邻接的所有未曾访问过的顶点;⒋循此以往,直至所有的顶点都被访问过为止。
这种搜索的次序体现沿层次向横向扩长的趋势,所以称之为广度优先搜索。
二、广度优先搜索算法描述:Program Bfs;初始化,初始状态存入OPEN表;队列首指针head:=0;尾指针tail:=1;repeat指针head后移一位,指向待扩展结点;for I=1 to max do {max为产生子结点的规则数}beginif 子结点符合条件 thenbegintail指针增1,把新结点存入列尾;if新结点与原已产生结点重复then删去该结点(取消入队,tail减1)elseif新结点是目标结点then输出并退出;end;end;until(tail>=head); {队列空}三、广度优先搜索注意事项:1、每生成一个子结点,就要提供指向它们父亲结点的指针。
当解出现时候,通过逆向跟踪,找到从根结点到目标结点的一条路径。
2、生成的结点要与前面所有已经产生结点比较,以免出现重复结点,浪费时间,还有可能陷入死循环。
3、如果目标结点的深度与“费用”(如:路径长度)成正比,那么,找到的第一个解即为最优解,这时,搜索速度比深度搜索要快些;如果结点的“费用”不与深度成正比时,第一次找到的解不一定是最优解。
4、广度优先搜索的效率还有赖于目标结点所在位置情况,如果目标结点深度处于较深层时,需搜索的结点数基本上以指数增长。
下面我们看看怎样用宽度优先搜索来解决八数码问题。
例如图2给出广度优先搜索应用于八数码难题时所生成的搜索树。
搜索树上的所有结点都标记它们所对应的状态,每个结点旁边的数字表示结点扩展的顺序。