第9章rapidminer_k_means聚类.辨别分析v1
K-means聚类分析
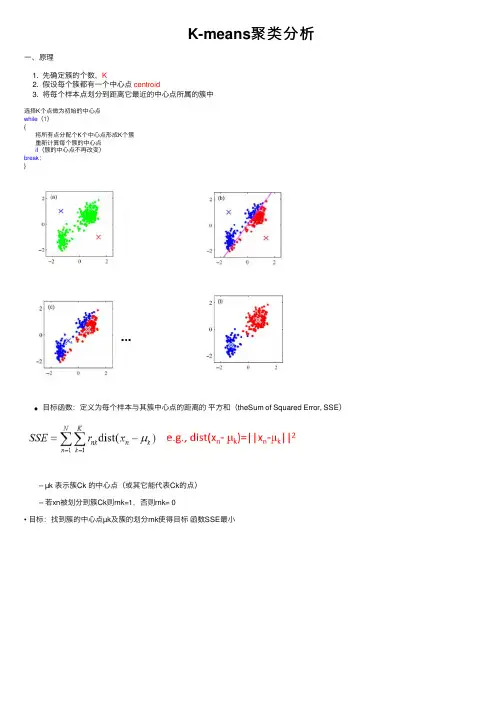
K-means聚类分析⼀、原理1. 先确定簇的个数,K2. 假设每个簇都有⼀个中⼼点centroid3. 将每个样本点划分到距离它最近的中⼼点所属的簇中选择K个点做为初始的中⼼点while(1){将所有点分配个K个中⼼点形成K个簇重新计算每个簇的中⼼点if(簇的中⼼点不再改变)break;}⽬标函数:定义为每个样本与其簇中⼼点的距离的平⽅和(theSum of Squared Error, SSE) – µk 表⽰簇Ck 的中⼼点(或其它能代表Ck的点) – 若xn被划分到簇Ck则rnk=1,否则rnk= 0• ⽬标:找到簇的中⼼点µk及簇的划分rnk使得⽬标函数SSE最⼩初始中⼼点通常是随机选取的(收敛后得到的是局部最优解)不同的中⼼点会对聚类结果产⽣不同的影响:1、2、此时你⼀定会有疑问:如何选取"较好的"初始中⼼点?1. 凭经验选取代表点2. 将全部数据随机分成c类,计算每类重⼼座位初始点3. ⽤“密度”法选择代表点4. 将样本随机排序后使⽤前c个点作为代表点5. 从(c-1)聚类划分问题的解中产⽣c聚类划分问题的代表点 结论:若对数据不够了解,可以直接选择2和4⽅法需要预先确定K Q:如何选取K SSE⼀般随着K的增⼤⽽减⼩A:emmm你多尝试⼏次吧,看看哪个合适。
斜率改变最⼤的点⽐如k=2总结:简单的来说,K-means就是假设有K个簇,然后通过上⾯找初始点的⽅法,找到K个初始点,将所有的数据分为K个簇,然后⼀直迭代,在所有的簇⾥⾯找到找到簇的中⼼点µk及簇的划分rnk使得⽬标函数SSE最⼩或者中⼼点不变之后,迭代完成。
成功把数据分为K类。
预告:下⼀篇博⽂讲K-means代码实现。
K-Means解析

Clustering中文翻译作“聚类”,简单地说就是把相似的东西分到一组,同Classification(分类)不同,对于一个classifier,通常需要你告诉它“这个东西被分为某某类”这样一些例子,理想情况下,一个classifier会从它得到的训练集中进行“学习”,从而具备对未知数据进行分类的能力,这种提供训练数据的过程通常叫做supervised learning(监督学习),而在聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起,因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了,因此clustering通常并不需要使用训练数据进行学习,这在Machine Learning中被称作unsupervised learning(无监督学习)。
举一个简单的例子:现在有一群小学生,你要把他们分成几组,让组内的成员之间尽量相似一些,而组之间则差别大一些。
最后分出怎样的结果,就取决于你对于“相似”的定义了,比如,你决定男生和男生是相似的,女生和女生也是相似的,而男生和女生之间则差别很大”,这样,你实际上是用一个可能取两个值“男”和“女”的离散变量来代表了原来的一个小学生,我们通常把这样的变量叫做“特征”。
实际上,在这种情况下,所有的小学生都被映射到了两个点的其中一个上,已经很自然地形成了两个组,不需要专门再做聚类了。
另一种可能是使用“身高”这个特征。
我在读小学候,每周五在操场开会训话的时候会按照大家住的地方的地域和距离远近来列队,这样结束之后就可以结队回家了。
除了让事物映射到一个单独的特征之外,一种常见的做法是同时提取N种特征,将它们放在一起组成一个N维向量,从而得到一个从原始数据集合到N维向量空间的映射——你总是需要显式地或者隐式地完成这样一个过程,因为许多机器学习的算法都需要工作在一个向量空间中。
那么让我们再回到clustering的问题上,暂且抛开原始数据是什么形式,假设我们已经将其映射到了一个欧几里德空间上,为了方便展示,就使用二维空间吧,如下图所示:从数据点的大致形状可以看出它们大致聚为三个cluster,其中两个紧凑一些,剩下那个松散一些。
聚类分析与判别分析 演示文稿ppt

10.2 层次聚类
Ø 层次聚类Q型聚类 Ø 层次聚类Q型聚类应用实例 Ø ห้องสมุดไป่ตู้次聚类R型聚类 Ø层次聚类R型聚类应用实例
10.2.1 层次聚类Q型聚类
层次聚类分析中的Q型聚类可使具有共同特点的样本聚齐在一起,以便对 不同类的样本进行分析。层次聚类分析中,测量样本之间的亲疏程度,一种是 样本数据与小类,小类与小类之间的亲疏程度。
和层次聚类分析一致,快速聚类分析也以距离为样本间亲疏程度的标志。但两者 的不同在于:层次聚类可以对不同的聚类类数产生一系列的聚类解,而快速聚类只能 产生固定类数的聚类解,类数需要用户事先指定。
另外,在快速聚类分析中,用户可以自己指定初始的类中心点。如果用户的经验 比较丰富可以指定比较合理的初始类点,否则,需要增加迭代的次数,以保证最终聚 类结果的准确性。
样本数据之间的亲疏程度主要通过样本之间的距离、样本间的相关系数来 度量。SPSS根据变量数据类型的不同,采用不同的测定亲疏程度的方法。
10.2.2 层次聚类Q型聚类应用实例
经调查得知某班8个学生入学时的语文成绩和中期测试语文成绩,现要求 对这8名学生的语文成绩进行聚类,聚类的依据是入学语文成绩和第一次考试 的语文成绩。
10.3.2 快速聚类分析的计算过程及公式
快速聚类分析的计算过程如下:
1.指定聚类的类数
在SPSS中确定 个类的初始类中心点。SPSS会根据样本数据的实际情况,选择 个 由代表性的样本数据作为初始类中心。初始类中心也可以由用户自行指定,需要指定 组样本数据作为初始类中心点。
2. 确定中心点
接着,SPSS重新确定 个类的中心点。SPSS计算每个变量的变量值均值, 并以均值点作的类中心点;最后重复上面的两步计算过程,直到达到指定的 迭代次数或终止迭代的判断要求为止。
K-means聚类算法ppt课件

ppt课件.
1
K-means算法是很典型的基于距离的 聚类算法,采用距离作为相似性的评价指 标,即认为两个对象的距离越近,其相似 度就越大。
该算法认为类是由距离靠近的对象组 成的,因此把得到紧凑且独立的类作为最 终目标。
ppt课件.
2
假设数据集合为(x1, x2, …, xn),并 且每个xi为d维的向量,K-means聚类的目 的是,在给定分类组数k(k ≤ n)值的条 件下,将原始数据分成k类:
ppt课件.
4
数学表达式:
n:样本数。 k:样本分为k类。 rnk:第n个样本点是否属于第k类,属于则
rnk=1, 不属于则rnk=0。 μK:第k个中心点。
ppt课件.
5
k-means 要做的就是最小化
这个函数。
迭代的方法: 1、固定μK,得到rnk。 2、固定rnk,求出最优的μK。
ppt课件.
ppt课件.
12
K- medoids算法流程如下: 1、任意选取K个对象作为初始中心点 (O1,O2,…Oi…Ok)。 2、将余下的对象分到各个类中去(根据与 中心点最相近的原则); 3、对于每个类(Oi)中,顺序选取一个Or, 计算用Or代替Oi后的消耗—E(Or)。选择 E最小的那个Or来代替Oi。这样K个中心点 就改变了。
。不过,加上归一化规定,一个数据点的 隶属度的和总等于1:
ppt课件.
21
把n个元素xi(i=1,2,…,n)分为c个模糊组, 目标函数:
其中,m是大于1的实数,加权实数。uij 是xi属于类别j隶属度,cj是 类j的聚类中心。
ppt课件.
22
算法步骤: 1、用值在0,1间的随机数初始化隶属矩阵U,
聚类分析—K-means and K-medoids聚类1

2015/11/15
K-means聚类算法
算法描述
1. 为中心向量c1, c2, …, ck初始化k个种子 2. 分组: 将样本分配给距离其最近的中心向量 由这些样本构造不相交( non-overlapping ) 的聚类 3. 确定中心: 用各个聚类的中心向量作为新的中心 4. 重复分组和确定中心的步骤,直至算法收敛
在图像分割上的简单应用
例1:
1. 图片:一只遥望大海的小狗;
2. 此图为100 x 100像素的JPG图片,每个像素可以表 示为三维向量(分别对应JPEG图像中的红色、绿色 和蓝色通道) ; 3. 将图片分割为合适的背景区域(三个)和前景区域 (小狗); 4. 使用K-means算法对图像进行分割。
2015/11/15
k-中心点聚类方法
k-平均值算法对孤立点很敏感!
因为具有特别大的值的对象可能显著地影响数据的分布.
k-中心点(k-Medoids): 不采用簇中对象的平均值作为参照
点, 而是选用簇中位置最中心的对象, 即中心点(medoid)作 为参照点.
10 9 8 7 6 5 4 3 2 1 0 0 1 2 3 4 5 6 7 8 9 10 10 9 8 7 6 5 4 3 2 1 0 0 1 2 3 4 5 6 7 8 9 10 6 5 4 3 2 1 0 0 1 2 3 4 5 6 7 8 9 10 10 9 8 7
智能数据挖掘
Topic3--聚类分析 K-means &K-medoids 聚类
主要内容
K-means算法 Matlab程序实现 在图像分割上的简单应用 K-medoids算法
k-中心点聚类算法--PAM
k-means聚类方法的原理和步骤

k-means聚类方法的原理和步骤k-means聚类方法是一种常用的数据聚类算法,它可以将一组数据划分成若干个类别,使得同一类别内的数据相似度较高,不同类别之间的数据相似度较低。
本文将介绍k-means聚类方法的原理和步骤。
k-means聚类方法基于数据的距离度量,具体而言,它通过最小化各个数据点与所属类别中心点之间的距离来达到聚类的目的。
其基本原理可以概括为以下几点:-定义类别中心点:在聚类开始前,需要预先设定聚类的类别数量k。
根据k的数量,在数据集中随机选取k个点作为初始的类别中心点。
-分配数据点到类别:对于每一个数据点,计算其与各个类别中心点之间的距离,并将其分配到距离最近的类别中。
-更新类别中心点:当所有数据点分配完毕后,重新计算每个类别中的数据点的均值,以此获得新的类别中心点。
-重复分配和更新过程:将新的类别中心点作为参考,重新分配数据点和更新类别中心点,直到类别中心点不再变化或达到预设的迭代次数。
按照上述原理,k-means聚类方法的步骤可以分为以下几个阶段:-第一步,随机选择k个类别中心点。
-第二步,计算每个数据点与各个类别中心点之间的距离,并将其分配到距离最近的类别中。
-第三步,重新计算每个类别中数据点的均值,以此获得新的类别中心点。
-第四步,判断新的类别中心点是否与上一次迭代的中心点相同,如果相同,则结束聚类过程;如果不同,则更新类别中心点,返回第二步继续迭代。
-第五步,输出最终的类别划分结果。
需要注意的是,k-means聚类方法对聚类的初始中心点敏感,不同的初始点可能会导致不同的聚类结果。
为了避免陷入局部最优解,通常采用多次随机初始化的方式进行聚类,然后选取最好的结果作为最终的聚类划分。
综上所述,k-means聚类方法是一种常用的数据聚类算法,它通过最小化数据点与类别中心点之间的距离来实现聚类。
按照预设的步骤进行迭代,最终得到稳定的聚类结果。
在实际应用中,还可以根据具体问题进行算法的改进和优化,以满足实际需求。
K-means聚类分析
i
E 是一个数据集中所有对象的误差平方和,P 是一个对象,mi 是聚类 Ci 的质心, 即 mi
qC i
q
Ci
k‐means 聚类算法的具体步骤如下: ①从数据集中选择 k 个质心 C1,C2,…,Ck 作为初始的聚类中心; ②把每个对象分配到与之最相似的聚合。每个聚合用其中所有对象的均值来 代表, “最相似”就是指距离最小。对于每个点 Vi,找出一个质心 Cj,使它与其 间 的距离 d(Vi,Cj)最小,并把 Vi 分配到第 j 组; ③把所有的点都分配到相应的组之后重新计算每个组的质心 Cj; ④循环执行第②步和第③步,直到数据的划分不再发生变化。 该算法具有很好的可伸缩性,其计算复杂度为 O(nkt),其中,t 是循环的次数。 K‐means 聚类算法的不足之处在于它要多次扫描数据库,此外,它只能找出球形 的 类, 而不能发现任意形状的类。 还有, 初始质心的选择对聚类结果有较大的影响, 该算法对噪声很敏感。
K‐means 聚类分析
主要的聚类算法可以分为以下几种:划分聚类、层次聚类、密度型聚类、网 格型聚类和基于模型的聚类。 划分聚类算法把数据点集分为 k 个划分,每个划分作为一个聚类。它一般从 一个初始划分开始,然后通过重复的控制策略,使某个准则函数最优化,而每个 聚类由其质心来代表(k‐means 算法),或者由该聚类中最靠近中心的一个对象来 代 表(k‐medoids 算法)。 划分聚类算法收敛速度快, 缺点在于它倾向于识别凸形分布 大小相近、密度相近的聚类,不能发现分布形状比较复杂的聚类,它要求类别数 目 k 可以合理地估计,并且初始中心的选择和噪声会对聚类结果产生很大影响。 主要的划分聚类算法有 k‐means,EM,k‐medoids,CLARA,CLARANS 等。 下面主要介绍 K‐means 聚类方法。 k‐means 算法首先随机选择 k 个对象,每个对象代表一个聚类的质心。对于其 余的每一个对象,根据该对象与各聚类质心之间的距离,把它分配到与之最相似 的聚类中。然后,计算每个聚类的新质心。重复上述过程,直到准则函数会聚。 通常采用的准则函数是平方误差准则函数(squared‐error criterion),即 E i 1 pC p m
K-means聚类算法
K-means聚类算法1. 概述K-means聚类算法也称k均值聚类算法,是集简单和经典于⼀⾝的基于距离的聚类算法。
它采⽤距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越⼤。
该算法认为类簇是由距离靠近的对象组成的,因此把得到紧凑且独⽴的簇作为最终⽬标。
2. 算法核⼼思想K-means聚类算法是⼀种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中⼼,然后计算每个对象与各个种⼦聚类中⼼之间的距离,把每个对象分配给距离它最近的聚类中⼼。
聚类中⼼以及分配给它们的对象就代表⼀个聚类。
每分配⼀个样本,聚类的聚类中⼼会根据聚类中现有的对象被重新计算。
这个过程将不断重复直到满⾜某个终⽌条件。
终⽌条件可以是没有(或最⼩数⽬)对象被重新分配给不同的聚类,没有(或最⼩数⽬)聚类中⼼再发⽣变化,误差平⽅和局部最⼩。
3. 算法实现步骤1、⾸先确定⼀个k值,即我们希望将数据集经过聚类得到k个集合。
2、从数据集中随机选择k个数据点作为质⼼。
3、对数据集中每⼀个点,计算其与每⼀个质⼼的距离(如欧式距离),离哪个质⼼近,就划分到那个质⼼所属的集合。
4、把所有数据归好集合后,⼀共有k个集合。
然后重新计算每个集合的质⼼。
5、如果新计算出来的质⼼和原来的质⼼之间的距离⼩于某⼀个设置的阈值(表⽰重新计算的质⼼的位置变化不⼤,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终⽌。
6、如果新质⼼和原质⼼距离变化很⼤,需要迭代3~5步骤。
4. 算法步骤图解上图a表达了初始的数据集,假设k=2。
在图b中,我们随机选择了两个k类所对应的类别质⼼,即图中的红⾊质⼼和蓝⾊质⼼,然后分别求样本中所有点到这两个质⼼的距离,并标记每个样本的类别为和该样本距离最⼩的质⼼的类别,如图c所⽰,经过计算样本和红⾊质⼼和蓝⾊质⼼的距离,我们得到了所有样本点的第⼀轮迭代后的类别。
此时我们对我们当前标记为红⾊和蓝⾊的点分别求其新的质⼼,如图d所⽰,新的红⾊质⼼和蓝⾊质⼼的位置已经发⽣了变动。
K-means聚类分析
大连理工大学硕士学位论文K-means聚类算法的研究姓名:冯超申请学位级别:硕士专业:软件工程指导教师:吴国伟20071215大连理工大学硕士学位论文摘要聚类是数据挖掘领域中重要的技术之一,用于发现数据中未知的分类。
聚类分析已经有了很长的研究历史,其重要性已经越来越受到人们的肯定。
聚类算法是机器学习、数据挖掘和模式识别等研究方向的重要研究内容之一,在识别数据对象的内在关系方面,具有极其重要的作用。
聚类主要应用于模式识别中的语音识别、字符识别等,机器学习中的聚类算法应用于图像分割,图像处理中,主要用于数据压缩、信息检索。
聚类的另一个主要应用是数据挖掘、时空数据库应用、序列和异常数据分析等。
此外,聚类还应用于统计科学,同时,在生物学、地质学、地理学以及市场营销等方面也有着重要的作用。
本文是对聚类算法K-means的研究。
首先介绍了聚类技术的相关概念。
其次重点对K-means算法进行了分析研究,K-means算法是一种基于划分的方法,该算法的优点是简单易行,时间复杂度为00),并且适用予处理大规模数据。
但是该算法存在以下缺点:需要给定初始的聚类个数K以及K个聚类中心,算法对初始聚类中心点的选择很敏感,容易陷入局部最优,并且一般只能发现球状簇。
本文针对聚类个数足的确定、初始K个聚类中心的选定作了改进,给出了改进的算法MMDBK(Max.Min and Davies.BouldinIndex based K-means,简称MMDBK)。
算法的出发点是确保发现聚类中心的同时使同一类内的相似度大,而不同类之间的相似度小。
算法采用Davies.Bouldin Index 聚类指标确定最佳聚类个数,改进的最大最小距离法选取新的聚类中心,以及聚类中心的近邻查找法来保证各个类之间的较小的相似度。
文中最后使用KDD99数据集作为实验数据,对K-means算法以及MMDBK算法进行了仿真实验。
结果显示改进后的MMDBK算法在入侵检测中是有效的。
K-means聚类分析
4.1KBAC算法描述
Initialcenterset=Co mputeMinCover (simlarityGraph, aa)
record culster intinalcenter to corecanditidateset
E(Ai )
v j 1
X1, j
X2, j N
X m, j * I ( X1, j , X 2, j ,
, Xm, j )
6. I ( X1, j , X 2, j , , X m, j ) 为子集Xj的熵,计算公式为:
m
I ( X1, j , X 2, j , , X m, j ) pi, j log2 pi, j i 1
m
I (C) P(Ci ) log2 P(Ci ) i 1
P(Ci ) | Ci | / N,| Ci | 为类别Ci中样本数量,| |返回 集合中元素个数运算
4.特征属性Ai的信息增益计算公式:
Gain分成子集的熵,计算公式:
其中pi,j为Xj中的属于Ci的概率,计算公式: pi,j =|Xi,j|/Xj
7.属性Ai的信息增益比例公式为:
GainRation( Ai ) Gain( Ai ) / Spilt( Ai )
其中Spilt(Ai)计算公式:
v
Spilt( Ai ) p j * log2 Pj , 其中Pj | X j | / X j 1
每时每刻大量数据都在产生
1. 引言
目前有的聚类经典算法 1)k-means算法 2)k-原型算法 3)模糊聚类算法 4)基于粗糙的k-model算法
2. K-means聚类方法的简单分析
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第9章K-Means 聚类、辨别分析9.1理解聚类分析餐饮企业经常会碰到这样的问题:1)如何通过餐饮客户消费行为的测量,进一步评判餐饮客户的价值和对餐饮客户进行细分,找到有价值的客户群和需关注的客户群?2)如何合理对菜品进行分析,以便区分哪些菜品畅销毛利又高,哪些菜品滞销毛利又低?餐饮企业遇到的这些问题,可以通过聚类分析解决。
9.1.1常用聚类分析算法与分类不同,聚类分析是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法。
与分类模型需要使用有类标记样本构成的训练数据不同,聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。
聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将他们划分为若干组,划分的原则是组样本最小化而组间(外部)距离最大化,如图9-1所示。
图9-1 聚类分析建模原理常用聚类方法见表9-1。
表9-1常用聚类方法类别包括的主要算法常用聚类算法见图9-2。
表9-2常用聚类分析算法9.1.2K-Means聚类算法K-Means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。
1.算法过程1)从N个样本数据中随机选取K个对象作为初始的聚类中心;2)分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中;3)所有对象分配完成后,重新计算K个聚类的中心;4)与前一次计算得到的K个聚类中心比较,如果聚类中心发生变化,转2),否则转5);5)当质心不发生变化时停止并输出聚类结果。
聚类的结果可能依赖于初始聚类中心的随机选择,可能使得结果严重偏离全局最优分类。
实践中,为了得到较好的结果,通常以不同的初始聚类中心,多次运行K-Means算法。
在所有对象分配完成后,重新计算K个聚类的中心时,对于连续数据,聚类中心取该簇的均值,但是当样本的某些属性是分类变量时,均值可能无定义,可以使用K-众数方法。
2. 数据类型与相似性的度量 (1) 连续属性对于连续属性,要先对各属性值进行零-均值规,再进行距离的计算。
K-Means 聚类算法中,一般需要度量样本之间的距离、样本与簇之间的距离以及簇与簇之间的距离。
度量样本之间的相似性最常用的是欧几里得距离、曼哈顿距离和闵可夫斯基距离;样本与簇之间的距离可以用样本到簇中心的距离(,)i d e x ;簇与簇之间的距离可以用簇中心的距离(,)i j d e e 。
用p 个属性来表示n 个样本的数据矩阵如下:1111p n n p x x x x ⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦欧几里得距离(,)d i j =曼哈顿距离1122(,)||+||++||i j i j ip jpd i j x x x x x x =--- (9-2)闵可夫斯基距离(,)d i j = (9-3)q 为正整数,=1q 时即为曼哈顿距离;=2q 时即为欧几里得距离。
(2) 文档数据对于文档数据使用余弦相似性度量,先将文档数据整理成文档—词矩阵格式,如表9-3。
表9-3 文档—词矩阵两个文档之间的相似度的计算公式为:(,)cos(,)||||i jd i j i j i j ⋅==(9-4)3. 目标函数使用误差平方和SSE 作为度量聚类质量的目标函数,对于两种不同的聚类结果,选择误差平方和较小的分类结果。
连续属性的SSE 计算公式为:21(,)iKi i x E SSE dist e x =∈=∑∑ (9-5)文档数据的SSE 计算公式为:21cos(,)iKii x E SSE e x =∈=∑∑ (9-6)簇i E 的聚类中心i e 计算公式为:1ii x E ie x n ∈=∑ (9-7)表9-4 符号表下面结合具体案例来实现本节开始提出问题。
部分餐饮客户的消费行为特征数据如表9-5。
根据这些数据将客户分类成不同客户群,并评价这些客户群的价值。
表9-5消费行为特征数据采用K-Means聚类算法,设定聚类个数K为3,距离函数默认为欧氏距离。
执行K-Means聚类算法输出的结果见表9-6。
表9-6聚类算法输出结果以下是绘制的不同客户分群的概率密度函数图,通过这些图能直观地比较不同客户群的价值。
图9-2分群1的概率密度函数图图9-3分群2的概率密度函数图图9-4分群3的概率密度函数图客户价值分析:分群1特点:R主要集中在10~30天之间;消费次数集中在5~30次;消费金额在1600~2000。
分群2特点:R分布在20~45天之间;消费次数集中在5~25次;消费金额在800~1600。
分群3特点:R分布在30~60天之间;消费次数集中在1~10次;消费金额在200~800。
对比分析:分群1时间间隔较短,消费次数多,而且消费金额较大,是高消费高价值人群。
分群2的时间间隔、消费次数和消费金额处于中等水平。
分群3的时间间隔较长,消费次数和消费金额处于较低水平,是价值较低的客户群体。
9.1.3 聚类分析算法评价聚类分析仅根据样本数据本身将样本分组。
其目标是,组的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。
组的相似性越大,组间差别越大,聚类效果就越好。
(1) purity 评价法purity 方法是极为简单的一种聚类评价方法,只需计算正确聚类数占总数的比例:1(,)max ||k i ik purity X Y x y n =⋂∑ (9-8)其中,()12,,,k x x x x =是聚类的集合。
k x 表示第k 个聚类的集合。
()12,,,k y y y y =表示需要被聚类的集合,i y 表示第i 个聚类对象。
n 表示被聚类集合对象的总数。
(2) RI 评价法实际上这是一种用排列组合原理来对聚类进行评价的手段,RI 评价公式如下:R WRI R M D W+=+++ (9-10)其中R 是指被聚在一类的两个对象被正确分类了,W 是指不应该被聚在一类的两个对象被正确分开了,M 指不应该放在一类的对象被错误的放在了一类,D 指不应该分开的对象被错误的分开了。
(3) F 值评价法这是基于上述RI 方法衍生出的一个方法,F 评价公式如下:22(1)prF p rααα+=+ (9-11)其中R p R M =+,Rr R D=+。
实际上RI 方法就是把准确率p 和召回率r 看得同等重要,事实上有时候我们可能需要某一特性更多一点,这时候就适合使用F 值方法。
9.2实例1—利用K-Means 聚类确定患冠心病的高风险人群9.2.1 背景和概要说明Sonia 在一家主要健康保险公司担任项目总监。
最近她一直在阅读医学刊物和其他文章,并发现好多文章都在强调体重、性别和胆固醇对患冠心病的影响。
她阅读的研究文件一次又一次地确认这三个变量之间存在关联。
尽管人们无法在自己的性别方面下功夫,但无疑可以通过选择合理的生活方式来改变胆固醇水平和体重。
于是她开始提议公司为健康保险客户提供体重和胆固醇管理项目。
在考虑她的工作在哪里开展可能最为有效时,她希望了解是否存在发生高体重和高胆固醇风险最高的自然群体,如果存在,这些群体之间的自然分界线在哪里。
9.2.2业务理解Sonia 的目标是确定由公司提供保险服务且因体重和/或高胆固醇患冠心病的风险非常高的人员,并试图联络这些人员。
她了解患冠心病风险较低的人员,即体重和胆固醇水平较低的人员不太可能会参加她提供的项目。
她还了解可能存在高体重和低胆固醇、高体重和高胆固醇,以及低体重和高胆固醇的保单持有人。
她还认识到可能会有许多人介于它们之间。
为了实现目标,她需要在数以千计的保单持有人中搜索具有类似特征的群体,并制定相关且对这些不同的群体有吸引力的项目和沟通方式。
9.2.3数据理解使用该保险公司的索赔数据库,Sonia 提取了 547 个随机挑选的人员的三个属性,即受保人最近的体检表上记录的体重(单位:磅)、最近一次验血时测得的胆固醇水平,以及性别。
和在许多数据集中的典型做法一样,性别属性使用 0 来表示女性,并使用 1 来表示男性。
我们将使用从 Sonia 公司的数据库中提取的这些样本数据构建聚类模型,以便帮助 Sonia 了解公司的客户(即健康保险保单持有人)根据体重、性别和胆固醇水平进行分组的情况。
我们应切记在构建模型时,均值尤其容易受到极端离群点的不当影响,因此在使用 K 均值聚类数据挖掘方法时查看是否存在不一致的数据至关重要。
9.2.4数据准备将“.K-Means聚类.csv”数据集导入到 RapidMiner 数据存储库中,保存为//Local Repository/data/K-Means聚类。
我们可以看到先前定义的三个属性有 547 个观察项。
我们可以看到三个属性中的每个属性的平均值,以及对应的标准差和围,如图9.5。
其中没有看起来不一致的值(切记前面关于使用标准差查找统计离群点的备注)。
由于没有缺失的值要处理,因此数据看起来非常干净,并可直接进行挖掘。
图9.5 数据基本信息9.2.5操作步骤第一步:对数据进行聚类将数据拖拽到操作视图界面,检索“k-Means”操作符并将其与数据进行连接,然后与输出端口连接,点击运行,我们可以看到如图运行结果,在参数设置如图9.6 中,我们可以设计聚成的k的类数,以及“max runs”最大循环迭代的次数。
图9.6 k-Means聚类参数设置第二步:结果集过滤将“Filter Examples”结果集过滤操作符拖进操作界面,如图9.7,在参数设置中,选择类别等于类别0,如图9.8。
图9.7 操作符流程视图图9.8 结果集过滤参数设置第三步:输出结果点击运行,我们可以看到如图9.9的输出结果图9.9 筛选类别后的输出结果这样我们的主人公,就可以根据显示输出的结果,来重点关注疾病的高发人群,从而有针对性的进行服务。
9.3实例2—利用判别分析技术分类运动员专攻项目9.3.1背景和概要说明Gill 运营着一个体育学院,旨在帮助高中年纪的运动员最大限度地发挥其在体育方面的潜力。
对于学院的男生,他侧重于四个主要体育项目,即橄榄球、篮球、棒球和曲棍球。
他发现虽然许多高中运动员在念高中时都喜欢参加多种体育项目,但随着他们开始考虑在大学时从事的体育项目,他们将倾向于专攻某一项。
通过多年来与运动员之间的合作,Gill 整理了一个容非常广泛的数据集。
现在他想知道他是否可以使用先前部分客户的以往成绩,为即将到来的高中运动员预测主攻的体育项目。
最终,他希望可以就每个运动员可能最应选择专攻哪个体育项目,向他们提供建议。
通过评估每个运动员在一系列测试中的成绩,Gill 希望我们可以帮助他确定每个运动员在哪个体育项目方面资质最高。
9.3.2判别分析的含义判别分析(Discriminant Analysis,简称DA)技术是由费舍(R.A.Fisher)于1936年提出的。