基于Hadoop的Web日志挖掘
基于Hadoop 集群的日志分析系统的设计与实现

基于Hadoop 集群的日志分析系统的设计与实现作者:陈森博陈张杰来源:《电脑知识与技术》2013年第34期摘要:当前Internet上存在着海量的日志数据,他们中蕴藏着大量可用的信息。
对海量数据的存储和分析都是一个艰巨而复杂的任务,单一主机已经无法满足要求,使用分布式存储和分布式计算来分析数据已经成为了必然的趋势。
分布式计算框架Hadoop已经日趋成熟,被广泛的应用于很多领域。
该文描述了一个针对大日志分析的分布式集群的构建与实现过程。
介绍了日志分析的现状,使用vmware虚拟机搭建了Hadoop集群和日志分析系统的构建方法,并对实验结果进行了分析。
关键词:分布式计算;日志分析;Hadoop;集群;vmware中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2013)34-7647-041 概述日志文件是由系统或者应用程序产生的,用于记录系统和应用程序的操作事件如各种服务的启动、运行、关闭等信息。
通过对日志文件的分析可以获得很多有价值的数据也能实现对系统安全、性能等方面的监控。
Web日志[1]是由Web服务器产生的,随着社交网络的兴起,Web2.0时代的到来,网站的用户访问量的成级数增长,产生的日志文件大幅增多。
传统的日志文件分析方式已经无法满足大数据量日志分析的需求。
该文将以Web日志文件为例,利用Hadoop集群构建一个分布式计算平台为大数据日志文件的分析提供一个可行的解决方案,以提高了日志分析的效率,为进一步的大数据分析的提供参考。
现今日志文件分析方案是对大的日志文件先进行分割,然后对分割后的日志文件进行分析,分析方法采用文本分析及模式匹配等,最常见的是采用awk、python、perl。
这种分析方式面对大数据的日志文件分析效率低下,耗时长。
王潇博提出了基于挖掘算法的日志分析方式,并设计了TAT系统[1]。
对于Web分析除了对Web日志本身进行分析外还可以主动收集访问信息,然后将信息存于关系型数据库中。
基于交友网站的日志挖掘和分析系统

基于交友网站的日志挖掘和分析系统
桑军;李丽
【期刊名称】《数字技术与应用》
【年(卷),期】2010(000)010
【摘要】针对女之海交友广场网站日志挖掘的具体需求,设计和开发了一个用于会员宣传的Web日志挖掘系统.结合自动获取的网站拓扑结构,对站点日志数据进行关联规则挖掘,以便更好地确定宣传的时间、地区、所针对的用户群年龄特征以及相应的会员信息内容等,系统实现了预期的挖掘任务和目的.
【总页数】2页(P142-143)
【作者】桑军;李丽
【作者单位】重庆大学软件学院,四川重庆,400044;重庆大学软件学院,四川重庆,400044
【正文语种】中文
【中图分类】TP321
【相关文献】
1.基于日志挖掘的打印管理系统的分析与设计 [J], 唐维燕
2.基于交友网站的日志挖掘和分析系统 [J], 桑军;李丽
3.基于粗糙集和模糊聚类的网站日志数据挖掘实例分析 [J], 高晓琴;王亨桂
4.基于日志挖掘的计算机取证系统的分析与设计 [J], 国光明;洪晓光
5.基于Hadoop的网站流量日志数据分析系统的设计 [J], 来学伟
因版权原因,仅展示原文概要,查看原文内容请购买。
大数据处理平台(完整版)

动态位置信息
位置数据规范化
更多…
热点分析
号码信息 用户信息 业务位置信息 更多信息
输出
标准的位置应用
基础统计分析 用户分类 更多…
谢谢!
对系统资源消耗严重。
数据采集面临巨大压力
接口单元名称
类别 数据量(天)
网络数据类信令
Gb/Gn接口 1.65T/Day
用户动态呼叫、短信、位置、 切换、开关机行为信息
A接口
3.3T/Day
WAP日志
WAP网关 300G/Day
…
…
…
1 运营商大数据背景 2 大数据平台介绍
3 应用案例
大数据平台规划
聚类
分类
信息统计
4
日志 汇总
用户 行为
网站
分类
访问 内容 主题
访搜问 索 关键 字
基础分 析能力
文本挖掘
数据挖掘
HIVE
HADOOP平台
云ETL 管理 应用 开发 应用 监控 应用 调度
M/R
ETL-基于流程的ETL工具
1. 云ETL基于Oozie工作流,提供ETL任务编排、任务调度、任务监控等功能。 2. 管理与监控提供平台应用层自管理能力,包含数据质量管理、安全管理、告警管理、日志管理、系统
设计更好的流量套餐、 终端和互联网业务
为用户精确地进行推荐, 及时地进行服务
更多…
用户的行为是什么
都是哪些用户在使用移 动互联网,都有什么样 的特征? 都在干什么? 行为模式如何? 占用了多少资源或流量? 对网络影响如何? 如何牵引用户行为改变 对网络的影响?
实 现
互联网内容分析基础服务
输出
互联网内容抓取
基于MapReduce的Web日志挖掘_李彬

2
MapReduce 编程模型
首先解释一下什么是云计算。云计算比较通用
的的定义: 云计算是一种商业计算模型。它将计算 任务分布在大量计算机构成的资源池上, 使各种应 用系统能够根据需要获取计算力、 存储空间和各种 软件服务。从这个定义上讲可把云计算看成是 “存 储云” 与 “计算云” 的有机结合。存储云对第三方用 户公开存储接口, 用户通过这个接口可以把数据存 储到 “云” 。计算云通过并行计算和虚拟化技术提供 给用户, 它的商业模式是给用户提供强大的计算能力。 MapReduce[4] 是 云 计 算 的 核 心 计 算 模 式 , 是一 种分布式运算技术, 也是简化的分布式编程模式。 MapReduce 模式的主要思想是将要执行的问题分 割。在数据被分割后通过 Map 函数的程序将数据映 射成不同的区块, 分配给计算机集群处理达到分布 式运算的效果, 再通过 Reduce 函数的程序将结果汇 整, 输出要得到的结果。具体流程如下[5-6]: (1) Fork。利用 MapReduce 提供的库将输入文件 分成大小相等的 M 份, 并在集群的不同机器上执行 程序的备份。 (2) Assign map/reduce。Master 节点的程序负责 找出空闲的 worker 节点并为它们分配子任务 (M 个 Map 子任务和 R 个 Reduce 子任务) 。 (3) Read。被分配到 Map 子任务的 worker 节点 读入已分割好的文件作为输入, 经过处理后生成键 值对 (key/value 对) , 并调用用户编写的 Map 函数。 (4) Local write。Map 函数的中间结果缓存在内 存中并周期性地写入本地磁盘。这些中间数据通过 分区函数分成 R 个区, 并将它们在本地磁盘的位置信 息发送给 Master 节点, 然后由 Master 将位置信息发 送给执行 Reduce 子任务的节点。 (5) Remote read。执行 Reduce 子任务的节点从 Master 节点获取子任务后, 根据位置信息调用 Map 工 作节点所在的本地磁盘上的中间数据, 并利用中间数 据的 key 值进行排序, 将具有相同键的对进行合并。 (6) Write。执行 Reduce 子任务的节点遍历所有 排序后的中间数据, 并传递给用户定义的 Reduce 函 数。Reduce 函数的结果将被输出到一个最终的输出 文件。 最后, 当所有 Map 子任务和 reduce 子任务完成
web数据挖掘的处理流程

web数据挖掘的处理流程对web数据的处理可以分为数据获取、数据预处理、数据的转换集成、知识发现和模式分析几个过程,如图6-2所示。
(1) web数据的获取Web数据的来源包括:log日志,记录了用户的访问页面、时间、IP地址等主要信息;web内容,用户所浏览的文字、图片等;用户注册信息,web站点采集的用户输入的自身信息;web结构数据,指web本身在频道、链接上的布局。
Web数据的获取方法有:a) 服务器端信息。
web服务器端产生3种类型的日志文件:Server logs,Error logs,Cookie logs,这些日志记录了用户访问的基本情况,是Web使用挖掘中最重要的数据来源。
服务器日志(Server logs)记录了多个用户对单个站点的用户访问行为。
错误日志(Error log)记录存取请求失败的数据。
Cookie logs用于识别用户和用户会话。
b) 客户端的数据收集。
用户客户端log记录了该用户对各个网站的访问情况,比服务器端Log数据更能准确地反映用户的访问行为,但由于隐私保护,需要用户同意才能获得。
c) 代理服务器端的数据收集。
代理端log数据记载了通过该代理进入Internet 的所有用户对各个网站的访问行为。
但是由于Cache的大量存在,使得代理服务器中的log数据不能准确地确定用户和时间,采集信息也不全面[50]。
(2) web数据的预处理Web数据的预处理包含数据清洗、用户识别、会话识别和事务识别等过程。
a) web数据的清洗数据的清洗,是指删除Web日志中与挖掘任务无关的数据。
将有用的web 日志记录转换为适当的数据格式,同时对用户请求页面时发生错误的记录进行适当处理。
在web日志中,包含许多对挖掘任务毫无意义的数据。
数据清洗的目标是消除冗余数据,方便于数据分析。
常见的数据清洗方法包括:删除日志文件中后缀为gif, jpg, jpeg的自动下载项;删除访问返回错误记录等。
web挖掘的基本任务

web挖掘的基本任务
Web挖掘的基本任务是指从Web中提取有价值的信息或模式,其主要包括以下几种类型:
1.内容挖掘:指从Web页面中提取出有用的信息。
由于Web页面经常是半
结构化或非结构化的,因此内容挖掘需要处理HTML和XML文档,解析并提取出文本、图片、音频、视频等多媒体内容。
2.结构挖掘:指对Web页面的超链接关系进行挖掘,找出重要的页面,理解
网站的结构和组织方式,以及发现页面之间的关系。
3.使用挖掘:主要通过挖掘服务器日志文件,获取有关用户访问行为的信息,
例如用户访问路径、访问频率、停留时间等,从而理解用户的访问模式和偏好。
4.用户行为挖掘:结合内容挖掘和用户日志挖掘,深入理解用户在Web上的
活动,包括浏览、搜索、点击、购买等行为,用于精准推荐、个性化广告等应用。
5.社区发现:通过分析用户在社交媒体或论坛上的互动,发现用户之间的社
交关系和社区结构。
综上,Web挖掘的基本任务是从Web中提取有价值的信息或模式,这些信息或模式可能是内容、结构、使用情况、用户行为或社区关系。
【计算机科学】_相似度算法_期刊发文热词逐年推荐_20140726
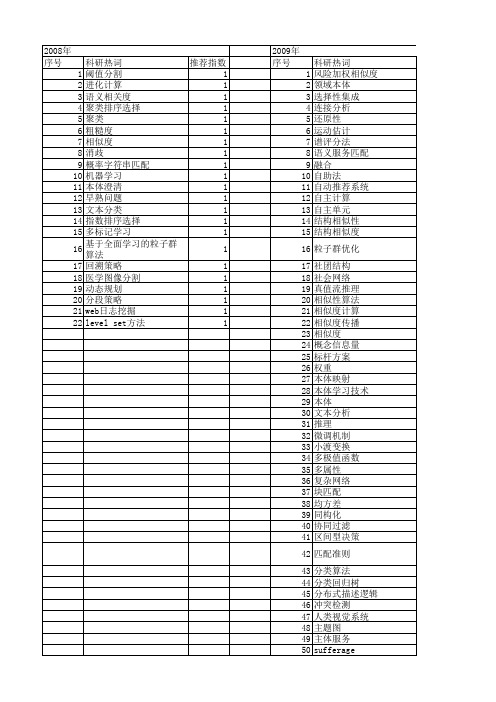
科研热词 风险加权相似度 领域本体 选择性集成 连接分析 还原性 运动估计 谱评分法 语义服务匹配 融合 自助法 自动推荐系统 自主计算 自主单元 结构相似性 结构相似度 粒子群优化 社团结构 社会网络 真值流推理 相似性算法 相似度计算 相似度传播 相似度 概念信息量 标杆方案 权重 本体映射 本体学习技术 本体 文本分析 推理 微调机制 小渡变换 多极值函数 多属性 复杂网络 块匹配 均方差 同构化 协同过滤 区间型决策 匹配准则 分类算法 分类回归树 分布式描述逻辑 冲突检测 人类视觉系统 主题图 主体服务 sufferage snn相似度矩阵 qos约束
科研热词 相似度计算 本体 链接分析 相似度 块结构 图的划分 图像检索 协同过滤 颜色直方图 领域本体 过程挖掘 边缘轮廓 语法结构信息 语义相似度 语义分析 语义 评分信息 触发词 视频相似度 视频检索 规则约简 虚拟新闻 舆情 自相似度 自然语言处理 自动文摘 背景补偿 聚类 粗集 粗糙集 等价关系 空间利用率 社会标签系统 知识库 相似度算法 电子商务 演化 混合自适应遗传算法 概要 检索算法 案例检索 标签聚类 服务 方向直方图 文档聚类 文本聚类 文本信息检索 数据源选择 推荐系统 扩展性 战略对抗演习 形状
53 fcm算法
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
中南大学第一届信息安全应用创新大赛获奖名单

创意赛获奖名单
序号 队名 1 2 3 4 5 6 7 8 9 teamone skyline 烫烫烫烫烫 DYH 梦之蓝 心脏流血 我们都爱笑 HZJ小分队 团队成员 郁博文 相雯 周怡 涂茂麟 崔志勇 路涌涛 祁特 彭澍 覃岩 杨可 黄祖贤 代巍 朱辉辉 王俊韡 胡慧 杜明哲 张振宇 廖浩伟 周建权 葛思江 舒晓波 贺雅婧 经航 张冬妮 作品名称 micro USB的可控数据传输 基于区域位置识别的移动终端认证 可控的安全访问U盘控制器USGuard 基于物联网技术的资产安全管理平台 基于信息安全的智能骑行识别系统 基于信息熵度量的网络流量可视分析系统 基于云端密码管理的免密登录方案 基于USBKEY认证的安全企业文档管理系统 优化自主安全借书机的设计与实现 结果 一等奖 一等奖 一等奖 二等奖 二等奖 二等奖 二等奖 二等奖 二等奖
三等奖 三等奖 三等奖 三等奖 三等奖 三等奖 三等奖 三等奖 优胜奖 优胜奖 优胜奖 优胜奖 优胜奖 优胜奖 优胜奖 优胜奖 优胜奖 优胜奖 优胜奖 优胜奖
基于蜘蛛搜索引擎和虚拟沙箱的交互信息防诈骗与安全链接技术 优胜奖
31 32 33 34 35
最强王者组
我们想当白帽子
王梅 季雅雯 唐也 李继仁 陈仁杰 彭皓文 谭思敏 纪书鉴 田泽佳 王璇 孙聪珊 范姝洁 郭梦圆 袁思蒙 李娅
基于二维码的物流信息身份认证系统 U盘加密与防丢失 二维码识别系统 U盘追踪及数据保护系统 移动医疗中的数据安全与隐私保护
优胜奖 优胜奖 优胜奖 优胜奖 优胜奖
TLOP 筑梦 GMK
我们不是Hacker 李浩 王兆岳 胡俊英
10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
势 ,设计一种基于 云计 算的 H do 集群框架 的 We aop b日志分析平 台,提 出一种能够在云计算环境 中进行分布 式处理 的混合 算法 。为进一步 验证该平 台的高效性 , 该平台上利用改进后 的算法挖掘 We 在 b日志 中用户 的偏爱访 问路径 。 实验结果表 明, 在集群 中运 用分布式算法处理
d v lp d t ot n c e e o e O a b t e e k.Usn e a v tg f c o d c mp tn — l ig t d a a e o lu o u ig h n iti t d p oc s i g a d vi u lz t n h s p p r p e e t e l g sr bu e r e sn n r ai a i ,t i a e r s n s a W b o t o
n lsspa r u d rt d o S l se a wo kb sdo lu o u ig i lope e t y r l oi a ay i lto m n e eHa o p’ cu tr r e r a e n co dc mp tn ,tas rs nsah b dag rtm ihC itiu e r c s f h fm i h whc a dsrb tdp o es n
第 3 卷 第 1 期 7 1
V_ -7 o 3 l
No. 1 1
计
算
机
工
程
2 1 年 6月 01
J n 01 ue2 l
Co mpu e t rEng n e i g i e rn
・云计 算专 题 ・
文章编号: Io 48 o11 o7 3 文献标识码: 1J 2( 1l 3—o M—3 2 )—o A
CHENG i o . M a CHEN a p n Hu - i g (. l g f n g me tb Colg f o ue c n e n e h o o y Unv ri f ce c dT c n lg f hn , e e 2 0 2 , ia a Col e e o Ma a e n; . l e mp tr i c dT c n lg , ie s yo in ea e h oo yo ia H fi 3 0 6 Chn ) e oC S e a t S n C
中圈分类号:T31 P1
基 于 Ha o p的 We 日志挖 掘 do b
程 苗a p陈华平
( 国科学技术大学 a 管理学院 ;b 计算机科学与技术 学院,合 肥 2 0 2 ) 中 . . 30 6
摘
要: 基于 单一节 点的数据挖掘系统在挖掘 We b海量数据源时存在计算瓶颈 , 针对该问题 , 利用云计算 的分布式处理和虚拟化技术 的优
大量 的 We b日志文件 ,可 以明显提 高 We 数据挖掘 的效率 。 b
关健词 :云计算 ;H do 架构 ;Ma/eue aop p dc 编程模 式 ; b日 R We 志挖掘 ; 遗传 算法 ;偏爱访问路径
W e l g M i i g Ba e n H a o p bo nn s do d o
[ b ta t h s aaf m baeds b td htrg no sa dd nmi, Otec r n aamiigss m ae n s gen d a A src IT emasd t o We r ir ue , eeo e eu n y a c S h ur t t nn yt b sdo i l o eh s r t i e d点 的计算能力 已经遇 到了瓶颈 ,因此 ,利
[ yw r s lu o u n ; d o a e Ma/ e ue We lgmiig gn t g r m;rfr dbo igpt Ke o d ]codc mp t g Ha o pf i r ; p d c; bo nn ; eei a o t peer rws a m R cl i h e n h D0I 1 .9 9 .s.0 03 2 .0 11 .1 : 03 6 0i n10 —4 82 1.1 3 s 0